迭代器在 Rust 的代码库中被广泛使用,因此除了基础知识外,详细了解它们是很有价值的。
在这个系列中,我们将讨论每个初、中级水平的 Rust 开发者都必须牢记的主题。
如果目前在看文章的你还对 Rust 迭代器了解不多(以会用会写迭代器为准),建议先通读《Rust程序设计语言》迭代器的相应章节。
阅读 std::iter 模块的文档也非常有帮助,因为它将全面概述 Rust 标准库提供的迭代器功能。
Iterator traits
编程在很大程度上是关于处理来自各种来源的数据,并且这些数据通常被划分为可管理的元素。
迭代器是一种对象,它使我们能够连续地从数据源中获取下一个元素。
从这样的基本概念中衍生出的丰富编程生态系统着实令人惊叹。
迭代器的概念并非现代的创新。其根源可以追溯到 20 世纪 70 年代,当时麻省理工学院的 Barbara Liskov 和她的团队开发了 CLU 编程语言。与我们如今熟悉的迭代器不同,CLU 的迭代器更像是生成器,它们生成元素而不仅仅是提供一种获取元素的方法。尽管存在这种细微的差异,但在 CLU 中明确具备了遍历元素序列的基本思想,这成为编程语言设计中的一个重要里程碑。
在 Rust 中,迭代器功能的核心部分以 trait 的形式呈现:
rust
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}这个 trait 的完整定义内容广泛,涵盖了超过 4000 行的代码和文档。
实际上,Rust 中迭代器功能的基础是由两个关键部分构建而成的:
- 正在迭代的元素类型。
next函数,用于在有可用元素时获取下一个元素。
next 函数至关重要,因为它在整个数据源处理循环内为单次迭代提供数据,这个就可以方便外部按顺序访问元素(实际上是否是按顺序这个是实现决定的,你可以是任意顺序)。
Rust 迭代器并不局限于特定类型的元素;相反,它们依赖于 trait 的关联类型特性。这种方法确保实现能够保持高度的通用性。此外,这意味着遍历元素时不需要深入了解这些元素。最后,对泛型类型的支持避免了为不同类型重复编写代码的需要。
Rust 中迭代器定义的一个关键方面是有意不指定具体的数据源,这样做使得该 trait 与这些数据源解耦,并提高了其灵活性。 所以,通常实现 Iterator trait 的结构通常会引用一个数据源或封装一个用于生成新元素的算法。
然而,迭代器的实现与它所处理的数据源的性质紧密相关。对于存储在内存中的大小相同的连续元素块,例如数组或切片,实现方法可能仅是维护当前元素的偏移量,并在获取下一个元素时增加该偏移量。在 Rust 中,这些实现通常表现为结构体,其中的成员引用特定的数据源。它们详细说明了在这些数据源中的确切位置,并允许根据请求获取这些元素。
实现 next 方法通常就足够了,但在某些情况下,重写其他 Iterator 方法以实现更高效的操作可能是有益的。
这种方法让创建能遍历各种数据源的迭代器成为可能,这些数据源包括数组、字符串、集合、哈希映射和其他数据结构,以及输入流、环境变量、正则表达式匹配项、命令行参数等等。
迭代器让处理不同类型的数据变得更加容易,并且有助于我们在后续步骤中以相同的方式处理这些数据。因此,我们能够处理所有类型的数据,并以多种方式将各个步骤组合在一起。这种方式使得解释复杂的概念变得更加容易,也让代码更易于理解和复用。
迭代器的概念出现后不久,人们就意识到,拥有一个处理每一块数据的标准方式,有助于建立处理这些数据的通用方法。这些通用方法可以应用于任何类型的数据。为这些方法命名能够更清晰地展现数据的处理过程,相比于仅仅使用循环,这样做更有助于提高代码的清晰度。
适配方法
一旦我们拥有一个能够遍历元素集合的迭代器,就有可能在其基本行为的基础上为它增加额外功能,或者以不同的方式进行迭代。在此情境下,"适配" 意味着我们可以基于原始迭代器创建一个新的迭代器。Iterator 特性包含许多为此目的而设计的方法,例如:
map,映射。它会对每个元素应用指定的函数(通常用户元素的转换)。filter,过滤。它能让你跳过某些你认为不必要的元素。enumerate,枚举。它会生成由索引(从 0 开始)和元素组成的对。
rust
let numbers = vec![10, 15, 20, 25, 30, 35, 40];
// 使用 enumerate 获取索引和值,
// filter 保留索引为偶数的项,
// map 将值翻倍,
// 最后收集结果为 Vec
let result: Vec<(usize, i32)> = numbers
.into_iter()
.enumerate() // 将迭代器转换为 (索引, 值) 的形式,例如:(0, 10), (1, 15), (2, 20)...
.filter(|(i, _)| i % 2 == 0) // 保留偶数索引
.map(|(i, val)| (i, val * 2)) // 值乘以 2
.collect();
println!("{:?}", result);
// output
// [(0, 20), (2, 40), (4, 60), (6, 80)]这些方法以及其他一些方法都充当迭代器适配器,它们会构建新的迭代器,而不是直接执行指定的行为。它们就像构建模块一样,用于定义处理管道,为数据操作提供了一种模块化的方法。
使用迭代器适配器的代码不同于传统的命令式风格,命令式风格通常指示程序按特定顺序执行操作。相反,这种代码风格采用高度声明性的方法,只概述需要完成的任务,而不规定操作的确切顺序。这提供了更大的灵活性,由编译器和库的实现来确定指定行为的最合理、最有效的执行路径。
除了迭代器适配器,Iterator 特性还包括一些直接启动操作的方法,比如:
for_each:遍历元素,并对每个元素应用提供的闭包。count:对元素进行计数,直到迭代器耗尽。collect:将所有元素聚合到内存中的指定数据结构中。
让我们看一个例子来阐述上述要点。假设我们有一个图书集合:
rust
struct Book {
title: String,
author: String,
year: i32
}
fn collection() -> Vec<Book> {
vec![
// ...
]
}我们对 20 世纪的书籍感兴趣。让我们数一数我们的藏书中到底有多少这样的书:
rust
let books: Vec<Book> = collection();
let number_of_books_from_20 = books
.iter() // 得到 &Book 的迭代器
.map(|book| (book.year - 1).div(100) + 1) // 将年份转为世纪:例如 1900 → 19 世纪
.filter(|&c| c == 20) // 筛选出属于指定世纪的书籍
.count();
println!(
"Number of books from the {} century: {}",
20,
number_of_books_from_20
);
// output
// Number of books from the 20 century: 6对 books 调用的 iter 函数提供了一个与其紧密相连的迭代器结构。如果你的编译器支持的话,它会提供一些有关这些类型的信息:
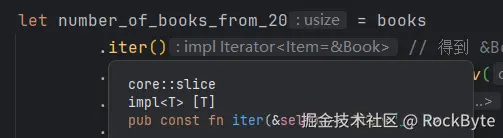
然后,我们对 book.year 进行筛选,只保留指定世纪的书籍。虽然筛选不会改变迭代器显示的类型,但它确实会改变返回的底层结构。如果我们将生成的迭代器(count 之前的部分)赋值给一个变量,我们会得到类似以下的输出:
rust
Filter<Map<Iter<Book>, fn(&Book) -> i32>, fn(&i32) -> bool>我们发现确切的类型相当复杂。它由 Filter、Map 和 Iter 迭代器结构以及它们相应的闭包类型组成。实际上,在代码中显式指定这样的类型是不允许的;闭包类型是匿名的,在 Rust 的语法中我们不能直接引用它们。
尽管如此,了解简单的 impl Iterator<Item = i32> 背后所隐藏的内容至关重要。
最终,我们继续对所有通过筛选的元素进行计数。这种计数操作会触发计算,从而得出我们想要的结果。
在这种情况下,Rust 的泛型允许对用户定义的 Book 类型的元素进行迭代。
效率
我们利用预定义的行为高效地对元素进行迭代、映射和筛选。代码按照顺序执行 ------ 先映射、再筛选,然后计数。从代码结构来看,是否意味着对 books 进行了多次遍历?
我们进行一次调试:
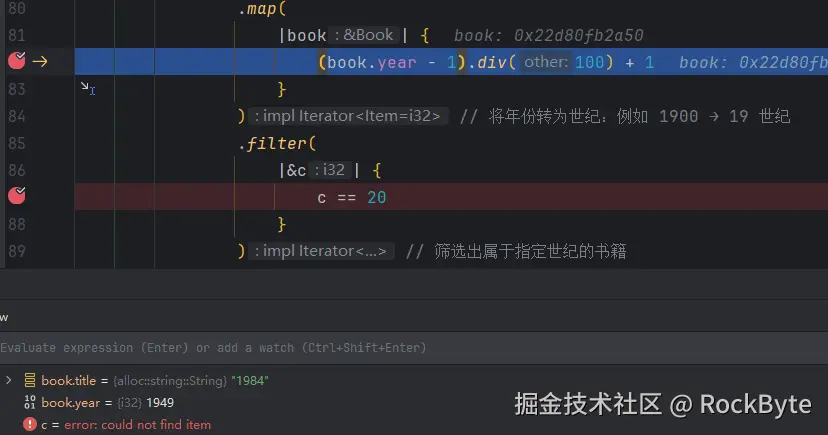
我们稍微修改了代码,与上面的示例逻辑相同,只是为了更清晰易懂进行了优化,设置两个断点,跟踪 book.year 和 c 的值,结果表明只进行了一次遍历。每一 book 被接收后,映射到其对应的世纪值,然后用这个世纪值来筛选掉不必要的元素。每一 book 都会执行这些步骤。
如果你依然质疑计数过程效率,我建议用以下代码替换 .count();,可以得到相同的结果:
rust
.fold(0, |acc, _| acc + 1)用这种修改进行调试可以清楚地看出,遇到来自 20 世纪的书籍后,acc 会立即递增,这与我们的预期完全相符。
Iterator trait 并不是 Rust 标准库提供的唯一迭代器 trait。其他 trait 在其基础上增加了新的功能,包括:
DoubleEndedIterator,它可以从数据源的最后一个元素反向迭代到第一个元素,增强了反向遍历能力。ExactSizeIterator,它知道元素的确切数量,从而可以进行更精确的控制和优化。FusedIterator,它保证在next方法首次返回None之后只会返回None,确保在迭代结束时行为更可预测。
必须认识到,要想扩展迭代器的功能,必须对数据源施加额外要求。例如,rev 迭代器适配器允许以相反的顺序遍历元素,它仅适用于双端迭代器。这意味着它可以应用于 vec,但不适用于输入流或其他未实现 DoubleEndedIterator 的结构。
rust
let vec = vec![1, 2, 3, 4, 5];
let mut iter = vec.iter(); // iter() 返回一个 DoubleEndedIterator
// 从前往后取一个
println!("{:?}", iter.next());
// 从后往前取一个
println!("{:?}", iter.next_back());
// output
// Some(1)
// Some(5)幸运的是,vec 也实现了 ExactSizeIterator。
rust
let data = vec![10, 20, 30, 40];
let iter = data.iter(); // 实现了 ExactSizeIterator
println!("总共有 {} 个元素", iter.len());
// output
// 总共有 4 个元素至于 FusedIterator,标准 Iterator trait 不要求这一点。理论上,一个"不规范"的迭代器可能在返回 None 之后,再次调用 .next() 又返回 Some(...)(虽然标准库中几乎不会这样)。这里我们不举例,你只需要知道,Iterator trait 并不是 Rust 标准库提供的唯一迭代器 trait 即可。
总结
Rust 的迭代器系统通过 Iterator、DoubleEndedIterator、ExactSizeIterator 和 FusedIterator 等 trait,构建了一个强大而灵活的数据处理框架。它不仅支持在各种数据结构上编写高效、简洁的代码,还通过声明式的风格显著提升了可读性和复用性。配合丰富的迭代器适配器(如 map、filter、enumerate 等),开发者可以像搭积木一样组合出清晰、优化的数据处理流程。当然,要充分发挥这套系统的优势,也需要了解底层数据源的特性和限制。
总体而言,Rust 的迭代器在抽象表达与运行效率之间取得了出色的平衡,为解决复杂的编程问题提供了优雅而实用的工具。