import os
import numpy as np
import torch
import gradio as gr
import spaces
from typing import Optional, Tuple
from funasr import AutoModel
from pathlib import Path
os.environ["TOKENIZERS_PARALLELISM"] = "false"
if os.environ.get("HF_REPO_ID", "").strip() == "":
os.environ["HF_REPO_ID"] = "openbmb/VoxCPM-0.5B"
import voxcpm
class VoxCPMDemo:
def __init__(self) -> None:
# 设备检测优先级: CUDA > MPS > CPU
if torch.cuda.is_available():
self.device = "cuda"
elif hasattr(torch.backends, 'mps') and torch.backends.mps.is_available():
self.device = "mps"
else:
self.device = "cpu"
# 添加设备类型信息显示
device_info = {
"cuda": "NVIDIA GPU (CUDA)",
"mps": "Apple Silicon GPU (MPS)",
"cpu": "CPU"
}
print(f"🚀 Running on device: {self.device} ({device_info.get(self.device, 'Unknown')})")
# 显示额外设备信息
if self.device == "cuda":
print(f"📊 GPU Count: {torch.cuda.device_count()}")
if torch.cuda.is_available():
print(f"🎯 GPU Name: {torch.cuda.get_device_name(0)}")
print(f"💾 GPU Memory: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f} GB")
elif self.device == "mps":
print("🍎 Apple Silicon GPU detected - Using Metal Performance Shaders")
print("💡 Note: MPS provides efficient GPU acceleration on Apple Silicon devices")
# ASR model for prompt text recognition
self.asr_model_id = "iic/SenseVoiceSmall"
# 根据 self.device 设置 ASR 模型设备
if self.device == "cuda":
asr_device = "cuda:0"
elif self.device == "mps":
asr_device = "mps"
else:
asr_device = "cpu"
self.asr_model: Optional[AutoModel] = AutoModel(
model=self.asr_model_id,
disable_update=True,
log_level='DEBUG',
device=asr_device,
)
# TTS model (lazy init)
self.voxcpm_model: Optional[voxcpm.VoxCPM] = None
self.default_local_model_dir = "./models/VoxCPM-0.5B"
# ---------- Model helpers ----------
def _resolve_model_dir(self) -> str:
"""
Resolve model directory:
1) Use local checkpoint directory if exists
2) If HF_REPO_ID env is set, download into models/{repo}
3) Fallback to 'models'
"""
if os.path.isdir(self.default_local_model_dir):
return self.default_local_model_dir
repo_id = os.environ.get("HF_REPO_ID", "").strip()
if len(repo_id) > 0:
target_dir = os.path.join("models", repo_id.replace("/", "__"))
if not os.path.isdir(target_dir):
try:
from huggingface_hub import snapshot_download # type: ignore
os.makedirs(target_dir, exist_ok=True)
print(f"Downloading model from HF repo '{repo_id}' to '{target_dir}' ...")
snapshot_download(repo_id=repo_id, local_dir=target_dir, local_dir_use_symlinks=False)
except Exception as e:
print(f"Warning: HF download failed: {e}. Falling back to 'data'.")
return "models"
return target_dir
return "models"
def get_or_load_voxcpm(self) -> voxcpm.VoxCPM:
if self.voxcpm_model is not None:
return self.voxcpm_model
print("Model not loaded, initializing...")
model_dir = self._resolve_model_dir()
print(f"Using model dir: {model_dir}")
try:
# 官方推荐方案:不传递 device 参数,让官方代码自动检测
# 仅禁用 denoiser 以避免 transformers 兼容性问题
# 仅在 CUDA 上启用 torch.compile 优化
optimize = (self.device == "cuda")
self.voxcpm_model = voxcpm.VoxCPM(
voxcpm_model_path=model_dir,
enable_denoiser=False,
optimize=optimize
)
except Exception as e:
print(f"Error initializing VoxCPM: {e}")
raise
print("✅ Model loaded successfully.")
return self.voxcpm_model
# ---------- Functional endpoints ----------
def prompt_wav_recognition(self, prompt_wav: Optional[str]) -> str:
if prompt_wav is None:
return ""
res = self.asr_model.generate(input=prompt_wav, language="auto", use_itn=True)
text = res[0]["text"].split('|>')[-1]
return text
def generate_tts_audio(
self,
text_input: str,
prompt_wav_path_input: Optional[str] = None,
prompt_text_input: Optional[str] = None,
cfg_value_input: float = 2.0,
inference_timesteps_input: int = 10,
do_normalize: bool = True,
denoise: bool = True,
) -> Tuple[int, np.ndarray]:
"""
Generate speech from text using VoxCPM; optional reference audio for voice style guidance.
Returns (sample_rate, waveform_numpy)
"""
current_model = self.get_or_load_voxcpm()
text = (text_input or "").strip()
if len(text) == 0:
raise ValueError("Please input text to synthesize.")
prompt_wav_path = prompt_wav_path_input if prompt_wav_path_input else None
prompt_text = prompt_text_input if prompt_text_input else None
print(f"Generating audio for text: '{text[:60]}...'")
# 在 MPS 设备上禁用 denoise 以避免兼容性问题
if self.device == "mps":
denoise = False
print("💡 Note: Denoise disabled on MPS device for compatibility")
wav = current_model.generate(
text=text,
prompt_text=prompt_text,
prompt_wav_path=prompt_wav_path,
cfg_value=float(cfg_value_input),
inference_timesteps=int(inference_timesteps_input),
normalize=do_normalize,
denoise=denoise,
)
return (16000, wav)
# ---------- UI Builders ----------
def create_demo_interface(demo: VoxCPMDemo):
"""Build the Gradio UI for VoxCPM demo."""
# static assets (logo path)
gr.set_static_paths(paths=[Path.cwd().absolute()/"assets"])
with gr.Blocks(
theme=gr.themes.Soft(
primary_hue="blue",
secondary_hue="gray",
neutral_hue="slate",
font=[gr.themes.GoogleFont("Inter"), "Arial", "sans-serif"]
),
css="""
.logo-container {
text-align: center;
margin: 0.5rem 0 1rem 0;
}
.logo-container img {
height: 80px;
width: auto;
max-width: 200px;
display: inline-block;
}
/* Bold accordion labels */
#acc_quick details > summary,
#acc_tips details > summary {
font-weight: 600 !important;
font-size: 1.1em !important;
}
/* Bold labels for specific checkboxes */
#chk_denoise label,
#chk_denoise span,
#chk_normalize label,
#chk_normalize span {
font-weight: 600;
}
"""
) as interface:
# Header logo
gr.HTML('<div class="logo-container"><img src="/gradio_api/file=assets/voxcpm_logo.png" alt="VoxCPM Logo"></div>')
# Quick Start
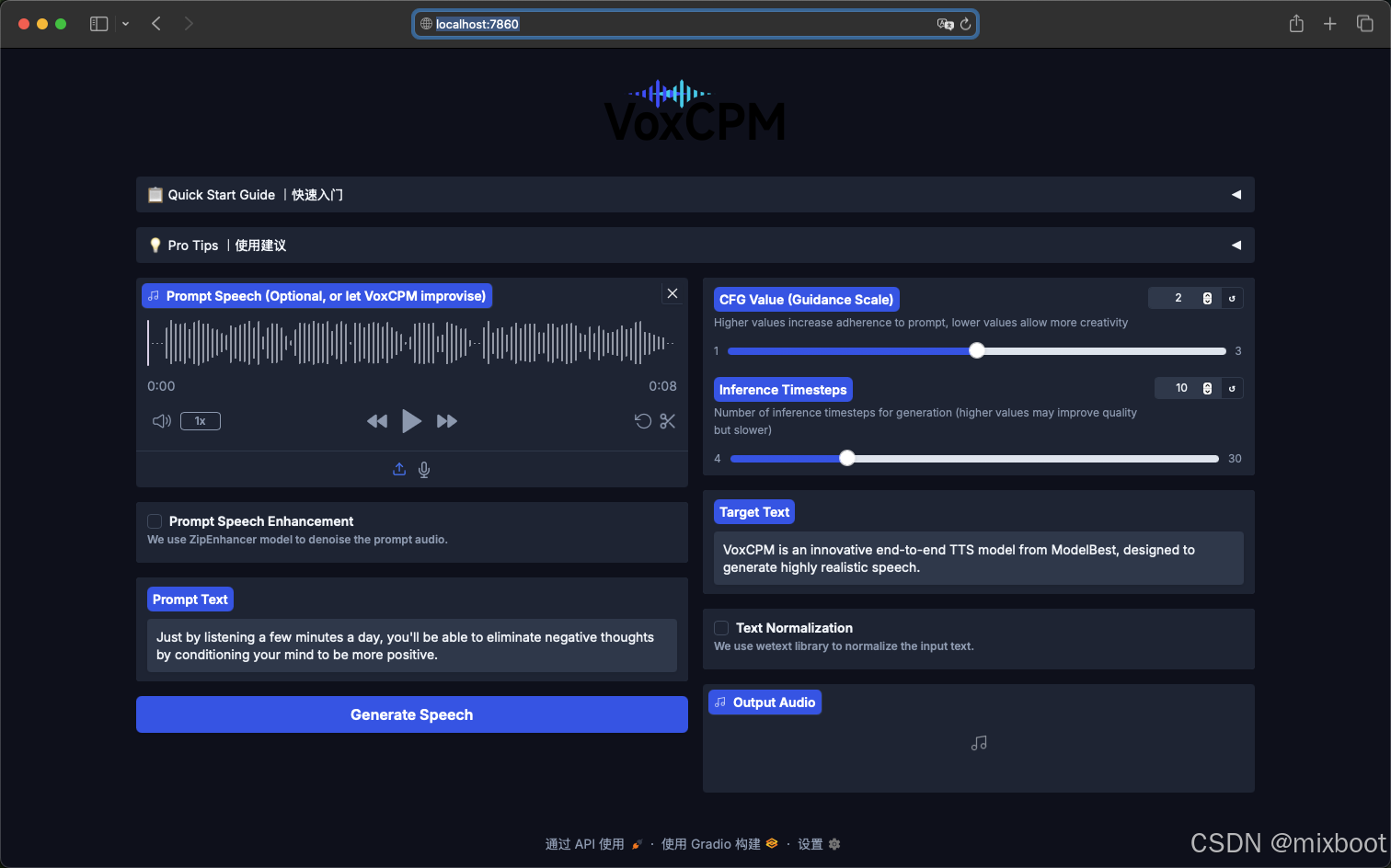
with gr.Accordion("📋 Quick Start Guide |快速入门", open=False, elem_id="acc_quick"):
gr.Markdown("""
### How to Use |使用说明
1. **(Optional) Provide a Voice Prompt** - Upload or record an audio clip to provide the desired voice characteristics for synthesis.
**(可选)提供参考声音** - 上传或录制一段音频,为声音合成提供音色、语调和情感等个性化特征
2. **(Optional) Enter prompt text** - If you provided a voice prompt, enter the corresponding transcript here (auto-recognition available).
**(可选项)输入参考文本** - 如果提供了参考语音,请输入其对应的文本内容(支持自动识别)。
3. **Enter target text** - Type the text you want the model to speak.
**输入目标文本** - 输入您希望模型朗读的文字内容。
4. **Generate Speech** - Click the "Generate" button to create your audio.
**生成语音** - 点击"生成"按钮,即可为您创造出音频。
""")
# Pro Tips
with gr.Accordion("💡 Pro Tips |使用建议", open=False, elem_id="acc_tips"):
gr.Markdown("""
### Prompt Speech Enhancement|参考语音降噪
- **Enable** to remove background noise for a clean, studio-like voice, with an external ZipEnhancer component.
**启用**:通过 ZipEnhancer 组件消除背景噪音,获得更好的音质。
- **Disable** to preserve the original audio's background atmosphere.
**禁用**:保留原始音频的背景环境声,如果想复刻相应声学环境。
### Text Normalization|文本正则化
- **Enable** to process general text with an external WeTextProcessing component.
**启用**:使用 WeTextProcessing 组件,可处理常见文本。
- **Disable** to use VoxCPM's native text understanding ability. For example, it supports phonemes input ({HH AH0 L OW1}), try it!
**禁用**:将使用 VoxCPM 内置的文本理解能力。如,支持音素输入(如 {da4}{jia1}好)和公式符号合成,尝试一下!
### CFG Value|CFG 值
- **Lower CFG** if the voice prompt sounds strained or expressive.
**调低**:如果提示语音听起来不自然或过于夸张。
- **Higher CFG** for better adherence to the prompt speech style or input text.
**调高**:为更好地贴合提示音频的风格或输入文本。
### Inference Timesteps|推理时间步
- **Lower** for faster synthesis speed.
**调低**:合成速度更快。
- **Higher** for better synthesis quality.
**调高**:合成质量更佳。
""")
# Main controls
with gr.Row():
with gr.Column():
prompt_wav = gr.Audio(
sources=["upload", 'microphone'],
type="filepath",
label="Prompt Speech (Optional, or let VoxCPM improvise)",
value="./examples/example.wav",
)
DoDenoisePromptAudio = gr.Checkbox(
value=False,
label="Prompt Speech Enhancement",
elem_id="chk_denoise",
info="We use ZipEnhancer model to denoise the prompt audio."
)
with gr.Row():
prompt_text = gr.Textbox(
value="Just by listening a few minutes a day, you'll be able to eliminate negative thoughts by conditioning your mind to be more positive.",
label="Prompt Text",
placeholder="Please enter the prompt text. Automatic recognition is supported, and you can correct the results yourself..."
)
run_btn = gr.Button("Generate Speech", variant="primary")
with gr.Column():
cfg_value = gr.Slider(
minimum=1.0,
maximum=3.0,
value=2.0,
step=0.1,
label="CFG Value (Guidance Scale)",
info="Higher values increase adherence to prompt, lower values allow more creativity"
)
inference_timesteps = gr.Slider(
minimum=4,
maximum=30,
value=10,
step=1,
label="Inference Timesteps",
info="Number of inference timesteps for generation (higher values may improve quality but slower)"
)
with gr.Row():
text = gr.Textbox(
value="VoxCPM is an innovative end-to-end TTS model from ModelBest, designed to generate highly realistic speech.",
label="Target Text",
)
with gr.Row():
DoNormalizeText = gr.Checkbox(
value=False,
label="Text Normalization",
elem_id="chk_normalize",
info="We use wetext library to normalize the input text."
)
audio_output = gr.Audio(label="Output Audio")
# Wiring
run_btn.click(
fn=demo.generate_tts_audio,
inputs=[text, prompt_wav, prompt_text, cfg_value, inference_timesteps, DoNormalizeText, DoDenoisePromptAudio],
outputs=[audio_output],
show_progress=True,
api_name="generate",
)
prompt_wav.change(fn=demo.prompt_wav_recognition, inputs=[prompt_wav], outputs=[prompt_text])
return interface
def run_demo(server_name: str = "localhost", server_port: int = 7860, show_error: bool = True):
demo = VoxCPMDemo()
interface = create_demo_interface(demo)
# Recommended to enable queue on Spaces for better throughput
interface.queue(max_size=10).launch(server_name=server_name, server_port=server_port, show_error=show_error)
if __name__ == "__main__":
run_demo()