背景
本系统为客服系统,对接了后端智能辅助系统;当消费者发文字时(问题),本系统会将文字发给辅助系统,辅助系统会返回相关回答,供客服参考。
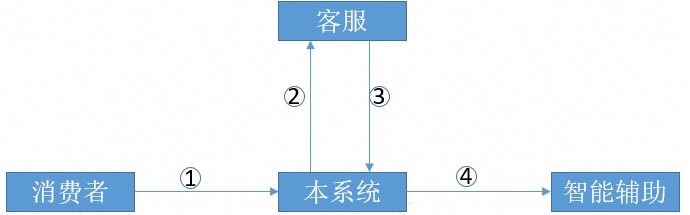
过程如下:
- 消费者发送问题(文字)给客服
- 消费者问题(文字)推送给客服上屏
- 客服前端调用本系统接口,将问题发过去
- 本系统将调用透传给智能辅助系统,并将结果回传给前端
3、4两步均采用的SSE,本系统调用智能辅助时纯透传没有额外逻辑。
本来我们系统基于Spring的RestTemplate写了一套类似feign的框架,简化调用后端。因为RestTemplate不能很好的处理SSE(RestTemplate返回时,会关闭连接,所以一次调用必须读取完整的响应,那就没办法实现流式效果),因此本次调用不能使用之前的框架,但是我们又不想引入新的开源组件,因此决定使用JDK自带的HttpURLConnection进行远程调用。
备注:流式效果是指像deepseek那样一个字一个字的返回给前端上屏,所以后台只要获取到内容就得写回给前端,而不是像通常的接口,后台获取到完整的结果后一次写回前端。
java
# 代码有简化
public void quireSopAnswer(Param param, HttpServletResponse response) {
setHead(response);
HttpURLConnection httpURLConnection = getHttpURLConnection(param);
InputStream inputStream = httpURLConnection.getInputStream();
OutputStream outputStream = response.getOutputStream()
while (true) {
byte[] tmp = new byte[8192];
int read = inputStream.read(tmp);
outputStream.write(tmp, 0, read);
outputStream.flush();
if (read < 0) {
break;
}
}
}该代码测试的时候发现,流式效果不是很明显,感觉所有内容都是挤在一起上屏的。
后面参考隔壁项目组的写法,能很好的实现流式的效果。
java
# 代码有简化
public void quireSopAnswer(HttpServletRequest request, HttpServletResponse response) {
setHead(response);
AsyncContext asyncContext = request.startAsync(request, response);
getWebClient().post()
.retrieve()
.bodyToFlux(new ParameterizedTypeReference<ServerSentEvent<String>>() { })
.subscribe(eventSourcet -> receiveAnswerAndSend(eventSourcet, asyncContext),
err -> LOGGER.error(err), asyncContext::complete);
}
private void receiveAnswerAndSend(ServerSentEvent<String> eventSourcet, AsyncContext asyncContext) {
HttpServletResponse resp = (HttpServletResponse) asyncContext.getResponse();
StringBuilder sb = new StringBuilder();
sb.append("event: ").append(eventSourcet.event()).append("\n");
sb.append("data: ").append(eventSourcet.data()).append("\n");
sb.append("\n");
resp.getWriter().write(sb.toString());
resp.getWriter().flush();
}既然代码不符合预期,那就要搞清楚根因是啥。
定位过程
因为已经有正确的写法(效果好的写法),为了快速确认原因,因此首先通过对比差异,针对差异点进行论证分析。
如果此方法仍未找到合理的原因,那就得根据第一性原理,先找到前端为什么一大段文字一起上屏,然后逐步追踪线索,找到最终根因。
分析一:先快速定界,确认我们后台收到后端的数据是不是本来就是挤在一起的
增加日志,每次read的时候,打印read的字节数以及内容。确认是不是后台自己一次将内容都挤在一次返回的,导致流式效果不明显。
结果:从日志来看,确实是流式输出,而不是所有内容挤在一起发送的。而且我们也看了后端的代码,他们也确实是一个一个的event独立返回的,并不会缓冲等着一起返回。
java
2025-11-15 15:59:42,300 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,301 SseClient:201 - 28
2025-11-15 15:59:42,302 SseClient:203 - ------Date-----
2025-11-15 15:59:42,303 SseClient:204 - event:requestId[N]data:{\"conte
2025-11-15 15:59:42,304 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,306 SseClient:201 - 127
2025-11-15 15:59:42,307 SseClient:203 - ------Date-----
2025-11-15 15:59:42,308 SseClient:204 - nt\":\"373BEB7200DDB2BABF0AC14DE6E6383F9F847C1FC85C422A\",\"conversionId\":\"a8bef8a85f1ed27fc3fff22de4747a412106\",\"fallback\":null}[N][N]
2025-11-15 15:59:42,323 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,324 SseClient:201 - 28
2025-11-15 15:59:42,325 SseClient:203 - ------Date-----
2025-11-15 15:59:42,327 SseClient:204 - event:handle_thoughts[N]data:{
2025-11-15 15:59:42,328 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,329 SseClient:201 - 200
2025-11-15 15:59:42,330 SseClient:203 - ------Date-----
2025-11-15 15:59:42,331 SseClient:204 - \"content\":\"1\",\"conversionId\":\"a8bef8a85f1ed27fc3fff22de4747a412106\",\"fallback\":null}[N][N]event:handle_thoughts[N]data:{\"content\":\".\",\"conversionId\":\"a8bef8a85f1ed27fc3fff22de4747a412106\",\"fallback\":null}[N][N]
2025-11-15 15:59:42,351 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,353 SseClient:201 - 28
2025-11-15 15:59:42,354 SseClient:203 - ------Date-----
2025-11-15 15:59:42,355 SseClient:204 - event:handle_thoughts[N]data:{
2025-11-15 15:59:42,356 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,357 SseClient:201 - 205
2025-11-15 15:59:42,358 SseClient:203 - ------Date-----
2025-11-15 15:59:42,359 SseClient:204 - \"content\":\" 发\",\"conversionId\":\"a8bef8a85f1ed27fc3fff22de4747a412106\",\"fallback\":null}[N][N]event:handle_thoughts[N]data:{\"content\":\"送\",\"conversionId\":\"a8bef8a85f1ed27fc3fff22de4747a412106\",\"fallback\":null}[N][N]
2025-11-15 15:59:42,361 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,362 SseClient:201 - 28
2025-11-15 15:59:42,363 SseClient:203 - ------Date-----
2025-11-15 15:59:42,364 SseClient:204 - event:handle_thoughts[N]data:{
2025-11-15 15:59:42,365 SseClient:200 - ------readed number-----
2025-11-15 15:59:42,366 SseClient:201 - 86
2025-11-15 15:59:42,367 SseClient:203 - ------Date-----
2025-11-15 15:59:42,368 SseClient:204 - \"content\":\"H\",\"conversionId\":\"a8bef8a85f1ed27fc3fff22de4747a412106\",\"fallback\":null}[N][N]
... ...分析二,分析两种写法的差异,通过修改第一种写法,保证2者行为一致,并测试效果,来确认是那个差异导致的问题
个人看到两者明显的差异是,第二种写法一次返回一个完整的event。而写法一,通过日志可以看到一个完整的event被拆开了,分好几次写回前端。
首先先分析了产生该现象的原因,然后在修改第一种写法,保证它也是一次返回完整的event,然后测试效果。
第一种写法,为什么本系统收到后端的event被拆成好几部分,而不是一次读取到完整的event。
- 先确认是不是后端问题,即后端持续流式输出的时候,本身就不是一次返回完整的event。
为了确认该问题,首先找后台要到了他们的代码进行分析,结果他们代码确实是一次写回完整的event。然后我们也通过抓包,确认通过中间件后,该行为并未改变(我们并不是直接调用后台服务器,中间还经过了几个中间件的转发)。通过抓包也确认,我们系统每次接受到的报文也确实是一个完整的event。



根据我掌握的知识来看,底层获取的tcp报文,在应用层read的时候,不会被拆分。因为底层的报文都是完整的放到缓冲区,供应用层read,除非应用层传的接收数组比缓存区当前已缓冲的数据要小,一次读取不完,导致截断。本系统并不属于该场景,因此该行为应该是HttpURLConnection自己的行为,因此需要对齐源码进行分析。
另外从报文里面也发现了其他的疑点,响应采用的是trunked编码(Transfer-Encoding: chunked),该编码每个分片前面都有长度字段,代表本次响应内容的长度,如上述截图中的"9b" "e4"。
如果HttpURLConnection不解析HTTP协议,即对底层的字节流完全不做处理,那么前端收到的报文会无端多出代表chunked编码长度的字段而导致内容语法错误。
为此分析源码,确认了以上2点疑点。
通过阅读代码发现HttpURLConnection会解析HTTP协议,如果是Transfer-Encoding: chunked,他会按照该编码格式,解析数据,并过滤掉chunked编码中多余的块长度字段。上面的日志也证明了这一点。
sun.net.www.protocol.http.HttpURLConnection#getInputStream
sun.net.www.protocol.http.HttpURLConnection#getInputStream0
sun.net.www.http.HttpClient#parseHTTP
sun.net.www.http.HttpClient#parseHTTPHeader
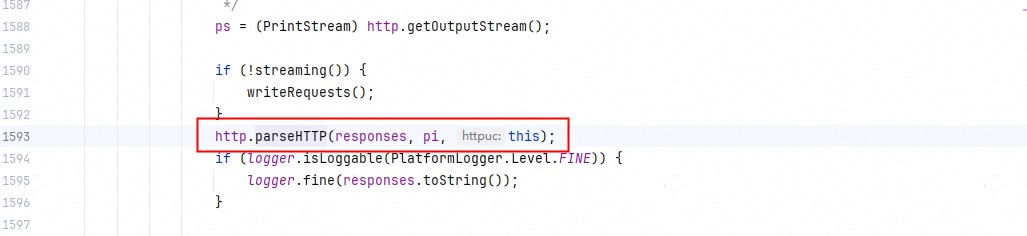
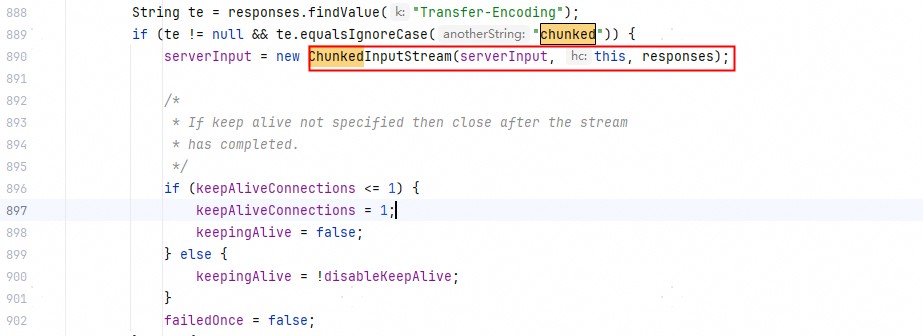
另外也通过阅读ChunkedInputStream的public synchronized int read(byte b\[\], int off, int len)发现为啥底层tcp一帧报文,HttpURLConnection需要read多次,而不是一次就read就返回全部(按说数据在缓冲区都是ready的,不存在读阻塞一说)。
java
public ChunkedInputStream(InputStream in, HttpClient hc, MessageHeader responses) throws IOException {
...
# 构造函数state 被初始化为STATE_AWAITING_CHUNK_HEADER
state = STATE_AWAITING_CHUNK_HEADER;
}
java
public synchronized int read(byte b[], int off, int len)
throws IOException
{
... ...
# 省略了无关的代码
int avail = chunkCount - chunkPos;
if (avail <= 0) {
if (state == STATE_READING_CHUNK) {
return fastRead( b, off, len );
}
# state初始状态为STATE_AWAITING_CHUNK_HEADER,代码会走这里
avail = readAhead(true);
if (avail < 0) {
return -1; /* EOF */
}
}
... ...
return cnt;
}
private int readAhead(boolean allowBlocking) throws IOException {
... ...
# 省略无关代码
if (allowBlocking) {
# 走的这个分支
return readAheadBlocking();
} else {
return readAheadNonBlocking();
}
}
private int readAheadBlocking() throws IOException {
# 代码有省略
do {
... ...
/*
* We must read into the raw buffer so make sure there is space
* available. We use a size of 32 to avoid too much chunk data
* being read into the raw buffer.
*/
# 重点在这里,第一次读时,只会只读32字节,方便先解析出chunk的大小,然后在逐步读取剩下的大小
# 因为此时还不知道单个chunk的大小,buff设多大合适并不知道,所以使用32byte先尝试读取一下
ensureRawAvailable(32);
int nread;
try {
nread = in.read(rawData, rawCount, rawData.length-rawCount);
}
... ...
rawCount += nread;
processRaw();
} while (chunkCount <= 0);
/*
* Return the number of chunked bytes available to read
*/
return chunkCount - chunkPos;
}从上面可以看到应用层调用read的时候,最终会调用到ChunkedInputStream的read,但是ChunkedInputStream初次调用时,只会尝试读取32byte,弄清楚chunk的大小后,在去设置buff以读取chunk剩余的内容。这个与我们日志也能映射上,每次读取完整的event时,第一次读取总是拿到的是28个字节的内容,因为chunked编码的块长度字段会占用4字节(2字节+空格+换行符)。
试验抹除差异后,是否有效果
java
public void quireSopAnswer(SopAgentReq sopAgentReq, HttpServletResponse response) {
setHead(response);
try (OutputStream outputStream = response.getOutputStream();
BufferedReader br = new BufferedReader(
new InputStreamReader(getSseInputStream(para), StandardCharsets.UTF_8))) {
String line;
StringBuilder builder = new StringBuilder();
while (true) {
line = br.readLine();
if (line == null) {
break;
}
# 为了快速验证,这里硬编码了,请忽略这里的不优雅
builder.append(line).append("\n"); # 读取event行
builder.append(line).append("\n"); # 读取data行
builder.append(line).append("\n"); # 读取空行
outputStream.write(builder.toString().getBytes(StandardCharsets.UTF_8));
outputStream.flush();
}
}
}验证发现,仍然没有效果,看来并不是该差异导致的问题。想来也是,SSE是业界标准的协议,只要按照标准格式返回数据,客户端应该是能好好处理这种场景的(netty中俗称的粘包)。
此路不通,我观察到第二种写法,用的servlet的startAsync。经验证也不是该差异导致的问题。此次通过差异点确认问题所在已基本走进死胡同了,因此整理思路,从源头出发逐步分析。
分析三,分析前端为什么会整段文字一起上屏
为了排除前端库的问题(可能前端处理粘包问题处理的不好,导致内容没办法及时丢给应用层代码,最终文字挤在了一起,或者换个说法,应用层瞬间拿到了大段的文字),经对event-source-plus组件的初步分析,排除此问题。
因此自然而然的想确认,前端是如何接收到数据的。通过F12观察到,很多event是同一时间接收到的。难道是网速太快,导致数据最终到达前端时,挤在了一起?
于是后台每次write的时候,我都sleep 100ms,进行降速,在观察效果。
最终观察到的效果并无区别,前端还是大段文字一起上屏,而且从F12看到,还是大量event在同一时间被接受到。此时我感觉像是每次flush并没生效,而是多次write后,缓存区满了后一次写回前端。
对于此疑问,我做了两件事进行确认:
- 同时打开浏览器F12及后台日志监控,一边观察前端F12中接收的数据,一边观察日志打印。
结果write的日志不断在打印,但是前端F12没有显示有数据接收,然后突然前端一下接收大量数据,此时我已经基本确认flush没有生效。 - 使用tcpdump监控网络报文,确认后台确实一次批量写回数据的。

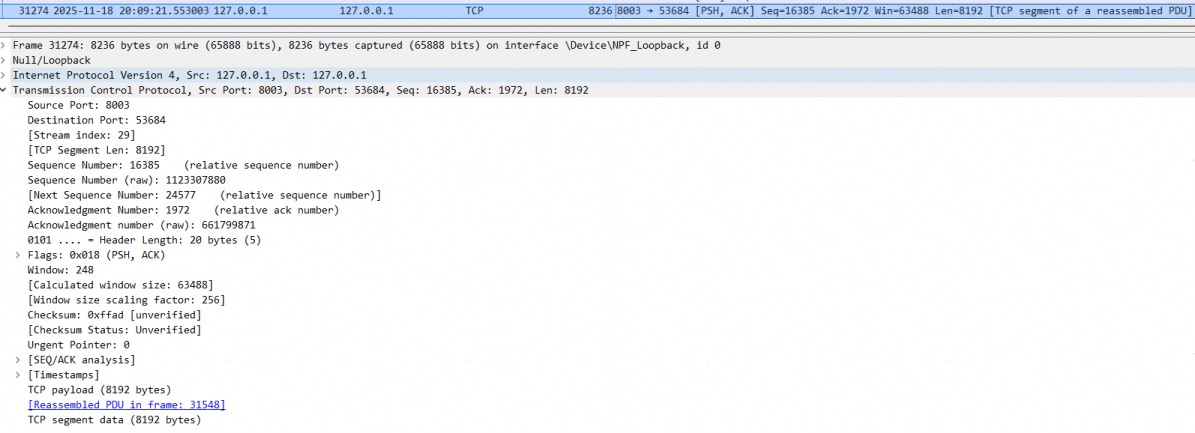
如果flush不生效,tomcat会等缓冲区满了后,写回数据,默认的缓冲区大小是8k,这个与tcpdump监控到的网络报文一致。
servlet的flush函数一定会强制将结果写回的,此时未生效,我第一想到的就是框架对HttpServletResponse做了包装,并重写了OutputStream的flush方法,因此打断点确认。

我们使用的CXF框架,因此代码里面拿到的是CXF包装后的HttpServletResponseFilter,OutputStream为ServletOutputStreamFilter,其flush方法为空,至此所有疑问得以解决。
java
public class HttpServletResponseFilter extends HttpServletResponseWrapper {
# 代码有省略
@Override
public ServletOutputStream getOutputStream() throws IOException {
return new ServletOutputStreamFilter(super.getOutputStream(), m);
}
}试验
将最开始的代码,搬到原生servlet写的接口中,进行验证。验证结果ok。