本文由体验技术团队成员原创。
1、大方向:合理规划产品演进形态,从+AI到AI+
从业界AI Coding产品看:
- Codium -> WindSurf Codeium成立于2021年,推出编程助手Codium(现Qodo);2024年11月,Exafunction Inc.(原Codeium)推出了Windsurf Editor,AI原生IDE,专注于通过智能协作和自动化提升软件开发效率。
- MarsCode -> Trae 2024年6月,字节跳动在北京发布了基于豆包大模型打造的智能开发工具- 豆包MarsCode,可以无缝集成到 IDEA、VSCode 中;2025年1月,字节发布了国内首个 AI 原生 IDE------Trae。Trae正式发布,初期仅支持macOS系统,2月17日Windows版本全量上线。
- Comate -> Comate IDE 2023年6月,百度推出代码助手Comate;2025年6月的百度Create AI开发者大会上,推出了独立的AI原生开发环境工具------Comate AI IDE1。
- Tongyilinma - > Tongyilinma IDE 2023年10 月阿里云正式发布的通义灵码智能编码助手;2025年10月,阿里云发布通义灵码AI IDE。
从业界数据分析Agent产品看:

合理的演进形态?
-
阶段1:+AI验证价值 在现有流程中嵌入AI能力,快速验证AI价值和用户接受度,并累计AI应用经验与数据
-
阶段2:AI+重构业务核心 重新设计核心业务流程,构建以AI为中心的产品架构,培养用户新的使用习惯
-
阶段3:原声AI全新体验 AI Native终极目标达成
2、怎么+AI?(如何寻找AI可切入的落地场景)
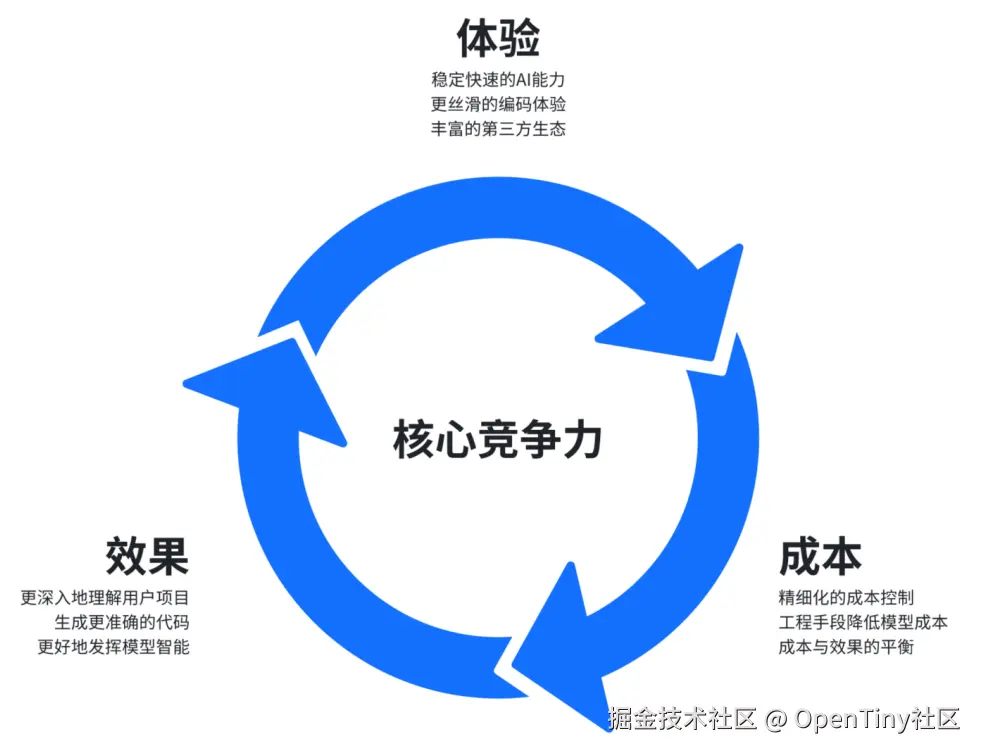
(1)敏锐洞察客户期望的演变趋势
重塑用户调研的繁琐过程
可以利用AI工具,来聚合所有来源的用户反馈、分析和挖掘数据,然后实时地将洞察直接推送到规划者。用户的期望变化得太快,如果流程不改进,遭遇"PMF丢失"的概率就会大大增加。
一些常见的期望演变:
从"给我一个创作的工具"到"直接帮我搞定" 从"提供标准版,我自己具体调整"到"为我量身打造一个方案"(主要是B2B) 从"手动操作"到"自动化操作"
- JIRA领域,创建任务、更新任务、长期梳理任务都需要时间
- CRM领域,销售代表需要花费大量时间来输入关于沟通和交易的数据)
从"按使用者数量/按月付费"到"按完成的工作量付费"
- 从lisence到生成的产品数量/节省的人力成本/...
(2)端到端的用户体验仍然重要
AI提高了单个环节的效率、同时也放大了不同环节间协作的价值
从企业服务看:回溯过去十年,企业服务的核心逻辑是模块化拼接,通过不同功能模块的组合满足企业需求,最佳单品才是主流。企业习惯用钉钉做协同、用用友管财务、用Salesforce搞CRM,再靠数据中台勉强去缝合。但随着AI技术走向成熟,这种逻辑逐渐失效。模块间数据因无法互通而形成信息孤岛,用户在多系统间切换导致体验割裂,第三方生态也难以深度整合。
- 钉钉AI助手 -> 钉钉One:阿里钉钉十周年发布会重磅推出"钉钉One",聚焦员工日常高频任务,实现智能化识别与自动化处理。
- YonSuite -> One YonSuite:八月中旬,用友旗下面向成长型企业的SaaS产品YonSuite发布全新品牌口号------One AI-World, One YonSuite,并宣告以AI原生+全球化的双轮驱动,重塑企业服务的底层逻辑。
是否掌握用户的"主要工作流"?上下游、端到端的生态很重要
用户关注的是诉求能否得到解决,并不在乎这是不是一个"AI功能"。因此,不同产品竞争优势未根本性变化, 应专注做好擅长领域, 利用AI快速补齐其余环节。
- 腾讯智能座舱的"花活",离不开小程序生态的支撑。
- Coze的战略价值,强化豆包大模型的产品化落地路径(通过COZE构建即调用豆包),形成上游→下游联动闭环,构建后可一键发布至抖音、飞书、懂车帝等诸多平台,形成"内容+AI+分发"的平台生态闭环。
- AI创作应用,比如编码开发环境、写作界面、设计画布等应用,如果产品位于这些创作界面的"下游"或外部,而不是用户完成核心工作的地方,就更容易被取代。AI可以直接整合到工作流中,成为一个更无缝的替代方案,而不是让用户离开他们的主要工作环境。
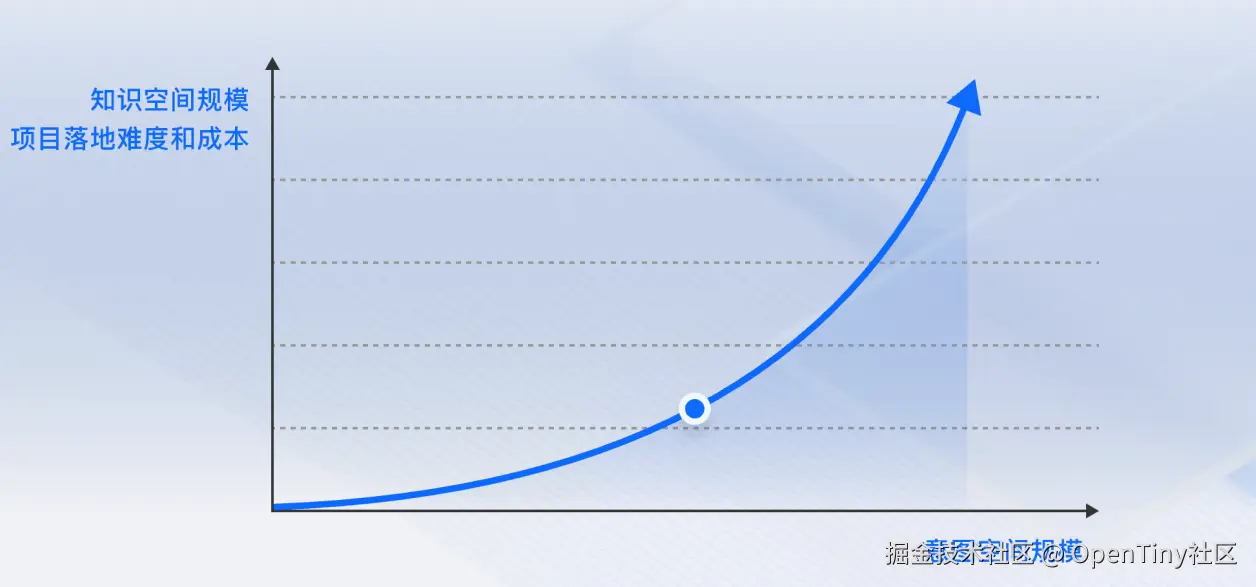
(3)合理评估技术成熟度、数据/知识完备度与产品功能边界,找到落地甜区
产品功能边界评估:
-
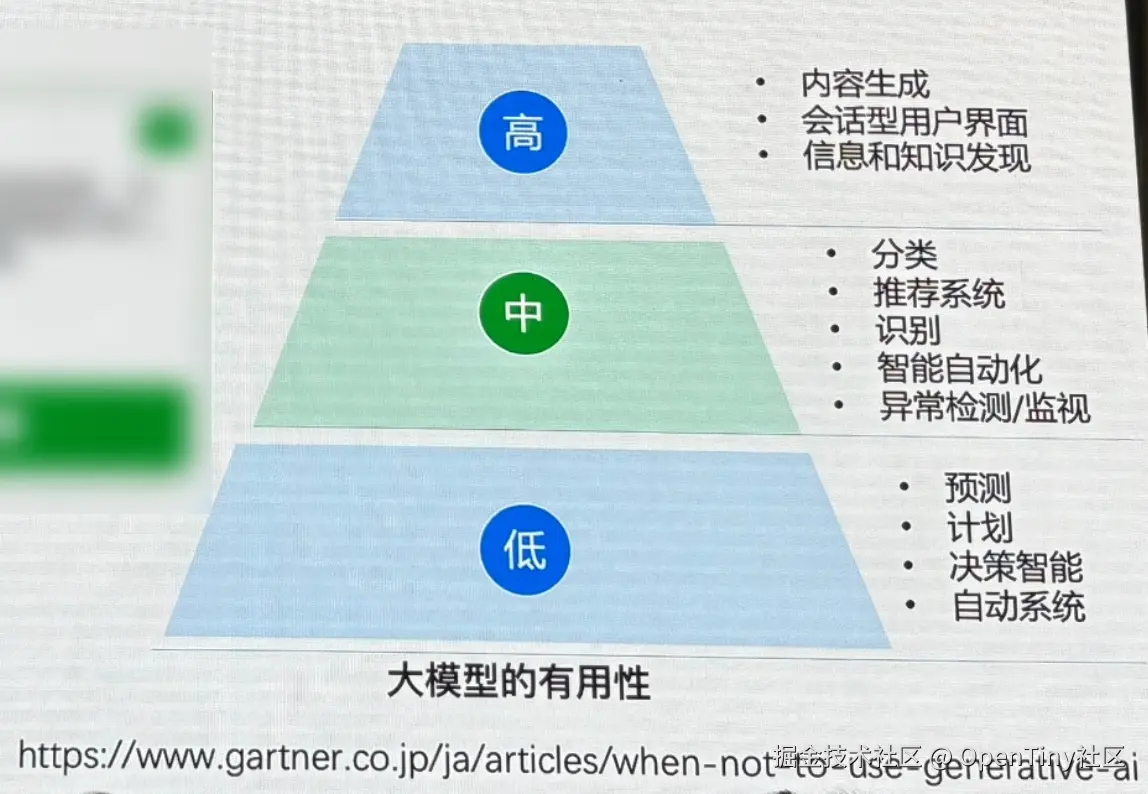
功能边界要"小":让AI在业务需要的地方做擅长的事 若对有用性低的领域进行导入,导入成本高,效果也很难达到预期,可能会导致项目失败。
-
功能边界要"大":比大模型升级主路径"多思考一步" AI 应用最大的危险是被大模型卷死,所以一定要避免在大模型升级的主路径上。否则就会变成一层包一层,Agent调Tool。
应避免将AI应用的主要功能定义为通用性高、附加价值低的任务、给大模型打补丁的任务。这些任务过于普遍和标准化,容易被大模型学习和模仿。例如,自动摘要提取、文本改写、文章生成、机器翻译、语言解释以及常规问题的回答等,在这类任务中,大模型的学习能力可以迅速复制并普及。很多创业公司尤其是 wrapper 类产品,本质就是在对大模型的这种输出的不稳定,不专业做修复,补偿,深加工和各类未来会成为大模型组件的大拼盘。
业务价值评估:
-
阿里云数字员工已扩展HC为结果目标:
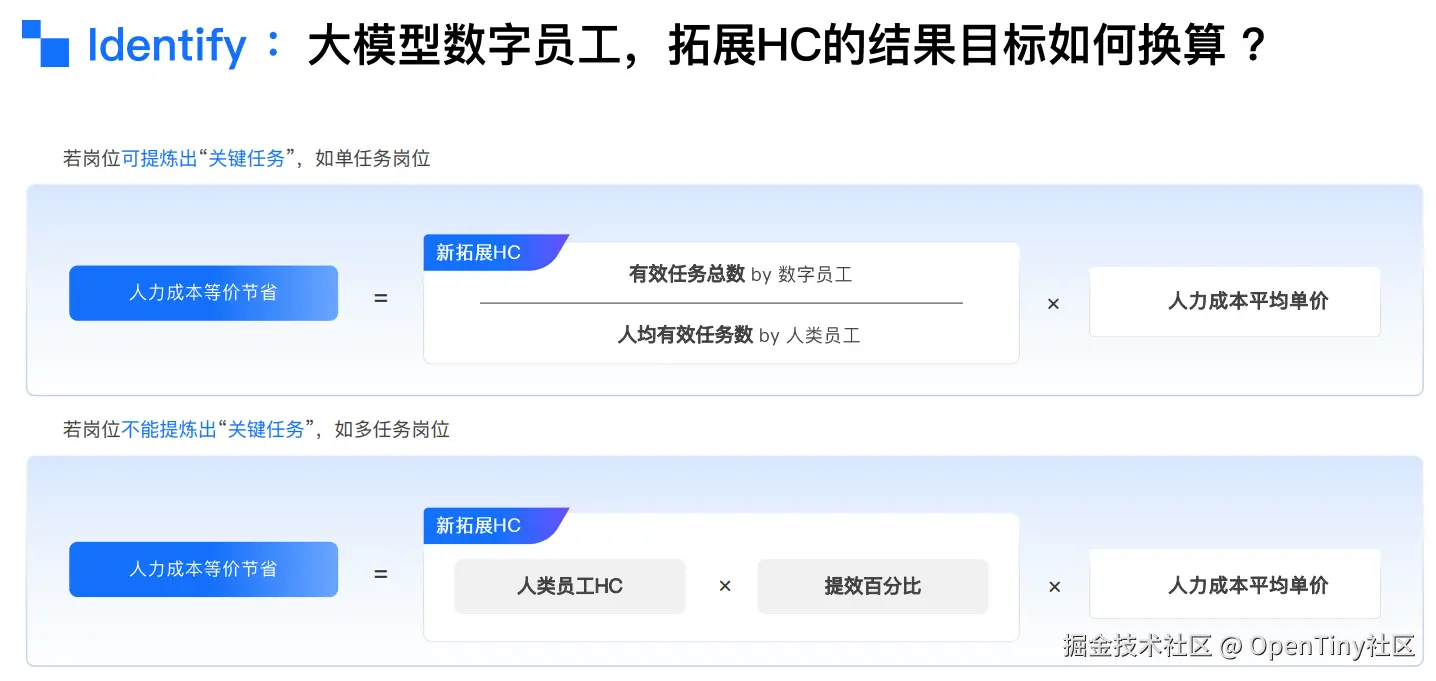
-
2D产品claude code新特性对外发布的标准:内部开发者为自己直接做出原型,在司内发布,内部反响是否好是对外发布的标准;内部反响一般则先迭代,等ready后再发布。
数据治理与知识工程: 需要进行持续的数据治理与知识工程建设,配套调整组织与生产关系,为AI应用打好"蛋糕胚"

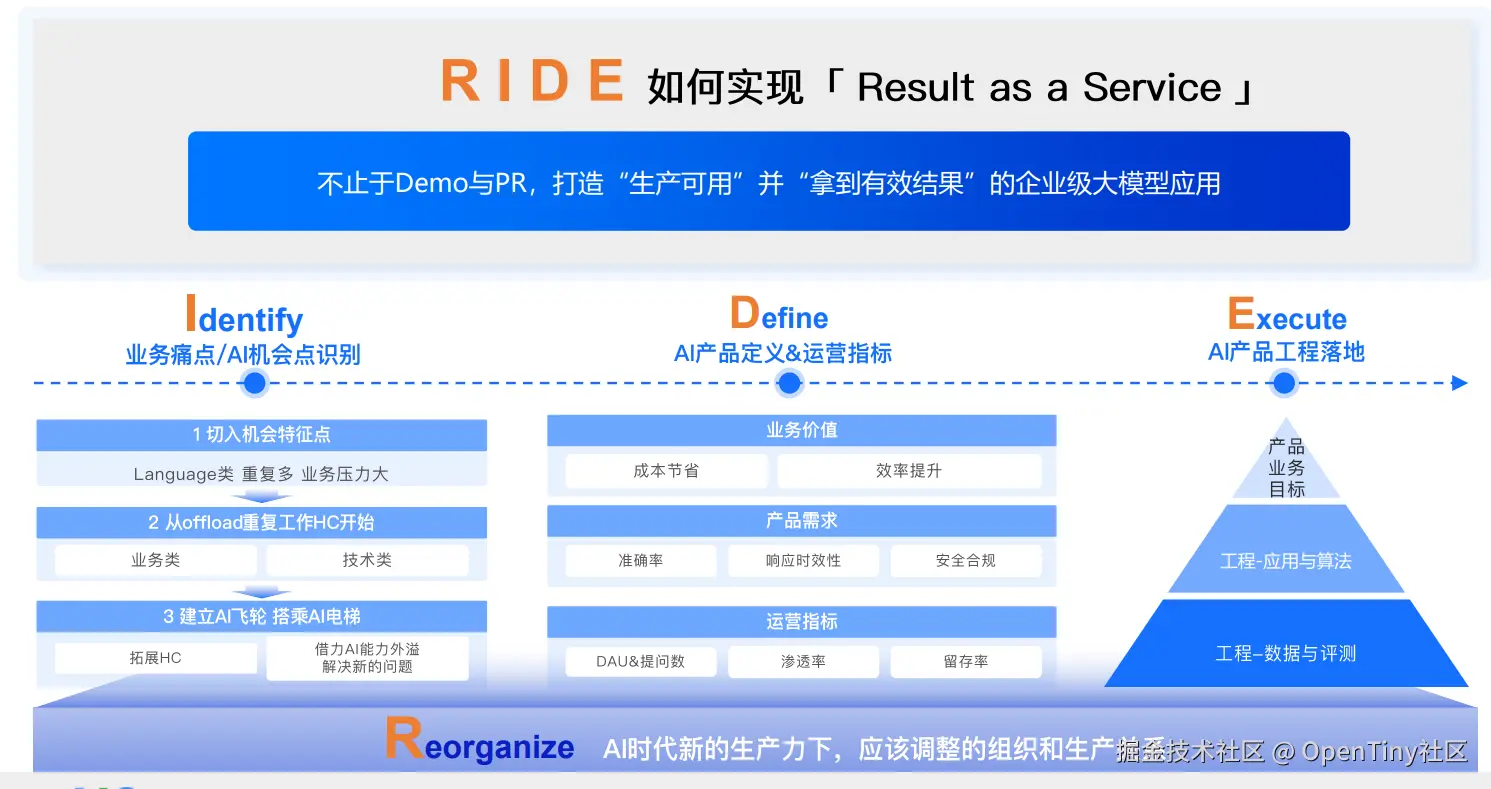
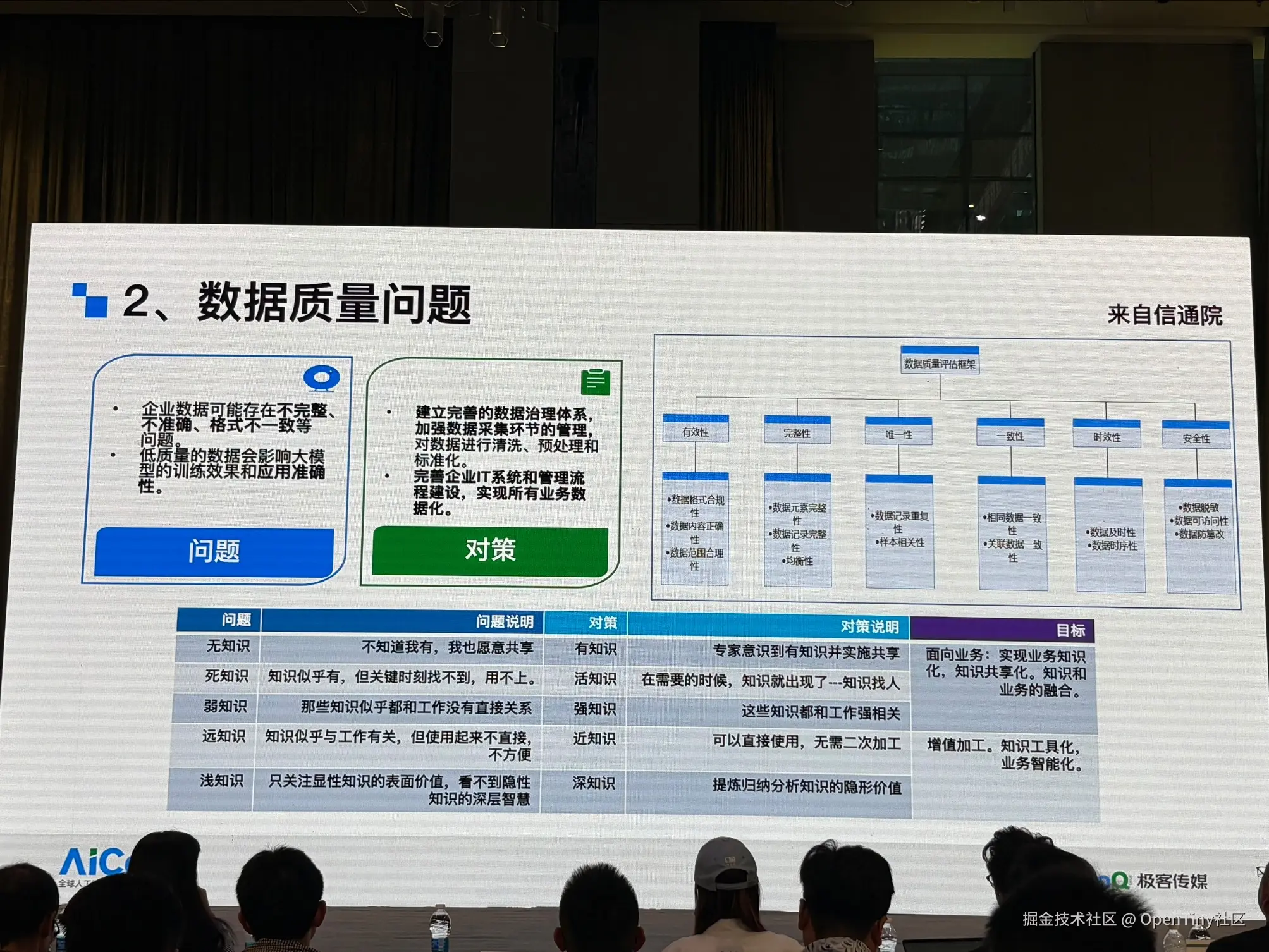
3、AI时代的PMF不仅是product market fit
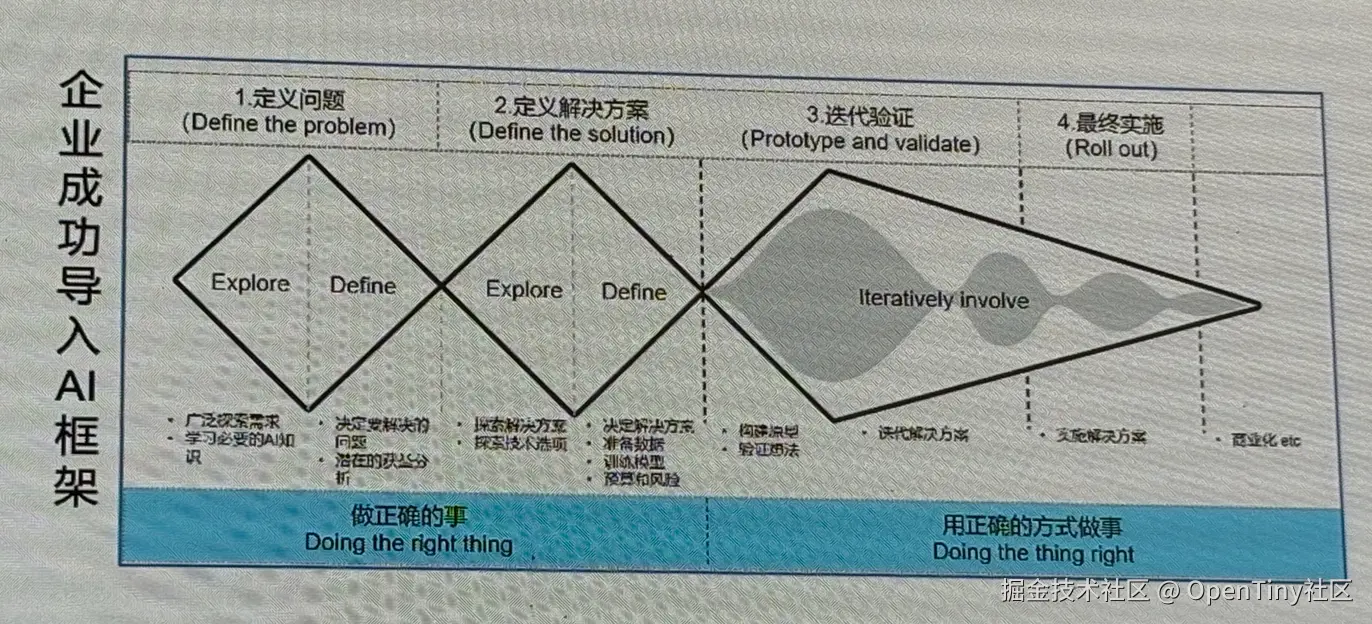
(1)以前,我们如何寻找PMF(产品市场契合度)
PMF(product market fit)指产品与市场需求达到匹配的一种状态,即产品能够很好地满足目标市场的需求,并且市场对该产品有强烈的需求和接受度。

通常,在寻找PMF时的一般路径是:
确定目标客户(未来产品的受众与未被满足的需求)→明确核心价值定位(有核心竞争力与一定壁垒)→明确产品MVP核心功能(团队与用户对产品的核心功能达成一致)→做出产品的模型并验证(目标客户使用MVP并密切互动、了解反馈,打磨体验)
传统互联网行业在评估 PMF 时,两个指标被认为是最关键的:
- 用户留存率:衡量用户在初次使用产品后的一定时间内,仍然继续使用产品的比例。移动互联网产品有个经典指标叫 421,次留 40%,周留 20%,月留 10%,满足这个表示基本达标。最重要的参数是长期留存,月留存率达到 30%或以上,表明产品具有很高的用户粘性。月留存率在 20%-30%之间,表明产品较为符合用户需求。月留存率在 10%-20%,可能需要进一步优化产品功能或用户体验。月留存率低于 10%,表明产品与用户需求存在较大偏差。
- 用户生命周期价值(LTV)与客户获取成本(CAC)之比:LTV/CAC 比率是衡量产品盈利潜力的关键指标。一个健康的 LTV/CAC 比率通常被认为是 3:1 或更高,这意味着用户在其整个生命周期内为公司带来的总收益至少是获取该用户成本的三倍。这个比率越高,表明产品的市场适应性和盈利能力越强。
(2)AI时代,寻找产品模型契合度(Produt Model Fit)同样重要
PMF强调在 AI 技术特性与产品功能之间找到匹配是成功的关键,即 AI 模型的技术特性与产品功能之间的契合度。
许多 AI 产品的 Demo 视频表现出色,但实际产品却难以满足市场预期,主要是因为实际能力与演示时相比有差距。因此,意味着需要深入理解技术的优势和局限性,能够识别技术适合解决哪些类型的问题,以及技术如何与用户需求相结合,从而设计出比传统应用好 10 倍的用户体验。产品团队需要深入理解 AI 模型的能力边界,利用模型的强项并规避弱点,同时对模型的技术演进方向有前瞻性的预判。成功的 AI 产品应基于对模型能力和市场需求的深刻理解,做出明智的取舍,而不是追求满足市场所有需求的完美产品。
(3)如何量化衡量AI时代的产品是否满足了PMF?
一般的产品路径:吸引客户 -> 留住客户 -> 赚到钱 -> scaling -> 守得住
是否切中用户真实需求?
是否切中用户真实需求,包括吸引和留住客户。这个要沿用活跃度指标,这个指标能反应MFP/TPF,因为否则的话,不可能吸引并留住用户。付费
是否拥有专有数据与知识?
在AI时代,数据才是真正的"新石油",尤其是那些大型语言模型无法获取的专有数据。如果数据(或内容)是公开的,可轻易被大型语言模型获取和处理。专有数据越多,护城河就越深。
能否在商业上闭环?
每一笔帐能算的过来(token的成本,数据成本,渠道,试错,迭代等等),且要能高效的回款,因为在早期还无法判断和计算用户life-time的时候,LTV/CAC的公式会显得过于长远。
长期包括能否赚到钱和scaling,看ROI或者LTV/CAC。
能否不被颠覆?
在移动互联网时代,技术基础设施相对稳定,产品和客户的匹配之后,产品被颠覆的风险很小。在AI时代这个前提不一定成立。做半天,用户反馈也不错,但是可能大模型一更新,就没有意义了。所以,需要一个指标表示对大模型safe程度,这个要求提供的服务远离大模型的演进主线,同时要在业务主流程中积累自己的私有数据闭环。 这个指标至少是这两个参数的函数,如 F(主航道偏离度,私有数据积累度)。
所以,AI时代的PMF至少要额外添加一个指数表示不被颠覆的程度,由两个参数驱动:主航道偏离度,私有数据积累度。
本文是由体验技术团队同学参与AICon后沉淀的技术思考及总结
关于OpenTiny
欢迎加入 OpenTiny 开源社区。添加微信小助手:opentiny-official 一起参与交流前端技术~
OpenTiny 官网:opentiny.design
OpenTiny 代码仓库:github.com/opentiny
TinyVue 源码:github.com/opentiny/ti...
TinyEngine 源码: github.com/opentiny/ti...
欢迎进入代码仓库 Star🌟TinyEngine、TinyVue、TinyNG、TinyCLI、TinyEditor~ 如果你也想要共建,可以进入代码仓库,找到 good first issue 标签,一起参与开源贡献~