基础知识
1. 埋点监控平台
什么是埋点监控平台?
埋点监控平台 是一套采集、存储、分析用户行为与系统数据的工具,核心是通过代码 "埋点" 获取数据,再通过平台实现可视化监控与分析。
就好比给一个产品安置了"眼睛"和"大脑", "眼睛"(埋点)负责看用户和系统的一举一动,"大脑"(平台)负责把这些 "看到的" 整理成有用的信息告诉你。
为什么要自己做一个埋点监控平台?
埋点监控平台是一个 "全链路技术实践" 项目,能串联起数据采集、后端服务、前端可视化等多个技术领域,可以快速提升个人综合开发能力以及团队协作能力。
其实我觉得市面上的大部分工具都需要钱💰,自己做一个埋点监控平台,可以想要啥功能就开发啥,完全跟着自己的业务走,不花冤枉钱。😋
通过这个项目准备学习哪些内容?
- ✨学会怎么写 "埋点 SDK": 比如给电商网页按钮加段 JS 代码,用户一点击就自动收集 "谁点的、什么时候点的、点的次数多吗",再把这些数据打包发给后端。搞懂 "数据怎么格式化成统一样子""怎么避免重复发数据" 这些实际问题。
- ✨学会怎么处理 "垃圾数据": 平台实际采集的数据可能会有垃圾(比如用户乱点产生的无效数据、格式错误的信息),学会如何写代码过滤这些数据,比如"用户1秒点击了按钮100次,导致页面崩溃",相信很多人过年抢车票的时候深有体会。
- ✨学会怎么做 "监控仪表盘": 用 ECharts 或 Grafana 画图表,比如把 "近 7 天点击量" 做成折线图、"不同设备的访问占比" 做成饼图,更直观的体现这些数据所体现出的问题。
- ✨团队协作: 这一点是对于第一次接触多人协作项目的初学者来说挺重要的一点,培养团队协作能力,学会如何与同事同步项目信息。
一个基础的埋点监控平台需要具备哪些功能?
| 功能模块 | 核心能力 |
|---|---|
| 埋点管理 | 支持创建 / 编辑埋点(定义埋点名称、类型、关联业务场景) 埋点数据格式校验(避免无效数据入库) |
| 数据采集 | 提供 SDK 供业务端集成埋点 接收埋点数据(支持高并发,避免数据丢失) |
| 数据存储 | 存储原始埋点数据(用于追溯) 存储聚合后的数据(用于快速查询,如 "今日按钮点击总量") |
| 可视化监控 | 支行为监控:用户点击、页面访问量等图表展示 系统监控:接口成功率、耗时、错误码分布展示 |
| 告警通知 | 支持配置告警规则(如接口成功率低于 99% 触发告警) 多渠道通知(短信、邮件、企业微信) |
怎么去实现这个项目基础功能?
架构设计
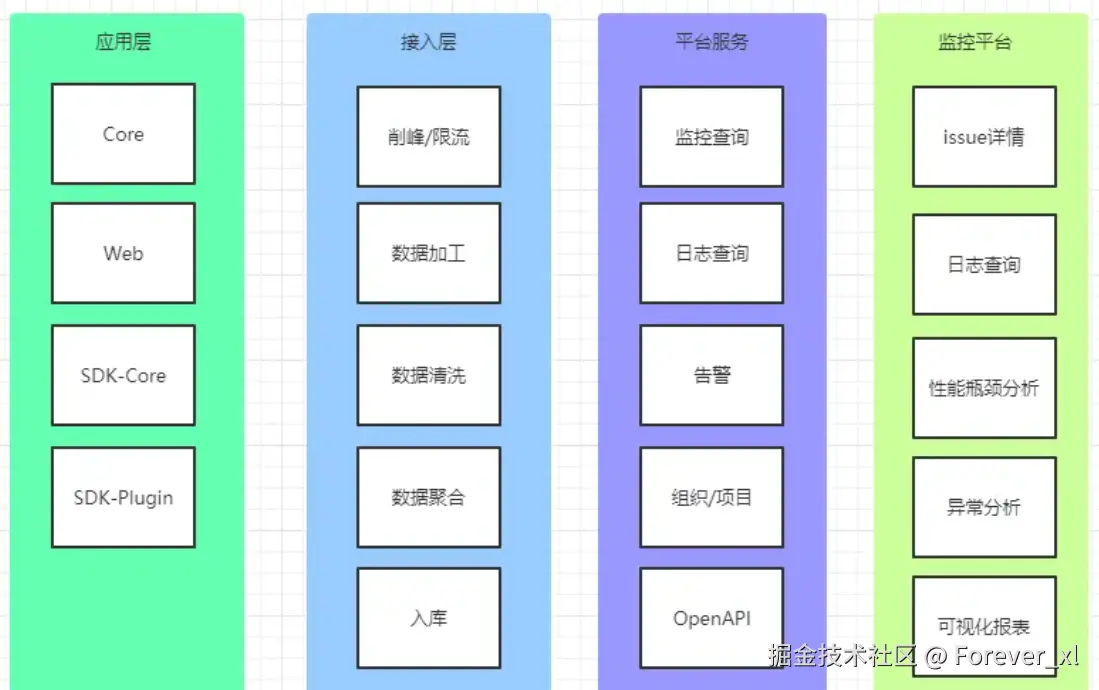
用户在应用层 (APP / 网站)产生行为→行为被应用层的 SDK 采集并发送→接入层 对数据加工、清洗、聚合后存起来→平台服务 提供查询、告警等功能→最终在监控平台以图表、报表的形式呈现,帮你发现问题、优化业务。
削峰限流: 用于应对数据量激增(如大促活动时用户行为爆发)或恶意高并发访问,防止因流量过载导致服务不可用。
数据加工: 对采集的原始数据进行增强,例如补充 IP 归属地、运营商类型等维度信息,丰富数据的分析价值。
数据清洗: 通过白名单过滤合法数据、黑名单拦截无效 / 恶意数据,同时清理已下线应用的历史残留数据,保障入库数据的有效性。
数据聚合: 将具有相同特征的分散数据进行归类汇总(如将同一类型的埋点异常抽象为一个可追踪的 issue),便于后续的查询分析和问题追溯。
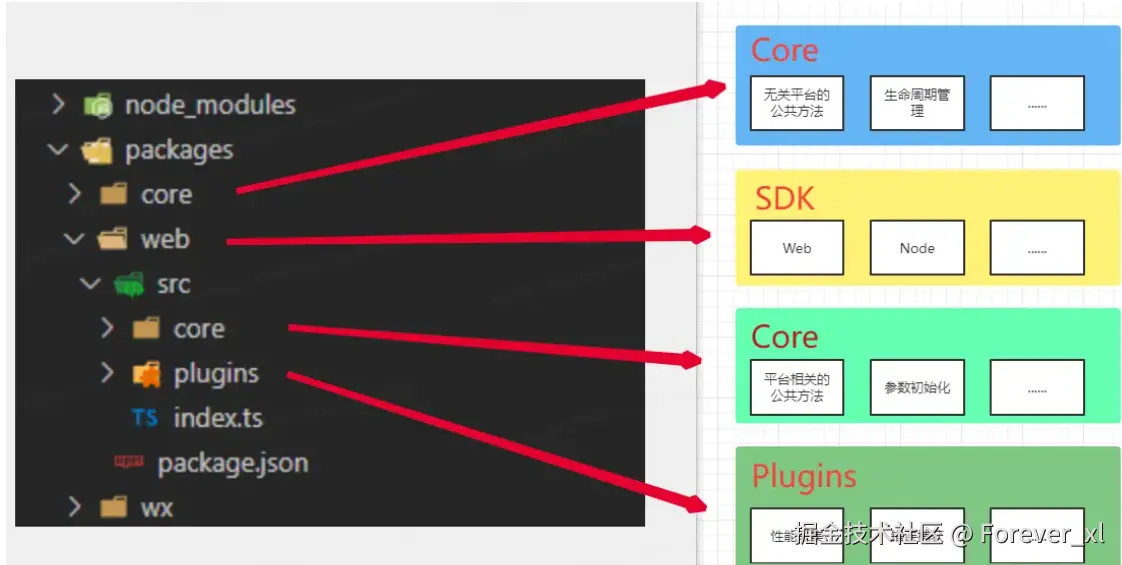
SDK架构设计
SDK 架构通过 "内核 + 插件" 设计,以多包管理实现多端兼容,通过 Core 层、SDK 层、Plugins 层构建功能体系,再依托内核与 Instance形成 "插件采集原始数据→Instance 传递给内核→内核格式化并通过 Fetch/Beacon 等方案上报" 的闭环,最终实现既能灵活适配 Web、小程序等多端场景,又能稳定提供一致的埋点采集能力,还可按需扩展功能的核心目标。
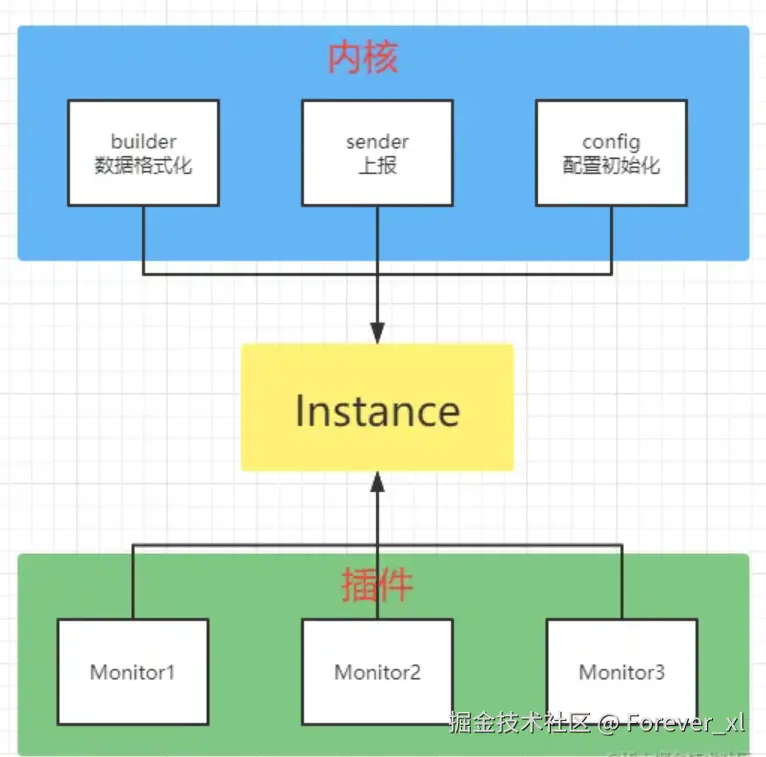
采集模块
1.性能监控:
核心目标:捕获页面加载、资源加载、交互响应等性能指标,定位性能瓶颈(如加载慢、卡顿),支撑体验优化。
js
window.addEventListener('load', () => {
const timing = performance.timing;
const performanceData = {
trackId: 'page_performance',
whiteScreenTime: timing.domLoading - timing.navigationStart, // 白屏时间
domReadyTime: timing.domContentLoadedEventEnd - timing.navigationStart, // DOM就绪
loadTime: timing.loadEventEnd - timing.navigationStart // 全量加载完成
};
dataProcessor.handle(performanceData);
});监控指标: 白屏时间、DOM 加载完成时间、页面完全加载时间、首屏渲染时间。
实现逻辑: 通过performance.timing获取页面导航到各阶段的时间戳,计算各指标耗时。
js
window.addEventListener('load', () => {
performance.getEntriesByType('resource').forEach(resource => {
dataProcessor.handle({
trackId: 'resource_performance',
url: resource.name,
type: resource.initiatorType, // 资源类型:img/script等
duration: resource.duration, // 加载耗时(ms)
startTime: resource.startTime // 开始加载时间
});
});
});监控指标: 各资源(JS/CSS/ 图片)的加载耗时、开始 / 结束时间、资源类型。
实现逻辑: 通过performance.getEntriesByType('resource')获取所有资源的加载详情。
2. 错误监控:
JS
window.onerror = (message, source, lineno, colno, error) => {
dataProcessor.handle({
trackId: 'js_error',
message: message,
source: source, // 错误文件路径
line: lineno,
column: colno,
stack: error?.stack || '无堆栈'
});
return true; // 阻止控制台重复输出
};监控范围: 同步代码错误(如undefined调用函数)、语法错误、DOM 操作错误。
实现逻辑: 通过window.onerror捕获错误信息、发生位置和堆栈。
JS
class ErrorBoundary extends React.Component {
componentDidCatch(error, info) {
dataProcessor.handle({
trackId: 'react_component_error',
message: error.message,
stack: error.stack,
componentStack: info.componentStack // 组件调用栈
});
}
render() { return this.props.children; }
}监控范围: React 组件渲染错误(如render函数报错、子组件异常)。
实现逻辑: 通过ErrorBoundary捕获组件树错误,上报组件调用栈。
3. 行为监控:
JS
// 点击行为捕获
document.addEventListener('click', (e) => {
const target = e.target;
if (target.classList.contains('ignore-track')) return; // 过滤无需采集的元素
dataProcessor.handle({
trackId: 'user_click',
elementId: target.id || target.dataset.track, // 元素标识
x: e.clientX, // 点击坐标
y: e.clientY,
pageUrl: location.href
});
});
// 表单输入行为捕获
document.addEventListener('input', (e) => {
const target = e.target;
if (target.type === 'text' || target.type === 'search') {
dataProcessor.handle({
trackId: 'user_input',
elementId: target.id,
value: target.value.slice(0, 5) // 脱敏,只保留前5位
});
}
}, { passive: true }); // 非阻塞模式,提升性能监控范围: 按钮点击、链接跳转、表单输入、页面滚动等。
实现逻辑: 在document上统一监听事件(如click/input),通过事件冒泡获取触发元素,过滤无效行为。
数据收集
标准化格式: 将不同场景的原始数据(如点击事件的 "坐标"、错误事件的 "堆栈")统一为固定结构,必含eventId(唯一标识)、trackId(事件类型)、timestamp(时间戳)、基础环境信息(设备、用户、页面)等核心字段,避免数据格式混乱。
JS
{
"eventId": "uuid-xxx-xxx", // 全局唯一ID(去重、追溯用)
"trackId": "user_click", // 事件类型标识(与埋点配置对应)
"timestamp": 1730764800000, // 事件发生时间戳(毫秒)
"basicInfo": { // 基础环境信息(自动补充)
"userId": "12345", // 登录用户ID(未登录则为空)
"deviceId": "xxx-xxx", // 设备唯一标识
"pageUrl": "https://xxx.com/home",
"browser": "Chrome 120", // 浏览器信息
"os": "Windows 10" // 操作系统
},
"eventData": {} // 场景化数据(如点击事件的elementId、错误事件的stack)
}清洗过滤剔除无效数据: 过滤格式错误(如非法trackId、异常时间戳)、重复数据(如 1 秒内同一设备的重复点击)、敏感信息(如手机号脱敏),只保留符合规则的有效数据。
JS
function cleanData(rawData) {
// 1. 校验trackId是否合法(从配置中心获取有效trackId列表)
if (!validTrackIds.includes(rawData.trackId)) {
console.warn(`无效trackId: ${rawData.trackId}`);
return null; // 过滤该数据
}
// 2. 校验时间戳
const now = Date.now();
if (rawData.timestamp < 1577808000000 || rawData.timestamp > now + 300000) { // 早于2020年或晚于5分钟后
console.warn(`无效时间戳: ${rawData.timestamp}`);
return null;
}
// 3. 重复数据过滤(用localStorage暂存最近1秒的事件ID)
const cacheKey = `dup_cache_${rawData.deviceId}_${rawData.trackId}`;
const recentEvents = JSON.parse(localStorage.getItem(cacheKey) || '[]');
if (recentEvents.includes(rawData.eventId)) {
return null; // 重复数据,过滤
}
// 保留最近10条,避免缓存过大
recentEvents.push(rawData.eventId);
if (recentEvents.length > 10) recentEvents.shift();
localStorage.setItem(cacheKey, JSON.stringify(recentEvents));
// 4. 敏感信息脱敏(如eventData中的手机号)
if (rawData.eventData.phone) {
rawData.eventData.phone = rawData.eventData.phone.replace(/(\d{3})\d{4}(\d{4})/, '$1****$2');
}
return rawData; // 清洗后的数据
}补充与聚合
自动补充上下文(如网络类型、页面标题、IP 属地),丰富数据维度;
对高频事件聚合处理,减少上报次数,降低性能损耗(对短时间内的重复点击,聚合为 "点击次数",如 10 次点击合并为 1 条数据,count: 10)。
数据上报
1.基础上报:Fetch/XMLHttpRequest
适用场景:用户主动操作(如点击按钮、提交表单),需要实时上报且允许等待响应。
原理:通过 HTTP 请求将数据发送到接入层接口,类似普通的前后端交互。
JS
// SDK中的上报函数(Fetch版)
function trackWithFetch(data) {
fetch("https://平台域名/api/track", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(data),
keepalive: true // 页面关闭时也能尝试发送(增强可靠性)
}).catch(err => {
// 失败时存本地(如localStorage),后续补发
saveToLocalStorage("pendingData", data);
});
}
JS
// SDK中的上报函数(XHR版)
function trackWithXHR(data) {
const xhr = new XMLHttpRequest();
xhr.open("POST", "https://平台域名/api/track", true);
xhr.setRequestHeader("Content-Type", "application/json");
xhr.onreadystatechange = () => {
if (xhr.readyState === 4 && xhr.status !== 200) {
saveToLocalStorage("pendingData", data); // 失败存本地
}
};
xhr.send(JSON.stringify(data));
}2.页面退出上报:Beacon
适用场景:用户离开页面时的行为(如 "页面停留时长""退出原因"),需要确保数据能发出去,不阻塞页面关闭。
痛点:用 Fetch/XHR 可能因页面关闭被中断,导致数据丢失。
原理 :浏览器提供的navigator.sendBeaconAPI,专门用于异步发送 "离开页面时的关键数据",优先级高且不阻塞页面卸载。
JS
// SDK中监听页面关闭事件(用Beacon上报)
window.addEventListener("unload", () => {
const data = {
trackId: "page_leave",
stayTime: Date.now() - pageLoadTime, // 页面停留时长
...baseData // 包含userId、deviceId等基础信息
};
// 转换为FormData(Beacon默认用POST,数据格式需兼容)
const formData = new FormData();
formData.append("data", JSON.stringify(data));
// 发送Beacon请求,返回true表示浏览器已接收任务
const success = navigator.sendBeacon("https://平台域名/api/track/beacon", formData);
if (!success) {
// 浏览器不支持或队列满了
trackWithFetch(data);
}
});技术栈调研选取及理由
| 技术环节 | 技术选型 | 选取理由 |
|---|---|---|
| 数据采集层(SDK 开发) | TypeScript + Webpack | 强类型减少数据格式错误,支持模块化与多端复用; 打包工具保障 SDK 轻量易集成。 |
| 数据传输与接入层 | Spring Boot(Java)+ Redis | Spring Boot 生态成熟,快速搭建高可用接口; Redis 做临时队列削峰、限流,保障高并发稳定性。 |
| 数据处理与存储层 | MySQL + Redis + Quartz | MySQL 存储原始数据,支持复杂查询与事务; Redis 存储聚合数据,提升高频读取效率; Quartz 实现定时聚合任务,稳定可靠。 |
| 可视化与应用层 | React + Vite + ECharts | React组件化思想成熟,适合拆分仪表盘的复杂模块,生态丰富; Vite支持 React 的快速热更新,开发效率不低于 Vue3 场景; ECharts与 React 兼容良好,可通过 |
| 告警通知层 | 企业微信 /飞书 | 配置简单、免费无限制,支持 @指定人员,确保告警及时触达,适合快速落地。 |
2.埋点
埋点这一块我将会从什么是埋点?有什么作用?前端如何埋点?三个角度出发👇
什么是埋点?
埋点 是一种在应用程序的特定功能或用户交互节点(例如用户在应用中的点击、浏览、购买、注册等操作行为)中预先嵌入代码片段,以采集用户行为数据(如操作路径、停留时长、功能使用频次)、系统运行数据(如接口响应时间、报错信息)及业务数据(如订单提交、商品收藏),并将这些数据传输至后端数据平台进行存储、分析,最终用于优化产品功能、提升用户体验、辅助业务决策的技术实现方式。 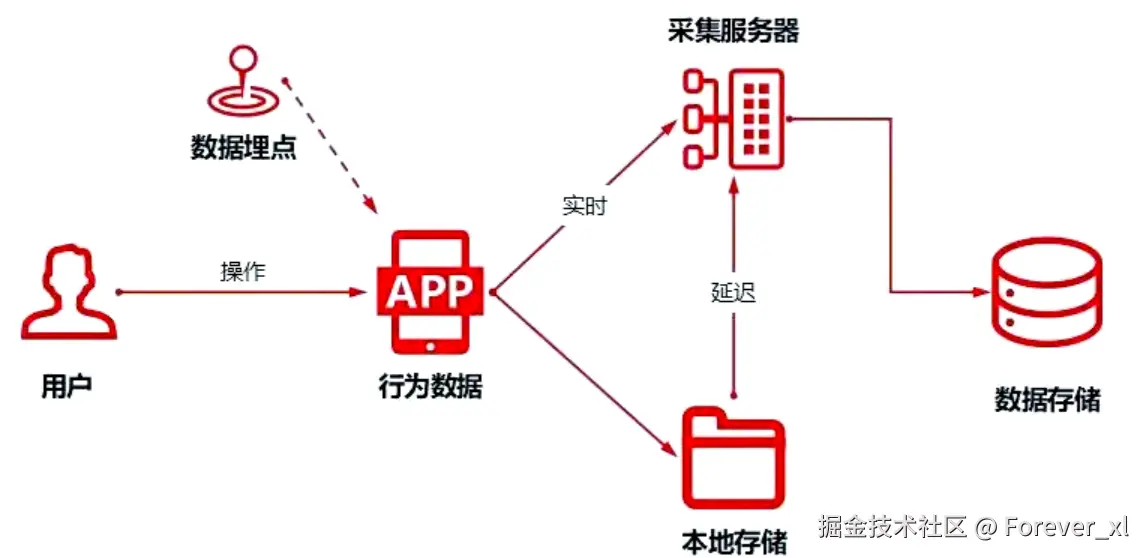
埋点有什么作用?
埋点主要用于收集和分析用户行为数据。通过对收集到的数据进行分析,开发人员和产品团队可以了解用户行为模式、优化产品功能、改善用户体验、评估转化率、针对不同用户群体制定营销策略等。具体分析如下👇
- 🍉收集用户行为数据: 通过在关键位置插入特殊代码,可以收集用户的行为数据,例如用户访问哪些页面,点击哪些按钮,使用哪些功能等。
- 🍊分析用户习惯: 通过分析收集的用户行为数据,可以了解用户的行为习惯,例如用户喜欢使用哪些功能,访问哪些页面,以及在什么时间段使用应用等。
- 🍎提供数据支持: 通过收集用户行为数据,企业可以有更有价值的数据支持,从而制定更科学的产品策略、营销策略和开发策略。
- 🍒优化产品体验: 通过收集用户行为数据,企业可以了解用户使用产品的痛点和需求,从而针对性地优化产品体验,提高用户满意度。
- 🍓提高转化率: 通过分析用户的行为数据,可以找到影响用户转化的关键因素,从而对产品、页面、营销策略等进行优化,提高转化率 什么是转化率?
比如在电商场景中,通过埋点追踪用户 "浏览商品 - 加入购物车 - 下单支付" 的全流程,若发现很多用户在购物车环节流失,就可以分析是价格、配送还是其他原因,然后优化购物车页面的设计、推出满减活动等,从而让更多用户完成支付,提高购买转化率。
举个简单粗暴的例子:100 个用户进入商品详情页,最终有 20 人下单,下单转化率就是 20%。
前端如何埋点?
前端埋点主要有代码埋点、可视化埋点、无埋点(全埋点) 三种核心方案,它们在实现方式、灵活性和成本上各有差异,需根据业务需求选择。
代码埋点
开发人员在代码中手动插入埋点代码,触发特定行为(如点击、提交)时上报数据。
优点:数据精准,仅采集需要的关键行为。可自定义上报字段,满足复杂业务需求。
缺点:开发成本高,需逐个场景写代码。易漏埋或错埋,后期维护麻烦。
使用场景:核心业务场景(如支付、注册)、需自定义数据的场景。
JS
// 给按钮绑定点击事件,触发埋点
document.getElementById('buy-btn').addEventListener('click', () => {
// 业务逻辑:比如跳转到支付页
console.log('用户点击了购买按钮');
// 埋点:上报"购买按钮点击"事件及商品信息
reportEvent('buy_button_click', {
productId: 'p1001',
price: 99
});
});可视化埋点
无需写代码,通过可视化工具选择页面元素(如按钮、链接),设置需要追踪的行为,工具自动生成埋点规则并生效。
优点:非技术人员也能操作,降低开发成本。埋点效率高,可快速配置和修改。
缺点:功能有局限,复杂交互可能无法精准圈选。
使用场景:简单交互,不需要自定义事件的场景。
无埋点(全埋点)
自动采集页面所有用户行为(如所有点击、页面浏览、输入操作),无需人工配置,数据全量上报后再在后台筛选需要的信息。
优点:一次性接入,后续无需维护埋点。可回溯分析,遗漏数据时无需重新埋点。
缺点:数据量极大,增加存储和传输成本。无用数据多,筛选和分析效率低。
使用场景:早期产品探索期、无法预判埋点需求的场景。
国内流行的埋点工具
TalkingData:移动数据分析平台,提供了用户画像、行为分析、漏斗分析等功能
阿里云ARMS:阿里云提供的应用性能监控服务,提供了性能埋点、错误监控、资源优化等功能。
诸葛IO:专业的用户行为分析平台,具备用户行为路径分析、留存分析、漏斗分析等功能,助力企业深入洞察用户行为,优化产品体验与运营策略。
友盟+:国内知名的全域数据智能服务商,覆盖 APP、小程序、H5 等多场景,提供用户增长、数据统计、精准营销等一站式解决方案,助力企业实现数据驱动的业务增长。
神策数据:以用户行为分析为核心的大数据分析平台,提供用户画像构建、行为路径挖掘、智能推荐等功能,帮助企业从数据中挖掘价值,驱动精细化运营与产品迭代。
流行的监控工具
监控 可以实时收集关于实时了解应用的性能表现,
如页面加载速度、响应时间等。这些数据可以为性能优化提供依据,帮助开发者找到性能瓶颈并进行优化,还可以帮助开发者及时发现应用中的错误和异常,通过对监控数据的分析,开发者可以定位问题原因,快速解决问题,降低故障对用户体验的影响
Sentry:一个开源的前端错误监控工具,可以捕获和报告JavaScript和前端框架的错误和异常。它提供详细的错误信息和堆栈跟踪,帮助开发人员快速定位和解决问题。
fundebug:专业的全栈错误监控平台,支持 JavaScript、微信小程序、Java、Node.js 等多技术栈,能实时捕获并分析代码错误、性能异常,提供错误详情、用户行为回溯等功能,助力开发者快速定位和解决线上问题,保障应用稳定运行。
webfunny:轻量级前端监控系统,专注于前端异常和性能监控,支持捕获 JavaScript 错误、资源加载异常、接口请求失败等场景,提供可视化的错误统计和用户行为轨迹,帮助开发者高效排查前端线上问题,提升应用质量。
下面这两个网址需要使用加速器
Google Analytics(谷歌分析):非常流行的网站统计和分析工具,提供了丰富的功能,如用户行为分析、性能监控、事件追踪等。
Lighthouse:由Google提供的开源网站性能分析工具,可以评估页面的性能、可访问性、SEO等方面
相关项目总结
websee(前端监控与埋点)
Github地址:github.com/xy-sea/web-...
demo地址:github.com/xy-sea/web-...
亮点:
- 支持多种错误还原方式: 定位源码、播放录屏、记录用户行为
- 支持项目的白屏检测: 兼容有骨架屏、无骨架屏这两种情况
- 支持错误上报去重: 错误生成唯一的id,重复的代码错误只上报一次
- 支持多种上报方式: 默认使用web beacon,也支持图片打点、http 上报
功能点:
- 错误捕获: 代码报错、资源加载报错、接口请求报错
- 性能数据: FP、FCP、LCP、CLS、TTFB、FID
- 用户行为: 页面点击、路由跳转、接口调用、资源加载
- 个性化指标: Long Task、Memory 页面内存、首屏加载时间
- 白屏检测: 检测页面打开后是否一直白屏
- 错误去重: 开启缓存队列,存储报错信息,重复的错误只上报一次
- 手动上报错误
- 支持多种配置: 自定义 hook 与选项
- 支持的 Web 框架: vue2、vue3、React
monitorjs_horse(前端异常监控工具库)
Github地址:github.com/Jameszws/mo...
npm包地址:www.npmjs.com/package/mon...
亮点:
- 轻量:作为轻量级工具,接入成本低,只需简单配置即可快速在项目中启用监控功能。
- 多框架兼容:对 Vue 等主流前端框架有良好的兼容性,适配多种技术栈的项目。
- 数据可定制化: 支持对采集的数据进行自定义过滤、加工,灵活适配不同业务场景的分析需求。
功能点:
- 前端异常监控:可捕获 JS 语法错误、运行时错误、Vue 框架错误等各类前端异常,还能监控资源加载异常(如图片、脚本加载失败)、接口请求失败等情况。
- 页面性能监控:能够采集页面加载时间、首屏渲染时间、资源加载耗时等性能指标,助力优化页面加载体验。
- 设备信息采集:可获取用户设备的浏览器类型、版本、操作系统、屏幕分辨率等信息,便于分析不同设备环境下的问题。
- 自定义埋点:支持自定义事件埋点,如按钮点击、页面跳转等用户行为,满足个性化的数据采集需求。
webfunny-monitor(前端全链路监控平台)
Github地址:github.com/a597873885/...
npm包地址:www.npmjs.com/package/@we...
官方地址:www.webfunny.cn/
亮点:
- 私有化部署:支持私有化部署,满足企业对数据隐私和安全性的高要求。
- 轻量级:工具使用简单,接入流程便捷,开发者可快速在项目中部署启用监控功能。
- 数据可视化强:提供丰富的可视化图表,如错误统计趋势图、性能指标对比图、用户行为轨迹图等,直观呈现监控数据。
- 功能全面且可扩展:覆盖前端异常、性能、用户行为等多方面监控需求,且支持二次开发和功能扩展,能适配不同业务场景的个性化需求。
功能点:
- 前端异常监控:可捕获 JS 语法错误、运行时错误、资源加载异常(如图片、脚本加载失败)、接口请求失败等各类前端异常,还能记录错误发生时的调用堆栈、用户操作路径等详细信息。
- 性能监控:采集页面加载时间、首屏渲染时间、资源加载耗时、接口响应时间等性能指标,助力优化页面加载体验和接口性能。
- 用户行为埋点与分析:支持自定义事件埋点(如按钮点击、页面跳转、表单提交等用户行为),并能对用户行为轨迹进行可视化分析,了解用户在产品中的操作路径。
- 设备信息采集:获取用户设备的浏览器类型、版本、操作系统、屏幕分辨率、网络环境等信息,便于分析不同设备环境下的问题。
- 告警功能:支持自定义告警规则,当出现异常或性能指标超出阈值时,可通过邮件、钉钉等方式及时通知相关人员。
- 多端支持:适配 Web、微信小程序、React Native 等多端应用的监控需求。