MCP服务构建、使用
-
- [一、什么是 MCP(Model Context Protocol)](#一、什么是 MCP(Model Context Protocol))
-
- [1. MCP 的定义与作用](#1. MCP 的定义与作用)
- [2. MCP 的核心组成](#2. MCP 的核心组成)
- [3. 为什么要用 MCP?](#3. 为什么要用 MCP?)
- 4.安装
- [二、先构建最简单的mcp server](#二、先构建最简单的mcp server)
- 三、获取mcp工具列表,如demo.py中的main、mian1、mian2三种方式。
- 四、mcp服务以及call_tool(工具调用)
- 五、更进一步------使用大模型提取问答中的参数和需要的工具,进而执行得出结果。
-
- 1、使用大模型提取参数和工具名称------再调用
- [2、直接使用tool call的能力](#2、直接使用tool call的能力)
一、什么是 MCP(Model Context Protocol)
1. MCP 的定义与作用
MCP 是一个开放协议,旨在标准化大型语言模型(LLM)与外部工具、数据源、服务的交互方式。
它可以被看作是:"AI 的 USB-C 接口" ------ 就像各种设备通过 USB-C 统一连接外设,LLM 可以通过 MCP 统一访问不同的工具、资源、API。
与传统 API 不同的是,MCP 专门为 语言模型交互 优化:LLM 能"看到"可用工具、知道参数结构、能够"调用"这些工具来增强它的能力。
2. MCP 的核心组成
在 MCP(以 FastMCP 为例)里,一般包含以下几类组件:
| 组件 | 含义 | 角色 / 相似概念 |
|---|---|---|
| Tools | 可执行的功能(方法 / 函数) | 类似 API 的 POST / 操作,比如 "查询数据库"、"调用计算" (FastMCP) |
| Resources | 只读数据 / 上下文资源 | 类似 API 的 GET / 数据接口 |
| Prompts | 预设的交互模板 | 有助于统一对话、构建复杂任务流程 (FastMCP) |
| Transport / 通信方式 | 客户端 ↔ 服务器 之间的连接协议 | 比如 stdio、HTTP(streamable)、SSE、WebSocket 等 (FastMCP) |
3. 为什么要用 MCP?
- 解耦 LLM 与工具实现:LLM 不需要了解底层工具怎么编写,只要有标准接口就能调用。
- 安全性与权限控制:工具可以有权限控制、验证、输入校验等约束。
- 可组合 & 可扩展:可以把多个工具 / 资源组合成复杂任务,让 LLM 编排使用。
- 统一标准:使用 MCP,各种客户端(Claude Desktop、LLM 应用等)都可以统一访问你的服务。
4.安装
python
pip install mcp二、先构建最简单的mcp server
python
# mcp_tools.py
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("TestServer")
@mcp.tool()
def add(a:int, b:int):
"""
返回两数之和。
Args:
a: int
b: int
Returns:
两数之和
"""
return {"result": a+b}
if __name__ == "__main__":
mcp.run(transport="sse")
# transport 可选 ['stdio', 'sse', 'streamable-http']当transport选择为 'sse'或 'streamable-http'时,需要在命令行启动。
python
python mcp_tools.py三、获取mcp工具列表,如demo.py中的main、mian1、mian2三种方式。
python
# demo.py
import asyncio
from mcp.client.stdio import stdio_client, StdioServerParameters
from mcp.client.session import ClientSession
from contextlib import AsyncExitStack
from mcp.client.sse import sse_client
from mcp.client.streamable_http import streamablehttp_client
async def main():
exit_stack = AsyncExitStack()
server_params = StdioServerParameters(
command="python",
args=["mcp_tools.py"],
env=None
)
stdio_transport = await exit_stack.enter_async_context(stdio_client(server_params))
stdio, write = stdio_transport
session = await exit_stack.enter_async_context(ClientSession(stdio, write))
await session.initialize()
print("✅ Session 已初始化")
tools = await session.list_tools()
print("🔧 Tools:", tools)
# result = await session.call_tool("query", {})
# print("📌 调用结果:", result)
await exit_stack.aclose()
async def main1():
exit_stack = AsyncExitStack()
server_params = StdioServerParameters(
command="python",
args=["mcp_tools.py"],
env=None
)
async with (stdio_client(server_params)) as (read, write):
session = await exit_stack.enter_async_context(ClientSession(read, write))
await session.initialize()
print("✅ Session 已初始化")
tools = await session.list_tools()
print("🔧 Tools:", tools)
# result = await session.call_tool("query", {})
# print("📌 调用结果:", result)
await exit_stack.aclose()
async def main2():
url = "https://mcp.api-inference.modelscope.net/your-key/sse" # modelscope中高德地图的mcp服务
# url = "http://localhost:8000/mcp" # 在本地自己启动 python mcp_tools.py 且transport="streamable-http"
# url = "http://localhost:8000/sse" # 在本地自己启动 python mcp_tools.py 且transport="sse"
print(f"尝试连接到: {url}")
exit_stack = AsyncExitStack()
# 1. 进入 SSE 上下文,但不退出
if url.endswith("sse"):
sse_cm = sse_client(url)
elif url.endswith("mcp"):
sse_cm = streamablehttp_client(url)
else:
raise ValueError("URL 必须以 'sse' 或 'mcp' 结尾")
# 手动调用 __aenter__ 获取流,并存储上下文管理器以便后续退出
streams = await exit_stack.enter_async_context(sse_cm)
print("SSE 流已获取。")
# 2. 进入 Session 上下文,但不退出
session_cm = ClientSession(streams[0], streams[1])
# 手动调用 __aenter__ 获取 session
session = await exit_stack.enter_async_context(session_cm)
print("ClientSession 已创建。")
# 3. 初始化 Session
await session.initialize()
print("Session 已初始化。")
# 4. 获取并存储工具列表
response = await session.list_tools()
tools = {tool.name: tool for tool in response.tools}
print(f"成功获取 {len(tools)} 个工具:")
for name, tool in tools.items():
print(f" - {name}: {tool.description[:50]}...") # 打印部分描述
print("连接成功并准备就绪。")
await exit_stack.aclose()
if __name__ == "__main__":
asyncio.run(main2())其中main2是两种主要的mcp服务形式。
四、mcp服务以及call_tool(工具调用)
使用sse方式启动mcp_tools.py之后,执行下面代码,可以模拟执行工具函数。主要关注session.call_tool
python
# call_tools.py
from mcp.client.session import ClientSession
from mcp.client.sse import sse_client
from mcp.client.streamable_http import streamablehttp_client
from contextlib import AsyncExitStack
import asyncio
import json
async def main2():
# url = "http://localhost:8000/mcp" # 在本地自己启动 python mcptest.py 且transport="streamable-http"
url = "http://localhost:8000/sse" # 在本地自己启动 python mcptest.py 且transport="sse"
print(f"尝试连接到: {url}")
exit_stack = AsyncExitStack()
# 1. 进入 SSE 上下文,但不退出
if url.endswith("sse"):
sse_cm = sse_client(url)
elif url.endswith("mcp"):
sse_cm = streamablehttp_client(url)
else:
raise ValueError("URL 必须以 'sse' 或 'mcp' 结尾")
# 手动调用 __aenter__ 获取流,并存储上下文管理器以便后续退出
streams = await exit_stack.enter_async_context(sse_cm)
print("SSE 流已获取。")
# 2. 进入 Session 上下文,但不退出
session_cm = ClientSession(streams[0], streams[1])
# 手动调用 __aenter__ 获取 session
session = await exit_stack.enter_async_context(session_cm)
print("ClientSession 已创建。")
# 3. 初始化 Session
await session.initialize()
print("Session 已初始化。")
# 4. 获取并存储工具列表
response = await session.list_tools()
tools = {tool.name: tool for tool in response.tools}
print(f"成功获取 {len(tools)} 个工具:")
for name, tool in tools.items():
print(f" - {name}: {tool.description[:500]}") # 打印部分描述
print("连接成功并准备就绪。")
tool_args = {"a":1, "b":3}
result = await session.call_tool(
"add", tool_args
)
print("\n输入数据是:", tool_args, "\n结果是:", json.loads(result.content[0].text)["result"])
await exit_stack.aclose()
if __name__ == "__main__":
asyncio.run(main2())执行结果如下:
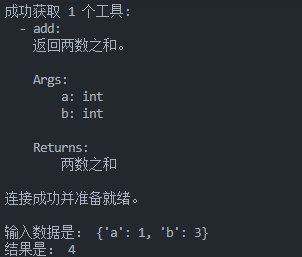
五、更进一步------使用大模型提取问答中的参数和需要的工具,进而执行得出结果。
1、使用大模型提取参数和工具名称------再调用
python
from mcp.client.session import ClientSession
from mcp.client.sse import sse_client
from mcp.client.streamable_http import streamablehttp_client
from contextlib import AsyncExitStack
import asyncio
import json
from mcptest import mcp
import asyncio, json
tools = asyncio.run(mcp.list_tools())
def format_tools_for_llm(tool) -> str:
"""对tool进行格式化
Returns:
格式化之后的tool描述
"""
args_desc = []
if "properties" in tool.inputSchema:
for param_name, param_info in tool.inputSchema["properties"].items():
arg_desc = (
f"- {param_name}: {param_info.get('Description', 'No description')}"
)
if param_name in tool.inputSchema.get("required", []):
arg_desc += " (required)"
args_desc.append(arg_desc)
return f"Tool: {tool.name}\nDescription: {tool.description}\nArguments:\n{chr(10).join(args_desc)}"
async def main2(params):
# url = "http://localhost:8000/mcp" # 在本地自己启动 python mcptest.py 且transport="streamable-http"
url = "http://localhost:8000/sse" # 在本地自己启动 python mcptest.py 且transport="sse"
print(f"尝试连接到: {url}")
exit_stack = AsyncExitStack()
# 1. 进入 SSE 上下文,但不退出
if url.endswith("sse"):
sse_cm = sse_client(url)
elif url.endswith("mcp"):
sse_cm = streamablehttp_client(url)
else:
raise ValueError("URL 必须以 'sse' 或 'mcp' 结尾")
# 手动调用 __aenter__ 获取流,并存储上下文管理器以便后续退出
streams = await exit_stack.enter_async_context(sse_cm)
print("SSE 流已获取。")
# 2. 进入 Session 上下文,但不退出
session_cm = ClientSession(streams[0], streams[1])
# 手动调用 __aenter__ 获取 session
session = await exit_stack.enter_async_context(session_cm)
print("ClientSession 已创建。")
# 3. 初始化 Session
await session.initialize()
print("Session 已初始化。")
# 4. 获取并存储工具列表
response = await session.list_tools()
tools = {tool.name: tool for tool in response.tools}
print(f"成功获取 {len(tools)} 个工具:")
for name, tool in tools.items():
print(f" - {name}: {tool.description[:500]}") # 打印部分描述
print("连接成功并准备就绪。")
result = await session.call_tool(
params["tool"], params["arguments"]
)
try:
print("\n输入数据是:", params["arguments"], "\n执行的工具是:", params["tool"], "\n结果是:", json.loads(result.content[0].text)["result"])
except:
print(result.content[0].text)
await exit_stack.aclose()
def extract_tool_params(text:str):
messages = []
tools_description = "\n".join([format_tools_for_llm(tool) for tool in tools])
system_prompt = (
"You are a helpful assistant with access to these tools:\n\n"
f"{tools_description}\n"
"Choose the appropriate tool based on the user's question. "
"If no tool is needed, reply directly.\n\n"
"IMPORTANT: When you need to use a tool, you must ONLY respond with "
"the exact JSON object format below, nothing else:\n"
"{\n"
' "tool": "tool-name",\n'
' "arguments": {\n'
' "argument-name": "value"\n'
" }\n"
"}\n\n"
'"```json" is not allowed'
"After receiving a tool's response:\n"
"1. Transform the raw data into a natural, conversational response\n"
"2. Keep responses concise but informative\n"
"3. Focus on the most relevant information\n"
"4. Use appropriate context from the user's question\n"
"5. Avoid simply repeating the raw data\n\n"
"Please use only the tools that are explicitly defined above."
)
messages.append({"role": "system", "content": system_prompt})
# print(messages)
messages.append({"role": "user", "content": text})
from openai import OpenAI
client = OpenAI(
base_url="https://api.deepseek.com",
api_key="your-api-key",# 替换成你的deepseek的api-key
)
model = "deepseek-chat"
response = client.chat.completions.create(
model=model,
messages=messages,
)
message = response.choices[0].message
return json.loads(message.content)
if __name__ == "__main__":
params = extract_tool_params("计算100+20等于几?")
asyncio.run(main2(params))运行结果:
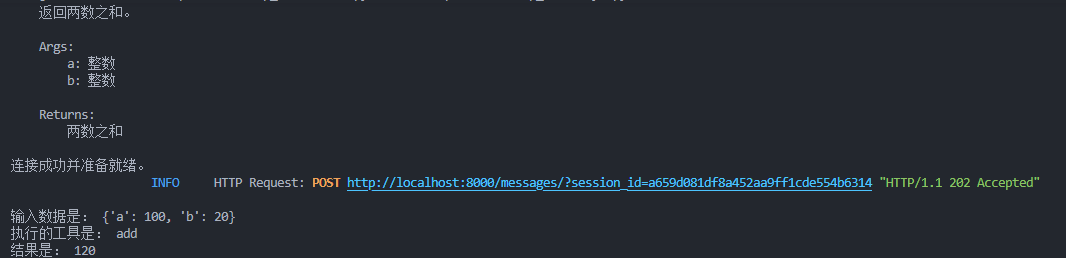
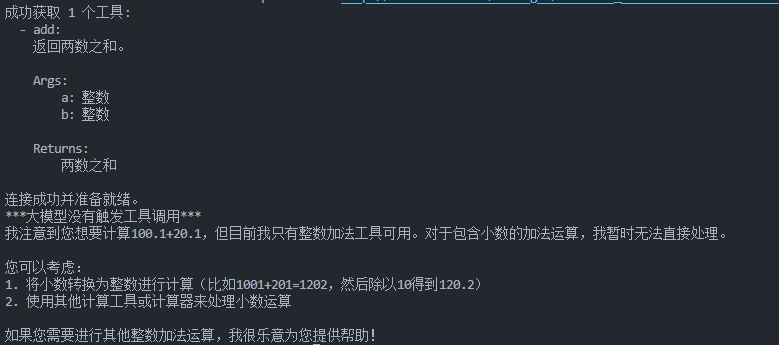
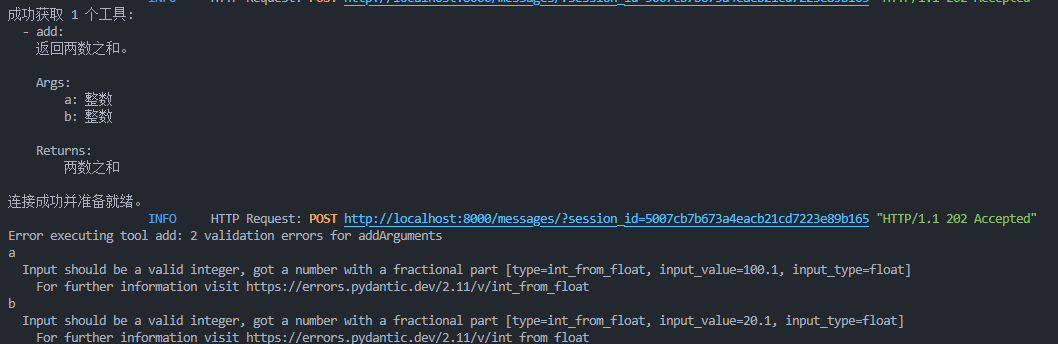
当我提问是
python
"计算100.1+20.1等于几"报错了,因为类型不符合
以上方式是利用大模型的提取参数的能力,还没有用到大模型的function call能力。从下图可以看出,它只是提取了参数和工具名,我们需要根据参数和工具名去执行工具。
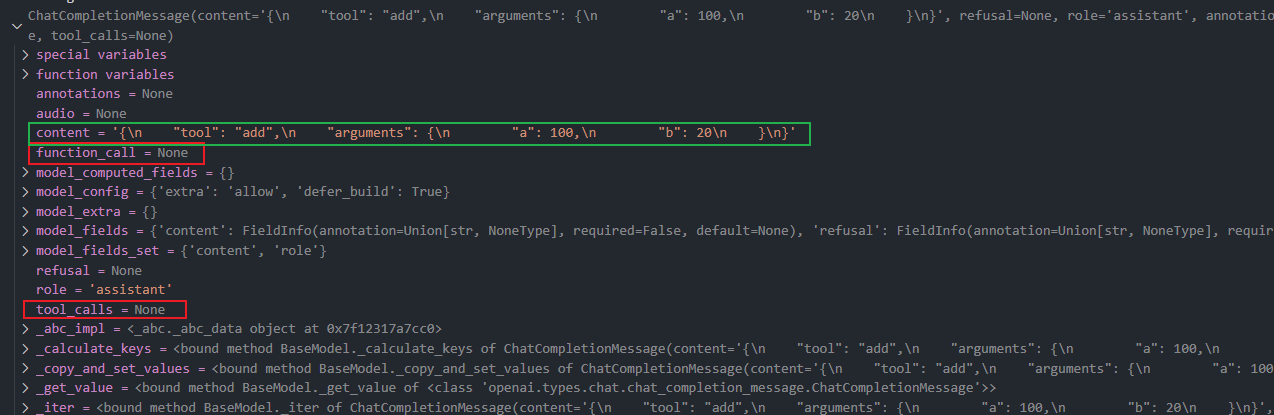
2、直接使用tool call的能力
python
from mcp.client.session import ClientSession
from mcp.client.sse import sse_client
from mcp.client.streamable_http import streamablehttp_client
from contextlib import AsyncExitStack
import asyncio
import json
from mcptest import mcp
import asyncio, json
import websockets
tools = asyncio.run(mcp.list_tools())
def format_tools_for_llm(tool) -> str:
"""对tool进行格式化
Returns:
格式化之后的tool描述
"""
args_desc = []
if "properties" in tool.inputSchema:
for param_name, param_info in tool.inputSchema["properties"].items():
arg_desc = (
f"- {param_name}: {param_info.get('Description', 'No description')}"
)
if param_name in tool.inputSchema.get("required", []):
arg_desc += " (required)"
args_desc.append(arg_desc)
return f"Tool: {tool.name}\nDescription: {tool.description}\nArguments:\n{chr(10).join(args_desc)}"
async def main2(message):
# url = "http://localhost:8000/mcp" # 在本地自己启动 python mcptest.py 且transport="streamable-http"
url = "http://localhost:8000/sse" # 在本地自己启动 python mcptest.py 且transport="sse"
print(f"尝试连接到: {url}")
exit_stack = AsyncExitStack()
# 1. 进入 SSE 上下文,但不退出
if url.endswith("sse"):
sse_cm = sse_client(url)
elif url.endswith("mcp"):
sse_cm = streamablehttp_client(url)
else:
raise ValueError("URL 必须以 'sse' 或 'mcp' 结尾")
# 手动调用 __aenter__ 获取流,并存储上下文管理器以便后续退出
streams = await exit_stack.enter_async_context(sse_cm)
print("SSE 流已获取。")
# 2. 进入 Session 上下文,但不退出
session_cm = ClientSession(streams[0], streams[1])
# 手动调用 __aenter__ 获取 session
session = await exit_stack.enter_async_context(session_cm)
print("ClientSession 已创建。")
# 3. 初始化 Session
await session.initialize()
print("Session 已初始化。")
# 4. 获取并存储工具列表
response = await session.list_tools()
tools = {tool.name: tool for tool in response.tools}
print(f"成功获取 {len(tools)} 个工具:")
for name, tool in tools.items():
print(f" - {name}: {tool.description[:500]}") # 打印部分描述
print("连接成功并准备就绪。")
for tool_call in message.tool_calls:
tool_request = {
"id": tool_call.id,
"type": "tool_call",
"tool": tool_call.function.name,
"params": json.loads(tool_call.function.arguments)
}
result = await session.call_tool(tool_request["tool"], tool_request["params"])
try:
print("\n输入数据是:", message["arguments"], "\n执行的工具是:", message["tool"], "\n结果是:", json.loads(result.content[0].text)["result"])
except:
print(result.content[0].text)
await exit_stack.aclose()
def extract_tool_params(text:str):
messages = []
messages.append({"role": "system", "content": "You are a helpful assistant"})
# print(messages)
messages.append({"role": "user", "content": text})
from openai import OpenAI
client = OpenAI(
base_url="https://api.deepseek.com",
api_key="your-api-key",
)
model = "deepseek-chat"
response = client.chat.completions.create(
model=model,
messages=messages,
tools=mcp_tools_to_openai(tools)
)
message = response.choices[0].message
return message
def mcp_tools_to_openai(tools_from_mcp):
openai_tools = []
for t in tools_from_mcp:
openai_tools.append({
"type": "function",
"function": {
"name": t.name,
"description": t.description,
"parameters": t.inputSchema
}
})
return openai_tools
if __name__ == "__main__":
message = extract_tool_params("计算100+20等于几?")
asyncio.run(main2(message))结果如下:
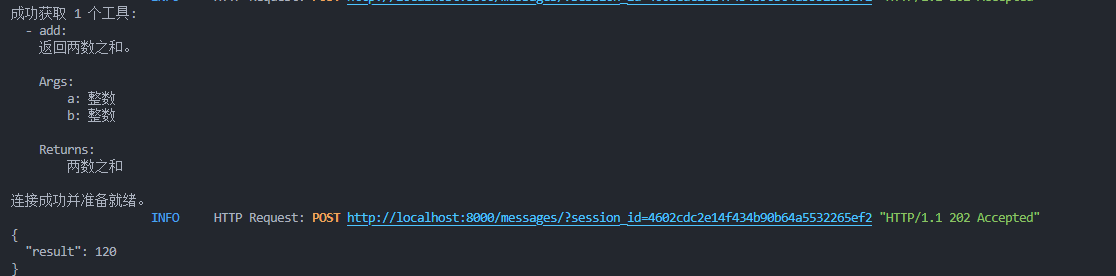
大模型返回信息如下:
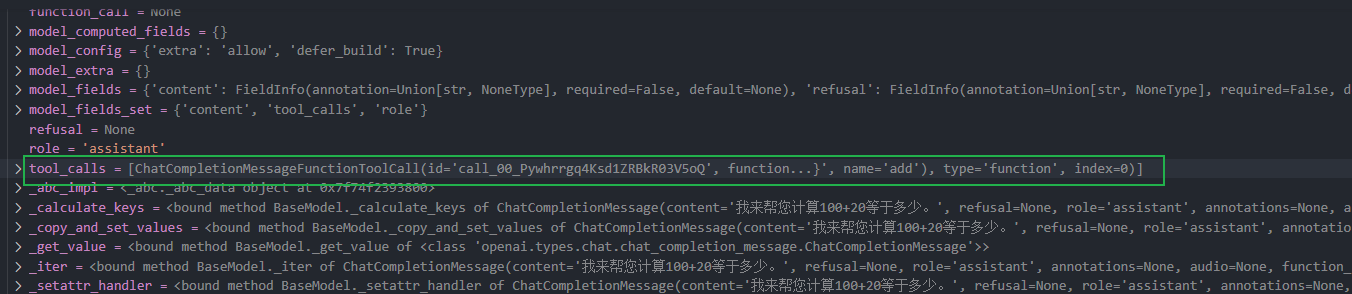
当我提问是
python
"计算100.1+20.1等于几"结果如下: