为什么要做 SERP 结构化处理?
在日常 SEO 或数据采集工作中,我们往往关注几个常规指标:某个关键词排名第几、某个页面是否掉出前十、今天的排名相比昨天是上升还是下降。这样的分析虽然直观,但随着 Google、Bing 等搜索引擎不断丰富搜索结果页(SERP)的内容,仅仅看排名已经不足以揭示用户真正的搜索意图,更无法支撑深度的商业决策。
事实上,SERP 本身的结构就能提供很多有价值的信息 。以搜索关键词 「best wireless earbuds」 为例,不同模块可能透露出截然不同的商业信号:
- Shopping 模块:如果此模块出现且位置靠前,表明该关键词的商业意图强烈,用户正处于购买决策阶段。
- 新闻模块:意味着该关键词对时效性要求高,可能是有新品发布或重大行业事件,是公关和内容营销的黄金机会。
- YouTube 视频:说明用户偏好视频这种信息载体。对于品牌方而言,投资视频内容可能比传统博客文章带来更高的回报。
- 知识卡片:搜索意图偏向于快速的事实查询。如果目标是品牌曝光或获取潜在客户,这类关键词的转化率可能较低。
- 广告位数量与分布:直接反映了该关键词的竞争程度与商业价值。顶部和底部布满广告,意味着这是一个"兵家必争"的高价值词。
结构化处理 SERP 的本质,是将一个杂乱的 HTML 页面,转化为一个标准化的、可量化的、可监控的数据模型。 通过分析这些模块,我们不仅能更准确地理解搜索意图,还能为 SEO 策略、内容规划、产品方向和市场判断提供直接的数据支撑,实现从"猜测"到"数据驱动"的跨越。
多区域 SERP 差异
同一个关键词在不同国家、地区甚至城市呈现的 SERP 可能天差地别,这背后反映了文化、消费习惯、市场竞争和互联网生态的巨大差异。因此,仅凭单一地区的搜索结果做决策,对于全球化业务来说是远远不够的。例如:
美国 SERP 的第一屏可能是电商 Shopping,德国 SERP 的第一屏可能是新闻,日本 SERP 可能加入视频 + 图集。因此,结构化和可视化 SERP 数据是必要的,而不仅是简单抓 HTML。
需求分析:结构化 SERP + 趋势监控
根据实际项目需求,可以将其拆成两个部分:
(1)结构化 SERP:把页面变成可分析数据
即:抓取 SERP,识别模块结构(网页、新闻、视频、图集、广告、Shopping、Google 模块),JSON-LD 内容解析,输出统一格式的 JSON。
这个步骤涉及更多工程细节,是本文实战的重点。
(2)趋势监控:持续记录 SERP 的结构变化
例如:
- 持续记录 SERP 模块变化
- 观察普通网页数量、新闻/视频模块增减、广告位变化、相关搜索关键词变化等
- 生成趋势图或报告,为内容策略和市场分析提供数据支撑
IPIDEA 动态住宅 IP 配置说明
为了稳定抓取跨区域 SERP,可以使用 IPIDEA 动态住宅 IP,操作流程如下
1.登录 IPIDEA 面板,选择"动态住宅 IP",将本地 IP 添加到白名单。
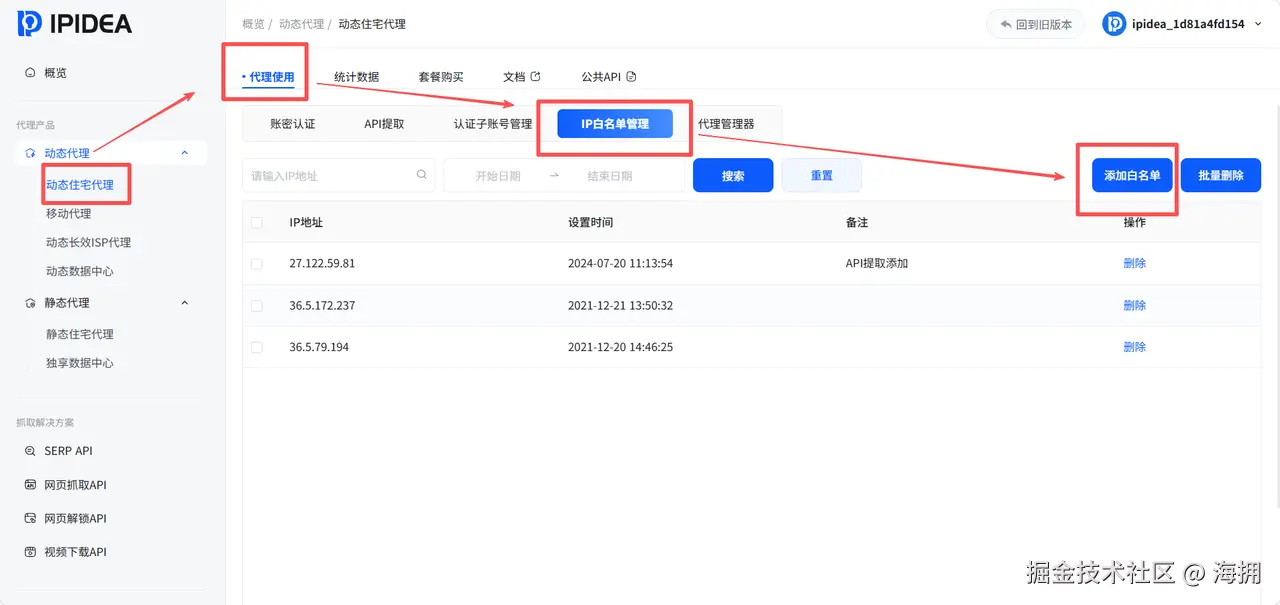
- 在 API 获取中选择动态住宅 IP,设置扣费方式、国家/地区、每次提取数量、代理协议和数据格式,点击生成链接。
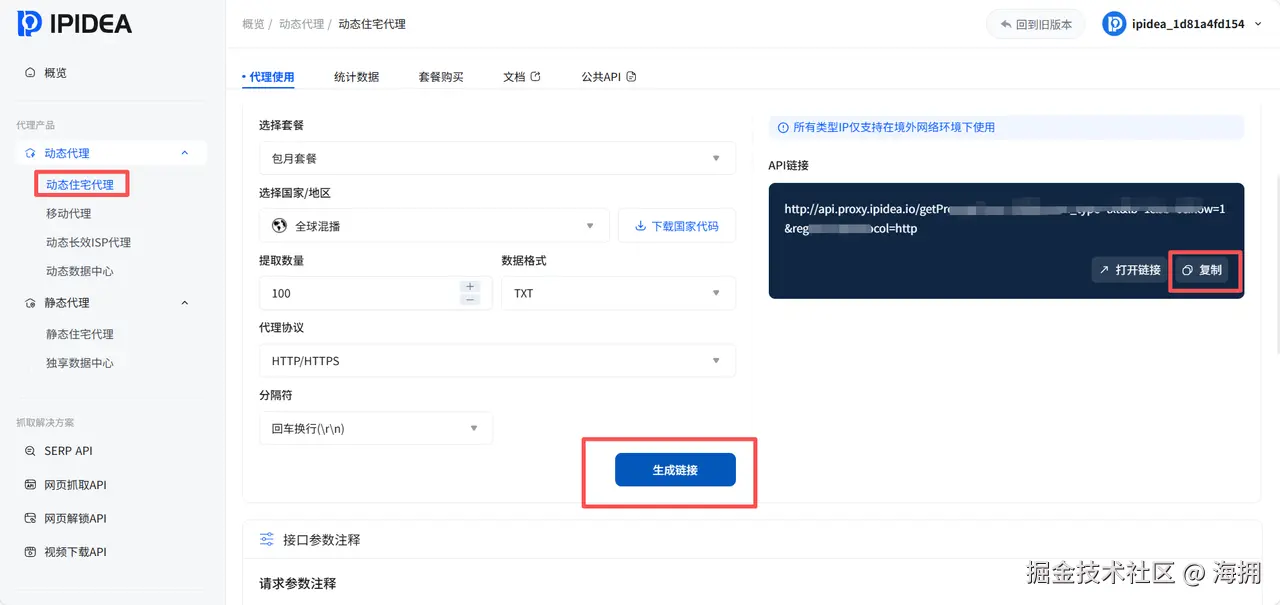
- 使用浏览器访问 API 链接,确认返回数据格式正确。
实操示例 1:抓取 PyPI requests 包并分析趋势
在技术领域,及时掌握开源项目的动态变化至关重要。以 PyPI 上的 requests 库为例,作为 Python 生态系统中最常用的 HTTP 库之一,其版本更新、发布频率和功能变化直接影响着成千上万个项目的技术选型和升级决策。
通过这个抓取 PyPI requests 包的示例,我们将展示如何从简单的网页抓取开始,构建一个完整的技术监控方案,为技术决策提供坚实的数据基础。
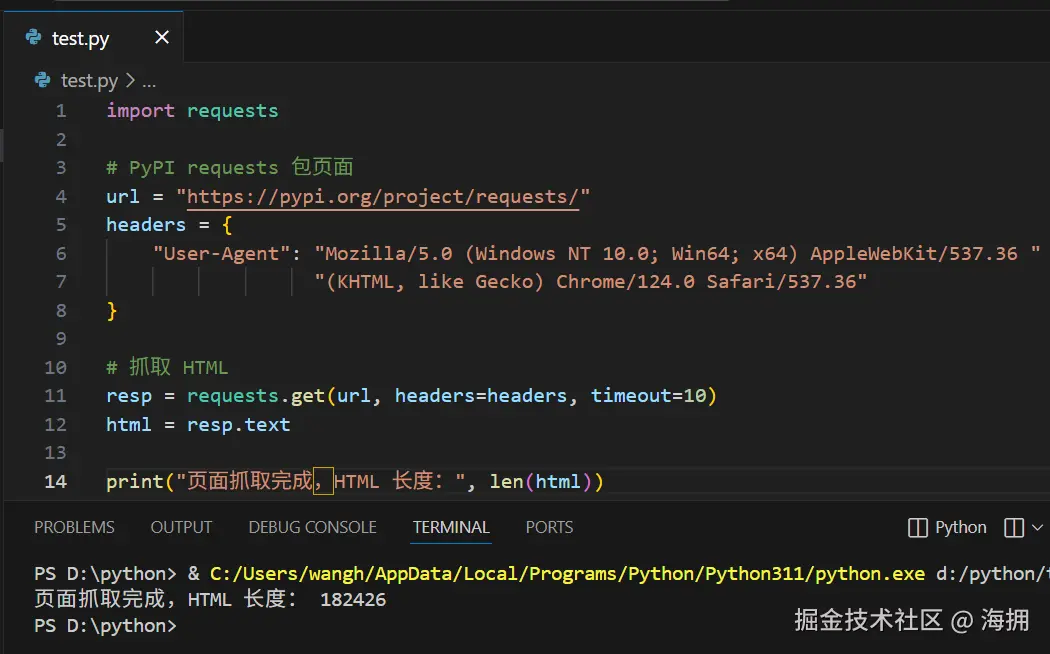
获取 PyPI 页面 HTML
python
import requests
# PyPI requests 包页面
url = "https://pypi.org/project/requests/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0 Safari/537.36"
}
# 抓取 HTML
resp = requests.get(url, headers=headers, timeout=10)
html = resp.text
print("页面抓取完成,HTML 长度:", len(html))说明:
- 抓取 PyPI
requests页面 HTML。- 后续解析 JSON 都会用到
html变量,因此必须先执行这一段。- 用途:让开发者或产品分析师快速获取包信息、版本变化和发布时间趋势
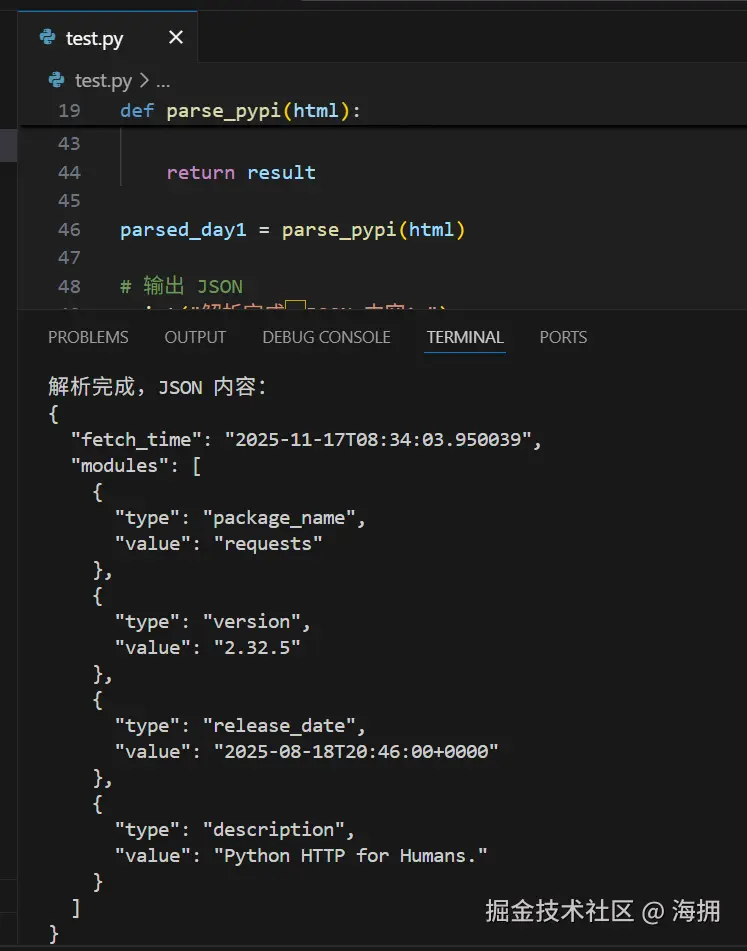
解析 HTML 为结构化 JSON
python
from bs4 import BeautifulSoup
from datetime import datetime
import json
import requests
# PyPI requests 包页面
url = "https://pypi.org/project/requests/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0 Safari/537.36"
}
# 抓取 HTML
resp = requests.get(url, headers=headers, timeout=10)
html = resp.text
print("页面抓取完成,HTML 长度:", len(html))
def parse_pypi(html):
soup = BeautifulSoup(html, "html.parser")
result = {"fetch_time": datetime.utcnow().isoformat(), "modules": []}
# 包名 + 版本
header = soup.select_one("h1.package-header__name")
if header:
text = header.text.strip()
if " " in text:
name, version = text.split(" ", 1)
result["modules"].append({"type": "package_name", "value": name})
result["modules"].append({"type": "version", "value": version})
else:
result["modules"].append({"type": "package_name", "value": text})
# 发布时间
time_tag = soup.select_one("time")
if time_tag:
result["modules"].append({"type": "release_date", "value": time_tag.get("datetime")})
# 项目描述
desc_tag = soup.select_one("p.package-description__summary")
if desc_tag:
result["modules"].append({"type": "description", "value": desc_tag.text.strip()})
return result
parsed_day1 = parse_pypi(html)
# 输出 JSON
print("解析完成,JSON 内容:")
print(json.dumps(parsed_day1, indent=2, ensure_ascii=False))说明:
- 将 HTML 解析成结构化 JSON。
- 包含模块:
package_name、version、release_date、description。- 方便统计模块数量、生成趋势分析和可视化报告
模拟 8 天趋势数据
python
from collections import Counter
# 模拟 8 天趋势
trend_data = []
for i in range(8):
day_modules = parsed_day1["modules"] + [{"type": "dummy", "value": j} for j in range(i % 4)]
trend_data.append({"modules": day_modules})
days = ["2025-11-" + str(14 + i) for i in range(8)]
# 统计每种模块每天数量
module_types = set()
for d in trend_data:
module_types.update([m["type"] for m in d["modules"]])
module_types = list(module_types)
trend_counts = {
t: [Counter([m["type"] for m in d["modules"]]).get(t, 0) for d in trend_data]
for t in module_types
}
# 打印每日模块统计
print("=== 每日模块统计 ===")
for t, counts in trend_counts.items():
print(f"{t}: {counts}")说明:
dummy数据仅用于演示趋势折线图- 方便快速判断哪些模块信息在变化,有助于内容更新策略或竞争分析
- 实际使用中可换为每日抓取的真实数据
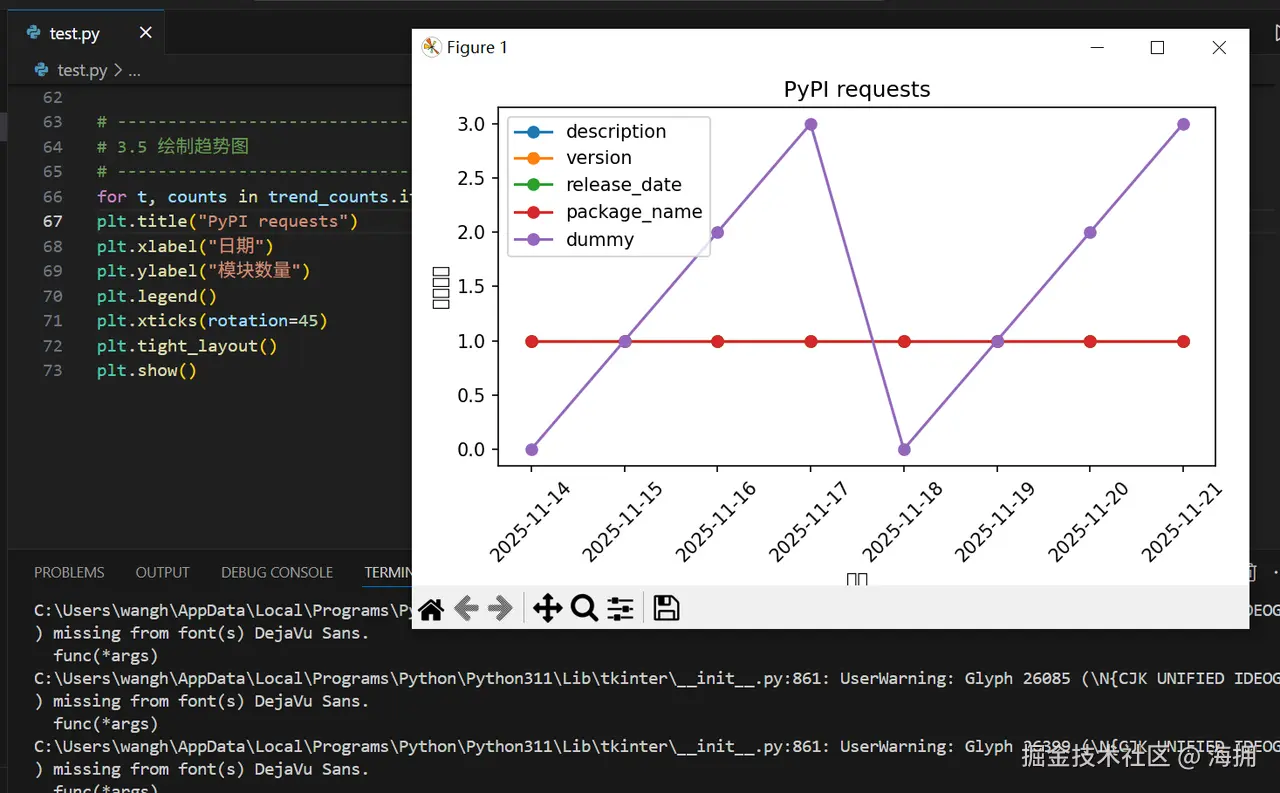
绘制趋势折线图
python
import matplotlib.pyplot as plt
for t, counts in trend_counts.items():
plt.plot(days, counts, marker='o', label=t)
plt.title("PyPI requests 包信息模块趋势(模拟 8 天)")
plt.xlabel("日期")
plt.ylabel("模块数量")
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()说明:
- 折线图显示每日各模块数量变化
- 便于观察趋势和异常
完整整合版(可直接运行)
python
import requests
from bs4 import BeautifulSoup
from datetime import datetime
from collections import Counter
import json
import matplotlib.pyplot as plt
# -----------------------------
# 3.1 抓取 HTML
# -----------------------------
url = "https://pypi.org/project/requests/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/124.0 Safari/537.36"}
resp = requests.get(url, headers=headers, timeout=10)
html = resp.text
# -----------------------------
# 3.2 解析 HTML
# -----------------------------
def parse_pypi(html):
soup = BeautifulSoup(html, "html.parser")
result = {"fetch_time": datetime.utcnow().isoformat(), "modules": []}
header = soup.select_one("h1.package-header__name")
if header:
text = header.text.strip()
if " " in text:
name, version = text.split(" ", 1)
result["modules"].append({"type":"package_name","value":name})
result["modules"].append({"type":"version","value":version})
else:
result["modules"].append({"type":"package_name","value":text})
time_tag = soup.select_one("time")
if time_tag: result["modules"].append({"type":"release_date","value":time_tag.get("datetime")})
desc_tag = soup.select_one("p.package-description__summary")
if desc_tag: result["modules"].append({"type":"description","value":desc_tag.text.strip()})
return result
parsed_day1 = parse_pypi(html)
print("解析完成 JSON:")
print(json.dumps(parsed_day1, indent=2, ensure_ascii=False))
# -----------------------------
# 3.3 模拟 8 天趋势
# -----------------------------
trend_data = []
for i in range(8):
day_modules = parsed_day1["modules"] + [{"type":"dummy","value":j} for j in range(i % 4)]
trend_data.append({"modules": day_modules})
days = ["2025-11-" + str(14 + i) for i in range(8)]
# -----------------------------
# 3.4 模块统计
# -----------------------------
module_types = set()
for d in trend_data: module_types.update([m["type"] for m in d["modules"]])
module_types = list(module_types)
trend_counts = {t:[Counter([m["type"] for m in d["modules"]]).get(t,0) for d in trend_data] for t in module_types}
print("\n=== 每日模块统计 ===")
for t, counts in trend_counts.items(): print(f"{t}: {counts}")
# -----------------------------
# 3.5 绘制趋势图
# -----------------------------
for t, counts in trend_counts.items(): plt.plot(days, counts, marker='o', label=t)
plt.title("PyPI requests 包信息模块趋势(模拟 8 天)")
plt.xlabel("日期")
plt.ylabel("模块数量")
plt.legend()
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()实操示例 2:SERP 模块分析指导内容策略
在内容营销竞争日益激烈的当下,众多内容团队面临着共同的困境:如何在有限的预算内,为不同的产品线制定最有效的内容策略?
为此,我制作了这款比较简易的 SERP 模块分析指导内容策略系统。通过深度解析 Google 搜索结果页面的结构化特征,将主观的经验判断转化为客观的数据分析,为不同产品线提供精准的内容创作方向,让每一份投入都产生可衡量的商业价值。
获取同一公司多产品线的 SERP 数据
python
import requests
import time
# 配置IPIDEA代理
proxy_url = "http://YOUR_USERNAME:YOUR_PASSWORD@proxy.ipidea.io:2333"
proxies = {"http": proxy_url, "https": proxy_url}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
# 同一科技公司的 5个不同产品线关键词(最新款)
keywords = [
"iPhone 17 Pro review", # 旗舰产品评测
"MacBook Air M4 unboxing", # 开箱体验类
"iPad Pro 2025 buying guide", # 购买指南类
"Apple Watch Series 11 setup tutorial", # 使用教程类
"AirPods Pro 4 vs Bose comparison" # 竞品对比类
]
def get_serp_html(keyword):
"""使用IPIDEA代理获取Google搜索结果"""
url = f"https://www.google.com/search?q={requests.utils.quote(keyword)}&gl=us&num=10"
try:
resp = requests.get(url, headers=headers, proxies=proxies, timeout=15)
return resp.text if resp.status_code == 200 else None
except Exception as e:
print(f" 请求失败: {e}")
return None
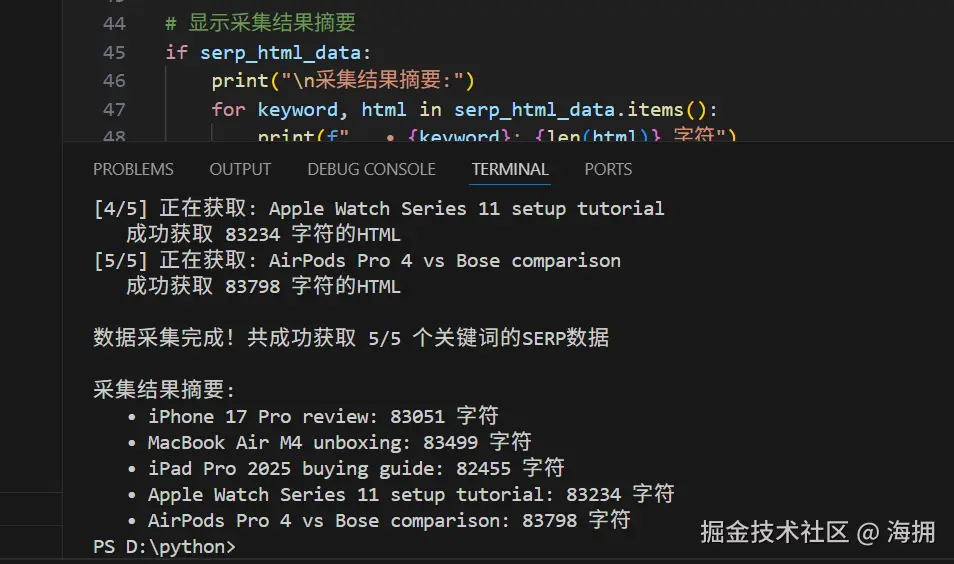
# 批量获取SERP数据并实时输出进度
print("开始使用IPIDEA代理采集SERP数据...")
print("代理配置:", proxy_url)
serp_html_data = {}
for i, keyword in enumerate(keywords, 1):
print(f"[{i}/{len(keywords)}] 正在获取: {keyword}")
html = get_serp_html(keyword)
if html:
serp_html_data[keyword] = html
print(f" 成功获取 {len(html)} 字符的HTML")
else:
print(f" 获取失败,请检查代理配置")
time.sleep(2) # 添加延时避免请求过快
print(f"\n数据采集完成!共成功获取 {len(serp_html_data)}/{len(keywords)} 个关键词的SERP数据")
# 显示采集结果摘要
if serp_html_data:
print("\n采集结果摘要:")
for keyword, html in serp_html_data.items():
print(f" • {keyword}: {len(html)} 字符")
else:
print("未获取到任何数据,请检查IPIDEA代理配置")实际输出:
说明:
- 包含最新款产品的评测、开箱、购买指南、使用教程、竞品对比等搜索意图
- 实时输出采集进度和结果,便于监控执行状态
- 添加请求延时防止反爬机制
解析 SERP 结构并生成产品线内容策略
python
def analyze_serp_structure(html, keyword):
"""分析SERP结构并生成内容策略建议"""
html_lower = html.lower()
# 简化的SERP模块分析
modules = {
"ads": min(html.count('Ad'), 10), # 广告数量
"shopping": any(word in html_lower for word in ['shop', 'buy', 'price']),
"videos": any(word in html_lower for word in ['youtube', 'video', 'watch']),
"news": any(word in html_lower for word in ['news', 'latest', 'update']),
"questions": min(html_lower.count('?'), 10), # 相关问题
"featured_snippet": any(word in html_lower for word in ['snippet', 'answer']),
"comparison": any(word in html_lower for word in ['vs', 'compare', 'comparison'])
}
# 生成内容策略
strategies = generate_content_strategy(modules, keyword)
return {
"keyword": keyword,
"modules": modules,
"strategies": strategies
}
def generate_content_strategy(modules, keyword):
"""基于SERP模块分析生成内容策略"""
strategies = []
# 商业价值判断
if modules["ads"] >= 3:
strategies.append("制作购买指南和产品对比")
elif modules["ads"] > 0:
strategies.append("制作评测和推荐内容")
# 内容类型建议
if modules["shopping"]:
strategies.append("创建产品评测和购买建议")
if modules["videos"]:
strategies.append("投资视频开箱或评测内容")
if modules["questions"] > 3:
strategies.append("制作FAQ解答用户问题")
if modules["featured_snippet"]:
strategies.append("优化内容争取精选摘要")
if modules["comparison"]:
strategies.append("制作详细竞品对比分析")
# 关键词类型建议
if "review" in keyword:
strategies.append("创建深度产品评测内容")
if "unboxing" in keyword:
strategies.append("制作开箱视频和第一印象")
if "buying guide" in keyword:
strategies.append("制作购买建议和配置推荐")
if "setup" in keyword or "tutorial" in keyword:
strategies.append("制作详细设置教程")
if "vs" in keyword or "comparison" in keyword:
strategies.append("制作功能对比表格")
return strategies if strategies else ["📝 创建综合信息内容"]
# 分析SERP数据并实时显示分析结果
print("开始SERP结构分析...")
serp_analyses = {}
for keyword, html in serp_html_data.items():
print(f"\n分析关键词: {keyword}")
analysis = analyze_serp_structure(html, keyword)
serp_analyses[keyword] = analysis
# 立即显示分析结果
modules = analysis["modules"]
active_modules = []
for module, value in modules.items():
if value and value > 0:
active_modules.append(f"{module}({value})")
print(f" 检测到模块: {', '.join(active_modules) if active_modules else '基础搜索结果'}")
print(f" 策略建议: {', '.join(analysis['strategies'][:3])}")
print(f"\nSERP分析完成!共分析 {len(serp_analyses)} 个关键词")实际输出:

说明:
- 基于模块存在情况自动生成具体的内容策略
- 针对不同产品线关键词提供定制化建议
- 实时输出每个关键词的分析结果,便于即时了解分析进展
生成内容策略报告
python
def generate_content_strategy_report(analyses):
"""生成内容策略报告"""
print("SERP模块分析 - 内容策略报告")
for keyword, analysis in analyses.items():
modules = analysis["modules"]
print(f"\n关键词: {keyword}")
# 显示发现的模块
active_modules = []
for module, value in modules.items():
if value and value > 0:
display_name = {
"ads": f"广告({value})",
"shopping": "购物模块",
"videos": "视频模块",
"news": "新闻模块",
"questions": f"相关问题({value})",
"featured_snippet": "精选摘要",
"comparison": "对比内容"
}[module]
active_modules.append(display_name)
print(f"SERP模块: {', '.join(active_modules) if active_modules else '基础搜索结果'}")
# 显示内容策略建议
print("内容策略建议:")
for i, strategy in enumerate(analysis["strategies"], 1):
print(f" {i}. {strategy}")
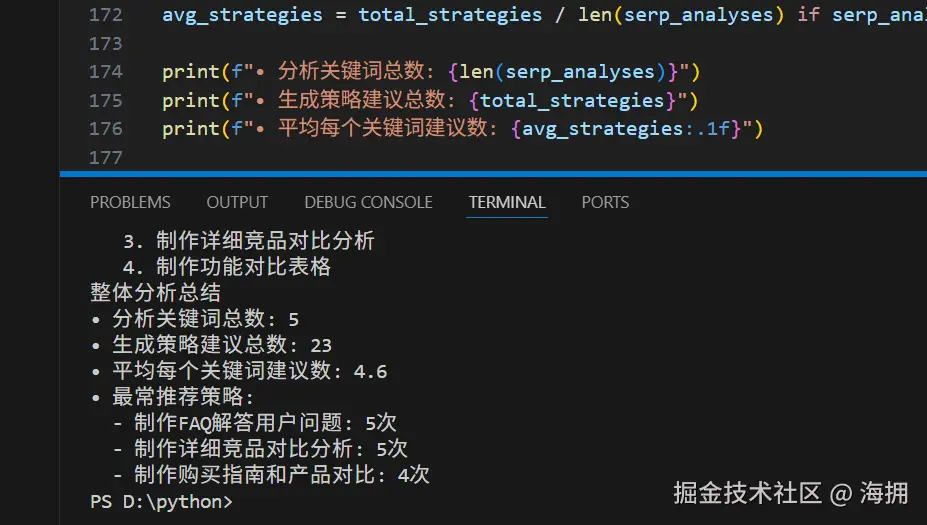
# 生成最终报告
print("生成最终内容策略报告")
generate_content_strategy_report(serp_analyses)
# 添加总结统计
print("整体分析总结")
total_strategies = sum(len(analysis["strategies"]) for analysis in serp_analyses.values())
avg_strategies = total_strategies / len(serp_analyses) if serp_analyses else 0
print(f"• 分析关键词总数: {len(serp_analyses)}")
print(f"• 生成策略建议总数: {total_strategies}")
print(f"• 平均每个关键词建议数: {avg_strategies:.1f}")
# 显示最推荐的策略类型
from collections import Counter
all_strategies = []
for analysis in serp_analyses.values():
all_strategies.extend(analysis["strategies"])
strategy_counts = Counter(all_strategies)
print(f"• 最常推荐策略:")
for strategy, count in strategy_counts.most_common(3):
print(f" - {strategy}: {count}次")实际输出:
完整整合版(可直接运行)
python
import requests
import time
from collections import Counter
class SERPContentStrategy:
def __init__(self):
# IPIDEA代理配置
self.proxy_url = "http://YOUR_USERNAME:YOUR_PASSWORD@proxy.ipidea.io:2333"
self.proxies = {"http": self.proxy_url, "https": self.proxy_url}
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
}
def analyze_keywords(self, keywords):
"""分析多个关键词的SERP结构"""
print("SERP模块分析 - 内容策略指导")
print(f"使用IPIDEA代理: {self.proxy_url}")
# 数据采集阶段
print("\n阶段1: 数据采集")
serp_html_data = {}
for i, keyword in enumerate(keywords, 1):
print(f"[{i}/{len(keywords)}] 获取: {keyword}")
html = self.get_serp_html(keyword)
if html:
serp_html_data[keyword] = html
print(f" 成功 ({len(html)} 字符)")
else:
print(f" 失败,请检查代理配置")
time.sleep(2)
print(f"\n采集完成: {len(serp_html_data)}/{len(keywords)} 成功")
# 数据分析阶段
print("\n阶段2: 数据分析")
analyses = {}
for keyword, html in serp_html_data.items():
analysis = self.analyze_serp_structure(html, keyword)
analyses[keyword] = analysis
self.display_insight(analysis)
# 报告生成阶段
print("\n阶段3: 报告生成")
self.generate_final_report(analyses)
return analyses
def get_serp_html(self, keyword):
"""使用IPIDEA代理获取SERP页面"""
url = f"https://www.google.com/search?q={requests.utils.quote(keyword)}&gl=us&num=10"
try:
resp = requests.get(url, headers=self.headers, proxies=self.proxies, timeout=15)
return resp.text if resp.status_code == 200 else None
except Exception as e:
return None
def analyze_serp_structure(self, html, keyword):
"""分析SERP结构"""
html_lower = html.lower()
modules = {
"ads": min(html.count('Ad'), 10),
"shopping": any(word in html_lower for word in ['shop', 'buy', 'price']),
"videos": any(word in html_lower for word in ['youtube', 'video', 'watch']),
"news": any(word in html_lower for word in ['news', 'latest', 'update']),
"questions": min(html_lower.count('?'), 10),
"comparison": any(word in html_lower for word in ['vs', 'compare', 'comparison'])
}
strategies = self.generate_strategies(modules, keyword)
return {"modules": modules, "strategies": strategies, "keyword": keyword}
def generate_strategies(self, modules, keyword):
"""生成内容策略"""
strategies = []
if modules["ads"] >= 3:
strategies.append("制作购买指南和产品对比")
if modules["shopping"]:
strategies.append("创建产品评测和购买建议")
if modules["videos"]:
strategies.append("投资视频开箱或评测内容")
if modules["questions"] > 3:
strategies.append("制作FAQ解答用户问题")
if modules["comparison"]:
strategies.append("制作详细竞品对比分析")
# 关键词类型建议
if "review" in keyword:
strategies.append("创建深度产品评测内容")
if "unboxing" in keyword:
strategies.append("制作开箱视频和第一印象")
if "buying guide" in keyword:
strategies.append("制作购买建议和配置推荐")
if "setup" in keyword or "tutorial" in keyword:
strategies.append("制作详细设置教程")
if "vs" in keyword:
strategies.append("制作功能对比表格")
return strategies if strategies else ["创建综合信息内容"]
def display_insight(self, analysis):
"""显示分析洞察"""
modules = analysis["modules"]
print(f" {analysis['keyword']}: {modules['ads']}广告 | {modules['questions']}问题 | ", end="")
if modules["shopping"]: print("购物 ", end="")
if modules["videos"]: print("视频 ", end="")
if modules["news"]: print("新闻 ", end="")
if modules["comparison"]: print("对比 ", end="")
print(f"→ {' | '.join(analysis['strategies'][:2])}")
def generate_final_report(self, analyses):
"""生成最终报告"""
print("最终内容策略报告")
total_strategies = sum(len(analysis["strategies"]) for analysis in analyses.values())
avg_strategies = total_strategies / len(analyses) if analyses else 0
print(f"\n执行摘要:")
print(f" • 分析关键词: {len(analyses)} 个")
print(f" • 生成策略: {total_strategies} 条")
print(f" • 平均每个关键词: {avg_strategies:.1f} 条建议")
# 策略分布
all_strategies = []
for analysis in analyses.values():
all_strategies.extend(analysis["strategies"])
strategy_counts = Counter(all_strategies)
print(f"\n热门策略排名:")
for i, (strategy, count) in enumerate(strategy_counts.most_common(5), 1):
print(f" {i}. {strategy} ({count}次)")
print(f"\n分析完成! 建议优先执行排名前3的策略")
# 使用示例
if __name__ == "__main__":
analyzer = SERPContentStrategy()
keywords = [
"iPhone 17 Pro review",
"MacBook Air M4 unboxing",
"iPad Pro 2025 buying guide",
"Apple Watch Series 11 setup tutorial",
"AirPods Pro 4 vs Bose comparison"
]
results = analyzer.analyze_keywords(keywords)
print(f"\n所有任务完成! 共处理 {len(results)} 个关键词")通过这种方法,内容团队可以更科学地针对不同产品线来制作相应类型的内容,基于实际搜索数据制定策略,显著提高内容投资回报率。系统自动识别 SERP 特征,为每个产品线提供定制化建议,防止凭感觉决策。
除了自己抓取和解析 HTML,我们也可以直接使用 IPIDEA 的 SERP API。通过 API 获取的数据更稳定,减少了验证码和封锁的干扰,可以跨区域抓取不同国家的 SERP,也更方便持续监控趋势和生成分析报告。
使用 IPIDEA SERP API 获取搜索结果
步骤 1:获取 API 链接
在 IPIDEA 面板中选择 SERP API 功能

设置国家/地区、关键词、代理类型(动态住宅 IP 推荐)、每次返回条数等然后即可获取 Token。
点击生成 API 链接,例如:
ini
https://api.ipidea.net/serp?apikey=YOUR_API_KEY&q=python requests&gl=us&hl=en&num=10&proxy_type=dynamic步骤 2:使用 Python 请求 API
python
import http.client
from urllib.parse import urlencode
conn = http.client.HTTPSConnection("scraper.ipidea.net")
params = {
"url": "https://www.google.com/search",
"q": "pizza",
"json": "1"
}
payload = urlencode(params)
headers = {
'Authorization': 'Bearer token',
'Content-Type': 'application/x-www-form-urlencoded'
}
conn.request("POST", "/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))发送请求后,API 就可以返回 JSON/HTML 格式的输出结果。
总结
通过以上这两个实操示例,我们搭建了完整的 SERP 数据分析工作流。从基础的 PyPI 包信息监控到较为复杂的内容策略制定,将杂乱的搜索结果转化为了清晰的数据洞察。每个环节都提供了可运行的代码和实用的业务逻辑,让大家能够快速上手并应用到实际工作中。
在实际使用中,如果需要进行小规模的分析,手动采集和解析 HTML 是完全可行的方案。但如果业务需要大规模运行、希望减少验证码干扰,或者需要直接获取结构化 JSON 数据,建议还是使用专业的 SERP API 服务(如 IPIDEA 的 SERP API)。无论是手动抓取还是借助专业 API,核心目标都是将这些信息转化为统一的结构化数据,建立可复用、可监控的数据管线。
在营销竞争日益激烈的当下,你会发现单纯关注排名是远远不够的。真正重要的是理解搜索结果页面背后的用户意图------他们到底在寻找什么?市场上缺少什么内容?哪些内容形式更受欢迎?精准的内容策略方向比盲目的内容生产更重要。希望以上理论方法能帮助到大家用数据驱动决策,让每一份内容投入都产生真正的价值。