主题:Docker 实用技巧与经验总结
字数:2800字
阅读时间:5分钟
最近重新梳理了一遍 Docker 的使用,发现之前很多理解都停留在表面。这篇笔记记录一些实用的认知和踩过的坑。
核心概念的重新理解
镜像不只是"安装包"
以前我把镜像理解成简单的安装包,但实际上镜像是分层的只读文件系统。
每个 Dockerfile 指令都会创建一层:
bash
FROM node:20 # 第1层:基础镜像
WORKDIR /app # 第2层:创建目录
COPY package*.json . # 第3层:复制文件
RUN npm install # 第4层:安装依赖
COPY . . # 第5层:复制源码
CMD ["npm", "start"] # 最后一层:启动命令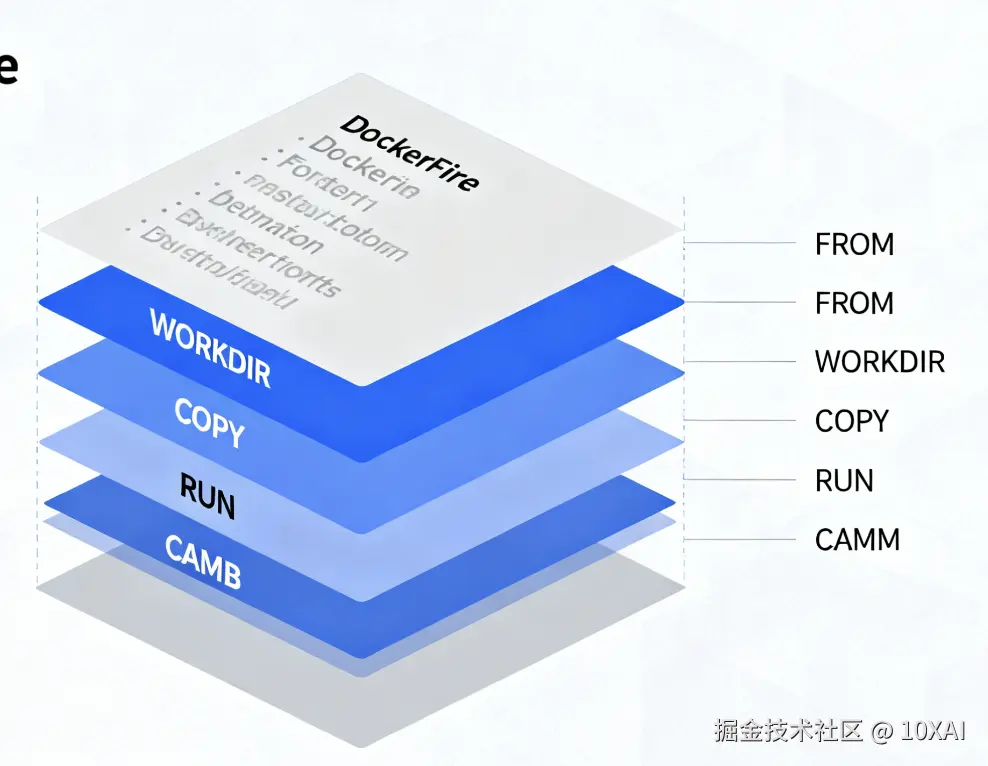 这个分层设计带来几个好处:
这个分层设计带来几个好处:
- 缓存优化:如果前面的层没变,Docker 会直接用缓存
- 存储效率:多个镜像可以共享相同的基础层
- 快速构建:只重新构建变化的层
我之前写 Dockerfile 经常把 COPY . . 放在 RUN npm install 前面,导致每次代码改动都要重新安装依赖。调整顺序后构建速度快了很多。
容器的生命周期管理
容器的状态转换比我想象的复杂:
scss
创建(created) → 运行(running) → 暂停(paused) → 停止(stopped) → 删除(removed)实用命令:
ruby
# 查看容器资源占用(CPU、内存、网络IO)
docker stats
# 查看容器内进程
docker top <container>
# 实时查看日志
docker logs -f --tail 100 <container>
# 进入容器调试
docker exec -it <container> bash
# 容器与宿主机文件传输
docker cp <container>:/path/to/file ./local/path一个常见误区:docker stop 和 docker kill 的区别。
stop:发送 SIGTERM,给容器 10 秒优雅退出时间kill:直接发送 SIGKILL,强制终止
生产环境应该用 stop,让应用有时间清理资源、关闭连接。
run vs start:理解容器的创建与启动
这是我最初混淆的地方:
docker run:创建新容器并启动docker start:启动已存在的容器
实际使用:
yaml
# 第一次运行(创建新容器)
docker run -d --name myapp -p 3000:3000 myapp:latest
# 停止容器
docker stop myapp
# 再次启动(复用同一个容器)
docker start myapp为什么要区分?因为容器内的非持久化数据 在容器存在时会保留,但 docker run 每次都会创建全新的容器。
Volume:数据持久化的三种方式
Volume 是我踩坑最多的地方。Docker 有三种数据挂载方式:
1. Named Volume(推荐)
kotlin
docker run -d \
-v postgres-data:/var/lib/postgresql/data \
postgres:16优点:
- Docker 自动管理存储位置
- 可以在容器间共享
- 备份和迁移方便
查看 volume:
bash
docker volume ls
docker volume inspect postgres-dataVolume 实际存储在 /var/lib/docker/volumes/ 下(Linux)或 Docker Desktop 的虚拟机里(Mac/Windows)。
2. Bind Mount(开发环境)
bash
docker run -d \
-v $(pwd)/data:/var/lib/postgresql/data \
postgres:16优点:
- 直接映射到宿主机目录
- 可以实时编辑文件
- 适合开发环境热重载
坑点:权限问题。
容器内进程通常以特定 UID 运行(如 Postgres 的 UID 999),如果宿主机目录权限不对,会启动失败。
解决方案:
bash
# 方式1:修改宿主机目录权限
chown -R 999:999 ./data
# 方式2:在 Dockerfile 中指定 USER
USER postgres3. Tmpfs Mount(临时数据)
arduino
docker run -d \
--tmpfs /tmp:rw,size=100m \
myapp数据存在内存中,容器停止即删除。适合临时缓存、session 数据。
Volume 的实际使用场景
我的项目里这样组织:
yaml
services:
postgres:
image: postgres:16
volumes:
# 数据持久化用 named volume
- postgres-data:/var/lib/postgresql/data
# 初始化脚本用 bind mount
- ./init.sql:/docker-entrypoint-initdb.d/init.sql:ro
app:
build: .
volumes:
# 开发环境代码热重载
- ./src:/app/src
# node_modules 不要覆盖(重要!)
- /app/node_modules
volumes:
postgres-data:注意 :/app/node_modules 这行很关键。
如果不写,宿主机的 ./src 会覆盖容器内的 /app,导致 node_modules 被覆盖(宿主机可能没有 node_modules 或版本不一致)。
网络:容器间通信的正确姿势
默认网络模式
 Docker Compose 会自动创建一个网络,同一个 compose 文件里的服务可以通过服务名互相访问。
Docker Compose 会自动创建一个网络,同一个 compose 文件里的服务可以通过服务名互相访问。
yaml
services:
redis:
image: redis:alpine
app:
build: .
environment:
# 直接用服务名作为 hostname
REDIS_HOST: redis在 app 容器内,redis 会被自动解析到 redis 容器的 IP。
自定义网络
有时需要多个 compose 文件共享网络:
yaml
# compose1.yml
networks:
shared-network:
external: true
services:
postgres:
networks:
- shared-network
yaml
# compose2.yml
networks:
shared-network:
external: true
services:
app:
networks:
- shared-network先创建网络:
lua
docker network create shared-network这样两个 compose 项目的容器就可以互相通信了。
端口映射的细节
yaml
# 只监听 localhost(更安全)
-p 127.0.0.1:6379:6379
# 监听所有网络接口(谨慎使用)
-p 6379:6379
# 随机宿主机端口
-p 6379生产环境建议:
- 数据库等敏感服务只暴露给内网或特定 IP
- 用 Nginx 等反向代理统一管理对外端口
Docker Compose 的进阶用法
多环境配置
 我用三个文件管理不同环境:
我用三个文件管理不同环境:
yaml
# docker-compose.yml(基础配置)
services:
app:
build: .
env_file: .env
# docker-compose.dev.yml(开发环境覆盖)
services:
app:
volumes:
- ./src:/app/src
command: npm run dev
# docker-compose.prod.yml(生产环境覆盖)
services:
app:
restart: always
logging:
driver: "json-file"
options:
max-size: "10m"使用:
bash
# 开发环境
docker compose -f docker-compose.yml -f docker-compose.dev.yml up
# 生产环境
docker compose -f docker-compose.yml -f docker-compose.prod.yml up -ddepends_on 的陷阱
depends_on 只保证启动顺序 ,不保证服务就绪。
yaml
services:
app:
depends_on:
- postgres # 只保证 postgres 先启动,不保证数据库已准备好实际上 Postgres 可能还在初始化,app 连接会失败。
解决方案1:在 app 代码里加重试逻辑
ini
async function connectDB(retries = 5) {
for (let i = 0; i < retries; i++) {
try {
await pool.connect();
return;
} catch (err) {
if (i === retries - 1) throw err;
await sleep(2000);
}
}
}解决方案2:用 wait-for-it.sh 等工具
yaml
services:
app:
depends_on:
- postgres
command: >
sh -c "
./wait-for-it.sh postgres:5432 --
npm start
"健康检查
定义服务真正"就绪"的条件:
yaml
services:
postgres:
image: postgres:16
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 10s
timeout: 5s
retries: 5
app:
depends_on:
postgres:
condition: service_healthy现在 app 会等到 Postgres 真正就绪后再启动。
Dockerfile 最佳实践
多阶段构建减小镜像体积
sql
# 构建阶段
FROM node:20 AS builder
WORKDIR /app
COPY package*.json ./
RUN npm ci --only=production
COPY . .
RUN npm run build
# 运行阶段
FROM node:20-alpine
WORKDIR /app
COPY --from=builder /app/dist ./dist
COPY --from=builder /app/node_modules ./node_modules
CMD ["node", "dist/index.js"]这样最终镜像只包含运行时需要的文件,不包含源码和开发依赖。
我的一个 Next.js 项目从 1.2GB 降到 180MB。
.dockerignore 很重要
bash
node_modules
.git
.env
*.log
dist
coverage避免把不必要的文件复制到镜像里,加快构建速度,减小镜像体积。
使用特定版本的基础镜像
ruby
# ❌ 不推荐:latest 版本不稳定
FROM node:latest
# ✅ 推荐:固定版本
FROM node:20.10.0-alpine
# ✅ 更好:使用 SHA256
FROM node:20.10.0-alpine@sha256:abc123...这避免了"我本地能跑,生产环境不行"的问题。
实际踩过的坑
坑1:容器时区问题
容器内默认 UTC 时区,导致日志时间不对。
解决:
bash
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone坑2:PID 1 僵尸进程
容器内的主进程是 PID 1,需要负责回收子进程。如果用 shell 脚本启动应用,会产生僵尸进程。
csharp
# ❌ 不推荐
CMD npm start
# ✅ 推荐:使用 exec 或 tini
CMD ["node", "dist/index.js"]
# ✅ 或使用 tini
RUN apk add --no-cache tini
ENTRYPOINT ["/sbin/tini", "--"]
CMD ["node", "dist/index.js"]坑3:Docker in Docker
在 CI/CD 中需要在容器里构建镜像,不要用 Docker in Docker(DinD),用 Docker socket 映射:
javascript
services:
ci:
image: docker:24
volumes:
- /var/run/docker.sock:/var/run/docker.sock这样容器可以调用宿主机的 Docker daemon,避免嵌套 Docker 的各种问题。
性能优化建议
1. 使用 BuildKit
ini
export DOCKER_BUILDKIT=1
docker build .BuildKit 提供并行构建、更好的缓存、构建秘钥管理等特性。
2. 清理无用资源
perl
# 清理悬空镜像
docker image prune
# 清理停止的容器
docker container prune
# 清理无用的 volume
docker volume prune
# 一键清理所有(谨慎使用)
docker system prune -a定期清理,否则磁盘会爆满。
3. 限制容器资源
yaml
services:
app:
deploy:
resources:
limits:
cpus: '2'
memory: 2G
reservations:
cpus: '0.5'
memory: 512M避免单个容器吃掉所有资源。
总结
Docker 的学习曲线不在于命令本身,而在于理解:
- 镜像的分层机制和缓存策略
- 容器的生命周期和状态管理
- 数据持久化的不同方案和适用场景
- 网络通信的细节和安全考虑
- Compose 的编排能力和多环境管理
这些理解都来自实际项目中的踩坑和总结。建议多动手实践,特别是搭建一个完整的多容器项目(前端 + 后端 + 数据库 + 缓存),会遇到很多书上没有的细节问题。
后续计划深入研究 Docker 的网络驱动(bridge、overlay、macvlan)和容器安全加固(AppArmor、Seccomp)。