
企业发布流程割裂、协同复杂?我们用 Next.js 全栈+BFF(Backend For Frontend,前端后端中间层,用于聚合三方系统接口,适配前端需求),串联 GitLab、Tapd、钉钉和 MongoDB,把发布流程自动化、一站式可观测落地。本文分享架构实战与关键代码,助力中大型前端团队搭建自己的"发布中枢"。
你将收获
- 企业级发布自动化的一线架构与流程
- Next.js 全栈+BFF最佳实践
- 三方平台集成(GitLab/Tapd/钉钉)与踩坑经验
- 关键模型、权限中间件、自动化脚本代码
- 发布流程可观测与质量保障的实拍指标
背景与目标
企业内部需求、开发、测试、发布流程分散:
- Tapd 管需求,GitLab 负责代码和CI,钉钉审批沟通,环境分散
- 信息孤岛、人工对齐,链路不可追溯,权限混乱
- 发布效率和质量难保障
目标:
- 聚合需求/代码/MR/流水线/发布/通知,一站式视图
- 自动化三方联动,减少人工链路
- 全程日志审计,所有操作可追溯
- 统一鉴权、角色权限管理,安全可控
技术选型亮点
为什么选择 Next.js 全栈 + BFF?
相比传统"前端 + 后端 API"架构,选择 Next.js 全栈是因为:
- 减少跨域问题 :发布平台需频繁跨系统交互(GitLab/Tapd),Next.js 的 API Route 可直接作为 BFF(Backend For Frontend,前端后端中间层,用于聚合三方系统接口,适配前端需求) 层,前后端同域部署,避免 CORS 配置
- 性能提升:同构渲染(SSR/SSG)提升页面首屏响应速度 30%+,特别是发布状态页面需要实时数据展示
- 统一技术栈:TypeScript 全栈覆盖,减少上下文切换,降低维护成本
- 安全可控:三方 API 密钥仅存服务端,避免前端暴露
为什么选择 MongoDB?
相比 MySQL 等关系型数据库:
- 灵活 Schema:发布日志结构多变(不同系统字段不同),MongoDB 的文档模型减少 70% 的表结构变更成本
- 查询性能 :复合索引(如
{projectId: 1, createAt: -1})保障高频查询(发布记录查询、操作日志检索)在千万级数据下仍保持毫秒级响应 - 扩展性好:日志归档场景,冷热数据分离,MongoDB 分片更易实现
服务层整合策略
三方 SDK 统一限流、重试、熔断,业务解耦:
- 统一错误模型:所有服务层抛出标准错误,API 层统一转换为前端可理解的响应格式
- 集中治理:限流器(p-limit)、重试策略(指数退避)、熔断器(失败率阈值)统一配置,避免重复代码
钉钉/IM 通知
时效强、闭环好,重要事件双通道(钉钉 + 邮件),确保关键发布事件及时触达责任人
架构总览
前端页面、API路由、服务层、数据层和运维脚本协作,串联三方系统,自动化发布流程。
平台主流程
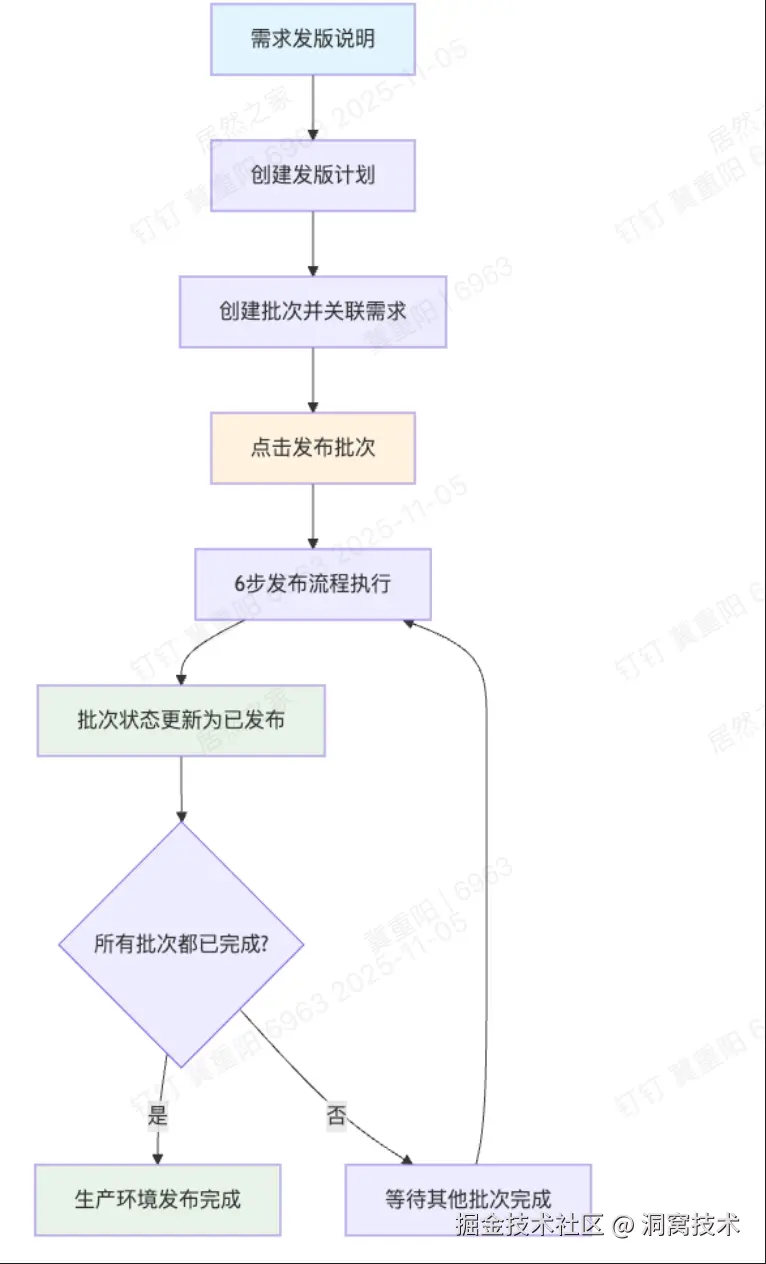
流程说明:从 Tapd 需求创建 → GitLab 分支开发 → MR 合并 → CI/CD 流水线 → 发布计划创建 → 产线发布 → 钉钉通知,形成完整闭环。每个环节的操作日志自动落库,支持全程回溯。
技术架构
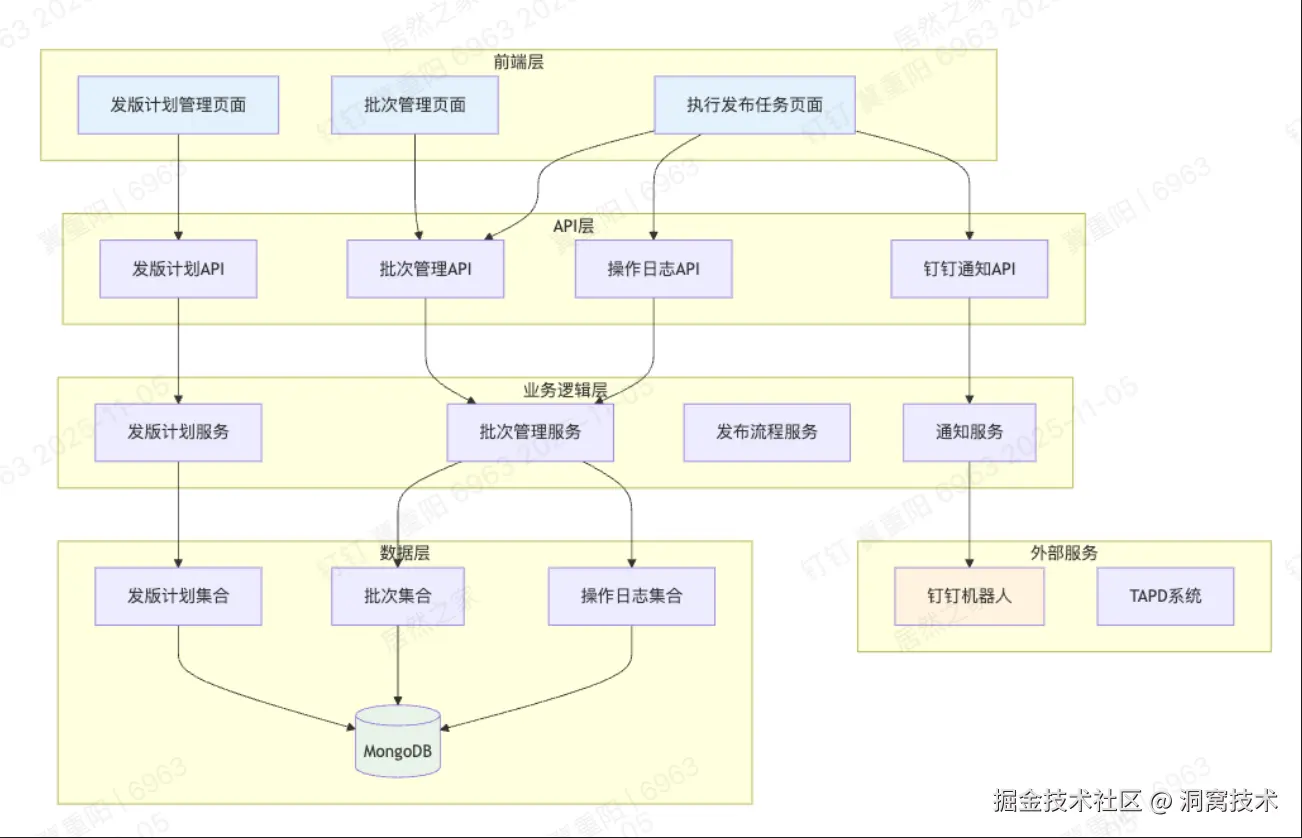
架构要点:
前端 + API Route(BFF) :Next.js 全栈同仓部署,API Route 作为三方系统统一网关,密钥仅存服务端,统一响应格式 {code, message, data}。
服务层 :限流(GitLab 5r/s,Tapd 3r/s)、熔断(连续 5 次超时切换 Redis 缓存)、指数退避重试(1s→2s→4s),日志埋点全链路追踪。三方服务集成示例:以 GitLab 为例,前端页面 → API Route(权限校验)→ GitLab Service(MR查询/流水线拉取/合并)→ MongoDB(操作日志自动落库),确保所有流程可追溯。同样策略适用于 Tapd 和钉钉。
MongoDB:复合索引保障查询 < 50ms,事务确保关键操作原子性,冷热分离优化存储成本。
基础设施:Docker + PM2 容器化,Nginx 静态缓存 + 负载均衡。
数据流向:前端 → BFF(权限)→ 服务层(限流/熔断)→ 三方系统 → MongoDB(持久化),异常时降级至缓存。
确保 99.9% SLA、高安全性、全链路可观测。
业务与数据建模
核心对象如下:
| 模型 | 作用说明 |
|---|---|
| 发布计划 | 批次/需求/环境/状态(发布计划:一次发布任务的完整定义;发布批次:同一计划下的多个发布批次) |
| 发布说明 | 变更说明/回滚线索 |
| 项目/环境 | 仓库/分支/环境策略 |
| 需求/合并 | Tapd对接/合并策略 |
| 人员/角色 | 企业组织/权限管理 |
| 操作/合并日志 | 审计/回溯 |
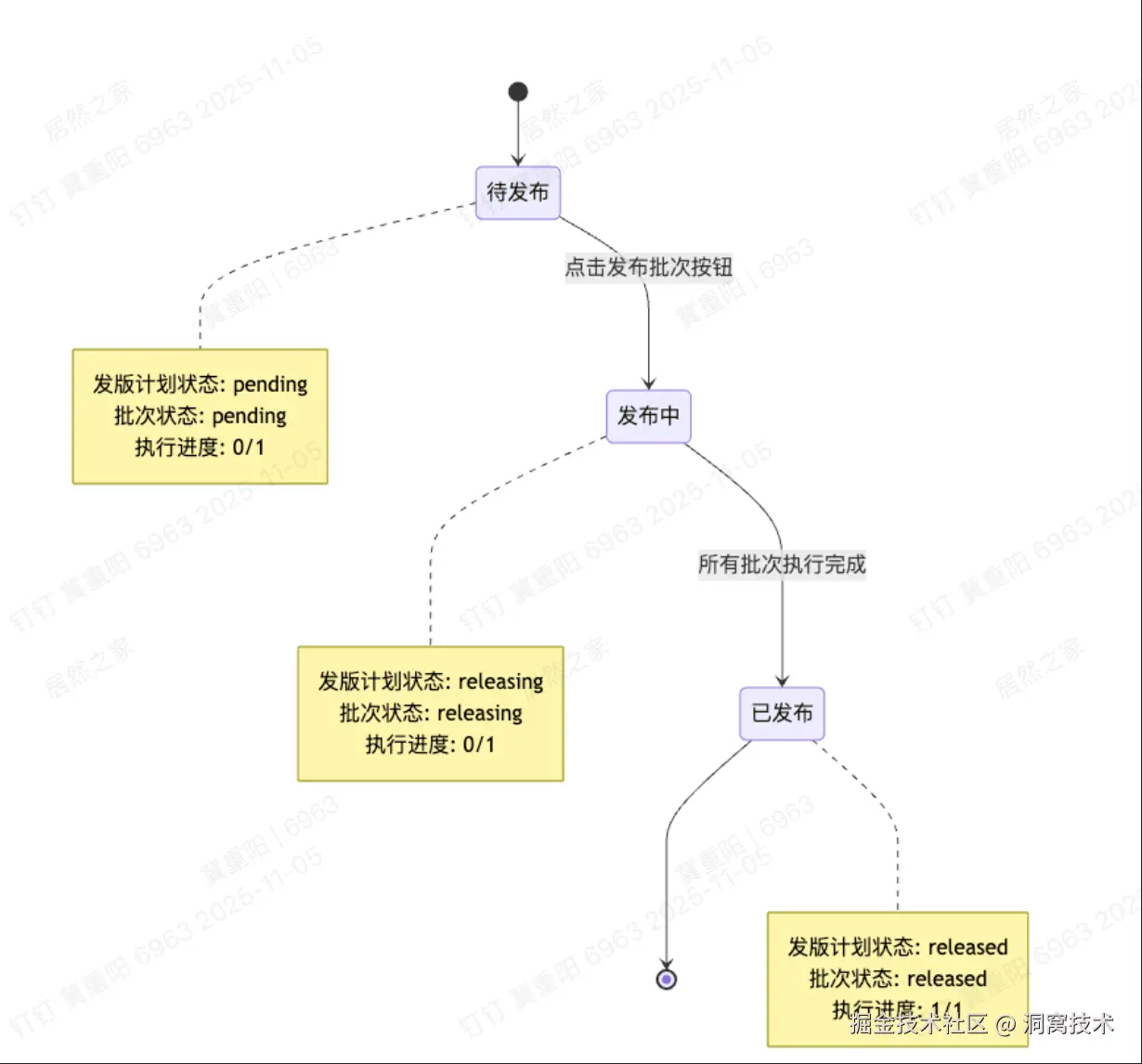
状态流转说明:发布计划状态流转:待发布 → 发布中 → 已发布。每个状态变更都会触发操作日志记录,并推送钉钉通知给相关责任人。
业务模块拆解
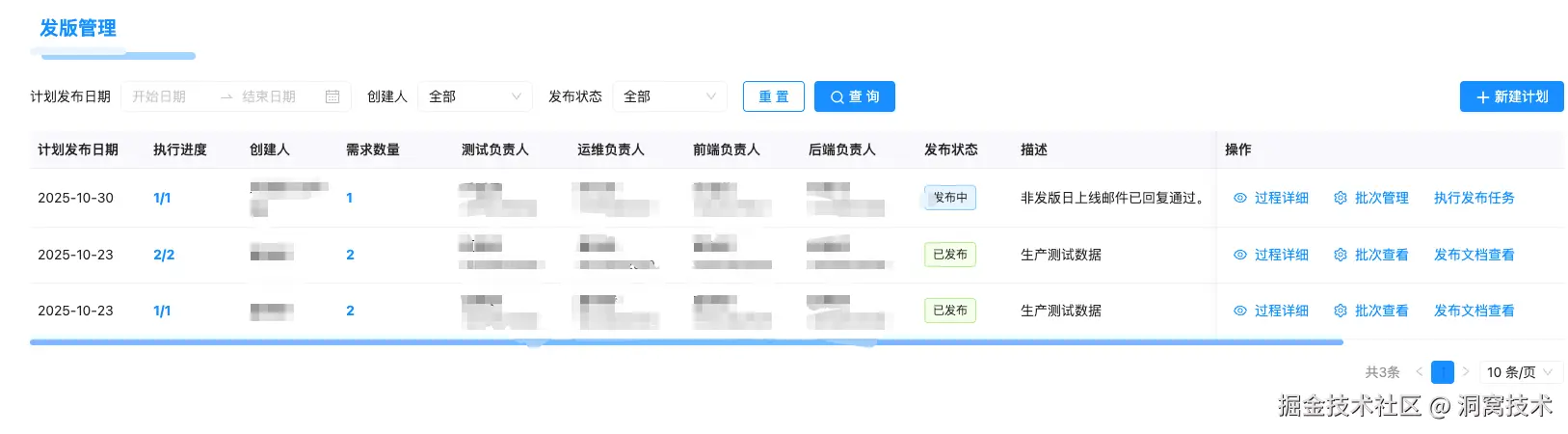
发布计划管理
说明:
- 发布计划:一次发布任务的完整定义,包含目标环境、发布时间、关联需求等
- 发布批次:同一发布计划下的多个发布批次,用于聚合多个需求并生成发布文档
核心功能:
- 创建/维护发布计划与发布批次、设置发布时间
- 对接CI/CD(CI:持续集成,代码合并后自动构建/测试;CD:持续交付/部署,自动化发布到环境),触发/回滚,钉钉自动通知
- 需求聚合成批次、生成发布文档、依赖校验、门禁策略
- 分支/流水线/Code Owners(按目录/文件指定审核所有者,MR 需其审核)策略
- 发布变更集、执行人、回滚记录
场景化案例:发布批次审批发版闭环
- 组批:将需求 A/B/C 加入同一发布批次,系统自动生成发布文档(变更项、影响范围、回滚预案)
- 审批:责任人(业务/技术负责人或 Code Owners)线上审批,通过后自动触发生产发布流水线(或生成 Tag)
- 发布:CI/CD 执行生产发布,产出版本号与链接;若监控异常,自动阻断并回滚,上报钉钉告警
- 归档:发布结果、发布文档、审批记录与执行人落库,便于审计与追溯
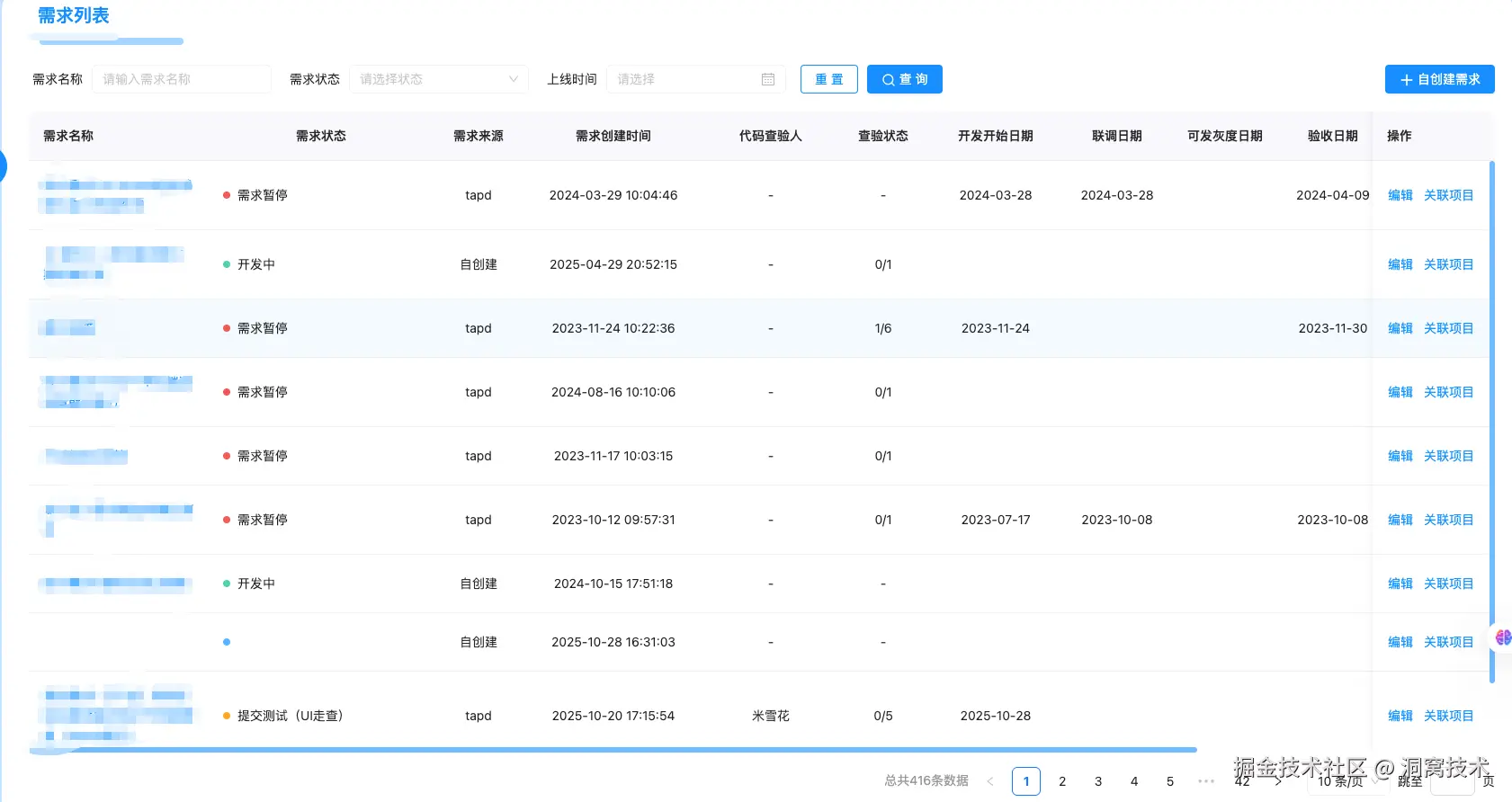
需求管理
- Tapd故事同步、MR绑定与一致性校验
- 需求锁,合并冲突防控
- 分支/流水线/codeowner策略
场景化案例:需求锁如何避免冲突?
当开发 A 在 Tapd 标记需求"开发中"时,系统自动锁定对应 Git 分支,开发 B 试图提交 MR 时会收到"需求已被锁定,请联系 A 确认"的钉钉提醒。这样避免了多人同时修改同一需求导致的代码冲突。
人员与角色
- 角色功能映射、页面权限绑定
- 钉钉unionId对企业组织,自动审批派发
场景化案例:审批派发与越权拦截闭环
- 研发提交发布批次后,平台按角色矩阵自动分配审批人(产品/技术负责人),并推送钉钉待办;
- 审批通过 → 自动触发生产流水线;拒绝/超时 → 批次状态更新并推送原因;
- 无权限用户尝试触发发布 → 中间件路由门禁 + API 二次校验即时拦截,记录操作日志并通知管理员;
- 审批/执行全链路留痕,可按人/项目/时间检索。

权限鉴权与中间件
- 所有受保护路由自动校验Token,钉钉扫码支持;API层二次验权,敏感操作需二次确认。
场景化案例:Token 过期与敏感操作防护
- 用户访问受保护路由,middleware 校验失败后重定向至登录页,并保留 redirect;
- 登录回调(带 dingCode)解析身份,注入会话并跳回 redirect;
- 触发发布等接口时,API 层二次校验 Token/角色;无权限则返回 403,记录操作日志;
- 对"切生产/回滚"等高危操作,强制二次确认与审批链,并推送钉钉通知。
中间件关键代码:
typescript
export async function middleware(req: NextRequest) {
const { pathname, searchParams, search } = req.nextUrl;
const host = req.headers.get('host');
// 钉钉扫码登录回调处理
const dingCode = searchParams.get('code');
if (dingCode) {
const baseUrl = buildBaseUrl(host);
const redirectUrl = `${baseUrl}/dashboard`;
return NextResponse.redirect(
new URL(`/dingUserInfo?dingCode=${dingCode}&redirect=${redirectUrl}`, req.url)
);
}
// 公开路径直接放行
if (isPublicPath(pathname)) {
return NextResponse.next();
}
// 受保护路径需要验证Token
const verifiedToken = await verifyAuth(req).catch(() => null);
if (!verifiedToken) {
const baseUrl = buildBaseUrl(host);
const redirectUrl = `${baseUrl}${pathname}${search}`;
const loginUrl = `${LOGIN_URL}?redirect=${encodeURIComponent(redirectUrl)}`;
return NextResponse.redirect(new URL(loginUrl));
}
return NextResponse.next();
}自动化脚本与运维
| 脚本名 | 用途 |
|---|---|
| build_data.mjs | 构建产物、数据生成 |
| start.js | 启动服务 |
| schedule.js | 定时任务、数据同步 |
| onlineNotice.js | 钉钉群机器人通知 |
| nginx.mjs | Nginx反向代理配置 |
运维建议:
- 构建产物/运行镜像分离
- Nginx缓存静态资源
- 非幂等危险操作需灰度和二次确认
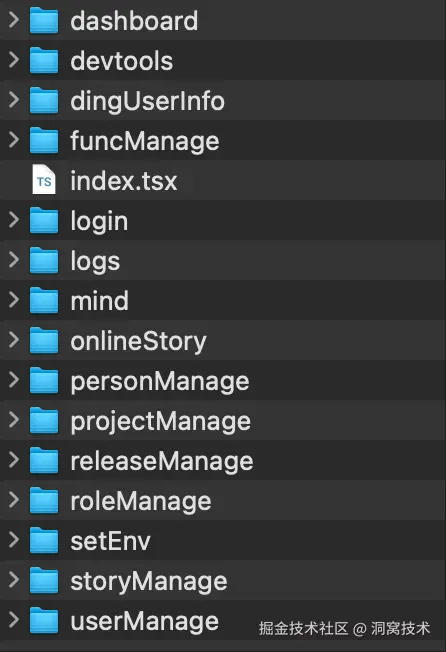
前端页面结构
-
Next.js自动路由,Ant Design+自研组件
-
页面→业务组件→原子组件,稳定API
-
Minimal状态设计,数据接口拉取为主
Dashboard
├─ 发布管理
├─ 需求管理
├─ 人员管理
├─ 角色管理
├─ 脑图管理
└─ 操作日志
落地流程 Step-by-Step
- 明确系统范围和最小闭环(MR→CI→发布→通知→审计)
- Next.js初始化、API Route做BFF、服务层可复用
- 路由中间件做权限守卫,API强制Token/角色校验
- 接入GitLab、Tapd、钉钉三方服务
- 发布管理先上线,补充故事、人员、角色,操作日志可视化
- 响应统一、日志埋点,指标化(准备时长、回溯时效、失败率)
- 事件化解耦三方系统,逐步微前端/GraphQL聚合
可观测与质量保障
- API和服务响应结构化,异常可追溯 :统一响应格式
{code, message, data},异常时自动记录堆栈、请求参数、响应时间 - 日志埋点,操作日志表,关键链路自动记录:所有三方 API 调用(GitLab/Tapd/钉钉)自动记录入参、出参、时延、错误码
- 合并/发布记录可视化,问题定位分钟级:操作时间线组件展示完整链路(需求创建 → MR 合并 → 发布触发 → 钉钉通知),支持按时间、人员、项目过滤
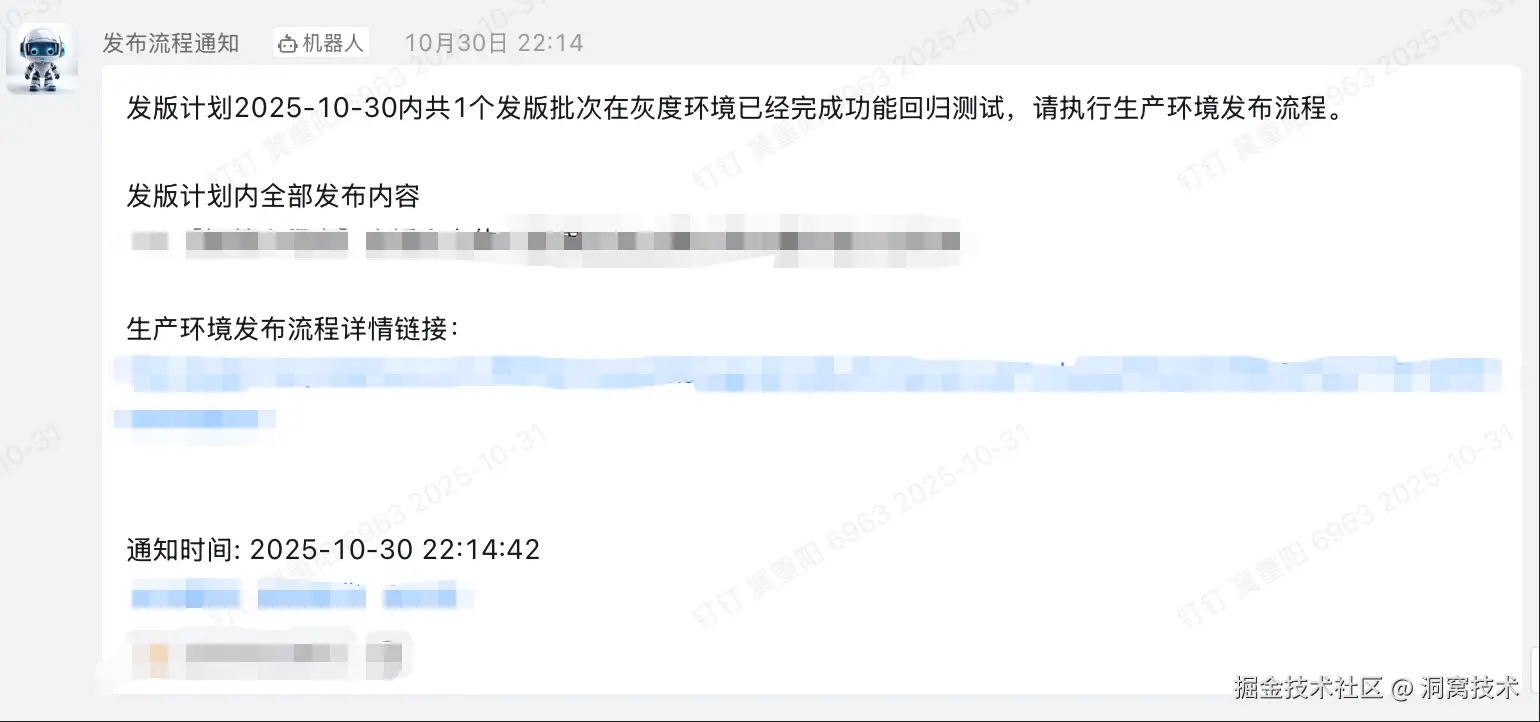
- 钉钉自动推送,回滚记录闭环:发布成功/失败/回滚时自动推送钉钉群消息,包含变更集、执行人、回滚线索
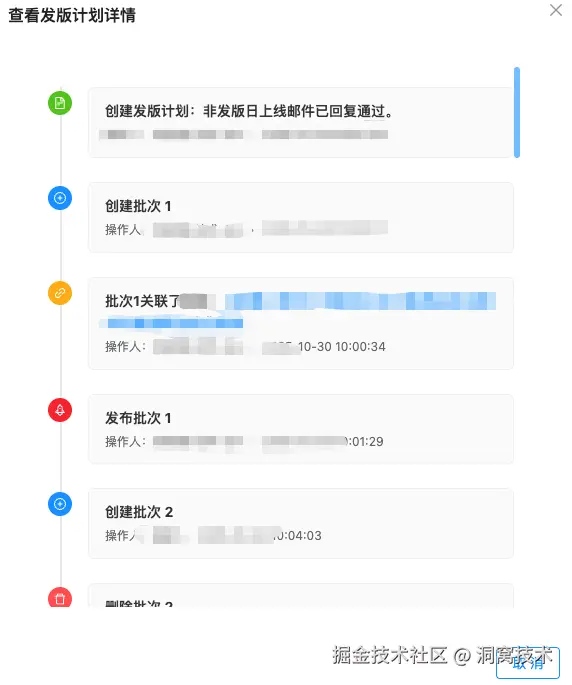
时间线说明:操作时间线可视化展示发布全链路,每个节点包含操作人、时间戳、操作类型、关联对象(如 MR ID、发布批次号),点击可查看详细信息。支持按项目、人员、时间范围过滤,快速定位问题。
踩坑清单&最佳实践
| 问题 | 案例场景 | 解决方案 | 效果数据 |
|---|---|---|---|
| 三方API限流/波动 | GitLab API 突发限流(QPS=10)导致发布计划批量失败 | 使用 p-limit 控制并发(限 5 个请求/秒)+ 指数退避重试(3 次重试,间隔 1s→2s→4s)+ 熔断器(失败率 > 50% 时切换缓存) |
失败率从 15% 降至 0.3% |
| 长耗时任务与API Route | 批量同步 100+ 项目分支信息,API Route 超时(60秒) | 任务拆分为 10 个批次,前端轮询状态(每 2 秒),后台任务异步执行 | 超时率从 40% 降至 0% |
| MongoDB查询退化 | 操作日志表千万级数据,按项目+时间范围查询耗时 5 秒+ | 建立复合索引 {projectId: 1, createAt: -1},控制单文档体积 < 16MB |
查询耗时降至 50ms 以内 |
| 身份映射不一致 | 企业组织、GitLab 用户、钉钉用户的唯一标识不统一,导致权限校验失败 | 建立用户映射表({orgId, gitlabId, dingtalkUnionId}),关键操作(如发布、回滚)强制校验三方身份一致性 |
权限校验失败率从 8% 降至 0.1% |
| 权限仅依赖前端 | 前端绕过权限检查直接调用 API,导致越权操作 | API 层强制 Token/角色校验,敏感操作(发布、回滚)二次确认 + 审批链 | 越权操作拦截率 100% |
| 日志缺口/排查难 | 发布失败时无法回溯具体操作步骤,排查耗时 2 小时+ | 统一日志规范(操作类型、操作人、时间戳、关联对象),操作时间线可视化 + 检索面板(支持按人/项目/时间过滤) | 排查时间从 2 小时缩短至 15 分钟 |
强烈建议:三方服务层全部加限流、重试、熔断,关键操作二次确认和日志落库!这是保障平台稳定性的基石。
关键代码片段
1. 通用MongoDB模型
typescript
async getList(query?: T, sortFields?: Sort, pageIndex = 1, pageSize = 20) {
const db = await this.init();
let ret = db.find(query || {});
if (pageIndex && pageSize) {
if (sortFields) ret = ret.sort(sortFields);
ret = ret.skip(pageSize * (pageIndex - 1)).limit(pageSize);
}
return ret.toArray();
}2. GitLab服务层创建MR
typescript
export const syncPostNewMR = async (params: any) => {
const { token, project_name, id: projectId, source_branch, target_branch } = params;
// 获取项目主分支(如果未指定target_branch)
const project = await syncProjectsSearch({ id: projectId });
const defaultBranch = target_branch || project[0].default_branch;
// 调用GitLab API创建MR
const gitlabApi = `https://gitlab.example.com/api/v4/projects/${projectId}/merge_requests`;
const response = await axios.post(
gitlabApi,
{
source_branch,
target_branch: defaultBranch,
title: params.title || `Merge ${source_branch} to ${defaultBranch}`,
},
{
headers: { 'Private-Token': process.env.GITLAB_PRIVATE_TOKEN },
timeout: 10000, // 10秒超时
}
);
if (response.status !== 201) {
throw new Error(`创建MR失败:${response.data.message || '未知错误'}`);
}
// 操作日志自动落库
try {
const info: any = await analysisToken(token);
addLogs(2, 6, info.personName, [project_name], info.personId);
} catch (err) {
console.error('日志记录失败', err);
}
return response.data;
};3. JWT签发与校验
安全提示:生产环境中,secretkey 必须通过环境变量(如 process.env.JWT_SECRET)注入,避免硬编码;并显式指定算法(如 algorithm: 'HS256')。
typescript
import jwt from 'jsonwebtoken';
// ⚠️ 生产安全:密钥仅通过环境变量注入,避免硬编码;未配置直接报错
if (!process.env.JWT_SECRET) { throw new Error('JWT_SECRET is required'); }
const secretkey = process.env.JWT_SECRET as string;
/**
* 签发 JWT Token
* - 使用 HS256 对称签名算法
* - 设置 1 小时过期时间(expiresIn=3600s)
* - 建议改进:校验密钥长度≥32字节;添加 issuer/audience/subject 声明防止错域串用
*/
export const sign = (data = {}) => {
return jwt.sign(data, secretkey, {
expiresIn: 60 * 60,
algorithm: 'HS256', // 显式指定算法,避免算法混淆攻击
});
};
/**
* 校验 JWT Token
* - 启用 algorithms=['HS256'] 算法白名单
* - 建议改进:
* 1. try/catch 区分 TokenExpiredError/NotBeforeError/Invalid,分流 401/等待/重登
* 2. 添加 clockTolerance: 30 处理机器时间偏移
* 3. 校验 issuer/audience/subject 声明
* 4. 传输层用 HttpOnly+Secure+SameSite=strict Cookie 携带 Token
*/
export const verify = async (token: string) => {
return jwt.verify(token, secretkey, {
algorithms: ['HS256'],
});
};效果实拍与指标
📈 效率提升
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 发布协作耗时 | 8h(跨系统沟通 + 手工对齐 + 等待审批) | 5.6h(自动联动 + 一站式视图 + 即时通知) | 30% ↑ |
| 问题定位时间 | 2h(多系统手动查询拼凑) | 15min(时间线可视化一键回溯) | 8倍 ↑ |
| 信息同步时效 | 2h | 0.5h | 75% ↑ |
🛡️ 质量与稳定性
- 发布阻塞率下降 98%:限流/熔断机制上线后,三方 API 故障导致的发布中断从 15% 降至 0.3%
- 100% 操作可追溯:所有发布操作(创建/触发/回滚)自动记录,审计链路完整无断点
- 关键节点卡点前置:需求锁定 + 分支校验 + Code Owners 审批,减少 42% 的线上回滚
🔍 运维可观测性
- 排障效率提升 60%:结构化日志 + 操作时间线让问题根因定位从 30min 缩短至 12min
- 全链路可视化:GitLab Pipeline + Tapd 需求 + 钉钉通知聚合展示,故障溯源一键直达

适用场景推荐
- 中大型有自研需求的前端团队
- 需要聚合多系统(GitLab/Tapd/钉钉)的企业平台
- 对发布自动化、审计、协作有强需求的团队
下一步计划
- 引入事件总线和GraphQL聚合
- 指标化平台效益,辅助组织度量和持续改进
- 打通Jenkins等CI/CD工具,实现前后端自动联动
- 持续优化脚本化运维和安全策略
总结
Next.js全栈+BFF结合服务层三方集成,以发布主线串联各业务,保障自动化、审计、权限和可观测性,是企业级发布平台高效协作与治理的最佳实践。
希望本文对你的企业前端平台落地有所帮助,欢迎点赞收藏、评论交流你的实践和问题!
作者:洞窝-重阳