最近在使用 NestJs 和 NextJs 在做一个协同文档 DocFlow,如果感兴趣,欢迎 star,有任何疑问,欢迎加我微信进行咨询 yunmz777
一、是什么?
SoulX‑Podcast 是由 Soul AI Lab 与 Northwestern Polytechnical University 等联合推出的语音合成模型,专门针对"播客/对话"这种多说话人、多轮、多情境的语音内容而设计。 核心目标包括:
- 支持 多说话人、多轮对话 的语音合成,而不只是传统的一个人朗读。
- 支持 长时段的生成(例如整期播客的长度,而非几句)。
- 支持 多语言/方言(普通话、英语、粤语、四川话、河南话)以及 副语言特征(如笑声、叹气、喘息等)。
- 支持 零样本语音克隆(zero‑shot voice cloning):只用很少目标说话人数据也能生成其风格。
简言之:如果你想自动"生成播客"、"做多人访谈音频"或"创建有地域口音或方言特征"的语音内容,这个模型就是为此类场景量身定制的。
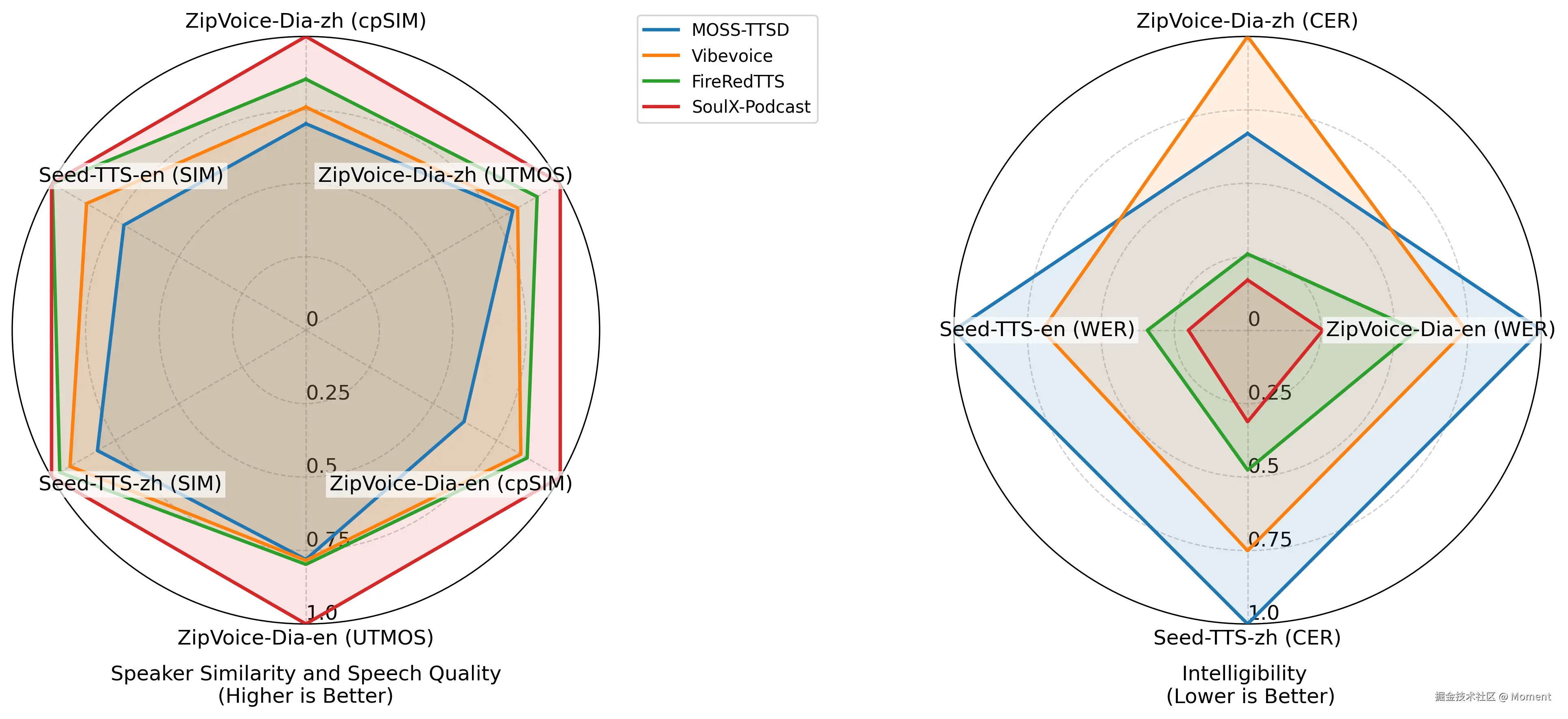
二、主要亮点(为什么很"酷")
以下是这个模型几个让人印象深刻的地方:
-
对话场景优化:传统 TTS 模型多数优化的是单个说话人说一段话,SoulX‑Podcast 则把"说话人切换""对话节奏""多轮往返"放进模型设计里。
-
长时间稳定输出:模型官方测试中能够输出超过 90 分钟的连续对话,并且说话人音色、音质维持稳定。
-
方言 + 跨方言支持:除了标准普通话与英语,还支持四川话、河南话、粤语等方言,并且支持用一种语言的提示生成另一种方言语音(跨方言提示)。
-
副语言控制:你可以在文本里加标签如"<|laughter|>"笑、"<|sigh|>"叹气,让生成语音听起来更"有人味"。模型在这方面识别准确率约 0.82。
-
开源 + 学术支持:代码托管在 GitHub,模型放在 Hugging Face,可用于研究/教育用途。
这里官方提供了一些 Demo,可以去体验一下。
三、能用在哪些场景?
结合其特点,以下是一些很实际的应用场景:
- 自动化播客/访谈:假如你想制作带多个角色、对话式的音频,可以用这个模型生成主持人+嘉宾对话。
- 虚拟主播或角色配音:给虚拟角色配一个有感情、有方言、有特色的声音。
- 方言语音产品:为特定地域群体提供方言语音服务,比如粤语播报、川话讲解。
- 语音克隆与定制化声音:你可以用少量样本,让系统生成你喜欢的声音风格用于朗读、音频书、角色对白等。
- 教育/语言学研究:对话语音、方言语音、非语言符号(如笑、喘)这些过去难以合成的内容,现在变得可用起来了。
四、简单上手指南
如果想快速体验模型,按照以下流程即可:
-
克隆仓库
bashgit clone https://github.com/Soul‑AILab/SoulX‑Podcast.git cd SoulX‑Podcast -
安装环境(推荐用 Conda)
bashconda create -n soulxpodcast -y python=3.11 conda activate soulxpodcast pip install -r requirements.txt如果在国内,可使用 PyPI 镜像:
bashpip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com -
下载预训练模型权重
- 基础模型:
SoulX‑Podcast‑1.7B - 方言模型:
SoulX‑Podcast‑1.7B‑dialect
bashpip install -U huggingface_hub huggingface-cli download --resume-download Soul‑AILab/SoulX‑Podcast‑1.7B --local-dir pretrained_models/SoulX‑Podcast‑1.7B huggingface-cli download --resume-download Soul‑AILab/SoulX‑Podcast‑1.7B‑dialect --local-dir pretrained_models/SoulX‑Podcast‑1.7B‑dialect或使用 Python 脚本:
pythonfrom huggingface_hub import snapshot_download snapshot_download("Soul‑AILab/SoulX‑Podcast‑1.7B", local_dir="pretrained_models/SoulX‑Podcast‑1.7B") snapshot_download("Soul‑AILab/SoulX‑Podcast‑1.7B‑dialect", local_dir="pretrained_models/SoulX‑Podcast‑1.7B‑dialect") - 基础模型:
-
运行示例生成音频
bashbash example/infer_dialogue.sh该脚本将生成一个对话音频,可用于快速体验模型效果。
-
(可选)启动 Web UI 如果希望通过图形界面操作:
bashpython3 webui.py --model_path pretrained_models/SoulX‑Podcast‑1.7B若使用方言模型,则替换
--model_path为pretrained_models/SoulX‑Podcast‑1.7B‑dialect。 -
脚本与输出检查建议
- 准备你的对话文本:设定说话人标签、可插入笑声/叹气等副语言标记,比如
<|laughter|>、<|sigh|>。 - 若想用某个方言(如粤语、四川话等),使用方言模型,脚本中可加入方言提示。
- 生成后务必听一听:说话人音色是否一致、说话切换是否自然、对话节奏是否流畅。如有不满意,可调整脚本或标签再试。
- 准备你的对话文本:设定说话人标签、可插入笑声/叹气等副语言标记,比如
这样,你只需要按照 1️⃣ → 6️⃣ 步骤执行,就可以快速上手 SoulX‑Podcast 模型,生成你想要的播客/对话音频。
五、使用时需注意/挑战点
尽管这个模型功能强大,但也有一些你需要留意的地方:
-
硬件要求:长篇生成 + 多说话人 +方言 +副语言标签,算力需求可能比较高。
-
生成质量还是有边界:虽然效果优秀,但在极端方言、非常复杂对话情境下,误差可能比普通话更大。论文中方言生成在某些评测上误差还略高。
-
伦理与合法性:模型支持"零样本语音克隆",所以存在被滥用的风险(假冒声音、冒充等)。项目方已明确表示不得用于未经授权的语音克隆、诈骗、冒充。
-
实时或交互式还有限:这个模型目前更适于"预先生成播客""录制场景",如果你要做实时语音对话或 live streaming,可能还需要额外的工程适配。
-
方言提示需要设计:若要生成方言语音,提示文本里可能需要加入"方言典型句子"来帮助模型切换方言。论文中称为 "Dialect‑Guided Prompting (DGP)" 方法。
六、总结
如果你正在寻找一个可以生成"多角色对话""整期播客""带方言+带笑+带感情"的语音合成解决方案,SoulX‑Podcast 无疑是目前非常值得尝试的一个选择。只不过要用好它,还需要一定的准备(脚本、提示、算力、合法性意识)。