大家好,我是Ai学习的老章
周末认真看了一个Huggingface上的热门🔥教程
全文几万字,建议时间2-4天,全英
我是配合使用沉浸式翻译阅读的,之前我介绍过
全方位拥抱 DeepSeek,本地部署、AI编程、辅助写作、网页/PDF全文_翻译_
我本想翻译,但是即便是网页版全文翻也非常慢,token消耗太多了。
比如仅这个svg配图都花费很多功夫
翻译
通过这个教程,你将学到:
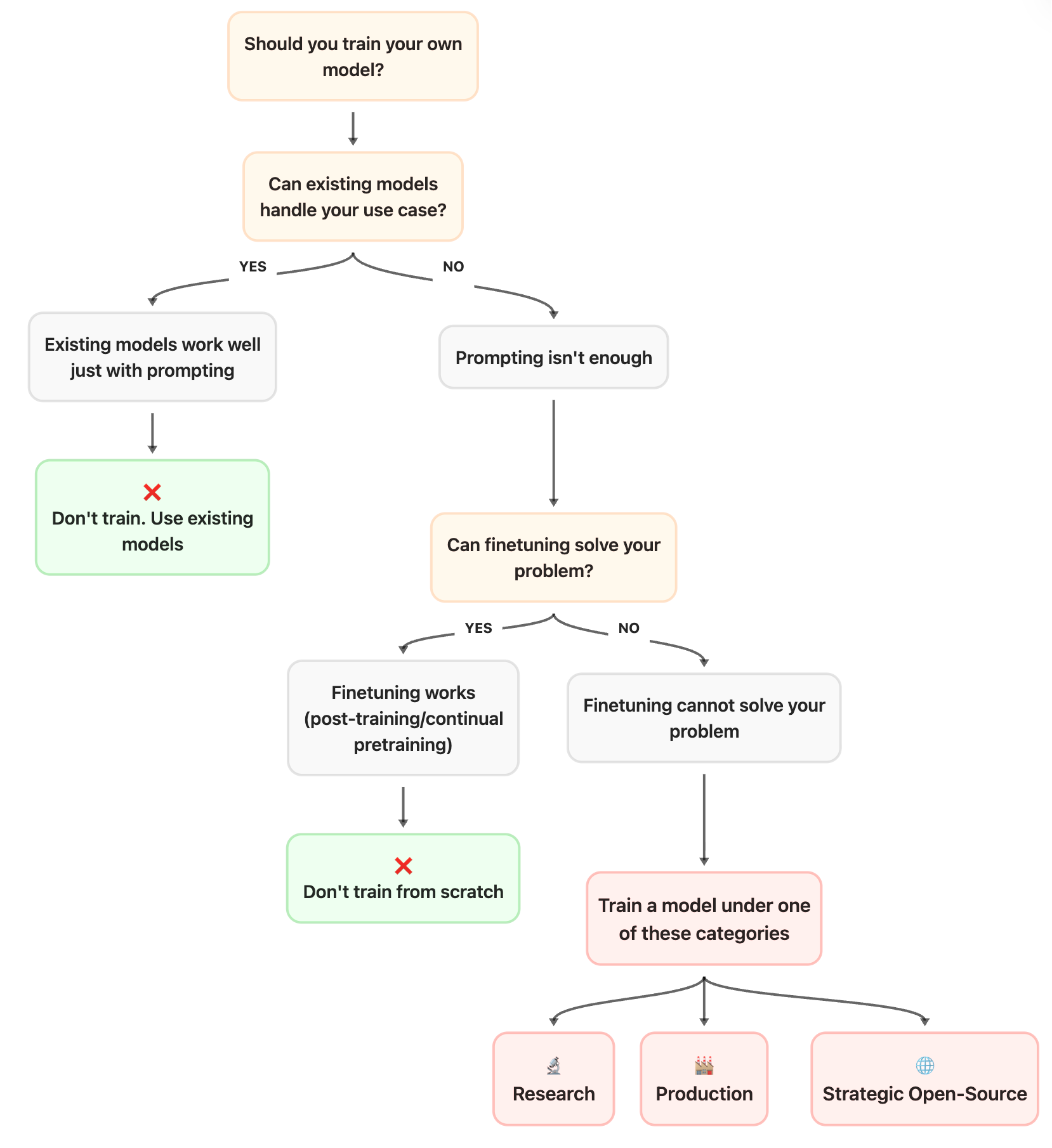
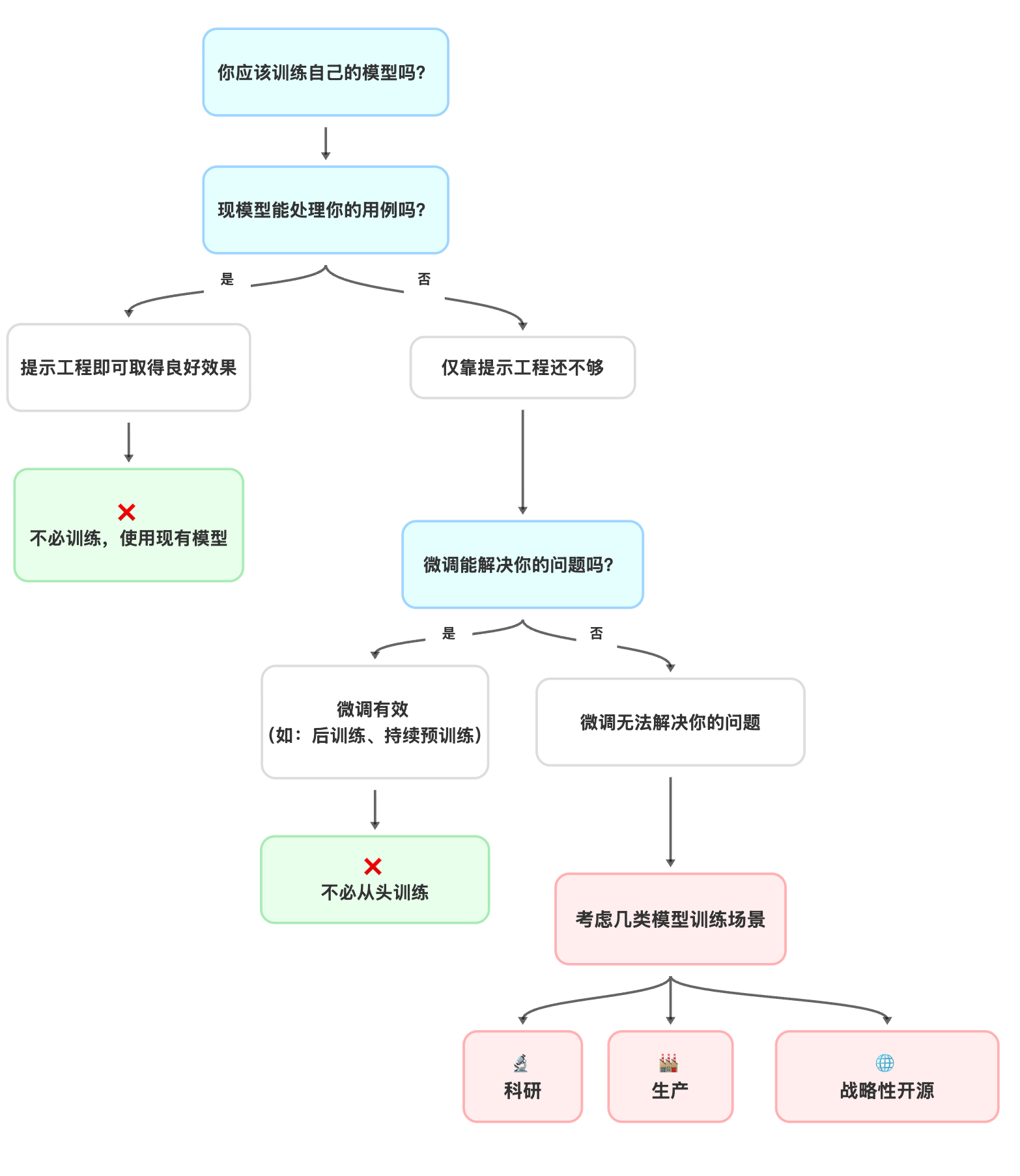
- 一个决策流程图(上图所示): 它会引导你系统性地思考,在投入巨额的计算和时间成本之前,你当前的需求是否真的需要从头训练一个模型。或许,简单的提示工程或微调(Finetuning)就足以解决问题。
- 训练的三个正当理由: 手册明确指出,从头预训练只适用于三种情况:前沿研究(Research)、特定的生产需求(Production),或是填补战略性的开源空白(Strategic Open-Source)。它会帮你判断你的项目是否属于其中之一。
- Hugging Face的真实案例: 它以自身的项目(如Bloom, StarCoder, SmolLM)为例,展示了顶尖团队是如何思考"为什么训练"以及如何找到生态位中的"空白"的。这不仅仅是理论,更是宝贵的实战经验。
- 成功的两大"超能力": 手册最后点明,成功的训练团队最关键的特质是迭代速度和对高质量数据的痴迷,而非其他。
你不需要从头到尾逐字阅读这篇博客文章,而且从目前来看,一次性读完整篇文章是不现实的(有点吃力)。
这个教程被结构化为几个独立的部分,你可以跳过或单独阅读:
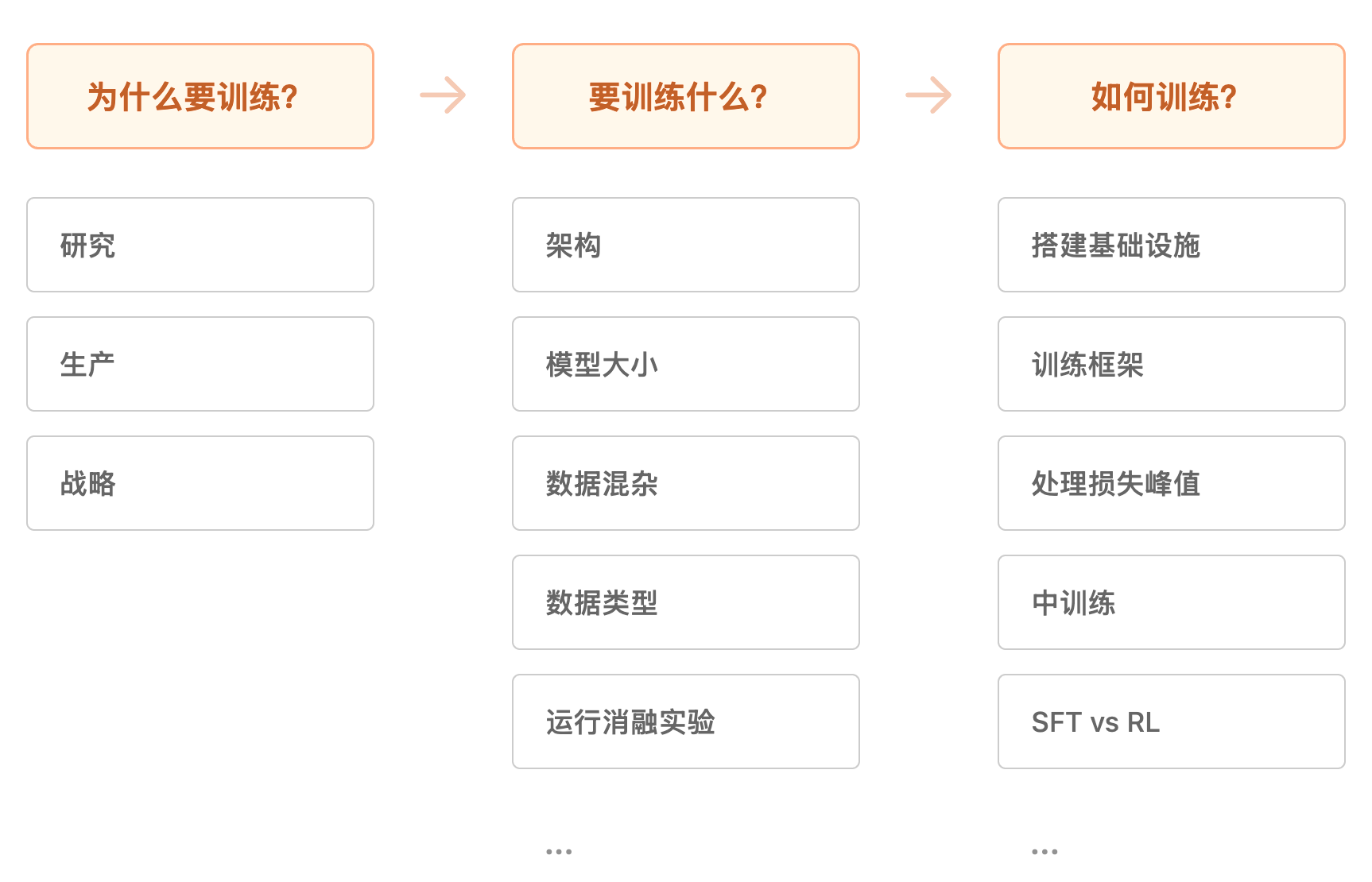
- 训练指南针:深度探讨是否该自己预训练模型。帮你厘清在烧光风投前必须思考的核心问题,建立系统化的决策框架。这部分偏战略层面,急着看技术细节的可以快速略过。
- 预训练实战:从消融实验到评估体系,从数据配比到架构选型,从超参调优到训练马拉松------手把手教你搭建预训练配方。无论你是从零开始还是做继续预训练,这套方法论都能套用。
- 后训练炼金术:把预训练模型的潜力彻底榨干。SFT、DPO、GRPO这些算法怎么玩?模型合并有哪些黑魔法?这些血泪经验都是踩坑踩出来的。
- 基础设施:预训练是蛋糕胚子,后训练是裱花和樱桃,基础设施就是工业烤箱。它要是罢工,你的烘焙派对立马变火灾现场。GPU拓扑、通信模式、性能瓶颈------这些散落在各处的知识碎片,拼成完整拼图。