问题
用户期望在互联网环境中解析域名(以xxx.company.com代替)时得到公网IP;在内网环境中,kubernetes集群的应用中,解析域名时得到的是内网IP。
在coredns的配置文件configmap coredns中添加hosts片段后,发现没有生效,解析到的还是公网IP。已知hosts片段的位置在forward之前,也排除了缓存影响。
排查
排查发现POD中指向的dns地址为节点本地地址:
sh
netshoot-node:~# cat /etc/resolv.conf
nameserver 169.254.20.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5用户使用了 NodeLocalDNS(node-local-dns)可以看作是CoreDNS在节点的本地部署,他们用的配置文件一样,会起到缓存的作用。因此问题的原因是"node-local-dns直接向pod返回了解析结果(解析请求没有到coredns),而这个解析结果是公网IP,是错的"。
官网中的示意图:
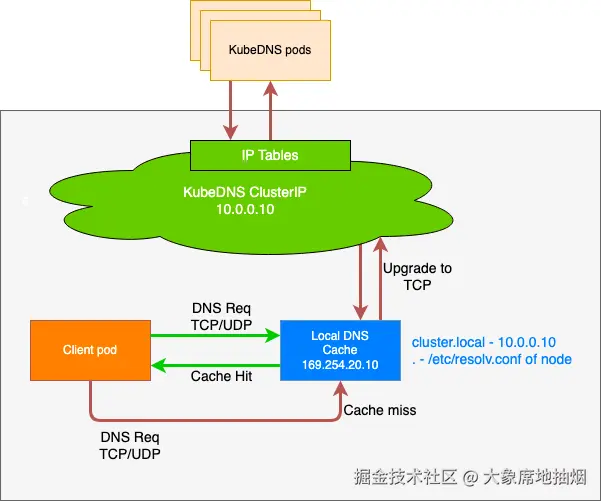
为什么需要 node-local-dns ?
perl
参考自 https://www.lixueduan.com/posts/kubernetes/23-node-local-dns/
处于 ClusterFirst 的 DNS 模式下的 Pod 可以连接到 kube-dns 的 serviceIP 进行 DNS 查询,通过 kube-proxy 组件添加的 iptables 规则将其转换为 CoreDNS 端点,最终请求到 CoreDNS Pod。
通过在每个集群节点上运行 DNS 缓存,NodeLocal DNSCache 可以缩短 DNS 查找的延迟时间、使 DNS 查找时间更加一致,以及减少发送到 kube-dns 的 DNS 查询次数。
在集群中运行 NodeLocal DNSCache 有如下几个好处:
如果本地没有 CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须到另一个节点进行解析,使用 NodeLocal DNSCache 后,拥有本地缓存将有助于改善延迟
跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表(上面提到的 5s 超时问题就是这个原因造成的)
从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP,TCP conntrack 条目将在连接关闭时被删除,而 UDP 条目必须超时(默认 nfconntrackudp_timeout 是 30 秒)
将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)node-local-dns和coredns的文件格式和提供方式一样,都是Corefile、Configmap
kubectl -n kube-system edit cm node-local-dns -o yaml,
conf
cluster.local:53 {
errors
cache {
success 998430
denial 9984 5
}
reload
loop
bind 169.254.20.10
forward . 172.250.0.2 {
force_tcp
}
prometheus :9253
health 169.254.20.10:8080
}
...
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10
forward . __PILLAR__UPSTREAM__SERVERS__
prometheus :9253
}bind 169.254.20.10, 在节点上创建了一个虚拟网卡,网卡地址是169.254.20.10;node-cache(node-local-dns的启动程序),它的securityContext.privileged是True,因此监听了169.254.20.10的53端口。forward . 172.250.0.2这个地址一般是kube-dns的地址(coredns的Service的IP)forward . __PILLAR__UPSTREAM__SERVERS__问题在这个占位符。在运行之前,占位符是一定要被替换掉的。
ps发现node-local-dns的启动命令是/node-cache -localip 169.254.20.10 -conf /etc/Corefile -upstreamsvc kube-dns-upstream。集群是通过kubeaz部署的,configmap被挂载到了node-core-dns pod的/etc/coredns/Confile.base, 在运行之前替换占位符,并移动到了/ect/Corefile。
替换的结果是 forward . /etc/resolv.conf。node-local-dns的dnsPolicy是default,因此/etc/resolv.conf正是节点的/etc/resolv.conf.
而节点的/etc/resolv.conf中,有nameserver 223.5.5.5, 阿里的dns服务器。真相大白。
解决:
- hosts直接定义在node-local-dns是最直接的解决方式。网上有资料说node-local-dns就是解析集群外的、无法被coredns解析的域名。
- 用户的集群规模不大,应用也有连接池,不用node-local-dns也行。不要要注意修改、让pod的/etc/resolv.conf直接指向coredns的Service IP(kube-dns),适当扩容coredns就行了。修改方法在下面dnsPolicy部分。
其他
dnsPolicy
Pod 解析域名时,会使用自身 /etc/resolv.conf 中配置的 nameserver。不同的 dnsPolicy 会决定这个 nameserver 的具体值(是集群 DNS、节点 DNS 还是自定义 DNS)。
dnsPolicy: ClusterFirst(默认)
/etc/resolv.conf 中的 nameserver 一般指向 kube-dns。这个值是由kubelet决定的,可以通过kubelet的启动参数或配置文件修改。
修改kubelet的配置文件:
yaml
clusterDNS:
- 169.254.20.10 # node-local-dns
- 172.250.0.2 # kube-dns Service IPclusterDNS中的顺序和/etc/resolv.conf中的顺序是一致的。nameserver之间是主备关系,不是负载均衡。前面的解析失败采用后面的。
lua
netshoot-node:~# cat /etc/resolv.conf
nameserver 169.254.20.10
nameserver 172.250.0.2
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5如果不想用node-local-dns, 就在clusterDNS只保留kube-dns的地址。不过要重启应用、慎重。
dnsPolicy: Default
/etc/resolv.conf 中的 nameserver 直接 继承节点的 /etc/resolv.conf
此时可能无法解析集群内部的 Service 或 Pod 域名
dnsPolicy: ClusterFirstWithHostNet
仅用于 hostNetwork: true** 的 Pod(共享节点网络命名空间)
/etc/resolv.conf 中的 nameserver 仍指向集群 DNS,但解析逻辑与 ClusterFirst 类似:内部域名用集群 DNS,外部域名转发到节点 DNS。
dnsPolicy: None + 自定义 dnsConfig
/etc/resolv.conf 中的 nameserver 由用户通过 dnsConfig.nameservers 显式指定(可自定义为任意 DNS 服务器,包括节点 DNS、外部 DNS 等)。