文章目录
- [1. 为什么关注"数据空间"?](#1. 为什么关注“数据空间”?)
- [2. 华为的总体思路(研究方向汇总)](#2. 华为的总体思路(研究方向汇总))
- [3. 关键能力分解与华为的技术实现(工程视角)](#3. 关键能力分解与华为的技术实现(工程视角))
- [4. 代表性实践与场景(行业落地)](#4. 代表性实践与场景(行业落地))
- [5. 华为经验的工程性总结(对工程团队的建议)](#5. 华为经验的工程性总结(对工程团队的建议))
- [6. 把"数据空间"作为工程化产品来做](#6. 把“数据空间”作为工程化产品来做)
- 7.《华为数据之道》书籍推荐
-
- [7.1 内容简介](#7.1 内容简介)
- [7.2 作者简介](#7.2 作者简介)
1. 为什么关注"数据空间"?
"数据空间"在工程实践中,通常被理解为:跨组织/跨域的数据治理、共享、目录化与计算能力的组合------它既包含物理层的存储与计算资源,也包含元数据、数据资产目录、权限与合规模型、以及能将数据转化为线上可复用能力(API、服务、知识图谱、模型输入输出)的上层能力。要把数据变成企业乃至产业级的可复用资产,既要有可靠的底座 ,也要有严格的治理与敏捷的数据服务化流程 。
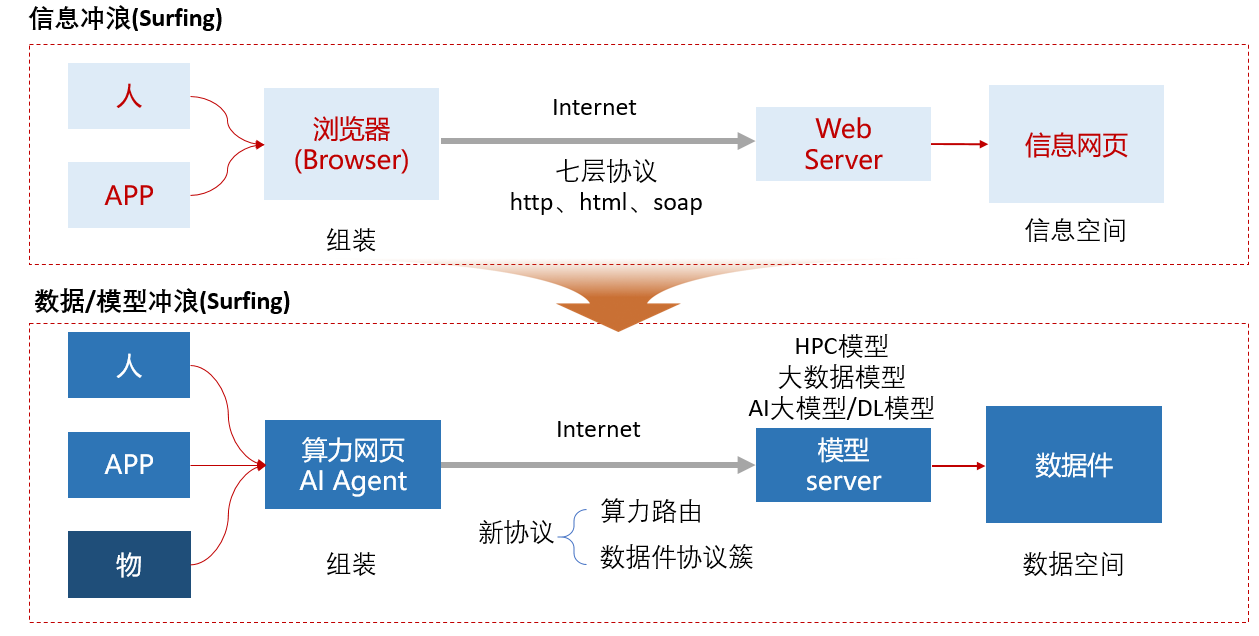
2. 华为的总体思路(研究方向汇总)
华为在近几年围绕"数据空间 / 数据基础设施"形成了相对系统的产品线与理论输出,主要可以分为以下几个方向:
-
AI-Ready 数据存储与加速:面向大规模训练与高并发推理场景对存储系统提出的延迟、带宽与元数据管理要求(例如 OceanStor、All-Flash、Scale-Out 解决方案)。这些产出体现为白皮书与产品化的存储系统演进路线。(Huawei Enterprise1)
-
分布式数据库与数据服务(GaussDB):把关系型/混合负载和分布式伸缩能力结合起来,增强 HTAP/OLTP/OLAP 混合场景下的数据处理能力与可用性。GaussDB 还强调智能运维与索引/分布式优化建议,降低运维成本。(华为云2)
-
数据织物 / Data Platform(DataArts / DME / eDataMate):围绕数据集成、元数据管理、血缘、质量、知识生成(例如把数据生成知识/向量/知识图谱的工具链 eDataMate)构建的一整套能力,使数据在企业内"可发现、可治理、可被模型/应用调用"。(华为云支持中心3)
-
数据安全与合规工程化(云与本地):强调全生命周期的数据安全控制(加密、秘钥管理、访问控制、跨境与合规策略),并发布了面向企业场景的白皮书与实践框架。(res-static.hc-cdn.cn4)
-
下一代数据中心与边云协同:把数据中心、模块化边缘机房等作为数据空间的物理承载,强调面向 AI 的数据流通、延迟与能效优化。华为在 Data Center 2030、Next-Gen Data Center 的报告中提出了相应的参考架构与能力指标。(Huawei Enterprise5)
3. 关键能力分解与华为的技术实现(工程视角)
下面把"数据空间"的关键能力逐项拆开,并指出华为在每一项的代表性研究或产品路径,以及工程实现要点与局限。
- 可用且可扩展的存储(AI-Ready)
华为把"存储"从传统的 IOPS/容量问题,延伸为"AI 训练数据的可用性、数据加速引擎与智能分层"。实践要点:
- 采用全闪/分层存储与数据感知的压缩与去重策略,降低训练数据的 I/O 瓶颈。(Huawei Enterprise1)
- 对大规模数据集提供全球命名空间或对象网关,减少数据复制成本(智能分发/缓存策略)。
工程启示:存储设计必须与上层训练框架紧耦合(数据预取、并行读取、热点感知),否则再好的硬件也难以提升训练效率。
- 分布式数据库作"交易+分析"混合引擎(GaussDB)
华为通过 GaussDB 提供分布式关系型能力,强调高可用、可扩展与智能运维:
- 自动索引建议、分布列建议与根因分析,降低 DBA 的工作量。(华为云2)
- HTAP/混合负载支持,适合线上业务同时需要分析能力的场景。
工程启示:选择数据库时要评估两类成本:一是实时性/一致性诉求,二是与数据平台(数据湖/仓/知识链路)的集成成本。
- 数据织物与数据平台(DataArts / DME / eDataMate)
华为的数据平台体系试图覆盖从数据接入、元数据、血缘、质量到知识生成的完整链路:
- DataArts 提供可视化的元数据管理、血缘追踪、权限控制模块;DME(Data Management Engine)用于存储与数据管理编排。(华为云支持中心3)
- eDataMate 之类的知识生成工具链把结构化/非结构化数据转成向量/知识图谱,支持下游大模型或检索式生成。
工程启示:落地时要先从"数据域/业务域"切分入手(domain-driven data),先做小范围的治理闭环再扩展全局。
- 数据安全与合规(工程化)
华为将数据安全视为构建数据空间的前提,推出从密钥管理到跨境合规的白皮书与工程实践:
- 全生命周期的数据保护框架:采集、传输、存储、使用、流通、销毁的管控。(res-static.hc-cdn.cn4)
工程启示:治理策略需嵌入到数据路径中(数据目录、访问 API、审计链路),否则合规只是文档而非可执行机制。
- 边缘/模块化数据中心与能效优化
华为在数据中心产品线(模块化机房、UPS、数字能源)与 Data Center 2030 报告中强调数据中心对未来数据空间的承载角色,特别是边缘场景的数据就近处理与低延迟保障。(Huawei Enterprise5)
4. 代表性实践与场景(行业落地)
-
AI训练平台与数据湖结合:在若干行业(金融、电信、制造)华为提出的"AI 数据湖 + 存储 + DME"组合,用于把标注、预处理、训练数据资产化,从而提升模型迭代效率。华为的案例与产品文档中对"AI-ready 存储 + 一站式知识生成链"有详述。(FutureCFO6)
-
面向企业的数据治理工程:基于 DataArts 的元数据与血缘管理,帮助企业实现数据的可发现、质量监控与权限控制,满足内外部合规要求。(华为云支持中心3)
-
混合云数据库与迁移实践:通过 GaussDB 与云上数据服务,支持企业将传统单体数据库迁移到分布式/云原生架构,兼顾可用性与可扩展性。(华为云2)
5. 华为经验的工程性总结(对工程团队的建议)
基于华为的研究路线与实践案例,结合工程落地的通用教训,给出若干可执行建议:
-
先治理后共享(分阶段):从最核心的 1--2 个数据域起步(如用户、订单),构建元数据与血缘、质量规则,形成可复用模板,再纵向扩展到更多域。
-
把存储与计算设计为"自适应"的数据路径:针对训练/推理/分析分别设计热/冷/归档分层,并实现数据预取与缓存策略,避免"全部搬到一个湖里"导致的性能退化。华为在 OceanStor 与 A系列存储中就强调了对 AI 场景的优化。(Huawei Enterprise1)
-
自动化的运维与智能建议要落地:采用数据库/平台的智能诊断、索引建议等能力(GaussDB 的实践表明能显著降低运维成本),同时保留人工可控的回退机制。(华为云2)
-
可审计的安全与合规机制必须从设计期纳入:将加密、密钥管理、权限审计作为数据 API 层的基础能力,确保每一步数据访问都有审计链路(华为数据安全白皮书给出框架性建议)。(res-static.hc-cdn.cn4)
-
边缘与中心协同:分层架构更现实:数据不必全部集中到中心,能就近处理就近处理(边/近边做预处理,中心做训练/长期存储),既降低网络成本也减少延迟。华为在其 Data Center 与模块化边缘机房方案中提出了相关思路。(Huawei Enterprise5)
- 跨组织互信与数据流通机制:产业级数据空间(例如多个企业共享的行业数据空间)在信任、支付/计费与隐私计算层仍需更多标准与工程化工具支持。
- 知识生成与数据质量的自动化:如何把原始数据高质量地转成可被大模型利用的向量/知识图谱,依然是工程难点(需要更好的标注自动化、数据描述与语义对齐工具)。华为的 eDataMate/知识链路是方向性的实践,但通用性/可解释性仍需加强。(FutureCFO6)
- 长期运维成本与能效约束:在海量数据规模下,存储/压缩/冷归档策略与能效优化是持续的工程挑战。华为关于 Data Storage 2030 的研究/白皮书提出了长期演进方向。(huawei7)
6. 把"数据空间"作为工程化产品来做
华为在数据空间相关的研究与产品链条(存储、数据库、数据平台、治理、安全、机房/边缘)上已经形成了较为完整的技术与产品体系,并且通过白皮书、产品化解决方案将理论与工程实践连接起来(可以看到在存储、GaussDB、DataArts、DME 以及数据安全白皮书上的系统化输出)。对企业来说,重要的不是照搬某个厂商的技术,而是学会把数据能力分解成可交付的工程模块(存储/数据库/元数据/质量/知识生成/安全),按价值优先顺序逐步交付并形成闭环。
7.《华为数据之道》书籍推荐
适读人群 :适合数据及相关领域的所有从业者阅读
(1)华为公司经验总结:华为公司从事数据空间相关研究和实践近8年,本书系统梳理和总结华为在数据空间领域的研究成果与实践经验。
(2)融合国内外经验:华为积极参与国际数据空间协会等国际组织的生态共建与标准制定,并与欧洲的相关科研机构合作,汇聚全球数据空间领域先进方法与经验。
(3)华为CIO陶景文作序:华为公司董事、质量与流程IT总裁、CIO陶景文对本书高度评价并作序推荐。
(4)内容系统、实战、前瞻:全书提供一套完整的数据空间知识体系、一套可落地的企业实践方法、一套面向未来的前瞻性思考。

7.1 内容简介
这是一部系统梳理和总结华为在数据空间领域的研究成果与实践经验的著作,全面讲解了如何构建可信、可控、可证的数据流通体系,旨在为跨主体、跨边界数据共享这一难题提供完整的解决方案。
华为致力于数据空间理论与架构的研究近8年,积极参与国际数据空间协会(IDSA)、
Gaia-X 等国际组织的生态共建与标准制定,并与欧洲的相关科研机构在研究项目上开展了大量的合作。华为成功研发了自己的数据空间服务产品EDS(交换数据空间),并在鲲鹏昇腾生态率先得到验证,如今已经在华为内部的4大类20多个场景和外部的大量客户中得到广泛应用。在此基础上,华为将自己在数据空间理论框架、工程实践、落地原则等方面的认知、经验、教训凝结成了这本书。
本书将为您揭示数据流通的破局之道,从理论到实践、从架构到落地,全面解析数据空间这一创新方案。阅读本书,您将收获:
(1)一套完整的数据空间知识体系: 全书共11章,系统覆盖了数据流通的时代背景与世界性难题、欧洲数据空间的新实践、数据空间的4大设计原则和五层三维参考架构、数据连接器的6大关键能力,以及如何构建"可信、可控、可证"的数据流通保障机制。
(2)一套可落地的企业实践方法: 详细阐述了企业在部署和运营数据空间时需要解答的3个关键问题(谁来用、谁来管、怎么用),并提供了4大类企业应用场景的实操指南,涵盖企业内部、集团内、产业链上下游以及与外部组织间的数据交换模式。
(3)一套面向未来的前瞻性思考: 深入探讨了在AI大模型时代,数据空间如何应对数据流通的新挑战,以及如何支撑AI场景下的数据可控利用,展望了数据空间成为未来国家数据要素流通基础设施的宏伟蓝图。
本书将为您的数据战略规划和数字化转型实践提供极具价值的参考与指引,帮助您在数据浪潮中占得先机。

7.2 作者简介
马运(MA YUN),华为公司数据总架构师、数据首席专家、信息架构专家委员会主任、数据管理教研室主任。
2015年至2022年期间,在华为公司担任数据管理部部长、质量与流程IT首席数据官,负责公司信息架构、数据底座和数据治理体系建设,主持公司数据资产管理、元数据驱动产品信息管理、主权可控数据交换等变革项目,深度参与数字化转型工作。畅销书《华为数据之道》第一作者,《华为数字化转型之道》主要作者。
曾在瑞典爱立信总部工作多年,担任产品线业务总监、集团信息管理部总监。曾任北京交通大学副教授、统计教研室主任、经济系主任,在瑞典国家公路与运输研究院任客座研究员。
当前研究领域:企业AI数据管理、AI+区块链、数据要素价值量化。