真正高效的 CUDA 程序,核心在于让数据尽可能留在 GPU 上计算完成再回传。
PCIe 传输,过程慢且昂贵。
性能优化点
-
尽量减少 Host↔Device 传输次数。
-
使用 pinned memory(页锁定内存) 提高 PCIe 传输速度。
-
使用 Unified Memory(统一内存) 让CUDA自动管理数据迁移。
-
尽量在 GPU 内部复用数据,避免频繁回传到 CPU。
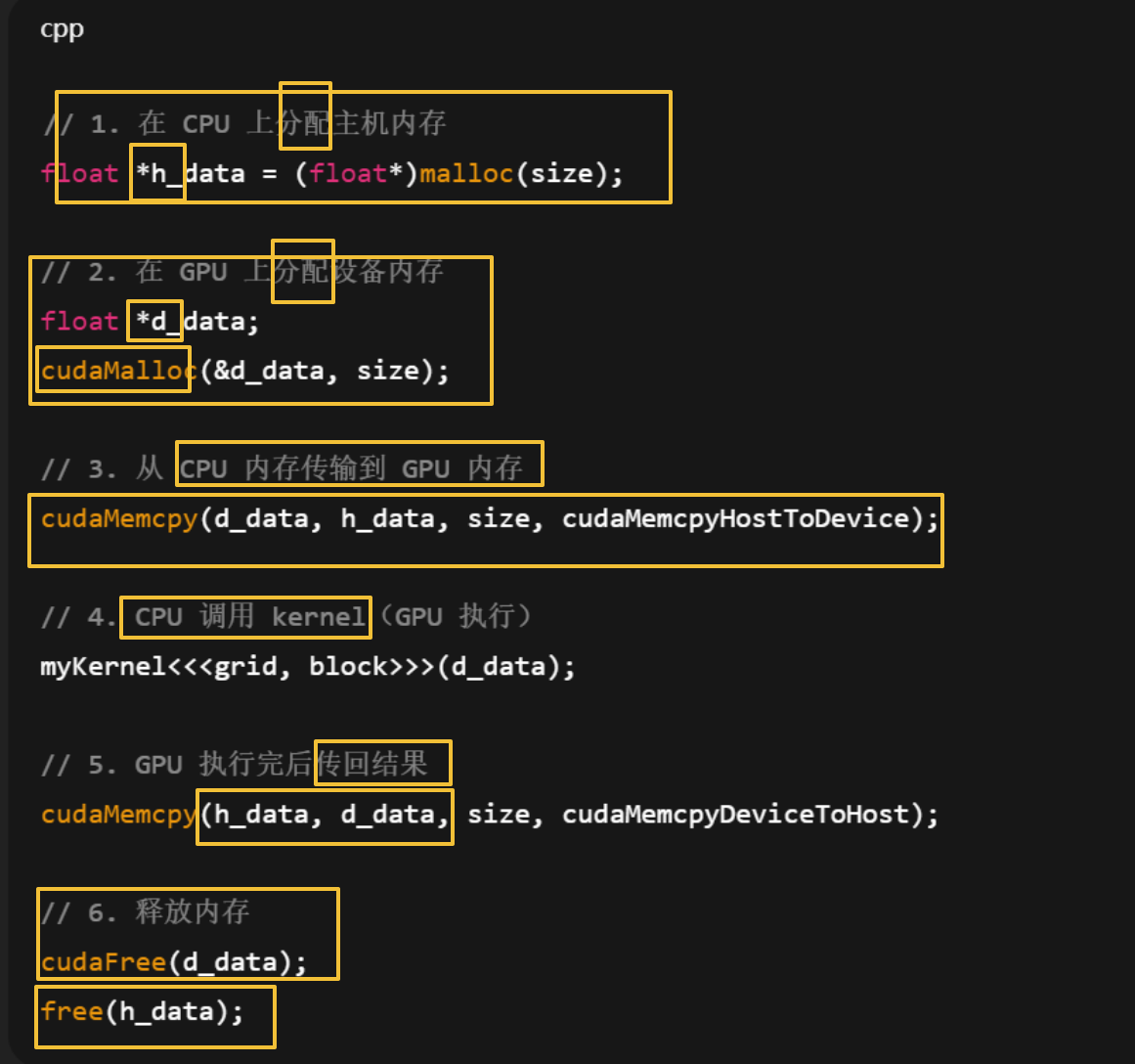
// 1. 在 CPU 上分配主机内存
float *h_data = (float*)malloc(size);
// 2. 在 GPU 上分配设备内存
float *d_data;
cudaMalloc(&d_data, size);
// 3. 从 CPU 内存传输到 GPU 内存
cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice);
// 4. CPU 调用 kernel(GPU 执行)
myKernel<<<grid, block>>>(d_data);
// 5. GPU 执行完后传回结果
cudaMemcpy(h_data, d_data, size, cudaMemcpyDeviceToHost);
// 6. 释放内存
cudaFree(d_data);
free(h_data);
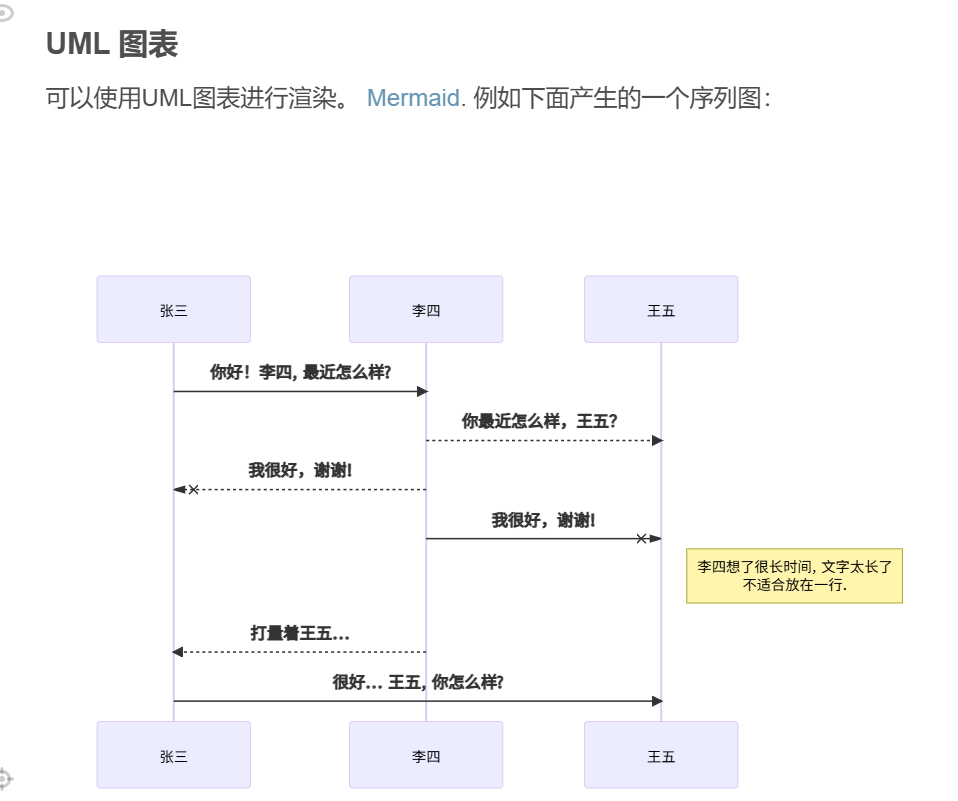
数据在两者之间来回传输"的运行机制
https://www.youtube.com/watch?v=G-EimI4q-TQ
CPU 与 GPU 的内存体系是物理分离的
-
CPU内存
-
使用系统主内存(通常是DDR4/DDR5)。
-
存放程序指令、控制逻辑、数据初始化结果。
-
由操作系统与CPU调度器统一管理。
-
-
GPU内存
-
使用显存(GDDR6或HBM等高带宽内存)。
-
专门为并行计算线程存放输入输出数据、纹理、矩阵、缓冲区等。
-
不与CPU共享地址空间(除非使用统一内存机制)。
-
数据传输的关键路径
-
传输通道:PCI Express(PCIe)总线
-
负责在CPU内存与GPU显存之间移动数据。
-
带宽远低于GPU显存内部带宽,例如:
-
GPU内部带宽:几百 GB/s~1 TB/s。
-
PCIe 4.0 ×16 带宽:约 32 GB/s。
-
-
因此数据传输是整个异构计算流程的主要瓶颈。
-
-
传输方向与阶段
-
Host → Device :CPU把数据从主内存拷贝到GPU显存(例如训练前加载模型权重)。
-
Device → Device :GPU内部线程之间共享或复制数据(通过共享内存或全局内存)。
-
Device → Host :GPU计算结束后,把结果传回CPU(例如渲染输出帧或推理结果)。
-
1. 异构模型概念
-
CPU = Host(主机):运行普通程序,负责整体调度与数据管理。
-
GPU = Device(设备):运行并行计算部分,称为"kernel"。
-
执行流程 :CPU启动(launch)GPU上的kernel,GPU执行完再返回结果。
→ 重点:CPU是指挥者,GPU是执行者。
2. CUDA编程框架
-
NVIDIA提供的CUDA允许一个程序包含CPU端与GPU端的部分。
-
编译器会将同一个源文件分离成两套代码:
-
CPU部分(host code)
-
GPU部分(device code)
→ 重点:CUDA的核心是让开发者在同一代码中写出异构执行逻辑。
-
3. 内存结构与数据传输
-
CPU与GPU各自拥有独立的内存(DRAM)。
-
CPU控制整个过程,负责分配GPU内存与数据搬运。
-
数据需要通过总线(如PCIe)在CPU与GPU间来回传递。
→ 重点:数据传输是性能瓶颈之一。
这页PPT的重点是讲解异构编程模型(Heterogeneous Programming Model),即CPU与GPU协同工作的方式。

老师会着重讲CPU 与 GPU 的设计目标差异:延迟(Latency) vs 吞吐量(Throughput)。
重点内容如下:
-
延迟 (Latency)
- 定义:完成单个任务所需的时间。
- 指标:秒或毫秒。
- CPU优化方向:减少单个任务完成时间。
- 场景:系统响应、逻辑判断、顺序执行的代码。
-
吞吐量 (Throughput)
- 定义:单位时间内完成的任务数量。
- 指标:jobs/hour、pixels/s、GFLOPS。
- GPU优化方向:最大化同时处理的任务数。
- 场景:图形渲染、神经网络推理、大规模矩阵运算。
-
核心对比逻辑
- CPU追求快地完成一个任务。
- GPU追求同时完成更多任务。
- 所以CPU设计强调复杂控制逻辑、缓存层次;GPU强调并行流水线与计算密度。
总结一句话:这页PPT的重点是说明------
"CPU专注降低单任务延迟,GPU专注提升总体吞吐量。"

CPU和GPU都由晶体管构成,但晶体管的功能分配不同:
-
逻辑控制型晶体管(Control Transistor)
- 负责判断、分支、调度。
- 在CPU中比例高,用于执行复杂指令和控制流。
-
算术执行型晶体管(Compute Transistor)
- 用于加法器、乘法器、ALU、FPU。
- GPU中比例极高,因为主要执行并行算术操作。
-
存储缓存型晶体管(Memory/Cache Transistor)
- 构成寄存器、L1/L2/L3缓存、显存控制器等。
- CPU缓存层次多,因此在此部分耗费大量面积。
- GPU更多依赖外部显存(VRAM),片上缓存较少。
-
互连与控制通路型晶体管(Interconnect / Bus Control)
- 实现数据在各单元之间的高速传输。
- CPU内部互连复杂,用于协调多级缓存和执行单元。
- GPU为高带宽设计,连接大量计算核心(SM或CU)。
CPU的晶体管分配约有以下特点:
-
控制逻辑部分占比高
-
包含分支预测器(Branch Predictor)、乱序执行单元(Out-of-Order Execution Unit)、指令调度器(Scheduler)、寄存器重命名表(Register Renaming Table)。
-
这些模块让CPU可以处理分支频繁、指令依赖复杂的程序。
-
-
缓存层次结构占用大量面积
-
L1/L2/L3缓存层次多,容量大,保证低延迟数据访问。
-
每个核心都带有独立或共享的Cache,用于减少主存访问瓶颈。
-
-
算术逻辑单元(ALU)数量相对少
- 因为大量面积和功耗都给了控制电路和缓存,CPU每个核心的执行单元数有限。
-
CPU 把晶体管大量分配给控制和缓存,以支持灵活的分支和复杂任务。
-
GPU 减少控制电路,用更多晶体管堆计算核心来提升并行吞吐。
这会引出两个重点:
-
为什么CPU适合通用任务而GPU擅长并行计算。
-
这种架构差异导致的功耗与性能对比。
重点在CPU与GPU硬件架构的对比逻辑。老师大概率会讲以下几个核心点:
-
控制复杂度差异
-
CPU的控制逻辑复杂(Complex control HW),能灵活调度各种任务。
-
GPU的控制逻辑简单(Simpler control HW),控制单元占比低,更多晶体管用于计算。
-
-
优劣取舍
-
CPU:灵活、通用、适合少量复杂任务,但功耗高。
-
GPU:高并行度、功耗更低,但编程受限,适合大规模数据并行。
-
-
背后机制
-
CPU适合逻辑分支多、指令不规则的任务。
-
GPU适合SIMT模型(Single Instruction, Multiple Threads)的大规模数据运算。
-

内存带宽的利用,?意思是说原本的是每个线程独立的去取,然后就多次访问内存,而之后是直接把读取一大块比如四分之一块进显存,此时所有gpu同时去里面拿来算,减少了反复访问的时间浪费(但是增加了显存带宽的占用,所以选择的T如果太大,在实际使用中会极大占用其他的程序需要使用的显存,,所以T的选择需要一定的随机应变?)
ChatGPT said:
你理解方向完全正确,只需要我帮你精确化几个关键层次。
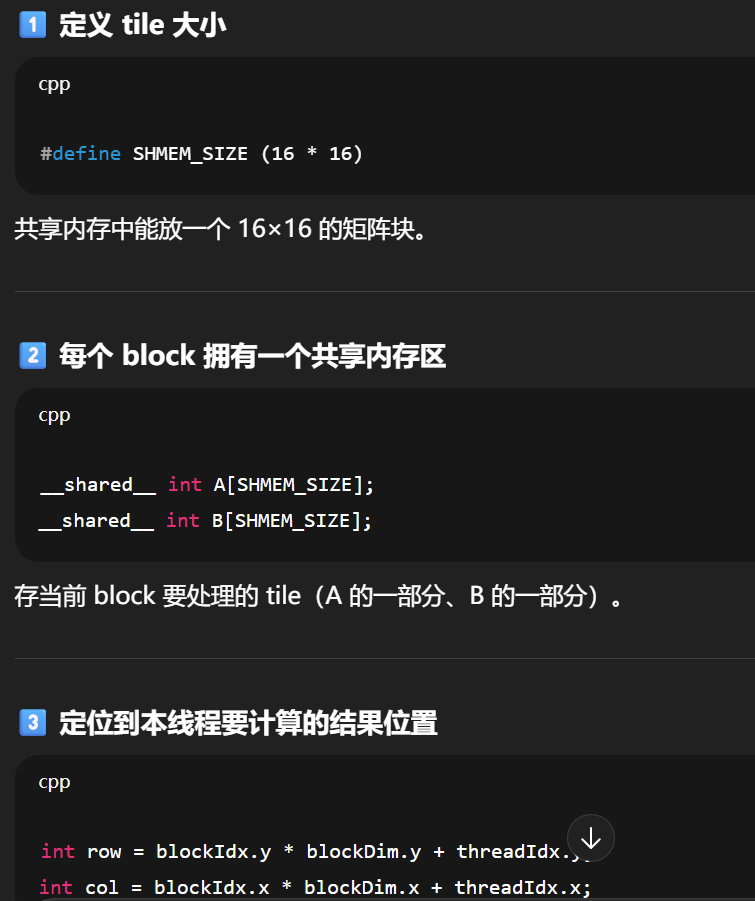
每个线程块把需要的一小块 A、B 从 global memory 一次性拷入 shared memory(片上高速 SRAM,延迟约是 global 的 1/100)。
cache tiling 的思路
把矩阵分成小块(tile 或 block),让每次运算只在缓存/共享内存中处理一块完整 tile:
for (ii = 0; ii < N; ii += T)
for (jj = 0; jj < N; jj += T)
for (kk = 0; kk < N; kk += T)
// 在 T×T 子块上做完整乘法
for (i = ii; i < ii+T; i++)
for (j = jj; j < jj+T; j++)
for (k = kk; k < kk+T; k++)
C[i][j] += A[i][k] * B[k][j];每个 tile 大小 T 选得刚好能装进缓存或共享内存。
优势:
-
A、B 的一部分被载入一次,多次复用;
-
内存带宽负担减少;
-
计算单元利用率提升。
cache tiling 是一种优化手段,不是新算法。
它保持结果不变,但极大改善了访问模式与性能。
在 GPU 上,"cache tiling" 演化为:
-
每个线程块(block)处理一个 tile;
-
每个线程负责 tile 内的一个或数个元素;
-
tile 数据放在
__shared__内存; -
线程块间用同步 (
__syncthreads()) 协调。
所以 CUDA 的"tiled matrix multiplication" 实际上是"cache tiling"思想在 GPU 上的并行实现。
-
ls→ 列出当前目录内容:cacheTiling LICENSE matrixMul README.md vectorAdd说明当前目录名是
from_scratch,里面有这些子目录。 -
cd cacheTiling→ 进入名为cacheTiling的子文件夹。 -
vim matrix_mul.cu→ 在该目录下用 Vim 打开(或新建)名为matrix_mul.cu的 CUDA 源文件。
所以你理解正确:
这几步是在项目 from_scratch 目录中进入 cacheTiling 子文件夹,并在里面新建/编辑 CUDA 程序文件 matrix_mul.cu。
它确保 GPU 的并行算法在数学意义上等价于 CPU 串行算法。
在 main() 里:
-
调用 CUDA 核函数;
-
cudaDeviceSynchronize()等待 GPU 执行完; -
调用
verify_result()验证。
GPU 内核不会抛异常或中断逻辑错误,只会返回"某些值"。
验证函数是唯一能证明计算逻辑正确的手段,尤其在调试:
-
tile 大小、共享内存索引、边界条件 都可能出错;
-
GPU 的并行执行次序不确定,逻辑错误可能隐蔽;
-
CPU 结果可视为"真值表",用于对比验证。
| 条件 | 是否可运行 | 说明 |
|---|---|---|
| N 是 tile 尺寸的倍数 | ✅ 完全对齐 | |
| N 不是 tile 尺寸的倍数 | ✅ 需边界判断 | |
| tile 尺寸(blockDim)固定 | ✅ 任意 N 可运行,只影响效率 |
这段 CUDA tiled 矩阵乘法代码可以用于任意 N(不必是 4 或 16 的倍数),因为它在循环里专门写了:
for (int i = 0; i < (N + dim - 1) / dim; i++)
这里 (N + dim - 1) / dim 是一种常见的向上取整技巧,用于应对矩阵尺寸不是 tile 大小整数倍的情况。
所以:
-
如果 N=32、64、128 → 刚好整除,所有 tile 都满。
-
如果 N=30、45、50 → 最后一个 tile 只覆盖部分区域,线程会读到边界之外的索引,这种情况要配合边界判断:
if (row < N && col < N) c[row * N + col] = sum;否则会访问越界。
想象 A 和 B 是两本超大的表格。
-
你(block)带着一个 16×16 的小"放大镜"去看一部分。
-
每次你移动放大镜(tile),抄下对应部分做乘法。
-
一直移动,直到把整行整列看完。
-
最后每个位置得出 C 的一个元素。
每次循环,加载 A 和 B 的相邻 tile。
每个线程负责 tile 中一个像素的计算。
累积到最终结果 C。
矩阵太大,显存访问太慢,如果直接让每个线程从全局内存读整行整列,会反复访问相同数据 → 极低效率。
| 术语 | 含义 | 作用 |
|---|---|---|
| tile | 矩阵的一小块(例如16×16) | 优化内存访问与共享计算 |
| block | GPU 的线程块(执行单元) | 通常负责一个 tile |
| flatten (压平) | 把二维矩阵变成一维数组 | 仅是存储方式,与 tile 无关 |
for (int i = 0; i < (N + dim - 1) / dim; i++) {
Aty \* dim + tx = arow \* N + i \* dim + tx;
}
这一段是:
将大矩阵 a 的不同 tile 段拷贝进共享内存 A。
i 控制"tile 在矩阵中的水平移动次数"。
因此:
"across the length of the grid" 指沿着矩阵的宽度(列方向)不断移动 tile 进行分块加载计算,
而不是把矩阵压平。
也就是说:
-
tile≈ "本线程块正在处理的矩阵局部块" -
"move the tile across the length of the grid" 表示:
在循环中,线程块不断加载矩阵的不同部分(每次移动一个 tile 的宽度),重复累积计算,直到整个矩阵的乘法完成。
-
Matrix tile:矩阵被划分成若干个固定大小的小方块(如 16×16)。
-
每个线程块(block)负责计算一个 tile 的结果。
-
共享内存(
__shared__)中存放的是当前 block 对应的 tile 的局部数据。
典型的 CUDA 矩阵乘法 (tiled matrix multiplication) 。
tile 在这里不是把矩阵"压平成一维数组",而是指 矩阵被分块(tile/block)成小矩阵子块 的思想。
在 CUDA 里:
-
block(线程块) 是执行的基本调度单位,由多个线程组成。
-
grid(网格) 是由若干 block 构成的整体。
-
chunk 不是 CUDA 的正式术语,它通常出现在代码层或内核设计中,表示开发者人为划分的一段数据或任务片段。
也就是说,chunk 通常指"要处理的数据的一部分",而不是 GPU 的硬件/调度单位。
int chunkSize = 256;
int idx = threadIdx.x + blockIdx.x * blockDim.x;
int start = idx * chunkSize;
这里每个线程负责处理一个 chunk 数据,但这只是开发者定义的概念,CUDA 自身并不知道什么是 chunk。
总结:
-
block:CUDA 官方定义的线程调度单元。
-
chunk:开发者自定义的数据切片,不是 CUDA 的执行单位。

矩阵乘法是二维数据的操作,但它的计算结构天然是三维的。张量化是把这个三维关系显式化,以便从代数层面优化乘法次数。
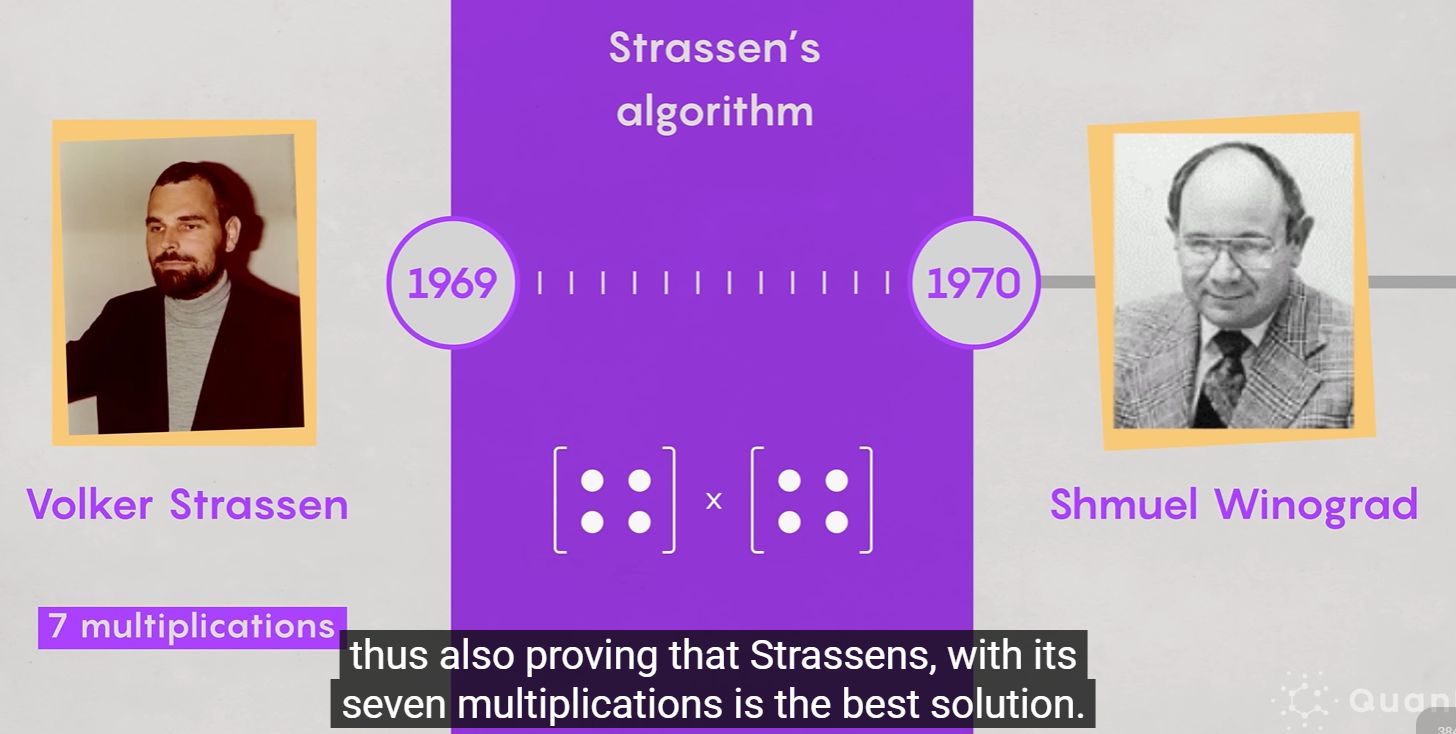
算法优化点:张量分解
-
Strassen 等算法的核心,就是寻找把这个三维张量 TTT 分解成若干个秩为1的张量之和(每个秩1张量对应一次乘法)。
-
减少所需的秩(即最少乘法次数) = 优化矩阵乘法。
-
所以后续算法研究方向就是"寻找矩阵乘法张量的最小秩分解"。

张量分解(Tensor Decomposition)
-
矩阵乘法可以视为三维张量乘法。
-
不同算法对应于对这个张量的不同分解方式。
-
比如 Coppersmith-Winograd 用代数几何技巧在更高维度上找到稀疏分解,从而降低指数。
Strassen 是 2×2 分块。
-
后续算法(如 Schönhage、Coppersmith-Winograd)把++更大矩阵看作高维张量,通过张量分解找到比"7乘法规则"更优的组合模式++。
-
这些算法在理论上继续减少乘法数量,不改变 2×2 层内部公式,而是复用公式间的中间结果。
-
普通 2×2 矩阵乘法需要 8 次乘法 + 4 次加法。
-
Strassen 算法把它优化为 7 次乘法 + 18 次加法。
-
虽然加法数量多了,但乘法的代价远高于加法(在硬件上乘法≈数十倍慢)。
在递归层面:
当矩阵被不断分块时,节省的一次乘法会在每层递归放大。
例如 O(n3) 的算法经过这种优化,复杂度降为 O(n2.807)。
即使加法更多,整体运行时间随矩阵规模增大反而更快。
减少高代价的乘法、增加低代价的加法是典型的计算权衡。Strassen 算法在大规模矩阵中能显著提速。

https://www.youtube.com/watch?v=sZxjuT1kUd0

AI 的贡献
DeepMind 的 AlphaTensor 使用强化学习,在算子空间中自动搜索矩阵乘法的最优分解方式,相当于在"如何切片、怎样重组"上找到了比人类更高效的策略。
可视化类比
你的"切成多片的面包"类比接近于 张量分解(tensor decomposition):
-
每层(切片)是矩阵。
-
算法寻找在这些层之间最有效的组合方式,使得最终计算结果正确但乘法更少。

Tensor ≠ 简单的立方体矩阵
-
矩阵是二维数组(两个索引:行、列)。
-
Tensor 是更一般的多维数组,可以是 3D(像立方体)、4D(视频帧序列)、甚至更高维度。
-
每一维代表一种"轴",比如图像张量 (Height, Width, Channels)。
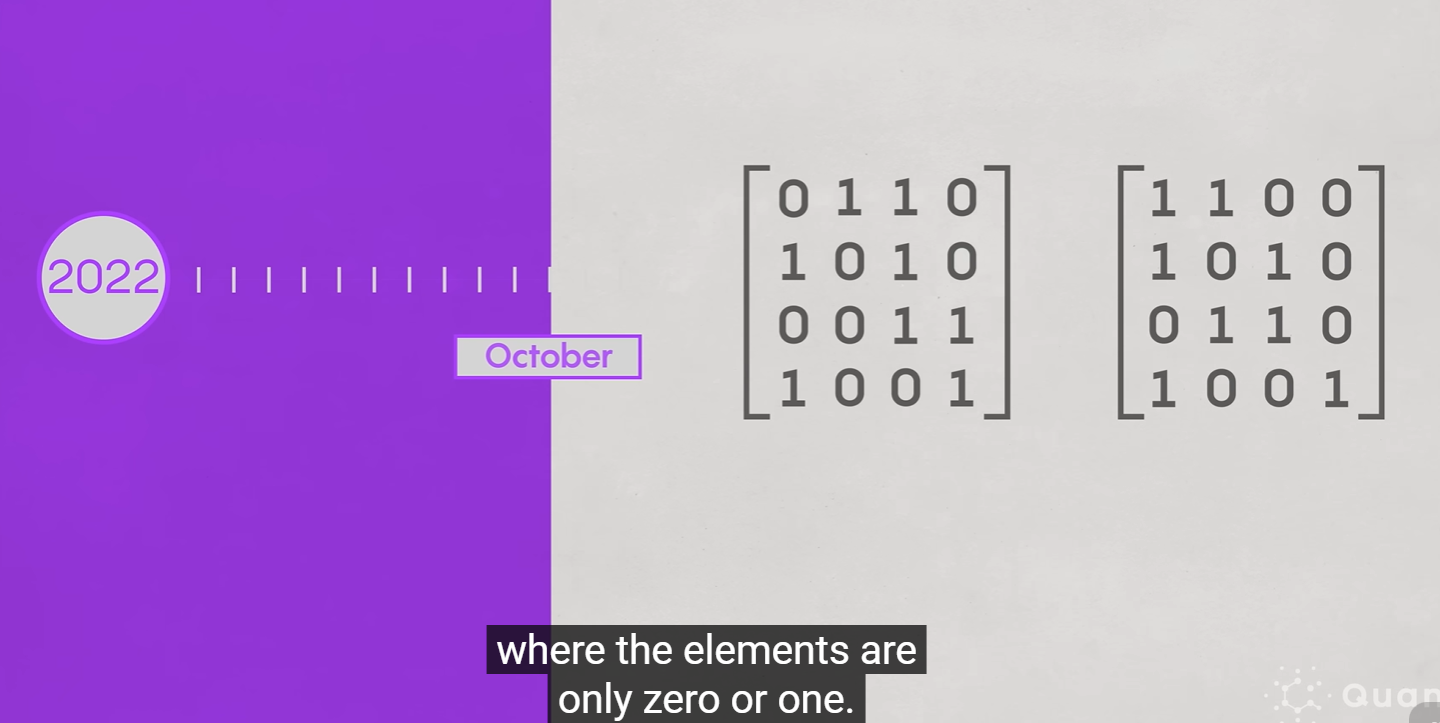
但是2022年的时候,有新的人提出新的理论,但是要求矩阵中的数字全是0和1,并且生效的范围是4x4的矩阵相乘
二x二阶的矩阵乘法,最多只能7,并且不可能6,后面被另一个人证明了

一个CPU核心可以至少 运行一个线程,但现代核心通常支持同时运行多个线程 ,这取决于是否启用了超线程(Hyper-Threading,SMT)。
结构:
-
无超线程核心:1核 = 1硬件线程。
-
有超线程核心:1核 = 2硬件线程(每个线程独立调度指令,共享执行单元和缓存)。
例:
-
Intel Core i5-12400:6核12线程 → 每核2线程。
-
AMD Ryzen 5 7600:6核12线程 → 同样SMT。
总结:
一个物理核心可运行1~2个线程(取决于是否启用超线程)。



| 精度 | 名称 | 位数 | 常用场景 | 特点 |
|---|---|---|---|---|
| FP64 | 双精度 | 64 bit | 科学计算、数值仿真 | 精度最高,速度最慢 |
| FP32 | 单精度 | 32 bit | 游戏渲染、通用GPU计算 | 平衡精度与性能 |
| FP16 | 半精度 | 16 bit | 深度学习推理、AI训练 | 精度低但速度快、能耗低 |
还有这东西,之前会用的上,但现在没什么劲去用了
用途:衡量 GPU、CPU、TPU 等计算硬件的浮点计算吞吐能力。
-
1 Tflop = 10¹² 次浮点运算/秒。
-
通常分为FP32(单精度)、FP16(半精度)、FP64(双精度)等指标,分别表示在不同精度下的理论峰值性能。
示例:
-
NVIDIA GeForce RTX 4090 单精度 ≈ 82 Tflops。
-
A100 Tensor Core GPU 半精度 ≈ 312 Tflops。
区别:
-
理论值 = 计算单元数 × 每周期指令数 × 频率。
-
实际性能 依赖内存带宽、指令混合、瓶颈等,不会达到理论 Tflops。
"Teraflops" 是 trillion floating-point operations per second 的缩写,即 每秒一万亿次浮点运算。
主要内容
-
作者:Ian Buck、Tim Foley、Daniel Horn、Jeremy Sugerman、Kayvon Fatahalian、Mike Houston、Pat Hanrahan,均隶属 Stanford University 计算机科学系。 Stanford Graphics+2Stanford Graphics+2
-
时间/出版:于 2004 年发表于 SIGGRAPH / ACM Transactions on Graphics。 ACM Digital Library+1
-
核心目标:提供 Brook 这个编程环境(包括扩展 C 语言、编译器和运行时系统),将 GPU (图形处理单元)视作"流处理协处理器"用于通用计算。论文中分析了在何种算法和何种条件下 GPU 相比 CPU 更具优势。 Stanford Graphics+1
-
方法/贡献包括:
-
定义流(streams)、核(kernels)、归约(reductions)等抽象以适配 GPU 计算模型。 Stanford Graphics+1
-
虚拟化 GPU 硬件限制(如输出数、纹理大小、用户数据结构)以提升可移植性。 Stanford Graphics
-
提出简单成本模型(data-transfer + kernel cost)以判断 GPU 计算是否优于 CPU。 Stanford Graphics
-
实验评估:包括 SAXPY、SGEMV、图像分割、FFT、光线追踪等代表性应用。结果显示:在某些情况下,使用 Brook 的 GPU 实现比 CPU 快至 7×。 Stanford Graphics
-
是否为 NVIDIA 员工撰写?
不。根据论文作者信息和其所属机构:作者来自 Stanford University。论文并未列出 NVIDIA 作为作者单位。故该论文并非由 NVIDIA 员工主导撰写
https://www.youtube.com/watch?v=pPStdjuYzSI
https://graphics.stanford.edu/papers/brookgpu/brookgpu.pdf
官方 PDF 《CUDA Programming Guide Version 1.0》标注版本 1.0 日期为 2007-06-23 。NVIDIA Developer Download+1
NVIDIA 成立早(1993 年)但 CUDA 平台在 2007 年才作为通用计算平台发布。
TPU 直接取消指令概念,只让数据按固定路径流过 → 零指令解码成本。
-
电路面积(控制单元约占核心面积 30%)
-
时钟周期(控制器延迟不可省)
-
功耗(控制信号切换频繁)
主要的优势比较参数,
GPU 每个周期都要做:取指令 → 解码 → 分派 → 执行 → 写回
即便只是做 A*B+C,也必须经过完整的指令路径。
这些「控制逻辑」虽然在架构上看是辅助模块,但在硬件层面占用大量晶体管、功耗与时钟周期。去掉它们,等于把电路从"智能机器"变成"纯算机器",差距是数量级的。
无需控制器、指令解码、缓存协调。
GPU 最初是为图形渲染而设计的,核心逻辑是 SIMT(Single Instruction, Multiple Thread) 。
也就是上万个小核心(CUDA Core)并行执行相同指令,适合像素、粒子、顶点这种可并行任务。
这种设计的优点:
-
通用:几乎任何可并行的任务都能跑。
-
可编程:程序员能写任意逻辑(条件分支、循环、访存控制)。
但也带来几个致命问题:
-
调度复杂:需要线程分配、寄存器分配、Warp 同步。
-
访存不规律:不同线程访问显存不连续时性能急降。
-
能耗高:指令调度、寄存器重命名、缓存一致性都会耗电。
→ GPU 擅长"宽而灵活的并行",不是"死板而极致的矩阵流计算"。
差距确实大。出现 TPU 这种"重新设计"的硬件,是因为 GPU 的可编程通用性带来了结构性浪费,而在深度学习这种固定运算模式下,这种浪费变成瓶颈。
| 特性 | GPU | TPU |
|---|---|---|
| 可编程性 | 高(通用 GPGPU) | 低(固定硬件路径) |
| 通用任务 | 游戏、科学计算、物理仿真 | 几乎无优势 |
| 深度学习矩阵计算 | 强,但需调度和显存管理 | 极强,直接硬件流水执行 |
| 延迟 | 稍高 | 极低 |
| 成本与生态 | 商业化成熟 | 仅云端可用(Google Cloud TPU) |
TPU:
-
主要由一个或多个 Systolic Array(典型如 128×128)组成。
-
该阵列每个时钟周期完成固定矩阵乘加:
C=A×B+C
-
没有通用逻辑单元,不能自由编程。
-
更像"专用计算电路"(ASIC),只为神经网络线性代数服务。
GPU:
-
内部是数千个可编程「核心」(CUDA Core)。
-
每个核心能执行各种浮点、逻辑、分支操作。
-
张量计算只是 GPU 功能的一部分(NVIDIA 通过 Tensor Core 扩展支持)。
16-bit floating point data type
Bfloat16 ( bf16 ) is a 16-bit floating point data type based on the IEEE 32-bit single-precision floating point data type ( f32 ). Both bf16 and f32 have an 8-bit exponent. However, while f32 has a 23-bit mantissa, bf16 has only a 7-bit one, keeping only the most significant bits.
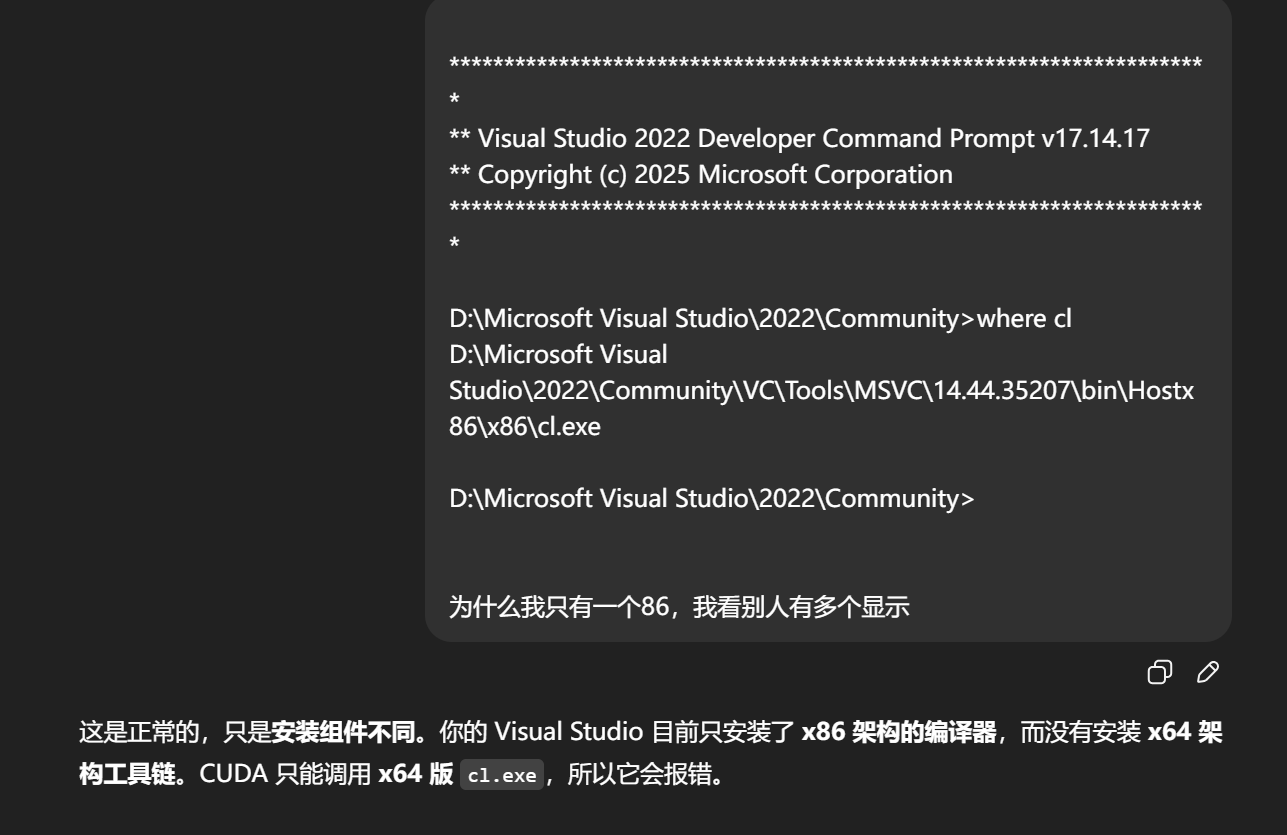
cl.exe
代表 C Language 编译器(C + L)。
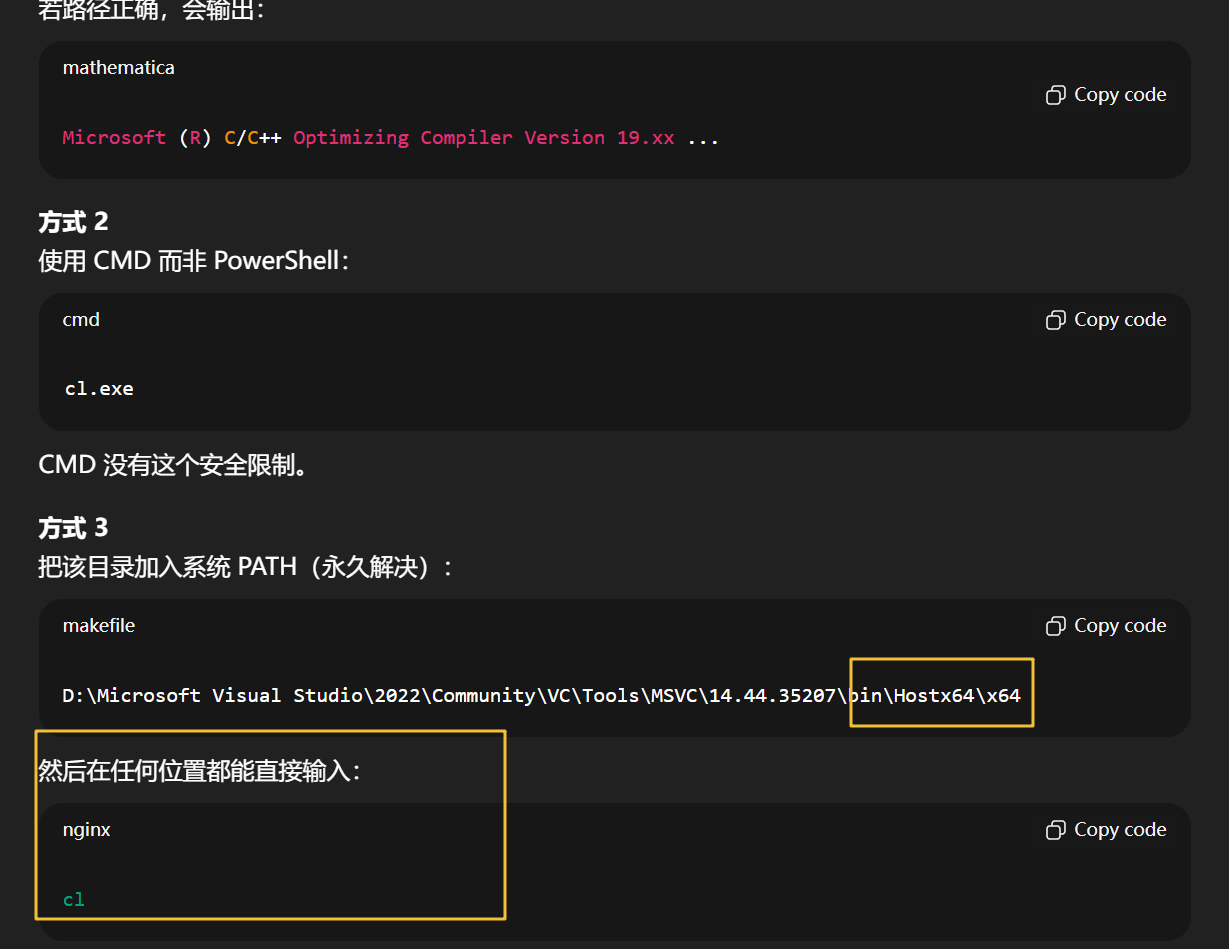
Visual Studio C++ 工具链有两个目标平台:
| 架构 | 对应路径 | 主要用途 |
|---|---|---|
| x86 | Hostx86\x86\cl.exe |
旧 32 位项目 |
| x64 | Hostx64\x64\cl.exe |
CUDA、现代桌面程序、游戏引擎等 |
你当前的 where cl 结果:
D:\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.44.35207\bin\Hostx86\x86\cl.exe
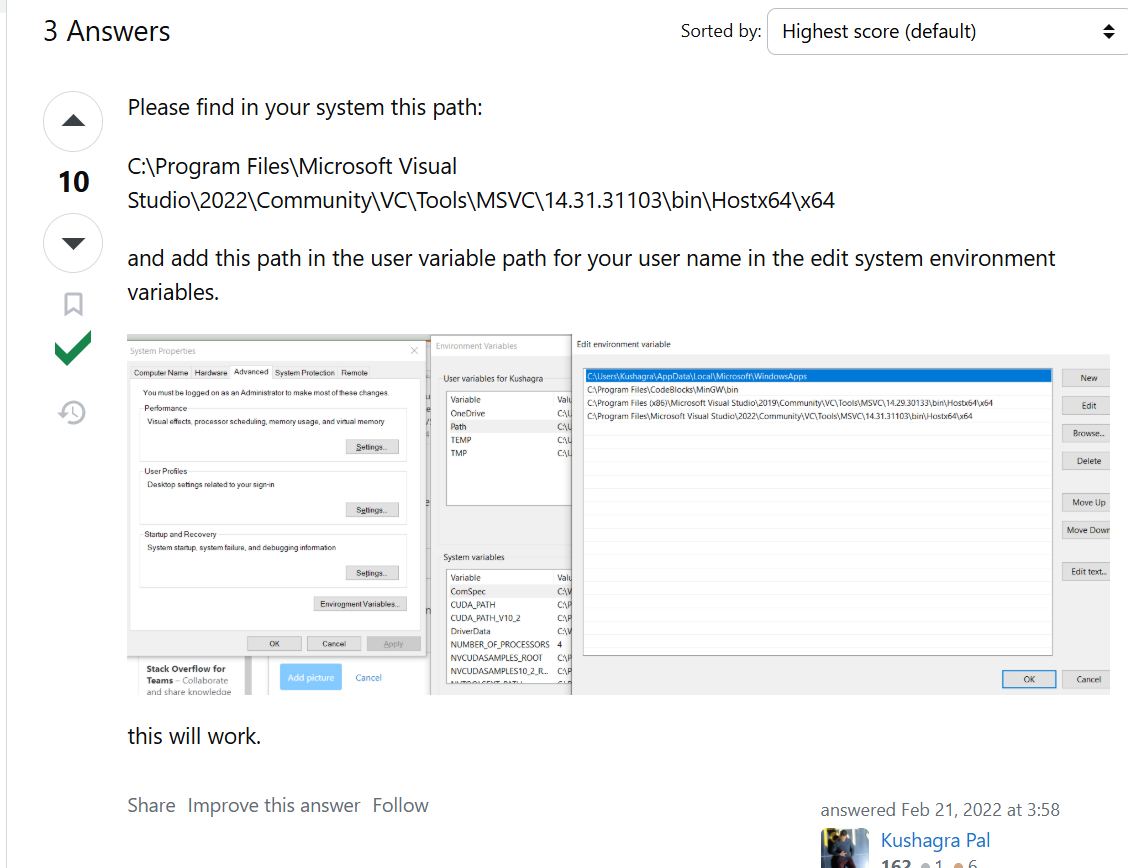
说明只有 32 位工具链,没有 64 位版本。
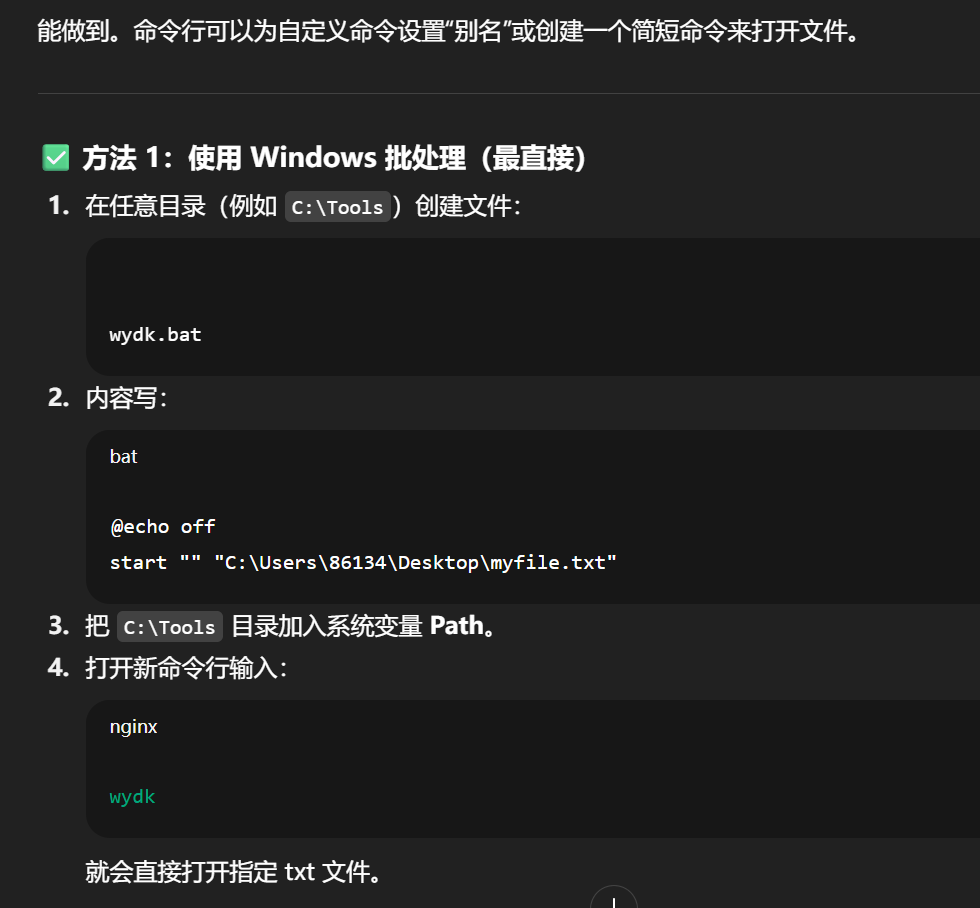
Unity 自己有 .unity 场景文件和 .meta 索引系统,所有资源与脚本都受 UnityEditor 管理。
但当 Unity 需要与 Visual Studio 协同时(例如脚本编辑、调试),它会自动生成 .sln 和 .csproj 文件来告诉 VS:
"这里是一个 Unity C# 项目,脚本都在这些目录,编译参数如下。"
也就是说:
-
.sln对 Unity 来说是 IDE 交互层; -
对 Visual Studio 来说是 项目构建层。
.sln 在 Visual Studio 的意义
-
代表一个解决方案(Solution),相当于一个项目集合。
-
内部列出若干
.vcxproj(C++ 工程)或.csproj(C# 工程)。 -
控制:
-
源码文件位置
-
构建目标(Debug/Release)
-
依赖库路径
-
使用的编译器与参数
-
Visual Studio 打开 .sln 就能重建整个工程环境。
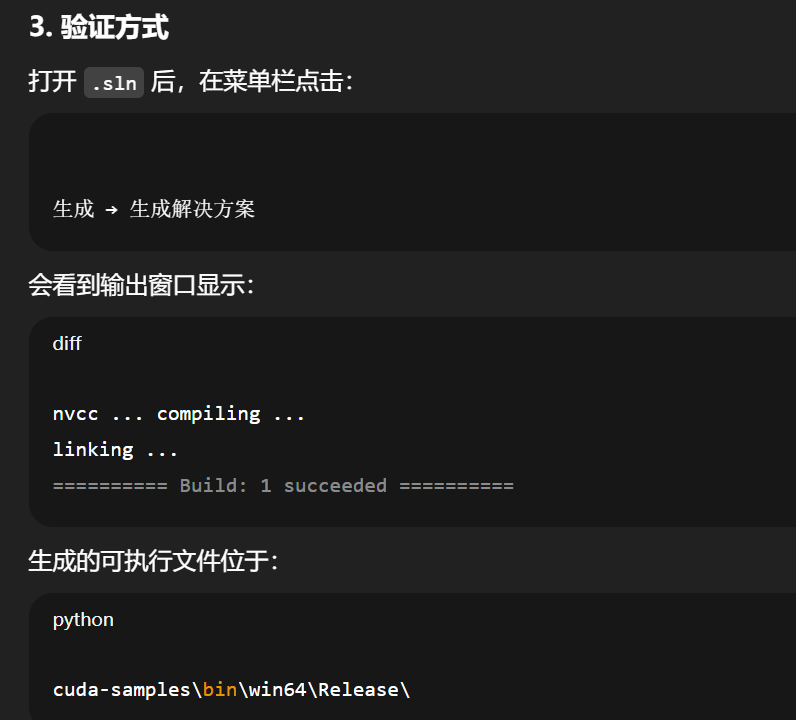
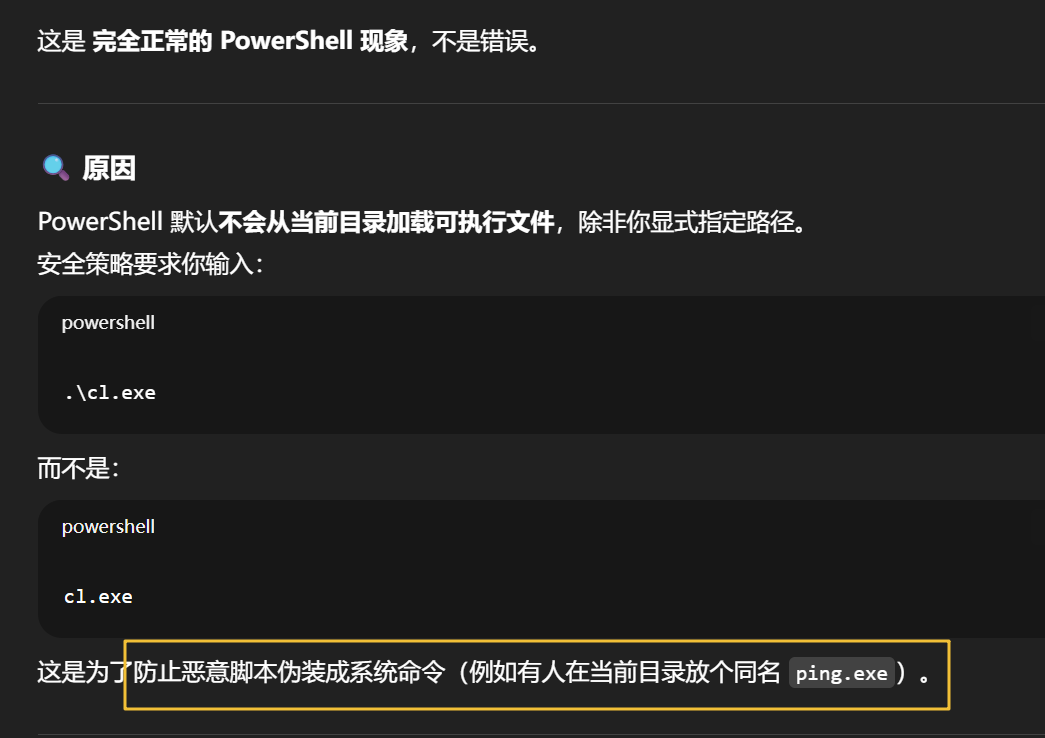
为什么看起来像"直接执行"
当你在 VS 里点击"运行"(或按 F5):
-
VS 先解析
.sln; -
调用
nvcc编译 CUDA 源码; -
链接生成
.exe; -
自动启动该
.exe;因此看起来像是 ".sln 能直接执行"。
实际上 .sln 只是工程描述文件,执行的是编译后生成的二进制。