第09讲:案例实战:面对突如其来的GC问题如何下手解决
本课时我们主要从一个实战案例入手分析面对突如其来的 GC 问题该如何下手解决。
想要下手解决 GC 问题,我们首先需要掌握下面这三种问题。
- 如何使用 jstat 命令查看 JVM 的 GC 情况?
- 面对海量 GC 日志参数,如何快速抓住问题根源?
- 你不得不掌握的日志分析工具。
工欲善其事,必先利其器。我们前面课时讲到的优化手段,包括代码优化、扩容、参数优化,甚至我们的估算,都需要一些支撑信息加以判断。
对于 JVM 来说,一种情况是 GC 时间过长,会影响用户的体验,这个时候就需要调整某些 JVM 参数、观察日志。
另外一种情况就比较严重了,发生了 OOM,或者操作系统的内存溢出。服务直接宕机,我们要寻找背后的原因。
这时,GC 日志能够帮我们找到问题的根源。本课时,我们就简要介绍一下如何输出这些日志,以及如何使用这些日志的支撑工具解决问题。
GC 日志输出
你可能感受到,最近几年 Java 的版本更新速度是很快的,JVM 的参数配置其实变化也很大。就拿 GC 日志这一块来说,Java 9 几乎是推翻重来。网络上的一些文章,把这些参数写的乱七八糟,根本不能投入生产。如果你碰到不能被识别的参数,先确认一下自己的 Java 版本。
在事故出现的时候,通常并不是那么温柔。你可能在半夜里就能接到报警电话,这是因为很多定时任务都设定在夜深人静的时候执行。
这个时候,再去看 jstat 已经来不及了,我们需要保留现场。这个便是看门狗的工作,看门狗可以通过设置一些 JVM 参数进行配置。
那在实践中,要怎么用呢?请看下面命令行。
Java 8
我们先看一下 JDK8 中的使用。
bash
#!/bin/sh
LOG_DIR="/tmp/logs"
JAVA_OPT_LOG=" -verbose:gc"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDetails"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCDateStamps"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintGCApplicationStoppedTime"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -XX:+PrintTenuringDistribution"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xloggc:${LOG_DIR}/gc_%p.log"
JAVA_OPT_OOM=" -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOG_DIR} -XX:ErrorFile=${LOG_DIR}/hs_error_pid%p.log "
JAVA_OPT="${JAVA_OPT_LOG} ${JAVA_OPT_OOM}"
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"合成一行。
bash
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps
-XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution
-Xloggc:/tmp/logs/gc_%p.log -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
-XX:-OmitStackTraceInFastThrow然后我们来解释一下这些参数:
| 参数 | 意义 |
|---|---|
| -verbose:gc | 打印 GC 日志 |
| PrintGCDetails | 打印详细 GC 日志 |
| PrintGCDateStamps | 系统时间,更加可读,PrintGCTimeStamps 是 JVM 启动时间 |
| PrintGCApplicationStoppedTime | 打印 STW 时间 |
| PrintTenuringDistribution | 打印对象年龄分布,对调优 MaxTenuringThreshold 参数帮助很大 |
| loggc | 将以上 GC 内容输出到文件中 |
再来看下 OOM 时的参数:
| 参数 | 意义 |
|---|---|
| HeapDumpOnOutOfMemoryError | OOM 时 Dump 信息,非常有用 |
| HeapDumpPath | Dump 文件保存路径 |
| ErrorFile | 错误日志存放路径 |
注意到我们还设置了一个参数 OmitStackTraceInFastThrow,这是 JVM 用来缩简日志输出的。
开启这个参数之后,如果你多次发生了空指针异常,将会打印以下信息。
undefined
java.lang.NullPointerException
java.lang.NullPointerException
java.lang.NullPointerException
java.lang.NullPointerException在实际生产中,这个参数是默认开启的,这样就导致有时候排查问题非常不方便(很多研发对此无能为力),我们这里把它关闭,但这样它会输出所有的异常堆栈,日志会多很多。
Java 13
再看下 JDK 13 中的使用。
从 Java 9 开始,移除了 40 多个 GC 日志相关的参数。具体参见 JEP 158。所以这部分的日志配置有很大的变化。
我们同样看一下它的生成脚本。
bash
#!/bin/sh
LOG_DIR="/tmp/logs"
JAVA_OPT_LOG=" -verbose:gc"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file=${LOG_DIR}/gc_%p.log:tags,uptime,time,level"
JAVA_OPT_LOG="${JAVA_OPT_LOG} -Xlog:safepoint:file=${LOG_DIR}/safepoint_%p.log:tags,uptime,time,level"
JAVA_OPT_OOM=" -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${LOG_DIR} -XX:ErrorFile=${LOG_DIR}/hs_error_pid%p.log "
JAVA_OPT="${JAVA_OPT_LOG} ${JAVA_OPT_OOM}"
JAVA_OPT="${JAVA_OPT} -XX:-OmitStackTraceInFastThrow"
echo $JAVA_OPT合成一行展示。
bash
-verbose:gc -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file
=/tmp/logs/gc_%p.log:tags,uptime,time,level -Xlog:safepoint:file=/tmp
/logs/safepoint_%p.log:tags,uptime,time,level -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log
-XX:-OmitStackTraceInFastThrow可以看到 GC 日志的打印方式,已经完全不一样,但是比以前的日志参数规整了许多。
我们除了输出 GC 日志,还输出了 safepoint 的日志。这个日志对我们分析问题也很重要,那什么叫 safepoint 呢?
safepoint 是 JVM 中非常重要的一个概念,指的是可以安全地暂停线程的点。
当发生 GC 时,用户线程必须全部停下来,才可以进行垃圾回收,这个状态我们可以认为 JVM 是安全的(safe),整个堆的状态是稳定的。

如果在 GC 前,有线程迟迟进入不了 safepoint,那么整个 JVM 都在等待这个阻塞的线程,会造成了整体 GC 的时间变长。
所以呢,并不是只有 GC 会挂起 JVM,进入 safepoint 的过程也会。这个概念,如果你有兴趣可以自行深挖一下,一般是不会出问题的。
如果面试官问起你在项目中都使用了哪些打印 GC 日志的参数,上面这些信息肯定是不很好记忆。你需要进行以下总结。比如:
"我一般在项目中输出详细的 GC 日志,并加上可读性强的 GC 日志的时间戳。特别情况下我还会追加一些反映对象晋升情况和堆详细信息的日志,用来排查问题。另外,OOM 时自动 Dump 堆栈,我一般也会进行配置"。
GC 日志的意义
我们首先看一段日志,然后简要看一下各个阶段的意义。
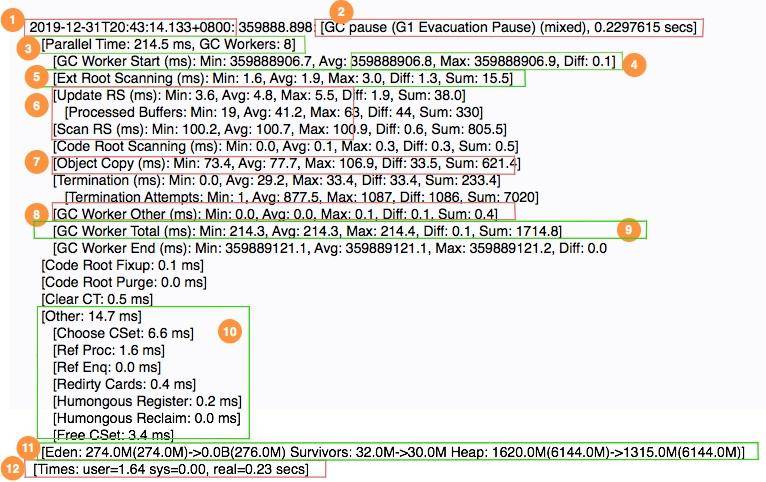
- 1 表示 GC 发生的时间,一般使用可读的方式打印;
- 2 表示日志表明是 G1 的"转移暂停: 混合模式",停顿了约 223ms;
- 3 表明由 8 个 Worker 线程并行执行,消耗了 214ms;
- 4 表示 Diff 越小越好,说明每个工作线程的速度都很均匀;
- 5 表示外部根区扫描,外部根是堆外区。JNI 引用,JVM 系统目录,Classloaders 等;
- 6 表示更新 RSet 的时间信息;
- 7 表示该任务主要是对 CSet 中存活对象进行转移(复制);
- 8 表示花在 GC 之外的工作线程的时间;
- 9 表示并行阶段的 GC 总时间;
- 10 表示其他清理活动;
- 11表示收集结果统计;
- 12 表示时间花费统计。
可以看到 GC 日志描述了垃圾回收器过程中的几乎每一个阶段。但即使你了解了这些数值的意义,在分析问题时,也会感到吃力,我们一般使用图形化的分析工具进行分析。
尤其注意的是最后一行日志,需要详细描述。可以看到 G C花费的时间,竟然有 3 个数值。这个数值你可能在多个地方见过。如果你手头有 Linux 机器,可以执行以下命令:
time ls /
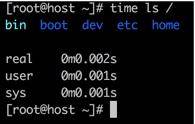
可以看到一段命令的执行,同样有三种纬度的时间统计。接下来解释一下这三个字段的意思。
- real 实际花费的时间,指的是从开始到结束所花费的时间。比如进程在等待 I/O 完成,这个阻塞时间也会被计算在内;
- user 指的是进程在用户态(User Mode)所花费的时间,只统计本进程所使用的时间,注意是指多核;
- sys 指的是进程在核心态(Kernel Mode)花费的 CPU 时间量,指的是内核中的系统调用所花费的时间,只统计本进程所使用的时间。
在上面的 GC 日志中,real < user + sys,因为我们使用了多核进行垃圾收集,所以实际发生的时间比 (user + sys) 少很多。在多核机器上,这很常见。
Times: user=1.64 sys=0.00, real=0.23 secs
下面是一个串行垃圾收集器收集的 GC 时间的示例。由于串行垃圾收集器始终仅使用一个线程,因此实际使用的时间等于用户和系统时间的总和:
Times: user=0.29 sys=0.00, real=0.29 secs
那我们统计 GC 以哪个时间为准呢?一般来说,用户只关心系统停顿了多少秒,对实际的影响时间非常感兴趣。至于背后是怎么实现的,是多核还是单核,是用户态还是内核态,它们都不关心。所以我们直接使用 real 字段。
GC日志可视化
肉眼可见的这些日志信息,让人非常头晕,尤其是日志文件特别大的时候。所幸现在有一些在线分析平台,可以帮助我们分析这个过程。下面我们拿常用的 gceasy 来看一下。
以下是一个使用了 G1 垃圾回收器,堆内存为 6GB 的服务,运行 5 天的 GC 日志。
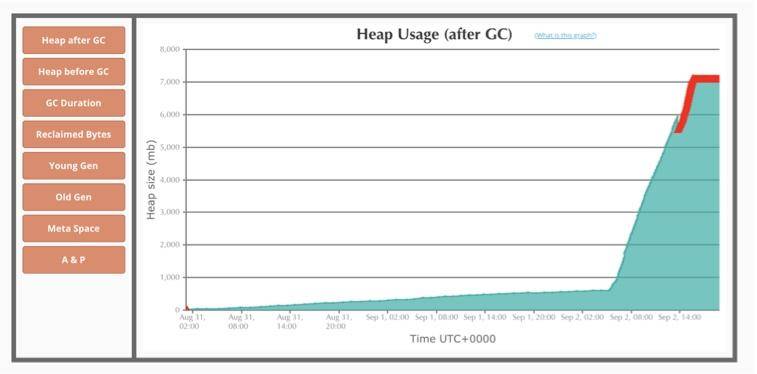
(1)堆信息
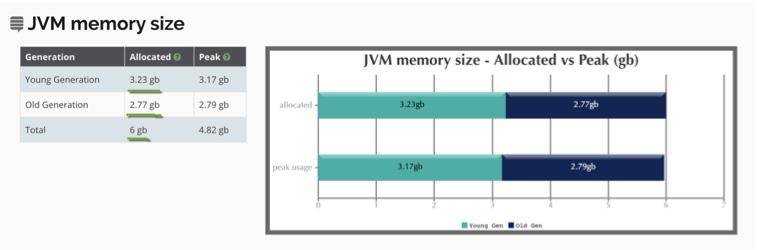
我们可以从图中看到堆的使用情况。
(2)关键信息
从图中我们可以看到一些性能的关键信息。
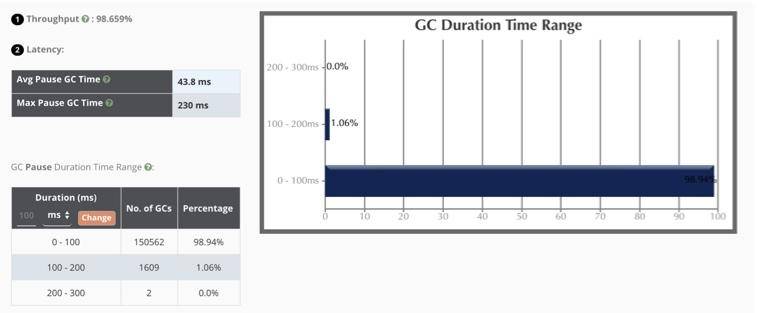
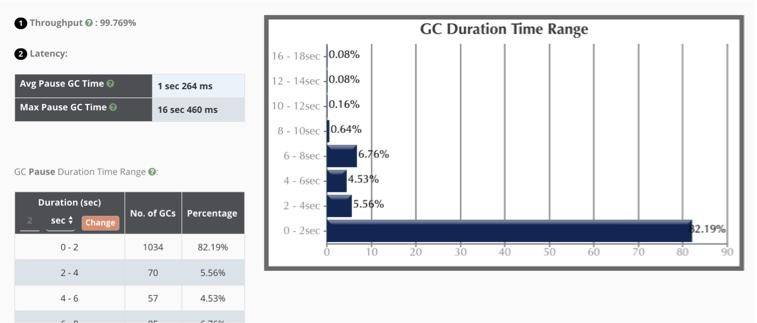
吞吐量:98.6%(一般超过 95% 就 ok 了);
最大延迟:230ms,平均延迟:42.8ms;
延迟要看服务的接受程度,比如 SLA 定义 50ms 返回数据,上面的最大延迟就会有一点问题。本服务接近 99% 的停顿在 100ms 以下,可以说算是非常优秀了。
你在看这些信息的时候,一定要结合宿主服务器的监控去看。比如 GC 发生期间,CPU 会突然出现尖锋,就证明 GC 对 CPU 资源使用的有点多。但多数情况下,如果吞吐量和延迟在可接受的范围内,这些对 CPU 的超额使用是可以忍受的。
(3)交互式图表
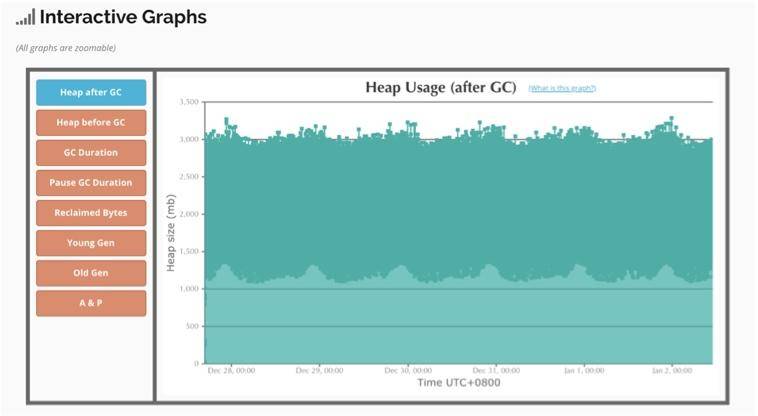
可以对有问题的区域进行放大查看,图中表示垃圾回收后的空间释放,可以看到效果是比较好的。
(4)G1 的时间耗时
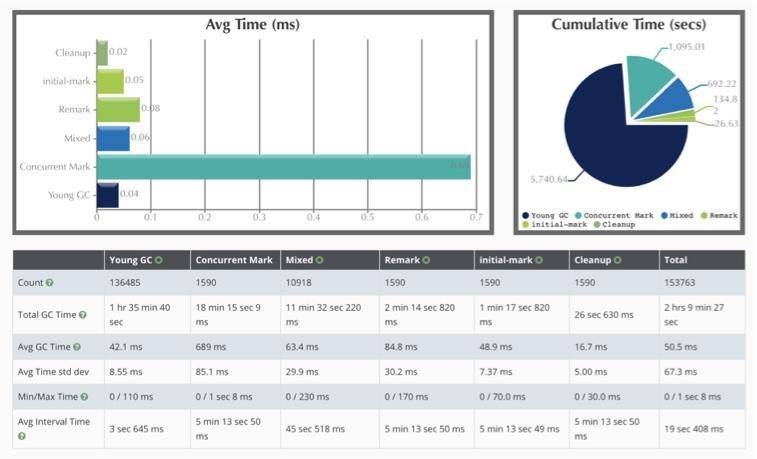
如图展示了 GC 的每个阶段花费的时间。可以看到平均耗时最长的阶段,就是 Concurrent Mark 阶段,但由于是并发的,影响并不大。随着时间的推移,YoungGC 竟然达到了 136485 次。运行 5 天,光花在 GC 上的时间就有 2 个多小时,还是比较可观的。
(5)其他
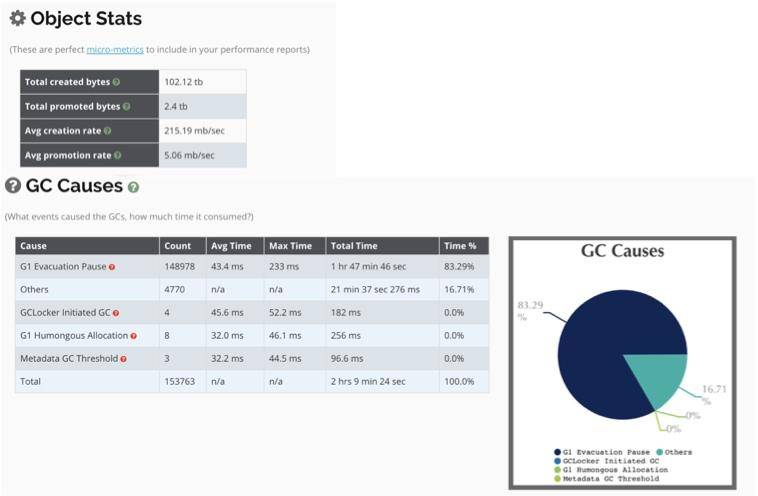
如图所示,整个 JVM 创建了 100 多 T 的数据,其中有 2.4TB 被 promoted 到老年代。
另外,还有一些 safepoint 的信息等,你可以自行探索。
那到底什么样的数据才是有问题的呢?gceasy 提供了几个案例。比如下面这个就是停顿时间明显超长的 GC 问题。
下面这个是典型的内存泄漏。
上面这些问题都是非常明显的。但大多数情况下,问题是偶发的。从基本的衡量指标,就能考量到整体的服务水准。如果这些都没有问题,就要看曲线的尖峰。
一般来说,任何不平滑的曲线,都是值得怀疑的,那就需要看一下当时的业务情况具体是什么样子的。是用户请求突增引起的,还是执行了一个批量的定时任务,再或者查询了大批量的数据,这要和一些服务的监控一起看才能定位出根本问题。
只靠 GC 来定位问题是比较困难的,我们只需要知道它有问题就可以了。后面,会介绍更多的支持工具进行问题的排解。
为了方便你调试使用,我在 GitHub 上上传了两个 GC 日志。其中 gc01.tar.gz 就是我们现在正在看的,解压后有 200 多兆;另外一个 gc02.tar.gz 是一个堆空间为 1GB 的日志文件,你也可以下载下来体验一下。
GitHub 地址:
另外,GCViewer 这个工具也是常用的,可以下载到本地,以 jar 包的方式运行。
在一些极端情况下,也可以使用脚本简单过滤一下。比如下面行命令,就是筛选停顿超过 100ms 的 GC 日志和它的行数(G1)。
## grep -n real gc.log | awk -F"=| " '{ if($8>0.1){ print }}'
1975: [Times: user=2.03 sys=0.93, real=0.75 secs]
2915: [Times: user=1.82 sys=0.65, real=0.64 secs]
16492: [Times: user=0.47 sys=0.89, real=0.35 secs]
16627: [Times: user=0.71 sys=0.76, real=0.39 secs]
16801: [Times: user=1.41 sys=0.48, real=0.49 secs]
17045: [Times: user=0.35 sys=1.25, real=0.41 secs]jstat
上面的可视化工具,必须经历导出、上传、分析三个阶段,这种速度太慢了。有没有可以实时看堆内存的工具?
你可能会第一时间想到 jstat 命令。第一次接触这个命令,我也是很迷惑的,主要是输出的字段太多,不了解什么意义。
但其实了解我们在前几节课时所讲到内存区域划分和堆划分之后,再看这些名词就非常简单了。
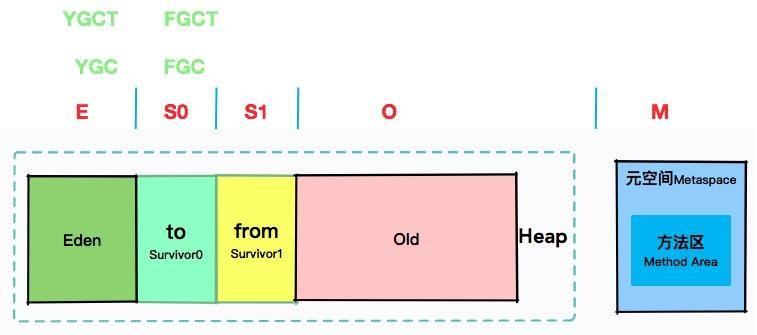
我们拿 -gcutil 参数来说明一下。
jstat -gcutil $pid 1000
只需要提供一个 Java 进程的 ID,然后指定间隔时间(毫秒)就 OK 了。
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 0.00 72.03 0.35 54.12 55.72 11122 16.019 0 0.000 16.019
0.00 0.00 95.39 0.35 54.12 55.72 11123 16.024 0 0.000 16.024
0.00 0.00 25.32 0.35 54.12 55.72 11125 16.025 0 0.000 16.025
0.00 0.00 37.00 0.35 54.12 55.72 11126 16.028 0 0.000 16.028
0.00 0.00 60.35 0.35 54.12 55.72 11127 16.028 0 0.000 16.028可以看到,E 其实是 Eden 的缩写,S0 对应的是 Surivor0,S1 对应的是 Surivor1,O 代表的是 Old,而 M 代表的是 Metaspace。
YGC 代表的是年轻代的回收次数,YGC T对应的是年轻代的回收耗时。那么 FGC 肯定代表的是 Full GC 的次数。
你在看日志的时候,一定要注意其中的规律。-gcutil 位置的参数可以有很多种。我们最常用的有 gc、gcutil、gccause、gcnew 等,其他的了解一下即可。
- gc: 显示和 GC 相关的 堆信息;
- gcutil: 显示 垃圾回收信息;
- gccause: 显示垃圾回收 的相关信息(同 -gcutil),同时显示 最后一次 或 当前 正在发生的垃圾回收的 诱因;
- gcnew: 显示 新生代 信息;
- gccapacity: 显示 各个代 的 容量 以及 使用情况;
- gcmetacapacity: 显示 元空间 metaspace 的大小;
- gcnewcapacity: 显示 新生代大小 和 使用情况;
- gcold: 显示 老年代 和 永久代 的信息;
- gcoldcapacity: 显示 老年代 的大小;
- printcompilation: 输出 JIT 编译 的方法信息;
- class: 显示 类加载 ClassLoader 的相关信息;
- compiler: 显示 JIT 编译 的相关信息;
如果 GC 问题特别明显,通过 jstat 可以快速发现。我们在启动命令行中加上参数 -t,可以输出从程序启动到现在的时间。如果 FGC 和启动时间的比值太大,就证明系统的吞吐量比较小,GC 花费的时间太多了。另外,如果老年代在 Full GC 之后,没有明显的下降,那可能内存已经达到了瓶颈,或者有内存泄漏问题。
下面这行命令,就追加了 GC 时间的增量和 GC 时间比率两列。
jstat -gcutil -t 90542 1000 | awk 'BEGIN{pre=0}{if(NR>1) {print $0 "\t" ($12-pre) "\t" $12*100/$1 ; pre=$12 } else { print $0 "\tGCT_INC\tRate"} }'
Timestamp S0 S1 E O M CCS YGC YGCT FGC FGCT GCT GCT_INC Rate
18.7 0.00 100.00 6.02 1.45 84.81 76.09 1 0.002 0 0.000 0.002 0.002 0.0106952
19.7 0.00 100.00 6.02 1.45 84.81 76.09 1 0.002 0 0.000 0.002 0 0.0101523GC 日志也会搞鬼
顺便给你介绍一个实际发生的故障。
你知道 ElasticSearch 的速度是非常快的,我们为了压榨它的性能,对磁盘的读写几乎是全速的。它在后台做了很多 Merge 动作,将小块的索引合并成大块的索引。还有 TransLog 等预写动作,都是 I/O 大户。
使用 iostat -x 1 可以看到具体的 I/O 使用状况。
问题是,我们有一套 ES 集群,在访问高峰时,有多个 ES 节点发生了严重的 STW 问题。有的节点竟停顿了足足有 7~8 秒。
Times: user=0.42 sys=0.03, real=7.62 secs
从日志可以看到在 GC 时用户态只停顿了 420ms,但真实的停顿时间却有 7.62 秒。
盘点一下资源,唯一超额利用的可能就是 I/O 资源了(%util 保持在 90 以上),GC 可能在等待 I/O。
通过搜索,发现已经有人出现过这个问题,这里直接说原因和结果。
原因就在于,写 GC 日志的 write 动作,是统计在 STW 的时间里的。在我们的场景中,由于 ES 的索引数据,和 GC 日志放在了一个磁盘,GC 时写日志的动作,就和写数据文件的动作产生了资源争用。
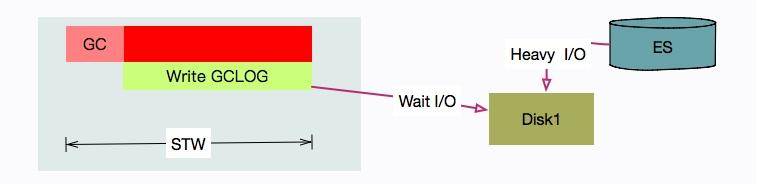
解决方式也是比较容易的,把 ES 的日志文件,单独放在一块普通 HDD 磁盘上就可以了。
小结
本课时,我们主要介绍了比较重要的 GC 日志,以及怎么输出它,并简要的介绍了一段 G1 日志的意义。对于这些日志的信息,能够帮助我们理解整个 GC 的过程,专门去记忆它投入和产出并不成正比,可以多看下 G1 垃圾回收器原理方面的东西。
接下来我们介绍了几个图形化分析 GC 的工具,这也是现在主流的使用方式,因为动辄几百 MB 的 GC 日志,是无法肉眼分辨的。如果机器的 I/O 问题很突出,就要考虑把 GC 日志移动到单独的磁盘。
我们尤其介绍了在线分析工具 gceasy,你也可以下载 gcviewer 的 jar 包本地体验一下。
最后我们看了一个命令行的 GC 回收工具 jstat,它的格式比较规整,可以重定向到一个日志文件里,后续使用 sed、awk 等工具进行分析。关于相关的两个命令,可以参考我以前写的两篇文章。
第10讲:动手实践:自己模拟JVM内存溢出场景
本课时我们主要自己模拟一个 JVM 内存溢出的场景。在模拟 JVM 内存溢出之前我们先来看下这样的几个问题。
- 老年代溢出为什么那么可怕?
- 元空间也有溢出?怎么优化?
- 如何配置栈大小?避免栈溢出?
- 进程突然死掉,没有留下任何信息时如何进行排查?
年轻代由于有老年代的担保,一般在内存占满的时候,并没什么问题。但老年代满了就比较严重了,它没有其他的空间用来做担保,只能 OOM 了,也就是发生 Out Of Memery Error。JVM 会在这种情况下直接停止工作,是非常严重的后果。
OOM 一般是内存泄漏引起的,表现在 GC 日志里,一般情况下就是 GC 的时间变长了,而且每次回收的效果都非常一般。GC 后,堆内存的实际占用呈上升趋势。接下来,我们将模拟三种溢出场景,同时使用我们了解的工具进行观测。
在开始之前,请你下载并安装一个叫作 VisualVM 的工具,我们使用这个图形化的工具看一下溢出过程。
虽然 VisualVM 工具非常好用,但一般生产环境都没有这样的条件,所以大概率使用不了。新版本 JDK 把这个工具单独抽离了出去,需要自行下载。
这里需要注意下载安装完成之后请在插件选项中勾选 Visual GC 下载,它将可视化内存布局。
堆溢出模拟
首先,我们模拟堆溢出的情况,在模拟之前我们需要准备一份测试代码。这份代码开放了一个 HTTP 接口,当你触发它之后,将每秒钟生成 1MB 的数据。由于它和 GC Roots 的强关联性,每次都不能被回收。
程序通过 JMX,将在每一秒创建数据之后,输出一些内存区域的占用情况。然后通过访问 http://localhost:8888 触发后,它将一直运行,直到堆溢出。
java
import com.sun.net.httpserver.HttpContext;
import com.sun.net.httpserver.HttpExchange;
import com.sun.net.httpserver.HttpServer;
import java.io.OutputStream;
import java.lang.management.ManagementFactory;
import java.lang.management.MemoryPoolMXBean;
import java.net.InetSocketAddress;
import java.util.ArrayList;
import java.util.List;
public class OOMTest {
public static final int _1MB = 1024 * 1024;
static List<byte[]> byteList = new ArrayList<>();
private static void oom(HttpExchange exchange) {
try {
String response = "oom begin!";
exchange.sendResponseHeaders(200, response.getBytes().length);
OutputStream os = exchange.getResponseBody();
os.write(response.getBytes());
os.close();
} catch (Exception ex) {
}
for (int i = 0; ; i++) {
byte[] bytes = new byte[_1MB];
byteList.add(bytes);
System.out.println(i + "MB");
memPrint();
try {
Thread.sleep(1000);
} catch (Exception e) {
}
}
}
static void memPrint() {
for (MemoryPoolMXBean memoryPoolMXBean : ManagementFactory.getMemoryPoolMXBeans()) {
System.out.println(memoryPoolMXBean.getName() + " committed:" + memoryPoolMXBean.getUsage().getCommitted() + " used:" + memoryPoolMXBean.getUsage().getUsed());
}
}
private static void srv() throws Exception {
HttpServer server = HttpServer.create(new InetSocketAddress(8888), 0);
HttpContext context = server.createContext("/");
context.setHandler(OOMTest::oom);
server.start();
}
public static void main(String[] args) throws Exception {
srv();
}
}我们使用 CMS 收集器进行垃圾回收,可以看到如下的信息。
命令:
java -Xmx20m -Xmn4m -XX:+UseConcMarkSweepGC -verbose:gc -Xlog:gc,
gc+ref=debug,gc+heap=debug,
gc+age=trace:file=/tmp/logs/gc_%p.log:tags,
uptime,
time,
level -Xlog:safepoint:file=/tmp/logs/safepoint_%p.log:tags,
uptime,
time,
level -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log -XX:-OmitStackTraceInFastThrow OOMTest输出:
[0.025s][info][gc] Using Concurrent Mark Sweep
0MB
CodeHeap 'non-nmethods' committed:2555904 used:1120512
Metaspace committed:4980736 used:854432
CodeHeap 'profiled nmethods' committed:2555904 used:265728
Compressed Class Space committed:524288 used:96184
Par Eden Space committed:3407872 used:2490984
Par Survivor Space committed:393216 used:0
CodeHeap 'non-profiled nmethods' committed:2555904 used:78592
CMS Old Gen committed:16777216 used:0
...省略
[16.377s][info][gc] GC(9) Concurrent Mark 1.592ms
[16.377s][info][gc] GC(9) Concurrent Preclean
[16.378s][info][gc] GC(9) Concurrent Preclean 0.721ms
[16.378s][info][gc] GC(9) Concurrent Abortable Preclean
[16.378s][info][gc] GC(9) Concurrent Abortable Preclean 0.006ms
[16.378s][info][gc] GC(9) Pause Remark 17M->17M(19M) 0.344ms
[16.378s][info][gc] GC(9) Concurrent Sweep
[16.378s][info][gc] GC(9) Concurrent Sweep 0.248ms
[16.378s][info][gc] GC(9) Concurrent Reset
[16.378s][info][gc] GC(9) Concurrent Reset 0.013ms
17MB
CodeHeap 'non-nmethods' committed:2555904 used:1120512
Metaspace committed:4980736 used:883760
CodeHeap 'profiled nmethods' committed:2555904 used:422016
Compressed Class Space committed:524288 used:92432
Par Eden Space committed:3407872 used:3213392
Par Survivor Space committed:393216 used:0
CodeHeap 'non-profiled nmethods' committed:2555904 used:88064
CMS Old Gen committed:16777216 used:16452312
[18.380s][info][gc] GC(10) Pause Initial Mark 18M->18M(19M) 0.187ms
[18.380s][info][gc] GC(10) Concurrent Mark
[18.384s][info][gc] GC(11) Pause Young (Allocation Failure) 18M->18M(19M) 0.186ms
[18.386s][info][gc] GC(10) Concurrent Mark 5.435ms
[18.395s][info][gc] GC(12) Pause Full (Allocation Failure) 18M->18M(19M) 10.572ms
[18.400s][info][gc] GC(13) Pause Full (Allocation Failure) 18M->18M(19M) 5.348ms
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at OldOOM.main(OldOOM.java:20)最后 JVM 在一阵疯狂的 GC 日志输出后,进程停止了。在现实情况中,JVM 在停止工作之前,很多会垂死挣扎一段时间,这个时候,GC 线程会造成 CPU 飙升,但其实它已经不能工作了。
VisualVM 的截图展示了这个溢出结果。可以看到 Eden 区刚开始还是运行平稳的,内存泄漏之后就开始疯狂回收(其实是提升),老年代内存一直增长,直到 OOM。
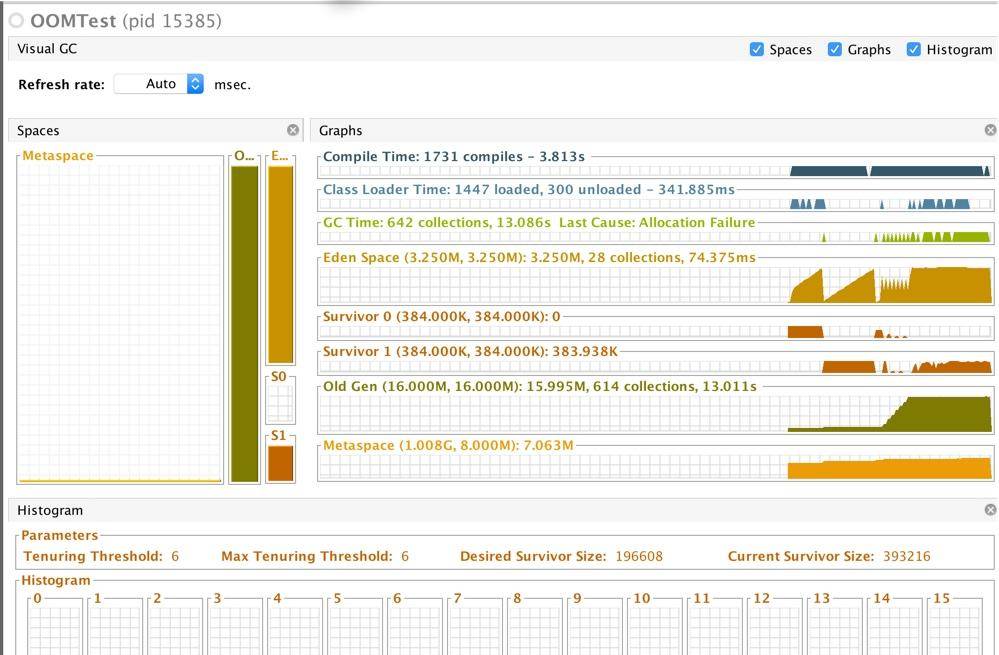
很多参数会影响对象的分配行为,但不是非常必要,我们一般不去调整它们。为了观察这些参数的默认值,我们通常使用 -XX:+PrintFlagsFinal 参数,输出一些设置信息。
命令:
# java -XX:+PrintFlagsFinal 2>&1 | grep SurvivorRatio
uintx SurvivorRatio = 8 {product} {default}Java13 输出了几百个参数和默认值,我们通过修改一些参数来观测一些不同的行为。
NewRatio 默认值为 2,表示年轻代是老年代的 1/2。追加参数 "-XX:NewRatio=1",可以把年轻代和老年代的空间大小调成一样大。在实践中,我们一般使用 -Xmn 来设置一个固定值。注意,这两个参数不要用在 G1 垃圾回收器中。
SurvivorRatio 默认值为 8。表示伊甸区和幸存区的比例。在上面的例子中,Eden 的内存大小为:0.8*4MB。S 分区不到 1MB,根本存不下我们的 1MB 数据。
MaxTenuringThreshold 这个值在 CMS 下默认为 6,G1 下默认为 15。这是因为 G1 存在动态阈值计算。这个值和我们前面提到的对象提升有关,如果你想要对象尽量长的时间存在于年轻代,则在 CMS 中,可以把它调整到 15。
java -XX:+PrintFlagsFinal -XX:+UseConcMarkSweepGC 2>&1 | grep MaxTenuringThreshold
java -XX:+PrintFlagsFinal -XX:+UseG1GC 2>&1 | grep MaxTenuringThreshold
PretenureSizeThreshold 这个参数默认值是 0,意味着所有的对象年轻代优先分配。我们把这个值调小一点,再观测 JVM 的行为。追加参数 -XX:PretenureSizeThreshold=1024,可以看到 VisualVm 中老年代的区域增长。
TargetSurvivorRatio 默认值为 50。在动态计算对象提升阈值的时候使用。计算时,会从年龄最小的对象开始累加,如果累加的对象大小大于幸存区的一半,则将当前的对象 age 作为新的阈值,年龄大于此阈值的对象直接进入老年代。工作中不建议调整这个值,如果要调,请调成比 50 大的值。
你可以尝试着更改其他参数,比如垃圾回收器的种类,动态看一下效果。尤其注意每一项内存区域的内容变动,你会对垃圾回收器有更好的理解。
UseAdaptiveSizePolicy ,因为它和 CMS 不兼容,所以 CMS 下默认为 false,但 G1 下默认为 true。这是一个非常智能的参数,它是用来自适应调整空间大小的参数。它会在每次 GC 之后,重新计算 Eden、From、To 的大小。很多人在 Java 8 的一些配置中会见到这个参数,但其实在 CMS 和 G1 中是不需要显式设置的。
值的注意的是,Java 8 默认垃圾回收器是 Parallel Scavenge,它的这个参数是默认开启的,有可能会发生把幸存区自动调小的可能,造成一些问题,显式的设置 SurvivorRatio 可以解决这个问题。
下面这张截图,是切换到 G1 之后的效果。
java -Xmx20m -XX:+UseG1GC -verbose:gc -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file=/tmp/logs/gc*%p.log:tags,uptime,time,level -Xlog:safepoint:file=/tmp/logs/safepoint*%p.log:tags,uptime,time,level -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log -XX:-OmitStackTraceInFastThrow OOMTest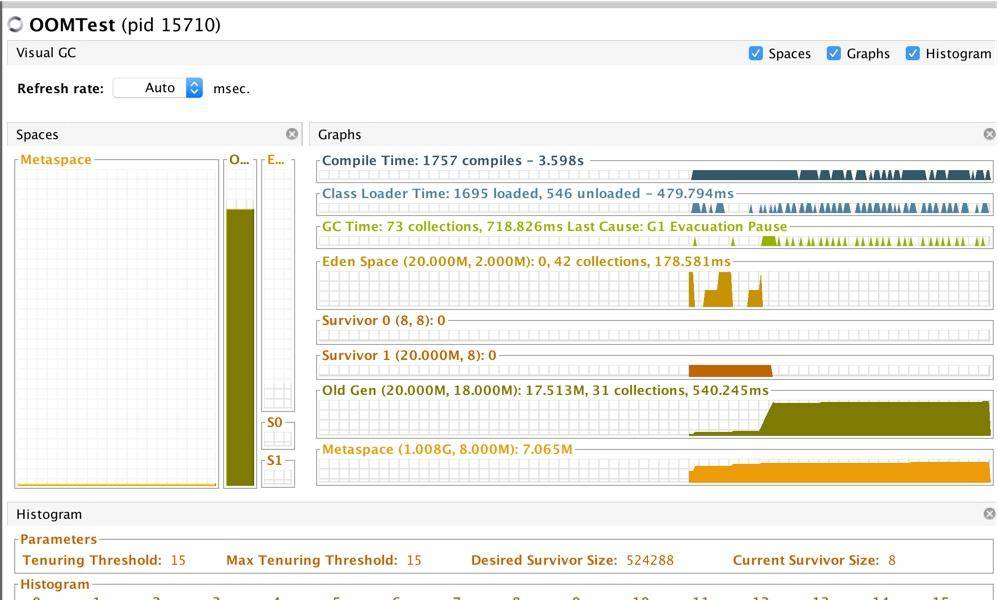
可以通过下面这个命令调整小堆区的大小,来看一下这个过程。
-XX:G1HeapRegionSize=M元空间溢出
堆一般都是指定大小的,但元空间不是。所以如果元空间发生内存溢出会更加严重,会造成操作系统的内存溢出。我们在使用的时候,也会给它设置一个上限 for safe。
元空间溢出主要是由于加载的类太多,或者动态生成的类太多。下面是一段模拟代码。通过访问 http://localhost:8888 触发后,它将会发生元空间溢出。
java
import com.sun.net.httpserver.HttpContext;
import com.sun.net.httpserver.HttpExchange;
import com.sun.net.httpserver.HttpServer;
import java.io.OutputStream;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.net.InetSocketAddress;
import java.net.URL;
import java.net.URLClassLoader;
import java.util.HashMap;
import java.util.Map;
public class MetaspaceOOMTest {
public interface Facade {
void m(String input);
}
public static class FacadeImpl implements Facade {
@Override
public void m(String name) {
}
}
public static class MetaspaceFacadeInvocationHandler implements InvocationHandler {
private Object impl;
public MetaspaceFacadeInvocationHandler(Object impl) {
this.impl = impl;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return method.invoke(impl, args);
}
}
private static Map<String, Facade> classLeakingMap = new HashMap<String, Facade>();
private static void oom(HttpExchange exchange) {
try {
String response = "oom begin!";
exchange.sendResponseHeaders(200, response.getBytes().length);
OutputStream os = exchange.getResponseBody();
os.write(response.getBytes());
os.close();
} catch (Exception ex) {
}
try {
for (int i = 0; ; i++) {
String jar = "file:" + i + ".jar";
URL[] urls = new URL[]{new URL(jar)};
URLClassLoader newClassLoader = new URLClassLoader(urls);
Facade t = (Facade) Proxy.newProxyInstance(newClassLoader, new Class<?>[]{Facade.class}, new MetaspaceFacadeInvocationHandler(new FacadeImpl()));
classLeakingMap.put(jar, t);
}
} catch (Exception e) {
}
}
private static void srv() throws Exception {
HttpServer server = HttpServer.create(new InetSocketAddress(8888), 0);
HttpContext context = server.createContext("/");
context.setHandler(MetaspaceOOMTest::oom);
server.start();
}
public static void main(String[] args) throws Exception {
srv();
}
}这段代码将使用 Java 自带的动态代理类,不断的生成新的 class。
java -Xmx20m -Xmn4m -XX:+UseG1GC -verbose:gc -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file=/tmp/logs/gc*%p.log:tags,uptime,time,level -Xlog:safepoint:file=/tmp/logs/safepoint*%p.log:tags,uptime,time,level -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log -XX:-OmitStackTraceInFastThrow -XX:MetaspaceSize=16M -XX:MaxMetaspaceSize=16M MetaspaceOOMTest我们在启动的时候,限制 Metaspace 空间大小为 16MB。可以看到运行一小会之后,Metaspace 会发生内存溢出。
[6.509s][info][gc] GC(28) Pause Young (Concurrent Start) (Metadata GC Threshold) 9M->9M(20M) 1.186ms
[6.509s][info][gc] GC(30) Concurrent Cycle
[6.534s][info][gc] GC(29) Pause Full (Metadata GC Threshold) 9M->9M(20M) 25.165ms
[6.556s][info][gc] GC(31) Pause Full (Metadata GC Clear Soft References) 9M->9M(20M) 21.136ms
[6.556s][info][gc] GC(30) Concurrent Cycle 46.668ms
java.lang.OutOfMemoryError: Metaspace
Dumping heap to /tmp/logs/java_pid36723.hprof ...
Heap dump file created [17362313 bytes in 0.134 secs]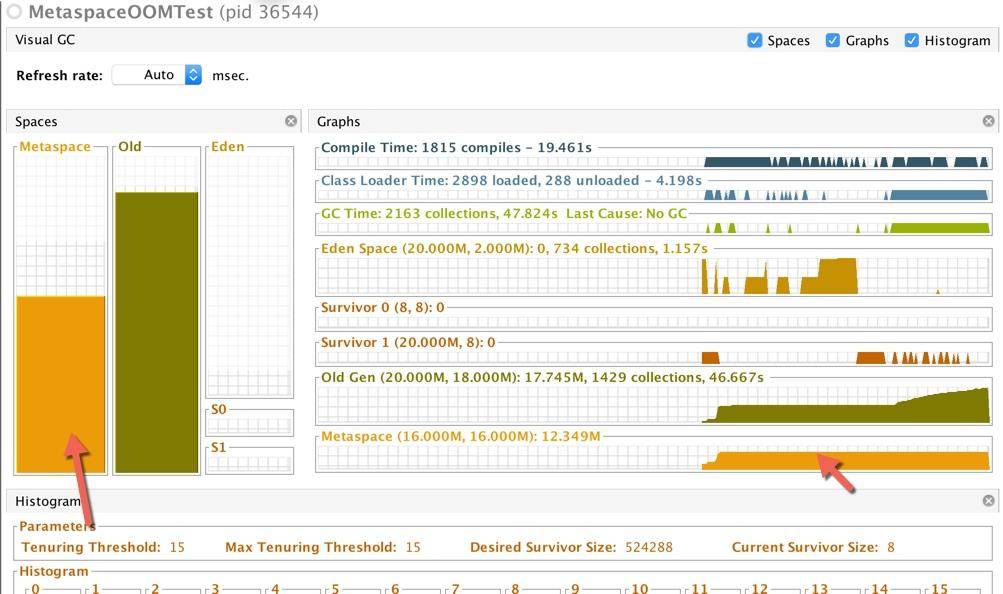
但假如你把堆 Metaspace 的限制给去掉,会更可怕。它占用的内存会一直增长。
堆外内存溢出
严格来说,上面的 Metaspace 也是属于堆外内存的。但是我们这里的堆外内存指的是 Java 应用程序通过直接方式从操作系统中申请的内存。所以严格来说,这里是指直接内存。
程序将通过 ByteBuffer 的 allocateDirect 方法每 1 秒钟申请 1MB 的直接内存。不要忘了通过链接触发这个过程。
但是,使用 VisualVM 看不到这个过程,使用 JMX 的 API 同样也看不到。关于这部分内容,我们将在堆外内存排查课时进行详细介绍。
java
import com.sun.net.httpserver.HttpContext;
import com.sun.net.httpserver.HttpExchange;
import com.sun.net.httpserver.HttpServer;
import java.io.OutputStream;
import java.lang.management.ManagementFactory;
import java.lang.management.MemoryPoolMXBean;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.List;
public class OffHeapOOMTest {
public static final int _1MB = 1024 * 1024;
static List<ByteBuffer> byteList = new ArrayList<>();
private static void oom(HttpExchange exchange) {
try {
String response = "oom begin!";
exchange.sendResponseHeaders(200, response.getBytes().length);
OutputStream os = exchange.getResponseBody();
os.write(response.getBytes());
os.close();
} catch (Exception ex) {
}
for (int i = 0; ; i++) {
ByteBuffer buffer = ByteBuffer.allocateDirect(_1MB);
byteList.add(buffer);
System.out.println(i + "MB");
memPrint();
try {
Thread.sleep(1000);
} catch (Exception e) {
}
}
}
private static void srv() throws Exception {
HttpServer server = HttpServer.create(new InetSocketAddress(8888), 0);
HttpContext context = server.createContext("/");
context.setHandler(OffHeapOOMTest::oom);
server.start();
}
public static void main(String[] args) throws Exception {
srv();
}
static void memPrint() {
for (MemoryPoolMXBean memoryPoolMXBean : ManagementFactory.getMemoryPoolMXBeans()) {
System.out.println(memoryPoolMXBean.getName() + " committed:" + memoryPoolMXBean.getUsage().getCommitted() + " used:" + memoryPoolMXBean.getUsage().getUsed());
}
}
}通过 top 或者操作系统的监控工具,能够看到内存占用的明显增长。为了限制这些危险的内存申请,如果你确定在自己的程序中用到了大量的 JNI 和 JNA 操作,要显式的设置 MaxDirectMemorySize 参数。
以下是程序运行一段时间抛出的错误。
Exception in thread "Thread-2" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:694)
at java.nio.DirectByteBuffer.(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at OffHeapOOMTest.oom(OffHeapOOMTest.java:27)
at com.sun.net.httpserver.Filter$Chain.doFilter(Filter.java:79)
at sun.net.httpserver.AuthFilter.doFilter(AuthFilter.java:83)
at com.sun.net.httpserver.Filter$Chain.doFilter(Filter.java:82)
at sun.net.httpserver.ServerImpl\(Exchange\)LinkHandler.handle(ServerImpl.java:675)
at com.sun.net.httpserver.Filter$Chain.doFilter(Filter.java:79)
at sun.net.httpserver.ServerImpl$Exchange.run(ServerImpl.java:647)
at sun.net.httpserver.ServerImpl$DefaultExecutor.execute(ServerImpl.java:158)
at sun.net.httpserver.ServerImpl$Dispatcher.handle(ServerImpl.java:431)
at sun.net.httpserver.ServerImpl$Dispatcher.run(ServerImpl.java:396)
at java.lang.Thread.run(Thread.java:748)启动命令。
java -XX:MaxDirectMemorySize=10M -Xmx10M OffHeapOOMTest栈溢出
还记得我们的虚拟机栈么?栈溢出指的就是这里的数据太多造成的泄漏。通过 -Xss 参数可以设置它的大小。比如下面的命令就是设置栈大小为 128K。
-Xss128K从这里我们也能了解到,由于每个线程都有一个虚拟机栈。线程的开销也是要占用内存的。如果系统中的线程数量过多,那么占用内存的大小也是非常可观的。
栈溢出不会造成 JVM 进程死亡,危害"相对较小"。下面是一个简单的模拟栈溢出的代码,只需要递归调用就可以了。
java
public class StackOverflowTest {
static int count = 0;
static void a() {
System.out.println(count);
count++;
b();
}
static void b() {
System.out.println(count);
count++;
a();
}
public static void main(String[] args) throws Exception {
a();
}
}运行后,程序直接报错。
Exception in thread "main" java.lang.StackOverflowError
at java.io.PrintStream.write(PrintStream.java:526)
at java.io.PrintStream.print(PrintStream.java:597)
at java.io.PrintStream.println(PrintStream.java:736)
at StackOverflowTest.a(StackOverflowTest.java:5)如果你的应用经常发生这种情况,可以试着调大这个值。但一般都是因为程序错误引起的,最好检查一下自己的代码。
进程异常退出
上面这几种溢出场景,都有明确的原因和报错,排查起来也是非常容易的。但是还有一类应用,死亡的时候,静悄悄的,什么都没留下。
以下问题已经不止一个同学问了:我的 Java 进程没了,什么都没留下,直接蒸发不见了
why?是因为对象太多了么?
这是趣味性和技巧性非常突出的一个问题。让我们执行 dmesg 命令,大概率会看到你的进程崩溃信息躺在那里。
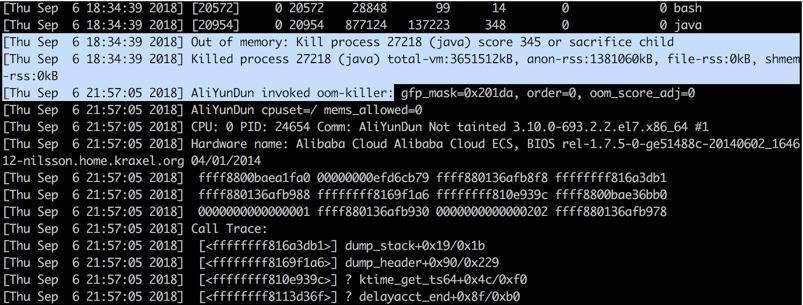
为了能看到发生的时间,我们习惯性加上参数 T(dmesg -T)。
这个现象,其实和 Linux 的内存管理有关。由于 Linux 系统采用的是虚拟内存分配方式,JVM 的代码、库、堆和栈的使用都会消耗内存,但是申请出来的内存,只要没真正 access过,是不算的,因为没有真正为之分配物理页面。
随着使用内存越用越多。第一层防护墙就是 SWAP;当 SWAP 也用的差不多了,会尝试释放 cache;当这两者资源都耗尽,杀手就出现了。oom-killer 会在系统内存耗尽的情况下跳出来,选择性的干掉一些进程以求释放一点内存。
所以这时候我们的 Java 进程,是操作系统"主动"终结的,JVM 连发表遗言的机会都没有。这个信息,只能在操作系统日志里查找。
要解决这种问题,首先不能太贪婪。比如一共 8GB 的机器,你把整整 7.5GB 都分配给了 JVM。当操作系统内存不足时,你的 JVM 就可能成为 oom-killer 的猎物。
相对于被动终结,还有一种主动求死的方式。有些同学,会在程序里面做一些判断,直接调用 System.exit() 函数。
这个函数危险得很,它将强制终止我们的应用,而且什么都不会留下。你应该扫描你的代码,确保这样的逻辑不会存在。
再聊一种最初级最常见还经常发生的,会造成应用程序意外死亡的情况,那就是对 Java 程序错误的启动方式。
很多同学对 Linux 不是很熟悉,使用 XShell 登陆之后,调用下面的命令进行启动。
java com.cn.AA &这样调用还算有点意识,在最后使用了"&"号,以期望进程在后台运行。但可惜的是,很多情况下,随着 XShell Tab 页的关闭,或者等待超时,后面的 Java 进程就随着一块停止了,很让人困惑。
正确的启动方式,就是使用 nohup 关键字,或者阻塞在其他更加长命的进程里(比如docker)。
nohup java com.cn.AA &进程这种静悄悄的死亡方式,通常会给我们的问题排查带来更多的困难。
在发生问题时,要确保留下了足够的证据,来支持接下来的分析。不能喊一句"出事啦",然后就陷入无从下手的尴尬境地。
通常,我们在关闭服务的时候,会使用"kill -15",而不是"kill -9",以便让服务在临死之前喘口气。信号9和15的区别,是面试经常问的一个问题,也是一种非常有效的手段。
小结
本课时我们简单模拟了堆、元空间、栈的溢出。并使用 VisualVM 观察了这个过程。
接下来,我们了解到进程静悄悄消失的三种情况。如果你的应用也这样消失过,试着这样找找它。这三种情况也是一个故障排查流程中要考虑的环节,属于非常重要的边缘检查点。相信聪明的你,会将这些情况揉进自己的面试体系去,真正成为自己的实战经验。
第11讲:动手实践:遇到问题不要慌,轻松搞定内存泄漏
当一个系统在发生 OOM 的时候,行为可能会让你感到非常困惑。因为 JVM 是运行在操作系统之上的,操作系统的一些限制,会严重影响 JVM 的行为。故障排查是一个综合性的技术问题,在日常工作中要增加自己的知识广度。多总结、多思考、多记录,这才是正确的晋级方式。
现在的互联网服务,一般都做了负载均衡。如果一个实例发生了问题,不要着急去重启。万能的重启会暂时缓解问题,但如果不保留现场,可能就错失了解决问题的根本,担心的事情还会到来。
所以,当实例发生问题的时候,第一步是隔离,第二步才是问题排查。什么叫隔离呢?就是把你的这台机器从请求列表里摘除,比如把 nginx 相关的权重设成零。在微服务中,也有相应的隔离机制,这里默认你已经有了(面试也默认你已经有隔离功能了)。
本课时的内容将涉及非常多的 Linux 命令,对 JVM 故障排查的帮助非常大,你可以逐个击破。
1. GC 引起 CPU 飙升
我们有个线上应用,单节点在运行一段时间后,CPU 的使用会飙升,一旦飙升,一般怀疑某个业务逻辑的计算量太大,或者是触发了死循环(比如著名的 HashMap 高并发引起的死循环),但排查到最后其实是 GC 的问题。
在 Linux 上,分析哪个线程引起的 CPU 问题,通常有一个固定的步骤。我们下面来分解这个过程,这是面试频率极高的一个问题 。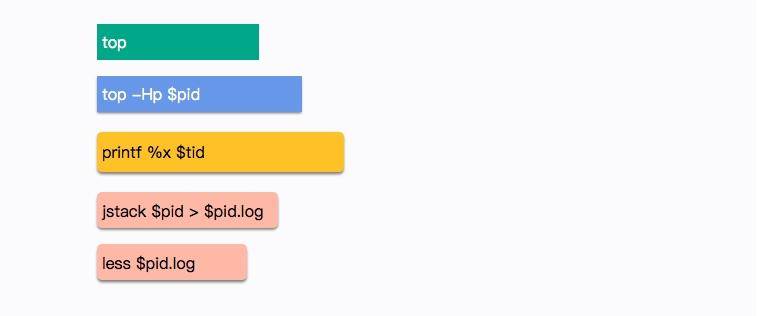
(1)使用 top 命令,查找到使用 CPU 最多的某个进程,记录它的 pid。使用 Shift + P 快捷键可以按 CPU 的使用率进行排序。
bash
top(2)再次使用 top 命令,加 -H 参数,查看某个进程中使用 CPU 最多的某个线程,记录线程的 ID。
bash
top -Hp $pid(3)使用 printf 函数,将十进制的 tid 转化成十六进制。
perl
printf %x $tid(4)使用 jstack 命令,查看 Java 进程的线程栈。
bash
jstack $pid >$pid.log(5)使用 less 命令查看生成的文件,并查找刚才转化的十六进制 tid,找到发生问题的线程上下文。
bash
less $pid.log我们在 jstack 日志中找到了 CPU 使用最多的几个线程。
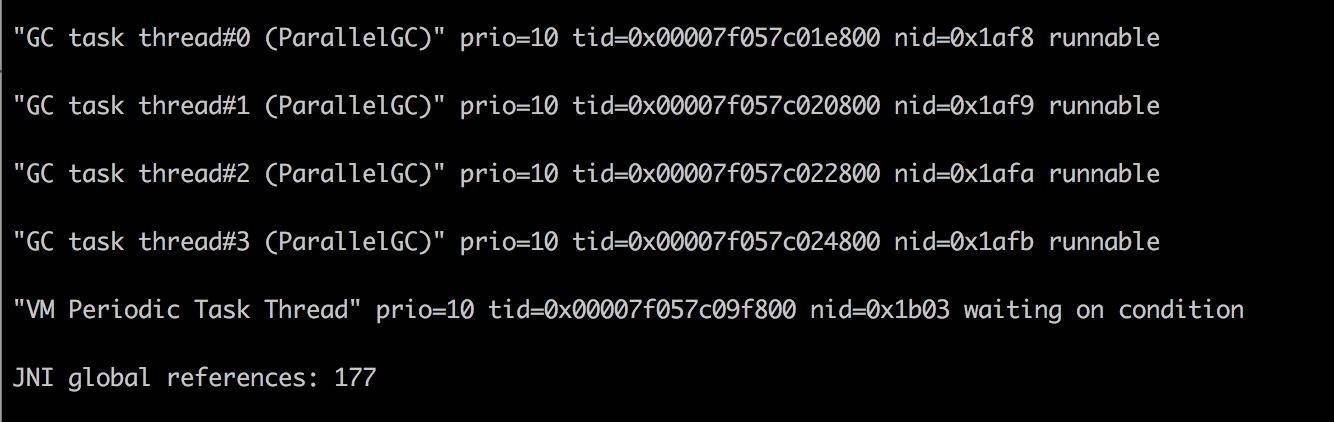
可以看到问题发生的根源,是我们的堆已经满了,但是又没有发生 OOM,于是 GC 进程就一直在那里回收,回收的效果又非常一般,造成 CPU 升高应用假死。
接下来的具体问题排查,就需要把内存 dump 一份下来,使用 MAT 等工具分析具体原因了(将在第 12 课时讲解)。
2. 现场保留
可以看到这个过程是繁杂而冗长的,需要记忆很多内容。现场保留可以使用自动化方式将必要的信息保存下来,那一般在线上系统会保留哪些信息呢?下面我进行一下总结。
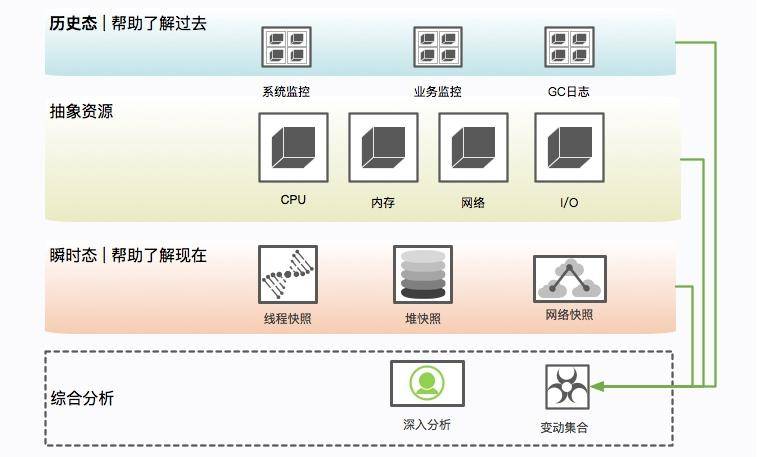
2.1. 瞬时态和历史态
为了协助我们的分析,这里创造了两个名词:瞬时态和历史态。瞬时态是指当时发生的、快照类型的元素;历史态是指按照频率抓取的,有固定监控项的资源变动图。
有很多信息,比如 CPU、系统内存等,瞬时态的价值就不如历史态来的直观一些。因为瞬时状态无法体现一个趋势性问题(比如斜率、求导等),而这些信息的获取一般依靠监控系统的协作。
但对于 lsof、heap 等,这种没有时间序列概念的混杂信息,体积都比较大,无法进入监控系统产生有用价值,就只能通过瞬时态进行分析。在这种情况下,瞬时态的价值反而更大一些。我们常见的堆快照,就属于瞬时状态。
问题不是凭空产生的,在分析时,一般要收集系统的整体变更集合,比如代码变更、网络变更,甚至数据量的变化。
接下来对每一项资源的获取方式进行介绍。
2.2. 保留信息
(1)系统当前网络连接
bash
ss -antp > $DUMP_DIR/ss.dump 2>&1其中,ss 命令将系统的所有网络连接输出到 ss.dump 文件中。使用 ss 命令而不是 netstat 的原因,是因为 netstat 在网络连接非常多的情况下,执行非常缓慢。
后续的处理,可通过查看各种网络连接状态的梳理,来排查 TIME_WAIT 或者 CLOSE_WAIT,或者其他连接过高的问题,非常有用。
线上有个系统更新之后,监控到 CLOSE_WAIT 的状态突增,最后整个 JVM 都无法响应。CLOSE_WAIT 状态的产生一般都是代码问题,使用 jstack 最终定位到是因为 HttpClient 的不当使用而引起的,多个连接不完全主动关闭。
(2)网络状态统计
bash
netstat -s > $DUMP_DIR/netstat-s.dump 2>&1此命令将网络统计状态输出到 netstat-s.dump 文件中。它能够按照各个协议进行统计输出,对把握当时整个网络状态,有非常大的作用。
bash
sar -n DEV 1 2 > $DUMP_DIR/sar-traffic.dump 2>&1上面这个命令,会使用 sar 输出当前的网络流量。在一些速度非常高的模块上,比如 Redis、Kafka,就经常发生跑满网卡的情况。如果你的 Java 程序和它们在一起运行,资源则会被挤占,表现形式就是网络通信非常缓慢。
(3)进程资源
bash
lsof -p $PID > $DUMP_DIR/lsof-$PID.dump这是个非常强大的命令,通过查看进程,能看到打开了哪些文件,这是一个神器,可以以进程的维度来查看整个资源的使用情况,包括每条网络连接、每个打开的文件句柄。同时,也可以很容易的看到连接到了哪些服务器、使用了哪些资源。这个命令在资源非常多的情况下,输出稍慢,请耐心等待。
(4)CPU 资源
bash
mpstat > $DUMP_DIR/mpstat.dump 2>&1
vmstat 1 3 > $DUMP_DIR/vmstat.dump 2>&1
sar -p ALL > $DUMP_DIR/sar-cpu.dump 2>&1
uptime > $DUMP_DIR/uptime.dump 2>&1主要用于输出当前系统的 CPU 和负载,便于事后排查。这几个命令的功能,有不少重合,使用者要注意甄别。
(5)I/O 资源
bash
iostat -x > $DUMP_DIR/iostat.dump 2>&1一般,以计算为主的服务节点,I/O 资源会比较正常,但有时也会发生问题,比如日志输出过多,或者磁盘问题等。此命令可以输出每块磁盘的基本性能信息,用来排查 I/O 问题。在第 8 课时介绍的 GC 日志分磁盘问题,就可以使用这个命令去发现。
(6)内存问题
bash
free -h > $DUMP_DIR/free.dump 2>&1free 命令能够大体展现操作系统的内存概况,这是故障排查中一个非常重要的点,比如 SWAP 影响了 GC,SLAB 区挤占了 JVM 的内存。
(7)其他全局
bash
ps -ef > $DUMP_DIR/ps.dump 2>&1
dmesg > $DUMP_DIR/dmesg.dump 2>&1
sysctl -a > $DUMP_DIR/sysctl.dump 2>&1dmesg 是许多静悄悄死掉的服务留下的最后一点线索。当然,ps 作为执行频率最高的一个命令,它当时的输出信息,也必然有一些可以参考的价值。
另外,由于内核的配置参数,会对系统和 JVM 产生影响,所以我们也输出了一份。
(8)进程快照,最后的遗言(jinfo)
bash
${JDK_BIN}jinfo $PID > $DUMP_DIR/jinfo.dump 2>&1此命令将输出 Java 的基本进程信息,包括环境变量和参数配置,可以查看是否因为一些错误的配置造成了 JVM 问题。
(9)dump 堆信息
bash
${JDK_BIN}jstat -gcutil $PID > $DUMP_DIR/jstat-gcutil.dump 2>&1
${JDK_BIN}jstat -gccapacity $PID > $DUMP_DIR/jstat-gccapacity.dump 2>&1jstat 将输出当前的 gc 信息。一般,基本能大体看出一个端倪,如果不能,可将借助 jmap 来进行分析。
(10)堆信息
bash
${JDK_BIN}jmap $PID > $DUMP_DIR/jmap.dump 2>&1
${JDK_BIN}jmap -heap $PID > $DUMP_DIR/jmap-heap.dump 2>&1
${JDK_BIN}jmap -histo $PID > $DUMP_DIR/jmap-histo.dump 2>&1
${JDK_BIN}jmap -dump:format=b,file=$DUMP_DIR/heap.bin $PID > /dev/null 2>&1jmap 将会得到当前 Java 进程的 dump 信息。如上所示,其实最有用的就是第 4 个命令,但是前面三个能够让你初步对系统概况进行大体判断。
因为,第 4 个命令产生的文件,一般都非常的大。而且,需要下载下来,导入 MAT 这样的工具进行深入分析,才能获取结果。这是分析内存泄漏一个必经的过程。
(11)JVM 执行栈
bash
${JDK_BIN}jstack $PID > $DUMP_DIR/jstack.dump 2>&1jstack 将会获取当时的执行栈。一般会多次取值,我们这里取一次即可。这些信息非常有用,能够还原 Java 进程中的线程情况。
bash
top -Hp $PID -b -n 1 -c > $DUMP_DIR/top-$PID.dump 2>&1为了能够得到更加精细的信息,我们使用 top 命令,来获取进程中所有线程的 CPU 信息,这样,就可以看到资源到底耗费在什么地方了。
(12)高级替补
bash
kill -3 $PID有时候,jstack 并不能够运行,有很多原因,比如 Java 进程几乎不响应了等之类的情况。我们会尝试向进程发送 kill -3 信号,这个信号将会打印 jstack 的 trace 信息到日志文件中,是 jstack 的一个替补方案。
bash
gcore -o $DUMP_DIR/core $PID对于 jmap 无法执行的问题,也有替补,那就是 GDB 组件中的 gcore,将会生成一个 core 文件。我们可以使用如下的命令去生成 dump:
bash
${JDK_BIN}jhsdb jmap --exe ${JDK}java --core $DUMP_DIR/core --binaryheap3. 内存泄漏的现象
稍微提一下 jmap 命令,它在 9 版本里被干掉了,取而代之的是 jhsdb,你可以像下面的命令一样使用。
bash
jhsdb jmap --heap --pid 37340
jhsdb jmap --pid 37288
jhsdb jmap --histo --pid 37340
jhsdb jmap --binaryheap --pid 37340heap 参数能够帮我们看到大体的内存布局,以及每一个年代中的内存使用情况。这和我们前面介绍的内存布局,以及在 VisualVM 中看到的 没有什么不同。但由于它是命令行,所以使用更加广泛。
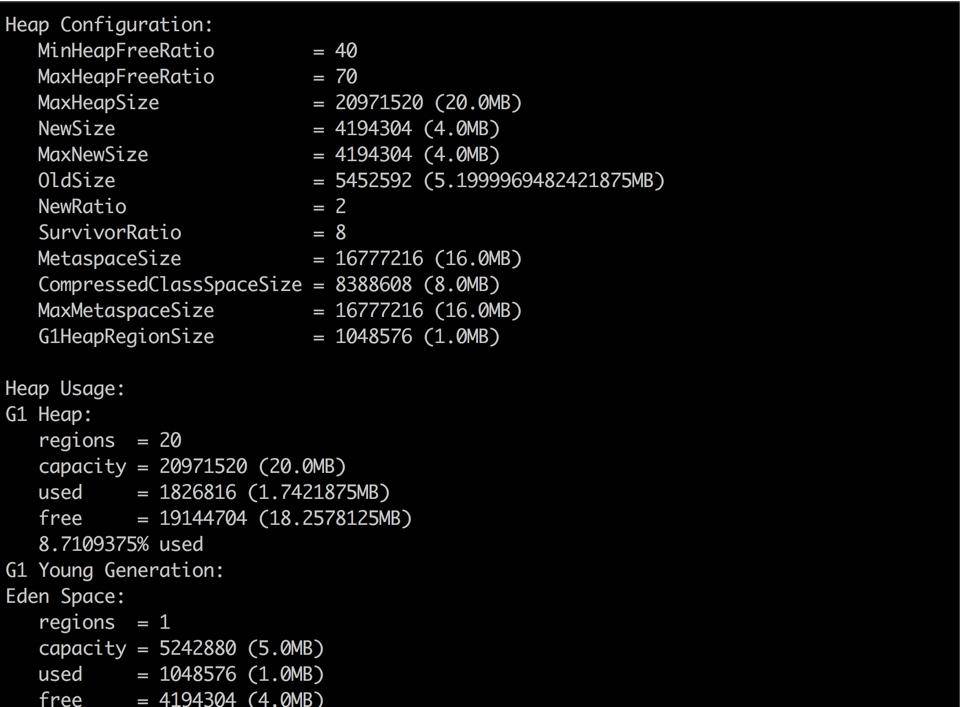
histo 能够大概的看到系统中每一种类型占用的空间大小,用于初步判断问题。比如某个对象 instances 数量很小,但占用的空间很大,这就说明存在大对象。但它也只能看大概的问题,要找到具体原因,还是要 dump 出当前 live 的对象。
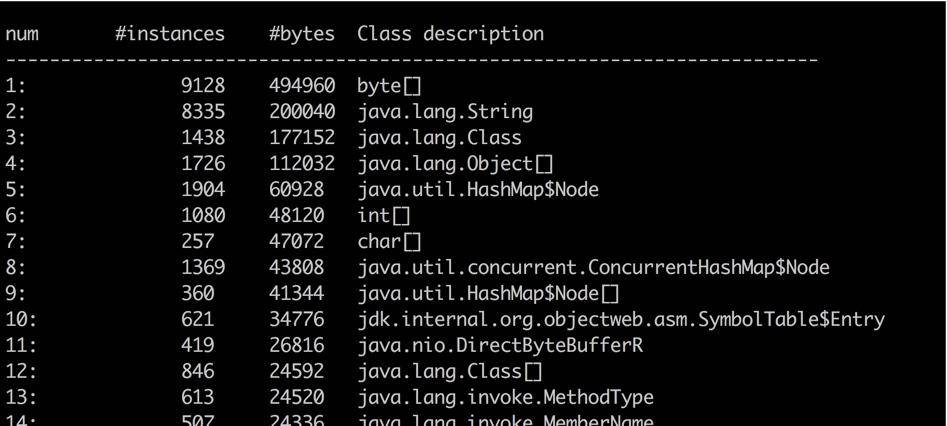
一般内存溢出,表现形式就是 Old 区的占用持续上升,即使经过了多轮 GC 也没有明显改善。我们在前面提到了 GC Roots,内存泄漏的根本就是,有些对象并没有切断和 GC Roots 的关系,可通过一些工具,能够看到它们的联系。
4. 一个卡顿实例
有一个关于服务的某个实例,经常发生服务卡顿。由于服务的并发量是比较高的,所以表现也非常明显。这个服务和我们第 8 课时的高并发服务类似,每多停顿 1 秒钟,几万用户的请求就会感到延迟。
我们统计、类比了此服务其他实例的 CPU、内存、网络、I/O 资源,区别并不是很大,所以一度怀疑是机器硬件的问题。
接下来我们对比了节点的 GC 日志,发现无论是 Minor GC,还是 Major GC,这个节点所花费的时间,都比其他实例长得多。
通过仔细观察,我们发现在 GC 发生的时候,vmstat 的 si、so 飙升的非常严重,这和其他实例有着明显的不同。
使用 free 命令再次确认,发现 SWAP 分区,使用的比例非常高,引起的具体原因是什么呢?
更详细的操作系统内存分布,从 /proc/meminfo 文件中可以看到具体的逻辑内存块大小,有多达 40 项的内存信息,这些信息都可以通过遍历 /proc 目录的一些文件获取。我们注意到 slabtop 命令显示的有一些异常,dentry(目录高速缓冲)占用非常高。
问题最终定位到是由于某个运维工程师执行了一句命令:
bash
find / | grep "x"他是想找一个叫做 x 的文件,看看在哪台服务器上,结果,这些老服务器由于文件太多,扫描后这些文件信息都缓存到了 slab 区上。而服务器开了 swap,操作系统发现物理内存占满后,并没有立即释放 cache,导致每次 GC 都要和硬盘打一次交道。
解决方式就是关闭 SWAP 分区。
swap 是很多性能场景的万恶之源,建议禁用 。当你的应用真正高并发了,SWAP 绝对能让你体验到它魔鬼性的一面:进程倒是死不了了,但 GC 时间长的却让人无法忍受。
5. 内存泄漏
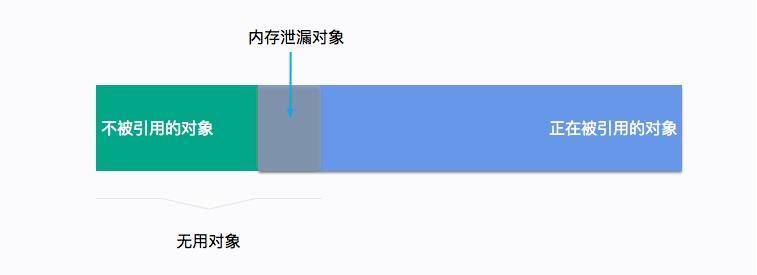
我们再来聊一下内存溢出和内存泄漏的区别。
内存溢出是一个结果,而内存泄漏是一个原因。内存溢出的原因有内存空间不足、配置错误等因素。
不再被使用的对象、没有被回收、没有及时切断与 GC Roots 的联系,这就是内存泄漏。内存泄漏是一些错误的编程方式,或者过多的无用对象创建引起的。
举个例子,有团队使用了 HashMap 做缓存,但是并没有设置超时时间或者 LRU 策略,造成了放入 Map 对象的数据越来越多,而产生了内存泄漏。
再来看一个经常发生的内存泄漏的例子,也是由于 HashMap 产生的。代码如下,由于没有重写 Key 类的 hashCode 和 equals 方法,造成了放入 HashMap 的所有对象都无法被取出来,它们和外界失联了。所以下面的代码结果是 null。
java
//leak example
import java.util.HashMap;
import java.util.Map;
public class HashMapLeakDemo {
public static class Key {
String title;
public Key(String title) {
this.title = title;
}
}
public static void main(String[] args) {
Map<Key, Integer> map = new HashMap<>();
map.put(new Key("1"), 1);
map.put(new Key("2"), 2);
map.put(new Key("3"), 2);
Integer integer = map.get(new Key("2"));
System.out.println(integer);
}
}即使提供了 equals 方法和 hashCode 方法,也要非常小心,尽量避免使用自定义的对象作为 Key。仓库中 dog 目录有一个实际的、有问题的例子,你可以尝试排查一下。
再看一个例子,关于文件处理器的应用,在读取或者写入一些文件之后,由于发生了一些异常,close 方法又没有放在 finally 块里面,造成了文件句柄的泄漏。由于文件处理十分频繁,产生了严重的内存泄漏问题。
另外,对 Java API 的一些不当使用,也会造成内存泄漏。很多同学喜欢使用 String 的 intern 方法,但如果字符串本身是一个非常长的字符串,而且创建之后不再被使用,则会造成内存泄漏。
java
import java.util.UUID;
public class InternDemo {
static String getLongStr() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 100000; i++) {
sb.append(UUID.randomUUID().toString());
}
return sb.toString();
}
public static void main(String[] args) {
while (true) {
getLongStr().intern();
}
}
}6. 小结

本课时介绍了很多 Linux 命令,用于定位分析问题,所有的命令都是可以实际操作的,能够让你详细地把握整个 JVM 乃至操作系统的运行状况。其中,jinfo、jstat、jstack、jhsdb(jmap)等是经常被使用的一些工具,尤其是 jmap,在分析处理内存泄漏问题的时候,是必须的。
同时还介绍了保留现场的工具和辅助分析的方法论,遇到问题不要慌,记得隔离保存现场。
接下来我们看了一个实际的例子,由于 SWAP 的启用造成的服务卡顿。SWAP 会引起很多问题,在高并发服务中一般是关掉它。从这个例子中也可以看到,影响 GC,甚至是整个 JVM 行为的因素,可能不仅限于 JVM 内部,故障排查也是一个综合性的技能。
最后,我们详细看了下内存泄漏的概念和几个实际的例子,从例子中能明显的看到内存泄漏的结果,但是反向去找这些问题代码就不是那么容易了。在后面的课时内容中,我们将使用 MAT 工具具体分析这个捉虫的过程。
第12讲:工具进阶:如何利用MAT找到问题发生的根本原因
我们知道,在存储用户输入的密码时,会使用一些 hash 算法对密码进行加工,比如 SHA-1。这些信息同样不允许在日志输出里出现,必须做脱敏处理,但是对于一个拥有系统权限的攻击者来说,这些防护依然是不够的。攻击者可能会直接从内存中获取明文数据,尤其是对于 Java 来说,由于提供了 jmap 这一类非常方便的工具,可以把整个堆内存的数据 dump 下来。
比如,"我的世界"这一类使用 Java 开发的游戏,会比其他语言的游戏更加容易破解一些,所以我们在 JVM 中,如果把密码存储为 char 数组,其安全性会稍微高一些。
这是一把双刃剑,在保证安全的前提下,我们也可以借助一些外部的分析工具,帮助我们方便的找到问题根本。
有两种方式来获取内存的快照。我们前面提到过,通过配置一些参数,可以在发生 OOM 的时候,被动 dump 一份堆栈信息,这是一种;另一种,就是通过 jmap 主动去获取内存的快照。
jmap 命令在 Java 9 之后,使用 jhsdb 命令替代,它们在用法上,区别不大。注意,这些命令本身会占用操作系统的资源,在某些情况下会造成服务响应缓慢,所以不要频繁执行。
java
jmap -dump:format=b,file=heap.bin 37340
jhsdb jmap --binaryheap --pid 373401. 工具介绍
有很多工具能够帮助我们来分析这份内存快照。在前面已多次提到 VisualVm 这个工具,它同样可以加载和分析这份 dump 数据,虽然比较"寒碜"。
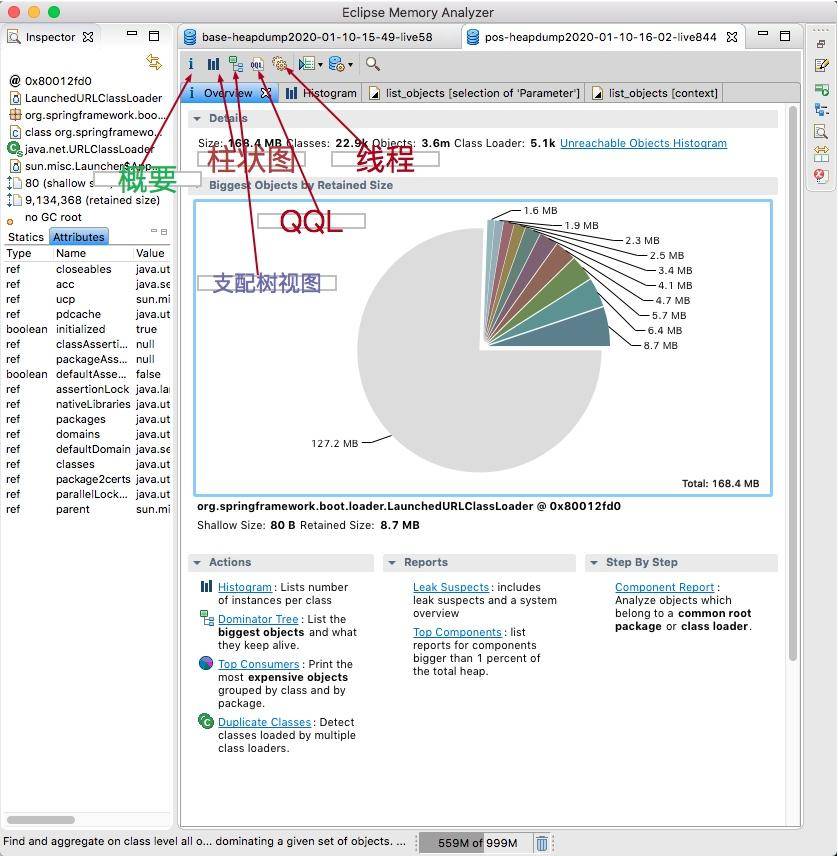
专业的事情要有专业的工具来做,今天要介绍的是一款专业的开源分析工具,即 MAT。
MAT 工具是基于 Eclipse 平台开发的,本身是一个 Java 程序,所以如果你的堆快照比较大的话,则需要一台内存比较大的分析机器,并给 MAT 本身加大初始内存,这个可以修改安装目录中的 MemoryAnalyzer.ini 文件。
来看一下 MAT 工具的截图,主要的功能都体现在工具栏上了。其中,默认的启动界面,展示了占用内存最高的一些对象,并有一些常用的快捷方式。通常,发生内存泄漏的对象,会在快照中占用比较大的比重,分析这些比较大的对象,是我们切入问题的第一步。
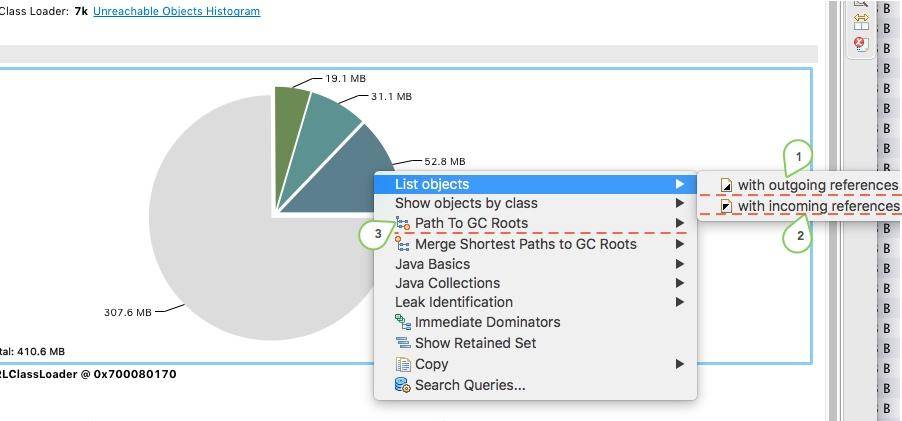
点击对象,可以浏览对象的引用关系,这是一个非常有用的功能:
- outgoing references 对象的引出
- incoming references 对象的引入
path to GC Roots 这是快速分析的一个常用功能,显示和 GC Roots 之间的路径。
另外一个比较重要的概念,就是浅堆 (Shallow Heap)和深堆(Retained Heap),在 MAT 上经常看到这两个数值。
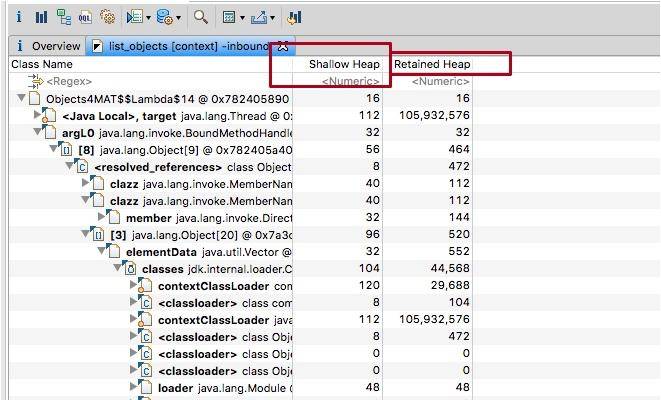
浅堆代表了对象本身的内存占用,包括对象自身的内存占用,以及"为了引用"其他对象所占用的内存。
深堆是一个统计结果,会循环计算引用的具体对象所占用的内存。但是深堆和"对象大小"有一点不同,深堆指的是一个对象被垃圾回收后,能够释放的内存大小,这些被释放的对象集合,叫做保留集(Retained Set)。
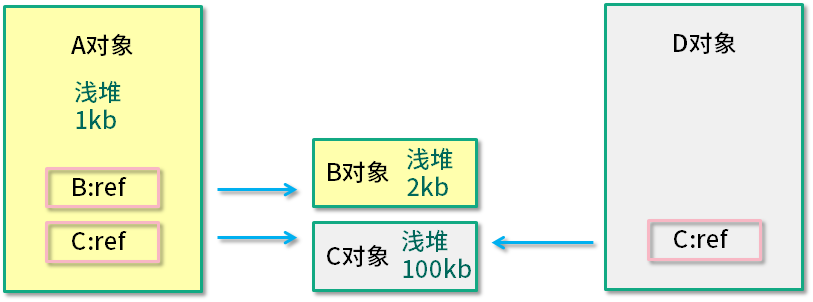
如上图所示,A 对象浅堆大小 1 KB,B 对象 2 KB,C 对象 100 KB。A 对象同时引用了 B 对象和 C 对象,但由于 C 对象也被 D 引用,所以 A 对象的深堆大小为 3 KB(1 KB + 2 KB)。
A 对象大小(1 KB + 2 KB + 100 KB)> A 对象深堆 > A 对象浅堆。
2. 代码示例
java
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.IntStream;
public class Objects4MAT {
static class A4MAT {
B4MAT b4MAT = new B4MAT();
}
static class B4MAT {
C4MAT c4MAT = new C4MAT();
}
static class C4MAT {
List<String> list = new ArrayList<>();
}
static class DominatorTreeDemo1 {
DominatorTreeDemo2 dominatorTreeDemo2;
public void setValue(DominatorTreeDemo2 value) {
this.dominatorTreeDemo2 = value;
}
}
static class DominatorTreeDemo2 {
DominatorTreeDemo1 dominatorTreeDemo1;
public void setValue(DominatorTreeDemo1 value) {
this.dominatorTreeDemo1 = value;
}
}
static class Holder {
DominatorTreeDemo1 demo1 = new DominatorTreeDemo1();
DominatorTreeDemo2 demo2 = new DominatorTreeDemo2();
Holder() {
demo1.setValue(demo2);
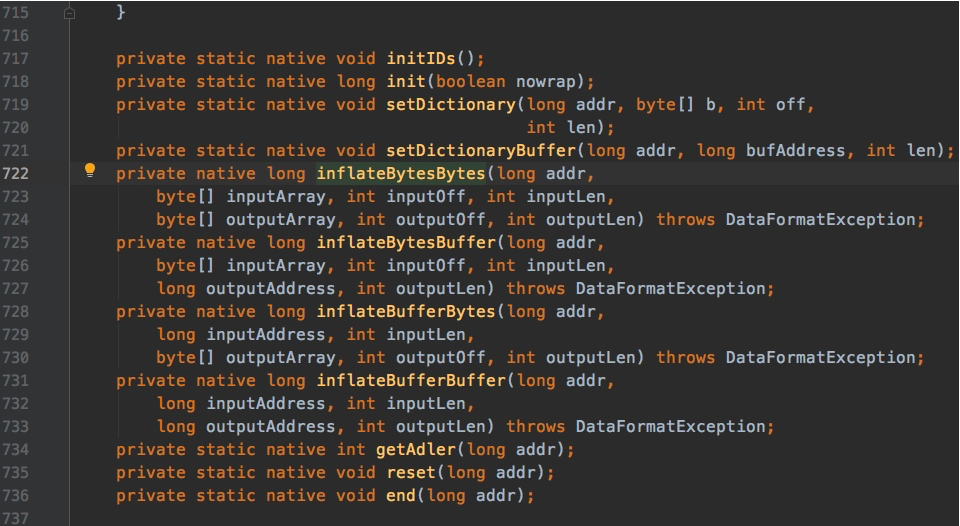
demo2.setValue(demo1);
}
private boolean aBoolean = false;
private char aChar = '\0';
private short aShort = 1;
private int anInt = 1;
private long aLong = 1L;
private float aFloat = 1.0F;
private double aDouble = 1.0D;
private Double aDouble_2 = 1.0D;
private int[] ints = new int[2];
private String string = "1234";
}
Runnable runnable = () -> {
Map<String, A4MAT> map = new HashMap<>();
IntStream.range(0, 100).forEach(i -> {
byte[] bytes = new byte[1024 * 1024];
String str = new String(bytes).replace('\0', (char) i);
A4MAT a4MAT = new A4MAT();
a4MAT.b4MAT.c4MAT.list.add(str);
map.put(i + "", a4MAT);
});
Holder holder = new Holder();
try {
//sleep forever , retain the memory
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
};
void startHugeThread() throws Exception {
new Thread(runnable, "huge-thread").start();
}
public static void main(String[] args) throws Exception {
Objects4MAT objects4MAT = new Objects4MAT();
objects4MAT.startHugeThread();
}
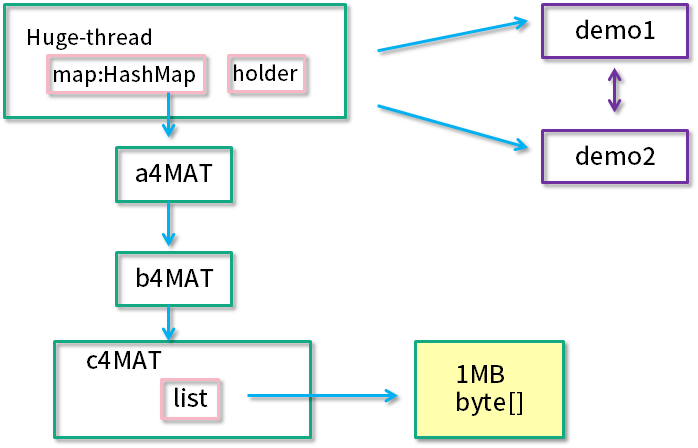
}2.1. 代码介绍
我们以一段代码示例 Objects4MAT,来具体看一下 MAT 工具的使用。代码创建了一个新的线程 "huge-thread",并建立了一个引用的层级关系,总的内存大约占用 100 MB。同时,demo1 和 demo2 展示了一个循环引用的关系。最后,使用 sleep 函数,让线程永久阻塞住,此时整个堆处于一个相对"静止"的状态。
如果你是在本地启动的示例代码,则可以使用 Accquire 的方式来获取堆快照。
2.2. 内存泄漏检测
如果问题特别突出,则可以通过 Find Leaks 菜单快速找出问题。
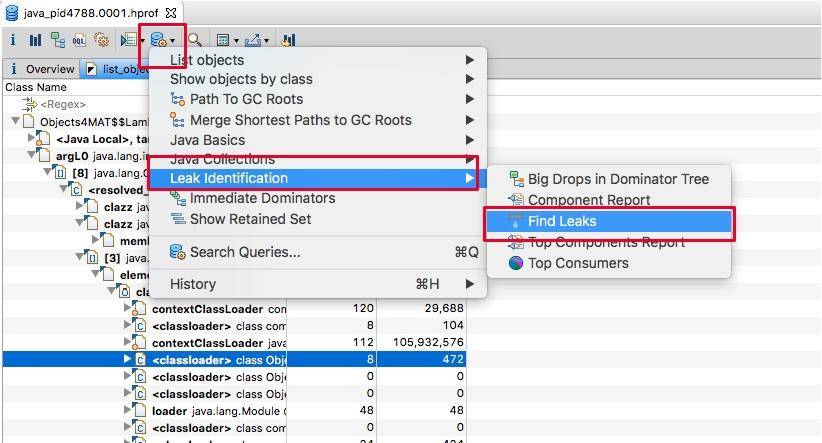
如下图所示,展示了名称叫做 huge-thread 的线程,持有了超过 96% 的对象,数据被一个 HashMap 所持有。
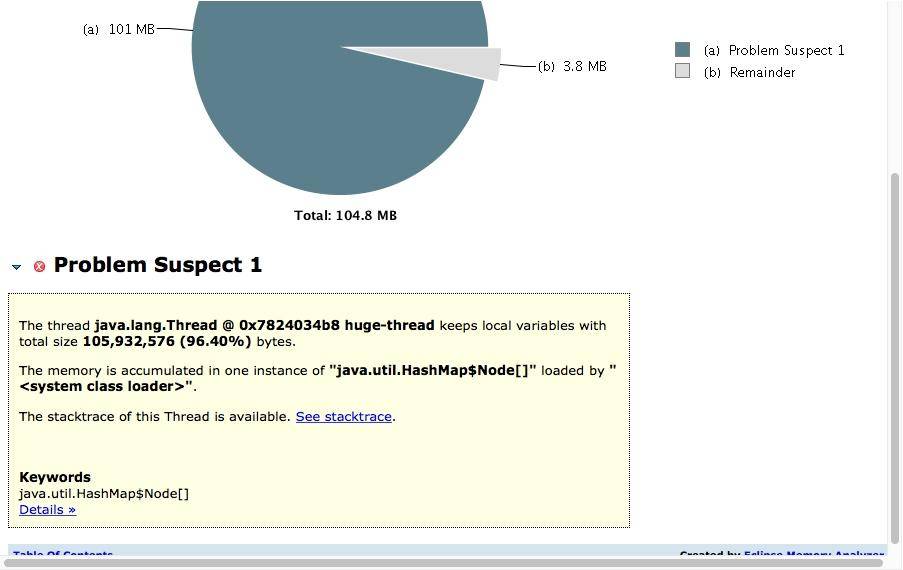
对于特别明显的内存泄漏,在这里能够帮助我们迅速定位,但通常内存泄漏问题会比较隐蔽,我们需要更加复杂的分析。
2.3. 支配树视图
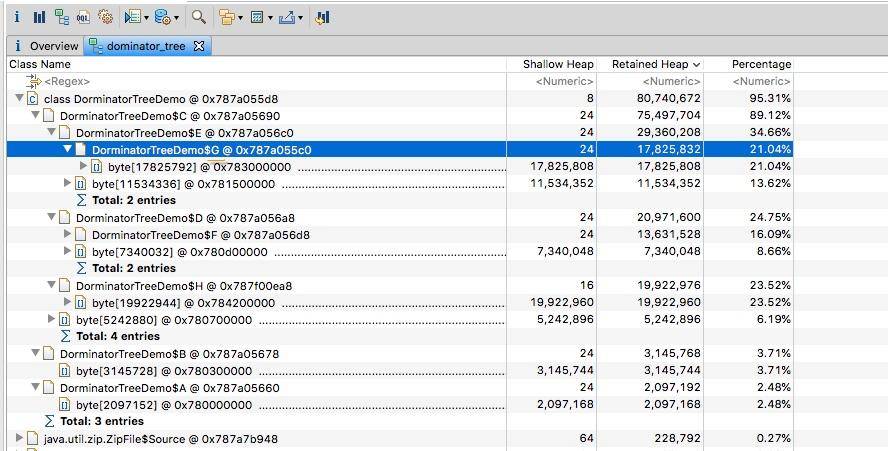
支配树视图对数据进行了归类,体现了对象之间的依赖关系。如图,我们通常会根据"深堆"进行倒序排序,可以很容易的看到占用内存比较高的几个对象,点击前面的箭头,即可一层层展开支配关系。
图中显示的是其中的 1 MB 数据,从左侧的 inspector 视图,可以看到这 1 MB 的 byte 数组具体内容。
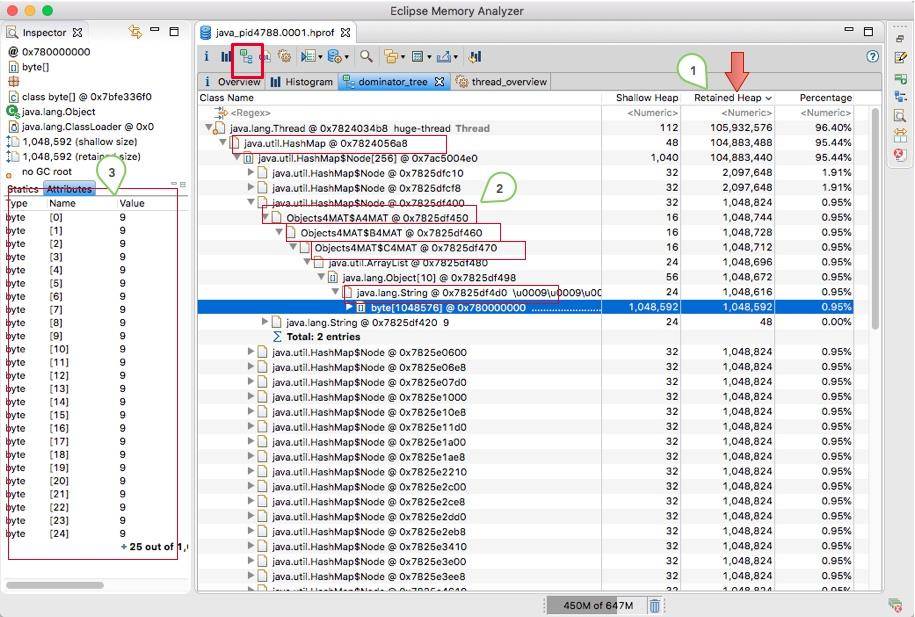
从支配树视图同样能够找到我们创建的两个循环依赖,但它们并没有显示这个过程。
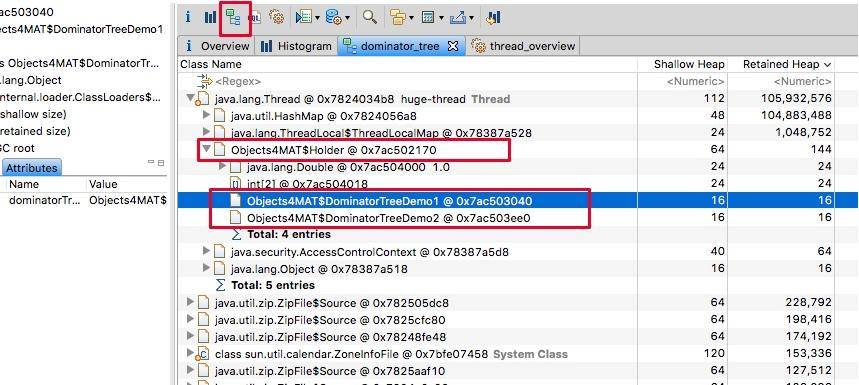
支配树视图的概念有一点点复杂,我们只需要了解这个概念即可。
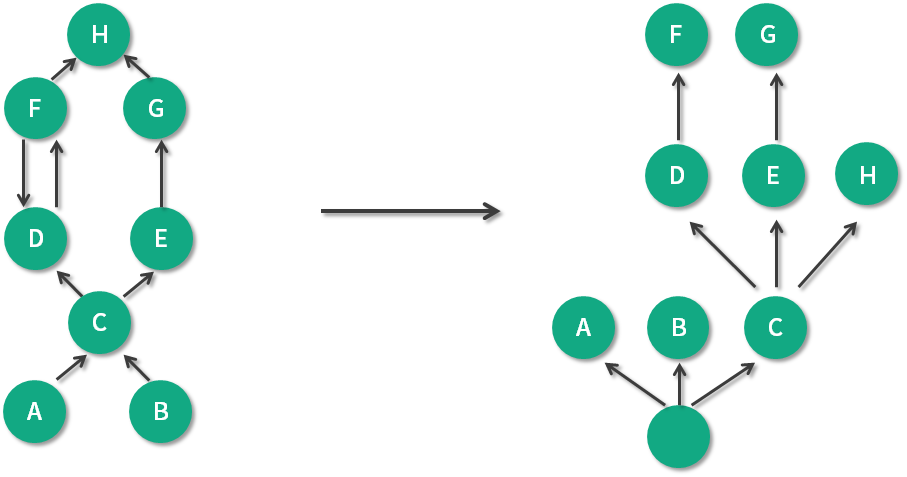
如上图,左边是引用关系,右边是支配树视图。可以看到 A、B、C 被当作是"虚拟"的根,支配关系是可传递的,因为 C 支配 E,E 支配 G,所以 C 也支配 G。
另外,到对象 C 的路径中,可以经过 A,也可以经过 B,因此对象 C 的直接支配者也是根对象。同理,对象 E 是 H 的支配者。
我们再来看看比较特殊的 D 和 F。对象 F 与对象 D 相互引用,因为到对象 F 的所有路径必然经过对象 D,因此,对象 D 是对象 F 的直接支配者。
可以看到支配树视图并不一定总是能看到对象的真实应用关系,但对我们分析问题的影响并不是很大。
这个视图是非常好用的,甚至可以根据 package 进行归类,对目标类的查找也是非常快捷的。
编译下面这段代码,可以展开视图,实际观测一下支配树,这和我们上面介绍的是一致的。
java
public class DorminatorTreeDemo {
static class A {
C c;
byte[] data = new byte[1024 * 1024 * 2];
}
static class B {
C c;
byte[] data = new byte[1024 * 1024 * 3];
}
static class C {
D d;
E e;
byte[] data = new byte[1024 * 1024 * 5];
}
static class D {
F f;
byte[] data = new byte[1024 * 1024 * 7];
}
static class E {
G g;
byte[] data = new byte[1024 * 1024 * 11];
}
static class F {
D d;
H h;
byte[] data = new byte[1024 * 1024 * 13];
}
static class G {
H h;
byte[] data = new byte[1024 * 1024 * 17];
}
static class H {
byte[] data = new byte[1024 * 1024 * 19];
}
A makeRef(A a, B b) {
C c = new C();
D d = new D();
E e = new E();
F f = new F();
G g = new G();
H h = new H();
a.c = c;
b.c = c;
c.e = e;
c.d = d;
d.f = f;
e.g = g;
f.d = d;
f.h = h;
g.h = h;
return a;
}
static A a = new A();
static B b = new B();
public static void main(String[] args) throws Exception {
new DorminatorTreeDemo().makeRef(a, b);
Thread.sleep(Integer.MAX_VALUE);
}
}
2.4. 线程视图
想要看具体的引用关系,可以通过线程视图。我们在第 5 讲,就已经了解了线程其实是可以作为 GC Roots 的。如图展示了线程内对象的引用关系,以及方法调用关系,相对比 jstack 获取的栈 dump,我们能够更加清晰地看到内存中具体的数据。
如下图,我们找到了 huge-thread,依次展开找到 holder 对象,可以看到循环依赖已经陷入了无限循环的状态。这在查看一些 Java 对象的时候,经常发生,不要感到奇怪。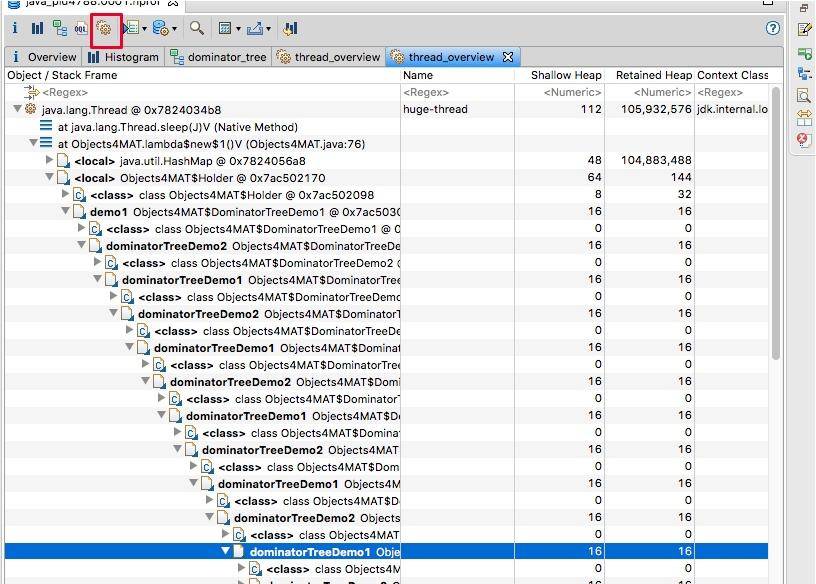
2.5. 柱状图视图
我们返回头来再看一下柱状图视图,可以看到除了对象的大小,还有类的实例个数。结合 MAT 提供的不同显示方式,往往能够直接定位问题。也可以通过正则过滤一些信息,我们在这里输入 MAT,过滤猜测的、可能出现问题的类,可以看到,创建的这些自定义对象,不多不少正好一百个。
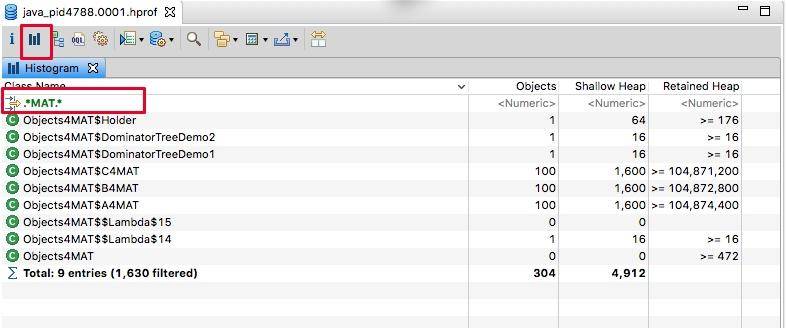
右键点击类,然后选择 incoming,这会列出所有的引用关系。
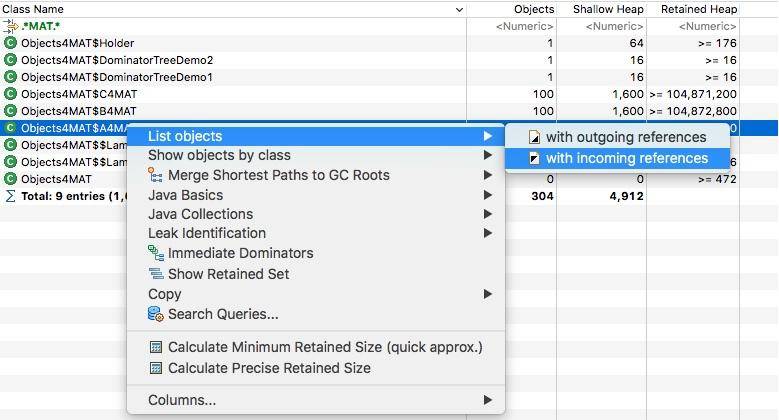
再次选择某个引用关系,然后选择菜单"Path To GC Roots",即可显示到 GC Roots 的全路径。通常在排查内存泄漏的时候,会选择排除虚弱软等引用。
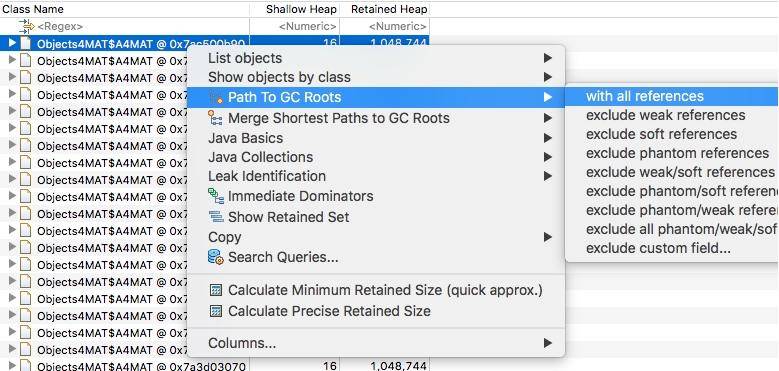
使用这种方式,即可在引用之间进行跳转,方便的找到所需要的信息。

再介绍一个比较高级的功能。
我们对于堆的快照,其实是一个"瞬时态",有时候仅仅分析这个瞬时状态,并不一定能确定问题,这就需要对两个或者多个快照进行对比,来确定一个增长趋势。
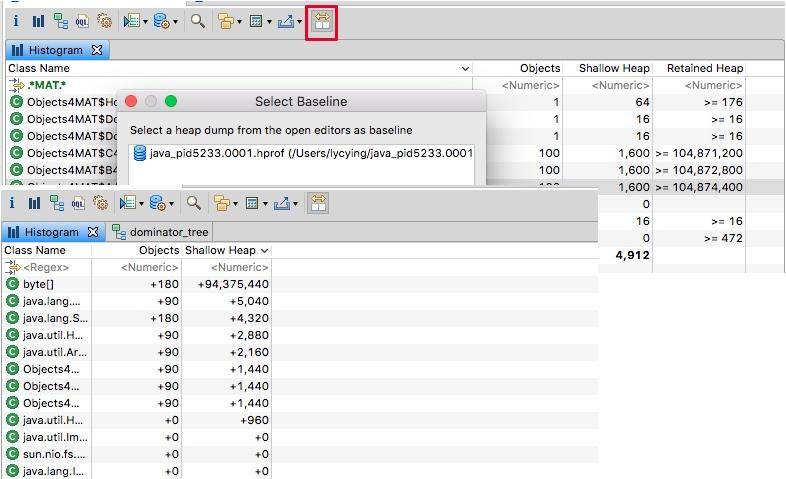
可以将代码中的 100 改成 10 或其他数字,再次 dump 一份快照进行比较。如图,通过分析某类对象的增长,即可辅助问题定位。
3. 高级功能---OQL
MAT 支持一种类似于 SQL 的查询语言 OQL(Object Query Language),这个查询语言 VisualVM 工具也支持。
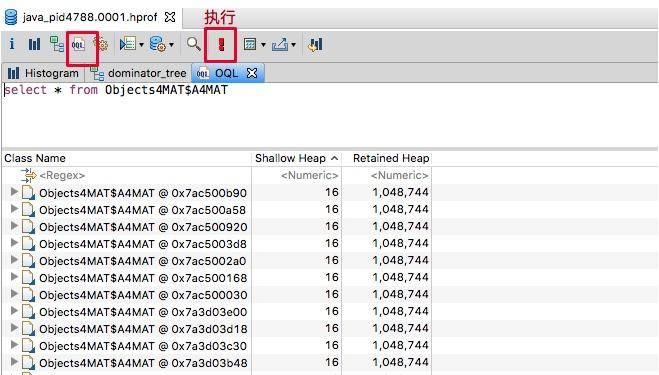
以下是几个例子,你可以实际实践一下。
查询 A4MAT 对象:
sql
SELECT * FROM Objects4MAT$A4MAT正则查询 MAT 结尾的对象:
sql
SELECT * FROM ".*MAT"查询 String 类的 char 数组:
sql
SELECT OBJECTS s.value FROM java.lang.String s
SELECT OBJECTS mat.b4MAT FROM Objects4MAT$A4MAT mat根据内存地址查找对象:
sql
select * from 0x55a034c8使用 INSTANCEOF 关键字,查找所有子类:
sql
SELECT * FROM INSTANCEOF java.util.AbstractCollection查询长度大于 1000 的 byte 数组:
sql
SELECT * FROM byte[] s WHERE s.@length>1000查询包含 java 字样的所有字符串:
sql
SELECT * FROM java.lang.String s WHERE toString(s) LIKE ".*java.*"查找所有深堆大小大于 1 万的对象:
sql
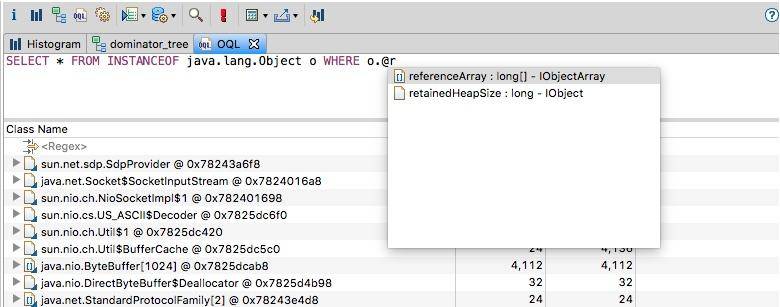
SELECT * FROM INSTANCEOF java.lang.Object o WHERE o.@retainedHeapSize>10000如果你忘记这些属性的名称的话,MAT 是可以自动补全的。
一般,我们使用上面这些简单的查询语句就够用了。
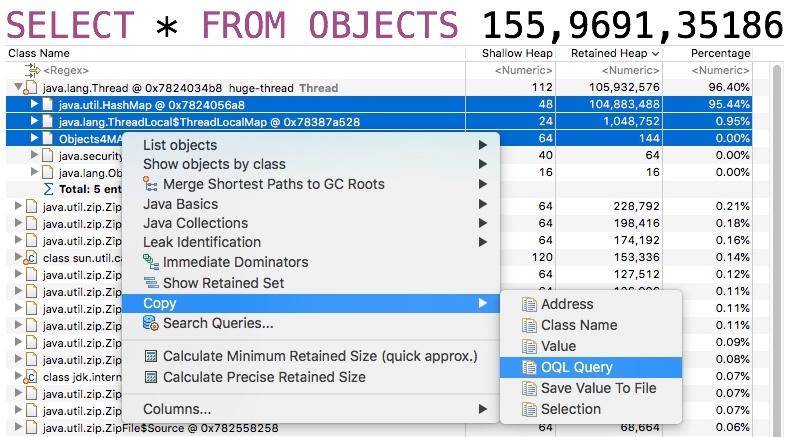
OQL 还有一个好处,就是可以分享。如果你和同事同时在分析一个大堆,不用告诉他先点哪一步、再点哪一步,共享给他一个 OQL 语句就可以了。
如下图,MAT 贴心的提供了复制 OQL 的功能,但是用在其他快照上,不会起作用,因为它复制的是如下的内容。
4. 小结
这一讲我们介绍了 MAT 工具的使用,其是用来分析内存快照的;在最后,简要介绍了 OQL 查询语言。
在 Java 9 以前的版本中,有一个工具 jhat,可以以 html 的方式显示堆栈信息,但和 VisualVm 一样,都太过于简陋,推荐使用 MAT 工具。
我们把问题设定为内存泄漏,但其实 OOM 或者频繁 GC 不一定就是内存泄漏,它也可能是由于某次或者某批请求频繁而创建了大量对象,所以一些严重的、频繁的 GC 问题也能在这里找到原因。有些情况下,占用内存最多的对象,并不一定是引起内存泄漏问题的元凶,但我们也有一个比较通用的分析过程。
并不是所有的堆都值得分析的,我们在做这个耗时的分析之前,需要有个依据。比如,经过初步调优之后,GC 的停顿时间还是较长,则需要找到频繁 GC 的原因;再比如,我们发现了内存泄漏,需要找到是谁在搞鬼。
首先,我们高度关注快照载入后的初始分析,占用内存高的 topN 对象,大概率是问题产生者。
对照自己的代码,首先要分析的,就是产生这些大对象的逻辑。举几个实际发生的例子。有一个 Spring Boot 应用,由于启用了 Swagger 文档生成器,但是由于它的 API 关系非常复杂,嵌套层次又非常深(每次要产生几百 M 的文档!),结果请求几次之后产生了内存溢出,这在 MAT 上就能够一眼定位到问题;而另外一个应用,在读取数据库的时候使用了分页,但是 pageSize 并没有做一些范围检查,结果在请求一个较大分页的时候,使用 fastjson 对获取的数据进行加工,直接 OOM。
如果不能通过大对象发现问题,则需要对快照进行深入分析。使用柱状图和支配树视图,配合引入引出和各种排序,能够对内存的使用进行整体的摸底。由于我们能够看到内存中的具体数据,排查一些异常数据就容易得多。
可以在程序运行的不同时间点,获取多份内存快照,对比之后问题会更加容易发现。我们还是用一个例子来看。有一个应用,使用了 Kafka 消息队列,开了一般大小的消费缓冲区,Kafka 会复用这个缓冲区,按理说不应该有内存问题,但是应用却频繁发生 GC。通过对比请求高峰和低峰期间的内存快照,我们发现有工程师把消费数据放入了另外一个 "内存队列",写了一些画蛇添足的代码,结果在业务高峰期一股脑把数据加载到了内存中。
上面这些问题通过分析业务代码,也不难发现其关联性。问题如果非常隐蔽,则需要使用 OQL 等语言,对问题一一排查、确认。
可以看到,上手 MAT 工具是有一定门槛的,除了其操作模式,还需要对我们前面介绍的理论知识有深入的理解,比如 GC Roots、各种引用级别等。
在很多场景,MAT 并不仅仅用于内存泄漏的排查。由于我们能够看到内存上的具体数据,在排查一些难度非常高的 bug 时,MAT 也有用武之地。比如,因为某些脏数据,引起了程序的执行异常,此时,想要找到它们,不要忘了 MAT 这个老朋友。
第13讲:动手实践:让面试官刮目相看的堆外内存排查
本课时我们主要讲解让面试官刮目相看的堆外内存排查。
第 02 课时讲了 JVM 的内存布局,同时也在第 08 课时中看到了由于 Metaspace 设置过小而引起的问题,接着,第 10 课时讲了一下元空间和直接内存引起的内存溢出实例。
Metaspace 属于堆外内存,但由于它是单独管理的,所以排查起来没什么难度。你平常可能见到的使用堆外内存的场景还有下面这些:
- JNI 或者 JNA 程序,直接操纵了本地内存,比如一些加密库;
- 使用了Java 的 Unsafe 类,做了一些本地内存的操作;
- Netty 的直接内存(Direct Memory),底层会调用操作系统的 malloc 函数。
使用堆外内存可以调用一些功能完备的库函数,而且减轻了 GC 的压力。这些代码,有可能是你了解的人写的,也有可能隐藏在第三方的 jar 包里。虽然有一些好处,但是问题排查起来通常会比较的困难。
在第 10 课时,介绍了 MaxDirectMemorySize 可以控制直接内存的申请。其实,通过这个参数,仍然限制不住所有堆外内存的使用,它只是限制了使用 DirectByteBuffer 的内存申请。很多时候(比如直接使用了 sun.misc.Unsafe 类),堆外内存会一直增长,直到机器物理内存爆满,被 oom killer。
java
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class UnsafeDemo {
public static final int _1MB = 1024 * 1024;
public static void main(String[] args) throws Exception {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
for (; ; ) {
unsafe.allocateMemory(_1MB);
}
}
}上面这段代码,就会持续申请堆外内存,但它返回的是 long 类型的地址句柄,所以堆内内存的使用会很少。
我们使用下面的命令去限制堆内和直接内存的使用,结果发现程序占用的操作系统内存在一直上升,这两个参数在这种场景下没有任何效果。这段程序搞死了我的机器很多次,运行的时候要小心。
ruby
java -XX:MaxDirectMemorySize=10M -Xmx10M UnsafeDemo相信这种情况也困扰了你,因为使用一些 JDK 提供的工具,根本无法发现这部门内存的使用。我们需要一些更加底层的工具来发现这些游离的内存分配。其实,很多内存和性能问题,都逃不过下面要介绍的这些工具的联合分析。本课时将会结合一个实际的例子,来看一下一个堆外内存的溢出情况,了解常见的套路。
1. 现象
我们有一个服务,非常的奇怪,在某个版本之后,占用的内存开始增长,直到虚拟机分配的内存上限,但是并不会 OOM。如果你开启了 SWAP,会发现这个应用也会毫不犹豫的将它吞掉,有多少吞多少。
说它的内存增长,是通过 top 命令去观察的,看它的 RES 列的数值;反之,如果使用 jmap 命令去看内存占用,得到的只是堆的大小,只能看到一小块可怜的空间。
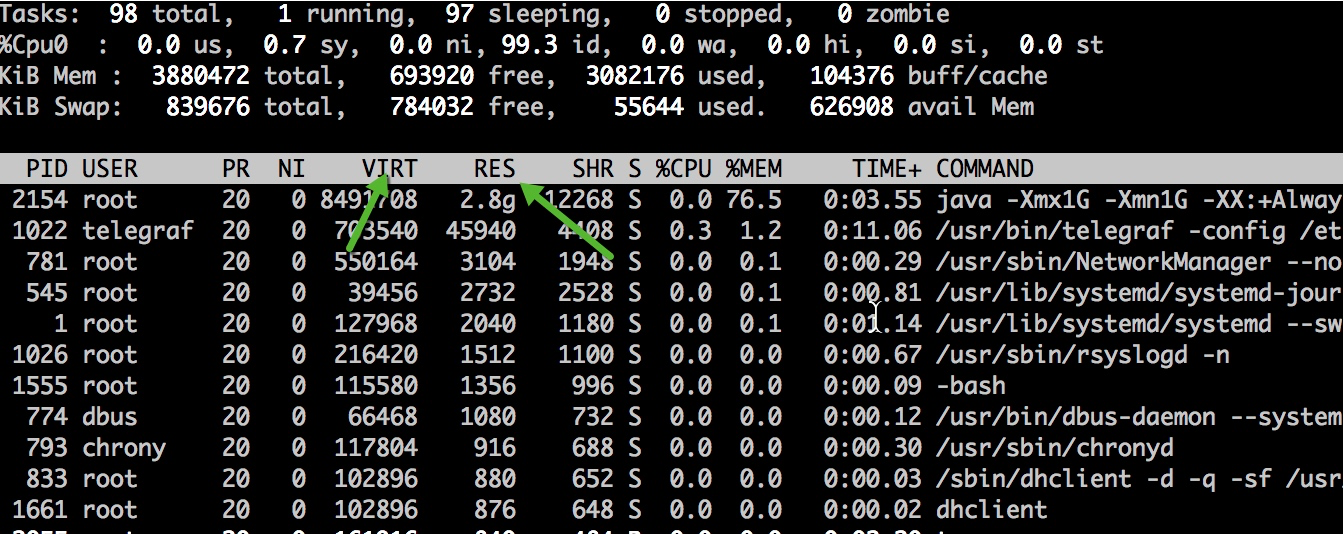
使用 ps 也能看到相同的效果。我们观测到,除了虚拟内存比较高,达到了 17GB 以外,实际使用的内存 RSS 也夸张的达到了 7 GB,远远超过了 -Xmx 的设定。
[root]$ ps -p 75 -o rss,vsz
RSS VSZ 7152568 17485844使用 jps 查看启动参数,发现分配了大约 3GB 的堆内存。实际内存使用超出了最大内存设定的一倍还多,这明显是不正常的,肯定是使用了堆外内存。
2. 模拟程序
为了能够使用这些工具实际观测这个内存泄漏的过程,我这里准备了一份小程序。程序将会持续的使用 Java 的 Zip 函数进行压缩和解压,这种操作在一些对传输性能较高的的场景经常会用到。
程序将会申请 1kb 的随机字符串,然后持续解压。为了避免让操作系统陷入假死状态,我们每次都会判断操作系统内存使用率,在达到 60% 的时候,我们将挂起程序;通过访问 8888 端口,将会把内存阈值提高到 85%。我们将分析这两个处于相对静态的虚拟快照。
java
import com.sun.management.OperatingSystemMXBean;
import com.sun.net.httpserver.HttpContext;
import com.sun.net.httpserver.HttpServer;
import java.io.*;
import java.lang.management.ManagementFactory;
import java.net.InetSocketAddress;
import java.util.Random;
import java.util.concurrent.ThreadLocalRandom;
import java.util.zip.GZIPInputStream;
import java.util.zip.GZIPOutputStream;
/**
* @author xjjdog
*/
public class LeakExample {
/**
* 构造随机的字符串
*/
public static String randomString(int strLength) {
Random rnd = ThreadLocalRandom.current();
StringBuilder ret = new StringBuilder();
for (int i = 0; i < strLength; i++) {
boolean isChar = (rnd.nextInt(2) % 2 == 0);
if (isChar) {
int choice = rnd.nextInt(2) % 2 == 0 ? 65 : 97;
ret.append((char) (choice + rnd.nextInt(26)));
} else {
ret.append(rnd.nextInt(10));
}
}
return ret.toString();
}
public static int copy(InputStream input, OutputStream output) throws IOException {
long count = copyLarge(input, output);
return count > 2147483647L ? -1 : (int) count;
}
public static long copyLarge(InputStream input, OutputStream output) throws IOException {
byte[] buffer = new byte[4096];
long count = 0L;
int n;
for (; -1 != (n = input.read(buffer)); count += (long) n) {
output.write(buffer, 0, n);
}
return count;
}
public static String decompress(byte[] input) throws Exception {
ByteArrayOutputStream out = new ByteArrayOutputStream();
copy(new GZIPInputStream(new ByteArrayInputStream(input)), out);
return new String(out.toByteArray());
}
public static byte[] compress(String str) throws Exception {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
GZIPOutputStream gzip = new GZIPOutputStream(bos);
try {
gzip.write(str.getBytes());
gzip.finish();
byte[] b = bos.toByteArray();
return b;
} finally {
try {
gzip.close();
} catch (Exception ex) {
}
try {
bos.close();
} catch (Exception ex) {
}
}
}
private static OperatingSystemMXBean osmxb = (OperatingSystemMXBean) ManagementFactory.getOperatingSystemMXBean();
public static int memoryLoad() {
double totalvirtualMemory = osmxb.getTotalPhysicalMemorySize();
double freePhysicalMemorySize = osmxb.getFreePhysicalMemorySize();
double value = freePhysicalMemorySize / totalvirtualMemory;
int percentMemoryLoad = (int) ((1 - value) * 100);
return percentMemoryLoad;
}
private static volatile int RADIO = 60;
public static void main(String[] args) throws Exception {
HttpServer server = HttpServer.create(new InetSocketAddress(8888), 0);
HttpContext context = server.createContext("/");
context.setHandler(exchange -> {
try {
RADIO = 85;
String response = "OK!";
exchange.sendResponseHeaders(200, response.getBytes().length);
OutputStream os = exchange.getResponseBody();
os.write(response.getBytes());
os.close();
} catch (Exception ex) {
}
});
server.start();
//1kb
int BLOCK_SIZE = 1024;
String str = randomString(BLOCK_SIZE / Byte.SIZE);
byte[] bytes = compress(str);
for (; ; ) {
int percent = memoryLoad();
if (percent > RADIO) {
Thread.sleep(1000);
} else {
decompress(bytes);
Thread.sleep(1);
}
}
}
}程序将使用下面的命令行进行启动。为了简化问题,这里省略了一些无关的配置。
java -Xmx1G -Xmn1G -XX:+AlwaysPreTouch -XX:MaxMetaspaceSize=10M -XX:MaxDirectMemorySize=10M -XX:NativeMemoryTracking=detail LeakExample3. NMT
首先介绍一下上面的几个 JVM 参数,分别使用 Xmx、MaxMetaspaceSize、MaxDirectMemorySize 这三个参数限制了堆、元空间、直接内存的大小。
然后,使用 AlwaysPreTouch 参数。其实,通过参数指定了 JVM 大小,只有在 JVM 真正使用的时候,才会分配给它。这个参数,在 JVM 启动的时候,就把它所有的内存在操作系统分配了。在堆比较大的时候,会加大启动时间,但在这个场景中,我们为了减少内存动态分配的影响,把这个值设置为 True。
接下来的 NativeMemoryTracking,是用来追踪 Native 内存的使用情况。通过在启动参数上加入 -XX:NativeMemoryTracking=detail 就可以启用。使用 jcmd 命令,就可查看内存分配。
bash
jcmd $pid VM.native_memory summary我们在一台 4GB 的虚拟机上使用上面的命令。启动程序之后,发现进程使用的内存迅速升到 2.4GB。
## jcmd 2154 VM.native_memory summary
2154:
Native Memory Tracking:
Total: reserved=2370381KB, committed=1071413KB
- Java Heap (reserved=1048576KB, committed=1048576KB)
(mmap: reserved=1048576KB, committed=1048576KB)
- Class (reserved=1056899KB, committed=4995KB)
(classes #432)
(malloc=131KB #328)
(mmap: reserved=1056768KB, committed=4864KB)
- Thread (reserved=10305KB, committed=10305KB)
(thread #11)
(stack: reserved=10260KB, committed=10260KB)
(malloc=34KB #52)
(arena=12KB #18)
- Code (reserved=249744KB, committed=2680KB)
(malloc=144KB #502)
(mmap: reserved=249600KB, committed=2536KB)
- GC (reserved=2063KB, committed=2063KB)
(malloc=7KB #80)
(mmap: reserved=2056KB, committed=2056KB)
- Compiler (reserved=138KB, committed=138KB)
(malloc=8KB #38)
(arena=131KB #5)
- Internal (reserved=789KB, committed=789KB)
(malloc=757KB #1272)
(mmap: reserved=32KB, committed=32KB)
- Symbol (reserved=1535KB, committed=1535KB)
(malloc=983KB #114)
(arena=552KB #1)
- Native Memory Tracking (reserved=159KB, committed=159KB)
(malloc=99KB #1399)
(tracking overhead=60KB)
- Arena Chunk (reserved=174KB, committed=174KB)
(mall可惜的是,这个名字让人振奋的工具并不能如它描述的一样,看到我们这种泄漏的场景。下图这点小小的空间,是不能和 2GB 的内存占用相比的。
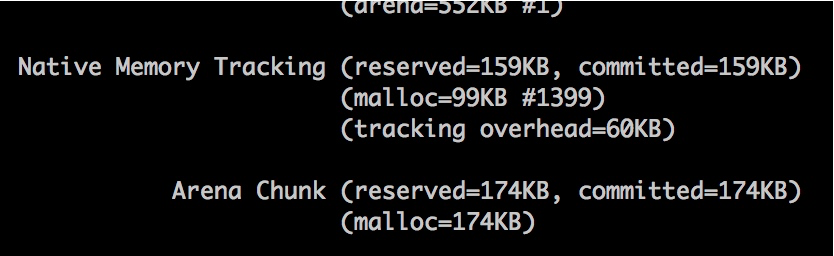
NMT 能看到堆内内存、Code 区域或者使用 unsafe.allocateMemory 和 DirectByteBuffer 申请的堆外内存,虽然是个好工具但问题并不能解决。
使用 jmap 工具,dump 一份堆快照,然后使用 MAT 分析,依然不能找到这部分内存。
4. pmap
像是 EhCache 这种缓存框架,提供了多种策略,可以设定将数据存储在非堆上,我们就是要排查这些影响因素。如果能够在代码里看到这种可能性最大的代码块,是最好的。
为了进一步分析问题,我们使用 pmap 命令查看进程的内存分配,通过 RSS 升序序排列。结果发现除了地址 00000000c0000000 上分配的 1GB 堆以外(也就是我们的堆内存),还有数量非常多的 64M 一块的内存段,还有巨量小的物理内存块映射到不同的虚拟内存段上。但到现在为止,我们不知道里面的内容是什么,是通过什么产生的。
## pmap -x 2154 | sort -n -k3
Address Kbytes RSS Dirty Mode Mapping
---------------- ------- ------- -------
0000000100080000 1048064 0 0 ----- [ anon ]
00007f2d4fff1000 60 0 0 ----- [ anon ]
00007f2d537fb000 8212 0 0 ----- [ anon ]
00007f2d57ff1000 60 0 0 ----- [ anon ]
.....省略N行
00007f2e3c000000 65524 22064 22064 rw--- [ anon ]
00007f2e00000000 65476 22068 22068 rw--- [ anon ]
00007f2e18000000 65476 22072 22072 rw--- [ anon ]
00007f2e30000000 65476 22076 22076 rw--- [ anon ]
00007f2dc0000000 65520 22080 22080 rw--- [ anon ]
00007f2dd8000000 65520 22080 22080 rw--- [ anon ]
00007f2da8000000 65524 22088 22088 rw--- [ anon ]
00007f2e8c000000 65528 22088 22088 rw--- [ anon ]
00007f2e64000000 65520 22092 22092 rw--- [ anon ]
00007f2e4c000000 65520 22096 22096 rw--- [ anon ]
00007f2e7c000000 65520 22096 22096 rw--- [ anon ]
00007f2ecc000000 65520 22980 22980 rw--- [ anon ]
00007f2d84000000 65476 23368 23368 rw--- [ anon ]
00007f2d9c000000 131060 43932 43932 rw--- [ anon ]
00007f2d50000000 57324 56000 56000 rw--- [ anon ]
00007f2d4c000000 65476 64160 64160 rw--- [ anon ]
00007f2d5c000000 65476 64164 64164 rw--- [ anon ]
00007f2d64000000 65476 64164 64164 rw--- [ anon ]
00007f2d54000000 65476 64168 64168 rw--- [ anon ]
00007f2d7c000000 65476 64168 64168 rw--- [ anon ]
00007f2d60000000 65520 64172 64172 rw--- [ anon ]
00007f2d6c000000 65476 64172 64172 rw--- [ anon ]
00007f2d74000000 65476 64172 64172 rw--- [ anon ]
00007f2d78000000 65520 64176 64176 rw--- [ anon ]
00007f2d68000000 65520 64180 64180 rw--- [ anon ]
00007f2d80000000 65520 64184 64184 rw--- [ anon ]
00007f2d58000000 65520 64188 64188 rw--- [ anon ]
00007f2d70000000 65520 64192 64192 rw--- [ anon ]
00000000c0000000 1049088 1049088 1049088 rw--- [ anon ]
total kB 8492740 3511008 3498584通过 Google,找到以下资料 Linux glibc >= 2.10 (RHEL 6) malloc may show excessive virtual memory usage) 。
文章指出造成应用程序大量申请 64M 大内存块的原因是由 Glibc 的一个版本升级引起的,通过 export MALLOC_ARENA_MAX=4 可以解决 VSZ 占用过高的问题。虽然这也是一个问题,但却不是我们想要的,因为我们增长的是物理内存,而不是虚拟内存,程序在这一方面表现是正常的。
5. gdb
非常好奇 64M 或者其他小内存块中是什么内容,接下来可以通过 gdb 工具将其 dump 出来。
读取 /proc 目录下的 maps 文件,能精准地知晓目前进程的内存分布。以下脚本通过传入进程 id,能够将所关联的内存全部 dump 到文件中。注意,这个命令会影响服务,要慎用。
bash
pid=$1;grep rw-p /proc/$pid/maps | sed -n 's/^\([0-9a-f]*\)-\([0-9a-f]*\) .*$/\1 \2/p' | while read start stop; do gdb --batch --pid $pid -ex "dump memory $1-$start-$stop.dump 0x$start 0x$stop"; done这个命令十分霸道,甚至把加载到内存中的 class 文件、堆文件一块给 dump 下来。这是机器的原始内存,大多数文件我们打不开。
更多时候,只需要 dump 一部分内存就可以。再次提醒操作会影响服务,注意 dump 的内存块大小,线上一定要慎用。
我们复制 pman 的一块 64M 内存,比如 00007f2d70000000,然后去掉前面的 0,使用下面代码得到内存块的开始和结束地址。
bash
cat /proc/2154/maps | grep 7f2d70000000
7f2d6fff1000-7f2d70000000 ---p 00000000 00:00 0 7f2d70000000-7f2d73ffc000 rw-p 00000000 00:00 0接下来就 dump 这 64MB 的内存。
bash
gdb --batch --pid 2154 -ex "dump memory a.dump 0x7f2d70000000 0x7f2d73ffc000"使用 du 命令查看具体的内存块大小,不多不少正好 64M。
bash
## du -h a.dump
64M a.dump是时候查看里面的内容了,使用 strings 命令可以看到内存块里一些可以打印的内容。
## strings -10 a.dump
0R4f1Qej1ty5GT8V1R8no6T44564wz499E6Y582q2R9h8CC175GJ3yeJ1Q3P5Vt757Mcf6378kM36hxZ5U8uhg2A26T5l7f68719WQK6vZ2BOdH9lH5C7838qf1
...等等?这些内容不应该在堆里面么?为何还会使用额外的内存进行分配?那么还有什么地方在分配堆外内存呢?
这种情况,只可能是 native 程序对堆外内存的操作。
6. perf
下面介绍一个神器 perf,除了能够进行一些性能分析,它还能帮助我们找到相应的 native 调用。这么突出的堆外内存使用问题,肯定能找到相应的调用函数。
使用 perf record -g -p 2154 开启监控栈函数调用,然后访问服务器的 8888 端口,这将会把内存使用的阈值增加到 85%,我们的程序会逐渐把这部分内存占满,你可以 syi。perf 运行一段时间后 Ctrl+C 结束,会生成一个文件 perf.data。
执行 perf report -i perf.data 查看报告。
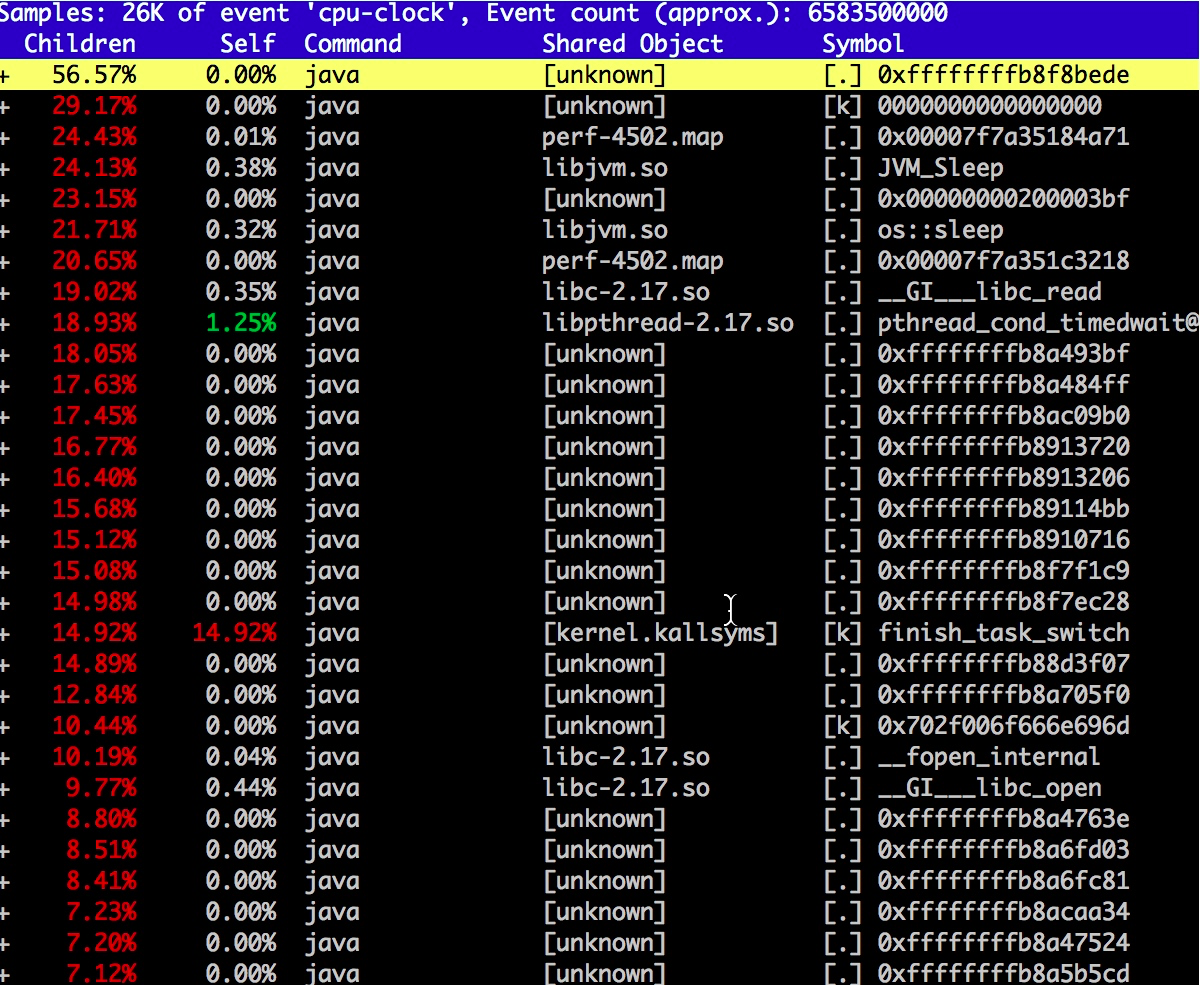
如图,一般第三方 JNI 程序,或者 JDK 内的模块,都会调用相应的本地函数,在 Linux 上,这些函数库的后缀都是 so。
我们依次浏览用的可疑资源,发现了"libzip.so",还发现了不少相关的调用。搜索 zip(输入 / 进入搜索模式),结果如下:
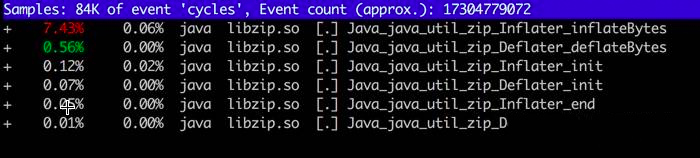
查看 JDK 代码,发现 bzip 大量使用了 native 方法。也就是说,有大量内存的申请和销毁,是在堆外发生的。
进程调用了Java_java_util_zip_Inflater_inflatBytes() 申请了内存,却没有调用 Deflater 释放内存。与 pmap 内存地址相比对,确实是 zip 在搞鬼。
7. gperftools
google 还有一个类似的、非常好用的工具,叫做 gperftools,我们主要用到它的 Heap Profiler,功能更加强大。
它的启动方式有点特别,安装成功之后,你只需要输出两个环境变量即可。
bash
mkdir -p /opt/test
export LD_PRELOAD=/usr/lib64/libtcmalloc.so
export HEAPPROFILE=/opt/test/heap在同一个终端,再次启动我们的应用程序,可以看到内存申请动作都被记录到了 opt 目录下的 test 目录。
接下来,我们就可以使用 pprof 命令分析这些文件。
bash
cd /opt/test
pprof -text *heap | head -n 200使用这个工具,能够一眼追踪到申请内存最多的函数。Java_java_util_zip_Inflater_init 这个函数立马就被发现了。
Total: 25205.3 MB
20559.2 81.6% 81.6% 20559.2 81.6% inflateBackEnd
4487.3 17.8% 99.4% 4487.3 17.8% inflateInit2_
75.7 0.3% 99.7% 75.7 0.3% os::malloc@8bbaa0
70.3 0.3% 99.9% 4557.6 18.1% Java_java_util_zip_Inflater_init
7.1 0.0% 100.0% 7.1 0.0% readCEN
3.9 0.0% 100.0% 3.9 0.0% init
1.1 0.0% 100.0% 1.1 0.0% os::malloc@8bb8d0
0.2 0.0% 100.0% 0.2 0.0% _dl_new_object
0.1 0.0% 100.0% 0.1 0.0% __GI__dl_allocate_tls
0.1 0.0% 100.0% 0.1 0.0% _nl_intern_locale_data
0.0 0.0% 100.0% 0.0 0.0% _dl_check_map_versions
0.0 0.0% 100.0% 0.0 0.0% __GI___strdup
0.0 0.0% 100.0% 0.1 0.0% _dl_map_object_deps
0.0 0.0% 100.0% 0.0 0.0% nss_parse_service_list
0.0 0.0% 100.0% 0.0 0.0% __new_exitfn
0.0 0.0% 100.0% 0.0 0.0% getpwuid
0.0 0.0% 100.0% 0.0 0.0% expand_dynamic_string_token8. 解决
这就是我们模拟内存泄漏的整个过程,到此问题就解决了。
GZIPInputStream 使用 Inflater 申请堆外内存、Deflater 释放内存,调用 close() 方法来主动释放。如果忘记关闭,Inflater 对象的生命会延续到下一次 GC,有一点类似堆内的弱引用。在此过程中,堆外内存会一直增长。
把 decompress 函数改成如下代码,重新编译代码后观察,问题解决。
java
public static String decompress(byte[] input) throws Exception {
ByteArrayOutputStream out = new ByteArrayOutputStream();
GZIPInputStream gzip = new GZIPInputStream(new ByteArrayInputStream(input));
try {
copy(gzip, out);
return new String(out.toByteArray());
} finally {
try {
gzip.close();
} catch (Exception ex) {
}
try {
out.close();
} catch (Exception ex) {
}
}
}9. 小结
本课时使用了非常多的工具和命令来进行堆外内存的排查,可以看到,除了使用 jmap 获取堆内内存,还对堆外内存的获取也有不少办法。
现在,我们可以把堆外内存进行更加细致地划分了。
元空间属于堆外内存,主要是方法区和常量池的存储之地,使用数"MaxMetaspaceSize"可以限制它的大小,我们也能观测到它的使用。
直接内存主要是通过 DirectByteBuffer 申请的内存,可以使用参数"MaxDirectMemorySize"来限制它的大小(参考第 10 课时)。
其他堆外内存,主要是指使用了 Unsafe 或者其他 JNI 手段直接直接申请的内存。这种情况,就没有任何参数能够阻挡它们,要么靠它自己去释放一些内存,要么等待操作系统对它的审判了。
还有一种情况,和内存的使用无关,但是也会造成内存不正常使用,那就是使用了 Process 接口,直接调用了外部的应用程序,这些程序对操作系统的内存使用一般是不可预知的。
本课时介绍的一些工具,很多高级研发,包括一些面试官,也是不知道的;即使了解这个过程,不实际操作一遍,也很难有深刻的印象。通过这个例子,你可以看到一个典型的堆外内存问题的排查思路。
堆外内存的泄漏是非常严重的,它的排查难度高、影响大,甚至会造成宿主机的死亡。在排查内存问题时,不要忘了这一环。
第14讲:预警与解决:深入浅出GC监控与调优
本课时我们主要讲解深入浅出 GC 监控与调优。
在前面的课时中不止一次谈到了监控,但除了 GC Log,大多数都是一些"瞬时监控"工具,也就是看到的问题,基本是当前发生的。
你可能见过在地铁上抱着电脑处理故障的照片,由此可见,大部分程序员都是随身携带电脑的,它体现了两个问题:第一,自动化应急处理机制并不完善;第二,缺乏能够跟踪定位问题的工具,只能靠"苦力"去解决。
我们在前面第 11 课时中提到的一系列命令,就是一个被分解的典型脚本,这个脚本能够在问题发生的时候,自动触发并保存顺时态的现场。除了这些工具,我们还需要有一个与时间序列相关的监控系统。这就是监控工具的必要性。
我们来盘点一下对于问题的排查,现在都有哪些资源:
- GC 日志,能够反映每次 GC 的具体状况,可根据这些信息调整一些参数及容量;
- 问题发生点的堆快照,能够在线下找到具体内存泄漏的原因;
- 问题发生点的堆栈信息,能够定位到当前正在运行的业务,以及一些死锁问题;
- 操作系统监控,比如 CPU 资源、内存、网络、I/O 等,能够看到问题发生前后整个操作系统的资源状况;
- 服务监控,比如服务的访问量、响应时间等,可以评估故障堆服务的影响面,或者找到一些突增的流量来源;
- JVM 各个区的内存变化、GC 变化、耗时等监控,能够帮我们了解到 JVM 在整个故障周期的时间跨度上,到底发生了什么。
在实践课时中,我们也不止一次提到,优化和问题排查是一个综合的过程。故障相关信息越多越好,哪怕是同事不经意间透露的一次压测信息,都能够帮助你快速找到问题的根本。
本课时将以一个实际的监控解决方案,来看一下监控数据是怎么收集和分析的。使用的工具主要集中在 Telegraf、InfluxDB 和 Grafana 上,如果你在用其他的监控工具,思路也是类似的。
监控指标
在前面的一些示例代码中,会看到如下的 JMX 代码片段:
java
static void memPrint() {
for (MemoryPoolMXBean memoryPoolMXBean : ManagementFactory.getMemoryPoolMXBeans()) {
System.out.println(memoryPoolMXBean.getName() +
" committed:" + memoryPoolMXBean.getUsage().getCommitted() +
" used:" + memoryPoolMXBean.getUsage().getUsed());
}
}这就是 JMX 的作用。除了使用代码,通过 jmc 工具也可以简单地看一下它们的值(前面提到的 VisualVM 通过安装插件,也可以看到这些信息)。
新版本的 JDK 不再包含 jmc 这个工具,可点击这里自行下载。
如下图所示,可以看到一个 Java 进程的资源概览,包括内存、CPU、线程等。
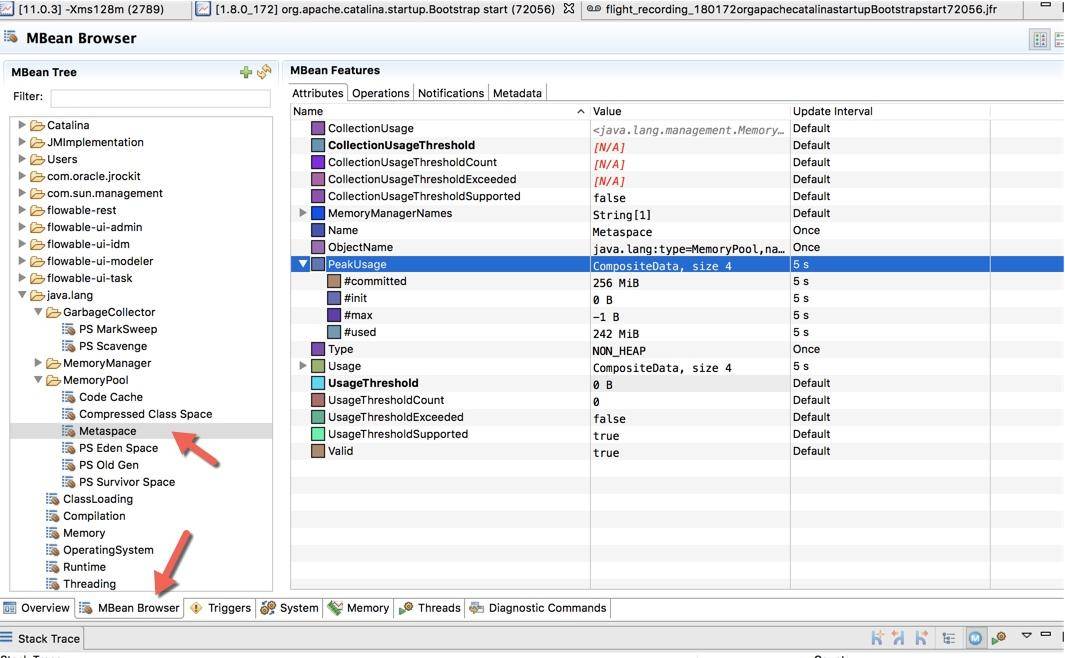
下图是切换到 MBean 选项卡之后的截图,可以看到图中展示的 Metaspace 详细信息。
jmc 还是一个性能分析平台,可以录制、收集正在运行的 Java 程序的诊断数据和概要分析数据,感兴趣的可以自行探索。但还是那句话,线上环境可能没有条件让我们使用一些图形化分析工具,相对比 Arthas 这样的命令行工具就比较吃香。
比如,下图就是一个典型的互联网架构图,真正的服务器可能是一群 docker 实例,如果自己的机器想要访问 JVM 的宿主机器,则需要配置一些复杂的安全策略和权限开通。图像化的工具在平常的工作中不是非常有用,而且,由于性能损耗和安全性的考虑,也不会让研发主动去通过 JMX 连接这些机器。
所以面试的时候如果你一直在提一些图形化工具,面试官只能无奈的笑笑,这个话题也无法进行下去了。
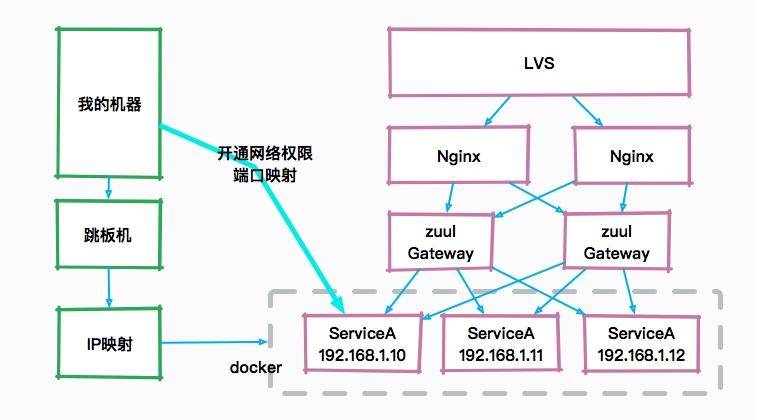
在必要的情况下,JMX 还可以通过加上一些参数,进行远程访问。
-Djava.rmi.server.hostname=127.0.0.1
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=14000
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false无论是哪种方式,我们发现每个内存区域,都有四个值:init、used、committed 和 max,下图展示了它们之间的大小关系。
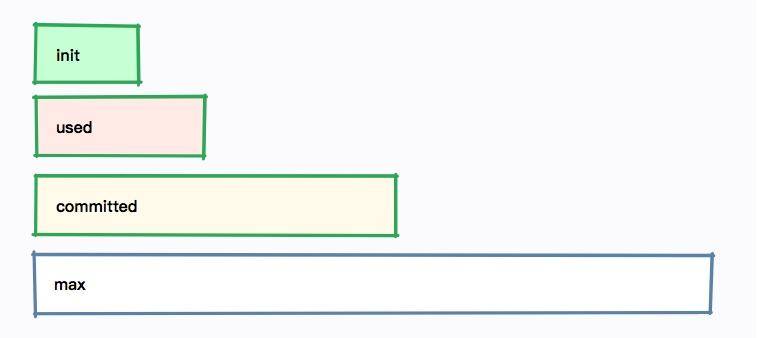
以堆内存大小来说:
- -Xmx 就是 max
- -Xms 就是 init
- committed 指的是当前可用的内存大小,它的大小包括已经使用的内存
- used 指的是实际被使用的内存大小,它的值总是小于 committed
如果在启动的时候,指定了 -Xmx = -Xms,也就是初始值和最大值是一样的,可以看到这四个值,只有 used 是变动的。
Jolokia
单独看这些 JMX 的瞬时监控值,是没有什么用的,需要使用程序收集起来并进行分析。
但是 JMX 的客户端 API 使用起来非常的不方便,Jolokia 就是一个将 JMX 转换成 HTTP 的适配器,方便了 JMX 的使用。
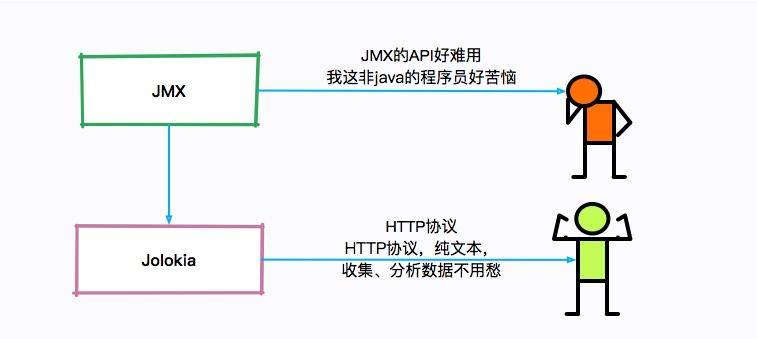
Jokokia 可以通过 jar 包和 agent 的方式启动,在一些框架中,比如 Spring Boot 中,很容易进行集成。
访问 http://start.spring.io,生成一个普通的 Spring Boot 项目。
直接在 pom 文件里加入 jolokia 的依赖。
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.jolokia</groupId>
<artifactId>jolokia-core</artifactId>
</dependency>在 application.yml 中简单地加入一点配置,就可以通过 HTTP 接口访问 JMX 的内容了。
yaml
management:
endpoints:
web:
exposure:
include: jolokia你也可以直接下载仓库中的 monitor-demo 项目,启动后访问 8084 端口,即可获取 JMX 的 json 数据。访问链接 /demo 之后,会使用 guava 持续产生内存缓存。
接下来,我们将收集这个项目的 JMX 数据。
bash
http://localhost:8084/actuator/jolokia/list附上仓库地址:https://gitee.com/xjjdog/jvm-lagou-res。
JVM 监控搭建
我们先简单看一下 JVM 监控的整体架构图: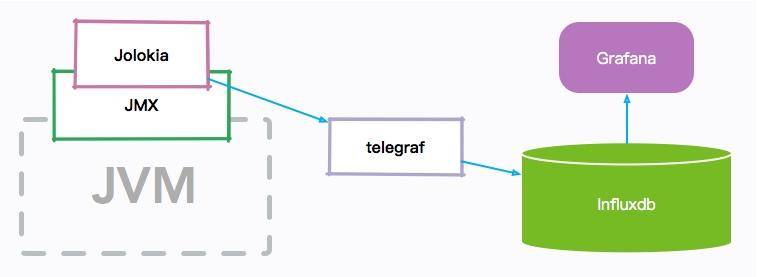
JVM 的各种内存信息,会通过 JMX 接口进行暴露;Jolokia 组件负责把 JMX 信息翻译成容易读取的 HTTP 请求。
telegraf 组件作为一个通用的监控 agent,和 JVM 进程部署在同一台机器上,通过访问转化后的 HTTP 接口,以固定的频率拉取监控信息;然后把这些信息存放到 influxdb 时序数据库中;最后,通过高颜值的 Grafana 展示组件,设计 JVM 监控图表。
整个监控组件是可以热拔插的,并不会影响原有服务。监控部分也是可以复用的,比如 telegraf 就可以很容易的进行操作系统监控。
influxdb
influxdb 是一个性能和压缩比非常高的时序数据库,在中小型公司非常流行,点击这里可获取 influxdb。
在 CentOS 环境中,可以使用下面的命令下载。
bash
wget -c https://dl.influxdata.com/influxdb/releases/influxdb-1.7.9_linux_amd64.tar.gz
tar xvfz influxdb-1.7.9_linux_amd64.tar.gz解压后,然后使用 nohup 进行启动。
bash
nohup ./influxd &InfluxDB 将在 8086 端口进行监听。
Telegraf
Telegraf 是一个监控数据收集工具,支持非常丰富的监控类型,其中就包含内置的 Jolokia 收集器。
接下来,下载并安装 Telegraf:
bash
wget -c https://dl.influxdata.com/telegraf/releases/telegraf-1.13.1-1.x86_64.rpm
sudo yum localinstall telegraf-1.13.1-1.x86_64.rpmTelegraf 通过 jolokia 配置收集数据相对简单,比如下面就是收集堆内存使用状况的一段配置。
ini
[[inputs.jolokia2_agent.metric]]
name = "jvm"
field_prefix = "Memory_"
mbean = "java.lang:type=Memory"
paths = ["HeapMemoryUsage", "NonHeapMemoryUsage", "ObjectPendingFinalizationCount"]设计这个配置文件的主要难点在于对 JVM 各个内存分区的理解。由于配置文件比较长,可以参考仓库中的 jvm.conf 和 sys.conf,你可以把这两个文件,复制到 /etc/telegraf/telegraf.d/ 目录下面,然后执行 systemctl restart telegraf 重启 telegraf。
grafana
grafana 是一个颜值非常高的监控展示组件,支持非常多的数据源类型,对 influxdb 的集成度也比较高,可通过以下地址进行下载:https://grafana.com/grafana/download
bash
wget -c https://dl.grafana.com/oss/release/grafana-6.5.3.linux-amd64.tar.gz
tar -zxvf grafana-6.5.3.linux-amd64.tar.gz下面是我已经做好的一张针对于 CMS 垃圾回收器的监控图,你可以导入 grafana-jvm-influxdb.json 文件进行测试。
在导入之前,还需要创建一个数据源,选择 influxdb,填入 db 的地址即可。
集成
把我们的 Spring Boot 项目打包(见仓库),然后上传到服务器上去执行。
打包方式:
bash
mvn package -Dmaven.tesk.skip=true执行方式(自行替换日志方面配置):
bash
mkdir /tmp/logs
nohup java -XX:+UseConcMarkSweepGC -Xmx512M -Xms512M -Djava.rmi.server.hos
tname=192.168.99.101 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmx
remote.port=14000 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.manage
ment.jmxremote.authenticate=false -verbose:gc -XX:+PrintGCDetails -XX:+PrintG
CDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistributio
n -Xloggc:/tmp/logs/gc_%p.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPat
h=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log -XX:-OmitStackTraceInF
astThrow -jar monitor-demo-0.0.1-SNAPSHOT.jar 2>&1 &请将 IP 地址改成自己服务器的实际 IP 地址,这样就可以使用 jmc 或者 VisualVM 等工具进行连接了。
确保 Telegraf、InfluxDB、Grafana 已经启动,这样,Java 进程的 JVM 相关数据,将会以 10 秒一次的频率进行收集,我们可以选择 Grafana 的时间轴,来查看实时的或者历史的监控曲线。
这类监控信息,可以保存长达 1 ~ 2 年,也就是说非常久远的问题,也依然能够被追溯到。如果你想要对 JVM 尽可能地进行调优,就要时刻关注这些监控图。
举一个例子:我们发现有一个线上服务,运行一段时间以后,CPU 升高、程序执行变慢,登录相应的服务器进行分析,发现 C2 编译线程一直处在高耗 CPU 的情况。
但是我们无法解决这个问题,一度以为是 JVM 的 Bug。
通过分析 CPU 的监控图和 JVM 每个内存分区的曲线,发现 CodeCache 相应的曲线,在增加到 32MB 之后,就变成了一条直线,同时 CPU 的使用也开始增加。
通过检查启动参数和其他配置,最终发现一个开发环境的 JVM 参数被一位想要练手的同学给修改了,他本意是想要通过参数 "-XX:ReservedCodeCacheSize" 来限制 CodeCache 的大小,这个参数被误推送到了线上环境。
JVM 通过 JIT 编译器来增加程序的执行效率,JIT 编译后的代码,都会放在 CodeCache 里。如果这个空间不足,JIT 则无法继续编译,编译执行会变成解释执行,性能会降低一个数量级。同时,JIT 编译器会一直尝试去优化代码,造成了 CPU 的占用上升。
由于我们收集了这些分区的监控信息,所以很容易就发现了问题的相关性,这些判断也会反向支持我们的分析,而不仅仅是靠猜测。
小结
本课时简要介绍了基于 JMX 的 JVM 监控,并了解了一系列观测这些数据的工具。但通常,使用 JMX 的 API 还是稍显复杂一些,Jolokia 可以把这些信息转化成 HTTP 的 json 信息。
还介绍了一个可用的监控体系,来收集这些暴露的数据,这也是有点规模的公司采用的正统思路。收集的一些 GC 数据,和前面介绍的 GC 日志是有一些重合的,但我们的监控更突出的是实时性,以及追踪一些可能比较久远的问题数据。
附录:代码清单
- sys.conf 操作系统监控数据收集配置文件,Telegraf 使用。
- jvm.conf JVM 监控配置文件,Telegraf 使用。
- grafana-jvm-influxdb.json JVM 监控面板,Grafana 使用。
- monitor-demo 被收集的 Spring Boot 项目。
第15讲:案例分析:一个高死亡率的报表系统的优化之路
本课时我们主要分析一个案例,那就是一个"高死亡率"报表系统的优化之路。
传统观念上的报表系统,可能访问量不是特别多,点击一个查询按钮,后台 SQL 语句的执行需要等数秒。如果使用 jstack 来查看执行线程,会发现大多数线程都阻塞在数据库的 I/O 上。
上面这种是非常传统的报表。还有一种类似于大屏监控一类的实时报表,这种报表的并发量也是比较可观的,但由于它的结果集都比较小,所以我们可以像对待一个高并发系统一样对待它,问题不是很大。
本课时要讲的,就是传统观念上的报表。除了处理时间比较长以外,报表系统每次处理的结果集,普遍都比较大,这给 JVM 造成了非常大的压力。
下面我们以一个综合性的实例,来看一下一个"病入膏肓"的报表系统的优化操作。
有一个报表系统,频繁发生内存溢出,在高峰期间使用时,还会频繁的发生拒绝服务,这是不可忍受的。
服务背景
本次要优化的服务是一个 SaaS 服务,使用 Spring Boot 编写,采用的是 CMS 垃圾回收器。如下图所示,有些接口会从 MySQL 中获取数据,有些则从 MongoDB 中获取数据,涉及的结果集合都比较大。
由于有些结果集的字段不是太全,因此需要对结果集合进行循环,可通过 HttpClient 调用其他服务的接口进行数据填充。也许你会认为某些数据可能会被复用,于是使用 Guava 做了 JVM 内缓存。
大体的服务依赖可以抽象成下面的图。
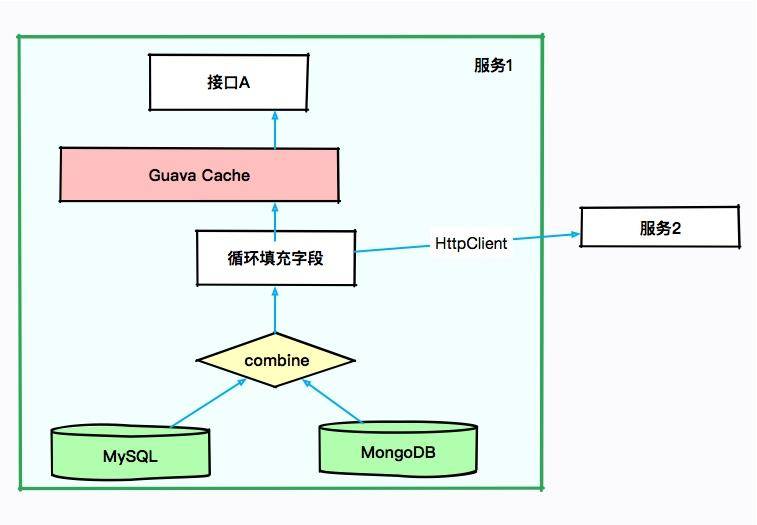
初步排查,JVM 的资源太少。当接口 A 每次进行报表计算时,都要涉及几百兆的内存,而且在内存里驻留很长时间,同时有些计算非常耗 CPU,特别的"吃"资源。而我们分配给 JVM 的内存只有 3 GB,在多人访问这些接口的时候,内存就不够用了,进而发生了 OOM。在这种情况下,即使连最简单的报表都不能用了。
没办法,只有升级机器。把机器配置升级到 4core8g,给 JVM 分配 6GB 的内存,这样 OOM 问题就消失了。但随之而来的是频繁的 GC 问题和超长的 GC 时间,平均 GC 时间竟然有 5 秒多。
初步优化
我们前面算过,6GB 大小的内存,年轻代大约是 2GB,在高峰期,每几秒钟则需要进行一次 MinorGC。报表系统和高并发系统不太一样,它的对象,存活时长大得多,并不能仅仅通过增加年轻代来解决;而且,如果增加了年轻代,那么必然减少了老年代的大小,由于 CMS 的碎片和浮动垃圾问题,我们可用的空间就更少了。虽然服务能够满足目前的需求,但还有一些不太确定的风险。
第一,了解到程序中有很多缓存数据和静态统计数据,为了减少 MinorGC 的次数,通过分析 GC 日志打印的对象年龄分布,把 MaxTenuringThreshold 参数调整到了 3(请根据你自己的应用情况设置)。这个参数是让年轻代的这些对象,赶紧回到老年代去,不要老呆在年轻代里。
第二,我们的 GC 时间比较长,就一块开了参数 CMSScavengeBeforeRemark,使得在 CMS remark 前,先执行一次 Minor GC 将新生代清掉。同时配合上个参数,其效果还是比较好的,一方面,对象很快晋升到了老年代,另一方面,年轻代的对象在这种情况下是有限的,在整个 MajorGC 中占的时间也有限。
第三,由于缓存的使用,有大量的弱引用,拿一次长达 10 秒的 GC 来说。我们发现在 GC 日志里,处理 weak refs 的时间较长,达到了 4.5 秒。
bash
2020-01-28T12:13:32.876+0800: 526569.947: [weak refs processing, 4.5240649 secs]所以加入了参数 ParallelRefProcEnabled 来并行处理 Reference,以加快处理速度,缩短耗时。
同时还加入了其他一些优化参数,比如通过调整触发 GC 的参数来进行优化。
bash
-Xmx6g -Xms6g -XX:MaxTenuringThreshold=3 -XX:+AlwaysPreTouch -XX:+Par
allelRefProcEnabled -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSwe
epGC -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccu
pancyOnly -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M优化之后,效果不错,但并不是特别明显。经过评估,针对高峰时期的情况进行调研,我们决定再次提升机器性能,改用 8core16g 的机器。但是,这会带来另外一个问题。
高性能的机器带来了非常大的服务吞吐量,通过 jstat 进行监控,能够看到年轻代的分配速率明显提高,但随之而来的 MinorGC 时长却变的不可控,有时候会超过 1 秒。累积的请求造成了更加严重的后果。
这是由于堆空间明显加大造成的回收时间加长。为了获取较小的停顿时间,我们在堆上采用了 G1 垃圾回收器,把它的目标设定在 200ms。G1 是一款非常优秀的垃圾收集器,不仅适合堆内存大的应用,同时也简化了调优的工作。通过主要的参数初始和最大堆空间、以及最大容忍的 GC 暂停目标,就能得到不错的性能。所以为了照顾大对象的生成,我们把小堆区的大小修改为 16 M。修改之后,虽然 GC 更加频繁了一些,但是停顿时间都比较小,应用的运行较为平滑。
bash
-Xmx12g -Xms12g -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=45 -XX:MaxGCPauseMillis=200 -XX:G1HeapRegionSize=16m -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m这个时候,任务来了:业务部门发力,预计客户增长量增长 10 ~ 100 倍,报表系统需要评估其可行性,以便进行资源协调。可问题是,这个"千疮百孔"的报表系统,稍微一压测,就宕机,那如何应对十倍百倍的压力呢?
使用 MAT 分析堆快照,发现很多地方可以通过代码优化,那些占用内存特别多的对象,都是我们需要优化的。
代码优化
我们使用扩容硬件的方式,暂时缓解了 JVM 的问题,但是根本问题并没有触及到。为了减少内存的占用,肯定要清理无用的信息。通过对代码的仔细分析,首先要改造的就是 SQL 查询语句。
很多接口,其实并不需要把数据库的每个字段都查询出来,当你在计算和解析的时候,它们会不知不觉地"吃掉"你的内存。所以我们只需要获取所需的数据就够了,也就是把 select 这种方式修改为具体的查询字段,对于报表系统来说这种优化尤其明显。
再一个就是 Cache 问题,通过排查代码,会发现一些命中率特别低,占用内存又特别大的对象,放到了 JVM 内的 Cache 中,造成了无用的浪费。
解决方式,就是把 Guava 的 Cache 引用级别改成弱引用(WeakKeys),尽量去掉无用的应用缓存。对于某些使用特别频繁的小 key,使用分布式的 Redis 进行改造即可。
为了找到更多影响因子大的问题,我们部署了独立的环境,然后部署了 JVM 监控。在回放某个问题请求后,观察 JVM 的响应,通过这种方式,发现了更多的优化可能。
报表系统使用了 POI 组件进行导入导出功能的开发,结果客户在没有限制的情况下上传、下载了条数非常多的文件,直接让堆内存飙升。为了解决这种情况,我们在导入功能加入了文件大小的限制,强制客户进行拆分;在下载的时候指定范围,严禁跨度非常大的请求。
在完成代码改造之后,再把机器配置降级回 4core8g,依然采用 G1 垃圾回收器,再也没有发生 OOM 的问题了,GC 问题也得到了明显的缓解。
拒绝服务问题
上面解决的是 JVM 的内存问题,可以看到除了优化 JVM 参数、升级机器配置以外,代码修改带来的优化效果更加明显,但这个报表服务还有一个严重的问题。
刚开始我们提到过,由于没有微服务体系,有些数据需要使用 HttpClient 来获取进行补全。提供数据的服务有的响应时间可能会很长,也有可能会造成服务整体的阻塞。
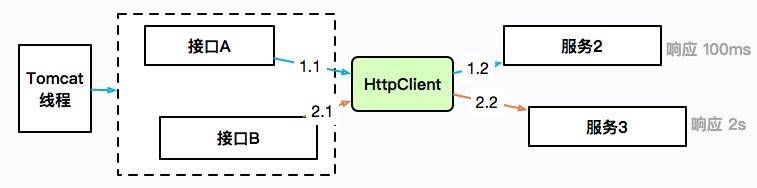
如上图所示,接口 A 通过 HttpClient 访问服务 2,响应 100ms 后返回;接口 B 访问服务 3,耗时 2 秒。HttpClient 本身是有一个最大连接数限制的,如果服务 3 迟迟不返回,就会造成 HttpClient 的连接数达到上限,最上层的 Tomcat 线程也会一直阻塞在这里,进而连响应速度比较快的接口 A 也无法正常提供服务。
这是出现频率非常高的的一类故障,在工作中你会大概率遇见。概括来讲,就是同一服务,由于一个耗时非常长的接口,进而引起了整体的服务不可用。
这个时候,通过 jstack 打印栈信息,会发现大多数竟然阻塞在了接口 A 上,而不是耗时更长的接口 B。这是一种错觉,其实是因为接口 A 的速度比较快,在问题发生点进入了更多的请求,它们全部都阻塞住了。
证据本身具有非常强的迷惑性。由于这种问题发生的频率很高,排查起来又比较困难,我这里专门做了一个小工程,用于还原解决这种问题的一个方式,参见 report-demo 工程。
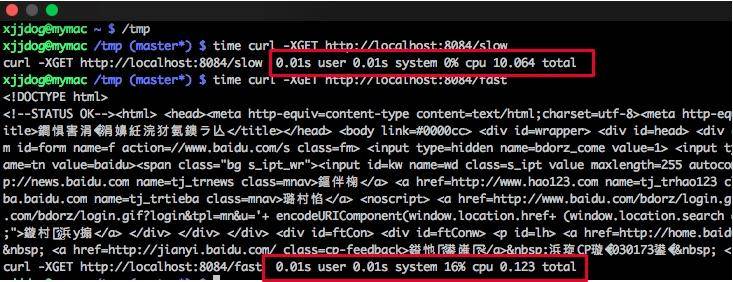
demo 模拟了两个使用同一个 HttpClient 的接口。如下图所示,fast 接口用来访问百度,很快就能返回;slow 接口访问谷歌,由于众所周知的原因,会阻塞直到超时,大约 10 s。
使用 wrk 工具对这两个接口发起压测。
bash
wrk -t10 -c200 -d300s http://127.0.0.1:8084/slow
wrk -t10 -c200 -d300s http://127.0.0.1:8084/fast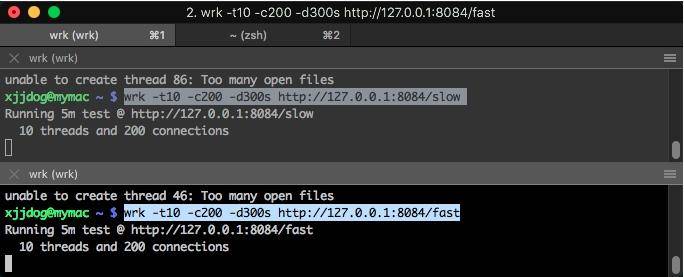
此时访问一个简单的接口,耗时竟然能够达到 20 秒。
bash
time curl http://localhost:8084/stat
fast648,slow:1curl http://localhost:8084/stat 0.01s user 0.01s system 0% cpu 20.937 total使用 jstack 工具 dump 堆栈。首先使用 jps 命令找到进程号,然后把结果重定向到文件(可以参考 10271.jstack 文件)。
过滤一下 nio 关键字,可以查看 tomcat 相关的线程,足足有 200 个,这和 Spring Boot 默认的 maxThreads 个数不谋而合。更要命的是,有大多数线程,都处于 BLOCKED 状态,说明线程等待资源超时。
bash
cat 10271.jstack |grep http-nio-80 -A 3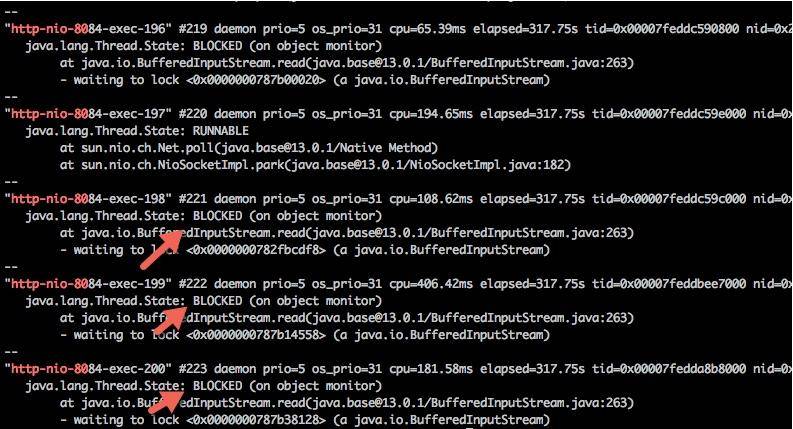
使用脚本分析,发现有大量的线程阻塞在 fast 方法上。我们上面也说过,这是一个假象,可能你到了这一步,会心生存疑,以至于无法再向下分析。
bash
$ cat 10271.jstack |grep fast | wc -l
137
$ cat 10271.jstack |grep slow | wc -l
63分析栈信息,你可能会直接查找 locked 关键字,如下图所示,但是这样的方法一般没什么用,我们需要做更多的统计。
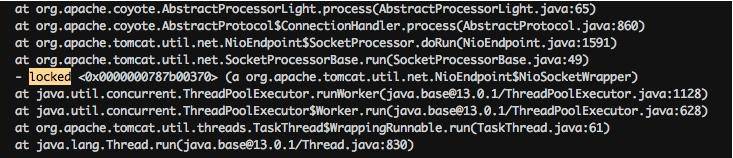
注意下图中有一个处于 BLOCKED 状态的线程,它阻塞在对锁的获取上(wating to lock)。大体浏览一下 DUMP 文件,会发现多处这种状态的线程,可以使用如下脚本进行统计。
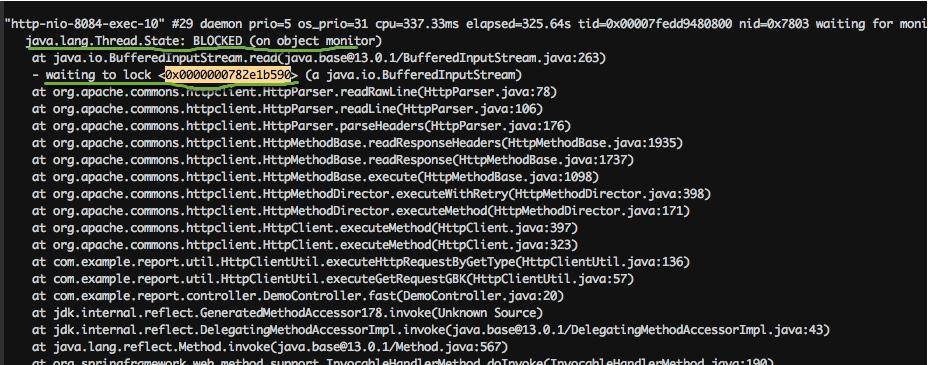
bash
cat 10271.tdump| grep "waiting to lock " | awk '{print $5}' | sort | uniq -c | sort -k1 -r
26 <0x0000000782e1b590>
18 <0x0000000787b00448>
16 <0x0000000787b38128>
10 <0x0000000787b14558>
8 <0x0000000787b25060>
4 <0x0000000787b2da18>
4 <0x0000000787b00020>
2 <0x0000000787b6e8e8>
2 <0x0000000787b03328>
2 <0x0000000782e8a660>
1 <0x0000000787b6ab18>
1 <0x0000000787b2ae00>
1 <0x0000000787b0d6c0>
1 <0x0000000787b073b8>
1 <0x0000000782fbcdf8>
1 <0x0000000782e11200>
1 <0x0000000782dfdae0>我们找到给 0x0000000782e1b590 上锁的执行栈,可以发现全部卡在了 HttpClient 的读操作上。在实际场景中,可以看下排行比较靠前的几个锁地址,找一下共性。
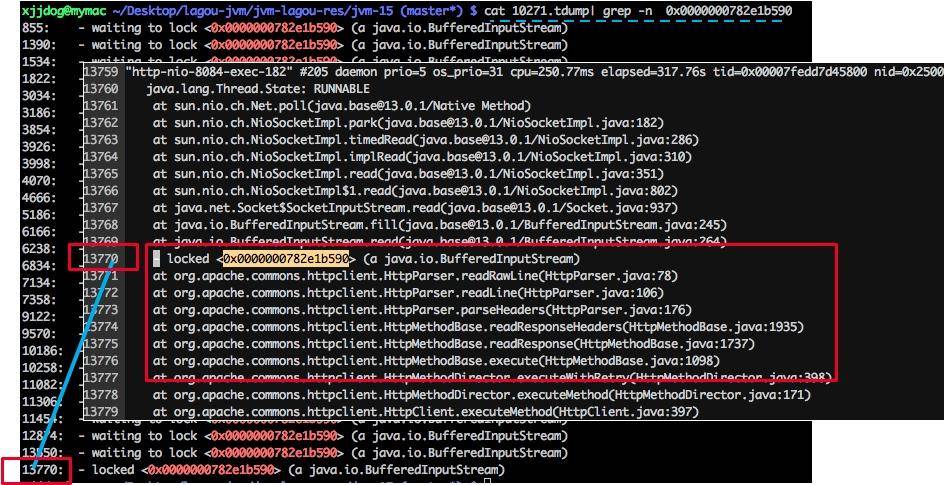
返回头去再看一下代码。我们发现 HttpClient 是共用了一个连接池,当连接数超过 100 的时候,就会阻塞等待。它的连接超时时间是 10 秒,这和 slow 接口的耗时不相上下。
java
private final static HttpConnectionManager httpConnectionManager = new SimpleHttpConnectionManager(true);
static {
HttpConnectionManagerParams params = new HttpConnectionManagerParams();
params.setMaxTotalConnections(100);
params.setConnectionTimeout(1000 * 10);
params.setSoTimeout(defaultTimeout);
httpConnectionManager.setParams(params);
}slow 接口和 fast 接口同时在争抢这些连接,让它时刻处在饱满的状态,进而让 tomcat 的线程等待、占满,造成服务不可用。
问题找到了,解决方式就简单多了。我们希望 slow 接口在阻塞的时候,并不影响 fast 接口的运行。这就可以对某一类接口进行限流,或者对不重要的接口进行熔断处理,这里不再深入讲解(具体可参考 Spring Boot 的限流熔断处理)。
现实情况是,对于一个运行的系统,我们并不知道是 slow 接口慢还是 fast 接口慢,这就需要加入一些额外的日志信息进行排查。当然,如果有一个监控系统能够看到这些数据是再好不过了。
项目中的 HttpClientUtil2 文件,是改造后的一个版本。除了调大了连接数,它还使用了多线程版本的连接管理器(MultiThreadedHttpConnectionManager),这个管理器根据请求的 host 进行划分,每个 host 的最大连接数不超过 20。还提供了 getConnectionsInPool 函数,用于查看当前连接池的统计信息。采用这些辅助的手段,可以快速找到问题服务,这是典型的情况。由于其他应用的服务水平低而引起的连锁反应,一般的做法是熔断、限流等,在此不多做介绍了。
jstack 产生的信息
为了观测一些状态,我上传了几个 Java 类,你可以实际运行一下,然后使用 jstack 来看一下它的状态。
waiting on condition
示例参见 SleepDemo.java。
java
public class SleepDemo {
public static void main(String[] args) {
new Thread(() -> {
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "sleep-demo").start();
}
}这个状态出现在线程等待某个条件的发生,来把自己唤醒,或者调用了 sleep 函数,常见的情况就是等待网络读写,或者等待数据 I/O。如果发现大多数线程都处于这种状态,证明后面的资源遇到了瓶颈。
此时线程状态大致分为以下两种:
-
java.lang.Thread.State: WAITING (parking):一直等待条件发生;
-
java.lang.Thread.State: TIMED_WAITING (parking 或 sleeping):定时的,即使条件不触发,也将定时唤醒。
"sleep-demo" #12 prio=5 os_prio=31 cpu=0.23ms elapsed=87.49s tid=0x00007fc7a7965000 nid=0x6003 waiting on condition [0x000070000756d000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(java.base@13.0.1/Native Method)
at SleepDemo.lambdamain0(SleepDemo.java:5)
at SleepDemo$$Lambda$16/0x0000000800b45040.run(Unknown Source)
at java.lang.Thread.run(java.base@13.0.1/Thread.java:830)
值的注意的是,Java 中的可重入锁,也会让线程进入这种状态,但通常带有 parking 字样,parking 指线程处于挂起中,要注意区别。代码可参见 LockDemo.java:
java
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LockDemo {
public static void main(String[] args) {
Lock lock = new ReentrantLock();
lock.lock();
new Thread(() -> {
try {
lock.lock();
} finally {
lock.unlock();
}
}, "lock-demo").start();
}
}堆栈代码如下:
"lock-demo" #12 prio=5 os_prio=31 cpu=0.78ms elapsed=14.62s tid=0x00007ffc0b949000 nid=0x9f03 waiting on condition [0x0000700005826000]
java.lang.Thread.State: WAITING (parking)
at jdk.internal.misc.Unsafe.park(java.base@13.0.1/Native Method)
- parking to wait for <0x0000000787cf0dd8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
at java.util.concurrent.locks.LockSupport.park(java.base@13.0.1/LockSupport.java:194)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(java.base@13.0.1/AbstractQueuedSynchronizer.java:885)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireQueued(java.base@13.0.1/AbstractQueuedSynchronizer.java:917)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquire(java.base@13.0.1/AbstractQueuedSynchronizer.java:1240)
at java.util.concurrent.locks.ReentrantLock.lock(java.base@13.0.1/ReentrantLock.java:267)
at LockDemo.lambda$main$0(LockDemo.java:11)
at LockDemo$$Lambda$14/0x0000000800b44840.run(Unknown Source)
at java.lang.Thread.run(java.base@13.0.1/Thread.java:830)waiting for monitor entry
我们上面提到的 HttpClient 例子,就是大部分处于这种状态,线程都是 BLOCKED 的。这意味着它们都在等待进入一个临界区,需要重点关注。
"http-nio-8084-exec-120" #143 daemon prio=5 os_prio=31 cpu=122.86ms elapsed=317.88s tid=0x00007fedd8381000 nid=0x1af03 waiting for monitor entry [0x00007000150e1000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.io.BufferedInputStream.read(java.base@13.0.1/BufferedInputStream.java:263)
- waiting to lock <0x0000000782e1b590> (a java.io.BufferedInputStream)
at org.apache.commons.httpclient.HttpParser.readRawLine(HttpParser.java:78)
at org.apache.commons.httpclient.HttpParser.readLine(HttpParser.java:106)
at org.apache.commons.httpclient.HttpConnection.readLine(HttpConnection.java:1116)
at org.apache.commons.httpclient.HttpMethodBase.readStatusLine(HttpMethodBase.java:1973)
at org.apache.commons.httpclient.HttpMethodBase.readResponse(HttpMethodBase.java:1735)in Object.wait()
示例代码参见 WaitDemo.java:
java
public class WaitDemo {
public static void main(String[] args) throws Exception {
Object o = new Object();
new Thread(() -> {
try {
synchronized (o) {
o.wait();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "wait-demo").start();
Thread.sleep(1000);
synchronized (o) {
o.wait();
}
}
}说明在获得了监视器之后,又调用了 java.lang.Object.wait() 方法。
关于这部分的原理,可以参见一张经典的图。每个监视器(Monitor)在某个时刻,只能被一个线程拥有,该线程就是"Active Thread",而其他线程都是"Waiting Thread",分别在两个队列"Entry Set"和"Wait Set"里面等候。在"Entry Set"中等待的线程状态是"Waiting for monitor entry",而在"Wait Set"中等待的线程状态是"in Object.wait()"。
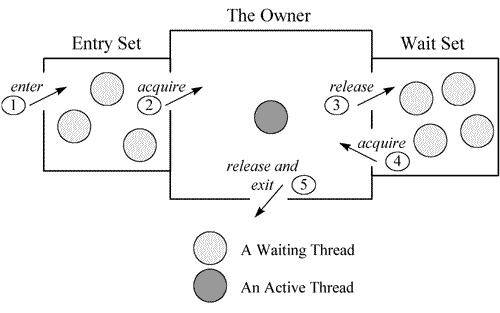
"wait-demo" #12 prio=5 os_prio=31 cpu=0.14ms elapsed=12.58s tid=0x00007fb66609e000 nid=0x6103 in Object.wait() [0x000070000f2bd000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(java.base@13.0.1/Native Method)
- waiting on <0x0000000787b48300> (a java.lang.Object)
at java.lang.Object.wait(java.base@13.0.1/Object.java:326)
at WaitDemo.lambda$main$0(WaitDemo.java:7)
- locked <0x0000000787b48300> (a java.lang.Object)
at WaitDemo$$Lambda$14/0x0000000800b44840.run(Unknown Source)
at java.lang.Thread.run(java.base@13.0.1/Thread.java:830)死锁
代码参见 DeadLock.java:
java
public class DeadLockDemo {
public static void main(String[] args) {
Object object1 = new Object();
Object object2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (object1) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (object2) {
}
}
}, "deadlock-demo-1");
t1.start();
Thread t2 = new Thread(() -> {
synchronized (object2) {
synchronized (object1) {
}
}
}, "deadlock-demo-2");
t2.start();
}
}死锁属于比较严重的一种情况,jstack 会以明显的信息进行提示。
Found one Java-level deadlock:
=============================
"deadlock-demo-1":
waiting to lock monitor 0x00007fe5e406f500 (object 0x0000000787cecd78, a java.lang.Object),
which is held by "deadlock-demo-2"
"deadlock-demo-2":
waiting to lock monitor 0x00007fe5e406d500 (object 0x0000000787cecd68, a java.lang.Object),
which is held by "deadlock-demo-1"
Java stack information for the threads listed above:
===================================================
"deadlock-demo-1":
at DeadLockDemo.lambda$main$0(DeadLockDemo.java:13)
- waiting to lock <0x0000000787cecd78> (a java.lang.Object)
- locked <0x0000000787cecd68> (a java.lang.Object)
at DeadLockDemo$$Lambda$14/0x0000000800b44c40.run(Unknown Source)
at java.lang.Thread.run(java.base@13.0.1/Thread.java:830)
"deadlock-demo-2":
at DeadLockDemo.lambda$main$1(DeadLockDemo.java:21)
- waiting to lock <0x0000000787cecd68> (a java.lang.Object)
- locked <0x0000000787cecd78> (a java.lang.Object)
at DeadLockDemo$$Lambda$16/0x0000000800b45040.run(Unknown Source)
at java.lang.Thread.run(java.base@13.0.1/Thread.java:830)
Found 1 deadlock当然,关于线程的 dump,也有一些线上分析工具可以使用。下图是 fastthread 的一个分析结果,但也需要你先了解这些情况发生的意义。
拿一个最简单的 Spring Boot 应用来说,请求会通过 Controller 层来接收数据,然后 Service 层会进行一些逻辑的封装,数据通过 Dao 层的 ORM 比如 JPA 或者 MyBatis 等,来调用底层的 JDBC 接口进行实际的数据获取。通常情况下,JVM 对这种数据获取方式,表现都是非常温和的。我们挨个看一下每一层可能出现的一些不正常的内存使用问题(仅限 JVM 相关问题),以便对平常工作中的性能分析和性能优化有一个整体的思路。
首先,我们提到一种可能,那就是类似于 Fastjson 工具所产生的 bug,这类问题只能通过升级依赖的包来解决,属于一种极端案例。具体可参考这里
Controller 层
Controller 层用于接收前端查询参数,然后构造查询结果。现在很多项目都采用前后端分离架构,所以 Controller 层的方法,一般使用 @ResponseBody 注解,把查询的结果,解析成 JSON 数据返回。
这在数据集非常大的情况下,会占用很多内存资源。假如结果集在解析成 JSON 之前,占用的内存是 10MB,那么在解析过程中,有可能会使用 20M 或者更多的内存去做这个工作。如果结果集有非常深的嵌套层次,或者引用了另外一个占用内存很大,且对于本次请求无意义的对象(比如非常大的 byte\[\] 对象),那这些序列化工具会让问题变得更加严重。
因此,对于一般的服务,保持结果集的精简,是非常有必要的,这也是 DTO(Data Transfer Object)存在的必要。如果你的项目,返回的结果结构比较复杂,对结果集进行一次转换是非常有必要的。互联网环境不怕小结果集的高并发请求,却非常恐惧大结果集的耗时请求,这是其中一方面的原因。
Service 层
Service 层用于处理具体的业务,更加贴合业务的功能需求。一个 Service,可能会被多个 Controller 层所使用,也可能会使用多个 dao 结构的查询结果进行计算、拼装。
Service 的问题主要是对底层资源的不合理使用。举个例子,有一回在一次代码 review 中,发现了下面让人无语的逻辑:
java
//错误代码示例
int getUserSize() {
List<User> users = dao.getAllUser();
return null == users ? 0 : users.size();
}这种代码,其实在一些现存的项目里大量存在,只不过由于项目规模和工期的原因,被隐藏了起来,成为内存问题的定时炸弹。
Service 层的另外一个问题就是,职责不清、代码混乱,以至于在发生故障的时候,让人无从下手。这种情况就更加常见了,比如使用了 Map 作为函数的入参,或者把多个接口的请求返回放在一个 Java 类中。
java
//错误代码示例
Object exec(Map<String, Object> params) {
String q = getString(params, "q");
if (q.equals("insertToa")) {
String q1 = getString(params, "q1");
String q2 = getString(params, "q2");
//do A
} else if (q.equals("getResources")) {
String q3 = getString(params, "q3");
//do B
}
...
return null;
}这种代码使用了万能参数和万能返回值,exec 函数会被几十个上百个接口调用,进行逻辑的分发。这种将逻辑揉在一起的代码块,当发生问题时,即使使用了 Jstack,也无法发现具体的调用关系,在平常的开发中,应该严格禁止。
ORM 层
ORM 层可能是发生内存问题最多的地方,除了本课时开始提到的 SQL 拼接问题,大多数是由于对这些 ORM 工具使用不当而引起的。
举个例子,在 JPA 中,如果加了一对多或者多对多的映射关系,而又没有开启懒加载、级联查询的时候就容易造成深层次的检索,内存的开销就超出了我们的期望,造成过度使用。
另外,JPA 可以通过使用缓存来减少 SQL 的查询,它默认开启了一级缓存,也就是 EntityManager 层的缓存(会话或事务缓存),如果你的事务非常的大,它会缓存很多不需要的数据;JPA 还可以通过一定的配置来完成二级缓存,也就是全局缓存,造成更多的内存占用。
一般,项目中用到缓存的地方,要特别小心。除了容易造成数据不一致之外,对堆内内存的使用也要格外关注。如果使用量过多,很容易造成频繁 GC,甚至内存溢出。
JPA 比起 MyBatis 等 ORM 拥有更多的特性,看起来容易使用,但精通门槛却比较高。
这并不代表 MyBatis 就没有内存问题,在这些 ORM 框架之中,存在着非常多的类型转换、数据拷贝。
举个例子,有一个批量导入服务,在 MyBatis 执行批量插入的时候,竟然产生了内存溢出,按道理这种插入操作是不会引起额外内存占用的,最后通过源码追踪到了问题。
这是因为 MyBatis 循环处理 batch 的时候,操作对象是数组,而我们在接口定义的时候,使用的是 List;当传入一个非常大的 List 时,它需要调用 List 的 toArray 方法将列表转换成数组(浅拷贝);在最后的拼装阶段,使用了 StringBuilder 来拼接最终的 SQL,所以实际使用的内存要比 List 多很多。
事实证明,不论是插入操作还是查询动作,只要涉及的数据集非常大,就容易出现问题。由于项目中众多框架的引入,想要分析这些具体的内存占用,就变得非常困难。保持小批量操作和结果集的干净,是一个非常好的习惯。
分库分表内存溢出
分库分表组件
如果数据库的记录非常多,达到千万或者亿级别,对于一个传统的 RDBMS 来说,最通用的解决方式就是分库分表。这也是海量数据的互联网公司必须面临的一个问题。
根据切入的层次,数据库中间件一般分为编码层、框架层、驱动层、代理层、实现层 5 大类。典型的框架有驱动层的 sharding-jdbc 和代理层的 MyCat。
MyCat 是一个独立部署的 Java 服务,它模拟了一个 MySQL 进行请求的处理,对于应用来说使用是透明的。而 sharding-jdbc 实际上是一个数据库驱动,或者说是一个 DataSource,它是作为 jar 包直接嵌入在客户端应用的,所以它的行为会直接影响到主应用。
这里所要说的分库分表组件,就是 sharding-jdbc。不管是普通 Spring 环境,还是 Spring Boot 环境,经过一系列配置之后,我们都可以像下面这种方式来使用 sharding-jdbc,应用层并不知晓底层实现的细节:
java
@Autowired
private DataSource dataSource;我们有一个线上订单应用,由于数据量过多的原因,进行了分库分表。但是在某些条件下,却经常发生内存溢出。
分库分表的内存溢出
一个最典型的内存溢出场景,就是在订单查询中使用了深分页,并且在查询的时候没有使用"切分键"。使用前面介绍的一些工具,比如 MAT、Jstack,最终追踪到是由于 sharding-jdbc 内部实现所引起的。
这个过程也是比较好理解的,如图所示,订单数据被存放在两个库中。如果没有提供切分键,查询语句就会被分发到所有的数据库中,这里的查询语句是 limit 10、offset 1000,最终结果只需要返回 10 条记录,但是数据库中间件要完成这种计算,则需要 (1000+10)*2=2020 条记录来完成这个计算过程。如果 offset 的值过大,使用的内存就会暴涨。虽然 sharding-jdbc 使用归并算法进行了一些优化,但在实际场景中,深分页仍然引起了内存和性能问题。
下面这一句简单的 SQL 语句,会产生严重的后果:
sql
select * from order order by updateTime desc limit 10 offset 10000这种在中间节点进行归并聚合的操作,在分布式框架中非常常见。比如在 ElasticSearch 中,就存在相似的数据获取逻辑,不加限制的深分页,同样会造成 ES 的内存问题。
另外一种情况,就是我们在进行一些复杂查询的时候,发现分页失效了,每次都是取出全部的数据。最后根据 Jstack,定位到具体的执行逻辑,发现分页被重写了。
java
private void appendLimitRowCount(final SQLBuilder sqlBuilder, final RowCountToken rowCountToken, final int count, final List<SQLToken> sqlTokens, final boolean isRewrite) {
SelectStatement selectStatement = (SelectStatement) sqlStatement;
Limit limit = selectStatement.getLimit();
if (!isRewrite) {
sqlBuilder.appendLiterals(String.valueOf(rowCountToken.getRowCount()));
} else if ((!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) && !selectStatement.isSameGroupByAndOrderByItems()) {
sqlBuilder.appendLiterals(String.valueOf(Integer.MAX_VALUE));
} else {
sqlBuilder.appendLiterals(String.valueOf(limit.isNeedRewriteRowCount() ? rowCountToken.getRowCount() + limit.getOffsetValue() : rowCountToken.getRowCount()));
}
int beginPosition = rowCountToken.getBeginPosition() + String.valueOf(rowCountToken.getRowCount()).length();
appendRest(sqlBuilder, count, sqlTokens, beginPosition);
}如上代码,在进入一些复杂的条件判断时(参照 SQLRewriteEngine.java),分页被重置为 Integer.MAX_VALUE。
总结
本课时以 Spring Boot 项目常见的分层结构,介绍了每一层可能会引起的内存问题,我们把结论归结为一点,那就是保持输入集或者结果集的简洁。一次性获取非常多的数据,会让中间过程变得非常不可控。最后,我们分析了一个驱动层的数据库中间件,以及对内存使用的一些问题。
很多程序员把这些耗时又耗内存的操作,写了非常复杂的 SQL 语句,然后扔给最底层的数据库去解决,这种情况大多数认为换汤不换药,不过是把具体的问题冲突,转移到另一个场景而已。
小结
本课时主要介绍了一个处处有问题的报表系统,并逐步解决了它的 OOM 问题,同时定位到了拒绝服务的原因。
在研发资源不足的时候,我们简单粗暴的进行了硬件升级,并切换到了更加优秀的 G1 垃圾回收器,还通过代码手段进行了问题的根本解决:
- 缩减查询的字段,减少常驻内存的数据;
- 去掉不必要的、命中率低的堆内缓存,改为分布式缓存;
- 从产品层面限制了单次请求对内存的无限制使用。
在这个过程中,使用 MAT 分析堆数据进行问题代码定位,帮了大忙。代码优化的手段是最有效的,改造完毕后,可以节省更多的硬件资源。事实上,使用了 G1 垃圾回收器之后,那些乱七八糟的调优参数越来越少用了。
接下来,我们使用 jstack 分析了一个出现频率非常非常高的问题,主要是不同速度的接口在同一应用中的资源竞争问题,我们发现一些成熟的微服务框架,都会对这些资源进行限制和隔离。
最后,以 4 个简单的示例,展示了 jstack 输出内容的一些意义。代码都在 git 仓库里,你可以实际操作一下,希望对你有所帮助。
第16讲:案例分析:分库分表后,我的应用崩溃了
本课时我们主要分析一个案例,那就是分库分表后,我的应用崩溃了。
前面介绍了一种由于数据库查询语句拼接问题,而引起的一类内存溢出。下面将详细介绍一下这个过程。
假设我们有一个用户表,想要通过用户名来查询某个用户,一句简单的 SQL 语句即可:
sql
select * from user where fullname = "xxx" and other="other";为了达到动态拼接的效果,这句 SQL 语句被一位同事进行了如下修改。他的本意是,当 fullname 或者 other 传入为空的时候,动态去掉这些查询条件。这种写法,在 MyBaits 的配置文件中,也非常常见。
java
List<User> query(String fullname, String other) {
StringBuilder sb = new StringBuilder("select * from user where 1=1 ");
if (!StringUtils.isEmpty(fullname)) {
sb.append(" and fullname=");
sb.append(" \"" + fullname + "\"");
}
if (!StringUtils.isEmpty(other)) {
sb.append(" and other=");
sb.append(" \"" + other + "\"");
}
String sql = sb.toString();
...
}大多数情况下,这种写法是没有问题的,因为结果集合是可以控制的。但随着系统的运行,用户表的记录越来越多,当传入的 fullname 和 other 全部为空时,悲剧的事情发生了,SQL 被拼接成了如下的语句:
sql
select * from user where 1=1数据库中的所有记录,都会被查询出来,载入到 JVM 的内存中。由于数据库记录实在太多,直接把内存给撑爆了。
在工作中,由于这种原因引起的内存溢出,发生的频率非常高。通常的解决方式是强行加入分页功能,或者对一些必填的参数进行校验,但不总是有效。因为上面的示例仅展示了一个非常简单的 SQL 语句,而在实际工作中,这个 SQL 语句会非常长,每个条件对结果集的影响也会非常大,在进行数据筛选的时候,一定要小心。
内存使用问题
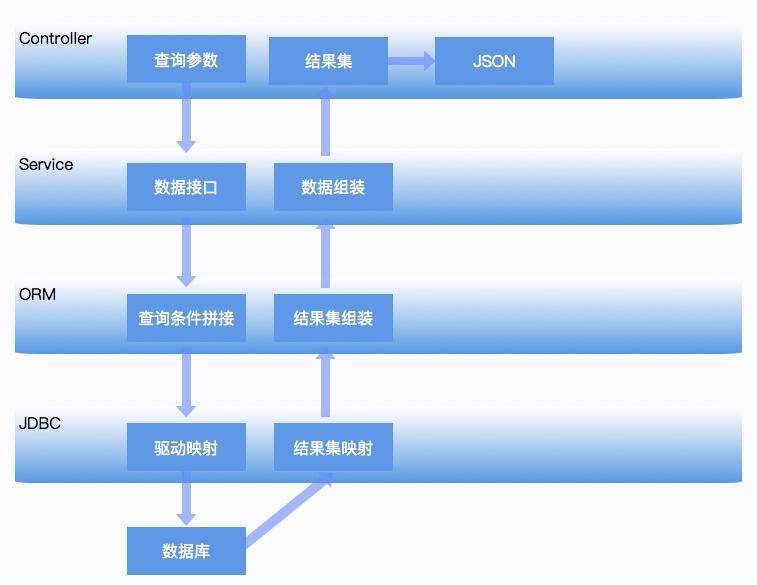
拿一个最简单的 Spring Boot 应用来说,请求会通过 Controller 层来接收数据,然后 Service 层会进行一些逻辑的封装,数据通过 Dao 层的 ORM 比如 JPA 或者 MyBatis 等,来调用底层的 JDBC 接口进行实际的数据获取。通常情况下,JVM 对这种数据获取方式,表现都是非常温和的。我们挨个看一下每一层可能出现的一些不正常的内存使用问题(仅限 JVM 相关问题),以便对平常工作中的性能分析和性能优化有一个整体的思路。
首先,我们提到一种可能,那就是类似于 Fastjson 工具所产生的 bug,这类问题只能通过升级依赖的包来解决,属于一种极端案例。具体可参考这里
Controller 层
Controller 层用于接收前端查询参数,然后构造查询结果。现在很多项目都采用前后端分离架构,所以 Controller 层的方法,一般使用 @ResponseBody 注解,把查询的结果,解析成 JSON 数据返回。
这在数据集非常大的情况下,会占用很多内存资源。假如结果集在解析成 JSON 之前,占用的内存是 10MB,那么在解析过程中,有可能会使用 20M 或者更多的内存去做这个工作。如果结果集有非常深的嵌套层次,或者引用了另外一个占用内存很大,且对于本次请求无意义的对象(比如非常大的 byte\[\] 对象),那这些序列化工具会让问题变得更加严重。
因此,对于一般的服务,保持结果集的精简,是非常有必要的,这也是 DTO(Data Transfer Object)存在的必要。如果你的项目,返回的结果结构比较复杂,对结果集进行一次转换是非常有必要的。互联网环境不怕小结果集的高并发请求,却非常恐惧大结果集的耗时请求,这是其中一方面的原因。
Service 层
Service 层用于处理具体的业务,更加贴合业务的功能需求。一个 Service,可能会被多个 Controller 层所使用,也可能会使用多个 dao 结构的查询结果进行计算、拼装。
Service 的问题主要是对底层资源的不合理使用。举个例子,有一回在一次代码 review 中,发现了下面让人无语的逻辑:
java
//错误代码示例
int getUserSize() {
List<User> users = dao.getAllUser();
return null == users ? 0 : users.size();
}这种代码,其实在一些现存的项目里大量存在,只不过由于项目规模和工期的原因,被隐藏了起来,成为内存问题的定时炸弹。
Service 层的另外一个问题就是,职责不清、代码混乱,以至于在发生故障的时候,让人无从下手。这种情况就更加常见了,比如使用了 Map 作为函数的入参,或者把多个接口的请求返回放在一个 Java 类中。
java
//错误代码示例
Object exec(Map<String, Object> params) {
String q = getString(params, "q");
if (q.equals("insertToa")) {
String q1 = getString(params, "q1");
String q2 = getString(params, "q2");
//do A
} else if (q.equals("getResources")) {
String q3 = getString(params, "q3");
//do B
}
...
return null;
}这种代码使用了万能参数和万能返回值,exec 函数会被几十个上百个接口调用,进行逻辑的分发。这种将逻辑揉在一起的代码块,当发生问题时,即使使用了 Jstack,也无法发现具体的调用关系,在平常的开发中,应该严格禁止。
ORM 层
ORM 层可能是发生内存问题最多的地方,除了本课时开始提到的 SQL 拼接问题,大多数是由于对这些 ORM 工具使用不当而引起的。
举个例子,在 JPA 中,如果加了一对多或者多对多的映射关系,而又没有开启懒加载、级联查询的时候就容易造成深层次的检索,内存的开销就超出了我们的期望,造成过度使用。
另外,JPA 可以通过使用缓存来减少 SQL 的查询,它默认开启了一级缓存,也就是 EntityManager 层的缓存(会话或事务缓存),如果你的事务非常的大,它会缓存很多不需要的数据;JPA 还可以通过一定的配置来完成二级缓存,也就是全局缓存,造成更多的内存占用。
一般,项目中用到缓存的地方,要特别小心。除了容易造成数据不一致之外,对堆内内存的使用也要格外关注。如果使用量过多,很容易造成频繁 GC,甚至内存溢出。
JPA 比起 MyBatis 等 ORM 拥有更多的特性,看起来容易使用,但精通门槛却比较高。
这并不代表 MyBatis 就没有内存问题,在这些 ORM 框架之中,存在着非常多的类型转换、数据拷贝。
举个例子,有一个批量导入服务,在 MyBatis 执行批量插入的时候,竟然产生了内存溢出,按道理这种插入操作是不会引起额外内存占用的,最后通过源码追踪到了问题。
这是因为 MyBatis 循环处理 batch 的时候,操作对象是数组,而我们在接口定义的时候,使用的是 List;当传入一个非常大的 List 时,它需要调用 List 的 toArray 方法将列表转换成数组(浅拷贝);在最后的拼装阶段,使用了 StringBuilder 来拼接最终的 SQL,所以实际使用的内存要比 List 多很多。
事实证明,不论是插入操作还是查询动作,只要涉及的数据集非常大,就容易出现问题。由于项目中众多框架的引入,想要分析这些具体的内存占用,就变得非常困难。保持小批量操作和结果集的干净,是一个非常好的习惯。
分库分表内存溢出
分库分表组件
如果数据库的记录非常多,达到千万或者亿级别,对于一个传统的 RDBMS 来说,最通用的解决方式就是分库分表。这也是海量数据的互联网公司必须面临的一个问题。
根据切入的层次,数据库中间件一般分为编码层、框架层、驱动层、代理层、实现层 5 大类。典型的框架有驱动层的 sharding-jdbc 和代理层的 MyCat。
MyCat 是一个独立部署的 Java 服务,它模拟了一个 MySQL 进行请求的处理,对于应用来说使用是透明的。而 sharding-jdbc 实际上是一个数据库驱动,或者说是一个 DataSource,它是作为 jar 包直接嵌入在客户端应用的,所以它的行为会直接影响到主应用。
这里所要说的分库分表组件,就是 sharding-jdbc。不管是普通 Spring 环境,还是 Spring Boot 环境,经过一系列配置之后,我们都可以像下面这种方式来使用 sharding-jdbc,应用层并不知晓底层实现的细节:
java
@Autowired
private DataSource dataSource;我们有一个线上订单应用,由于数据量过多的原因,进行了分库分表。但是在某些条件下,却经常发生内存溢出。
分库分表的内存溢出
一个最典型的内存溢出场景,就是在订单查询中使用了深分页,并且在查询的时候没有使用"切分键"。使用前面介绍的一些工具,比如 MAT、Jstack,最终追踪到是由于 sharding-jdbc 内部实现所引起的。
这个过程也是比较好理解的,如图所示,订单数据被存放在两个库中。如果没有提供切分键,查询语句就会被分发到所有的数据库中,这里的查询语句是 limit 10、offset 1000,最终结果只需要返回 10 条记录,但是数据库中间件要完成这种计算,则需要 (1000+10)*2=2020 条记录来完成这个计算过程。如果 offset 的值过大,使用的内存就会暴涨。虽然 sharding-jdbc 使用归并算法进行了一些优化,但在实际场景中,深分页仍然引起了内存和性能问题。
下面这一句简单的 SQL 语句,会产生严重的后果:
sql
select * from order order by updateTime desc limit 10 offset 10000这种在中间节点进行归并聚合的操作,在分布式框架中非常常见。比如在 ElasticSearch 中,就存在相似的数据获取逻辑,不加限制的深分页,同样会造成 ES 的内存问题。
另外一种情况,就是我们在进行一些复杂查询的时候,发现分页失效了,每次都是取出全部的数据。最后根据 Jstack,定位到具体的执行逻辑,发现分页被重写了。
java
private void appendLimitRowCount(final SQLBuilder sqlBuilder, final RowCountToken rowCountToken, final int count, final List<SQLToken> sqlTokens, final boolean isRewrite) {
SelectStatement selectStatement = (SelectStatement) sqlStatement;
Limit limit = selectStatement.getLimit();
if (!isRewrite) {
sqlBuilder.appendLiterals(String.valueOf(rowCountToken.getRowCount()));
} else if ((!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) && !selectStatement.isSameGroupByAndOrderByItems()) {
sqlBuilder.appendLiterals(String.valueOf(Integer.MAX_VALUE));
} else {
sqlBuilder.appendLiterals(String.valueOf(limit.isNeedRewriteRowCount() ? rowCountToken.getRowCount() + limit.getOffsetValue() : rowCountToken.getRowCount()));
}
int beginPosition = rowCountToken.getBeginPosition() + String.valueOf(rowCountToken.getRowCount()).length();
appendRest(sqlBuilder, count, sqlTokens, beginPosition);
}如上代码,在进入一些复杂的条件判断时(参照 SQLRewriteEngine.java),分页被重置为 Integer.MAX_VALUE。
总结
本课时以 Spring Boot 项目常见的分层结构,介绍了每一层可能会引起的内存问题,我们把结论归结为一点,那就是保持输入集或者结果集的简洁。一次性获取非常多的数据,会让中间过程变得非常不可控。最后,我们分析了一个驱动层的数据库中间件,以及对内存使用的一些问题。
很多程序员把这些耗时又耗内存的操作,写了非常复杂的 SQL 语句,然后扔给最底层的数据库去解决,这种情况大多数认为换汤不换药,不过是把具体的问题冲突,转移到另一个场景而已。