背景与问题发现
在日常开发中,我们经常需要进行结构体的深拷贝操作。在 Go 中,我们广泛使用github.com/jinzhu/copier 做深拷贝操作
然而,在一次偶然的基准测试中,我们发现了令人意外的结果:copier 的深拷贝性能竟然远低于通过 JSON 序列化/反序列化的方式。这一发现严重违背了我们的性能直觉,因为反射操作理应在理论上优于涉及数据编解码的序列化过程。
性能基准测试初步结果

测试数据显示,copier 在相同数据结构的深拷贝操作中,耗时和内存分配均显著高于 JSON 方式,这促使我们深入探究其根本原因。
问题根因分析
通过 go tool pprof 对 copier 进行性能剖析,我们发现性能瓶颈主要集中在反射操作上:
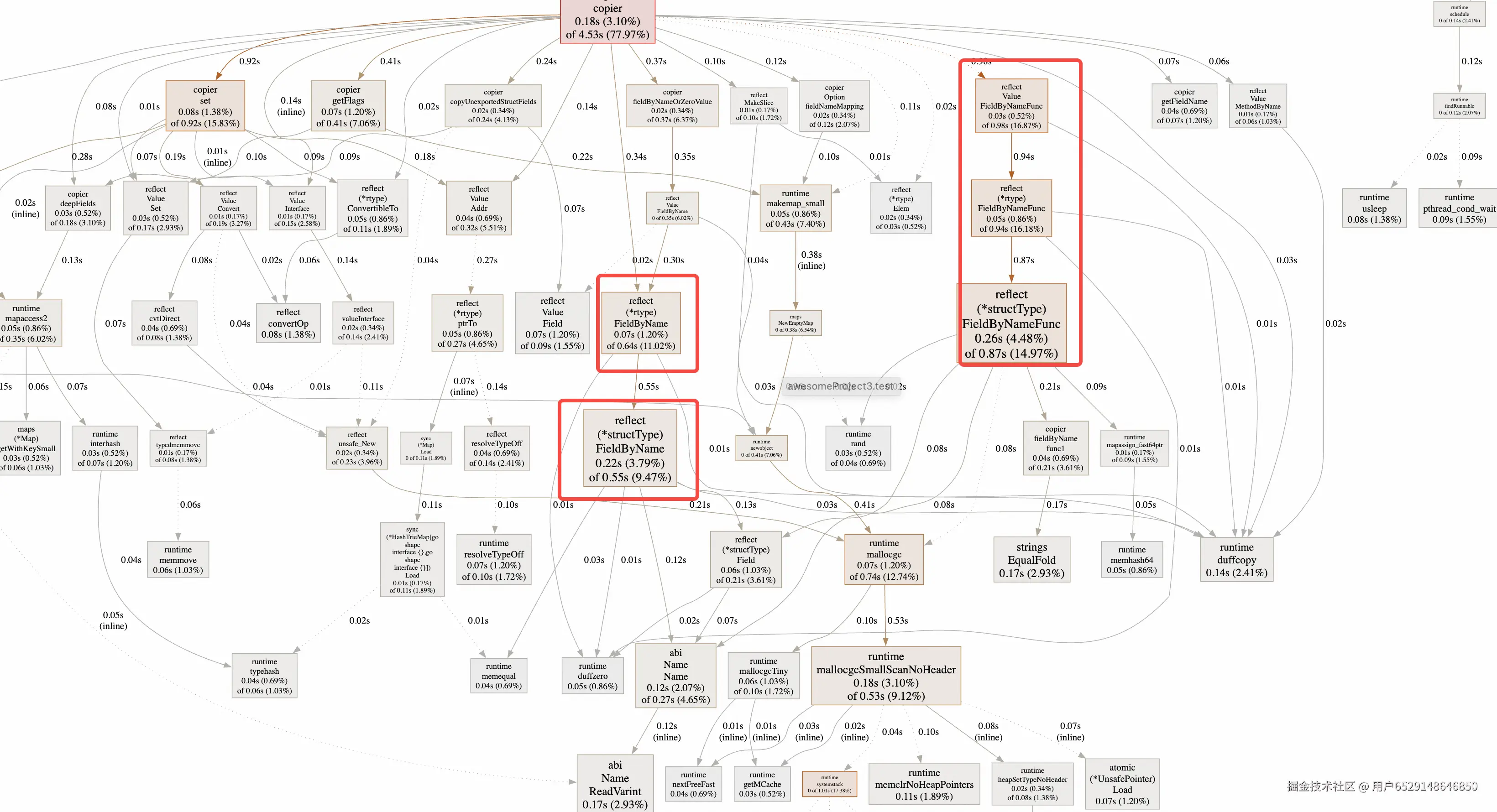
关键性能瓶颈
- 过度依赖反射机制:copier 大量使用
reflect包进行运行时类型检查和方法调用 - 频繁的
FieldByName调用:这是反射操作中特别耗时的部分,每次字段访问都需要遍历结构体 - 缺乏缓存机制:重复的类型解析和函数查找导致不必要的性能开销
优化方式
基于上述分析,我们决定从四个核心方向对 copier 库进行深度优化:
1、结构体反射结果缓存 - 避免重复的类型解析
众所周知,反射的性能比较差,因为反射将编译期的工作(类型检查、方法绑定、内存布局)转移到了运行时,并且无法享受编译器的任何优化。它带来了巨大的运行时类型检查开销、潜在的内存分配以及低效的方法调用。我们在第一次解析结构体结构的时候,可以尽可能多记一下结构体信息(名称,类型,偏移量等),缓存下来,之后需要再次解析的时候可以直接使用缓存数据,避免多次反射带来的性能损耗,FieldMap记录下名称到Field的映射,将O(N)的FieldByName优化成O(1)的map取值操作
go
func loadStructFieldsInfo(vt reflect2.Type) StructDescriptor {
if structInfo, ok := structInfoCache.Load(vt); ok {
return structInfo.(StructDescriptor)
}
structInfo := describeStruct(vt)
structInfo.FieldMap = make(map[string]*Binding, len(structInfo.Fields))
for i := 0; i < len(structInfo.Fields); i++ {
structInfo.FieldMap[structInfo.Fields[i].Name] = structInfo.Fields[i]
}
structInfoCache.Store(vt, structInfo)
return structInfo
}
type StructField struct {
// Name is the field name.
Name string
// PkgPath is the package path that qualifies a lower case (unexported)
// field name. It is empty for upper case (exported) field names.
// See https://golang.org/ref/spec#Uniqueness_of_identifiers
PkgPath string
Type Type // field type
Tag StructTag // field tag string
Offset uintptr // offset within struct, in bytes
Index []int // index sequence for Type.FieldByIndex
Anonymous bool // is an embedded field
}性能收益
- 字段查找:从 O(N) 遍历优化为 O(1) Map 查找
- 类型解析:每个类型只需解析一次,后续操作直接使用缓存
- 内存分配:减少重复的类型描述对象创建
2、指针直接读写优化 - 减少中间内存分配
反射获取数据的时候reflect.value.Interface()创建interface{}临时变量,然后通过类型强转转成指定类型,中间多了创建临时变量的内存过程。通过结构体指针和字段的偏移量,在读取数据的时候可以通过指针强行转换的方式(unsafe.Pointer)将其直接转换成所需要的值对象,省去反射过程。
但是reflect包中的类型和指针是私有变量,不对外漏出,可以使用三方反射包github.com/modern-go/reflect2,获取字段的类型和指针(也是通过unsafe.Pointer指针强行转换的方式获取类型和指针)
go
// 读
func (v Value) Int() int64 {
k := v.Typ.Kind()
p := v.Ptr
switch k {
case reflect.Int:
return int64(*(*int)(p))
case reflect.Int8:
return int64(*(*int8)(p))
case reflect.Int16:
return int64(*(*int16)(p))
case reflect.Int32:
return int64(*(*int32)(p))
case reflect.Int64:
return *(*int64)(p)
}
return 0
}
// 写
func (v Value) SetInt(x int64) {
switch k := v.Typ.Kind(); k {
case reflect.Int:
*(*int)(v.Ptr) = int(x)
case reflect.Int8:
*(*int8)(v.Ptr) = int8(x)
case reflect.Int16:
*(*int16)(v.Ptr) = int16(x)
case reflect.Int32:
*(*int32)(v.Ptr) = int32(x)
case reflect.Int64:
*(*int64)(v.Ptr) = x
}
}性能收益
- 零内存分配:直接操作目标内存,避免临时对象
3、转换函数缓存机制 - 加速类型转换决策
A和B类型相互转换的函数是确定的,可以将类型和转换函数的关系缓存下来,下一次需要确定转换函数时可以直接从缓存中读取转换函数,减少确定转换函数的过程
递归类型怎样处理?
借鉴标准库 encoding/json 的方案:
- 间接编码器:先注册一个占位函数,防止无限递归
- 等待组同步:确保实际函数初始化完成前,调用者正确等待
- 原子性更新:函数就绪后原子替换为实际实现
scss
func LoadConvertFunc(v, t reflect2.Type) ConvertFunc {
key := [2]uintptr{v.RType(), t.RType()}
if fi, ok := mFuncMap.Load(key); ok {
return fi.(rcuCacheInfo).ConvertFunc
}
var (
wg sync.WaitGroup
f ConvertFunc
)
wg.Add(1)
// 递归类型处理
fi, loaded := mFuncMap.LoadOrStore(key, rcuCacheInfo{
ConvertFunc: func(v, t rt.Value) error {
wg.Wait()
return f(v, t)
},
})
if loaded {
return fi.(rcuCacheInfo).ConvertFunc
}
f = convertOp(v, t)
wrapFunc := ConvertFunc(func(v rt.Value, t rt.Value) error {
if f == nil {
return ErrNotSupported
}
if v.Typ.UnsafeIsNil(v.Ptr) {
if t.Typ.Kind() == reflect.Ptr {
*((*unsafe.Pointer)(t.Ptr)) = nil
return nil
}
t.Typ.UnsafeSet(t.Ptr, t.Typ.UnsafeNew())
return nil
}
return f(v, t)
})
wg.Done()
mFuncMap.Store(key, rcuCacheInfo{ConvertFunc: wrapFunc})
return wrapFunc
}性能对比
关闭函数缓存

使用函数缓存

可以发现使用函数缓存后,耗时由3864 ns/op降低到3010 ns/op,内存分配次数由91 allocs/op降低到18 allocs/op,性能有明显提升
4、RCU 无锁读取优化 - 提升并发读取性能
函数缓存和结构体缓存是典型的读多写少场景,因此最初是使用sync.Map缓存数据,但是在读极多写极少的场景下RCU性能会优于sync.Map,因为对于sync.Map,在读数据最坏的情况下(键不在 read 中),需要加互斥锁去访问 dirty map,性能会急剧下降。RCU读取数据是完全不需要加锁的
RCU和sync.Map读取代码对比
go
//RCU
func (c *LinerRCU) Load(key reflect2.Type) (v any, ok bool) {
m := (*linerMap)(atomic.LoadPointer(&c.m))
res := m.get(key)
return res, res != nil
}
func (self *linerMap) get(vt reflect2.Type) any {
i := self.m + 1
h := uint32(vt.RType())
p := h & self.m
/* linear probing */
for ; i > 0; i-- {
if b := self.b[p]; b.vt == vt {
return b.fn
} else if b.vt == nil {
break
} else {
p = (p + 1) & self.m
}
}
/* not found */
return nil
}
arduino
//sync.Map
func (m *Map) Load(key any) (value any, ok bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
e, ok = m.dirty[key]
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
return e.load()
}性能对比
使用sync.Map

使用RCU
可以发现使用RCU后,耗时由3331 ns/op降低到3010 ns/op,性能有明显提升
结果对比
一、指标含义
ns/op:每次操作的耗时(纳秒),数值越小性能越好。B/op:每次操作的内存分配大小(字节),数值越小内存开销越低。allocs/op:每次操作的内存分配次数,数值越小内存分配效率越高。
二、性能对比
| 深拷贝方式 | 耗时(ns/op) | 内存大小(B/op) | 分配次数(allocs/op) | 性能总结 |
|---|---|---|---|---|
| copier-10 | 14039 | 4288 | 183 | 性能最差,内存和分配次数开销大 |
| go_deep_copy-10 | 3010 | 672 | 18 | 性能最优,耗时、内存、分配次数均表现最好 |
| json-10(JSON 序列化反序列化方式) | 5813 | 1641 | 37 | 性能居中,开销高于go_deep_copy但优于copier |
综上,在这三种结构体深拷贝方式中,go_deep_copy 的性能和内存效率显著优于 copier 和 json 方式,是更推荐的实现选择。