目录
- 一、SortedSet点赞模块:
-
- [1. 点赞功能实现:](#1. 点赞功能实现:)
- [2. 按照点赞时间将点赞人排序:](#2. 按照点赞时间将点赞人排序:)
- 二、Feed流:
-
- 1.Feed流实现方案:
-
- [1.1 拉模式(读扩散):](#1.1 拉模式(读扩散):)
- [1.2 推模式(写扩散):](#1.2 推模式(写扩散):)
- [1.3 读写混合:](#1.3 读写混合:)
- 2.推模式实现将用户发布的动态推送给粉丝:
- 3.SortedSet滚动分页查询:
一、SortedSet点赞模块:
1. 点赞功能实现:
这里写redis和写数据库两步操作其实是会有线程安全问题的,应该加事务和锁。
java
public Result likeBlog(Long id) {
String userId = UserHolder.getUser().getId().toString();
// 有对应数据返回具体分数,没有则返回null
Double score = stringRedisTemplate.opsForZSet().score("like:" + id, userId);
if (score == null){// 这里直接用null来判断返回值null或空对象(区别在于是否分配内存地址),String\List\Map判断空对象就要用isEmpty()了
stringRedisTemplate.opsForZSet().add("like:" + id, userId, System.currentTimeMillis());// 用当前ms时间作为排序值
update().setSql("liked = liked + 1").eq("id", id).update();
}else{
stringRedisTemplate.opsForZSet().remove("like:" + id, userId);
update().setSql("liked = liked - 1").eq("id", id).update();
}
return Result.ok();
}2. 按照点赞时间将点赞人排序:
java
public Result queryBlogLikes(Long id) {
// 点赞顺序前5的用户id集合
Set<String> userIds = stringRedisTemplate.opsForZSet().range("like:" + id, 0, 4);
if (userIds == null || userIds.isEmpty()){// 没有点赞信息
return Result.ok(Collections.emptyList());
}
/** 查询用户 select * from tb_user where id in (#{userIds}) order by field (id, #{userIds})
* order by field (id, #{userIds}) 是因为"in"查询的返回结果是按照用户id排序的,而不是按照userIds排序,导致返回给前端的用户顺序错乱
* userIds.stream().map(Long::valueOf).collect(Collectors.toList())是将String类型的List转为Long类型的List
* StrUtil.join(",",userIds)是将userIds拼接成字符串,以逗号分隔
*/
List<User> users = userService.query().
in("id", userIds.stream().map(Long::valueOf).collect(Collectors.toList()))
.last("ORDER BY FIELD(id," + StrUtil.join(",", userIds) + ")").list();
List<UserDTO> userDTOS = new ArrayList<>();//为了防止用户信息泄露所以只返回给前端用户基础信息
users.forEach(user -> {
UserDTO userDTO = new UserDTO();
BeanUtil.copyProperties(user,userDTO,true);
userDTOS.add(userDTO);
});
return Result.ok(userDTOS);
}二、Feed流:
Feed流也叫关注推送,为用户持续推送消息的一种方式。
Feed流常见有两种实现模式:
- Timeline:不做内容筛选,推送内容按照内容发布时间排序,例如微信朋友圈。
- 智能排序:利用推荐算法推送用户感兴趣的内容,例如抖音。
1.Feed流实现方案:
在redis中,可以为用户创建收件箱和发件箱:
- 收件箱:用来接收消息,推送给用户的消息保存在用户的收件箱中。
- 发件箱:用户自己的消息保存在该用户的发件箱中,用于发送消息。
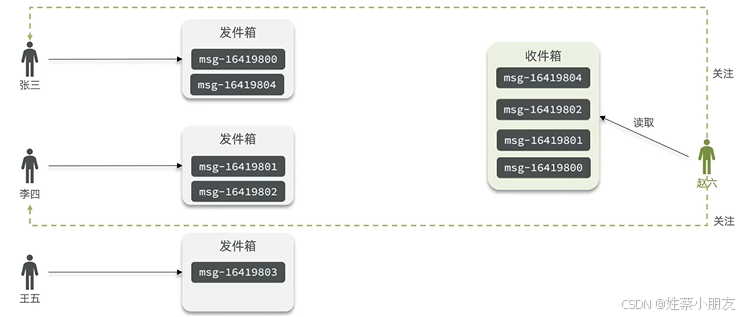
1.1 拉模式(读扩散):
每个用户只需维护发件箱,用户A发消息时服务器都会将该消息保存到用户A的发件箱中。用户B想要查看消息时,会从用户A的发件箱中获取消息。
优点:每条消息只存一份,节省redis内存空间
缺点:读消息要查发件箱,延迟高
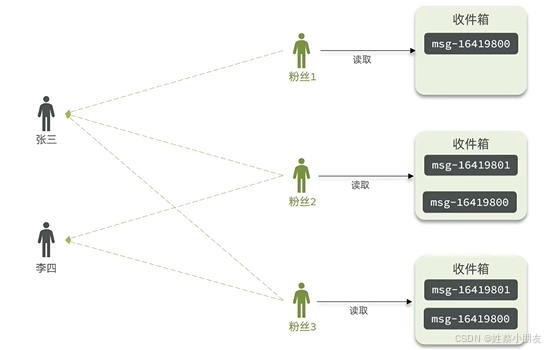
1.2 推模式(写扩散):
每个用户只需维护收件箱,用户A发消息时服务器都会将该消息推送到用户B的收件箱中。用户B想要查看消息时,只需要从自己的收件箱中获取消息。
优点:读消息速度快,延迟低
缺点:每条消息保存n份,非常占用redis内存空间
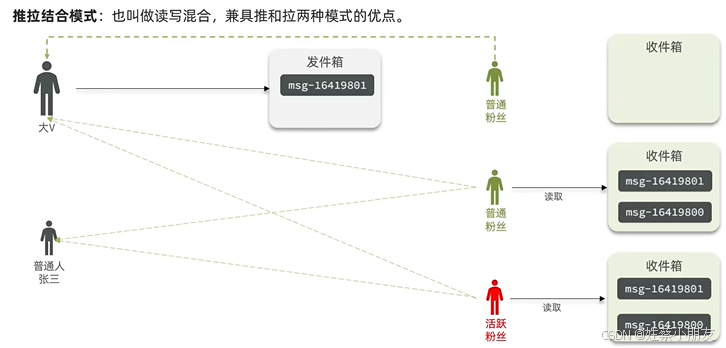
1.3 读写混合:
读写混合结合了推模式和拉模式的优点。
每个用户需维护发件箱和收件箱 。
用户A发消息时:
- 若接收该消息的用户太多(好友太多或粉丝太多),那么服务器都会将该消息保存到用户A的发件箱中。
- 更进一步设计,若用户A是用户B的特别关注,那么将消息保存到用户B的收件箱中。
- 若用户C是用户A的僵尸粉,或用户C不经常查看消息,那么将消息保存到用户A的发件箱中。
- 若接收该消息的用户很少,那么服务器都会将该消息保存到其他用户的收件箱中。
用户B想要查看消息时:
- 先查看自己的收件箱,再查看其他用户的发件箱。
具体可以灵活设计,例如如果用户是活跃用户那么可以把消息推到他的收件箱中,反之不经常刷抖音的用户没必要给他开辟收件箱,他想刷视频那么就去其他用户的发件箱中获取视频。新用户的话不能亏待他就用推模式,等用久了再杀熟。
此外,如果用户经常发高质量视频,那么完全可以用推模式,直接将通知推送到其他用户的手机中,反之低质量视频就不用推,拉模式节省内存就够了。
2.推模式实现将用户发布的动态推送给粉丝:
java
@Override // 发布动态
public Result saveBlog(Blog blog) {
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存动态
save(blog);
// 获取粉丝
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
if (follows != null && !follows.isEmpty()){
// 获取粉丝id
follows.forEach(follow -> {
// 推送当前动态的id到所有粉丝的redis收件箱中
stringRedisTemplate.opsForZSet().add("receive:"+follow.getUserId(),blog.getId().toString(),System.currentTimeMillis());
});
}
// 返回id
return Result.ok(blog.getId());
}3.SortedSet滚动分页查询:
由于SortedSet是有序的,当按照插入时间排序时(当数据有序时 ),若按照下标分页 ,会出现如下问题:t1时刻读取时间最新的5条数据,则第一页数据为6~10。t2时刻插入了一条数据11,此时t3时刻会读取第二页数据,正常应该读取1~5,但是由于中途插入数据导致下标发生变化,导致数据下标混乱(本质) ,会重复的读数据6。如下图所示:
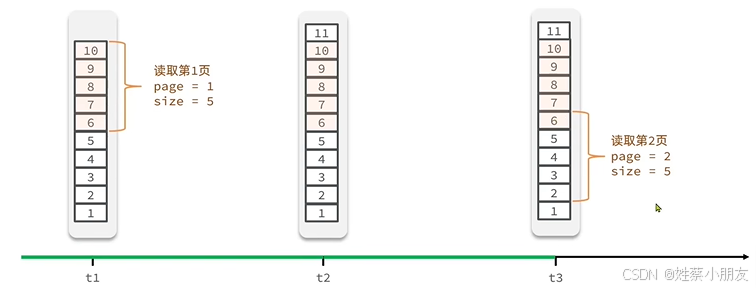
滚动分页的思想是:记录t1时刻读的最后一条数据6,t2时刻从6号数据的下一个数据,即5号数据开始读。如何记录每次查询的最后一条数据 ?可以按照元素进入集合的先后顺序给每个元素编号,元素的编号给定后就固定不变,每次记录读的最后一个数据的编号x (而非下标),然后给定偏移量offset为与x编号相同的元素个数 ,那么下一次从x-offset开始读。
java
@Override // lastId:上一页的最小时间戳,也就是这一页的最大时间戳,开区间;offset:偏移量
public Result ofFollow(Long lastId, Integer offset) {
// 按照score范围查询,查score范围在[0,lastId)即[0,lastId-1]中score最大的3条数据
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(
"receive:" + UserHolder.getUser().getId().toString(),
0,
lastId,
offset,
3
);
if (typedTuples==null || typedTuples.isEmpty()){
return Result.ok();//关注的用户没有发布动态
}
// 获取所有动态的blogId,以及该页的最小时间戳lastId,偏移量offset
// blogId用于页面显示,lastId和offset作为下一页取数据的依据
List<Long> blogIds = new ArrayList<>(typedTuples.size());
long lastIdNextPage = 0;
int offsetNextPage = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
// blogId
blogIds.add(Long.valueOf(tuple.getValue()));
// offsetNextPage为与lastIdNextPage相同的元素个数,其中lastIdNextPage为该页的最小编号(时间,其实重复的可能性很小)
long time = tuple.getScore().longValue();
if (time == lastIdNextPage){
offsetNextPage ++;
}else {
offsetNextPage = 1;
}
// 记录该页的最小编号(时间,其实重复的可能性很小)
lastIdNextPage = time;
}
// 根据blogIds查对应的动态信息
List<Blog> blogs = query().
in("id", blogIds)
.last("ORDER BY FIELD(id," + StrUtil.join(",", blogIds) + ")").list();
return Result.ok(new ScrollResult(blogs,lastIdNextPage,offsetNextPage));
}其实可以简单抽象为一个算法问题:给定一个包含数字1-10的数组,数组元素有序排列,从数组末尾向前遍历,规定每一轮输出3个元素,不同轮次之间输出的元素不能有重复,轮次内的元素可以重复,输出各轮次的元素。