这是《深入 Rust 迭代器》 系列的第三部分,我们将通过实例进行学习。我们将探索一些有用但鲜为人知的迭代器特性,以及它们在用 Rust 开发的各种流行开源项目中的应用。
下面是前两篇文章的链接,方便读者跳转复习一下:
获取迭代器

如果你要从数据源获取数据,优先尝试是否可以通过迭代器访问。
我们来看第一个示例,考虑使用正则表达式,正则表达式可以以迭代器的形式提供搜索结果。当你需要在一个很长的字符串中进行搜索,查找多个匹配项,并且不希望一次性将所有结果加载到内存中时,Regex::find_iter 方法就特别有用:
rust
// 查找IP地址
println!("\n查找IP地址:");
let ip_re = Regex::new(r"\b(?:\d{1,3}.){3}\d{1,3}\b").unwrap();
let ip_text = "服务器地址: 192.168.1.1, 备用地址: 10.0.0.1, 无效IP: 999.999.999.999";
for mat in ip_re.find_iter(ip_text) {
println!("找到IP: '{}' at {:?}", mat.as_str(), mat.range());
}
// output
// 查找IP地址:
// 找到IP: '192.168.1.1'
// 找到IP: '10.0.0.1'
// 找到IP: '999.999.999.999'在这种情况下,我们有一个正则表达式 ip_re,用于在内容中进行搜索,目的是逐个查找符合规则的内容,这里是 IP 地址。find_iter 创建的迭代器会生成 Match 结构体,该结构体保存着每个匹配项的详细信息,包括原始字符串中的起始和结束索引。
在我们的示例中,mat.as_str() 会返回匹配到的字符串,mat.range() 会返回这些匹配项在原文中的范围。
再举一个例子,让我们看看 Bevy 项目。Bevy 采用了 ECS (实体、组件、系统)模式,其中系统负责处理组件。为了协调各种系统的执行,Bevy 的 ECS 利用了调度机制。这些调度是使用由 petgraph 板条箱支持的图来设计的 。图作为复杂的数据结构,通过几个迭代器提供对其内部数据的访问。在下面的代码片段中,我们以相反的顺序访问图的节点。然后,对于每个节点,我们通过遍历出边来探索其邻居:
rust
for a in topsorted.nodes().rev() {
let index_a = *map.get(&a).unwrap();
// 按拓扑顺序迭代它们的后继节点
for b in topsorted.neighbors_directed(a, Outgoing) {
//...nodes 和 neighbors_directed 方法都会返回迭代器。值得注意的是,Bevy 的开发者并没有试图将所有代码都整合到迭代器流水线中。考虑到每次迭代的复杂性以及可能出现的深度嵌套,选择使用显式循环是很合理的。
像图这样的复杂数据结构,通常会提供多个用于访问其数据的迭代器。花些时间研究这些接口并找出可用的迭代器,对于编写地道的 Rust 代码非常有帮助。
一般来说,许多数据来源都有迭代器接口。一旦获取了迭代器,就可以充分利用各种迭代器工具来高效地处理数据。
构建迭代器:successors 和 from_fn
有时,数据源可能不会直接提供迭代器接口,而是提供一个用于检索下一个元素的函数或一种构造迭代器的方法。此外,在没有预先存在的数据且必须通过算法生成数据的情况下,仍然可以使用迭代器。
std::iter::successors 函数为这些场景提供了一个绝佳的解决方案。该函数接受一个初始元素以及一个返回 Option 的函数,Option 中要么包含下一个元素,要么包含 None。以这种方式创建的迭代器可以以常规方式使用。
我们看一下简单的示例代码:
rust
for i in std::iter::successors(Some(12345u32), |&n| if n == 0 { None } else { Some(n / 10) }) {
println!("{}", i);
}
// output
// 12345
// 1234
// 123
// 12
// 1
// 0该代码中,successors 的第一个参数是 Some(12345u32),表示该迭代器的初始值,后续 |&n| if n == 0 { None } else { Some(n / 10) } 是生成值的函数。
如结果输出那样,从 12345 到 0 都进行了输出。
以极快的速度著称的 Python 代码检查和格式化工具 Ruff ,也使用了 successors:
rust
std::iter::successors(
Some(AnyNodeRef::from(preceding)),
AnyNodeRef::last_child_in_body,
)
.take_while(|last_child|...)
.any(|last_child| ...)上面例子中,我们要确定某个前面的代码元素之前或之后是否需要空行。所有这些元素都是树结构的一部分,我们使用一个函数来识别子树最后一个分支中的最后一个子元素。通过使用 successors,我们创建了一个由所有这类最后子元素组成的数据流,并以常规方式对其进行遍历。
std::iter::successors 函数需要一个初始种子来启动。它还依赖前一个元素来生成下一个元素。有时,生成这些元素的模式并不简单,特别是当我们需要维护一些状态来推导后续元素时。std::iter::from_fn 函数就是专门为这种情况设计的。
在下面这个取自 Meilisearch 项目的示例中,std::iter::from_fn 函数用于生成一个无穷的随机数序列。该序列是使用一个随机数生成器构建的:
rust
let mut rng = rand::rngs::SmallRng::from_seed([0; 32]);
for key in std::iter::from_fn(|| Some(rng.gen_range(0..256))).take(128) {
//...
}from_fn 函数提供了极大的灵活性,可以执行构造下一个元素所需的任何操作。
在来自 InfluxDb 项目的这个示例中,作为参数传递给 from_fn 的一个函数包含一个循环。这个循环从缓冲区读取数据,解码数据,并在数据准备好后返回下一个元素:
rust
fn decode_entries<R: BufRead>(mut r: R) -> Result<Vec<ListEntry>> {
let mut decoder = ListDecoder::default();
let iter = std::iter::from_fn(move || {
loop {
let buf = r.fill_buf().unwrap();
// ...
}
decoder.flush().transpose()
});
iter.collect()
}值得注意的是,将闭包捕获的可变变量移入 from_fn 函数是常见的做法。每当迭代器请求下一个元素时,都会调用这个闭包。每次调用都会改变状态,因此需要拥有该状态的所有权。
合并数据流

一旦获得迭代器,它并不总是可以立即进行元素处理。你可能需要:
- 在开头或结尾添加一些元素,以方便算法运行;
- 合并多个数据流以便进行统一处理;
- 用来自其他源的额外信息丰富每个元素。
在这些情况下,迭代器的两个特性非常有用: chain 和 zip 。std::iter::Iterator::chain 方法将两个迭代器连接起来,创建一个单一的迭代器,该迭代器先产生第一个迭代器中的元素,直到耗尽,然后产生第二个迭代器中的元素。std::iter::Iterator::zip 方法将两个迭代器中的元素配对,形成一个元组迭代器。
此外, once 和 repeat 函数旨在分别生成返回单个指定元素或重复元素的无限序列的迭代器。它们的对应函数 once_with 和 repeat_with 则根据需要动态创建元素。当通过 chain 或 zip 适配器与其他迭代器结合使用时,这些函数特别有用。
chain:
rust
let iter1 = vec![1, 2, 3].into_iter();
let iter2 = vec![4, 5, 6].into_iter();
let chained: Vec<i32> = iter1.chain(iter2).collect();
println!("连接: {:?}", chained);
// output
// 连接: [1, 2, 3, 4, 5, 6]zip:
rust
let names = vec!["Alice", "Bob", "Charlie"];
let ages = vec![25, 30, 35];
let paired: Vec<(&&str, &i32)> = names.iter().zip(ages.iter()).collect();
println!("配对: {:?}", paired);
// output
// 配对: [("Alice", 25), ("Bob", 30), ("Charlie", 35)]once:
rust
let single_value = iter::once(42);
let once_vec: Vec<i32> = single_value.collect();
println!("once(42) 结果: {:?}", once_vec);
let start = iter::once(0);
let middle = vec![1, 2, 3];
let end = iter::once(4);
let combined: Vec<i32> = start.chain(middle).chain(end).collect();
println!("在 [1,2,3] 前后添加元素: {:?}", combined);
// output
// once(42) 结果: [42]
// 在 [1,2,3] 前后添加元素: [0, 1, 2, 3, 4]repeat:
rust
let repeated: Vec<&str> = iter::repeat("hello").take(5).collect();
println!("重复 'hello' 5次: {:?}", repeated);
// output
// 重复 'hello' 5次: ["hello", "hello", "hello", "hello", "hello"]因为 repeat 会一直产出数据,所以一般搭配 take 使用,防止迭代器无法结束。
简单的介绍完用法之后,让我们看看真实项目中的应用。
redis-rs 这个库如何使用这种策略来管理主节点及其副本之间的访问:
rust
std::iter::once(&self.primary).chain(self.replicas.iter())上述代码生成了一个迭代器,它可以毫无差别地无缝遍历主节点及其所有副本。
接下来看 JavaScript 运行时 Deno,我们会发现另一个极具说明性的例子:
rust
self
.open_docs
.values()
.chain(file_system_docs.docs.values())
.filter_map(|doc| {
//...我们有已打开的文档,也有存储在文件系统中的文档,这都需要进行统一处理。
至于使用 zip,让我们看看 Deno 将 16 字节的输入块加密为匹配的输出块的方法:
rust
for (input, output) in input.chunks(16).zip(output.chunks_mut(16)) {
encryptor.encrypt_block_b2b_mut(input.into(), output.into());
}不可变的输入块与相应的可变输出块进行 zip 操作,这样加密器始终知道将加密数据放在何处。
Rust 代码检查工具 Clippy 使用 zip 和 repeat_with 来生成按降序排列的元素:
rust
let mut i = end_search_start;
let end_begin_eq = block.stmts[block.stmts.len() - end_search_start..]
.iter()
.zip(iter::repeat_with(move || {
let x = i;
i -= 1;
x
}))请注意,repeat_with 闭包会被多次执行,每次都会产生一个新元素。
还有 zip 的另一种变体:std::iter::zip 函数。它接受两个实现了 IntoIterator 特征的参数,将它们转换为迭代器,然后将它们进行 zip 操作。
例如,在 Ruff 中,这个函数用于对向量和切片的元素进行 zip 操作,而无需事先引用相应的迭代器:
rust
std::iter::zip(&tuple.elts, args)zip 适配器有一个会消耗迭代器的对应方法,即 Iterator::unzip 方法,该方法作用于成对元素的迭代器,将其第一个和第二个组件同时收集到两个单独的容器中。
在用于多平台部署的应用程序框架 Tauri 的实现中,可以看到这种传统的用例:
rust
let (paths, attrs): (Vec<Path>, Vec<Vec<Attribute>>) = command_defs
.into_iter()
.map(|def| (def.path, def.attrs))
.unzip();我们有一个结构体向量,每个结构体有两个成员,我们的目标是将其拆分成单独的向量。将构建成对的 map 与 unzip 结合起来可以完成此任务。
处理数据流的不同部分

在许多情况下,我们的代码遵循线性流程:获取或创建一个迭代器,应用几个处理步骤,最后使用该迭代器。然而,有些情况下这种线性方法并不足够,特别是当我们希望以不同方式处理数据流的不同部分时。
例如,以特别的方式处理开头的一组元素就需要特定的操作:
- 将迭代器绑定到局部变量或存储在结构体的成员中。
- 确保在处理开头的一组元素时,不转移迭代器的所有权。
虽然第一个操作相对简单(不过可能需要将变量设为可变的,特别是在显式调用 next() 的时候),但第二个操作需要更细致地了解如何使用 by_ref 适配器。
请看以下代码片段:
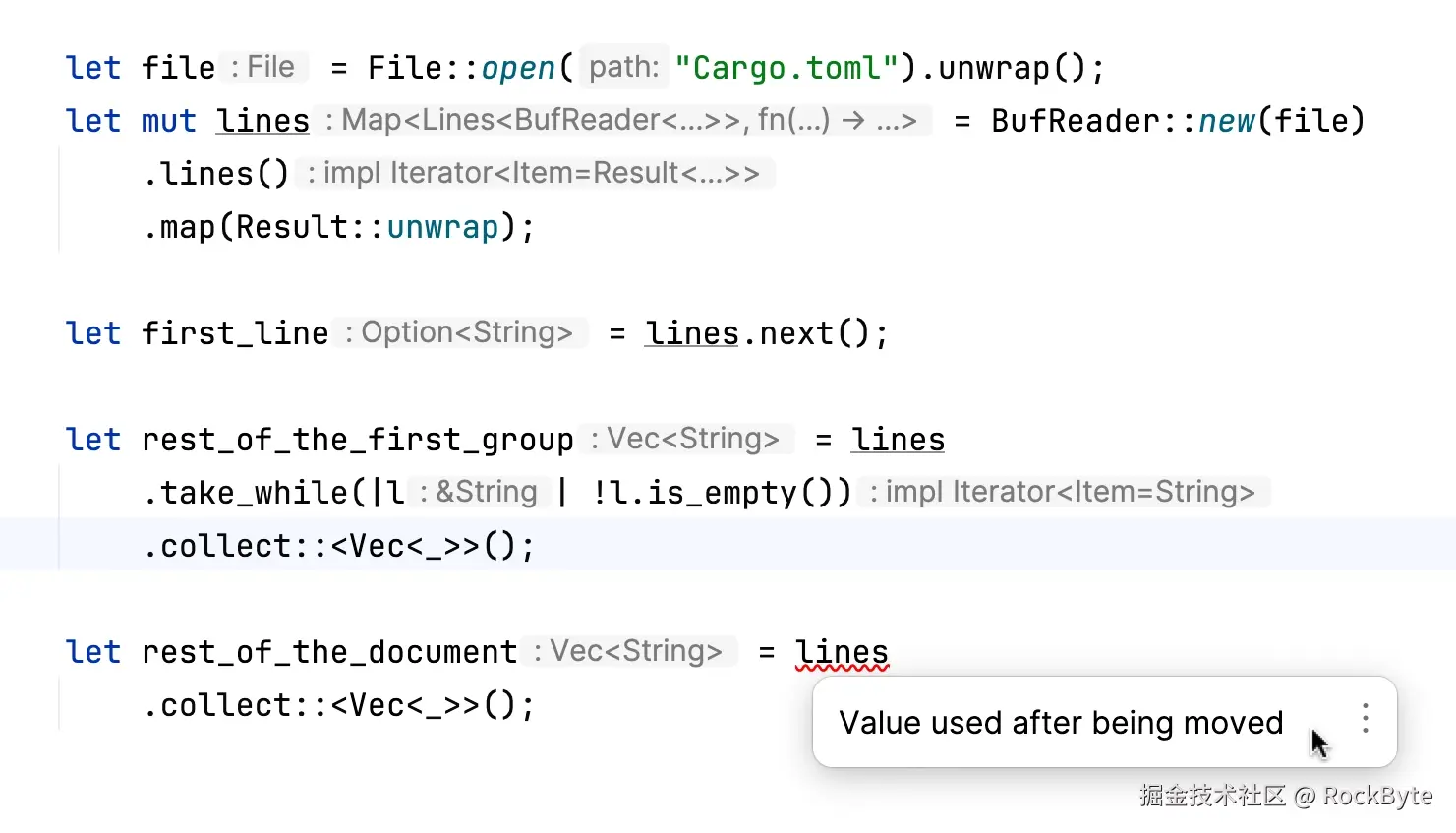
我们打开一个文件,并为其所有行准备一个迭代器。我们读取第一行 ------ 此操作要求 lines 变量是可变的。我们继续读取行,直到遇到空行,然后继续读取剩余的行。take_while 适配器带来了一个问题,它会获取 lines 迭代器的所有权,使我们无法进一步使用它。
为了解决这个问题,当首次将迭代器与迭代器适配器一起使用时,我们必须提供对该迭代器的可变引用,如下所示:
rust
let rest_of_the_first_group = lines
.by_ref()
.take_while(|l| !l.is_empty())
.collect::<Vec<_>>();注意这里对 by_ref 方法的调用。
从它的实现可以看出,其主要功能是传递可变引用:
rust
fn by_ref(&mut self) -> &mut Self
where
Self: Sized,
{
self
}我们看一个更简单的例子:
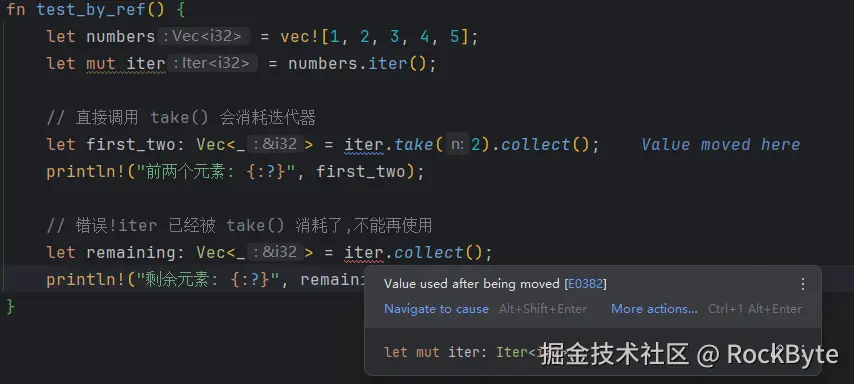
因为 take 会消耗迭代器(即获得迭代器的所有权),所以 iter 不能再后续使用。
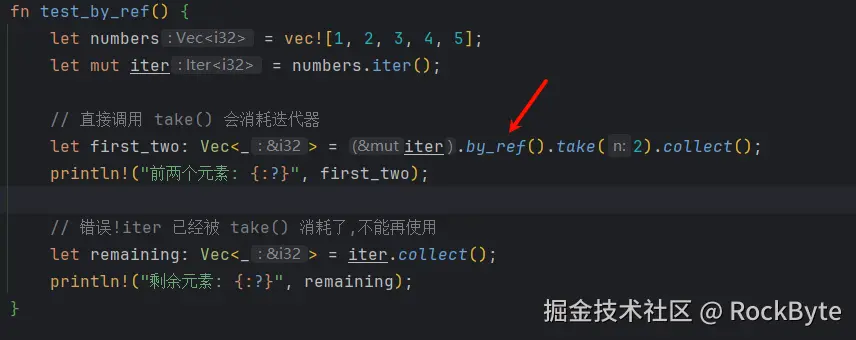
只需要简单的加入 by_ref,该问题便迎刃而解。
我们看一下真实项目中的例子,以下是来自 Ruff 源代码的简化示例:
rust
let mut lines = ...
for line in lines.by_ref() {
if ... {
...
break;
}
}
for line in lines {
if ... {
...
break;
}
}我们先处理第一组元素,然后处理剩余的元素。by_ref 方法使我们能够保留对 lines 迭代器的所有权。
调试管道
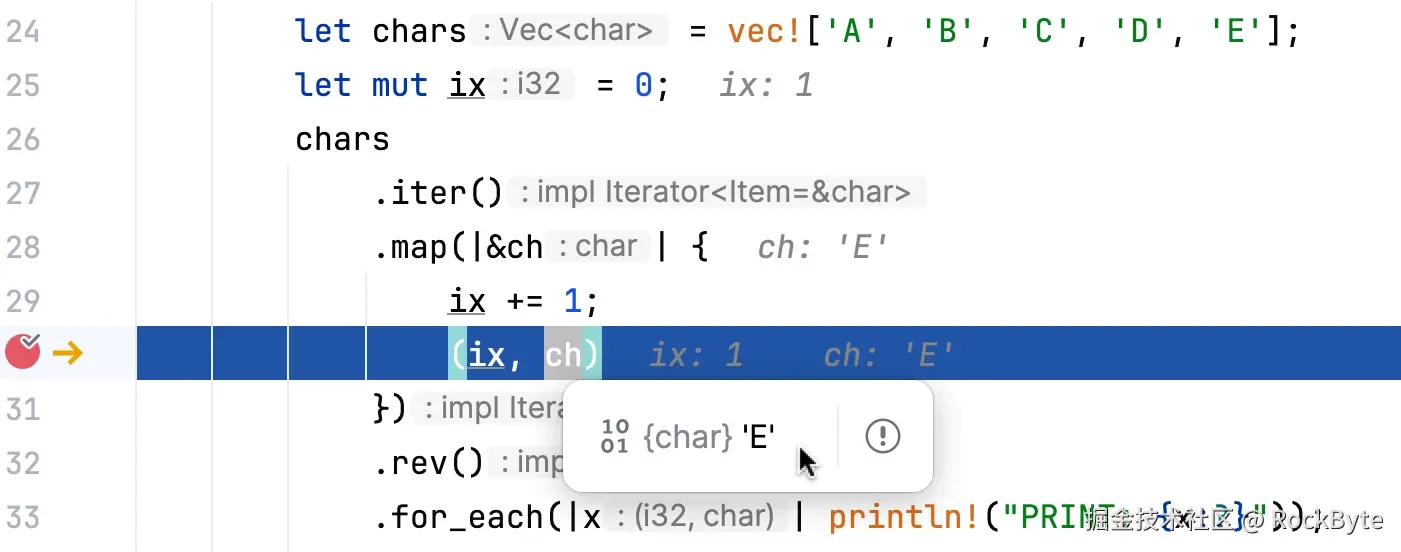
我们来看以下代码:
rust
let chars = vec!['A', 'B', 'C', 'D', 'E'];
let mut ix = 0;
chars
.iter()
.map(|&ch| {
ix += 1;
(ix, ch)
})
.rev()
.for_each(|x| println!("PRINT: {x:?}"));各位可以先猜测一下输出是什么?
要想知道这种情况下的输出,需要理解映射中的副作用与迭代器管道中 rev 适配器的使用之间的相互作用。这里的关键是警告你不要将涉及副作用(例如读取和修改变量)的映射操作与 rev 适配器混合使用。无论迭代器管道中 rev 和 map 的出现顺序如何,输出都是相同的,这说明了在组合这些操作时的复杂性以及可能出现意外结果的情况:
txt
PRINT: (1, 'E')
PRINT: (2, 'D')
PRINT: (3, 'C')
PRINT: (4, 'B')
PRINT: (5, 'A')之所以输出是这样的,根本原因在于迭代器固有的惰性。map 中的闭包会在 for_each 中的打印操作之前立即执行。到这个阶段,所有元素已经以逆序呈现。因此,原始向量的最后一个元素被赋以 ix 的初始值。也就是说,当运行 map 时,元素已经是逆序了。
让我们记住这些核心要点:
- 惰性求值:
map不会提前执行 rev()改变迭代顺序:从后往前遍历- 副作用的顺序:
ix += 1按照rev()后的顺序执行 for_each消费迭代器:按照当前迭代顺序(已反转)逐个处理
尝试一次调试会很快发现这种行为:
如果你更喜欢分析程序输出,那么 inspect 迭代器适配器在这种情况下是另一个很有用的工具。
rust
chars
.iter()
.inspect(|ch| println!("INSPECT: {ch}"))
.map(|&ch| {
ix += 1;
(ix, ch)
})
.rev()
.for_each(|x| println!("PRINT: {x:?}"));输出如下:
txt
INSPECT: E
PRINT: (1, 'E')
INSPECT: D
PRINT: (2, 'D')
// ... 在其他迭代器适配器之间放置多个 inspect 调用,对于跟踪处理流程以及正确理解操作顺序很有帮助。如前所述,在更复杂的场景中,将处理流程划分为多个独立的函数,也有助于提高代码的可读性和可管理性。
总结
该篇文章探讨了使用 Rust 迭代器的很多场景。通过来自 Ruff 、Deno 、Bevy 、Clippy 、redis-rs 、Tauri 、Meilisearch 和 Bloop 等实际项目的示例以及简单的自测项目,我们了解了迭代器如何便利诸如构建可迭代对象、链式操作、合并以及数据转换等操作。
我们着重介绍了处理迭代器的技巧,包括使用 by_ref 方法来保留所有权并避免过早消耗迭代器。
此外,我们还讨论了理解迭代器惰性以及为调试和分析而合理放置 inspect 调用的重要性。在所有示例中,RustRover 的代码分析和调试器帮助我们理解代码并快速解决出现的任何问题。
总体而言,这些技巧能让我们为各种应用程序编写地道且高效的 Rust 代码。