2025年,PaddleOCR 陆续推出了文字识别方案 PP-OCRv5、文档解析方案 PP-StructureV3、关键信息抽取方案 PP-ChatOCRv4 等多项重磅解决方案。
得益于多项创新突破,PaddleOCR 受到了用户的广泛青睐,并崛起为大模型产业化的关键工具。
PaddleOCR 团队将把用户的信任转化为前进的动力,持续攀登 OCR 与文档解析技术的新高峰。
10月16日,新一代多模态文档解析模型方案 PaddleOCR-VL 正式发布!
据消息,HuggingFace官网显示,百度昨晚发布的自研多模态文档解析模型PaddleOCR-VL,发布 16 小时内即登顶 HuggingFace Trending 全球第一。
该模型核心参数仅 0.9 B,轻量高效,能以极低计算开销精准识别文本、手写、表格、公式、图表等复杂元素,支持 109 种语言。
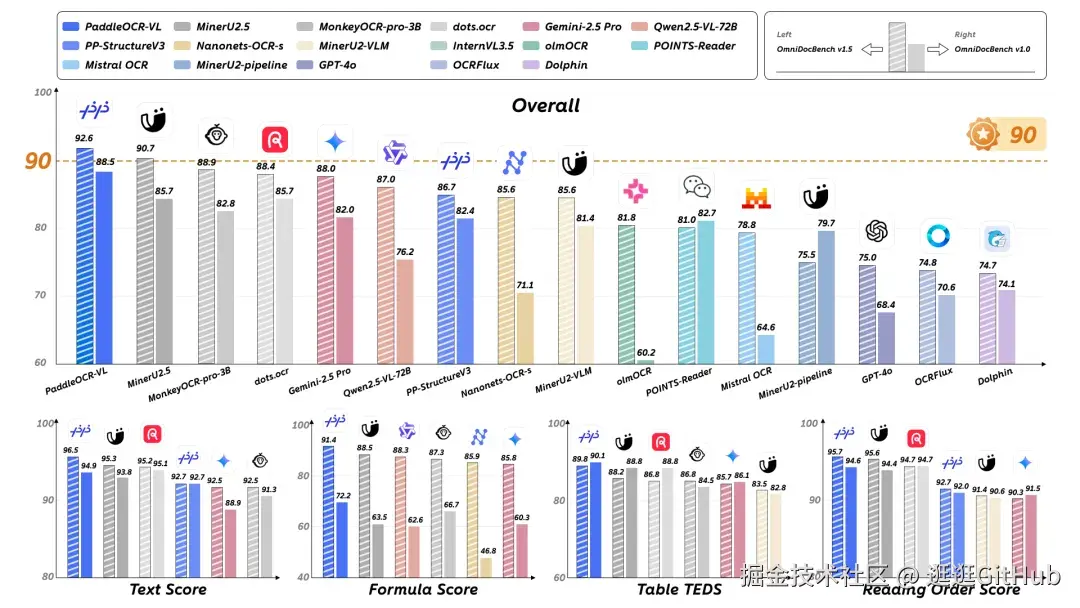
在权威榜单 OmniDocBench 中,它以 92.6 分获综合性能全球第一,四大核心能力全线 SOTA,超越 GPT-4o 等模型,刷新 OCR VL 模型性能纪录。
作为文心 4.5 衍生模型,PaddleOCR-VL 融合了 NaViT 动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型,实现精度与效率双突破。
01 模型介绍
PaddleOCR-VL 是一款极致轻量高效的文档解析模型,专为文档中的元素识别设计。它的核心模型 PaddleOCR-VL-0.9B 集成了高效的视觉编码器和强大的语言模型,能够精准识别图片中的文本、手写汉字、表格、公式和图表等复杂元素。
PaddleOCR-VL 覆盖多达 109 种语言,无论是中文、英文等主流语言,还是小语种,都能实现轻松处理。与其他同类模型相比,PaddleOCR-VL 不仅识别效果更好,资源消耗也非常低,速度快,效率高。
在多个公开和内部测试中,PaddleOCR-VL 在整页文档解析和单个元素的识别方面都取得了业界领先的成绩,明显优于现有的其他方案。凭借这些优势, PaddleOCR-VL 非常适合在各种实际场景中部署使用。
02 核心亮点
紧凑而强大的VLM架构:核心模型 PaddleOCR-VL-0.9B 是一种专为资源高效推理设计的全新视觉语言模型,在文档类元素识别上取得卓越表现。
通过将 NaViT 风格的动态高分辨率视觉编码器与轻量级 ERNIE-4.5-0.3B 语言模型相结合,显著提升了识别能力与解码效率。在保持高精度的同时降低计算开销,使其非常适合高效、实用的文档处理应用。
文档解析的SOTA表现:PaddleOCR-VL在文档解析任务中取得最先进的性能。它在识别包含表格、公式和图表等元素的复杂文档方面表现优异,擅长手写文本与历史文档在内的多种挑战性内容类型。
支持 109 种语言的文字识别:覆盖主要通用语言及多样书写体系(如俄语、阿拉伯语、印地语等),PaddleOCR-VL在多语种与全球化文档处理场景中具有广泛适用性。
03 方案简介
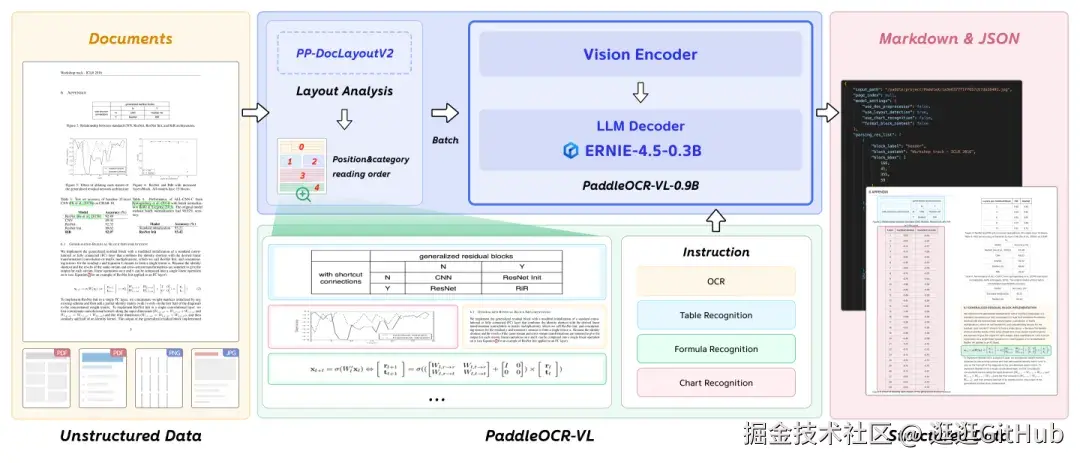
PaddleOCR-VL将复杂的文档解析任务分解为两个阶段。第一阶段PP-DocLayoutV2 负责版面分析,定位语义区域并预测其阅读顺序。
随后,第二阶段 PaddleOCR-VL-0.9B 基于这些版面预测,对文本、表格、公式和图表等多样化内容进行细粒度识别。最后,聚合两个阶段的输出,并将最终待预测文档化为结构化的 Markdown 和 JSON 文件。
04 案例展示
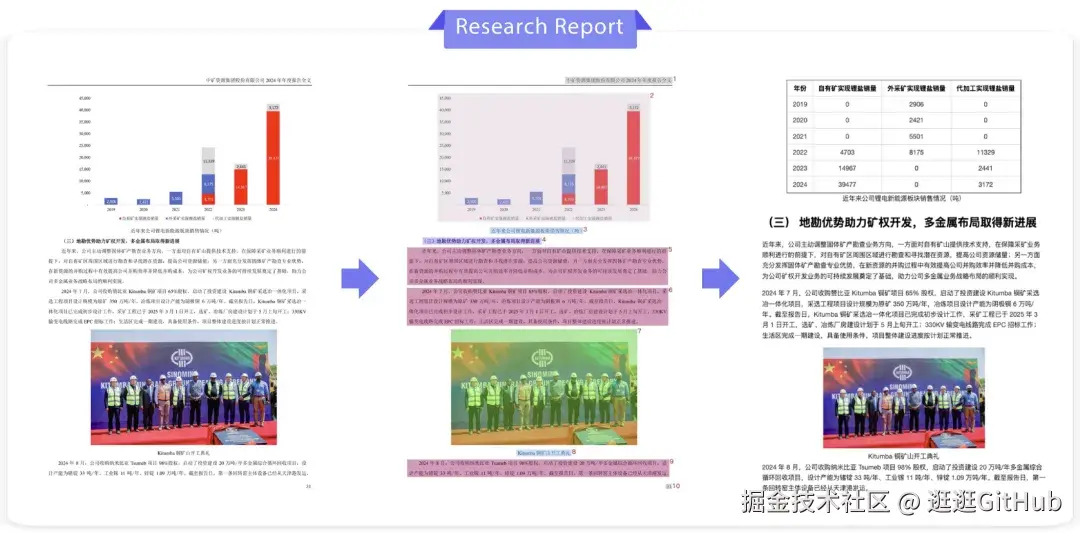
PaddleOCR-VL 能够支持多种类型的文档解析,以下是一些预测案例的展示:





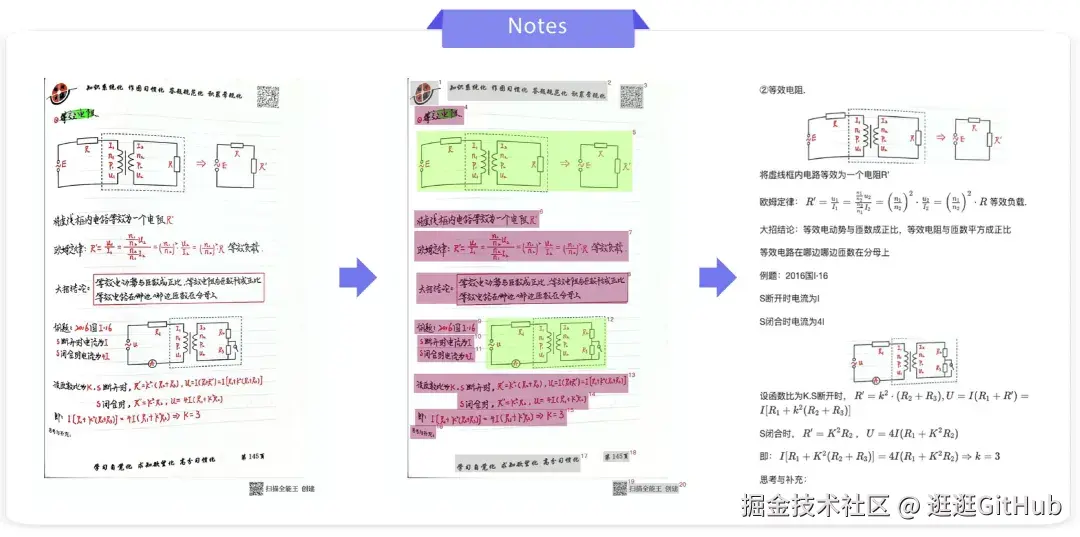


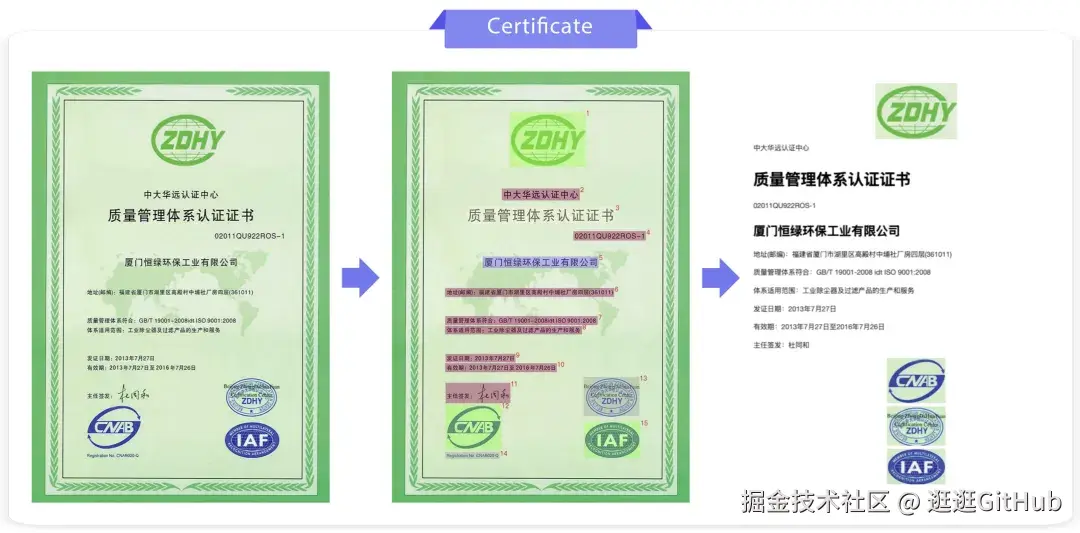


更多的案例可参考技术报告:
arduino
技术报告:https://arxiv.org/pdf/2510.1452805 推理性能
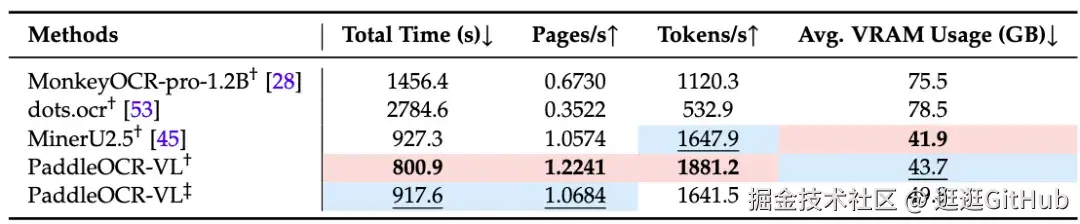
下表展示了不同文档解析模型在A100上的端到端推理速度。凭借轻量化的模型结构,PaddleOCR-VL每秒可处理 1881 个Token,推理速度较MinerU2.5提升14.2%,较 dots.ocr 提升253.01%。在当前主流开源多模态 OCR 方案中,PaddleOCR-VL 展现出显著的速度优势。
此外,PaddleOCR 团队还将开设针对 PaddleOCR-VL 多模态文档解析方案的产业场景实战营,手把手带开发者们体验基于PaddleOCR-VL的整页文档解析和单个元素识别的强大能力。
ruby
开源地址:https://github.com/PaddlePaddle/PaddleOCR技术报告地址:https://arxiv.org/pdf/2510.14528体验Demo地址:https://aistudio.baidu.com/application/detail/9836506 结语
在长期关注和使用 PaddleOCR 的过程中,我深刻感受到它已经成长为文档智能领域的重要基石。如今在众多大模型应用中,PaddleOCR 已成为文档识别环节不可或缺的技术支撑。
令人印象深刻的是,PaddleOCR 早已超越传统文字识别的范畴,正朝着AI落地基础设施的方向稳步迈进。这种定位的升级,让开发者们能基于更稳定、更强大的基础能力来构建各类应用。
回顾过去几年,PaddleOCR 在开源社区的持续投入和技术迭代实在令人赞赏。作为一个受益于该项目的开发者,我同样也见证了大量基于 PaddleOCR 实现的优秀行业解决方案。
展望未来,我相信 PaddleOCR 将继续推动技术进步,拓展能力边界。这对于我们开发者社区来说意义重大------只有基础技术的持续创新,才能为我们实现业务智能化转型提供更强大的技术支撑。