论文标题:Real-Time Object Detection Meets DINOv3
论文作者: Shihua Huang Yongjie Hou Longfei Liu Xuanlong Yu Xi Shen
论文地址:Real-Time Object Detection Meets DINOv3
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水*有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
好久没有在这里记录论文了,也许是这样的方式有些慢,但是回头想想,这样可以*复心情。 最*deimv2特别火,也顺便在这里记录一下。比较效果很好,同时也是和DINOv3结合。确实值得一看。自己的一个个人笔记。
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote
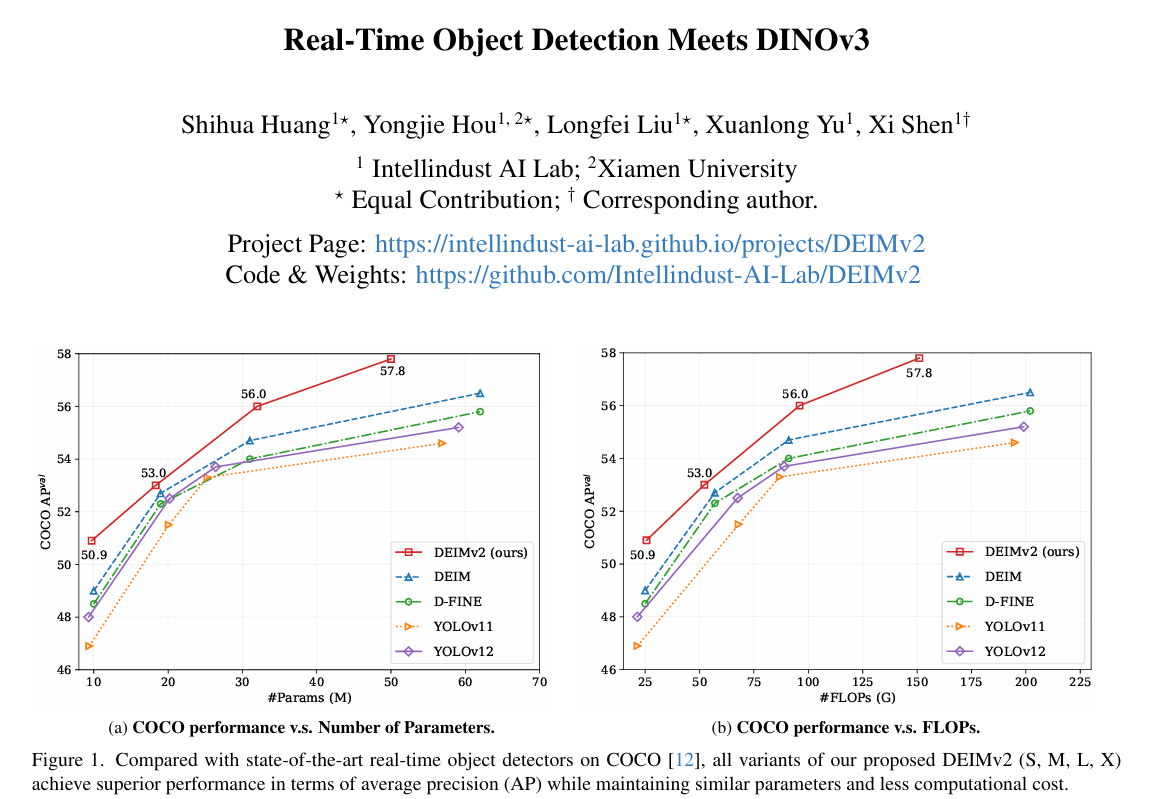
这篇题为《Real-Time Object Detection Meets DINOv3》的论文提出了DEIMv2------一个新一代实时目标检测框架,通过巧妙融合DINOv3的强语义表征能力与轻量级设计,在多个维度实现了突破。以下是核心总结:
1,统一架构,全场景覆盖
1:提出8个不同规格的模型(X/L/M/S/Nano/Pico/Femto/Atto),覆盖GPU、边缘设备和移动端。
2:大模型(X/L/M/S)基于DINOv3主干 + 空间调谐适配器(STA)
3:轻量模型(Nano/Atto)基于剪枝优化的HGNetv2
2,空间谐调适配器(STA)
1:将DINOv3的但尺度输出转换为多尺度特征,无需参数,仅通过插值实现
2:配合轻量CNN的提取细节,补充DINOv3在小物体检测上的不足
3,高效解码器设计
1,实验SwiGLU-FFN与RMSNorm提升表达与训练效率
2,共享位置嵌入,减少冗余计算
4,增强的Dense O2O 训练策略
1,提出Copy_Blend数据增强,只融合物体不覆盖背景,更贴*真实场景。
所以说DEIMv2 不仅在精度-效率权衡上设立新标杆,还提供了一个统一且可扩展的框架,推动实时检测在自动驾驶、工业检测、移动端等实际场景的落地。未来方向包括优化小物体检测、引入推理加速技术(如FlashAttention)等。下面来看一下:


摘要
得益于Dense O2O和MAL的简洁性与有效性,DEIM已成为实时DETR的主流训练框架,其性能显著超越YOLO系列。本研究通过引入DINOv3特征对其进行扩展,推出了DEIMv2。DEIMv2涵盖从X到Atto的八个模型规模,覆盖GPU、边缘设备和移动端部署场景。针对X、L、M和S版本,我们采用DINOv3预训练/蒸馏主干网络,并提出了空间调谐适配器(STA)。该模块能高效地将DINOv3的单尺度输出转换为多尺度特征,通过补充细粒度细节来增强强语义表征,从而提升检测性能。对于超轻量级模型(Nano、Pico、Femto和Atto),我们采用经过深度和宽度剪枝的HGNetv2来满足严格的资源预算。结合简化解码器和升级版Dense O2O,这种统一设计使DEIMv2在多样化场景中实现了卓越的性能-成本*衡,创造了新的性能纪录。值得关注的是,我们最大的DEIMv2-X模型仅用5030万参数就实现了57.8 AP,超越了先前需要超过6000万参数仅获得56.5 AP的X规模模型。在紧凑型方面,DEIMv2-S成为首个在COCO数据集上突破50 AP里程碑的亚千万级模型(971万参数),达到50.9 AP。即便是仅150万参数的超轻量级DEIMv2-Pico,也能实现38.5 AP------以约50%更少的参数匹配了YOLOv10-Nano(230万参数)的性能。


1,引言
实时目标检测6, 18, 22, 29是许多实际应用中的关键组成部分,包括自动驾驶11、机器人技术16和工业缺陷检测8。在检测性能与计算效率之间实现良好*衡仍然是一个关键挑战,特别是对于适用于边缘设备和移动端的轻量级模型而言。
在主流实时目标检测器中,基于DETR的方法因其端到端设计和Transformer赋能的高容量能力而日益受到关注,实现了更优越的权衡。在此范式下,DEIM已成为一个强大的训练框架,推动了实时DETR的发展,并带来了该领域的领先模型。与此同时,DINOv321在各种视觉任务中展现了强大的特征表示能力。然而,其在实时目标检测领域的潜力尚未得到充分探索。
本工作中,我们推出了DEIMv2------一个基于我们先前DEIM7 pipeline构建,并通过DINOv321特征增强的实时目标检测器。DEIMv2在其最大变体(L和X尺寸)中采用官方DINOv3预训练主干网络(ViT-Small和ViT-Small+)以最大化特征丰富度,而其S和M变体则利用从DINOv3蒸馏得到的ViT-Tiny和ViT-Tiny+主干网络,精心*衡性能与效率。为应对超轻量级场景,我们进一步引入了四个专门变体:Nano、Pico、Femto和Atto,从而将DEIMv2的可扩展性延伸至广泛的计算预算范围。
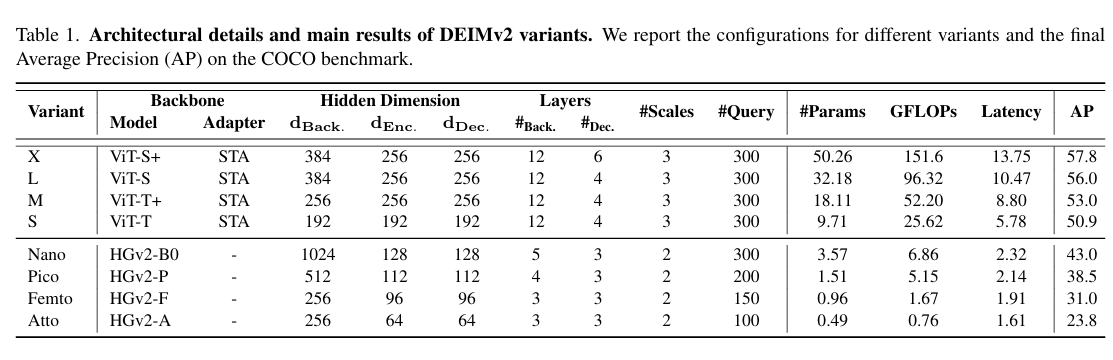


为在实时约束下更好地利用基于大规模数据预训练的DINOv3强大特征表示能力,我们设计了空间调谐适配器(STA)。该模块与DINOv3并行运行,以无参数的方式将其单尺度输出高效转换为目标检测所需的多尺度特征。同时,STA对输入图像进行快速下采样,提供具有极小感受野的细粒度多尺度细节特征,从而与DINOv3的强语义特征形成互补。
我们借鉴Transformer领域的最新进展进一步简化了解码器。具体而言,我们将传统的FFN和LayerNorm替换为SwishFFN20和RMSNorm27------这两种组件均被证明能在不影响性能的前提下提升效率。我们还发现物体查询位置在迭代优化过程中变化极小,这促使我们在所有解码层之间共享查询位置嵌入。除此之外,我们通过引入物体级复制-混合数据增强来增强Dense O2O,此举增加了有效监督并进一步提升了模型性能。
在COCO数据集12上的大量实验表明,DEIMv2在多个模型尺度上均实现了最先进的性能(如图1所示)。尽管设计简洁,DEIMv2系列仍展现出强劲性能。例如,我们最大的DEIMv2-X变体仅用5030万参数就在COCO上达到57.6 AP,超越了先前需要超过6000万参数却仅获得56.5 AP的最佳X尺度检测器DEIM-X。在小型模型方面,DEIMv2-S树立了重要里程碑------成为首个参数量不足1000万却超越50 AP的模型,这凸显了我们设计在紧凑尺度上的有效性。此外,我们仅含150万参数的超轻量级DEIMv2-Pico达到38.5 AP,在参数量减少约50%的情况下实现了与YOLOv10-Nano(230万参数)相当的性能,从而重新定义了极轻量级别领域的效果和准确率的边界。


本研究的主要贡献可概括如下:
-
我们提出了DEIMv2系列模型,提供涵盖GPU、边缘计算和移动端部署的八种不同规模版本。
-
针对较大规模模型,我们利用DINOv3获取强语义特征,并引入空间调谐适配器(STA)将其高效集成到实时目标检测流程中。
-
面向超轻量级模型,我们运用专家知识对HGNetv2-B0进行深度与宽度的有效剪枝,以满足严格的计算资源限制。
-
除主干网络优化外,我们进一步简化了解码器结构并升级Dense O2O机制,持续突破性能边界。
-
最终,我们在COCO数据集上验证了DEIMv2在所有资源配置下均超越现有最优方法,创造了新的性能纪录。








2,方法
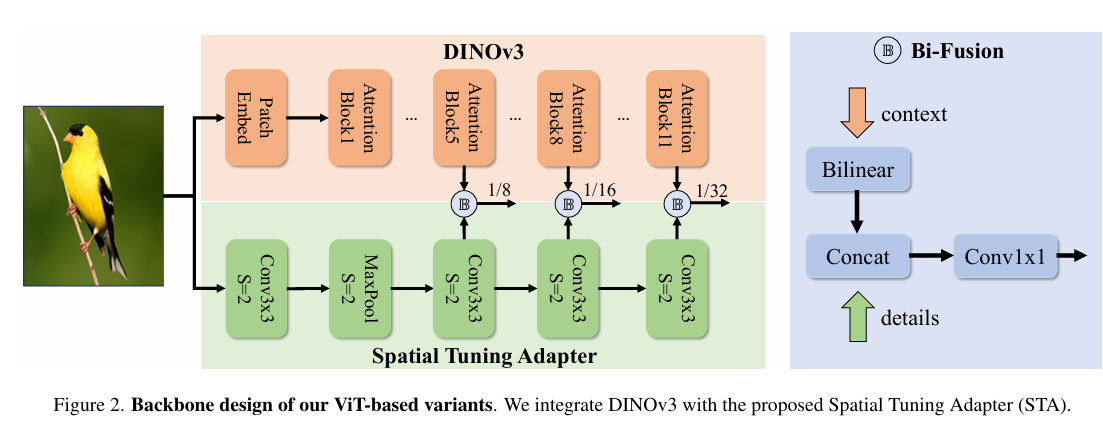
整体架构 我们的整体架构遵循RT-DETR14的设计,包含主干网络、混合编码器和解码器三大组件。如表1所示,针对主流变体X、L、M和S,我们采用基于DINOv3的主干网络并集成了我们提出的空间调谐适配器(STA),其余变体则使用HGNetv21作为主干网络。来自主干网络的多尺度特征首先经过编码器处理,生成初始检测结果并筛选出前K个候选边界框。解码器则通过迭代优化这些候选框来生成最终预测结果。
(该架构通过差异化涉及实现多场景覆盖------高性能版本借助DINOv3与STA模块强化特征表示,轻量版则依赖于优化后的HGNetv2保障效率,形成完整的实时检测解决方法)
基于ViT的模型变体 针对较大规模的DEIMv2变体(S、M、L、X),我们围绕视觉Transformer(ViT)系列精心设计了主干网络,以*衡模型容量与效率。对于L和X变体,我们采用两种公开的DINOv3模型21:ViT-Small和ViT-Small+,这些模型通过12个网络层和384维隐藏大小提供强大的语义表征能力。针对更轻量级的S和M变体,我们直接从ViT-Small DINOv3蒸馏得到紧凑型主干网络ViT-Tiny和ViT-Tiny+,在保持12层网络深度的同时将隐藏维度分别降至192和256。这一设计实现了S→M→L→X之间的*滑缩放路径,确保每个变体在适应不同效率需求的同时都能保持具有竞争力的准确度。
(这段揭示了模型缩放策略的精妙之处------通过保持网络深度不变仅调整隐藏维度,即维持了特征提取的一致性,又实现了计算资源的精细调控,为不同应用场景提供了连续的性能谱系)
基于HGNetv2的模型变体 由百度飞桨团队开发的HGNetv21因其高效性而被广泛应用于实时DETR框架------例如D-FINE17就采用完整版HGNetv2系列作为其主干网络。在我们的超轻量级DEIMv2模型(Nano、Pico、Femto和Atto)中,我们同样基于HGNetv2-B0进行构建,但通过逐步剪裁其深度和宽度来满足不同的参数量预算。具体而言,Pico版主干网络移除了B0的第四阶段,仅保留至1/16尺度的输出。Femto版本进一步将Pico末阶段的块数从两个缩减为一个。Atto版本则通过将末块的通道数从512压缩至256来实现更深度的精简。
(这段描述展示的是精密的模型压缩策略------通过阶梯式剪枝(阶段移除------块数消减------通道压缩)构建了参数递减的轻量级模型家族,为资源极端受限的场景提供了精准的解决方案)
空间调谐适配器 为更好地使DINOv3特征适配实时目标检测任务,我们提出了如图2所示的空间调谐适配器(STA)。该模块是一个全卷积网络,集成了一個用于提取细粒度多尺度细节的超轻量前馈网络,以及一个能进一步增强DINOv3特征表征能力的双向融合算子。
基于ViT主干网络的DINOv3天然生成单尺度(1/16)密集特征。然而在目标检测任务中,物体尺寸差异显著,而多尺度特征正是提升性能的最有效途径之一。为此,ViTDet10引入了特征金字塔模块,通过反卷积从最终ViT输出生成多尺度特征。相比之下,我们的STA设计更为简洁:我们直接通过无参数的双线性插值,将来自多个ViT块(如第5、8、11层)的1/16尺度特征重采样至多种尺度。这些多尺度特征随后经由双向融合算子进行增强------该算子包含1×1卷积和专门设计的超轻量CNN,用于提取细粒度细节以补充DINOv3的输出特征。此种设计在效率与精度间实现了卓越*衡,使其特别适合实时检测场景。
(STA模块的创新新体现在两方面:一是通过无参数插值替代复杂计算实现多尺度转换,二是通过双向架构同时利用原始特征与细节特征,在保持轻量化的同时突破ViT单尺度输出的局限性)
增强型Dense O2O 在我们先前提出的DEIM7中,我们引入了Dense O2O方法,通过增加每张训练图像中的物体数量来提供更强的监督信号,从而改善收敛性与性能。该方法最初通过Mosaic和MixUp28等图像级增强技术验证了其有效性。在DEIMv2中,我们进一步在物体层面探索Dense O2O的潜力,提出了Copy-Blend增强策略------该策略仅添加新的物体实例而不包含其背景信息。与完全覆盖目标区域的Copy-Paste4技术不同,Copy-Blend将新物体与原始图像进行融合处理,这种设计更契合我们的应用场景,并持续带来性能提升。
(Copy-Blend技术的创新在于通过背景保留的混合策略,在维持场景上下文完整性的同时增加物体密度,即增强了监督信号又避免了人工合成痕迹,体现了数据增强策略从"覆盖式"到"融合式"的理念演进)
训练设置与损失函数 我们的训练策略遵循DEIM7这一专为快速收敛与高性能设计的基础框架。整体优化目标由五个损失分量的加权和构成:匹配感知损失(MAL)7、细粒度定位损失(FGL)17、解耦蒸馏焦点损失(DDF)17、边界框回归损失(L1)以及GIoU损失19。总损失函数定义为各分量的加权组合,所有实验中权重参数设定为λ1=1.0,λ2=0.15,λ3=1.5,λ4=5,λ5=2。
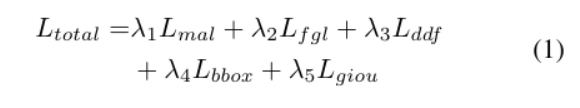
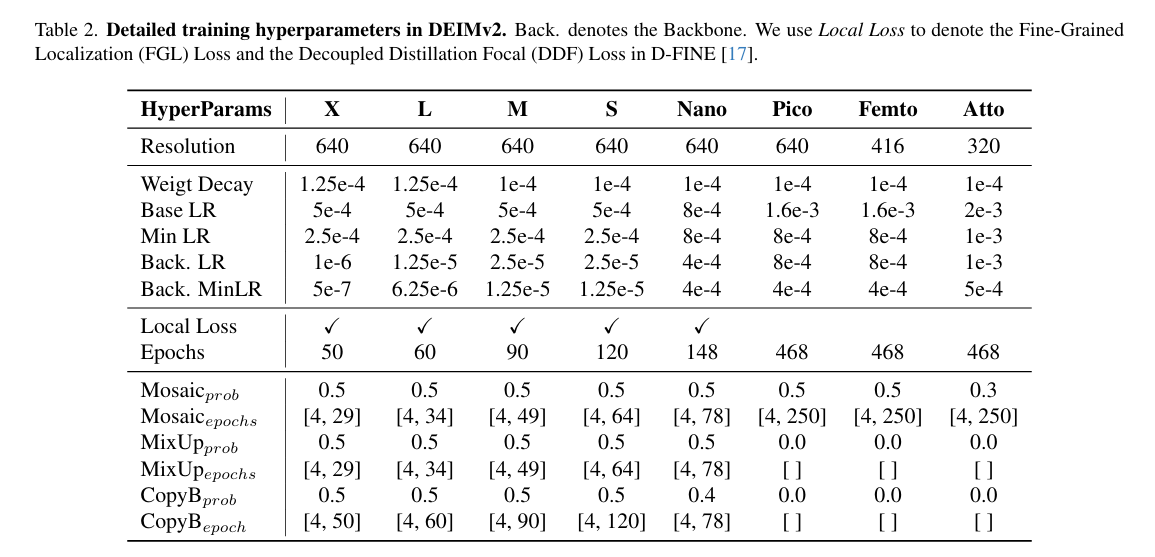
我们在表2中汇总了训练超参数,包括输入分辨率、学习率、训练周期和Dense O2O设置。一个有趣的发现是:对超轻量级模型应用FGL和DDF损失反而会导致性能下降。我们将此归因于其有限模型容量与固有较弱的基础精度,这降低了自蒸馏机制的有效性。因此,在训练Pico、Femto和Atto变体时,我们排除了这两个损失分量(即局部损失)。
(该训练策略体现了"因模施教"的优化哲学------通过损失函数的动态配置,即为大型模型提供多维度监督信号,又为轻量模型规避过载风险,实现了训练效率与模型性能的精准*衡。)




3,实验
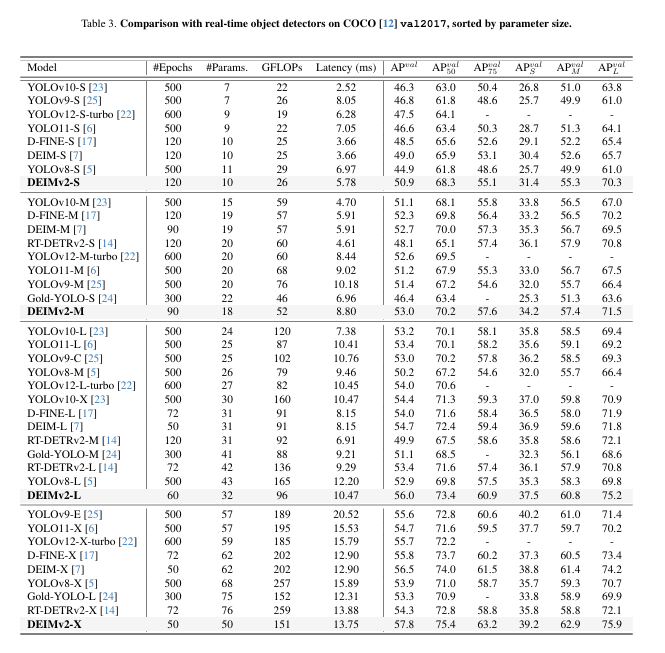
与最先进实时目标检测器的对比 表3汇总了DEIMv2在S、M、L、X四个变体上的性能表现,结果显示其相较先前最优检测器实现了显著提升。具体而言:最大规格的DEIMv2-X以仅约5000万参数和151G FLOPs的计算量取得了57.8 AP,超越了此前最佳的DEIM-X(该模型需要6200万参数和202G FLOPs却仅获得56.5 AP)。这证明DEIMv2能够以更少的参数和更低的计算成本实现更优的精度。在小型模型端,DEIMv2-S创造了新的里程碑------成为首个参数量不足1000万却在COCO数据集上突破50 AP阈值的模型,仅以1100万参数和26G FLOPs即达成50.9 AP。这较之前的DEIM-S(1000万参数实现49.0 AP)呈现明显进步,同时保持了*乎相同的模型规模。尽管基于CNN的主干网络通常更具硬件友好性,但我们基于ViT的主干以更少的参数和更低的FLOPs实现了轻量级设计,提供了更优的可扩展性与部署灵活性。需要特别说明的是,本方法的推理延迟尚未经过专门优化。若采用YOLOv1222中使用的FlashAttention2等技术,可进一步加速推理过程。总体而言,FLOPs的降低凸显了基于ViT的主干网络通过适当优化后实现低延迟性能的巨大潜力。
(注意:该实验验证了ViT架构在实时检测领域的突破性进展------不仅在高精度范畴建立新标杆,更在轻量级领域突破传统CNN的性能天花板,为视觉Transformer在编译计算的推广应用提供了实证依据)
值得关注的现象 在可比参数量和FLOPs预算下对比基于DINOv3的DEIMv2模型与其前代DEIM模型时,我们发现精度提升主要来源于中大型物体的检测改进,而小物体检测性能基本保持不变。具体而言:DEIMv2-S在中型物体检测得分达到55.3 AP_M,大型物体70.3 AP_L,明显超越DEIM-S(52.6 AP_M和65.7 AP_L),然而小物体检测得分却*乎持*(31.4 vs. 30.4 AP_S)。在更大模型上也观察到类似趋势:DEIMv2-X将中型物体检测从61.4提升至62.8 AP_M,大型物体从74.2提升至75.9 AP_L,而其小物体检测得分(39.2 AP_S)与DEIM-M(38.8 AP_S)保持接*。这些结果表明DEIMv2的主要优势在于增强了对中大型物体的表征与检测能力,而小物体检测在不同规模模型中仍是持续存在的挑战。该发现进一步证实DINOv3擅长捕捉强全局语义特征,但在细粒度细节表征方面存在局限。因此,探索如何将DINOv3特征更有效地集成到实时检测器中,成为未来研究的重要方向。

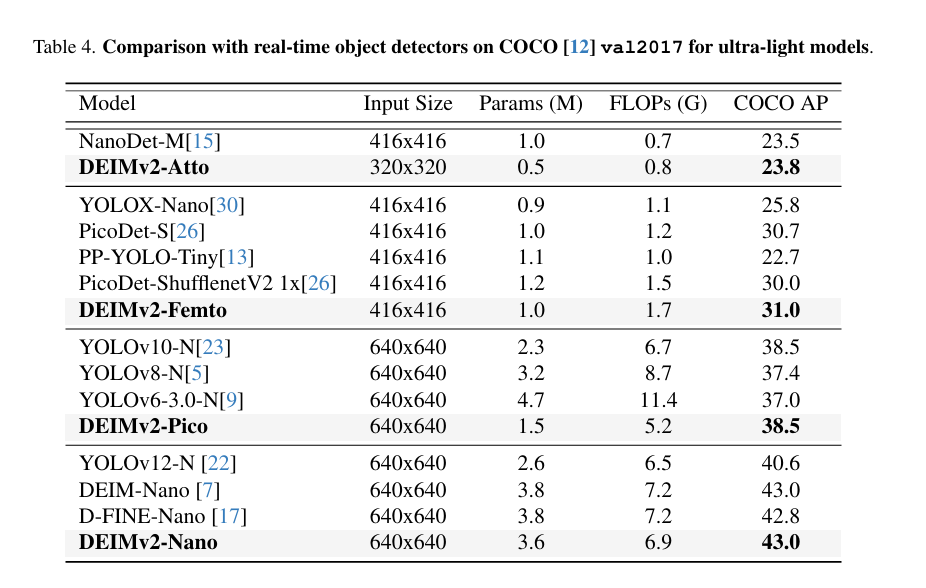
与竞争性超轻量目标检测器的对比 DEIMv2的超轻量级变体同样展现出强劲性能,其对比数据汇总于表4。仅含49万参数的DEIMv2-Atto在模型体积显著更小的前提下,实现了与NanoDet-M相当的性能表现。同样地,DEIMv2-Pico在达到YOLOv10-N23同等性能水*的同时,所需参数量不足后者的一半。这些成果印证了DEIMv2在极致紧凑模型领域的有效性,并凸显其适用于资源受限边缘设备部署的显著优势。
(该对比实验验证了模型压缩策略的成功------通过阶梯式剪枝与结构优化,在保持竞争力的检测精度前提下实现参数量的数量级降低,为物联网设备等极端资源场景提供了切实可行的解决方案)


4,总结
本报告介绍了新一代实时目标检测器DEIMv2,该系统通过将DINOv3的强语义表征能力与我们研发的轻量级STA模块相结合,实现了突破性进展。经过精心设计与规模扩展,DEIMv2在全系列模型尺寸上均达到了最先进的性能水*:在高端规格方面,DEIMv2-X以显著少于以往大型检测器的参数量实现了57.8 AP的卓越精度;在紧凑型领域,DEIMv2-S成为同尺寸模型中首个突破50 AP大关的标杆;而超轻量级DEIMv2-Pico在参数量减少超50%的前提下仍保持与YOLOv10-N相当的检测能力。这些成果共同证明DEIMv2不仅具备卓越效率,更拥有高度可扩展性,提供了一个能持续推升"精度-效率"边界的统一框架。这种多场景适应性使DEIMv2非常适合从资源受限的边缘设备到高性能检测系统的多样化部署环境,为实时检测技术在实际应用中的广泛普及开辟了新的道路。