前言
在 AI 与大数据深度融合的数字化浪潮中,数据形态正从单一结构化向 "结构化 + 非结构化" 混合形态演进。而数据库作为企业数据资产的核心载体,其选型直接关系到业务连续性、数据安全性与技术前瞻性。随着开源技术成为企业级应用的主流选择,市场对数据库的需求已从单纯的 "存储与查询",升级为对 "高性能、高安全、高可用、智能化" 综合能力的诉求。
openGauss 作为源于华为技术沉淀的企业级开源关系型数据库,凭借架构创新、技术突破与生态共建,已成为越来越多关键行业的选型之一。下面,我们就来探究 openGauss 在数据库选型中究竟具备哪些竞争力!

一、openGauss 向量数据库简介
openGauss是一款全面友好开放,携手伙伴共同打造的企业级开源关系型数据库。openGauss提供面向多核架构的极致性能、全链路的业务、数据安全、基于AI的调优和高效运维的能力。其核心架构采用 "内核 + 引擎" 的模块化设计,内核层面保留关系型数据库的 ACID 事务特性,引擎层面则集成 DataVec 向量数据库能力,形成 "结构化 + 非结构化" 一体化处理能力。
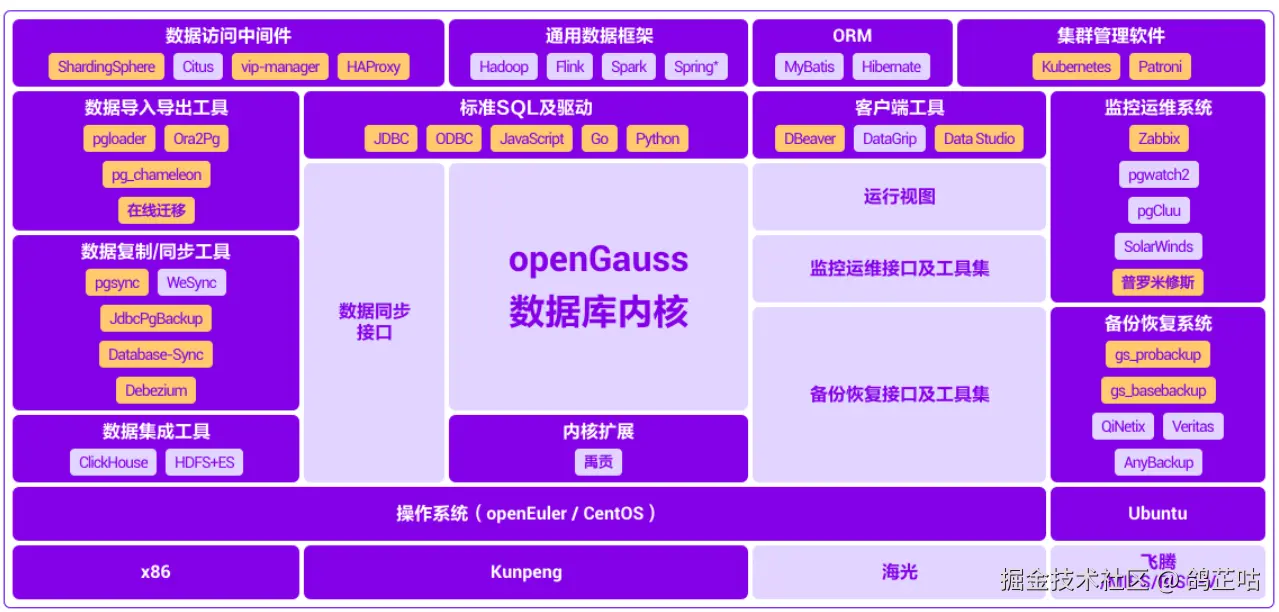
在开源属性上,openGauss 采用木兰宽松许可证 V2,允许用户免费下载、使用、修改源代码,且无需开源衍生作品,极大降低企业技术接入成本,同时鼓励社区开发者参与代码贡献与功能迭代。
二、openGauss 的技术特性
2.1 向量数据库能力
openGauss 依托内核原生特性 DataVec 向量引擎构建向量数据库能力,支持向量数据类型的存储与检索,针对大规模高维向量数据可提供快速精准的检索结果,涵盖精确与近似最近邻搜索两种模式,支持 L2 距离、余弦距离、内积等多种相似度计算方式,同时具备向量索引、丰富的向量操作函数与操作符,且兼容熟悉的 SQL 语法简化使用流程,无需额外复杂部署,能广泛适配智能知识检索、检索增强生成(RAG)等各类复杂智能应用场景,为相关场景落地提供高效可靠的技术支撑。

2.2 AI 与数据库的深度融合
作为"AI与数据库双向融合"领域较早落地的开源数据库,openGauss通过其AI特性子模块DBMind,明确划分出AI4DB(AI优化数据库)与DB4AI(数据库驱动AI)两大核心方向,构建起"自优化、自诊断、自运维、自安全"的智能化闭环。这并非简单的功能叠加,而是从内核层面实现AI与数据库的深度协同,精准破解传统数据库"运维难、调优难、AI接入复杂"的核心痛点。
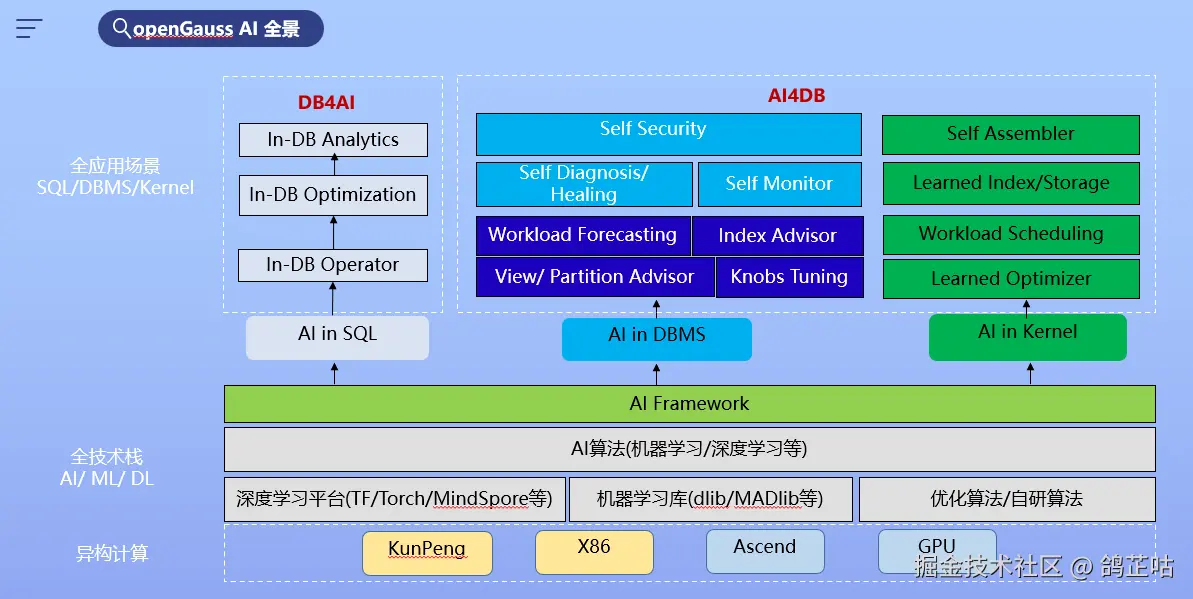
其中AI4DB主要用于对数据库进行自治运维和管理,从而帮助数据库运维人员减少运维工作量。在实现上,DBMind的AI4DB框架具有监控和服务化的性质,同时也提供即时AI工具包,提供开箱即用的AI运维功能(如索引推荐)。AI4DB的监控平台以开源的Prometheus为主,DBMind提供监控数据生产者exporter, 可与Prometheus平台完成对接。

2.3 RAG 场景技术适配
检索增强生成(RAG)是大模型落地的核心场景,其核心需求是"快速检索高质量上下文并输入大模型,提升回答准确性"(避免大模型"一本正经地胡说八道")。openGauss 针对 RAG 场景的三大痛点(向量检索效率低、数据更新不及时、多源数据难整合)进行深度适配,成为 RAG 系统的理想数据底座。
三、实测体验
3.1 安装openGauss
由于国内镜像源访问原因,直接拉取下载的话特别容易出现拉取失败等提示,所以我们选择通过 wget 命令下载 openGauss 的 Docker 镜像包,并加载到docker启动。

- 下载镜像包(我们本次用的是Centos 7.6版本的所以在下载的时候要注意一点要选择CentOS7-x86_64架构下的安装包 )
plain
wget https://openGauss.obs.cn-south-1.myhuaweicloud.com/7.0.0-RC2/openEuler22.03/x86/openGauss-Docker-7.0.0-RC2-x86_64.tar
- 加载镜像
plain
docker load -i openGauss-Docker-7.0.0-RC2-x86_64.tar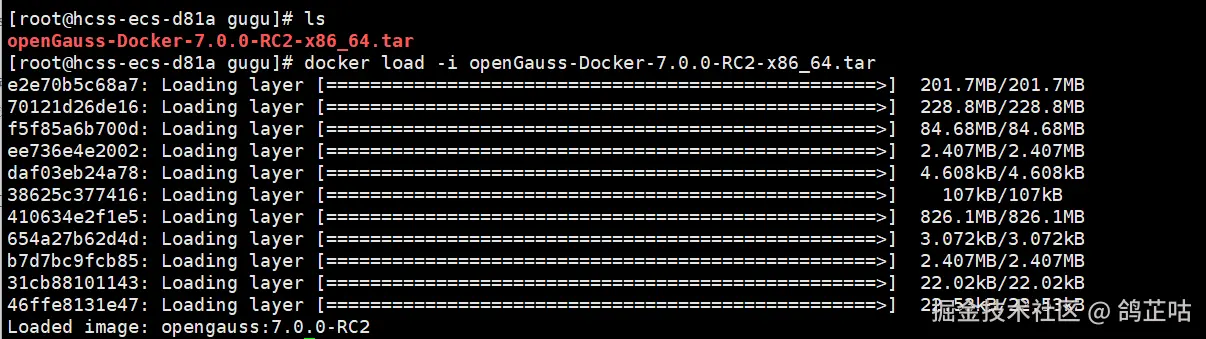
- 验证镜像状态
plain
docker images
- 启动容器,从上面可以看到我们的仓库名是 openGauss,标签是 7.0.0-RC2。然后直接用本地镜像启动就OK了
plain
[root@hcss-ecs-d81a gugu]# #
[root@hcss-ecs-d81a gugu]# docker run --name openGauss --privileged=true -d -e GS_PASSWORD=Gugu@123 -p 5432:5432 openGauss:7.0.0-RC2
- 参看容器状态
plain
docker ps | grep openGauss
3.2 gsql 连接数据库
数据可以启动之后,我们就可以直接试用官方提供的 gsql 连接数据库。gsql是openGauss提供在命令行下运行的数据库连接工具,可以通过此工具连接服务器并对其进行操作和维护,除了具备操作数据库的基本功能,gsql还提供了若干高级特性,便于用户使用。
- 进入容器
plain
docker exec -it openGauss bash
plain
gsql -d postgres -U omm -p 5432 -r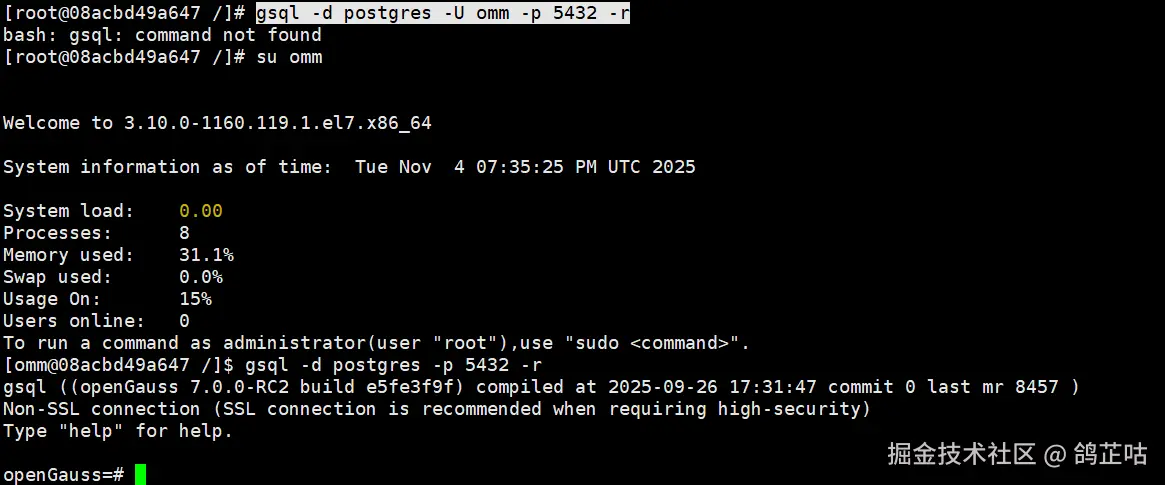
3.3 SQL兼容性测试
以上openGauss就已经安装连接好了,那么接下来我们就来测试一下SQL语句的兼容性。验证一下增删改查 这些操作。
- 首先我们先创建一个测试数据库在使用 \l 命令查看一下数据库列表。
plain
-- 创建新数据库 test_db
CREATE DATABASE test_db;
-- 查看所有数据库(验证创建结果)
\l
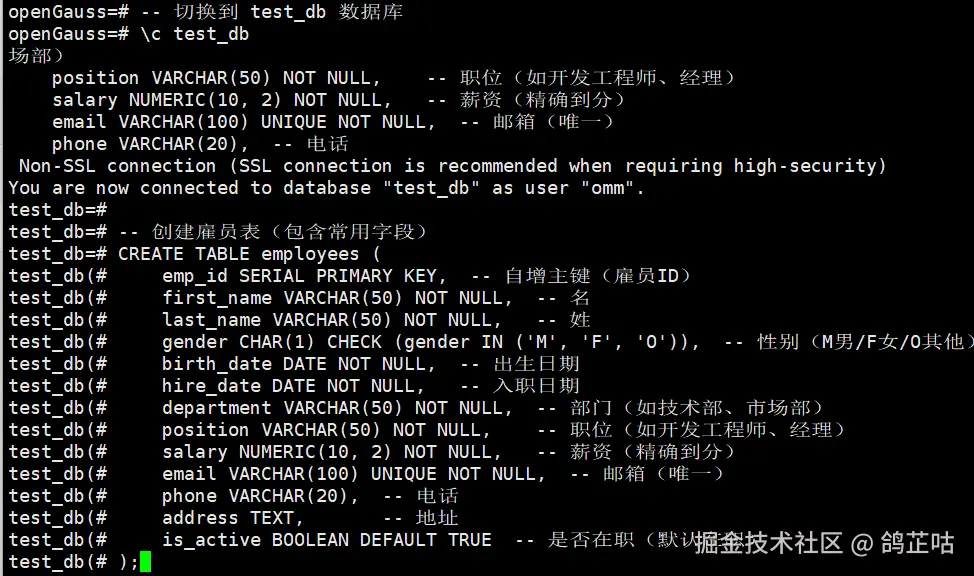
- 切换到 test_db 数据库,创建一个雇员表
plain
-- 切换到 test_db 数据库
\c test_db
-- 创建雇员表(包含常用字段)
CREATE TABLE employees (
emp_id SERIAL PRIMARY KEY, -- 自增主键(雇员ID)
first_name VARCHAR(50) NOT NULL, -- 名
last_name VARCHAR(50) NOT NULL, -- 姓
gender CHAR(1) CHECK (gender IN ('M', 'F', 'O')), -- 性别(M男/F女/O其他)
birth_date DATE NOT NULL, -- 出生日期
hire_date DATE NOT NULL, -- 入职日期
department VARCHAR(50) NOT NULL, -- 部门(如技术部、市场部)
position VARCHAR(50) NOT NULL, -- 职位(如开发工程师、经理)
salary NUMERIC(10, 2) NOT NULL, -- 薪资(精确到分)
email VARCHAR(100) UNIQUE NOT NULL, -- 邮箱(唯一)
phone VARCHAR(20), -- 电话
address TEXT, -- 地址
is_active BOOLEAN DEFAULT TRUE -- 是否在职(默认在职)
);
- 下面我们来测试 openGauss 对 PL/pgSQL 语法的兼容性及执行效率。 通过运行 PL/pgSQL 代码批量插入 10 万条测试数据,直观验证其语法支持情况与数据插入性能。
plain
-- 批量插入 1000 条雇员数据(使用 PL/pgSQL 循环)
DO $$
DECLARE
i INT := 1;
depts TEXT[] := ARRAY['技术部', '市场部', '财务部', '人力资源部', '销售部'];
positions TEXT[] := ARRAY['开发工程师', '产品经理', '测试工程师', '财务专员', '销售代表', 'HR专员', '部门经理'];
genders CHAR[] := ARRAY['M', 'F', 'O'];
BEGIN
WHILE i <= 100000 LOOP
INSERT INTO employees (
first_name, last_name, gender, birth_date, hire_date,
department, position, salary, email, phone, address, is_active
) VALUES (
'员工' || i, -- 名(如 员工1、员工2...)
'测试', -- 姓
genders[floor(random() * array_length(genders, 1)) + 1], -- 随机性别
CURRENT_DATE - (30 + floor(random() * 30)::INT) * 365, -- 30-60岁随机生日
CURRENT_DATE - (1 + floor(random() * 10)::INT) * 365, -- 1-10年随机入职时间
depts[floor(random() * array_length(depts, 1)) + 1], -- 随机部门
positions[floor(random() * array_length(positions, 1)) + 1], -- 随机职位
5000 + floor(random() * 25000)::NUMERIC(10,2), -- 5000-30000随机薪资
'emp' || i || '@test.com', -- 邮箱(唯一)
'138' || lpad(floor(random() * 100000000)::TEXT, 8, '0'), -- 随机手机号
'测试地址' || i, -- 地址
CASE WHEN random() > 0.1 THEN TRUE ELSE FALSE END -- 90%概率在职
);
i := i + 1;
END LOOP;
END $$;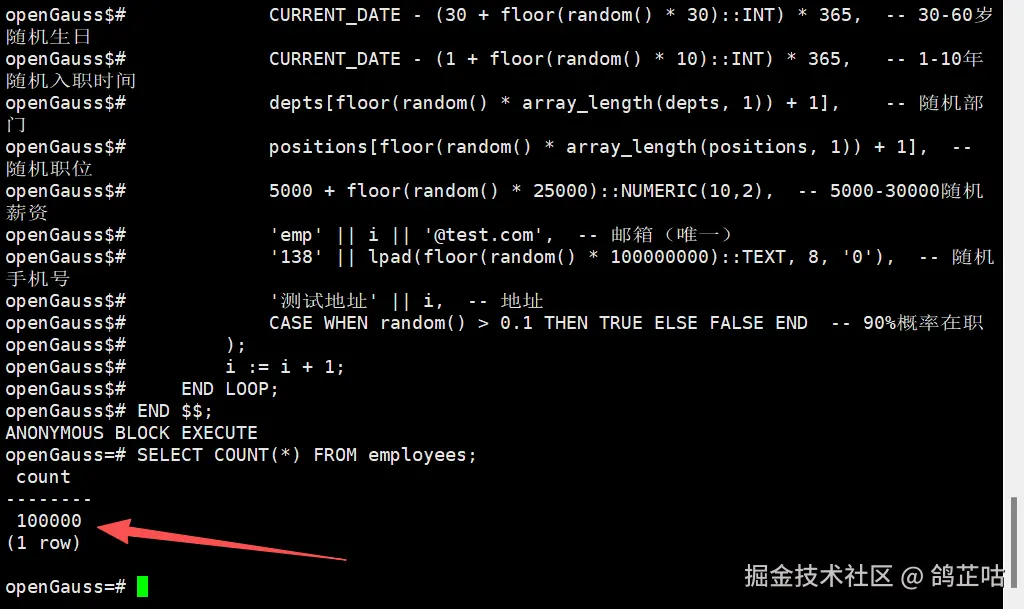
从测试结果可知,100000 条雇员数据已成功写入 employees 表,操作完全符合预期。数据在插入过程响应极快。接下来,我们将进一步验证 openGauss 对 SQL 语句其他功能的支持表现。
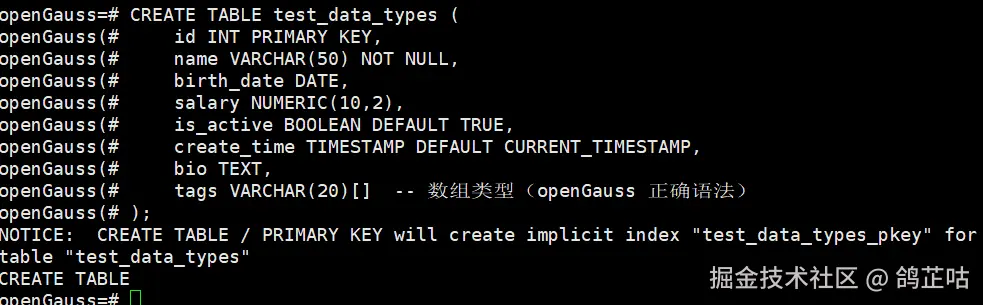
- 基础数据类型与表操作(DDL)
基础数据类型与表操作我们测试主要围绕以下内容展开:创建包含多种数据类型的表以验证数据类型兼容性,查看表结构以验证元数据查询兼容性,以及修改表结构以验证 ALTER 语法兼容性。
plain
CREATE TABLE test_data_types (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
birth_date DATE,
salary NUMERIC(10,2),
is_active BOOLEAN DEFAULT TRUE,
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
bio TEXT,
tags VARCHAR(20)[]
);
plain
-- 查询 information_schema 系统表(标准 SQL 兼容方式)
SELECT
column_name,
data_type,
is_nullable,
column_default
FROM information_schema.columns
WHERE table_name = 'test_data_types';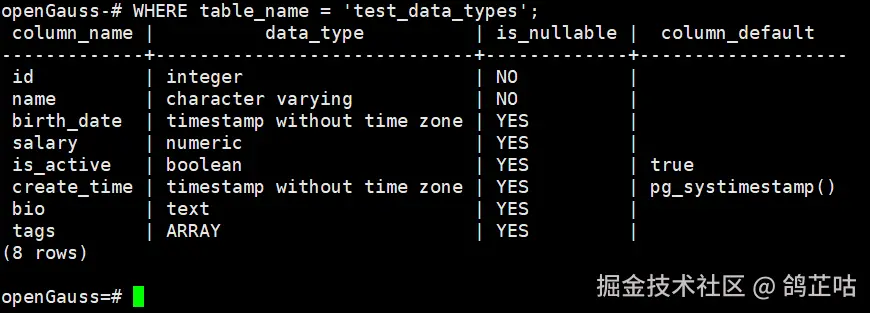
plain
-- 修改表结构(验证ALTER语法兼容性)
ALTER TABLE test_data_types
ADD COLUMN dept_id INT,
ALTER COLUMN salary SET DEFAULT 0.00;
3.4 测试总结
从上述测试可看出,openGauss 作为高性能、高可靠性的开源关系型数据库,既继承了 PostgreSQL 的强大功能,又在语法与协议层面进行了针对性优化增强,尤其提升了对 MySQL 语法的兼容性。这种良好的兼容性,让我们能从 MySQL 到 openGauss 的迁移过程更加便捷顺畅。
四、开放与繁荣的技术生态
4.1 生态建设方面
在生态建设这方面,openGauss深知,现代数据库的竞争不仅是技术的竞争,进入 "生态决胜" 的新阶段。因此,它从生态顶层设计出发,始终以 "全面开放、协同共生" 为核心,构建覆盖伙伴、开发者与用户的技术生态体系。

早在 2019 年宣布开源之初,openGauss 就同步启动开源社区运营,通过文档共建、技术研讨、贡献者激励等机制吸引全球参与者。经过多年沉淀,其生态规模持续壮大:目前已汇聚 820 家企业成员、7500 名活跃开发者,全球累计下载量突破 350 万次,无论是企业级伙伴的深度参与,还是个人开发者的代码贡献,都呈现出清晰的增长趋势,生态活力肉眼可见。

4.2 伙伴与产品
伙伴体系方面,openGauss 不依赖单一厂商,而是联合上下游伙伴打造"硬件+软件+服务"全栈生态,解决企业"适配难、落地难"问题。以硬件适配为例,其与鲲鹏服务器的协同不仅停留在基础兼容性层面,更深入技术内核做联合优化 ------ 通过集成 RDMA 高速网络技术,直接加速数据库 WAL(预写日志)的跨节点传输效率,我们在进行鲲鹏服务器进行测试也明显的感受到,数据同步速度确实比普通服务器快。

4.3 迁移与丰富的工具生态
企业更换数据库时,最担心"数据迁移难、代码适配繁、工具不兼容",而openGauss 则给我们提供完善的迁移工具链与兼容方案,解决迁移痛点。
- 自动化迁移工具:推出 DataKit 迁移工具,支持从 MySQL、Oracle、PostgreSQL 等数据库向 openGauss 迁移,实现"三步完成迁移"

- 丰富的工具链 :提供了openGauss-OM :提供了一键式部署、升级、监控和管理的运维工具。Data Studio:图形化的数据库管理开发工具。pg_chameleon:MySQL到openGauss数据迁移工具等等。
总结
从以上分析实测我们不难看出,openGauss 凭借高可用、高性能、高安全、易运维(基于AI的智能参数调优和索引推荐,提供AI自动参数推荐)等已经成为成为企业数字化转型的核心优选。在技术上,openGauss 率先实现 AI 与数据库的深度融合 ------DBMind 模块的 AI4DB 能力降低运维成本、提升系统稳定性,DB4AI 能力简化 AI 任务落地;目前,已有众多知名企业基于 openGauss 搭建了专属数据库系统。所以对于企业有智能化数据处理需求openGauss是一个不错的选择。