从其他编程语言(如 Python、JavaScript,甚至 C++ 或 Java)转向 Rust 的开发者,在迭代器方面常常会面临挑战。
Rust 的所有权规则、类型系统的复杂性,以及对生成高效代码的追求,赋予了 Rust 迭代器独特的特性,看下面的 Rust 迭代器代码:
rust
let mut vec = vec![1, 2, 3, 4, 5];
// 通过不可变引用遍历 vector,不会获取所有权,vec 在循环后仍可使用
for i in &vec {
print!("{} ", i);
}
println!();
// 通过可变引用遍历 vector,不获取所有权但可以修改元素,vec 在循环后仍可使用
for i in &mut vec {
*i += 1;
print!("{} ", i);
}
println!();
// 通过获取所有权的方式遍历 vector,vec 在循环后不再可用
for i in vec {
print!("{} ", i);
}该篇文章,让我们深入细节,以获得更深入的理解。
谁拥有内存
迭代器源于数据源。根据数据源的不同,我们可以对以下内容进行迭代:
- 对类型为
&T的元素的引用。 - 对类型为
&mut T的元素的可变引用。 - 通过获取所有权来迭代类型为
T的元素本身。
上面三种方法,恰恰也是在 Rust 中如何使用数据的三种方法
对于容器,我们通常使用 iter、iter_mut 或 into_iter 方法来获取相应的迭代器,但通常还有其他选项。例如,std::collections::HashMap 提供了多种迭代器可供选择:
iter:用于访问所有键值对(键和值均为引用)。iter_mut:用于访问所有键值对(键为引用,值为可变引用)。keys:用于以引用的形式访问所有键。values和values_mut:分别用于以引用和可变引用的形式访问所有值。drain:用于从哈希映射中移除所有元素,并且能够在元素被丢弃之前以键值对的形式访问它们。
如果是实验阶段的代码,还有更多的选项。
额外说明一下,在 Rust 迭代器中,有三种等价情况:
for i in &vec等价于for i in vec.iter()。for i in &mut等价于for i in vec.iter_mut()。for i in vec等价于for i in vec.into_iter()。
某些数据源可能会使用其他名称,例如:
std::env::vars为我们提供impl Iterator<Item=(String, String)>。std::io::BufRead::lines返回impl Iterator<Item=Result<String>>。regex库提供find_iter、captures、captures_iter、split和splitn方法,这些方法会在包含&str的值上返回不同类型的迭代器。
与集合不同,这些数据源并不存储数据,而是在需要时生成数据。因此,我们不能对它们进行多次迭代。如果我们在其他地方需要接收到的数据,那么必须要么将其移动(在获得所有权之后),要么显式地创建自己的副本(在涉及引用的情况下)。如果不这样做,生命周期检查器会报错。我们可以使用以下迭代器方法将引用转换为拥有所有权的值:
copied:复制每个元素(如果元素实现了Copy特性,则可以使用)。cloned:克隆元素(当实现了Clone特性时适用)。
Rust 标准库中的迭代器提供的最重要保证之一是:不为我们处理流程中的每个元素执行隐式堆分配。
内存使用
不进行隐式堆分配意义重大。首先,这极大地限制了可以使用迭代器实现的有用抽象的范围。Rust 标准库优先考虑内存使用和性能,而其他编程语言在这些方面的关注较少,因此提供的功能要丰富得多。
itertools库就是一个功能丰富的迭代器库的杰出例子,它不受堆分配限制的约束。然而,这种灵活性是有代价的:会过度使用内存,而且有时候内存使用情况难以预测。
虽然 Rust 标准库中的迭代器遵循这些规则,但外部数据源可能并不遵循。例如,std::io::BufRead::lines 生成 Result<String> 作为流元素,这表明每次迭代都会发生一次堆分配。从流中读取的字符会被放入新分配的 String 中,这样该字符串就有了所有权。为了避免这种情况,我们应该使用 std::io::BufRead::read_line 函数,并且提供我们自己的 String 作为缓冲区来存储流中的字符。像十亿行挑战这样的难题就说明了过度的、不必要的分配是如何对性能产生显著影响的。
对冗长说 "不"
编写任何使用迭代器的代码的过程包括以下几个阶段:
- 我们将数据源转换为迭代器来创建一个可迭代对象,然后对其进行优化,使其适合后续阶段。
- 我们根据需要应用尽可能多的迭代器适配器来执行管道过程。
- 我们要么收集生成的元素,要么以其他方式消耗最终的迭代器。
我们是否需要将所有这些代码写成一长串调用,放在一个代码块中呢?不一定。为了增强代码的可读性,使其更易于理解和维护,对代码进行结构化处理至关重要。遗憾的是,在 Rust 中完成这项任务可能比预期更富有挑战性。
让我们来看下面这个示例。和本系列上一篇文章一样,我们有一个图书集合。现在,我们想为集合中出现的每个世纪打印一份图书列表。我们还想打印图书标识符,图书标识符为图书在集合向量中的索引加 1。
我们需要多次计算世纪信息,所以让我们将这个功能添加到 Book 结构体本身:
rust
impl Book {
fn century(&self) -> i32{
(self.year - 1).div(100) + 1
}
}以下是解决我们问题的代码:
rust
let books = collection();
books
.iter()
.map(Book::century)
.collect::<BTreeSet<_>>()
.into_iter() // 世纪升序排序
.for_each(|century| {
println!("Books from the {} century:", century);
books
.iter()
.enumerate()
.filter_map(|(ix, b)| {
if b.century() == century {
Some((ix + 1, b))
} else {
None
}
})
.for_each(|(id, book)| println!("#{id}: {book:?}"));
});我们将这个问题分解为两个主要步骤:
- 确定书籍中出现的所有世纪。这一初始步骤需要分析书籍,以提取书籍所属的不同世纪。
- 逐个处理每个世纪:
- 枚举向量中的元素。
- 根据所讨论的世纪对书籍进行筛选,同时计算每本书的标识符(枚举中的书籍索引加1)。
- 打印每本留存书籍的详细信息。
这种结构化方法有助于明确划分职责:先确定所涉及的世纪范围,然后专注于特定标准(世纪),据此对书籍进行处理和展示。
涉及嵌套迭代器链的代码可读性可能因人而异。有些人可能觉得它很清晰,但也有人会觉得不够清晰。
主要问题在于,乍一看,两个嵌套的迭代器链的可见性被遮蔽了,这实际上将代码的实际逻辑和结构隐藏在了迭代器适配器内部。
迭代器旨在通过具有描述性名称的方法和过程来阐明正在执行的操作。然而,当逻辑深度嵌套在多层迭代器中时,这种清晰度就会受到影响,使得理解代码的流程和意图变得更加困难。
要记住,迭代器虽然功能强大,但使用迭代器本身并不是目的。目标应该始终是编写高效、可维护且易于理解的代码,而不是不考虑对代码可读性和可维护性的影响,就一味地在所有可能的场景中使用迭代器。
为了改进我们的代码,我们可以遵循一个简单的改进计划:
- 引入图书 ID 和显式可迭代对象:创建一个函数,返回包含图书 ID 的图书迭代器,从而提供清晰的可迭代对象构造。
- 收集世纪信息:从集合中收集所有唯一的世纪。
- 用
for循环遍历世纪:使用for循环遍历各个世纪。这通过避免迭代器链嵌套简化了代码。 - 过滤并打印图书:在循环内,使用简洁的迭代器链为每个世纪过滤并打印图书。
这个计划旨在提高代码的可读性,并为保持效率而保留迭代器的使用。
引入图书 ID 和显式可迭代对象
rust
struct BookId(usize);
fn books_with_ids<'a>(
books_iter: impl Iterator<Item = &'a Book>,
) -> impl Iterator<Item = (BookId, &'a Book)> {
books_iter.enumerate().map(|(ix, b)| (BookId(ix + 1), b)) // book's id is ix + 1
}这个函数处理一个指向 &Book 的迭代器,并生成一个包含 BookId 和 &Book 键值对的迭代器。为了将我们管道中的一部分封装到一个函数中,我们在参数和返回类型中都使用了 impl trait 类型。由于使用了引用,我们需要显式地指定生命周期,因为我们必须确保只要返回的图书在提供的迭代器中,它们就仍然有效。
收集世纪信息
rust
let centuries: BTreeSet<_> = books.iter()
.map(Book::century)
.collect();这行代码的可读性很强。将它们的结果赋给一个具有显式类型的变量,能让人更容易在脑海中想象出一个包含数据集中所有世纪的集合,相比之前的实现方式(.collect::<BTreeSet<_>>())------使用 turbofish(::<_>)语法,我更喜欢指定显式类型,因为我觉得这样编写的代码更容易理解。
用 for 循环遍历
rust
for century in centuries {
println!("Books from the {} century:", century);
books_with_ids(books.iter())
.filter(|(_, b)| b.century() == century)
.for_each(|(BookId(id), book)| {
println!("#{id}: {book:?}")
});
}这些步骤也非常简单明了。
可读性
使用迭代器的主要目的是使代码的可读性超越显式循环所能达到的程度。然而,当遇到一长串迭代器和深层嵌套时,这个目标就无法实现了。在这种情况下,传统的编码技术,比如提取函数或引入新类型,会更为有效,尽管可能需要应对与类型系统、借用检查器和生命周期相关的难题 。
在实现一个返回迭代器的函数时使用 impl Iterator 类型,会掩盖该迭代器的具体结构。不过,其应用仅限于函数的参数和返回值。那么,当我们想要将中间迭代器结构作为一个字段保留下来(可能是为了根据提供的输入构建一个迭代器管道)时,会发生什么情况呢?下一节将着重探讨这一点。
将迭代器作为变量和结构体成员
让我们先做一个小实验。假设我们有一组数字。有时我们需要对这组数字进行过滤,只保留偶数,而有时则不进行任何过滤。下面我们来探讨一下如何使用迭代器解决这个问题:
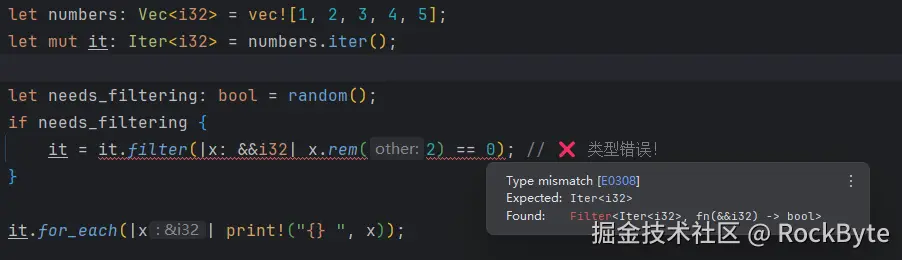
问题在于设计一种既能容纳原始迭代器又能容纳过滤后迭代器的类型。
这里的问题是,我们不能将 impl Iterator 用于变量类型。因为 impl Trait 指定了实现该 trait 的特定类型,并且这个类型必须在编译时就已知。然而,在上述场景中,直到运行时生成一个随机数,类型才会确定。为了解决这个问题,我们借助 trait 对象。
为了解决根据需要将过滤器与映射组合起来这一更广泛的问题,我们的目标是构建一个迭代器管道,它能够集成任意数量的映射或过滤器,具体操作在运行时确定。此外,我们的目标是在这个解决方案中保持尽可能多的通用性。
我们的管道需要封装了一个堆分配的 Iterator trait 对象:
rust
struct PipelineBuilder<'a, T> {
iter: Box<dyn Iterator<Item = T> + 'a>
}为了处理迭代器大小事先未知且根据运行时输入而变化的情况,我们必须使用 Box。Box 允许我们为迭代器分配堆内存,从而克服了在编译时需要知道其大小的限制。此外,在这种情况下,控制生命周期至关重要,以确保迭代器引用的数据在其预期使用期间保持有效。使用 Box<dyn Iterator<Item=T> + 'a> 既可以动态调度到适当的迭代器方法,又可以显式管理生命周期,确保迭代器及其引用在整个使用过程中都是有效的。
管道最初使用 new 函数参数中提供的迭代器来构建:
rust
impl<'a, T: 'a> PipelineBuilder<'a, T> {
fn new(iter: impl Iterator<Item = T> + 'a) -> Self {
Self {
iter: Box::new(iter)
}
}
}通过明确要求元素和迭代器具有相同的生命周期,我们创建了一个通用的解决方案,既能迭代拥有所有权的元素,也能迭代引用。
现在我们可以从不同的源构建管道。例如,我们可以从文件中的行开始:
rust
let file = File::open("Cargo.toml").unwrap();
let lines = BufReader::new(file).lines().map(Result::unwrap);
let pipeline= PipelineBuilder::new(lines);或者从一系列整数构建的迭代器开始:
rust
let mut pipeline = PipelineBuilder::new((1..10).into_iter());添加过滤器或映射需要更改 PipelineBuilder::iter 结构体成员的值。为了避免所有权问题,每次添加过滤器或映射时,我们都将返回一个新的构建器。
rust
impl<'a, T: 'a> PipelineBuilder<'a, T> {
fn with_filter(self, cond: impl FnMut(&T) -> bool + 'a) -> Self {
Self {
iter: Box::new(self.iter.filter(cond))
}
}
fn with_map<S>(self, f: impl FnMut(T) -> S + 'a) -> PipelineBuilder<'a, S> {
PipelineBuilder {
iter: Box::new(self.iter.map(f))
}
}
}with_filter 和 with_map 方法都会返回一个新的 builder 构建器,将之前的 iter 迭代器包含在新添加的迭代器之前。这种方法使我们能够在需要时添加一个新的处理阶段。由于 with_map 方法可以改变管道内元素的类型,因此我们必须显式地引用类型名称------注意看该函数的返回,它不再是 Self 类型。
现在我们可以轻松地操作管道了。例如,对于来自文件的行:
rust
let pipeline = if random() {
pipeline.with_filter(|s| s.len() > 5 )
} else {
pipeline.with_map(|s| format!("{s}!"))
}.with_map(|s| s.len());根据运行时获得的随机值,我们的管道要么包含一个过滤器和一个映射,要么包含两个连续的映射。由于在此处应用了最后一个映射,原来的 PipelineBuilder<String> 被转换为 PipelineBuilder<usize>。
为了完成这个实现,我们需要考虑如何使用管道中的迭代器。让我们通过实现方便的 for_each 方法来继续:
rust
impl<'a, T: 'a> PipelineBuilder<'a, T> {
fn for_each(self, f: impl FnMut(T) -> () + 'a) {
self.iter.for_each(f)
}
}for_each 方法不返回任何值。由于它获取了 self 的所有权,在调用该方法后管道构建器将被释放。该方法可以按以下方式使用:
rust
pipeline.for_each(|s| {
print!("{s} ")
});此处调用之后,pipeline 将不再可用。
回到管道构建器的第二个示例(使用来自某个范围的整数的示例),我们的 PipelineBuilder 允许我们以完全不可预测的结果来处理数据:
rust
let cnt = random::<usize>().rem(10);
for i in 0..cnt {
pipeline = pipeline.with_map(move |x| x + i)
}
pipeline
.with_filter(|x| x.rem(2) == 0)
.for_each(|x| print!("{x} "));给出一开始任务的完整示例代码:
rust
let numbers: Vec<i32> = vec![1, 2, 3, 4, 5];
let it: Iter<i32> = numbers.iter();
let mut pipline = PipelineBuilder::new(it);
let needs_filtering: bool = random(); // 这里需要 rand lib。
if needs_filtering {
pipline = pipline.with_filter(|x: &&i32| x.rem(2) == 0);
}
pipline.for_each(|x| print!("{} ", x));Impl trait 与 dyn trait
理解 impl traits 和 dyn trait 对象之间的区别至关重要。
impl traits 通过将各个阶段提取到函数中,用于拆分冗长的调用链;而 dyn trait 对象则用于将迭代器存储为结构体成员。
Trait 对象允许将方法调度延迟到运行时,从而可以使用在编译时类型未知的迭代器。虽然 impl trait 类型有助于隐藏复杂的迭代器类型,但它们要求在编译时就知道类型。例如,不允许将 impl Iterator 用作某个函数的返回类型,因为该函数可能根据输入返回 filter 或 map 迭代器,它们的类型不同。在这种情况下,需要使用 dyn trait 对象来适应返回类型的可变性。这种方法为动态迭代器操作提供了所需的灵活性,确保能与各种运行时条件兼容。
有读者认为使用迭代器比使用显式循环慢。
然而,很难找到证据来支持这一说法。如果你在迭代器管道中途避免使用 collect,那么 Rust 编译器会确保生成的优化代码与显式循环实现相比没有显著差异。这体现了 Rust 迭代器设计的效率,以及编译器将基于迭代器的代码优化到与传统循环结构性能相当的能力。
这里我有几个功能相同的函数:
rust
#[no_mangle]
fn add_even_sum(numbers: &Vec<i32>, a: i32) -> i32 {
numbers.iter()
.map(|x| x + a)
.filter(|&x| x > 2)
.sum()
}
#[no_mangle]
fn add_even_sum_loop(numbers: &Vec<i32>, a: i32) -> i32 {
let mut sum = 0;
for x in numbers {
let x = x + a;
if x > 2 {
sum += x
}
}
sum
}迭代器方法更简洁、更清晰,也更易于理解。此外,对生成代码的比较也没有显示出效率低下的迹象(不信的话各位可以测试一下看看)。
如果你有兴趣深入比较汇编代码,那么最好从基础学起。
在迭代器及其性能方面,建议调试步骤如下:
- 编写注重可读性的迭代代码:首先,专注于使用迭代器编写可读性强的代码,要认识到在某些情况下,显式循环可能更为合适。
- 进行基准测试并监控性能:使用基准测试工具,或者监控性能和内存使用指标,以便了解你的代码在实际运行中的表现。
- 必要时进行性能分析:如果检测到性能问题,对代码进行性能分析以确定问题所在。确保问题确实是由迭代器的使用导致的。
- 重新审视归约/折叠结构:如果你发现与迭代器相关的性能瓶颈,检查在归约/折叠操作中使用的结构。迭代过程中传递的大型结构可能是问题的根源。在这种情况下,选择可变结构来维护中间状态可能会有所帮助。
- 向Rust编译器报告问题:如果其他方法都失败了,那么恭喜你,你真的找到了一个 Bug,可以向 Rust 编译器或标准库团队提交问题,寻求进一步的帮助。
需要注意的是,这里并没有将"用显式循环重写代码"列为一个步骤。不能仅仅因为性能问题就放弃使用迭代器。然而,不可否认的是,某些数据源本身提供的迭代器效率可能较低。在这种情况下,要么自己尝试创建更高效的迭代器,要么采用不依赖迭代器的实现方式。
总结
由于 Rust 在所有权、类型系统和效率方面采用独特的处理方式,其迭代器范式可能会被认为具有挑战性。在 Rust 中,迭代器可以遍历引用、可变引用或自有值,标准库提供了各种迭代器方法来高效处理集合和其他数据源。Rust 注重避免在迭代器中进行隐式堆分配,这促使人们在进行更复杂的操作时使用像 itertools 这样的库。
然而,当迭代器链变得很长或嵌套很深时,代码的可读性可能会受到影响,这意味着需要通过提取函数或引入类型来进行重构。尽管存在对性能的担忧,但 Rust 高效的编译器优化通常能确保结构良好的基于迭代器的代码与传统循环结构的性能相当,强调代码的可读性和可维护性比过早进行优化更为重要。
最后:千万不要认为显示的 for 循环比迭代器快!