转转UI自动化走查方案探索
前言
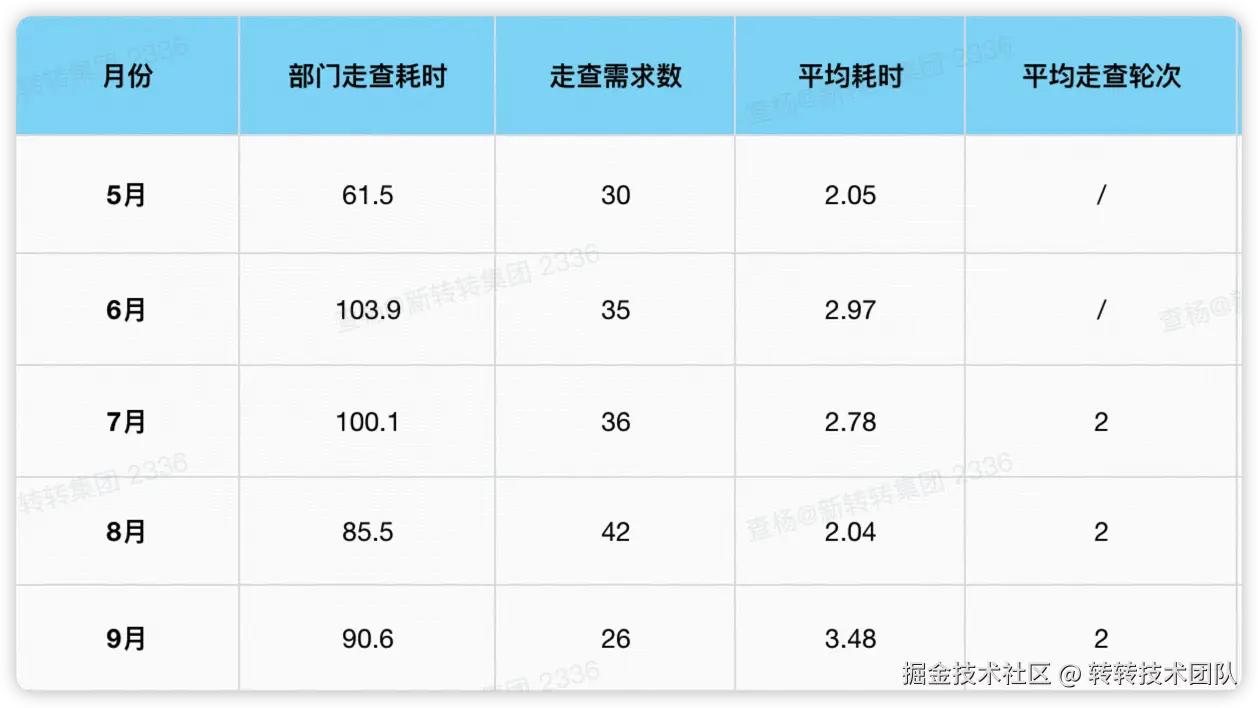
UI走查是现在转转C端需求开发流程中相当重要的一环,然而UI走查这一环节难以接入自动化流程中,导致其没有如同测试环节一样的冒烟环节(又称测试准入),因此实际走查阶段时,前端的UI交付质量难以在流程上做硬性管控,UI还原度参差不齐,这也就进一步导致了UI走查效率难以把控。经UI侧同学的不完全统计,2025年5-8月期间,共走查需求20个,总耗时33h,平均单个需求耗时1.6h,在需求规模较大的情况下,走查耗时最高时可达3-4小时,走查轮次3次,异常数量30-50个不等,而走查本身耗时并不高,而大部分的时间都耗费在对UI异常问题的标注上。因此,开发一种自动化比对UI设计稿与HTML结构,自动化标注比对结果的工具,能在根本上提升UI还原度,提升UI走查效率。
方案的调研与选择
叠图比对方案
目前现存的大多数UI走查方案走的都是比对UI设计稿与前端页面截图的方案,此方案虽通用性高,但是结果难以量化,难以与标准化研发流程结合,在前言中我们也说明了,走查的耗时成本在与异常数据的标注,而非获取比对结果。因此这种方案显然无法达成目的
像素比对方案
像素级的比对方案与叠图比对方案的原理相似,在实现上,叠图方案需要开发者主动判断结果,而像素比对方案则是通过类似于opencv之类的图像处理工具配合类似于scikit-image之类的结构相似度算法进行实现。这种方案虽然能拿到量化的比对数据,以及自动化标注,但是在双方图片的相似度上要求较高,设计稿与UI在文案上有一定的区别都能造成比对的误差,且误差不可控。如果进一步的考虑通过微调、自训练ai模型的方案,则训练、标注的成本也相当高。因此改方案也并非最佳的选择。

基于前端与UI节点的比对方案
在现在流行的一些前端化UI设计工具(例如Figma、Master Go)中,UI设计稿在底层其实是一个大型的带有嵌套关系的JSON数据结构,而前端的Dom树也是一个带有嵌套关系的数据结构。基于这两点,很容易就想到如果能将双方的节点数据归一化处理成相同的数据结构,那么在节点间间距的精确匹配与比对上,或许会有不错的效果。
数据结构设计
既然要归一化处理数据,那么首先需要考虑的就是这个数据结构需要什么。
在上文提到的UI走查情况统计数据中,UI走查出现的问题中,间距问题占比约95% ,字体相关问题约占3%,其余诸如背景色、边框等问题占比共2%,因此在方案前期,首要需要解决的问题就是间距问题。
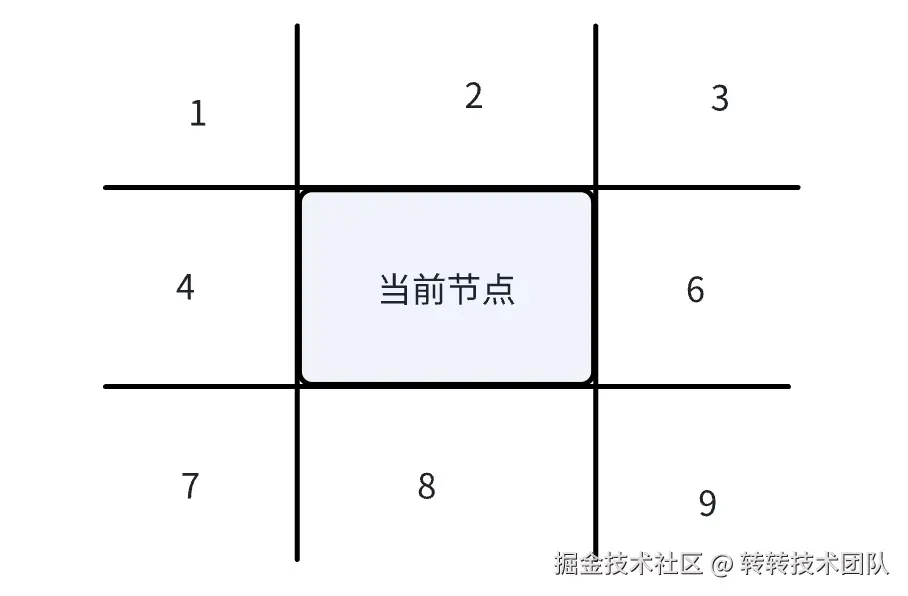
要检测出间距问题,首先需要找到当前节点的相邻节点,于是我们对相邻节点做出如下定义。
-
定义当前节点A与另一个节点B之间总共有9种环绕关系,按从左到右从上到下编号分别即为1-9号位置。
-
2、4、6、8号位置中,与当前节点的距离最小的节点,即为当前节点的四个方位的相邻节点
-
所谓上下左右的间距,即为当前节点与各方位上的相邻节点的间距。
typescript/** 相对于当前节点的兄弟节点位置枚举 */ export enum SiblingPosition { /** 不在任何位置 */ NONE = 0, /** 左上角 */ TOP_LEFT = 1, /** 正上方 */ TOP = 2, /** 右上角 */ TOP_RIGHT = 3, /** 左侧 */ LEFT = 4, /** 右侧 */ RIGHT = 6, /** 左下角 */ BOTTOM_LEFT = 7, /** 正下方 */ BOTTOM = 8, /** 右下角 */ BOTTOM_RIGHT = 9, } /** 节点的唯一ID标识符 */ type UniqueId = string /** 只记录2 4 6 8 四个方向的兄弟节点信息 */ type SiblingRelativeNodeInfo = Partial<Record<SiblingPosition, UniqueId>>
除此之外,我们还需要该节点的boundingRect、padding、margin、border、font相关的信息,最终设计了如下的数据结构
typescript
/** 节点信息 */
export interface NodeInfo extends SiblingRelativeNodeInfo {
/** 父节点 id */
parentId: UniqueId
/** 子节点 id */
children: UniqueId[]
/** 兄弟节点 id */
sibling: UniqueId[]
uniqueId: UniqueId
nodeName: string
/** 节点边界 */
boundingRect: BoundingRect
/** padding信息 */
paddingInfo: PaddingInfo
/** border信息 */
borderInfo: BorderInfo
/** 背景色 */
backgroundColor: string
/** 标签名称(设计稿则为节点类型) */
tagName?: string | SceneNode['type']
/** 文本样式信息, 只有内部是文本的节点才有这个字段 */
textStyleInfo?: TextStyleInfo
/** 节点的中心信息 @description DOM ONLY */
nodeFlexInfo?: NodeFlexInfo
/** 相邻节点的边距 */
neighborMarginInfo: Partial<Record<SiblingPosition, NeighborMarginInfo>>
}数据归一化处理流程
Dom侧数据处理与UI侧数据处理逻辑基本一致,上图为整个Dom结构数据处理流程,下面将对该流程中比较核心的部分进行讲解。
processLargeLineHeight处理行高问题
处理行高问题,旨在抹平前端侧与UI侧在相同渲染效果下,因为设置了不同的行高导致节点高度不同造成的异常。行高数据的归一化处理依赖于节点内部的textStyleInfo,其结构如下
typescript
export interface TextStyleInfo {
/** 行高 */
lineHeight: number
/** 文本宽度 */
textWidth: number
/** 字体大小 */
fontSize: number
/** 字体粗细 */
fontWeight: number
/** 字体 */
fontFamily: string
/** 文本行数 */
textLineCount: number
/** 文本对齐方向 */
textAlignment: TextAlignment
/** 文本内容 */
textContent: string
/** master go的文本节点的宽高策略 */
textAutoResize?: TextNode['textAutoResize']
}其核心逻辑如下:
- 创建测量容器
typescript
const measureElement = document.createElement('div')
measureElement.style.position = 'absolute'
measureElement.style.visibility = 'hidden'- 克隆关键样式
复制影响文本布局的所有样式到测量元素:
- 字体样式 :
fontSize,fontFamily,fontWeight - 排版 :
lineHeight,whiteSpace,wordBreak,textTransform - 约束 :
width(使用原节点宽度) - 清零 :
padding,margin,border(避免干扰)
- 首次测量(多行场景)
typescript
measureElement.style.width = `${domNode.getBoundingClientRect().width}px`
document.body.appendChild(measureElement)
const measureHeight = measureElementRect.height- 设置固定宽度(与原节点一致)
- 测量文本在此宽度约束下的实际高度
- 计算行数
typescript
const shouldUseOriginHeight = !isInline && originHeight < measureHeight
const textHeight = shouldUseOriginHeight ? originHeight : measureHeight
const lineCount = Math.max(1, Math.round(textHeight / lineHeightValue))关键逻辑:
- 如果原节点是 block 且设置了固定高度,且该高度小于测量高度
- 说明文本被裁剪了(如
height: 50px但文本实际需要 100px) - 使用原始高度计算行数(因为实际显示的就是被裁剪的部分)
- 说明文本被裁剪了(如
- 否则使用测量高度
行数 = 文本高度 / 行高
- 单行特殊处理
typescript
if (lineCount > 1) {
return baseTextStyle
}
// 单行场景,重新计算宽度
measureElement.style.width = 'auto'
document.body.appendChild(measureElement)
const measureElementRect2 = measureElement.getBoundingClientRect()单行重新测量,根本上是为了确定单行文本的场景下实际占用的最小宽度。
在获取了textStyleInfo之后,就可以进行行高的归一化处理了。
- Inline 节点特殊处理
typescript
if (isInlineNode && !!parentNodeInfo) {
nodeInfo.boundingRect.y = parentNodeInfo.boundingRect.y
nodeInfo.boundingRect.height = parentNodeInfo.boundingRect.height
return
}inline节点的处理是一个大坑,在MasterGo的渲染器中,文字始终是在TextNode中居中处理的,但是在前端文本中,文本是以baseline为基准对齐的,文字在lnlineNode中的居中方式,取决于字体本身的设置,而非始终居中渲染。因此此套逻辑只能在非行内元素中使用,而行内元素的宽高则始终与父节点保持一致。
- 单行文本行高大于字体大小的场景处理
typescript
const realHeight = boundingRect.height - paddingBottom - paddingTop
if (textLineCount > 1 || fontSize === realHeight) {
return
}
const deltaValue = realHeight - fontSize
nodeInfo.boundingRect.y = boundingRect.y + deltaValue / 2
nodeInfo.boundingRect.height = fontSize + paddingTop + paddingBottom调整方式:
scss
原始高度 = 50px (行高撑开)
字体大小 = 14px
多余空间 = 36px
调整后:
- Y 坐标下移:y + 18px (居中)
- 高度缩小:14px + paddingprocessMarginCollapsing处理边距合并的场景
要理解这一步骤,首先需要理解CSS中的核心概念:Margin 折叠(Margin Collapsing)
Margin Collapsing介绍
在特定条件下,子元素的 margin 会穿透父元素边界,直接作用到父元素外部。举个例子:
html
<div class="parent" style="background: lightblue;">
<div class="child" style="margin-top: 30px; background: pink;">
子元素
</div>
</div>预期效果 :子元素距离父元素顶部 30px
实际效果:父元素整体向下移动 30px,子元素紧贴父元素顶部
❌ 预期布局 ✅ 实际布局
┌─────────────┐ ↓ 30px
│ Parent │ ┌─────────────┐
│ ↓ 30px │ │ Parent │
│ ┌────────┐ │ │┌────────┐ │
│ │ Child │ │ ││ Child │ │
│ └────────┘ │ │└────────┘ │
└─────────────┘ └─────────────┘不会发生 Margin 折叠的条件:
-
BFC区域
-
父节点有边界或者背景
-
Flex、Grid布局
-
节点中有内联文本
html<div class="parent"> 内联文本 <div class="child" style="margin-top: 30px;">子元素</div> </div>
处理逻辑
- 判断是否会发生Margin折叠
- 会发生Margin折叠时,对应方向上是否有子节点有
margin - 有
margin时,将子节点设置为margin: 0,并将父节点对应方向上的margin设置为子节点的值与父节点的值中的最大值。
typescript
export function hoistingNotBfcBoundaryMargin(domNode: HTMLElement) {
Array.from(domNode.children).forEach((childNode) => {
// 反向DFS,先走最内部节点,然后往外走
hoistingNotBfcBoundaryMargin(childNode as HTMLElement)
})
// 是否是bfc
const isBFC = getDomIsBfc(domNode)
// 是否是flex or grid
const isFlexOrGridItem = getIsFlexOrGridItem(domNode)
// 是否有内联元素
const hasInlineContent = getHasInlineContent(domNode)
// 是否有clear
const hasClearance = getHasClearance(domNode)
const childNodeList = Array.from(domNode.children).filter((childNode) => {
const isDataTextWrapper = childNode.getAttribute('data-text-wrapper') === '1'
return !isDataTextWrapper
})
// 全部为false才需要提升margin
const preJudgeResult = [isBFC, isFlexOrGridItem, hasInlineContent, hasClearance, !childNodeList.length].every(it => !it)
if (!preJudgeResult) {
return
}
const shouldHoistTopMargin = judgeDomNodeMarginHoisting(domNode, 'top')
const shouldHoistBottomMargin = judgeDomNodeMarginHoisting(domNode, 'bottom')
if (shouldHoistTopMargin) {
hostingTargetDirectionMargin(domNode, 'top')
}
if (shouldHoistBottomMargin) {
hostingTargetDirectionMargin(domNode, 'bottom')
}
}processPaddingInfo 合并padding逻辑
在UI设计稿中,他们的边距可能是两个节点之间的距离,也可能是自动化布局的时候配置的padding。
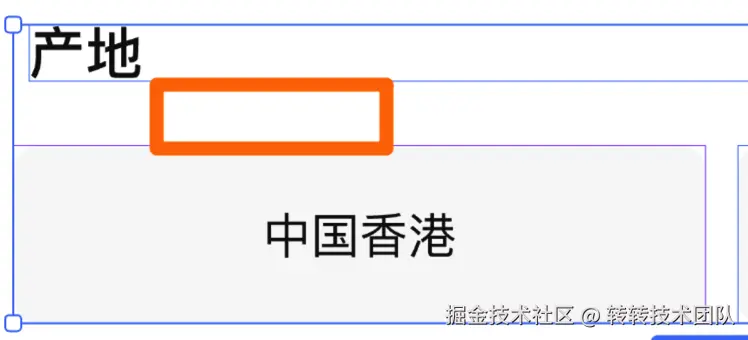

而在前端页面中,由于时常要考虑到节点存在与不存在的情况下的间距稳定性,因此常会出现各种拼接边距的情况。
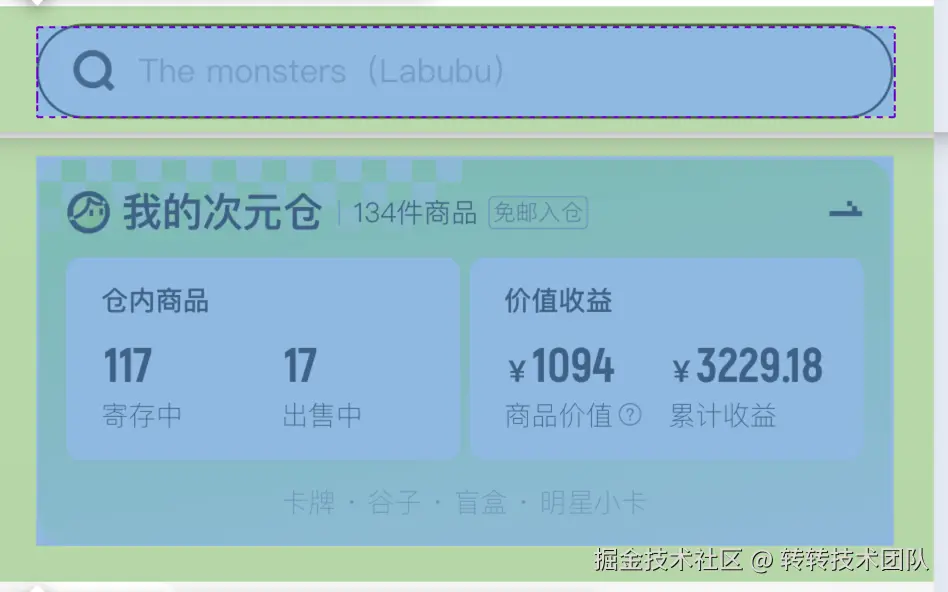
所以需要将纯粹地用来作为拼接边距的padding,从当前节点的width和height中排除出去,让节点的尺寸中不包含任何多余的无效padding。本处理方法的核心逻辑如下
- 对每个节点的上、下、左、右四个方向独立处理
typescript
paddingInfoDirectionList.forEach((currentPosition) => {
// top, right, bottom, left
})- 判断当前方向的 padding 是否可以被合并(可能需要检查子节点是否占用了这个空间)
typescript
const targetDirectionPaddingValue = getTargetDirectionPaddingValue({
currentNodeInfo,
flatNodeMap,
position: currentPosition,
})
export function getTargetDirectionPaddingValue({ currentNodeInfo, position }: JudgeMergableConfig) {
const paddingKey = camel(`padding ${position}`) as keyof PaddingInfo
// 是否存在目标方向的padding
const targetDirectionPaddingValue = currentNodeInfo.paddingInfo[paddingKey]
return targetDirectionPaddingValue || 0
}- 执行合并操作
- 扩展边界框:将 padding 空间纳入 boundingRect
- 减少 padding 值:从 paddingInfo 中扣除已合并的值
typescript
/**
* 合并padding
* @param curNodeInfo 当前节点信息
* @param position 目标方向
* @param paddingInfo 目标方向的padding值
* @returns 合并后的节点信息
*/
function handleMergePadding(curNodeInfo: NodeInfo, position: 'left' | 'right' | 'top' | 'bottom', paddingInfo: number) {
const clonedBoundingRect = clone(curNodeInfo.boundingRect)
if (position === 'left') {
clonedBoundingRect.x += paddingInfo
clonedBoundingRect.width -= paddingInfo
}
if (position === 'right') {
clonedBoundingRect.width -= paddingInfo
}
if (position === 'top') {
clonedBoundingRect.y += paddingInfo
clonedBoundingRect.height -= paddingInfo
}
if (position === 'bottom') {
clonedBoundingRect.height -= paddingInfo
}
return clonedBoundingRect
}
/**
* 减去已被合并的padding值
* @param curNodeInfo 当前节点信息
* @param position 目标方向
* @param paddingInfo 目标方向的padding值
* @returns 减去padding值后的节点信息
*/
function handleSubtractPaddingValue(curNodeInfo: NodeInfo, position: 'left' | 'right' | 'top' | 'bottom', paddingInfo: number) {
const clonedPaddingInfo = clone(curNodeInfo.paddingInfo)
const paddingKey = camel(`padding ${position}`) as keyof PaddingInfo
clonedPaddingInfo[paddingKey] -= paddingInfo
return clonedPaddingInfo
}
function processingPaddingInfo() {
//...
const paddingMergedBoundingRect = handleMergePadding(
currentNodeInfo,
currentPosition,
targetDirectionPaddingValue
)
const newPaddingInfo = handleSubtractPaddingValue(
currentNodeInfo,
currentPosition,
targetDirectionPaddingValue
)
//...
}shrinkRectBounding收缩矩形边界
为什么要收缩矩形边界?
在UI设计稿中,存在一些质量不可控的现象,比如 
在这个设计稿中,看似左侧的成色+定级标准节点与右侧的上下边距混乱,毫无居中的感觉。但是倘若我们对他进行一下变更:
 实际上只需要处理好左侧的高度,右侧的高度完全可以和左侧相同,并处理成为
实际上只需要处理好左侧的高度,右侧的高度完全可以和左侧相同,并处理成为 justify-content: space-between即可。
但是当FE拿到第一张图的时候,并不会一眼就看出来左右两侧的高度是可以完全一样的(因为选中左侧的时候是一个大的rectangle)
这个例子告诉我们,在UI侧常会存在一些凌乱的、难以用直觉判断实际效果的设计节点。这时候如果想要用自动化的方案进行比对,就需要针对这些噪声进行降噪处理。在本文中,采用的就是以实际渲染内容为主的节点收缩方案
主要逻辑就是尽可能的收缩节点的尺寸,让其可以紧凑地包裹在内容之外,尽可能地不包含多余的空间。
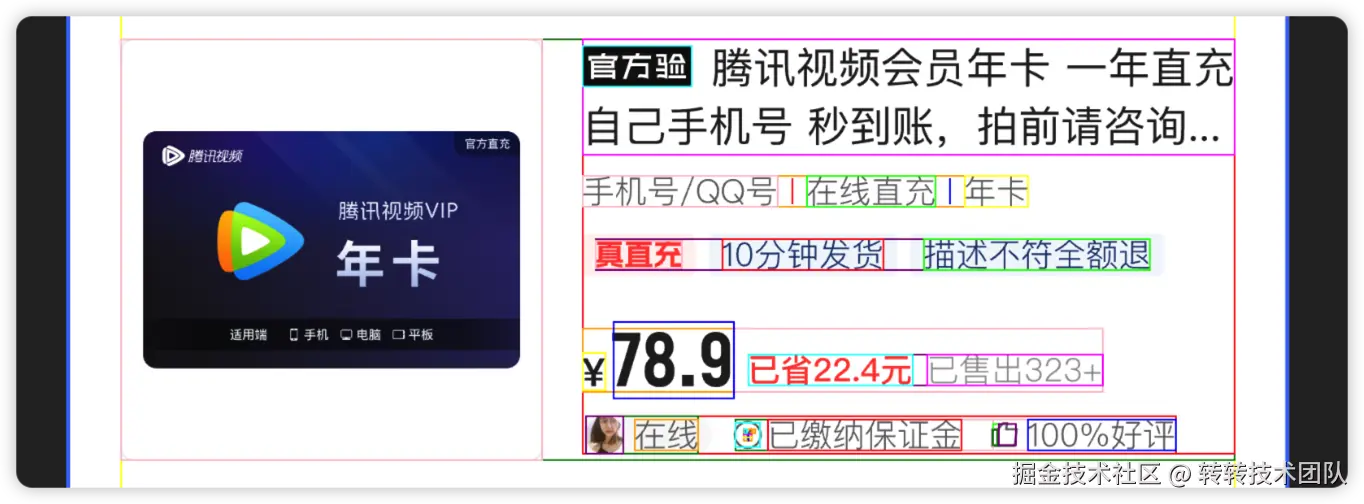

在做完这些工作后,便可以进行节点与其相邻节点的间距计算了。
Dom与设计稿数据的预处理逻辑
所谓预处理逻辑,旨在解决归一化处理数据时遇到的一些特殊case。包括但不限于:设计稿蒙版节点处理、设计稿使用rectange节点作为背景色节点的逻辑处理、前端px2rem误差精度修正等
设计稿蒙版节点处理
在设计稿中 Mask 的形式如下
less
GROUP
├─ 图片 A
├─ 图片 B
└─ 圆形 (isMask: true) ← Mask 图层其效果为:圆形作为遮罩,图片 A 和 B 只显示圆形范围内的部分。
虽然蒙版节点与被蒙版的节点是同一层的几个节点,但是从效果上来说,被蒙版的节点,可以视为蒙版的子节点。因此,将蒙版节点及被蒙版的节点视为一个父子结构,可以有效简化数据结构的处理。其流程如下:
- 查找 Mask 节点
- 先反转子节点列表(因为设计工具中 mask 在图层堆叠的底部)
- 找出所有可见的
isMask: true节点的索引
typescript
const reversedChildNodeList = originChildNodeList.toReversed()
const childMastIndexList = reversedChildNodeList
.filter(it => !!it.isVisible)
.reduce((prev, it, index) => {
if (!nodeCanBeMaskSet.has(curNode.type) || !curNode.isMask) {
return prev
}
return [...prev, index]
}, [] as number[])- 计算 Mask 影响范围
- Mask 节点会影响它上方的所有节点(直到遇到下一个 mask)
- 计算每个 mask 的影响范围
[start, end]
typescript
const maskChildIndexStartEndList = childMastIndexList
.map((it, index, originArr) => {
if (index === 0) {
return [reversedChildNodeList.length - it, reversedChildNodeList.length]
}
return [reversedChildNodeList.length - it, reversedChildNodeList.length - originArr[index - 1] - 1]
})
.toReversed()示例:
yaml
原始顺序(反转后):
[0: 图片A, 1: 图片B, 2: Mask1, 3: 图片C, 4: Mask2]
↑ ↑
Mask1 影响范围: [0, 2] (图片A, 图片B)
Mask2 影响范围: [3, 4] (图片C)- 创建新的 FRAME 容器
typescript
const newFrameNode = {
...emptyFrameNode, // 基础 FRAME 属性
id: `${id}${MASK_REPLACE_SUFFIX}`,
name: `${name}${MASK_REPLACE_SUFFIX}`,
// 继承 mask 节点的位置和尺寸
absoluteTransform,
relativeTransform,
x, y, width, height,
cornerRadius, // 继承圆角
clipsContent: true, // 关键:裁剪内容
children, // 被遮罩的内容
}-
优化:单个 Mask 且尺寸一致
如果只有一个 mask 且和父容器尺寸相同,直接替换父节点,减少层级。
typescript
const isSameSize = currentNode.width === firstMaskRelpaceNodeInfo.width
&& currentNode.height === firstMaskRelpaceNodeInfo.height
if (newChildGroupList.length === 1 && isSameSize) {
// 直接合并到父节点
return {
...currentNode,
...firstMaskRelpaceNodeInfo,
}
}设计稿背景节点的提升
由于一些原Adobe软件 or sketch的操作习惯,且在MasterGo工具中,Group节点无法主动设置宽高,因此常使用group节点+rectangle节点的方式去撑开一个节点或者给一个节点设置背景色。而这个rectangle节点在比对过程中则属于一个需要忽略的节点,因此在此预处理逻辑中,需要识别背景色节点,并将背景色提升到父节点的属性上去,简化图层结构。其处理流程如下:
- 分离背景图层和内容图层
typescript
export function judgeIsBgStyleRectangle(currentNode: PenNode | RectangleNode, parentNode: FrameNode | GroupNode) {
const { width, height } = currentNode
const { width: parentWidth, height: parentHeight } = parentNode
const deltaWidth = Math.abs(width - parentWidth)
const deltaHeight = Math.abs(height - parentHeight)
// 大于为图片 + mask 或者 图片+overflow hidden的场景
const isSameSize = deltaWidth < 2 && deltaHeight < 2
return isSameSize
}
// 背景图层:RECTANGLE/PEN 且判断为背景样式
const bgStyleNodeList = currentNode.children.filter((it) => {
if (it.type !== 'RECTANGLE' && it.type !== 'PEN') return false
return judgeIsBgStyleRectangle(it, currentNode)
})
// 其他图层:非背景的内容
const restNodeChildList = currentNode.children.filter((it) => {
if (it.type !== 'RECTANGLE' && it.type !== 'PEN') return true
return !judgeIsBgStyleRectangle(it, currentNode)
})- 合并背景样式
typescript
// 合并所有背景图层的填充
const combinedFillList = bgStyleNodeList.flatMap(node => node.fills || [])前端px2rem误差精度修正
转转App的px2rem方案走的是常规的px2rem方案,root上的font-size配置为了document.clientWidth / 10的值,rem值的取值精度为两位小数。
在前端响应式配置设置为iphone se(375px)的场景下,其页面实际渲染的值并非设计稿的一半。

单个节点的场景误差尚可以用四舍五入的逻辑修正,但是在多数值拼接的场景下,误差可能会被放大,导致比对异常。因此需要对px2rem精度进行修正,以避免过多的误差出现。
- 模块结构
shell
📦 css-hacker
├─ main-hacker.ts # 主流程编排
├─ dom-parser.ts # 解析页面样式表
├─ css-fetcher.ts # 获取 CSS 内容
├─ css-modifier.ts # 修改 CSS 内容
├─ css-injector.ts # 注入修改后的 CSS
├─ convert-px2rem-deviation.ts # rem 单位转换插件
└─ types.ts # 类型定义- 核心流程
- 核心逻辑:
通过px2rem逻辑,构建一个1-2000数值的哈希Map,key为rem的值,value为原px值。
通过劫持页面CSS文件,用一个自定义的postcss插件,配合预配置的Map,将px值反向映射为设计稿原值。
typescript
// 单例1-2000映射Map
class PxConvertMapSingleton {
private static instance: PxConvertMapSingleton
private convertMap: Map<number, number>
private constructor() {
this.convertMap = this.generateConvertMap()
}
public static getInstance(): PxConvertMapSingleton {
if (!PxConvertMapSingleton.instance) {
PxConvertMapSingleton.instance = new PxConvertMapSingleton()
}
return PxConvertMapSingleton.instance
}
private convertPx(originPxValue: number): number {
const originRemValue = originPxValue / 750 * 10
const remValue = Math.round(originRemValue * 100) / 100
return Math.round(remValue * 37.5 * 1000) / 1000
}
private generateConvertMap(): Map<number, number> {
const startValue = 1
const endValue = 2000
const entries = Array.from({ length: endValue - startValue + 1 }).map((_, index) => {
const curValue = index + startValue
if (curValue === 1) {
return [1, 1] as const
}
return [this.convertPx(curValue), curValue] as const
})
return new Map(entries)
}
public getConvertMap(): Map<number, number> {
return this.convertMap
}
}
export function getPxConvertMap(): Map<number, number> {
return PxConvertMapSingleton.getInstance().getConvertMap()
}再通过设计稿数据处理方案转换成前端页面实际的px值,最终形成新的css样式表注入到HTML中。
typescript
const remRegex = /(\d+(?:\.\d+)?|\.\d+)rem/gi
/** 处理CSS属性值中的rem单位,转换为px */
export function processRemInValue(value: string, baseFontSize: number): string {
if (!value || !value.includes('rem')) {
return value
}
const convertMap = getPxConvertMap()
return value.replace(remRegex, (_match, remValue) => {
// rem值
const convertedRemValue = Number(remValue)
// 四舍五入取4位精度
const convertedPxValue = Math.round(convertedRemValue * baseFontSize * 10000) / 10000
const designValue = convertMap.get(convertedPxValue)
if (!designValue) {
return `${convertedRemValue}rem`
}
return `${convertDesignToPx(designValue)}px`
})
}
// post-css插件
export const convertPx2RemDeviation: PluginCreator<Px2RemDeviationOptions> = (opts) => {
const combinedOptions = { ...(opts || {}), ...defaultOptions }
const { baseFontSize } = combinedOptions
return {
postcssPlugin: 'convert-px2rem-deviation',
Rule(rule: Rule) {
rule.walkDecls((decl: Declaration) => {
const value = decl.value
if (!value || !value.includes('rem')) {
return
}
const newValue = processRemInValue(value, baseFontSize)
decl.value = newValue
})
},
}
}
convertPx2RemDeviation.postcss = true
export default convertPx2RemDeviation-
为什么不通过
computedStyle进行反向映射?原因在于
computedStyle获取到的值无法通过1-2000的Map直接进行映射,比如一个box-sizing:border-box的div节点,需要面临三种场景:- 如果其宽度是直接设置的,则需要拆解成
padding、border、width三部分分别进行映射。 - 如果其宽度是撑满父容器的,则需要受控于其父容器的宽度。
- 如果是被子节点撑开的,则又需要分别计算子节点的宽度进行组合。
其整体判断逻辑复杂程度高,难以理清。所以采用css注入的方式从css文件层面去解决精度问题,是当前最优解。
- 如果其宽度是直接设置的,则需要拆解成
Dom节点与UI节点的匹配
节点匹配策略为一块较为独立且完整的模块,由于时间、人力等一些问题,目前的节点匹配方案为常规的IOU匹配方案,匹配准确率约为40%~60%左右,有较高的优化空间,并将在后续的开发中探索匹配层面的优化方案,以提高匹配率和检测准确度。
基本匹配策略
节点匹配算法采用欧几里得距离计算的方式,综合考虑节点的位置和尺寸信息:
- 位置距离:计算两个节点中心点的欧几里得距离
- 尺寸距离:计算两个节点宽高的欧几里得距离
- 综合距离:通过加权平均得到最终匹配分数
距离计算公式
typescript
// 位置距离计算
const positionDistance = Math.sqrt(
(x - mgX) 2 + (y - mgY) 2
)
// 尺寸距离计算
const sizeDistance = Math.sqrt(
(width - mgWidth) 2 + (height - mgHeight) 2
)
// 综合距离(位置权重 0.7,尺寸权重 0.3)
const totalDistance = positionDistance 0.7 + sizeDistance 0.3
匹配阈值机制
- 最大可接受距离:MAX_ACCEPTABLE_DISTANCE = 100
- 只有当综合距离小于阈值时,才会被认为是有效匹配
- 在所有有效匹配中选择距离最小的作为最终匹配结果
算法流程
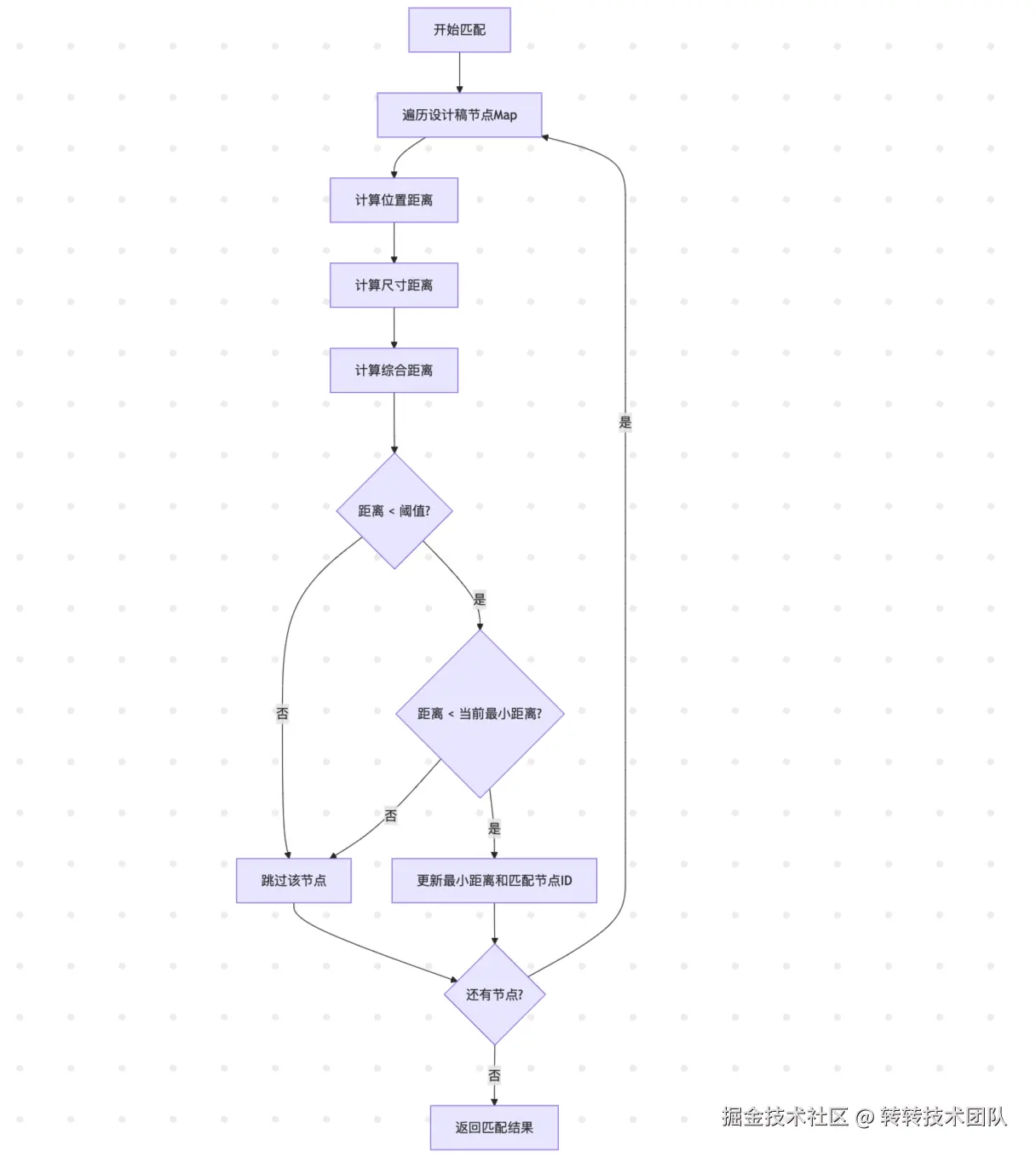
部分区域UI比对逻辑
上述的比对逻辑虽是比较通用的逻辑,但是在初版实现时,以全页面的比对逻辑为主。但是在实际业务开发过程中,对页面部分区域进行修改的需求数量是多余构建全新页面的需求数量的。因此部分区域比对逻辑是比较关键的一环。
这部分开发的重点在于如何快速简单地让用户选中需要比对的区域?
可以通过chrome插件中的devtools相关功能来实现。
chrome插件通信时序图
获取用户当前在element标签下选中的元素
主要通过chrome插件的chrome.devtools.inspectedWindow.eval方法实现。
ts
function handleGetSelectedElement() {
const getSelectorExpression = `
(function() {
// ...生成selector逻辑
// $0 是 DevTools 中当前选中的元素
return getElementSelector($0);
})()
`
// 使用 chrome.devtools.inspectedWindow.eval 在页面上下文中执行
chrome.devtools.inspectedWindow.eval(
getSelectorExpression,
(result, exceptionInfo) => {
// 将获取到的selector发送给background
const responseMsg: ChromeListenerMessageType = {
type: ChromeMessageType.RETURN_ELEMENT_SELECTOR,
data: {
tabId: chrome.devtools.inspectedWindow.tabId,
selector: result,
},
}
backgroundPort?.postMessage(responseMsg)
},
)
}生成对应节点的selector逻辑
通过生成对应节点的selector,将结果经由background层发送给content_script(插件主体),在content_script中通过document.querySelector(${selector})重新获取到用户选中的节点。
typescript
function getElementSelector(element) {
if (!element) {
return null
}
// 如果是 document,返回 html
if (element === document.documentElement) {
return 'html'
}
// 如果元素有 id,使用 id
if (element.id) {
return `#${element.id}`
}
// 构建 CSS Selector
const path = []
let current = element
while (current && current.nodeType === Node.ELEMENT_NODE) {
let selector = current.nodeName.toLowerCase()
// 添加类名(如果有)
if (current.className && typeof current.className === 'string') {
const classes = current.className.trim().split(/\\s+/).filter(c => c)
if (classes.length > 0) {
selector += `.${classes.join('.')}`
}
}
// 计算同级元素的位置(如果需要)
if (current.parentNode) {
const siblings = Array.from(current.parentNode.children).filter(
sibling => sibling.nodeName === current.nodeName,
)
if (siblings.length > 1) {
const index = siblings.indexOf(current) + 1
selector += `:nth-of-type(${index})`
}
}
path.unshift(selector)
current = current.parentNode
// 如果到达了有 id 的父元素,可以停止
if (current && current.id) {
path.unshift(`#${current.id}`)
break
}
}
return path.join(' > ')
}写在最后
这套方案从最初的想法到现在的实现,其实走了不少弯路。最开始我们也想过用图像识别,毕竟看起来很"AI"很"高级",但实际跑下来发现根本不靠谱------设计稿改个文案、换个颜色,算法就得重新训练。后来才想明白,既然设计稿和DOM都是结构化数据,为什么不直接对比结构呢?
整个方案的核心其实就做了一件事:把两个看起来完全不同的东西(设计稿的JSON和HTML的DOM树),通过一系列归一化处理,变成可以直接比对的同构数据。这个过程中最大的感受是,前端开发和UI设计之间的gap,本质上是两套不同的渲染规则在互相较劲。CSS的margin折叠、行高计算、盒模型,每一个细节都可能让设计稿"看起来一样"的两个元素在代码层面完全不同。
说实话,当前40%-60%的匹配准确率还远谈不上完美,但至少让我们看到了一个方向:自动化UI走查的关键不在于追求百分百的准确,而在于建立一套可量化、可追溯的比对标准。就像单元测试不能保证代码零bug,但能让我们对代码质量有个基本的信心。
更重要的是,这套方案让我们重新思考了前端工程化的本质。过去我们总说要提效、要自动化,但往往只盯着代码构建、打包部署这些环节。UI还原度这件事一直是个"玄学"------全凭开发的经验和责任心。现在我们把它量化了、标准化了,这意味着整个研发流程可以往前再推一步:不仅要保证代码能跑,还要保证UI能过。
当然,技术方案永远只是工具。真正能提升团队协作效率的,是大家对质量的共识。这套自动化走查如果只是用来"抓bug",那价值就太有限了。我更希望它能成为一面镜子,让前端看到自己对设计的理解偏差,让设计看到自己稿子的不规范之处,最终推动双方在规范上达成更多共识。
技术的意义从来不在于解决所有问题,而在于让问题变得可见、可量化、可改进。