"中国芯片要爆发了。"
官宣完 "地表最强" 的英伟达新 GPU 后,黄仁勋面对全球媒体的镜头如是说。
他还大夸中国模型,直言 Qwen、DeepSeek 都是 "世界级、革命性" 的成果。
近一个小时的接连提问,有一半的问题都关于中国,仿佛让人忘了英伟达的新成果才是这场发布会的主角。

发布会上,老黄介绍了英伟达新核弹 Vera Rubin,算力 100PFLOPs,是英伟达首款专用 AI 计算机 DGX-1 性能的 100 倍。
该款芯片也正是 OpenAI 英伟达千亿大单第一阶段要部署的芯片,现在老黄手里已经有了样品,预计明年实现量产。
此外,老黄还官宣了英伟达在量子计算、6G 通信、自动驾驶等其他领域的战略布局。

下一代芯片和超算
Vera Rubin 平台是继 GB200_(Grace Blackwell NVLink 72)_之后的第三代 NVLink 72 机架规模的计算机,从芯片、系统、软件到模型架构都进行了全新设计。
而最核心的 Vera Rubin 超级芯片则是搭载了一颗 Vera CPU 和两颗大型的 Rubin GPU。
英伟达已经收到了首批由台积电生产的 Rubin GPU,每个 GPU 芯片都采用了 HBM4 高带宽内存,主板其他区域配备了 32 个 LPDDR 内存插槽,和 HBM4 内存协同工作。
在 FP4 精度下,浮点计算性能可达 50PFLOPs,相较于现有的 GB300,性能有数倍跃迁。
而 Vera 则采用 Arm 架构,搭载了 88 个核心以及 176 线程,NVLINK-C2C 互联带宽可达 1.8TB/s。

黄仁勋展示的 Vera Rubin 计算托盘则采用高度集成设计,是一个完全无线并且 100% 液冷的节点。
这个计算托盘的核心处理器内置了两个 Vera CPU 和四个 Rubin 封装,形成了强大的算力核心。
而为了应对 AI 日益增长的对于上下文处理的需求,英伟达还在托盘中新增了 Bluefield 4 数据处理器,配备了 8 个全新的 ConnectX-9 超级网卡。
不过,老黄表示 Vera Rubin 计算托盘的安装过程极其简单,甚至调侃道:
连我都能做到。

首代基于 Vera Rubin 的 Vera Rubin NVL144 平台计划于 2026 年下半年推出,可实现 3.6Exaflops 的 FP4 推理算力和 1.2Exaflops 的 FP8 训练算力,相较于 GB300 的 NVL72 提升约 3.3 倍。
而升级版的 Rubin Ultra NVL576 将在 2027 年下半年推出,将 NVL 系统规模从 144 扩展到 576,FP4 推理算力可以达到 15Exaflops,FP8 训练算力达 5Exaflops,相较 GB300 NVL72 提升 14 倍。
英伟达科学家范麟熙(Jim Fan)评价:科幻场景与 "真实的《黑客帝国》" 相比黯然失色。

英伟达还规划和美国能源部合作新建 7 座超算集群。
其中,Mission 和 Vision 两台基于 Vera Rubin 平台的新超级计算机是与 HPE 合作,为洛斯阿拉莫斯国家实验室建造的,预计 2027 年投入使用。
下一代超级芯片蓄势待发时,当前的 Blackwell 架构也实现了量产,正在大规模生产和部署。
黄仁勋透露,涵盖至 2026 年的出货量,Blackwell 和 Rubin 的订单总销售额将达到 5000 亿美元。
现场老黄又搬出了 GPU 未来三年计划------到 2028 年推出 Feynman。
就像从 Blackwell 到 Rubin 的节奏一样,承诺每年一次重大更新。

除了官宣超级芯片,老黄也透露了英伟达在其他领域的计划。
AI 超算与量子处理器的无缝连接
量子计算,一个获得诺贝尔物理学奖的热门课题,英伟达在这方面也有所布局。
这次演讲中,NVIDIA 发布了 NVQLink ,这是一种新的互连架构,可以直接连接量子处理器(QPUs)和 NVIDIA GPU,首次实现了 AI 超算与量子处理器的无缝连接。

它能够以每秒数千次的速度,在量子硬件之间传输高达 TB 级的数据,这是量子错误校正所需的关键速度。
功能上,NVQLink 负责量子计算机的控制和校准、量子错误校正,以及连接 QPU 和 GPU 超级计算机以进行混合模拟。
并且该架构具有完全可扩展性,可以处理从当前的数百个量子比特扩展到未来数万甚至数十万个量子比特的纠错需求。
为了实现这种融合,NVIDIA 推出 CUDA-Q,这是一个用于量子 GPU 计算的开放平台, 将 CUDA 扩展到支持 QPU,使之能够与 GPU 协同工作。
之前的 GTC 巴黎站上,英伟达宣布已经在 Blackwell 集成了 CUDA-Q,通过 GPU 为量子计算加速,其功能主要有两大方面:
-
如果没有真 · 量子计算单元,CUDA-Q 可以在经典计算机上模拟量子运算;
-
如果有了量子计算单元,CUDA-Q 可以实现量子与经典加速计算的协同,也就是 QPU 协作。

除了数据中心和量子计算,英伟达这一次也宣布将踏足新的领域------6G 通信。
投资诺基亚,入局 6G 通信
英伟达认为,加速计算和 AI 给通信行业也带来了一场新计算模型所驱动的平台转型。
为此,英伟达宣布推出新的产品线,名为 NVIDIA Arc (Aerial Radio Network Computer),专门用于 6G。
Arc 由三项基础新技术构建而成------Grace CPU、Blackwell GPU 以及 ConnectX Melanox 网络技术。
Arc 运行在 CUDA X 库中的无线通信系统 Aerial 上,目标是创建首个能够同时进行无线通信和 AI 处理的、软件定义的可编程计算机。
具体来说,英伟达与诺基亚达成合作推出了支持 AI 原生 6G 的加速计算平台------Aerial RAN Computer Pro(ARC-Pro)。
这是一款 AI 基站主机,搭载了 6G-ready 加速计算平台,并实现了无线 + AI 共生,把 AI 推理传统 RAN 处理跑在了同一套基础设施上。

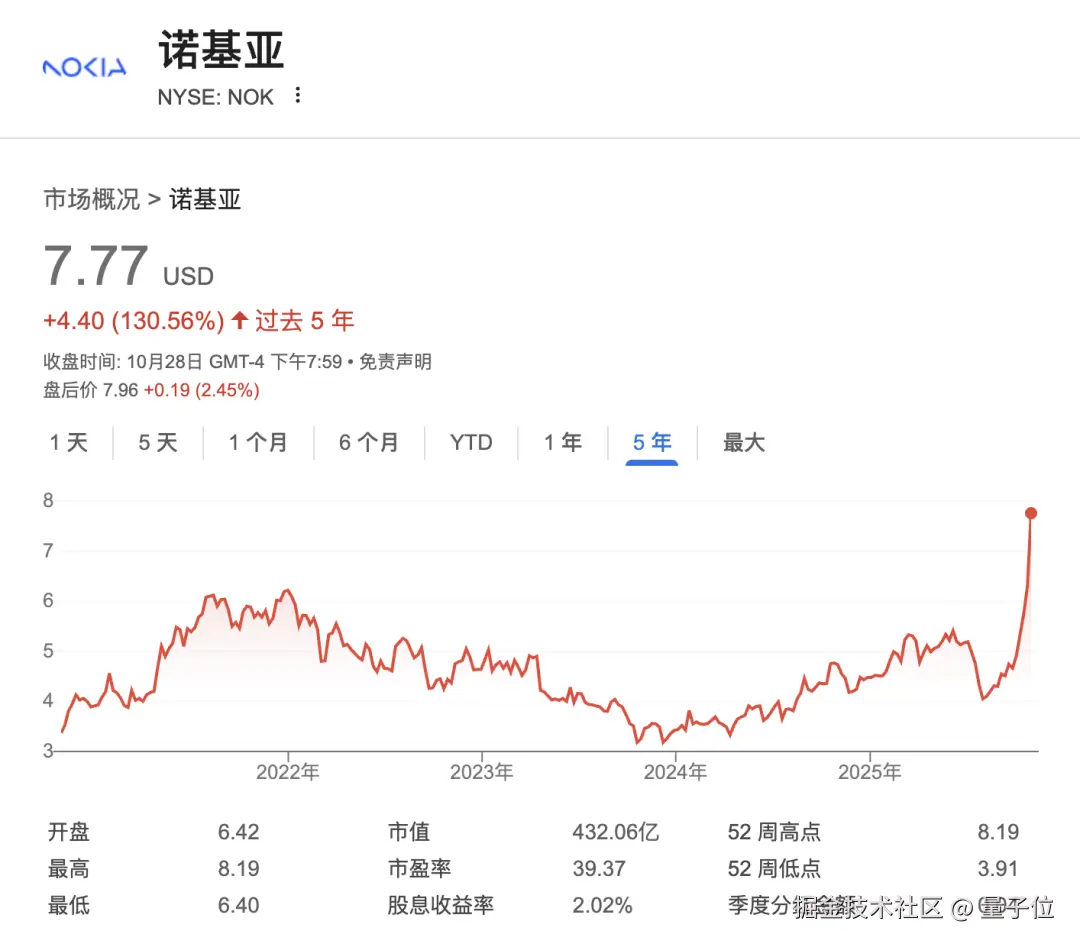
技术合作的同时,英伟达还对诺基亚进行了投资,总金额为 10 亿美元,这一举措让诺基亚股价大幅度上涨,创下了 6 年多以来的新高。
One More Thing
无论是英伟达的 "现金奶牛" 数据中心,还是新布局的量子计算和 6G,英伟达都不无对手、都有潜在挑战者。
隔壁 AMD 刚刚拿下了两台超算订单,金额为 10 亿美元。
这两台超级计算机的主要硬件部分将全部由 AMD 打造其中的首台名为 Lux,搭载 AMD Instinct MI355X 加速器 ,每台板载功率高达 1400 瓦,预计将在六个月内投入使用。

Lux 的人工智能性能将是现有超级计算机的三倍,AMD CEO 苏姿丰表示,这是同规模超级计算机中部署速度最快的一次。
除了 AMD,不满足于在端侧发展的高通也想要分一杯羹,宣布推出两款全新的 AI 芯片------AI200 和 AI250,正式进军数据中心市场。
这两款芯片聚焦 AI 模型的推理阶段 ,主打行业最低的总拥有成本 (TCO)、更高的能效 与更强的内存处理能力,分别预计于 2026 和 2027 年实现商用。

AMD、高通,还有老黄口中正在爆发的中国芯片,都有可能是英伟达面临的潜在竞争对手。
还有老黄看好的量子计算领域,甚至出现了不同路线的竞争------
英伟达认为 GPU 和 QPU 的组合是量子计算的未来,但 IBM 成功用 AMD 芯片实现了无 GPU 的量子计算。
IBM 的算法解决了量子计算中最核心的挑战之一------量子比特的脆弱性与高错误率。
这套方案的运行速度比实际需求快 10 倍,而且不需要昂贵的 GPU,只需要 FPGA 芯片与量子计算机配合。

与诺基亚合作的 6G 同样存在激烈竞争。
去年 7 月,北邮张平院士团队成功搭建了国际上首个通信与智能融合的 6G 试验网。
今年 8 月,北京大学和香港城市大学合作的全球首款全频段 6G 芯片问世,利用光子技术实现了 100Gbps 的传输速率。
该芯片只有 11×1.7mm 的尺寸,但融合了毫米波、太赫兹通信以及低频微波波段,覆盖了 0.5-115GHz。
这一成果被视为 6G 的关键突破,论文已经登上 Nature。

尽管在各个领域都面临竞争,但市场投资者还是选择看好英伟达------收盘时,英伟达股价上涨 4.98%,达到 201.03 美元每股,盘后价格更是达到每股 204.43 美元,创下了历史新高。
若以盘后价格计算,英伟达的市值增长了 3154 亿美元,折合人民币近 3 万亿,仅增长部分就相当于 1.59 个英特尔。

这场基础设施的全面竞争,究竟会鹿死谁手?
参考链接:
1www.youtube.com/watch?v=lQH...
2wccftech.com/nvidia-show...
3x.com/DrJimFan/st...
欢迎在评论区留下你的想法!
--- 完 ---