何为RAG
检索增强生成(Retrieval Augmented Generation,简称 RAG)是一种先进的自然语言处理技术,旨在进一步提升大语言模型的输出质量和可靠性。该技术通过整合信息检索功能,将用户查询与向量数据库进行精准匹配,从而为用户提供了更加准确和可信的答案,有效减轻了大型模型在生成回答时可能出现的"幻觉"现象。
RAG的工作原理基于一个简单而强大的流程:在LLM生成答案前,先从一个外部知识库中检索出与用户查询最相关的片段,然后将这些检索结果作为额外的上下文信息与原始查询一起输入给LLM,指导LLM生成更准确、更丰富、更具时效性的回答。
简单来讲就是 :RAG=LLM+外部知识
与LLM的联系
下面通过一个图片介绍LLM与RAG的相互作用
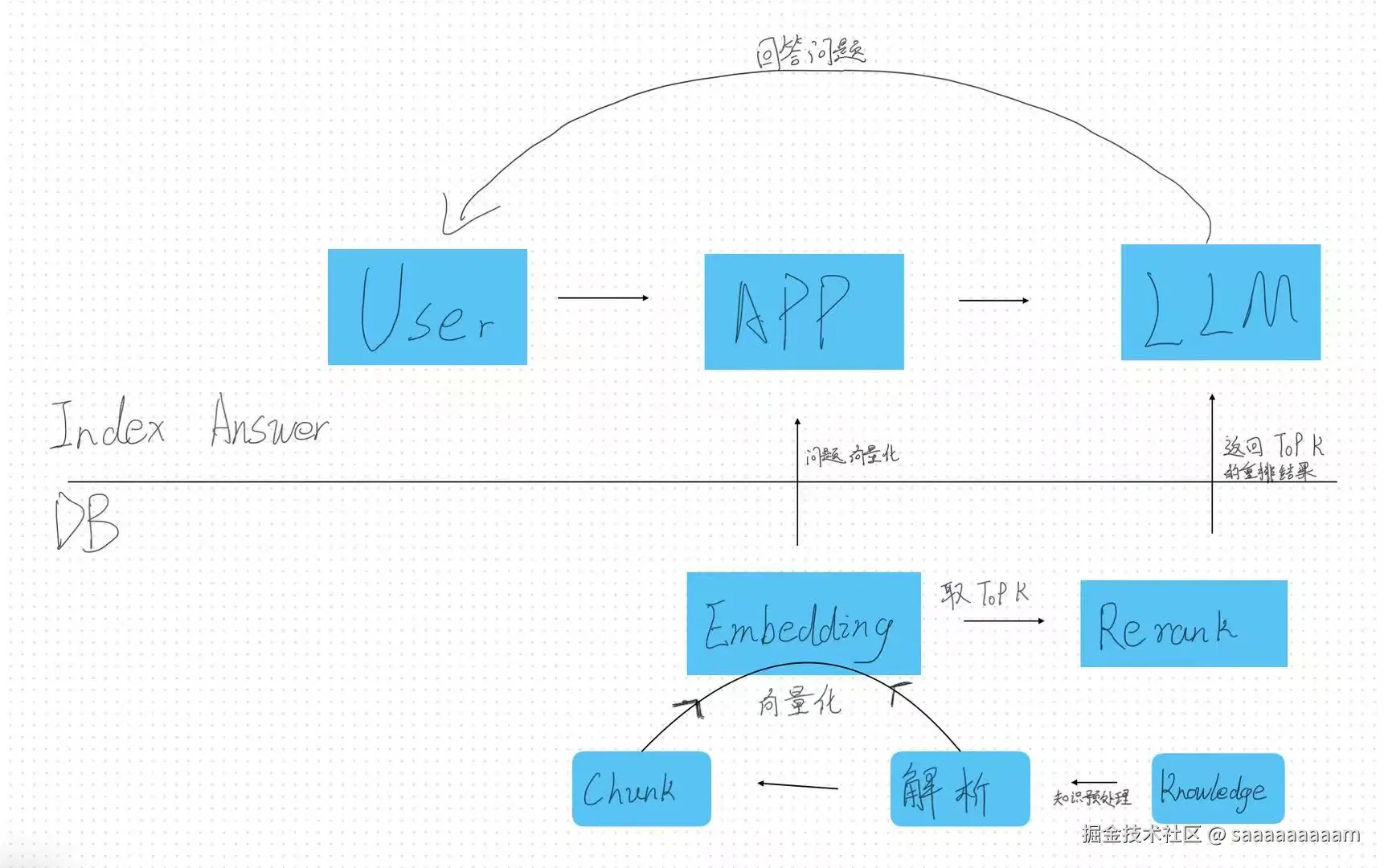
总归而言RAG技术的核心流程通常包含三个主要阶段:
- 索引(Indexing) :将外部知识源(如文档、网页、数据库)处理成可检索的形式,通常涉及文本分块、生成向量嵌入,并存储在向量数据库中。
- 检索(Retrieval) :当用户提出问题时,系统将问题转换成查询向量,从索引中检索出最相关的知识片段。
- 生成(Generation) :将检索到的相关知识片段与原始问题一起提供给LLM,由LLM生成最终回答。
朴素RAG
设计之初时在2020,其严格按照 "索引->检索->生成" 的三阶段流程执行,显现的样式直接但也存在一定的局限性。
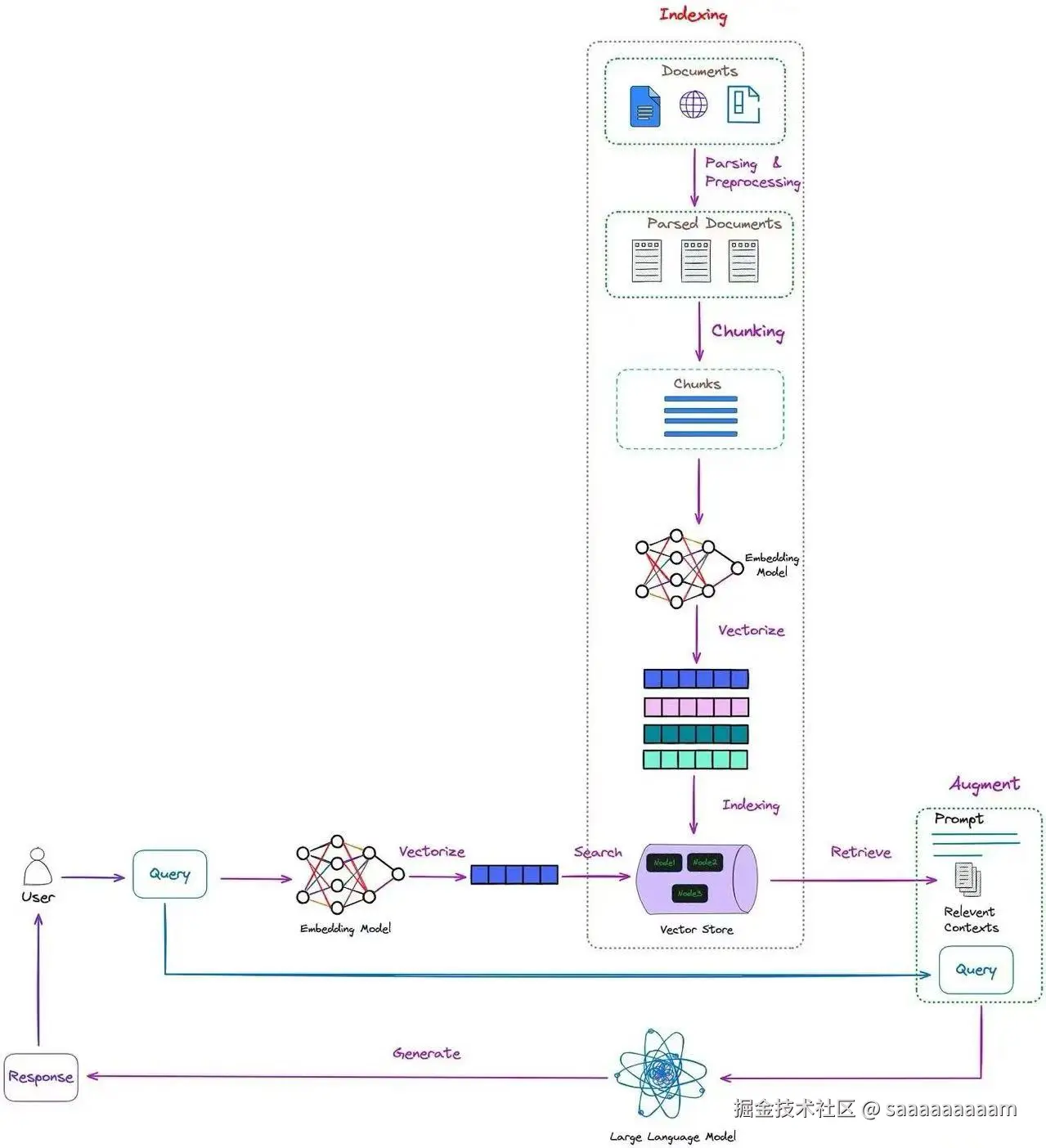
工作流程
朴素RAG的工作流程如下:
- 索引阶段:
- 把原始文档直接切分成固定尺寸的文本片段(chunks)
- 为每个文本片段生成向量表征(一般采用通用嵌入模型,例如OpenAI的text-embedding-ada-002)
- 将这些向量存入向量数据库(像Pinecone、Milvus等)
- 检索阶段:
- 把用户的查询转化为向量形式
- 借助向量相似性检索,找到最相似的前K个文本片段
- 直接返回这些文本片段,不做额外处理
- 生成阶段:
- 将检索到的文本片段和原始查询一同发送给大语言模型(LLM)
- LLM根据提供的上下文内容生成相应答案
局限性
-
噪声干扰:检索结果中可能包含与查询相关性不高的信息,干扰LLM的理解
-
检索冗余:多个检索结果可能包含重复信息,浪费有限的上下文窗口
-
复杂查询理解不足:对于复杂或含糊的查询,直接检索往往效果不佳
-
召回率有限:如果关键信息分散在多个文档中,简单检索可能遗漏重要内容
-
上下文窗口限制:LLM的上下文窗口有限,无法容纳过多检索结果
尽管存在这些局限性,朴素RAG作为一种基础实现,已经能够显著提升LLM回答特定领域问题的能力,尤其是在处理那些超出模型训练数据范围的问题时。但是人类的进步追求于精益求精,所以RAG技术随后进化出了更高级的形式。
示例
对应到Dify中的知识库中
索引阶段: 选择对文档表格等数据处理时使用通用分段方式,对每一个chunk都做相同大小分段处理 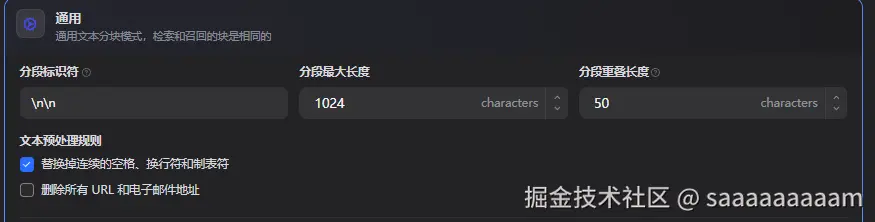
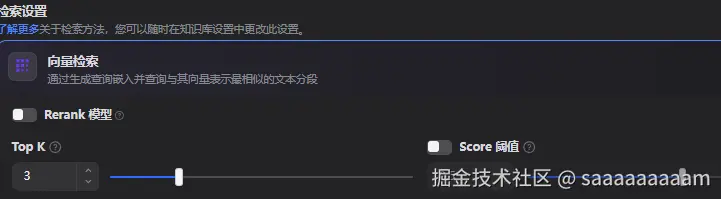
检索阶段: 单纯的使用向量检索,通过设置Top K以寻找与用户查询相似度最高的K个文本直接返回
进阶RAG
高级 RAG 是朴素 RAG 的深度优化版本,它并非对原有框架的颠覆,而是在 RAG 全流程的每个关键环节,都加入了针对性的进阶技术,以此大幅提升检索的精准度与最终生成内容的质量。与朴素 RAG 的线性流程不同,高级 RAG 在索引、检索、生成等各个阶段,都整合了更复杂、更具智能化的处理逻辑。
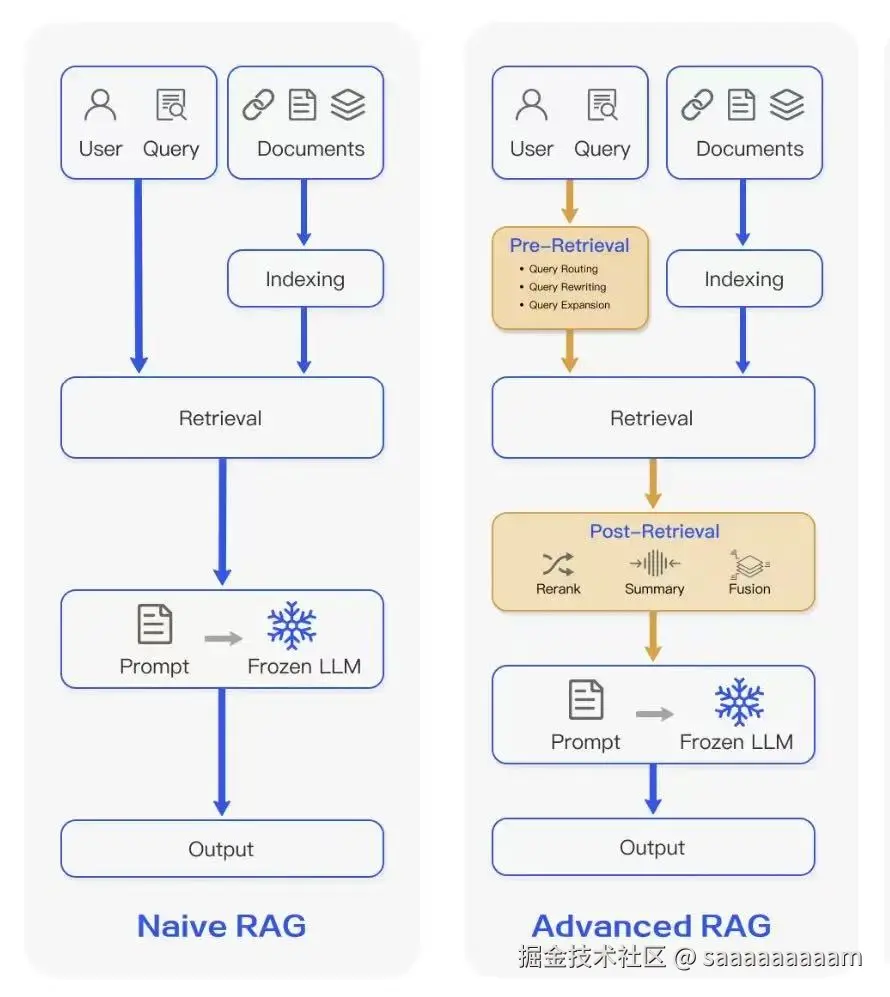
优化
预检索优化
-
查询重写(Query Rewriting)
使用LLM对原始查询进行改写,生成多个语义相似但表达不同的变体,增加检索到相关内容的概率。例如,将"股票市场今天怎么样?"改写为"今日股市表现如何?"和"最新的股票市场指数是多少?"
-
查询分解(Query Decomposition)
将复杂查询分解为多个简单子查询,分别检索后再整合结果。例如,"比较DeepSeek和豆包的擅长领域和调用成本"可分解为分别关于擅长领域和API成本的子查询。
-
智能索引优化
使用更先进的文档分块策略(如QA问答分块而非固定大小分块),为文档添加元数据标签,使用领域适应的嵌入模型等,提高索引质量。
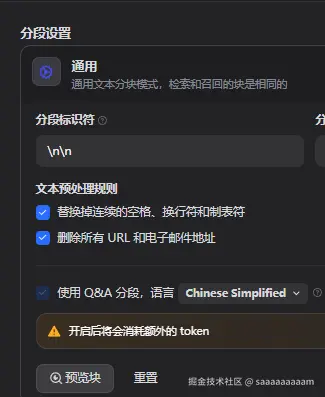
通过知识库设定QA分段,有助于LLM 更精确定位用户查询的内容以减少模型幻觉问题 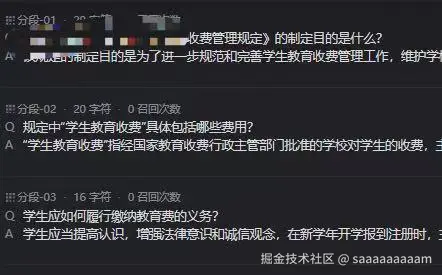
检索过程优化
-
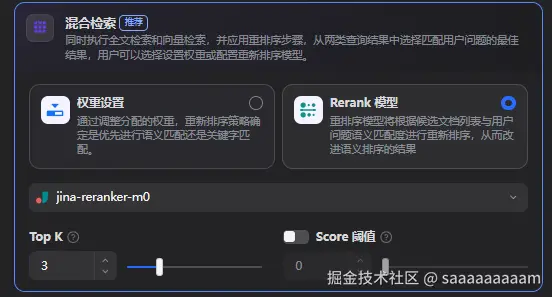
混合检索(Hybrid Search)
结合稠密检索(向量相似度)和稀疏检索(关键词匹配,如BM25算法),平衡语义理解和关键词精确匹配的优势。
-
多查询检索(Multi-Query Retrieval)
使用不同的查询变体并行检索,然后合并结果,提高查全率。
-
元数据过滤(Metadata Filtering) 基于文档的元数据(如时间、来源、主题分类等)进行检索范围限定,提高检索效率和相关性
不仅可以使用知识库自带的类似时间、关键词等元数据,还可以自定义强相关性的元数据来帮助模型更好完成查询任务。

后检索优化
-
重排序(Reranking)
使用更复杂的模型对初步检索结果进行二次评分和排序,将最相关的内容排在前面。例如,使用交叉编码器(Cross-encoder)模型评估查询与每个检索结果的精确匹配度。
-
冗余过滤(Redundancy Filtering)
检测并移除检索结果中的重复信息,优化上下文窗口利用。
-
提示压缩(Prompt Compression)
使用LLM提取检索结果的核心信息,生成更紧凑的摘要,以便在有限的上下文窗口中包含更多信息。
-
信息过滤与整合(Filtering and Synthesis)
根据相关性和重要性筛选信息,并将分散的信息整合成连贯的背景知识。
较朴素RAG的优势
高级RAG通过上述优化策略,成功解决了朴素RAG面临的主要问题,带来了一系列显著的性能提升:
-
更高的检索精度和召回率,确保找到最相关的信息
-
更有效利用有限的上下文窗口,避免浪费在冗余或不相关内容上
-
更好地理解复杂查询意图,提供更全面、准确的回答
-
能够处理多步推理问题,即使所需知识分散在多个文档中
-
生成更连贯、更相关、更准确的回答
RAG技术远不止于此剩下的交给大家去继续探索,理论知识总归是落实到实践的,唯有自己动手才能真正领悟RAG的真谛。