逛 GitHub 挖到宝了,这个叫 UltraRAG 的开源项目是首个基于 MCP 的检索增强生成(RAG)框架,不写代码也能玩转。
用 YAML 文件轻松构建复杂 RAG 系统。
RAG 系统:简单来说,就是让 AI 模型能先检索相关信息,再生成答案,从而提高准确性。

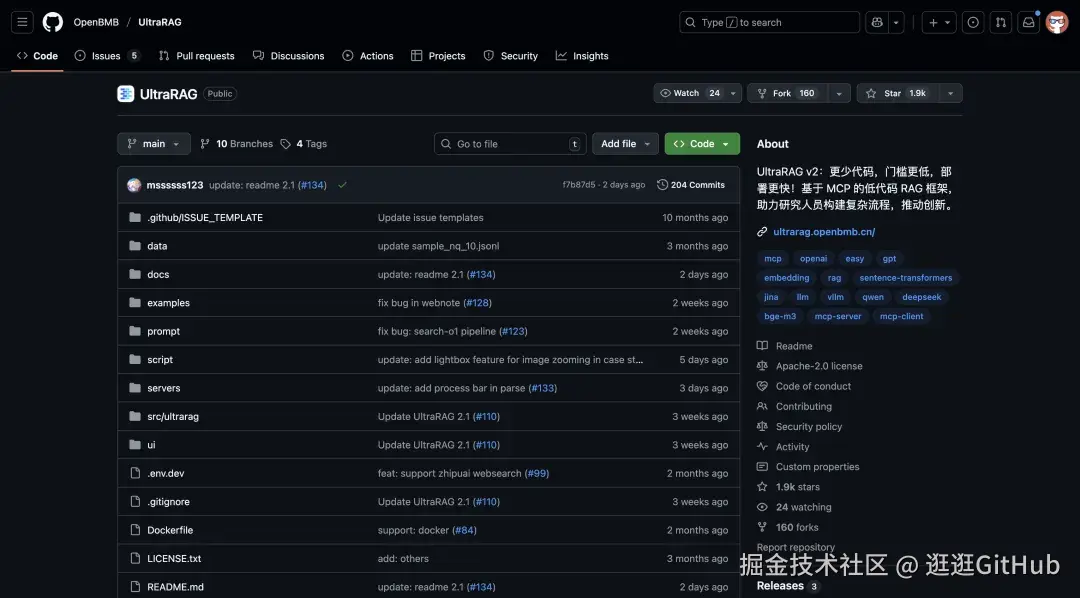
UltraRAG 是由清华 THUNLP、东北大学 NEUIR、OpenBMB 等多方联合推出的开源项目。
它能让你更容易构建和测试复杂的 RAG 系统。
01、开源项目简介
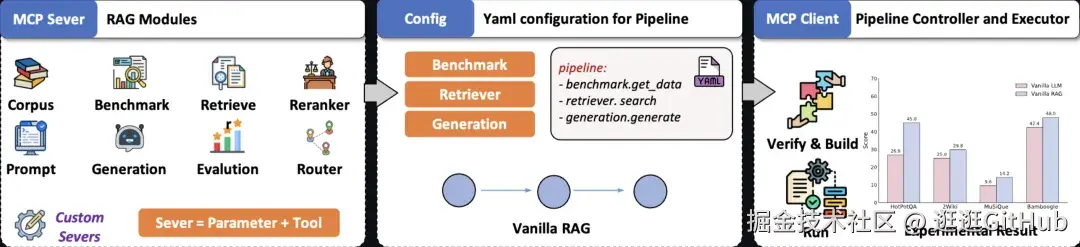
这个开源项目的核心思路是把 RAG 的核心组件封装为标准化的独立 MCP Server,提供函数级 Tool 接口支持灵活调用,借助 MCP 客户端建立简洁的链路搭建。这种设计让想使用 RAG 系统的人只需编写 YAML 配置文件,就能直接声明复杂逻辑,大大降低了技术门槛。
新版版本升级,最新的 2.1 版本主要围绕以下三大核心方向进行了全面升级:
① 原生多模态
统一框架支持文本、图像的检索与生成,新增 VisRAG Pipeline 实现 PDF 到多模态问答的闭环。
而且内置的多模态 Benchmark 覆盖视觉问答等任务,并提供统一的评估体系,方便研究者快速对比实验效果。
② 知识接入与语料构建自动化
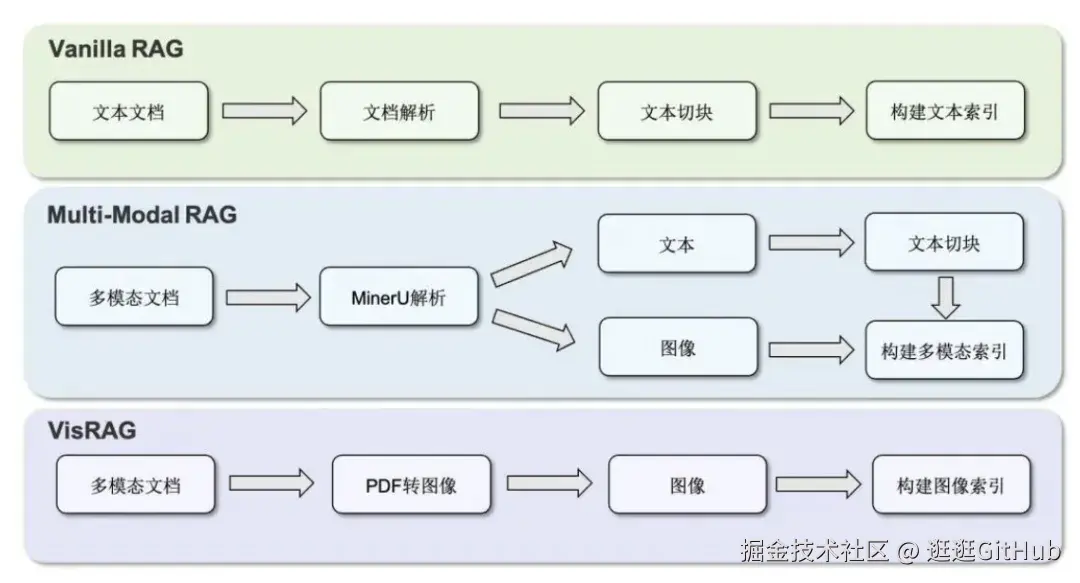
支持多格式文档,比如 Word、电子书、网页存档的自动解析与分块,不需要编写复杂脚本即可构建统一格式的知识库。
而且在 PDF 解析方面,它集成了 MinerU 工具,能高保真还原复杂版面与多栏结构,并支持将 PDF 按页转换为图像,保留视觉布局信息。
③ 统一工作流
通过 YAML 配置驱动检索、生成、评估全流程,支持多种引擎与可视化分析,提升实验复现效率。
开源项目链接和相关教程如下:
ruby
代码仓库:https://github.com/OpenBMB/UltraRAG教程文档:https://ultrarag.openbmb.cn/数据集:https://modelscope.cn/datasets/UltraRAG/UltraRAG_Benchmark02、实际效果
先来看看效果,基于这个开源项目搭建的 RAG 系统的真实示例。比如第一个 Case:基于论文《Attention is All You Need》咨询一个问题,论文中的表 4 具体说了什么,帮忙解释一下。
AI 可以直接解析表格内容,给出如下回答,还是挺清晰的。

这是因为刚刚升级的 2.0 可以统一处理文本和图像数据。上传的 PDF 文档,它不仅能读取文字,还能分析里面的图表和公式,实现真正的多模态检索和生成。这避免了以前需要切换不同工具的麻烦。
第二个 Case:基于麦肯锡的《生成式人工智能的经济潜力》报告。让 AI 基于里面的内容,输出生成式 AI 最有潜力的企业职能有哪些?请结合图表和正文说明它们在组织生产力中的影响。

03、如何使用
UltraRAG 支持两种部署方式,第一种是使用 Conda 创建虚拟环境:

另外一种部署方式是通过 Docker:
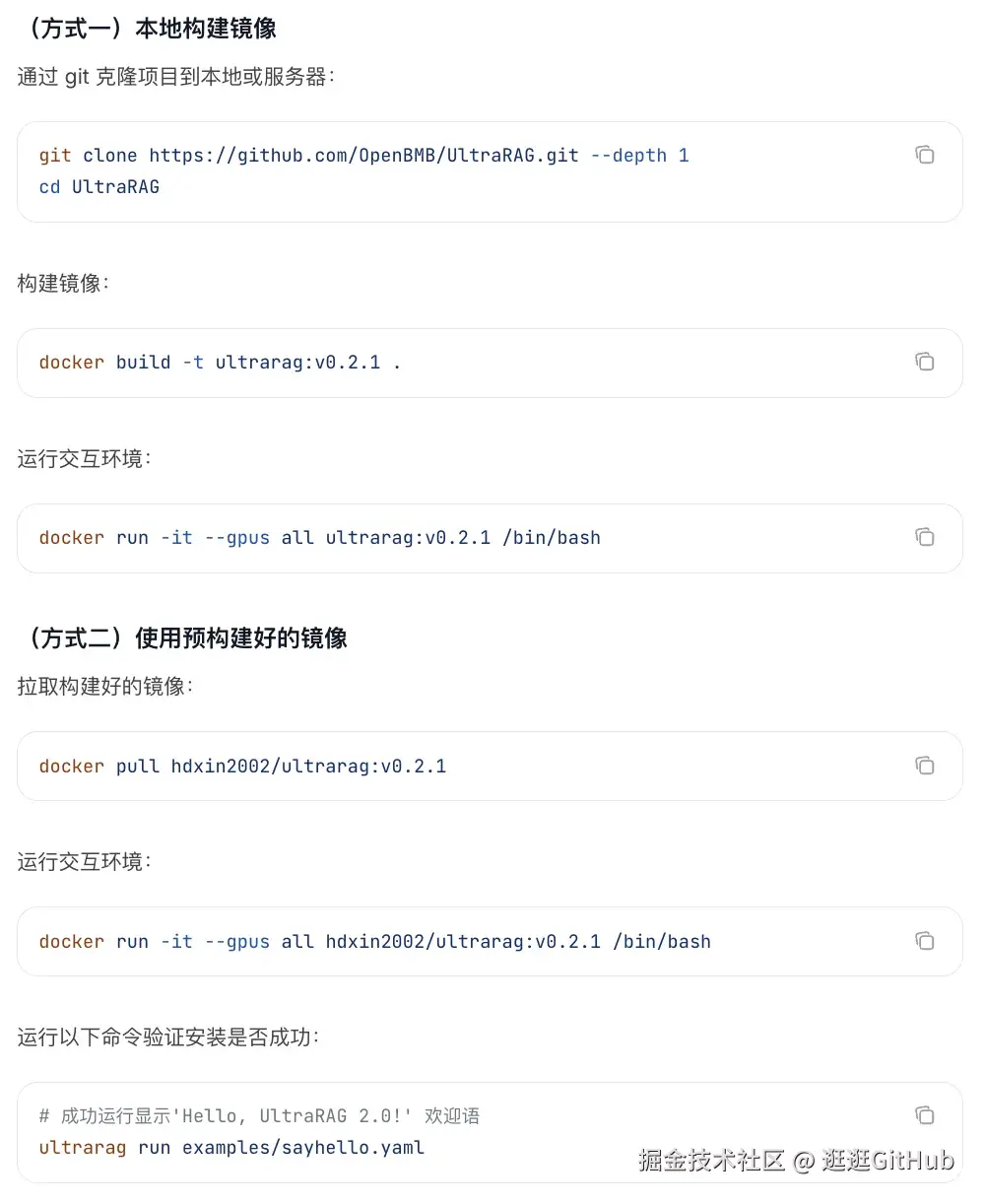 接下来就能可以基于 UltraRAG 运行一个完整的 RAG Pipeline 了。使用流程主要包括以下三个阶段:
接下来就能可以基于 UltraRAG 运行一个完整的 RAG Pipeline 了。使用流程主要包括以下三个阶段:
- 编写 Pipeline 配置文件
- 编译 Pipeline 并调整参数
- 运行 Pipeline
这里不详细展开,可以直接看下面这个文档,写的很详细。
ruby
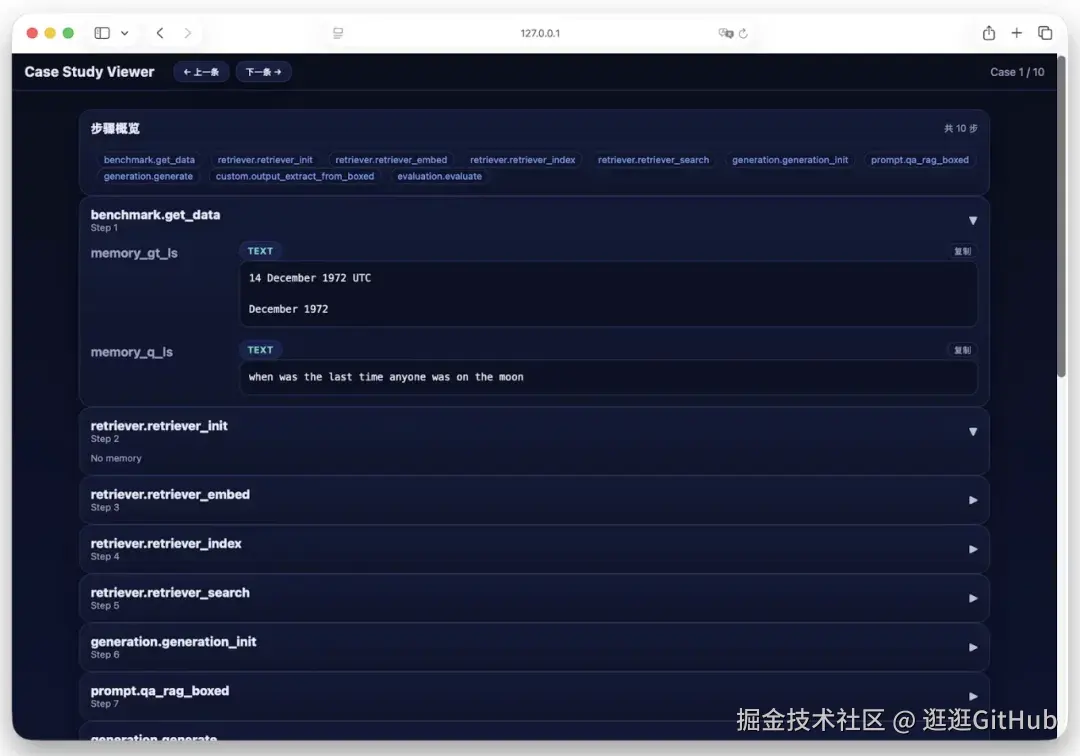
https://ultrarag.openbmb.cn/pages/cn/getting_started/quick_start你不需要写代码,配置一个 YMAL 文件就行了。而且开源项目内置了 Case Study Viewer 界面,可以对结果进行交互式浏览与分析。 就是下面这样的界面。