背景
在业务中,我们通常会访问数据库(DB)或远程服务(API)来获取数据,这些访问:
- 延迟高(I/O开销大)
- 数据变化不频繁
- 多次重复查询相同的数据
针对这些数据我们可以进行缓存,减少对数据库的查询次数,减轻数据库的访问压力。但是在不同的场景下缓存实现的是方式也各有不同。所以记录一下常见的缓存实现方式叭~
常见的缓存实现方式
线程级缓存(ThreadLocal)
当前线程独有,随着线程销毁,不同线程下不共享。
知识点
1.ThreadLocal内部关系图

每一个线程内部都有一个ThreadLocalMap
ThreadLocalMap的key是对
ThreadLocal的弱引用value是你存进去的实际数据(强引用)
不同线程的ThreadLocalMap相互独立,不共享
2.内存泄漏
当 ThreadLocal 对象被 GC 了
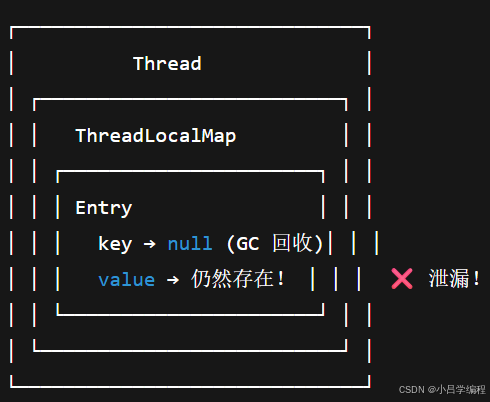
key 变成 null(因为是弱引用被 GC 回收)
value 还在内存中(因为 ThreadLocalMap 还在当前线程中)
若线程是线程池管理(长生命周期),value 就永远不会释放
应当在业务处理完之后调用remove()方法
3.线程的生命周期
在典型的web应用(springboot)中,每一个用户请求都会分配一个独立的线程来执行。
不同用户 → 不同线程 → 各自独立运行递归 → 各自拥有独立的
ThreadLocal缓存空间
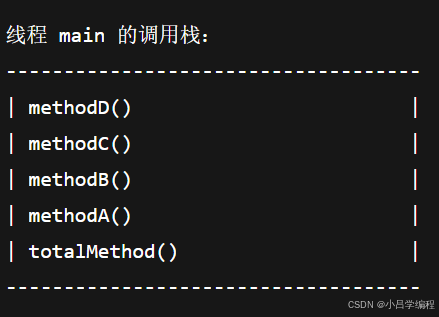
方法之间涉及调用或者递归调用自己都是在一个线程里面,调用过程中只是函数调用栈的变化,例如
java
public class DemoService {
public void totalMethod() {
methodA();
methodB();
methodC();
methodD();
}
private void methodA() { ... }
private void methodB() { ... }
private void methodC() { ... }
private void methodD() { ... }
}当执行:
java
new DemoService().totalMethod();在这个过程中:
所有的这些方法(totalMethod、methodA、methodB...)都是在同一个线程里顺序执行的。
调用过程只是函数调用栈的变化,不会创建新线程。
4.什么时候才会有多个线程
显示创建线程或线程池中执行才会在不同的线程中执行
| 场景 | 是否多线程 | 执行方式 | 调用关系 |
|---|---|---|---|
| 普通调用(方法里互相调用) | ❌ 否 | 同一线程内,顺序执行 | 依次入栈出栈 |
| 递归调用 | ❌ 否 | 同一线程内,多层入栈 | 自己调用自己 |
new Thread(...) |
✅ 是 | 不同线程并发执行 | 各自独立 |
线程池 / CompletableFuture |
✅ 是 | 不同线程并发执行 | 异步 |
应用场景
当我们了解了ThreadLocal基本知识点后,就可以开始利用它的特点进行线程级别的缓存啦。当涉及线程级别的缓存,同时在同线程下多次查询相同的数据的。
实现方式
java
//1.初始化一个ThreadLocal对象
private static final ThreadLocal<Map<Long, List<Benefit>>> BENEFIT_CACHE = ThreadLocal.withInitial(HashMap::new);
//2.从ThreadLocal对象里面取出数据,无则直接返回,有则新增
list = BENEFIT_CACHE.get().computeIfAbsent(customBenefit.getId(), k -> lambdaQuery().in(Benefit::getId, benefitIds).list());
//3.如果有递归
unpacking(current.getIncludes(), current, benefits, depth + 1);
//4. 递归深度 == 0时 清空ThreadLocal
if (depth == 0) { BENEFIT_CACHE.remove(); }本地缓存
本地缓存应该是我们最常用一种方式,应用场景也比较多,大多数是通过map进行实现的。存储位置在JVM内存中,随着应用进程销毁,不同线程可共享。
分布式缓存
当涉及跨服务之间的数据共享的场景下,使用分布式缓存就比较合适了。常用的缓存方式就是通过redis实现了,长期存在,可过期。
总结
每个缓存适应的场景不同,可以在不同的情况下使用不同的缓存方式,来减轻I/O消耗,减轻数据库的访问压力
| 缓存方式 | 存储位置 | 生命周期 | 并发访问 | 常用场景 |
|---|---|---|---|---|
| 本地缓存(Local Cache) | JVM 内存(如 Map、ThreadLocal、Guava Cache) |
随应用进程销毁 | 线程内共享(可加锁) | 单机服务、小数据量、低延迟查询 |
| 分布式缓存(Distributed Cache) | 独立服务(如 Redis、Memcached) | 长期存在,可过期 | 多线程/多实例共享 | 大型系统、微服务集群间共享数据 |
| 线程级缓存(ThreadLocal) | 当前线程独有 | 随线程销毁 | 不同线程不共享 | 临时缓存,如递归、批量操作 |