目录
[🐼HTTP 常见 Header](#🐼HTTP 常见 Header)
[🐼重定向 &&Location &&状态码为3XX](#🐼重定向 &&Location &&状态码为3XX)
[🐼HTTP 常见方法](#🐼HTTP 常见方法)
🐼前言
本篇文章基于一份http代码,让我们深入理解http协议及其相应字段,并且理解前后端是如何交互的。代码在最后
🐼快速看到http协议
虽然我们说, 应用层协议是我们程序猿自己定的. 但实际上, 已经有大佬们定义了一些现成的, 又非常好用的应用层协议, 供我们直接参考使用. HTTP(超文本传输协议)就是其中之一。
HTTP 协议是一个无连接、 无状态的协议, 即每次请求都需要建立新的连接, 且服务器不会保存客户端的状态信息。既然每次请求都需要建立新的连接,不像我们上节做的网络版本计算器一样,是需要长连接的。
下面我们基于上篇文章封装的Socket类,以浏览器作为客户端,来访问我们的服务器,我们的服务器底层以创建多进程来向客户端提供服务。下面,我们通过代码,获取到了浏览器的请求字段,直接看看浏览器的请求字段长什么样:
伪代码:
cpp
// 这里我们已经把http服务器用Socket建立好了
std::string hellohttp(std::string& req)
{
std::cout << "################################" << std::endl;
std::cout << req << std::endl;
std::cout << "################################" << std::endl;
return "hello http";
}
std::unique_ptr<HttpServer> tsvr = std::make_unique<HttpServer>(port, hellohttp);
✅细节一:http协议在我看来,就是一个大字符串,只有一行。只不过用"/r/n"作为换行符分隔开
✅细节二:http协议如何进行反序列化的?在大佬实现的HTTP中,序列和反序列化就是对一个字符串的切分和拼接过程,没有引入任何第三方库(避免用户觉得麻烦,还要引入其他库)所以我们之后做的序列化反序列化过程就是字符串的操作
假如我们给浏览器(客户端)返回一个html型的hello world。这个过程是怎么样的?如图:

浏览器作为一个千万级代码量的复杂项目,可以帮助我们将应答提取出来完成渲染工作。
🐼宏观了解HTTP协议本身
我们基于HTTP协议,一点一点来认识每个字段,最后会总结
如图:

🐛对于HTTP Request,为什么要有空行?
区别有效载荷和正文。
🐛认识URL
✅如何理解正文问题?
人类上网无非就两种行为:1.从网络获取信息;2.向网络上传信息。我们上网的过程,就是客户端和服务器在进程间通信,通过套接字IO的过程。
**✅而客户端获取信息,比如html/css/js, 图片,音频,视频, 如何获取呢,在哪获取呢?可以通过URL(Uniform Resource Lacator)。什么是URL呢?就是标识互联网中的唯一文件的!能让你找到。你使用URL->就是在获取信息->信息在哪里?->服务器上->Linux服务器(为例)->Linux上如何保存资源->Linux一切皆文件->如何找到Linux服务器的唯一文件呢?->Socket+特定路径->所以文件就必须要有路径咯。所以URL为什么叫统一资源定位符。**如图:

平时我们俗称的 "网址" 其实就是说的 URL,可以看到上述图资源一定是在Linux服务器上('/')
✅但是你只有Ip地址,端口号呢?我怎么没见?不带端口号行吗?不行!因为只有IP+PORT才能标识全网内唯一进程,因为是进程在通信!那port呢?本质这些常见常见的协议,都是有固定端口号的,像http port: 80, https port: 443 ftp... 在业界都是默认的,前1023个端口是知名端口,所以省略了,浏览器会自动加。
✅当客户端获取到了服务器的的指定路径的资源,谁来把资源发回给客户端?
也就是我们自已的Server了,以指定协议发回,浏览器会自已帮我们解析协议,进行渲染咯。
**✅访问的资源一定在根目录下吗?不一定,**如图:

✅urlencode和urldecode问题。
像 / ? : 等这样的字符, 已经被 url 当做特殊意义理解了. 因此这些字符不能随意出现.比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.转义的规则如下:
将需要转码的字符转为 16 进制, 然后从右到左, 取 4 位(不足 4 位直接处理), 每 2 位做一位, 前面加上%, 编码成%XY 格式。这就是我们访问资源时,url为什么会有这么多%的原因。

🐛协议里为什么要带版本?
因为http协议不仅只有1.0还有1.1; 2.0;3.0...是不断在更新迭代的,所以对于不同的http协议,有些字段略微有区别,如果不标明版本,可能序列化和反序列化就会有错误。本质导致双方没有规定好统一协议! 这就是http协议请求和应答都有版本字段的原因。
🐛HTTP Requset 和 Response如何解决粘包问题?
想想Tcp协议中对于NetCal我们是如何解决粘包问题的。通过第一个"/r/n"提取len->通过len知道报文有效载荷的长度->进而判断提取出一个完整的报文
对于Http协议我们仅需要回答两个问题。
你怎么保证一定读到了一个完整的请求报头?通过空行!
你怎么知道有还是没有正文?通过报头中的"content-Length"字段,
如果有正文部分,content-Length字段中会保存正文部分的长度。你怎么保证将你的正文一字不落的读取上来。通过报头中的"content-Length"字段,我们把这种在协议内部的字段用于描述数据内容的字段叫做自描述字段。
🐼如何访问到资源?
如果知道了URL能不能把uri提取出来,当然可以。
我们已经知道了,请求报文中的请求行有一个字段为uri,如果有了uri,我们就可以知道自已要访问什么资源了。
而什么是资源?就是一个Linux特定的文件路径罢了。一般我们以一个web根目录的形式,把资源保存起来。什么是web根目录?任何一个路径,目录形式把文件资源保存起来就是web。所以,如果资源访问不存在,不就是文件不存在,不就返回404了吗?

我们一般把web根目录下请求目标服务器的首页为index.html。
这样,对于用户访问的资源。我们可以自由拼接上我们的web根目录了
cpp
// 对uri进行拼接
_path = wwwroot; // ./wwwroot
_path += _url; // / 或者 /a/b/c
if (_url == "/")
{
_path += home; // ./wwwroot/index.html
}我们就可以试着以http://ip:port/a/b/c这样的方式来访问你想要的资源了!
但是,在真实情况下,我们并不是以这样的方式访问的,而是以鼠标点击链接的方式。

现在,我们把视角切换到前端。我们点击鼠标这个行为,会解释称成什么呢?在前端,有一个a标签,就是超链接,就是uri,而我们鼠标点击的文字,就对应一个唯一的资源,然后后端就可以根据这个uri,拼接上web根目录,就可以访问这个资源,然后返回给用浏览器了!
假设我们的首页有三个这样的a标签。
cpp
<li><a href="/login.html">登录</a></li>
<li><a href="/register.html">注册</a></li>
<li><a href="https://www.baidu.com/">百度一下</a></li>当我们点击时,我们的httpserver会自动拼接路径。

所以我们能不能理解当用户点击一个个链接时,其实就是在做cd 命令,前后端时,如何过渡的,这里具体化了。
🐛一个页面只对应一个http请求吗?
No!**http请求的时候,获取任何页面的时候,页面有很多元素构成,获取完整首页!=一次http请求。**假设我们的界面有别的资源,比如有很多图片,那么对于一个首页的获取,可能是成百上千次的http请求。比如我们的界面现在有三个图片资源,就会有3次http请求:
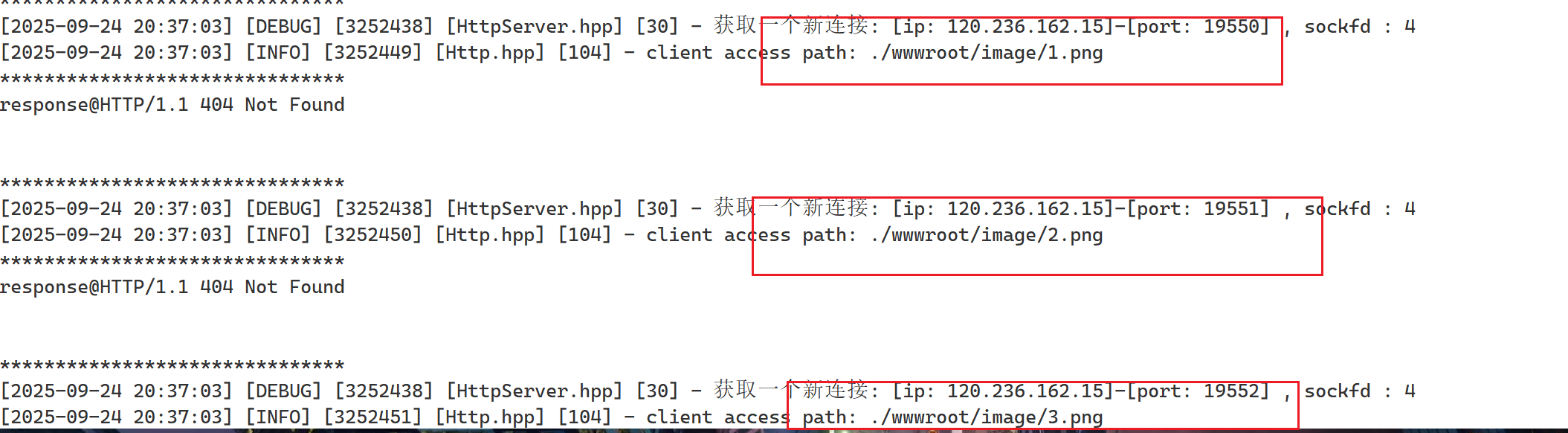
这样我们就能理解了,为什么大的公司都要一些高并发的服务器,因为一个页面就可能对应成百上千次的http请求。而对于我们的服务器底层作为多进程的服务器,这显然是有上限的。
🐼HTTP响应正文类型
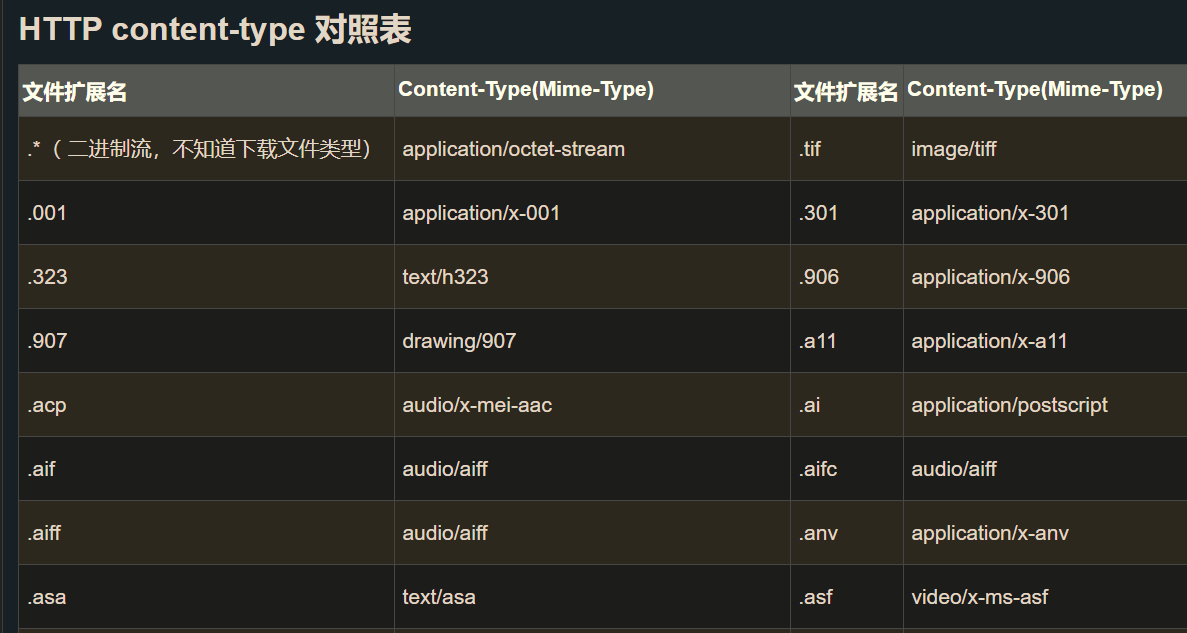
我们已经知道了不管对于http请求还是应答,都有content-Length,作为超文本的http,自已也是有类型的。客户端如何知道正文的类型?通过uri的后缀(所以总归,都是围绕uri展开的,因为这个过程就是IO),知道了uri,就能提取到后缀,如何知道其对应类型。有一个对照表,关于后缀和content-type的映射关系。content-type
🐼HTTP 常见 Header
我们现在总结一下,Http的常见Header字段。有的是请求的报头,有的是应答的报头,有的字段大家都有。
✅Content-Type: 数据类型(text/html 等)只在应答中有 。目的是标识响应正文类型
✅Content-Length: Body 的长度,请求应答都有 。目的是为了描述正文字段的长度,空行+content-Length,方便解决数据包粘包问题。
✅Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;一般代理服务器会使用 ,比如请求的主机不是自已,自已仅仅是代理的。请求报头中有 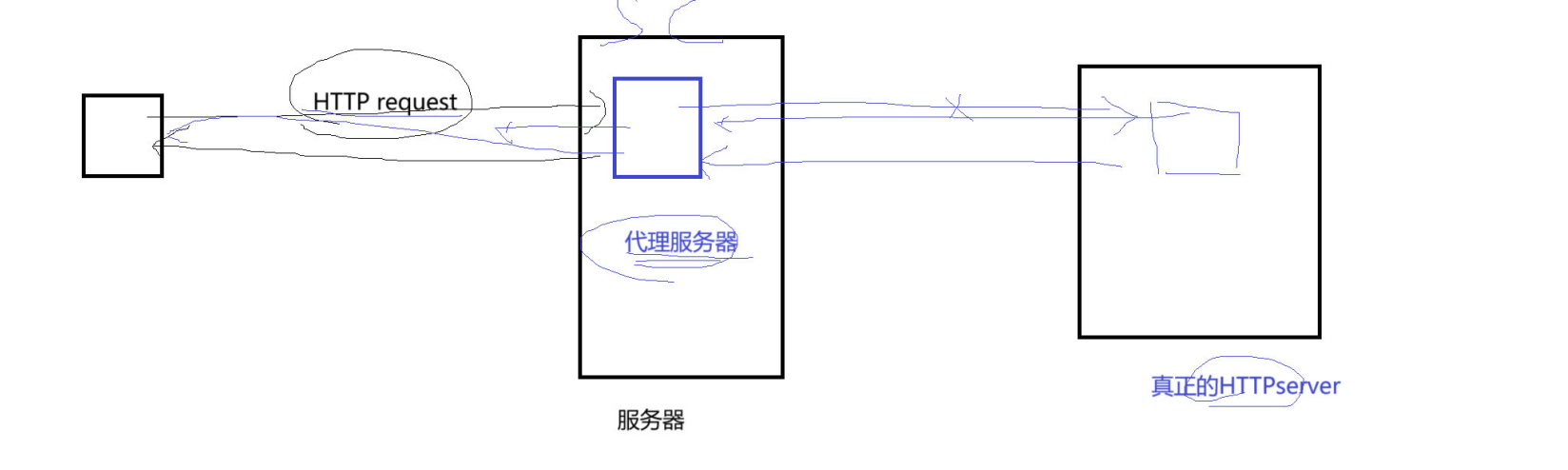
✅User-Agent: 声明用户的操作系统和浏览器版本信息,只有请求有;作用是为了标识自已的信息。有一些爬虫为了绕过服务器,伪装成浏览器,修改的就是这个字段。
✅Referer: 当前页面是从哪个页面跳转过来的,只有请求报头中有;假设我们有三个页面index.html,login.html,register.html,现在从跳转首页->登录->注册。
我们从Referer字段就可以获取是从哪个界面从哪跳转来的到如图:
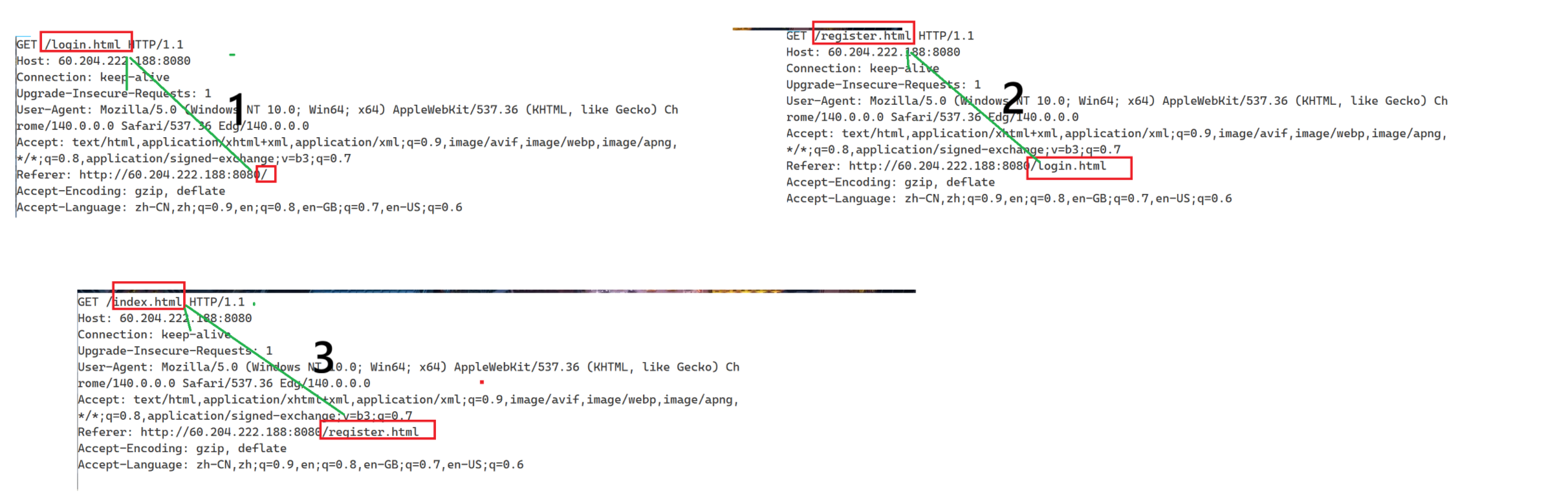
有什么作用呢?1.方便数据统计 2.方便拦截 3.可以爬虫
✅Connection:字段用于控制当前HTTP连接的生命周期和行为。为什么会有Connection,解决HTTP/1.0的连接效率问题,对于我们现在的服务器,没收到一个http请求,就会创建一个子进程,并且还会Tcp三次握手,效率太低了。而Connection: Keep-Alive,表明实现连接复用,这样就会使得一个TCP连接处理多个HTTP请求,大幅提升性能!请求和应答报头中都有比如:
cpp
客户端请求保持连接:
GET /page1.html HTTP/1.1
Host: www.example.com
Connection: keep-alive
服务器同意保持连接:
HTTP/1.1 200 OK
Content-Type: text/html
Connection: keep-alive
Keep-Alive: timeout=30, max=100 # 保持30秒,最多100个请求下面两个字段我们下面会单独说。
✅ Location: 搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问 ;只有应答报头有
✅Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能; 只有请求报头有暂时!!!!!!!!!!!!!!!!!
下面附上一张关于 HTTP 常见 header 的表格
文末尾
🐼HTTP的状态码
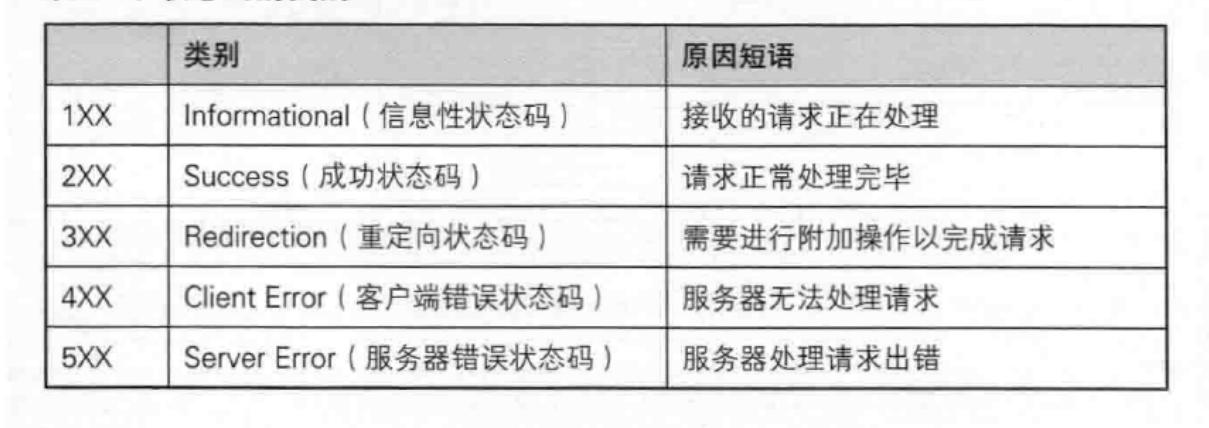
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)。文末附上关于状态码的详细介绍。
✅这里需要知道两个问题,就是为什么服务器无法处理请求,是客户端的错误呢?
因为这就是客户端的错误,明明服务器没有这个资源,可你偏偏要访问 ,你说是不是你的错误。
✅为什么有5开头的错误呢?服务器挂了就不回复不就行了?
原因有两点,首先,对于任何http请求都必须有应答! 其次,如果一个攻击者想攻击一个网站,他需要收集信息。其中一项信息就是了解服务器的健康状况和容量。一个重要的安全原则是避免泄露像并发度这样的内部细节,以防止被攻击者利用。
而应答报文中的状态码描述该如何设置呢?其实,状态码和状态码描述是强关联关系。
也就是110就是报警电话,报警电话就是110.
下面附上一张关于 HTTP 常见 header 的表格
文末尾
🐼重定向 &&Location &&状态码为3XX
这里来详细谈一谈关于重定向的话题。从重定向是什么?为什么?怎么办?的话题来展开
✅下面我们来介绍一下什么是重定向?
因为提供服务的一方,服务的地址(url)发生变更,要求client更改访问的位置,去访问新的地址,就叫做重定向。
✅重定向又分为临时重定向和永久重定向?他们有啥区别?
当应答状态行的状态码为301时,就表明是永久重定向,当应答状态行的状态码为302时,就表明是临时重定向。HTTP 状态码 301(永久重定向) 和 302(临时重定向) 都依赖 Location 选项。
当服务器返回 HTTP 301 状态码时, 表示请求的资源已经被永久移动到新的位置,在这种情况下, 服务器会在响应中添加一个 Location 头部, 用于指定资源的新位置。 这个 Location 头部包含了新的 URL 地址, 浏览器会自动重定向到该地址,也就是浏览器会以新资源的位置替换掉原本访问的位置!
当服务器返回 HTTP 302 状态码时, 表示请求的资源临时被移动到新的位置,同样地, 服务器也会在响应中添加一个 Location 头部来指定资源的新位置。 浏览器会暂时使用新的 URL 进行后续的请求, 但不会缓存这个重定向。也就是每次访问都需要重定向。
简单来说:
-
临时重定向:不影响客户端对原始地址的"认识",客户端知道这只是暂时的。
-
永久重定向:会永久改变客户端对原始地址的"认识",客户端会记住并跳过原始地址。
总结:无论是 HTTP 301 还是 HTTP 302 重定向, 都需要依赖 Location 选项来指定资源的新位置。 这个 Location 选项是一个标准的 HTTP 响应头部, 用于告诉浏览器应该将请求重定向到哪个新的 URL 地址。下面,
✅为什么要有重定向呢?
一句话,重定向保证了互联网的灵活性。比如结合生态问题的引流。刷新页面重复操作...
✅如何做呢?
假设,如果我们请求的资源不存在,我们就重定向到百度首页!
这个过程如图:
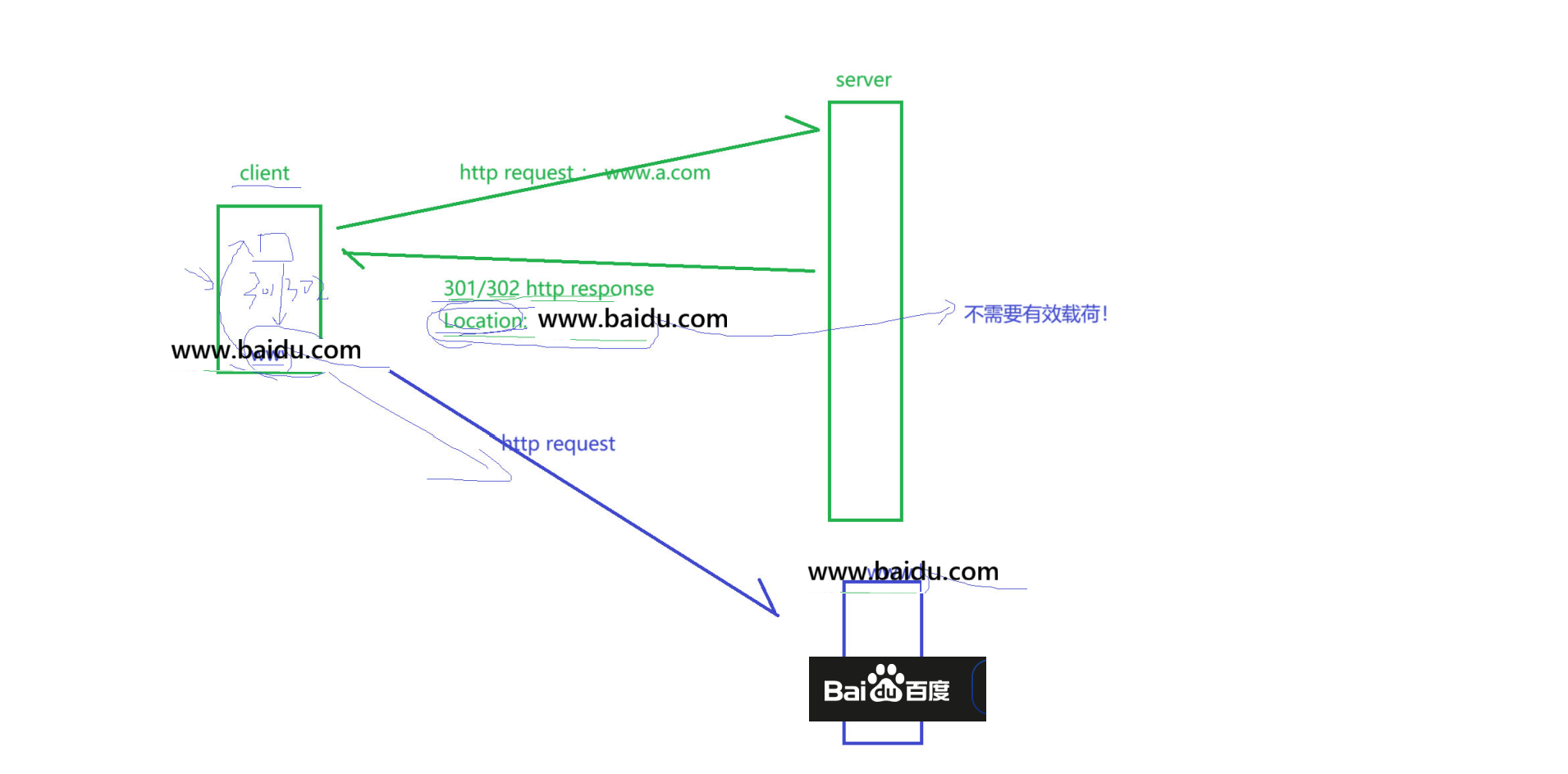
cpp
if (AccessResources(req.Path(), resp))
{
// 访问资源成功
resp.SetStatus(200);
resp.SetHeader("content-type", _contents[suffix]); // 设置content-type
}
else
{
// 资源不存在--- // 重定向到 www.baidu.com
resp.SetHeader("Location", "https://www.baidu.com/");
resp.SetStatus(301); // 设置重定向状态码
}如图,当我们访问一个不存在资源,resp会帮我们重定向到www.baidu.com
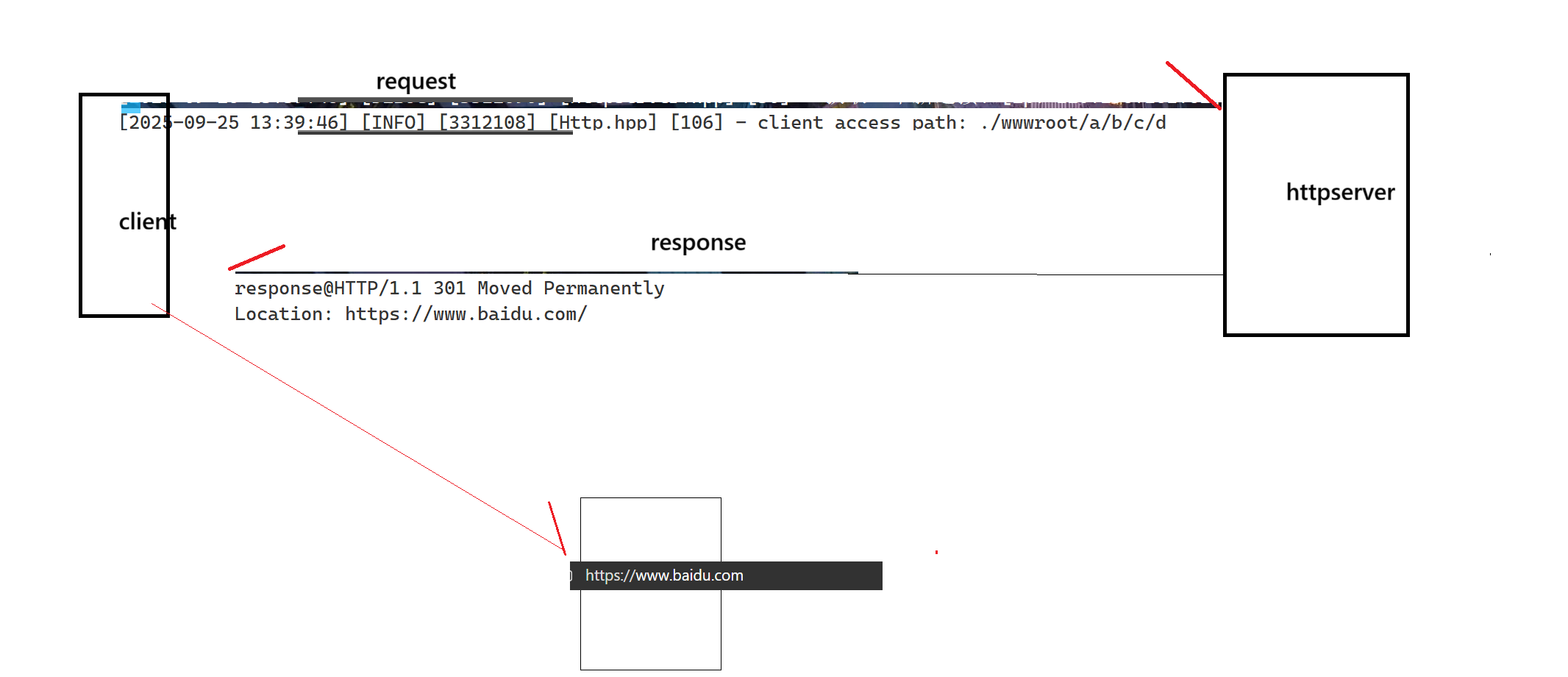
需要注意的是,重定向时,当服务器返回一个3XX的响应报文,并且Location了一个网址,并不需要带正文!不需要有效载荷。
重定向一定要配合着Location和3XX状态码使用。缺一不可
🐼HTTP 常见方法
http方法有很多,但99%都是GET和POST方法。
因为我们上网的行为无非就两种,1.从服务器获取数据,2.上传数据到服务器。
✅下面我们来先认识GET方法
如何理解GET方法,我们必须前后端联动的理解,在前端,有一个form表单,比如我们的登录模块。
cpp
<form action="login" method="GET">
<div class="form-group">
<label for="username">用户名</label>
<input type="text" id="username" name="username" required>
</div>
<div class="form-group">
<label for="password">密码</label>
<input type="password" id="password" name="password" required>
</div>
<button type="submit">登录</button>
</form>
// method="get": 这是核心,告诉浏览器,当用户提交表单时,要使用 HTTP GET 请求来发送数据。
// action="/search": 指定数据要发送到服务器的哪个地址(URL)。
// name="keyword" 和 name="category": 极其重要! name 属性是数据的"键",用户输入的内容是"值"。没有 name 属性的表单字段,其数据不会被提交。其中action就是我们处理表单的后端模块。为什么这么说?
当我们登录时,通过前端的form表单,后端会收到这样的请求

其中username就是我们刚刚输入的用户名,password就是我们刚刚输入的密码。这是不是意味着GET方法也能提交参数,访问的是我们的login模块。
那么如果把有多个模块,分别是登录,注册,查询,模块,那是不是意味着form中action的模块就是我们要访问的后端的模块,而"?"后面的内容就是要提交的参数。如图:
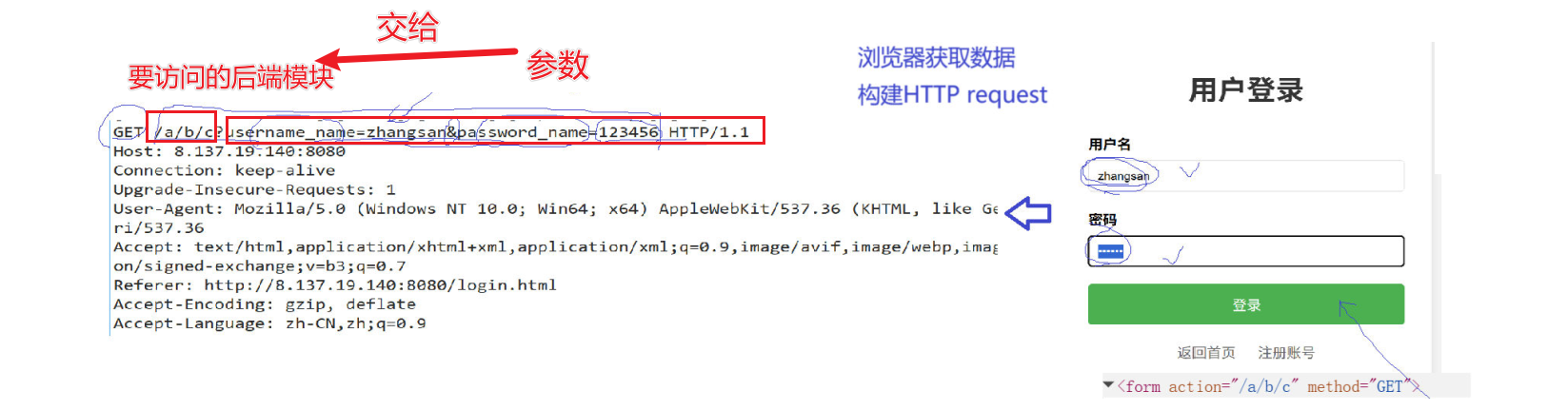
我们把这种请求方式叫做GET传参,也就是交互式处理。而我们之前客户端访问服务器资源叫做处理静态网页资源
所以,我们服务器当然要区别出是交互式处理还是处理静态网页资源了。如何区别,还是靠uri中是否有"?"。伪代码:
cpp
using func_t = std::function<HttpResponse(HttpRequest &)>;
{
// 反序列化
HttpRequest req;
std::string resp_json;
if (req.DeSerialize(req_json))
{
HttpResponse resp;
std::string target = req.Path(); // // ./wwwroot/index.html -> ./wwwroot/login
if (_handlers.count(target))
{
// 交互式处理
resp = _handlers[target](req); // 路由到其他模块
}
else
{
// 静态网页请求
std::string suffix = req.Suffix();
if (AccessResources(req.Path(), resp))
{
// 访问资源成功
resp.SetStatus(200);
resp.SetHeader("content-type", _contents[suffix]); // 设置content-type
}
else
{
// 资源不存在---404 // ./wwwroot/404.html
// 重定向到404.html,会再次发起一次对404.html的请求。
resp.SetHeader("Location", "/404.html"); // 这里会自动拼接,使用根目录绝对路径
resp.SetStatus(302); // 永久重定向,设置状态码
}
}
resp_json = resp.Serialize();
}
}
private:
std::unordered_map<std::string, func_t> _handlers; // 功能路由
// main函数,注册方法
std::unique_ptr<Http> ht = std::make_unique<Http>();
ht->Register("login", Login);
ht->Register("register", Register);
ht->Register("search", Search);
// 三个模块
HttpResponse Login(HttpRequest& req)
{
LOG(LogLevel::DEBUG) << "----Login, args: " << req.Args();
}
HttpResponse Register(HttpRequest& req)
{
LOG(LogLevel::DEBUG) << "----Login, args: " << req.Args();
}
HttpResponse Search(HttpRequest& req)
{
LOG(LogLevel::DEBUG) << "----Login, args: " << req.Args();
}所以,前后端是怎么联动的呢?前端form中的action就是后端要路由的模块。

所以HTTP可以以URL的形式,对外提供完整的网络服务!!!
就像函数调用一样。我们把这种叫做restful风格的微服务接口

所以在上网时,对于
我们就知道它在请求后端模块s的服务,并将参数交给他。
✅下面我们来先认识POST方法
POST方法也是要结合前端,在form表单中只需要将method改为POST即可。
那和GET方法有什么区别呢?我们看一下请求报文就知道了
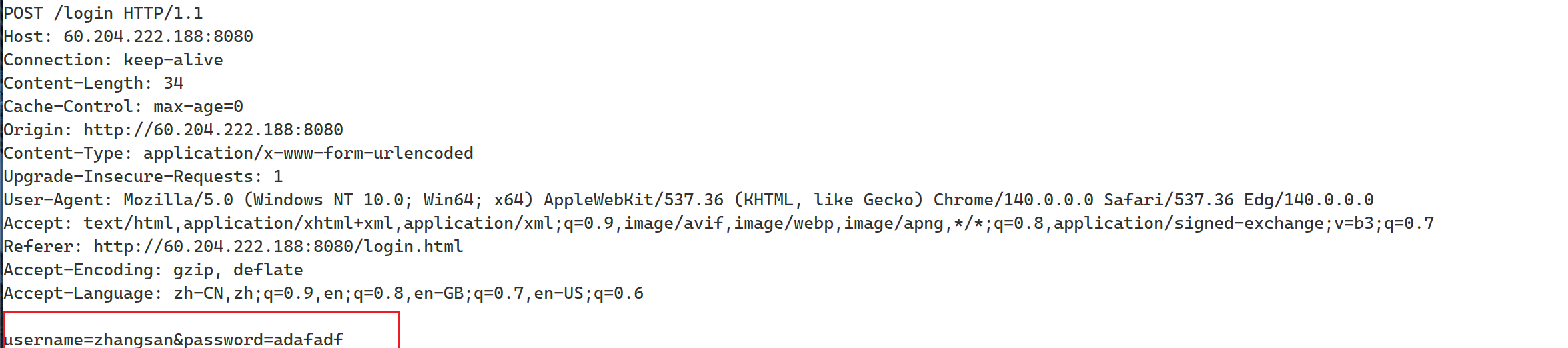
POST方法是通过正文来传参。而GET方法是通过URL的方式来传参。
🐼GET和POST方法安全吗?
我们上面已经演示了。GET方法时通过URL来传参的,参数回显在URL中,这显然是不安全的,如果是账号和密码的话。
POST请求,更私密一点,账号和密码是在正文的,并且可以传较长的参数。那么就是安全的对吧?不安全,绝对 不安全!为什么呢?
我们可以通过抓包工具来抓到GET请求和POST请求。
抓取GET请求

抓取POST请求:

所以他们都是明文的。那么如何加密呢?下一节我们会探讨。
🐼HTTP代码
这里是短连接,我们就不用多进程了,处理短任务还是线程池高效一点。我们接入线程池,并呈现一些
关键代码:
httpserver
cpp
#pragma once
#include <iostream>
#include <memory>
#include <functional>
#include <unistd.h>
#include <sys/types.h>
#include <signal.h>
#include "Socket.hpp"
#include "ThreadPool.hpp" // 引入线程池
using callback_t = std::function<std::string( std::string &)>;
using task_t = std::function<void()>;
class HttpServer
{
public:
HttpServer(uint16_t port, callback_t cb) : _tcpsockfd(std::make_unique<TcpSocket>()),
_port(port),
_cb(cb)
{
_tcpsockfd->BuildTcpServerSocketMethod(_port);
}
void Run()
{
// 接入线程池----这里为为了方便,完全可以在外面就启动线程池。
ThreadPool<task_t>* tp = ThreadPool<task_t>::GetInstance();
signal(SIGCHLD, SIG_IGN);
while (true)
{
InetAddr client;
std::shared_ptr<Socket> sockfd = _tcpsockfd->Accept(&client);
if (sockfd < 0)
continue; // 暂时
LOG(LogLevel::DEBUG) << "获取一个新连接: " << client.SocketToString()
<< ", sockfd : " << sockfd->SockFd();
task_t task = bind(&HttpServer::HandlerIO, this, sockfd); // 先提前给线程绑定一个方法
tp->Enqueue(task); // 入任务队列
}
}
void HandlerIO(std::shared_ptr<Socket> &sockfd)
{
std::string recv_json; // 保存每个Tcp长连接的报文,可能一次并没有读完整,可能需要多次拼接
// 短连接
// 假设我们这里每次都到一个完整的http请求。把它当成长字符串处理
ssize_t n = sockfd->Recv(&recv_json);
if (n < 0)
{
LOG(LogLevel::WARNING) << "recv err";
}
else if (n == 0)
{
LOG(LogLevel::INFO) << "对端已经关闭连接,me too";
}
else
{
// 交给上层,http
std::string result = _cb(recv_json);
if (!result.empty())
{
sockfd->Send(result);
}
}
sockfd->Close(sockfd->SockFd()); // 执行完必须关闭,防止文件描述符泄露
}
~HttpServer()
{
_tcpsockfd->Close(_tcpsockfd->SockFd());
}
private:
std::unique_ptr<Socket> _tcpsockfd;
uint16_t _port;
callback_t _cb;
};应用层服务Http.hpp
cpp
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <sstream>
#include <unordered_map>
#include <functional>
#include "Logger.hpp"
#define debug
const static std::string args = "?";
const static std::string space = " ";
const static std::string sep = ": ";
const static std::string point = ".";
const static std::string line_break = "\r\n";
const static std::string wwwroot = "./wwwroot";
const static std::string home = "index.html";
const static std::string err_home = "404.html";
class HttpRequest
{
private:
bool ReadLine(std::string &req, std::string *outline)
{
auto pos = req.find(line_break);
if (pos == std::string::npos)
return false;
// 提取第一行
*outline = req.substr(0, pos);
req.erase(0, pos + line_break.size());
return true;
}
void ParseLine(const std::string &line)
{
std::stringstream ss(line);
ss >> _method >> _uri >> _version;
#ifdef debug
// LOG(LogLevel::DEBUG) << _method;
// LOG(LogLevel::DEBUG) << _uri;
// LOG(LogLevel::DEBUG) << _version;
#endif
}
#ifdef debug
void ShowHeaders()
{
std::cout << "********************************************" << std::endl;
for (auto &kv : _headers)
{
std::cout << kv.first << "## " << kv.second << std::endl;
}
std::cout << "********************************************" << std::endl;
}
#endif
public:
HttpRequest() {}
void Serialize() {} // 我们不做,客户端浏览器会做
bool DeSerialize(std::string &req)
{
// std::cout << "---------------------------------------" << std::endl;
// std::cout << req << std::endl;
// std::cout << "---------------------------------------" << std::endl;
// 解析一行--提取请求行
std::string line;
if (!ReadLine(req, &line) || line.empty())
return false;
#ifdef debug
// LOG(LogLevel::DEBUG) << line;
#endif
ParseLine(line);
// 提取请求报文
std::string header_line;
// 当header_line为空时,代表遇到空行了,就将整个报头解析完整了!
while (ReadLine(req, &header_line) && !header_line.empty())
{
// 解析kv
auto pos = header_line.find(sep);
if (pos == std::string::npos)
{
LOG(LogLevel::WARNING) << header_line << " is not a legal header";
continue;
}
std::string key = header_line.substr(0, pos);
std::string value = header_line.substr(pos + sep.size());
if (key.empty() || value.empty())
continue;
_headers.emplace(key, value);
}
#ifdef debug
// ShowHeaders();
#endif
// 提取请求正文
if (!req.empty())
_body = req;
// 对_uri进行拼接
_path = wwwroot; // ./wwwroot
_path += _uri; // / 或者 /a/b/c
if (_uri == "/")
{
_path += home; // ./wwwroot/index.html
}
// 如果是交互式处理提取参数
// ./wwwroot/login?username=sjldjdkl&password=adfadaf
if (_method == "GET")
{
auto pos = _path.find(args);
if (pos != std::string::npos)
{
_args = _path.substr(pos + args.size());
_path = _path.substr(0, pos);
}
}
else if (_method == "POST")
{
// 参数在请求正文中
_args = _body;
}
// LOG(LogLevel::DEBUG) << "_path:" << _path;
// LOG(LogLevel::DEBUG) << "_args:" << _args;
LOG(LogLevel::INFO) << "client access path: " << _path;
return true;
}
std::string Path()
{
return _path;
}
void SetPath(const std::string &path)
{
_path = path;
}
std::string Args()
{
return _args;
}
std::string Suffix()
{
auto pos = _path.rfind(point);
if (pos == std::string::npos)
{
LOG(LogLevel::DEBUG) << "非法后缀";
return std::string();
}
return _path.substr(pos);
}
~HttpRequest() {}
private:
// 请求行
std::string _method;
std::string _uri;
std::string _version;
// 请求报文
std::unordered_map<std::string, std::string> _headers;
// 请求正文
std::string _body;
std::string _path; // 表示真正请求的路径
std::string _args; // get方法提取的参数
};
class HttpResponse
{
private:
std::string Code2Desc(int code)
{
switch (code)
{
case 200:
return "ok";
break;
case 400:
return "Bad Request";
break;
case 404:
return "Not Found";
break;
case 301:
return "Moved Permanently";
case 302:
return "See Other";
case 307:
return "Temporary Redirect";
default:
return "";
break;
}
}
public:
HttpResponse()
{
}
std::string Serialize()
{
std::ostringstream os;
// 拼接状态行
os << _version << space << _status << space << _desc_status << line_break;
if (!_body.empty())
{
size_t len = _body.size();
SetHeader("Content-Length", std::to_string(len));
}
// 拼接响应报文
for (auto &kv : _headers)
{
os << kv.first << sep << kv.second << line_break;
}
// 拼接cookie字段
for (auto &cookie : _cookies)
{
os << cookie;
}
// 拼接空行
os << line_break;
// 拼接响应正文
os << _body;
return os.str();
}
void SetBody(const std::string &body)
{
_body = body;
}
void SetStatus(int status)
{
_status = status;
_desc_status = Code2Desc(status);
}
void SetHeader(const std::string &k, const std::string &v)
{
_headers[k] = v;
}
void SetCookie(const std::string &k, const std::string &v)
{
std::ostringstream os;
// 确保格式为:name=value
os << "Set-Cookie: " << k << "=" << v << "; Path=/" << "\r\n";
_cookies.push_back(os.str());
}
std::string Body()
{
return _body;
}
// void DeSerialize() // 我们不做,客户端浏览器会做
// {
// }
~HttpResponse() {}
private:
// 状态行
std::string _version = "HTTP/1.1";
int _status;
std::string _desc_status;
// 响应报文
std::unordered_map<std::string, std::string> _headers;
// cookie字段,因为cookie字段可能是多行
std::vector<std::string> _cookies;
// 响应正文
std::string _body;
};
const static std::string content_path = "./content.txt";
const static std::string innerspace1 = ": ";
using handler_t = std::function<HttpResponse(HttpRequest &)>;
class Http
{
public:
Http()
{
std::ifstream file(content_path);
if (!file.is_open())
{
std::cerr << "Error: Could not open file " << content_path << std::endl;
exit(1);
}
std::string line;
while (std::getline(file, line))
{
if (line.empty())
continue;
auto pos = line.find(innerspace1);
if (pos == std::string::npos)
{
std::cerr << "格式错误" << std::endl;
continue;
}
std::string k = line.substr(0, pos);
std::string v = line.substr(pos + innerspace1.size());
_contents.insert(std::make_pair(k, v));
}
file.close();
}
private:
bool AccessResources(const std::string &filename, HttpResponse &resp)
{
std::ifstream in(filename, std::ios::binary | std::ios::ate);
if (!in.is_open())
{
return false;
}
// 获取文件大小
std::streamsize size = in.tellg();
in.seekg(0, std::ios::beg);
// 读取文件内容
std::vector<char> buffer(size);
if (!in.read(buffer.data(), size))
{
return false;
}
std::string body(buffer.begin(), buffer.end());
resp.SetBody(body);
return true;
}
public:
void Register(const std::string &action, handler_t method)
{
std::string k = wwwroot; //./wwwroot/login
k += "/";
k += action;
_handlers[k] = method;
}
std::string HandlerHttpResquestToResponse(std::string &req_json)
{
// 反序列化
HttpRequest req;
std::string resp_json;
if (req.DeSerialize(req_json))
{
HttpResponse resp;
std::string target = req.Path(); // // ./wwwroot/index.html -> ./wwwroot/login
if (_handlers.count(target))
{
// 交互式处理
resp = _handlers[target](req); // 路由到其他模块
}
else
{
// 静态网页请求
std::string suffix = req.Suffix();
if (AccessResources(req.Path(), resp))
{
// 访问资源成功
resp.SetStatus(200);
resp.SetHeader("content-type", _contents[suffix]); // 设置content-type
}
else
{
// 资源不存在---404 // ./wwwroot/404.html
// 重定向到404.html,会再次发起一次对404.html的请求。
resp.SetHeader("Location", "/404.html"); // 这里会自动拼接,使用根目录绝对路径
resp.SetStatus(302); // 永久重定向,设置状态码
}
}
resp_json = resp.Serialize();
}
#ifdef debug
// std::cout << "*******************************" << std::endl;
// std::cout << "response@";
// std::cout << resp_json << std::endl;
// std::cout << "*******************************" << std::endl;
#endif
return resp_json;
}
private:
std::unordered_map<std::string, std::string> _contents;
std::unordered_map<std::string, handler_t> _handlers; // 功能路由
};main.cpp
cpp
#include <memory>
#include "Http.hpp"
#include "HttpServer.hpp"
void Usage(const std::string &msg)
{
printf("Usage: %s + port\n", msg.c_str());
}
std::string hellohttp(std::string &req)
{
std::cout << "################################" << std::endl;
std::cout << req << std::endl;
std::cout << "################################" << std::endl;
return "hello http";
}
HttpResponse Login(HttpRequest &req)
{
LOG(LogLevel::DEBUG) << "----Login, args: " << req.Args();
HttpResponse resp;
resp.SetStatus(302);
resp.SetHeader("Location", "/login.html");
resp.SetCookie("username", "zhangsan"); // 暂时,后面可以提取出来
resp.SetCookie("session_id", "abc123"); // 暂时,后面可以提取出来参数
resp.SetCookie("hhhhhh", "111111"); // 暂时,后面可以提取出来参数
resp.SetCookie("dddddd", "sssssss"); // 暂时,后面可以提取出来参数
resp.SetCookie("dd", "k1"); // 暂时,后面可以提取出来参数
return resp;
}
HttpResponse Register(HttpRequest &req)
{
LOG(LogLevel::DEBUG) << "----Login, args: " << req.Args();
}
HttpResponse Search(HttpRequest &req)
{
LOG(LogLevel::DEBUG) << "----Login, args: " << req.Args();
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(0);
}
// 启动日志模块
EnableConsoleLogStrategy();
uint16_t port = std::stoi(argv[1]);
std::unique_ptr<Http> ht = std::make_unique<Http>();
ht->Register("login", Login);
ht->Register("register", Register);
ht->Register("search", Search);
std::unique_ptr<HttpServer> tsvr = std::make_unique<HttpServer>(port, [&ht](std::string &req)
{ return ht->HandlerHttpResquestToResponse(req); });
tsvr->Run();
return 0;
}🐼结语
favicon.ico 是一个网站图标, 通常显示在浏览器的标签页上、 地址栏旁边或收藏夹中。 这个图标的文件名 favicon 是 "favorite icon" 的缩写, 而 .ico 是图标的文件格式。• 浏览器在发起请求的时候, 也会为了获取图标而专门构建 http 请求, 我们不管它。
总结一下,我们的HTTP服务器是如何搭起来的?
通过解析请求行->uri->设置web根目录->获取真实要访问的path->访问资源了->设置应答相应正文->设置content-Length->设置content->type->设置状态码->访问失败->进行重定向
给http注册方法->通过uri->获取是否是交互式处理的网页->如果是->进行功能路由->如果不是->那么就访问静态资源即可。
🐼文本末
HTTP状态码:
cpp
```
HTTP状态码总结
1xx 信息性状态码
100 Continue
- 含义:继续
- 场景:上传大文件时,服务器告诉客户端可以继续上传
2xx 成功状态码
200 OK
- 含义:成功
- 场景:访问网站首页,服务器返回网页内容
201 Created
- 含义:已创建
- 场景:发布新文章,服务器返回文章创建成功的信息
204 No Content
- 含义:无内容
- 场景:删除文章后,服务器返回"无内容"表示操作成功
3xx 重定向状态码
301 Moved Permanently
- 含义:永久移动
- 场景:网站换域名后,自动跳转到新域名;搜索引擎更新网站链接时使用
302 Found 或 See Other
- 含义:临时重定向
- 场景:用户登录成功后,重定向到用户首页
304 Not Modified
- 含义:未修改
- 场景:浏览器缓存机制,对未修改的资源返回304状态码
307 Temporary Redirect
- 含义:临时重定向
- 场景:临时重定向资源到新的位置(较少使用)
308 Permanent Redirect
- 含义:永久重定向
- 场景:永久重定向资源到新的位置(较少使用)
4xx 客户端错误状态码
400 Bad Request
- 含义:错误请求
- 场景:填写表单时,格式不正确导致提交失败
401 Unauthorized
- 含义:未授权
- 场景:访问需要登录的页面时,未登录或认证失败
403 Forbidden
- 含义:禁止访问
- 场景:尝试访问你没有权限查看的页面
404 Not Found
- 含义:未找到
- 场景:访问不存在的网页链接
5xx 服务器错误状态码
500 Internal Server Error
- 含义:服务器内部错误
- 场景:服务器崩溃或数据库错误导致页面无法加载
502 Bad Gateway
- 含义:错误网关
- 场景:使用代理服务器时,代理服务器无法从上游服务器获取有效响应
503 Service Unavailable
- 含义:服务不可用
- 场景:服务器维护或过载,暂时无法处理请求
```HTTP HEADER
XML
HTTP 请求头 (Request Headers)
Accept
- 作用:客户端可接受的响应内容类型
- 示例:Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding
- 作用:客户端支持的数据压缩格式
- 示例:Accept-Encoding: gzip, deflate, br
Accept-Language
- 作用:客户端可接受的语言类型
- 示例:Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Host
- 作用:请求的主机名和端口号
- 示例:Host: www.example.com:8080
User-Agent
- 作用:客户端的软件环境信息
- 示例:User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
Cookie
- 作用:客户端发送给服务器的 HTTP cookie 信息
- 示例:Cookie: session_id=abcdefg12345; user_id=123
Referer
- 作用:请求的来源 URL
- 示例:Referer: http://www.example.com/previous_page.html
Content-Type
- 作用:实体主体的媒体类型
- 示例:Content-Type: application/x-www-form-urlencoded (表单提交) 或 Content-Type: application/json (JSON 数据)
Content-Length
- 作用:实体主体的字节大小
- 示例:Content-Length: 150
Authorization
- 作用:认证信息,如用户名和密码
- 示例:Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== (Base64 编码)
Cache-Control
- 作用:缓存控制指令
- 示例:请求时:Cache-Control: no-cache 或 max-age=3600;响应时:Cache-Control: public, max-age=3600
Connection
- 作用:请求完成后是关闭还是保持连接
- 示例:Connection: keep-alive 或 Connection: close
Date
- 作用:请求或响应的日期和时间
- 示例:Date: Wed, 21 Oct 2023 07:28:00 GMT
HTTP 响应头 (Response Headers)
Location
- 作用:重定向的目标 URL(与 3xx 状态码配合使用)
- 示例:Location: http://www.example.com/new_location.html (与 302 状态码配合)
Server
- 作用:服务器类型
- 示例:Server: Apache/2.4.41 (Unix)
Last-Modified
- 作用:资源的最后修改时间
- 示例:Last-Modified: Wed, 21 Oct 2023 07:20:00 GMT
ETag
- 作用:资源的唯一标识符,用于缓存
- 示例:ETag: "3f80f-1b6-5f4e2512a4100"
Expires
- 作用:响应过期的日期和时间
- 示例:Expires: Wed, 21 Oct 2023 08:28:00 GMT
Cache-Control
- 作用:缓存控制指令
- 示例:Cache-Control: public, max-age=3600