Linux 内核同步原语详解(原理、场景与示例)
本文系统性讲解 Linux 4.4 内核的 8 类同步机制:
- 原子操作(
atomic_t,atomic64_t等) - 自旋锁(
spinlock_t/raw_spinlock_t) - 读-写自旋锁(
rwlock_t) - 信号量(
struct semaphore) - 读-写信号量(
struct rw_semaphore) - 互斥体(
struct mutex) - 顺序锁(
seqlock_t/seqcount_t) - 禁止抢占(
preempt_disable()/preempt_enable())
每一节包含:实现原理、工作机制、适用场景、注意事项,以及可运行的核心示例片段(放在文档中,便于理解)。同时插入了对应的流程图帮助快速把握结构。代码基于内核 4.4 API,路径引用以本仓库为准。
图表阅读说明:
- 蓝色框:操作/接口(API 调用)
- 橙色框:上下文/约束(是否可睡眠、中断上下文等)
- 绿色框:数据/资源(共享变量、队列、结构体)
- 紫色框:内存序/屏障(Acquire/Release、smp_* 屏障)
- 箭头:流程或依赖关系;图仅用于直观理解,不代表全部细节
目录结构与参考文件:
- 头文件:
include/linux/atomic.h,include/linux/spinlock.h,include/linux/rwlock.h,include/linux/semaphore.h,include/linux/rwsem.h,include/linux/mutex.h,include/linux/seqlock.h,include/linux/preempt.h - 关键实现:
- RW 信号量:
kernel/locking/rwsem-xadd.c,kernel/locking/rwsem-spinlock.c - 互斥体:
kernel/locking/mutex.c(内部辅助:kernel/locking/mutex.h) - 自旋锁与读写锁:各架构特有实现(例如
arch/x86/include/asm/spinlock.h),通用接口在include/linux/spinlock.h - 顺序锁:
include/linux/seqlock.h
- RW 信号量:
1. 原子操作(Atomic Operations)
示意图:
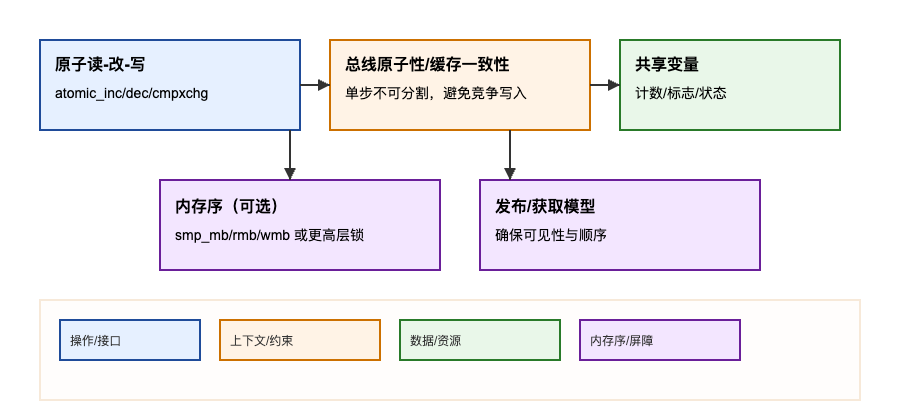
原理与机制:
- 原子操作在 CPU/总线层面保证单步读写的不可分割性。常用类型:
atomic_t(32 位)、atomic64_t(64 位)。 - 常用接口:
atomic_read(),atomic_set(),atomic_inc(),atomic_dec(),atomic_add_return(),atomic_cmpxchg()等。 - 内存序:大多数原子操作本身不隐含"全面的内存屏障"。读/写本身是原子的,但并不保证与其他内存访问的顺序;需要配合
smp_mb()/smp_rmb()/smp_wmb()或者使用"有 acquire/release 语义"的变体(具体到架构)。
适用场景:
- 轻量计数器(引用计数、状态标志)。
- 与锁配合的快速路径(例如尝试锁定或状态检查)。
- CAS(比较并交换)实现无锁队列/栈的关键原语(需谨慎,复杂场景建议使用现成内核结构)。
注意事项:
atomic_read()/atomic_set()不提供内存序屏障;若需与并发访问建立发布/获取关系,请显式添加屏障或使用更高层同步原语。- 原子操作不等于无锁即安全;可见性与顺序仍需正确设计。
示例:简单引用计数与条件翻转
c
#include <linux/atomic.h>
static atomic_t refcnt = ATOMIC_INIT(0);
static atomic_t flag = ATOMIC_INIT(0);
void acquire_resource(void)
{
atomic_inc(&refcnt); // 原子增加
}
void release_resource(void)
{
if (atomic_dec_and_test(&refcnt)) {
// 计数归零,安全释放资源
}
}
bool try_set_flag(void)
{
// 当 flag == 0 时置为 1,成功返回 true
return atomic_cmpxchg(&flag, 0, 1) == 0;
}2. 自旋锁(Spinlock)
示意图:
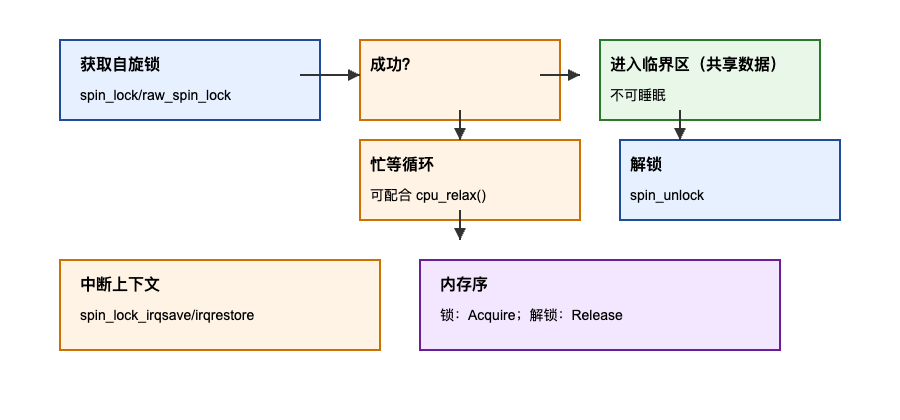
原理与机制:
- 自旋锁通过忙等(busy-wait)在短临界区内实现互斥。持锁期间禁止调度,不能睡眠。
- 典型接口:
spin_lock(),spin_unlock(),spin_lock_irqsave(),spin_unlock_irqrestore();原始版本:raw_spin_lock()。 - 内存序:
spin_lock()提供 acquire 语义,spin_unlock()提供 release 语义;在多数架构上等价于全面的临界区内存有序性保障。
适用场景:
- 极短的临界区、对延迟敏感(尤其在中断上下文)。
- 保护 per-CPU 数据、队列头、状态位等快速更新路径。
注意事项:
- 持锁期间不得调用可能睡眠的 API(如
mutex_lock()、down())。 - 中断上下文使用
spin_lock_irqsave(),确保不会被本地中断打断且正确恢复标志位。 - 避免长临界区与重入,防止严重的活锁/延迟。
- 严格遵守锁顺序,防止死锁;启用
lockdep可在开发期辅助检查。
示例:保护链表头(中断安全)
c
#include <linux/spinlock.h>
static spinlock_t lock; // 需要 init,例如在模块初始化中 spin_lock_init(&lock)
static struct list_head my_list; // 需 INIT_LIST_HEAD(&my_list)
void push_item(struct my_node *n)
{
unsigned long flags;
spin_lock_irqsave(&lock, flags);
list_add(&n->link, &my_list);
spin_unlock_irqrestore(&lock, flags);
}3. 读-写自旋锁(RW Spinlock)
示意图:
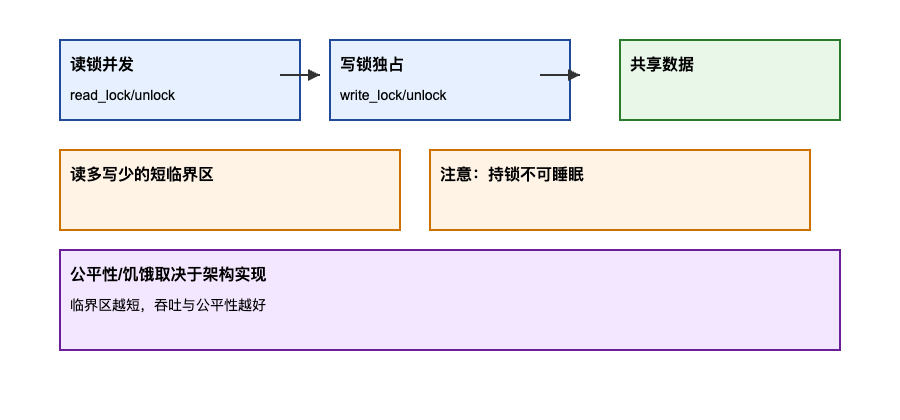
原理与机制:
rwlock_t允许多个读者并发,写者独占,基于自旋实现。- 典型接口:
read_lock()/read_unlock(),write_lock()/write_unlock();对应的irqsave变体同理。 - 读锁不会阻塞其他读者;写锁需要等待所有读者释放。
适用场景:
- 读多写少且临界区非常短的场景,例如读取共享配置、统计头信息等。
注意事项:
- 与普通自旋锁相同,持锁期间不得睡眠。
- 写优先或读优先具体依赖架构与实现细节,可能存在饥饿风险;临界区需尽量短。
示例:读多写少的配置访问
c
#include <linux/rwlock.h>
static rwlock_t cfg_lock; // rwlock_init(&cfg_lock)
static int cfg_value;
int read_cfg(void)
{
unsigned long flags;
int v;
read_lock_irqsave(&cfg_lock, flags);
v = cfg_value;
read_unlock_irqrestore(&cfg_lock, flags);
return v;
}
void write_cfg(int newv)
{
unsigned long flags;
write_lock_irqsave(&cfg_lock, flags);
cfg_value = newv;
write_unlock_irqrestore(&cfg_lock, flags);
}4. 信号量(Semaphore)
示意图:
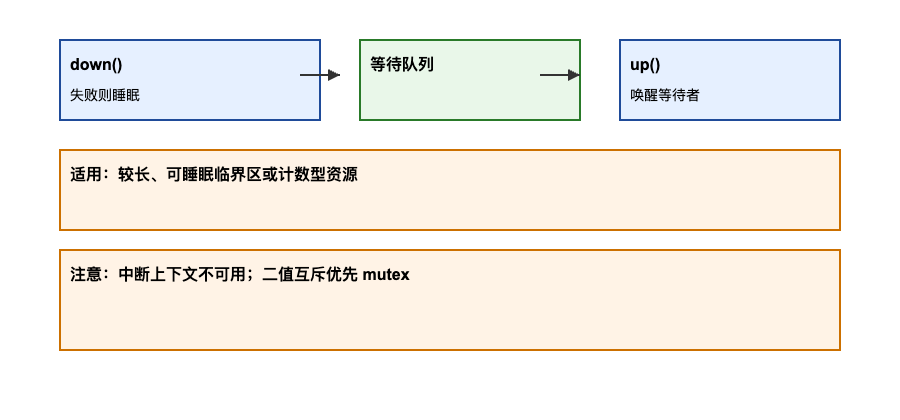
原理与机制:
struct semaphore是可阻塞的计数型锁,线程在无法获取时会睡眠,适合较长临界区。- 典型接口:
sema_init(),down(),down_interruptible(),down_trylock(),up()。 - 实现依赖等待队列和调度,可能包含唤醒策略与公平性处理。
适用场景:
- 需要睡眠等待的资源访问,跨调用链的较长操作。
- 计数型资源(N 个并发许可)。但在现代内核中计数型资源更常用更高层抽象或特定子系统接口。
注意事项:
- 相比
mutex,信号量更通用但也更容易误用;若只是二值互斥,优先考虑mutex。 - 不可在中断上下文使用(会睡眠)。
示例:二值信号量充当互斥(不建议,示例仅为说明)
c
#include <linux/semaphore.h>
static struct semaphore sem;
static int init_sem(void)
{
sema_init(&sem, 1); // 二值互斥
return 0;
}
void critical_section(void)
{
if (down_interruptible(&sem))
return; // 被信号打断
// ... 执行较长的可睡眠操作 ...
up(&sem);
}何时选 mutex / 何时选 semaphore(针对本小节)
- 优先选
mutex:单持有者互斥、可睡眠、临界区较长;需要所有权约束与更强的误用检测(如禁止递归、跨线程解锁)。 - 选
semaphore:明确的"计数型资源"(N>1 并发许可),如连接槽位、缓冲区配额;不建议用二值信号量充当互斥,改用mutex更安全。 - 共同约束:两者都可能睡眠,不能在中断上下文使用;持有自旋锁时不可调用
down*()/mutex_lock()。 - 快速映射:
- 二值互斥 →
mutex - 计数配额(N>1)→
semaphore - 中断上下文/极短不可睡眠 →
spinlock_t/rwlock_t - 读多写少且较长 →
rw_semaphore
- 二值互斥 →
5. 读-写信号量(RW Semaphore)
示意图:

原理与机制:
struct rw_semaphore支持读并发、写独占,但读写都可能睡眠等待。适合"读多写少且临界区较长"的场景。- 典型接口:
init_rwsem(),down_read(),up_read(),down_write(),up_write(),downgrade_write()。 - 4.4 内核实现包含争用处理与优化(如乐观自旋),参考:
kernel/locking/rwsem-xadd.c,kernel/locking/rwsem-spinlock.c。
适用场景:
- 页缓存、VFS、内存管理子系统中读多写少的路径;需要睡眠等待且临界区可能较长。
注意事项:
- 写方可能唤醒队列中的读者或写者,唤醒策略会影响公平性与吞吐。
- 与自旋版 RW 锁相比,这里是可睡眠的;不可在中断上下文使用。
示例:元数据读写
c
#include <linux/rwsem.h>
static DECLARE_RWSEM(meta_rwsem);
static struct meta { int a; long b; } M;
int read_meta_copy(struct meta *out)
{
down_read(&meta_rwsem);
*out = M; // 复制较长结构
up_read(&meta_rwsem);
return 0;
}
void update_meta(int a, long b)
{
down_write(&meta_rwsem);
M.a = a;
M.b = b;
up_write(&meta_rwsem);
}6. 互斥体(Mutex)
示意图:
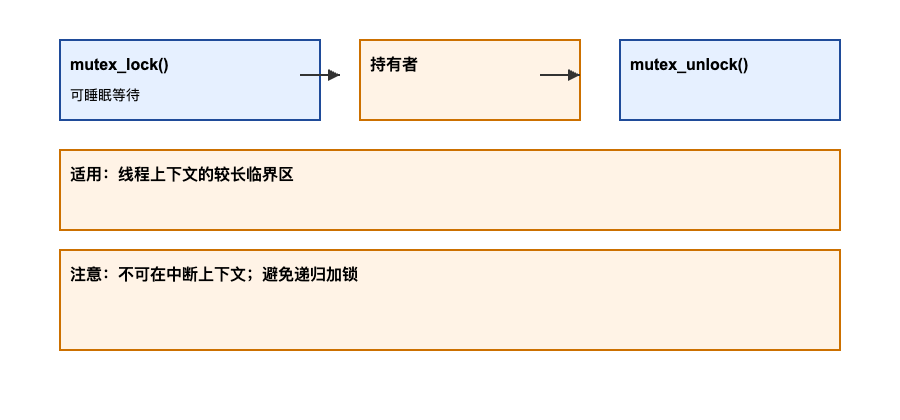
原理与机制:
struct mutex是最常用的可睡眠互斥原语,提供简单的锁定语义与(可选的)自旋优化。接口:mutex_init(),mutex_lock(),mutex_lock_interruptible(),mutex_trylock(),mutex_unlock()。- 内存序:
mutex_lock()/mutex_unlock()具有 acquire/release 语义。
适用场景:
- 线程上下文中的较长临界区;API 设计更安全、易读。
注意事项:
- 不可在中断上下文使用(会睡眠)。
- 谨防递归加锁(会触发
DEBUG_MUTEXES报错)。 - 锁持有期间避免调用可能导致不可控延迟的耗时操作;必要时拆分临界区。
示例:典型互斥保护
c
#include <linux/mutex.h>
static DEFINE_MUTEX(mtx);
static long shared_state;
void do_work(long v)
{
mutex_lock(&mtx);
shared_state += v; // 较长但可睡眠的路径
mutex_unlock(&mtx);
}何时选 mutex / 何时选 semaphore(针对本小节)
- 选
mutex:需要严格"互斥"语义(一次仅一个持有者)、临界区可睡眠且较长、希望有更好的调试支持与所有权约束。 - 改用
semaphore的情况:确实存在"资源配额(N>1 并发许可)"的需求;如果只是二值互斥,应继续使用mutex。 - 共同约束:不可在中断上下文使用;避免在持自旋锁区域调用可能睡眠的 API。
- 快速映射:
- 单持有者互斥(可睡眠)→
mutex - 多许可并发(可睡眠)→
semaphore - 读多写少且较长 →
rw_semaphore - 中断/不可睡眠短临界区 →
spinlock_t/rwlock_t
- 单持有者互斥(可睡眠)→
7. 顺序锁(Seqlock / Seqcount)
示意图:

原理与机制:
- 顺序锁通过"写方增加序号,读方无锁读取并重试"的模式,实现读路径的无锁一致性检查。
- 写路径独占(使用自旋或禁抢占/禁中断),读路径不加锁但可能多次重试。
- 典型接口:
seqlock_t:write_seqlock(),write_sequnlock(),read_seqbegin(),read_seqretry()等。seqcount_t:更细粒度的序号计数,不绑定具体锁策略,由调用者保证写侧的互斥。
- 用途示例:时钟、统计信息、轻量结构体快照(读多写少)。
适用场景:
- 读路径需要无锁快速读取,允许重试;写路径短而可控。
注意事项:
- 读方可能重试多次,适合小结构体和轻量拷贝。
- 不适合读方需要"实时"一致的复杂结构(如链表遍历)。
- 写方必须保证互斥(通常配合自旋锁或禁抢占)。
示例:读取时间戳快照
c
#include <linux/seqlock.h>
static seqlock_t ts_lock = SEQLOCK_UNLOCKED;
struct ts { u64 tsc; u64 jiffies; } TS;
struct ts read_ts(void)
{
struct ts snapshot;
unsigned seq;
do {
seq = read_seqbegin(&ts_lock);
snapshot = TS; // 无锁读
} while (read_seqretry(&ts_lock, seq));
return snapshot;
}
void update_ts(u64 tsc, u64 j)
{
write_seqlock(&ts_lock);
TS.tsc = tsc;
TS.jiffies = j;
write_sequnlock(&ts_lock);
}8. 禁止抢占(preempt_disable / preempt_enable)
示意图:

原理与机制:
- 抢占是调度器在任意合适点切换当前任务的能力。
preempt_disable()禁止当前 CPU 上的内核抢占,preempt_enable()恢复。 - 常用于保护 per-CPU 数据访问的短窗口(避免迁移到其他 CPU 导致并发问题)。
- 与中断不同:禁抢占不禁止中断;如需同时禁止本地中断,使用
local_irq_save()/local_irq_restore()或spin_lock_irqsave()。
适用场景:
- 极短的窗口访问
__percpu数据或 CPU 本地状态,无需锁但需要保证不被调度迁移。
注意事项:
- 禁抢占不提供内存屏障;仅防止任务切换。必要时使用锁或显式内存屏障保证有序。
- 窗口必须非常短,避免影响系统实时性。
示例:安全访问 per-CPU 计数
c
#include <linux/preempt.h>
#include <linux/percpu.h>
DEFINE_PER_CPU(unsigned long, pcpu_hits);
void bump_hits(void)
{
preempt_disable();
this_cpu_inc(pcpu_hits); // 当前 CPU 局部更新
preempt_enable();
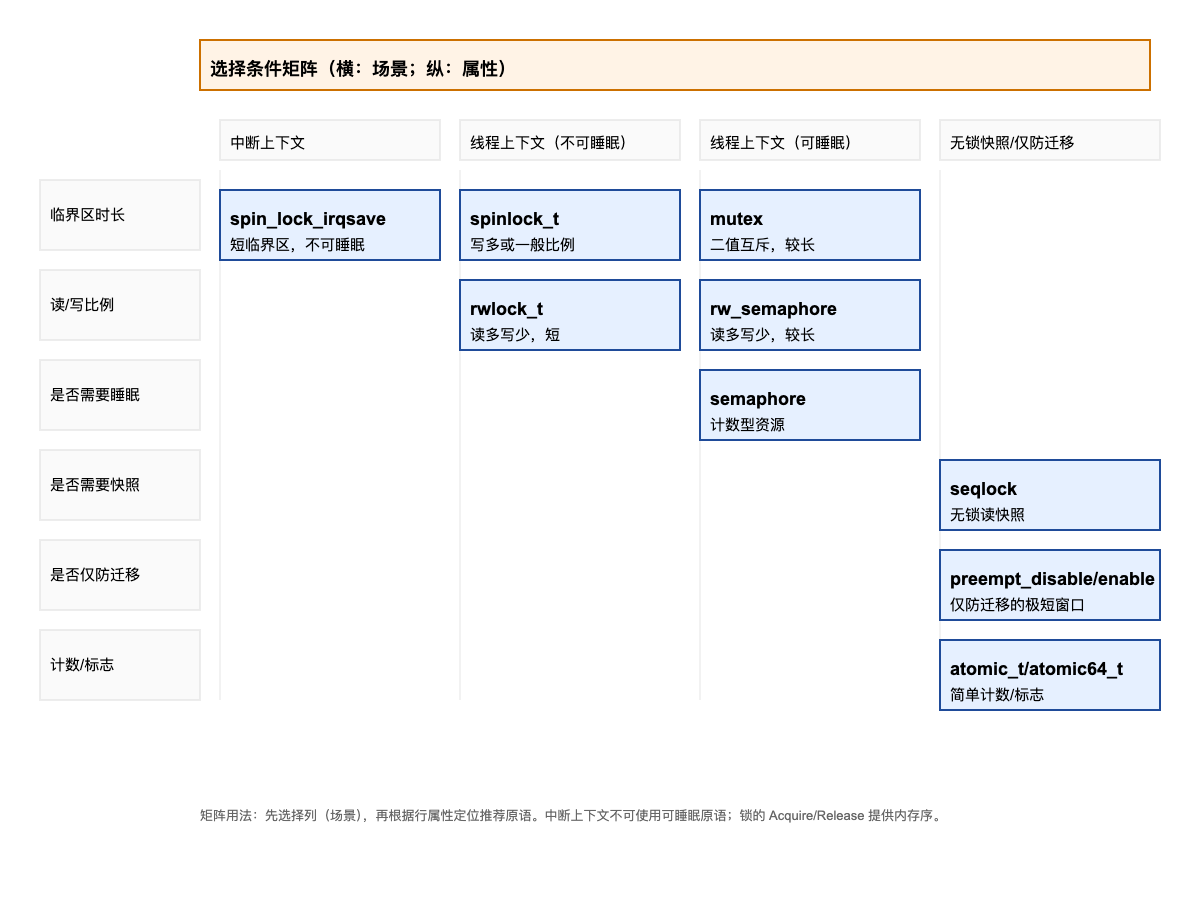
}选择指南(何时用哪种?)
总览矩阵(更直观的选择方式):
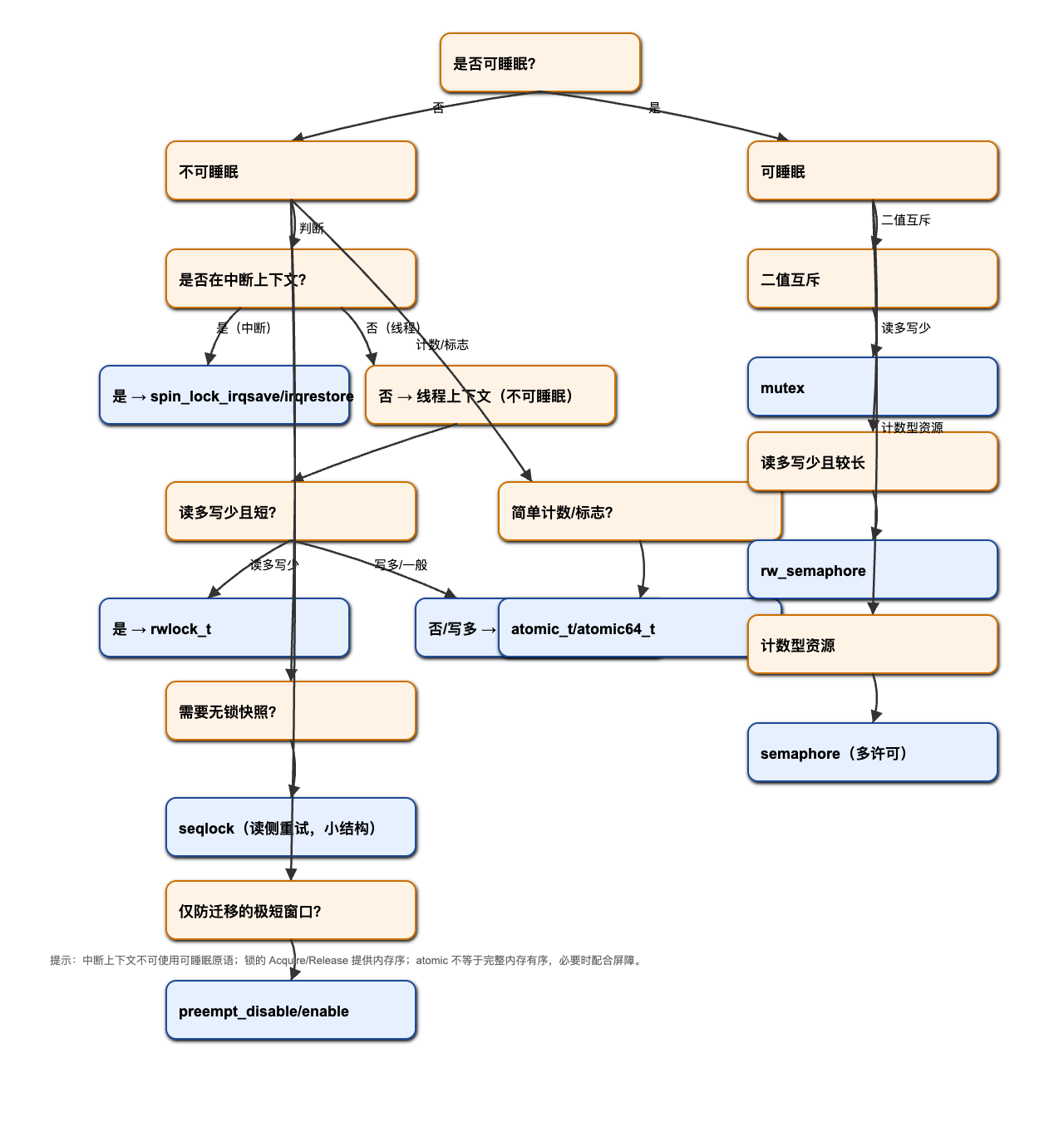
另见:曲线决策树(按问题逐步选择):
快速映射:
- 极短、不可睡眠:优先
spinlock_t;读多写少且短:rwlock_t。 - 可睡眠、较长临界区:优先
mutex;读多写少且较长:rw_semaphore。 - 读方无锁快照、允许重试:
seqlock/seqcount。 - 简单计数或状态位:
atomic_t/atomic64_t配合屏障。 - 仅防迁移的极短窗口:
preempt_disable()。
常见模式:
- 设备中断处理:
spin_lock_irqsave()保护共享队列。 - 配置读取(读多写少):用户态接口读路径用
rw_semaphore,写路径独占更新。 - 时间/统计快照:使用
seqlock,读侧无锁重试。 - 内核线程长操作:使用
mutex,避免自旋造成 CPU 浪费。
内存序与屏障简表
spin_lock():Acquire;spin_unlock():Release;临界区内形成有序性。mutex_lock()/unlock():Acquire/Release。rwlock/rw_semaphore:按读/写加解锁,整体遵循 Acquire/Release 语义。atomic_*:原子性 != 完整有序;必要时使用smp_mb()、smp_rmb()、smp_wmb()。seqlock:写侧递增序号并提供必要屏障;读侧需read_seqretry()检测并重试。preempt_disable():仅禁止抢占,不是屏障。
开发注意事项(最佳实践)
- 锁定粒度:尽量缩小临界区,减少持锁时间;必要时按数据分片使用不同锁。
- 锁顺序:统一的全局锁顺序,避免循环等待;调试期启用
lockdep。 - 避免在持自旋锁或禁中断期间调用可能睡眠的函数。
- 中断上下文只能使用不可睡眠的原语(自旋锁、seqlock 写侧自旋等)。
- 性能权衡:读多写少优先读写锁或 seqlock;写多读少倾向普通互斥。
- 结合 RCU:只读路径且可接受延迟释放,考虑 RCU;与本文原语互补。
演示实例集合(文档内嵌)
以下片段汇总了上文示例的关键用法,便于一次性对比:
原子计数与 CAS:
c
static atomic_t refcnt = ATOMIC_INIT(0);
static atomic_t flag = ATOMIC_INIT(0);
atomic_inc(&refcnt);
if (atomic_dec_and_test(&refcnt)) { /* release */ }
bool set = (atomic_cmpxchg(&flag, 0, 1) == 0);自旋锁(中断安全):
c
spinlock_t lock; unsigned long flags;
spin_lock_irqsave(&lock, flags);
/* short critical section */
spin_unlock_irqrestore(&lock, flags);读写自旋锁:
c
rwlock_t rwl; unsigned long flags; int v;
read_lock_irqsave(&rwl, flags); v = cfg_value; read_unlock_irqrestore(&rwl, flags);
write_lock_irqsave(&rwl, flags); cfg_value = v; write_unlock_irqrestore(&rwl, flags);信号量(可睡眠):
c
struct semaphore sem; sema_init(&sem, 1);
if (!down_interruptible(&sem)) { /* long section */ up(&sem); }读写信号量:
c
DECLARE_RWSEM(meta_rwsem);
down_read(&meta_rwsem); /* copy */ up_read(&meta_rwsem);
down_write(&meta_rwsem); /* update */ up_write(&meta_rwsem);互斥体:
c
DEFINE_MUTEX(mtx);
mutex_lock(&mtx); /* long but sleepable */ mutex_unlock(&mtx);顺序锁:
c
seqlock_t sl = SEQLOCK_UNLOCKED; unsigned seq;
do { seq = read_seqbegin(&sl); snapshot = S; } while (read_seqretry(&sl, seq));
write_seqlock(&sl); S = newS; write_sequnlock(&sl);禁止抢占与 per-CPU:
c
preempt_disable(); this_cpu_inc(pcpu_hits); preempt_enable();结语
选择同步原语的核心是:理解"是否可睡眠、临界区长短、读写比例、是否在中断上下文、是否需要无锁读快照以及内存序要求"。遵循上述指引与注意事项,可在内核 4.4 环境下写出既正确又高效的并发代码。
如需进一步结合具体子系统(如 VFS、MM、RCU)展开,可在本仓库的相关文档与源码路径中交叉阅读:
fs/(VFS/文件系统)、mm/(内存管理)、kernel/locking/(锁与同步)、kernel/rcu/(RCU)。