AI在前端工作中的应用
在AI的高速发展中,也离不开前端,前端开发也在AI工具中发挥着举足轻重的作用。同时,一些AI工具也是的前端开发工作提效不少,合理利用工具,能在工作中提升效率。本文介绍一些前端与AI结合的场景,不限于接入,也包含一些工具的使用。
1、自定义GPT场景
在自定义 GPT 场景中,前端的核心职责是搭建 "用户 - 自定义 GPT" 的交互入口,同时支撑 GPT 的个性化配置、功能扩展与数据可视化,需围绕 "交互体验、配置能力、集成适配" 三大核心展开工作。
ant-design提供给前端开发者快速开发AI相关的UI组件库:https://ant-design-x.antgroup.com
- SSE
SSE是一种基于HTTP协议的数据传输方式,它允许服务端向客户端推送数据。前端可以通过SSE实现GPT的实时对话,用户输入问题,GPT返回结果。为什么选择这种方式,是因为GPT返回结果是很漫长的,所以用流式传入,能让用户体验更友好,不用websocket是因为长连接占用资源过多,服务器长连接数有限,所以用SSE。
可以直接使用微软的SSE库:https://github.com/microsoft/fetch-event-source
npm i -S @microsoft/fetch-event-sourcec使用也很简单,注意处理 onerror,否则发生错误后还会一直尝试请求。
ts
import { fetchEventSource } from '@microsoft/fetch-event-source';
fetchEventSource(`${process.env.API_MOLSCI_URL}/v1/chat`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(data),
// tab失焦,聚焦后不断开
openWhenHidden: true,
onopen() {
console.log('连接成功');
},
onmessage(event) {
console.log('传输内容', event);
},
onclose() {
console.log('连接关闭');
return false;
},
onerror(err) {
console.error('连接错误', err);
throw err; // 抛出错误,不处理的话发生错误后还会一直尝试请求
},
})- GPT对话
GPT对话框,用户输入问题,GPT返回结果。用户刷新后,能查看到聊天记录。
我们可以封装 Chat 的 Hooks,实现这些通用的数据处理逻辑:
ts
export function useChat() {
// 存储历史记录,游标分页
const [historyList, setHistoryList] = React.useState([]);
// 存储当前输入和SSE接受的数据合并成动态messageList
const [messageList, setMessageListState] = React.useState([]);
// 渲染列表
const renderList = [...historyList, ...messageList];
/**
* 处理SSE接受数据等逻辑
* 处理滚动
* 处理loading状态
* 主动断开SSE连接使用 new AbortController()
* ......
*/
return {
renderList,
}
}- markdown渲染
GPT有时候返回的是纯文本,有时候是markdown,所以需要处理markdown。
npm i -S react-markdown
tsx
import ReactMarkdown from 'react-markdown';
<ReactMarkdown>{str}</ReactMarkdown>- 划词翻译、解释
划词翻译、解释,前端开发需要实现划词翻译、解释,用户输入问题,GPT返回结果。用户刷新后,能查看到聊天记录。
利用 window?.getSelection 来获取划词文本,然后传入Chat进行后续对话。
tsx
const SelectableText = () => {
const [selectedText, setSelectedText] = useState('');
const [isShowChatTranslateDrawer, setIsShowChatTranslateDrawer] = useState(false);
const debounceHandlerMouseup = _lodash.debounce(handlerMouseup, 200);
useEffect(() => {
window.addEventListener('mouseup', debounceHandlerMouseup);
window.addEventListener('click', handleOnWindowClick);
return () => {
window.removeEventListener('mouseup', debounceHandlerMouseup);
window.removeEventListener('click', handleOnWindowClick);
};
}, []);
function handlerMouseup(event) {
const selectedText = window?.getSelection
? window?.getSelection()?.toString() || ''
: '';
initCardPos(event);
setSelectedText(selectedText);
}
function handleOnWindowClick() {
setIsShowChatTranslateDrawer(false);
}
// 划词解释框为了能一直保持在屏幕内,可以计算划词位置与屏幕边界的距离,计算之后设置坐标
function initCardPos(event) { }
}
export default SelectableText2、知识库问答场景
在纯调模型的基础上,与企业自己数据库结合,使用RAG、MCP等技术接入自己的数据。现在很多企业都在做自己的知识库,利用企业内部数据库与大模型结合,实现知识库的检索。这时候,前端开发需要实现GPT对话框,让用户输入问题,然后通过API调用GPT模型,返回结果。
- RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是融合检索技术与生成模型的人工智能框架。
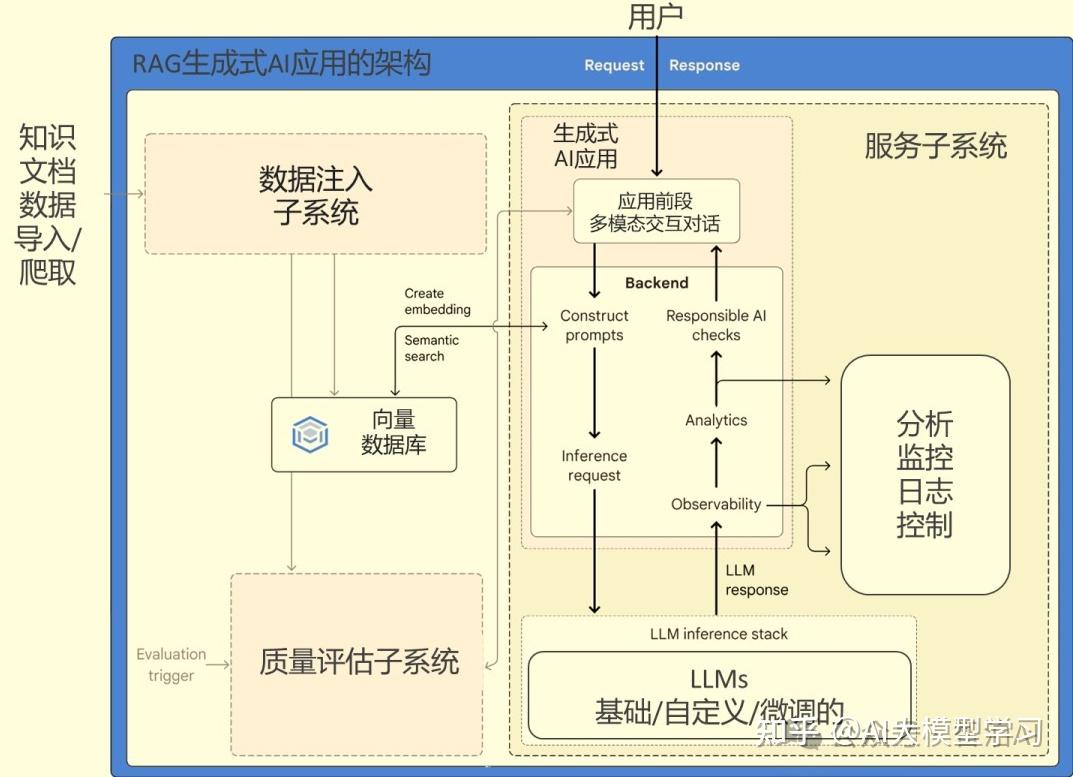
通俗的讲,就是在调用GPT模型时,先调用向量数据库,获取相关的数据,作为GPT的预设,然后调用GPT模型,返回结果。比如:
我们系统中有一些专业术语的翻译,如果不告知GPT,那么就是纯靠运气,它返回什么就是什么了,RAG的作用就是先告诉GPT这些专业术语的翻译是什么,那么GPT就会按照这个翻译进行翻译,而不是纯靠运气。
- MCP
MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大模型与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
通俗的讲,MCP的作用就是让GPT模型在自身功能无法实现,可以调用提供给它的工具,比如:数据库、文件、API、工具等。MCP协议的话规范了参数的格式,所有企业与大模型都遵守这个规范,那么就能随意切换任何模型使用,算是统一了标准。
- 前端对接
RAG是纯后端预设向量数据库,基本与前端无关。MCP工具调用,前端需要在SSE中捕获到工具调用的指令时,处理工具调用,然后调用工具,带上工具的参数,再次调用GPT,继续对话,直至完成对话结果。
ts
/** 约定工具调用flag,遇到flag时,再度调用接口,由接口去处理工具调用,返回结果,继续对话 */当然这是我的思路,大家可以自由发挥,毕竟通向罗马的路不止一条
3、AI提效工具
在日常工作中,确实很多AI工具能助力我们提效,比如:
(1)代码提示工具
- GitHub Copilot
最早在这个赛道,一度收费导致用户量上不去。GitHub Copilot 是 GitHub 推出的代码提示工具,基于 GPT 模型,可以提供代码提示、代码补全、代码重构、代码生成、代码注释、代码测试、代码调试等功能。
- 通义灵码
我目前用的,阿里推出的语言模型,基于通义千问,提供代码提示、代码补全、代码重构、代码生成、代码注释、代码测试、代码调试等功能。
- MarsCode
字节推出的代码提示工具,基于字节的Mars模型,提供代码提示、代码补全、代码重构、代码生成、代码注释、代码测试、代码调试等功能。
(2)编辑器
高度适配AI模型的编辑器,市面上也有几种,比如:
- Cursor
Cursor是由Anysphere开发的AI代码编辑器,集成GPT-4o等大语言模型,提供代码补全、重构、自然语言生成等功能。该工具支持中英双语环境,国内用户可通过特定方式使用。
- Trae
Trae是由字节团队开发的AI代码编辑器,基于字节的Mars模型,提供代码补全、重构、代码生成、代码注释、代码测试、代码调试等功能。该工具支持中英双语环境,国内用户可通过特定方式使用。
- Lingma
这是阿里云旗下首个AI原生的开发环境工具,深度适配了最新的千问3大模型,并集成国内最大的魔搭MCP市场,可调用超过3000个MCP服务,一键安装部署。
(3)设计稿转代码
- Figma AI
9月23日,Figma正式推出官方远程MCP(Model Context Protocol)服务器,这一创新工具彻底摆脱了对Figma客户端的依赖,让AI编码代理无缝接入设计上下文。
可以在Trae中,配置MCP Server - Figma AI Bridge,配置智能体,然后使用指令自动生成前端页面。
- Vercel AI
Vercel 宣布推出了 V0.dev,这是一款专为开发人员和设计师设计的工具,能够使用 AI 生成 React 代码。
- 总结
总的来说,目前AI在将设计稿转成代码时,还是无法达到交付效果的,并且大型项目及维护,还是需要专业的技术人员。AI并不是替代人员,而是让开发更高效,将重复率高,高复用的轮子共享。
(4)自动化测试
- Selenium AI
Parasoft Selenic通过AI技术赋能Selenium测试,实现了智能识别真实回归问题、自动修复定位器以及增强定位器和等待条件策略等多项强大功能,有效提高了测试的效率和稳定性,降低了维护成本。
- Testim AI
Testim是AI 驱动的端到端自动化测试平台,支持 Web 和移动应用测试。
4、纯前端模型
其实前端还是不太好搭上模型的车,毕竟模型吃配置,直接在客户端运行模型很耗内存,所以只能通过服务端运行模型,然后通过SSE将结果返回给前端。但是服务端运行的成本随用户量递增,这时候如果能把小的模型放在前端,无疑为企业节省很多成本,那么这个思路就出现了。
- tensorflow
比较经典的库了,支持在浏览器端运行神经网络模型,适用于图像分类、表单自动填充等场景。需注意模型体积需控制在合理范围内以避免页面加载延迟。
举个例子:
ts
// 使用预训练的MobileNet实现图像分类
import * as mobilenet from '@tensorflow-models/mobilenet';
async function classifyImage(imageElement) {
// 加载模型(首次加载较慢)
const model = await mobilenet.load();
// 执行分类
const predictions = await model.classify(imageElement);
// 处理结果
return predictions.map(pred => ({
label: pred.className,
probability: (pred.probability * 100).toFixed(2) + '%'
}));
}
// 使用示例
const img = document.getElementById('product-image');
img.onload = async () => {
const results = await classifyImage(img);
console.log('识别结果:', results);
};- Web Worker
Web Worker 是 JavaScript 的一个内置对象,允许我们创建一个线程来执行任务,从而提高应用程序的性能。当我们在客户端加载模型,使用Web Worker时,模型会运行在另一个线程中,不会阻塞主线程,从而提高应用程序的性能。
ts
const worker = new Worker('worker.js');
worker.postMessage({ type: 'init' });
worker.onmessage = (e) => {
if (e.data.predictions) {
console.log('Worker返回结果:', e.data.predictions);
}
};- WebAssembly
WebAssembly 是一种用于在浏览器中运行二进制代码的格式,它可以在浏览器中运行 JavaScript 代码,并且与 JavaScript 兼容。
可以将模型转换成 WebAssembly 格式,然后使用 WebAssembly 来运行模型。
还有些复杂运算js不太适合去做,这时候很多前端选择Rust来编写,然后编译成WebAssembly,然后通过WebAssembly来运行。
Rust有插件可以直接生成WebAssembly
wasm-pack build --target web
ts
import init, { add, fib } from './math_ops.js'; // 加载ES模块
async function run() {
await init(); // 初始化Wasm模块
// 调用加法函数
const sum = add(3, 5);
console.log('3 + 5 =', sum); // 输出:8
}
run();5、AI在软实力中使用
其实工作中,一些事情让AI帮忙,能事半功倍,比如:
- 测试数据生成
比如使用DeepSeek或任何GPT,让其生成一组测试数据,有的甚至能要求给excel。
以下是一个例子,比较符合现在GPT的prompt:
你是一名测试工程师
你现在正在编写测试用例,请生成2条用户数据,包含姓名、手机号、邮箱、地址
以JSON格式返回以下就是生成的结果:
json
[
{
"姓名": "陈宇",
"手机号": "13812345678",
"邮箱": "chenyu123@163.com",
"地址": "广州市天河区珠江新城华穗路263号"
},
{
"姓名": "林晓",
"手机号": "13987654321",
"邮箱": "linxiao890@qq.com",
"地址": "杭州市西湖区文三路98号东方通信大厦15层"
}
]- PPT
可以利用DeepSeek生成PPT的大纲,然后使用kimi来生成PPT
比如:
让DeepSeek生成一个高级前端工程师年度述职的PPT大纲
你是一名高级前端工程师
你这一年完成的工作内容有:
Q1
1. 创建了1000个页面
Q2
1. 创建了5000个组件
Q3
1. 创建了10000个接口
Q4
1. 创建了50000个测试用例
你要生成一个年度述职PPT的大纲然后再把这个大纲给kimi,kimi会生成PPT
- 会议纪要
可以利用GPT生成会议纪要,钉钉、飞书之类的办公软件都有会议纪要的功能
视频会议还能通过纪要定位到视频播放位置
6、思考
- AI代码维护
如果一个公司要求全用AI对话式编码,那么这个公司就会失去代码维护的技能,网上很多总是说用AI的话,2个小时能做出一个什么样的程序出来,但是这个程序后续没法维护的,功能基本是什么样就什么样了。
就像我用Trae,让他用Rust实现一个将html字符串转成word的功能,尽管向他提出问题后,都能不断去改,但是依然无法达到预期,而且它设计的代码,根本无法二次开发。
还有就是前端代码,如果直接从设计稿用AI转成代码,会用上unocss,也无法从全局层面考虑问题,只能逐个组件考虑。这样的AI代码,如果被某公司的外包部门买回去,然后招开发进去维护,简直比裁缝机还惨。
- 上下文
如果要和AI对话,那么上下文很重要,如果上下文不够,那么AI就会重复回答,或者回答错误。之后根据上下文内容,AI才能理解到语义,从而给出更好的答案。
但是很多用户都是全用一个窗口和AI对话,那么全部的上下文都会被保存,里面的内容太杂太乱,就会导致搜索困难,或者搜索结果不准确。所以我会根据问题的类型,开启新对话,而普通用户恐怕就不知道了。
上下文越多,对tokens的消耗就越高,然后对服务器的CPU计算,内存消耗,带宽的消耗,都会增加。
- 能源
AI对全球电力的消耗呈现快速增长趋势,预计到2030年数据中心用电量可能翻倍。大多企业都在自建数据中心,但是自建数据中心需要耗费大量电,而AI的计算能力也受电力限制。
AI图形训练需要大量显存,导致现在英伟达的显卡价格已经比CPU高了,这也是需要能源消耗
7B参数模型:FP16精度下需要约14GB显存,INT4量化后可降至3.5-4.9GB显存。推荐配置为NVIDIA RTX 3060(8GB显存)或更高,32GB内存,1TB NVMe SSD
13B参数模型:FP16需要26GB显存,INT4量化后约6.5-9.1GB显存。推荐NVIDIA RTX 3090(24GB显存)或A4000(16GB显存),64GB内存
70B参数模型:FP16需要140GB显存,INT4量化后约35-49GB显存。通常需要多GPU配置,如2×NVIDIA A100 80GB或4×RTX 4090(通过NVLink并联)DeepSeek之所以能火,就是它在实现8-90%的能力基础上,对硬件的运用能力进行了优化,大幅降低了成本。
- 发展
现在AI的发展,基本都是在软件层面突飞猛进,在硬件层面却很缓慢,宇树科技制造的机器人确实让人眼前一亮。我们不是希望重复枯燥的事情交给机器人去做,而内容创作,具有创造力的事情人类自己做,然而这个发展势头却恰恰相反。