#模力方舟 #MoArk #GPU #租显卡 #模力方舟GPU体验官 #模力方舟GPU赛博名片 #国产GPU
随着大模型应用进入加速落地阶段,如何以更低门槛、更高效率获得稳定算力,成为团队与开发者的共识需求。
模力方舟近期上线的「算力市场」,提供即开即用、灵活计费的国产 GPU 实例,现已全面支持 沐曦 C500、燧原 S60 等多型号算力资源,最高 64GB 显存,按分钟计费,随用随开。
原 ai.gitee.com 启用了新的域名 moark.com/
快速体验一把国产算力的澎湃动力吧!
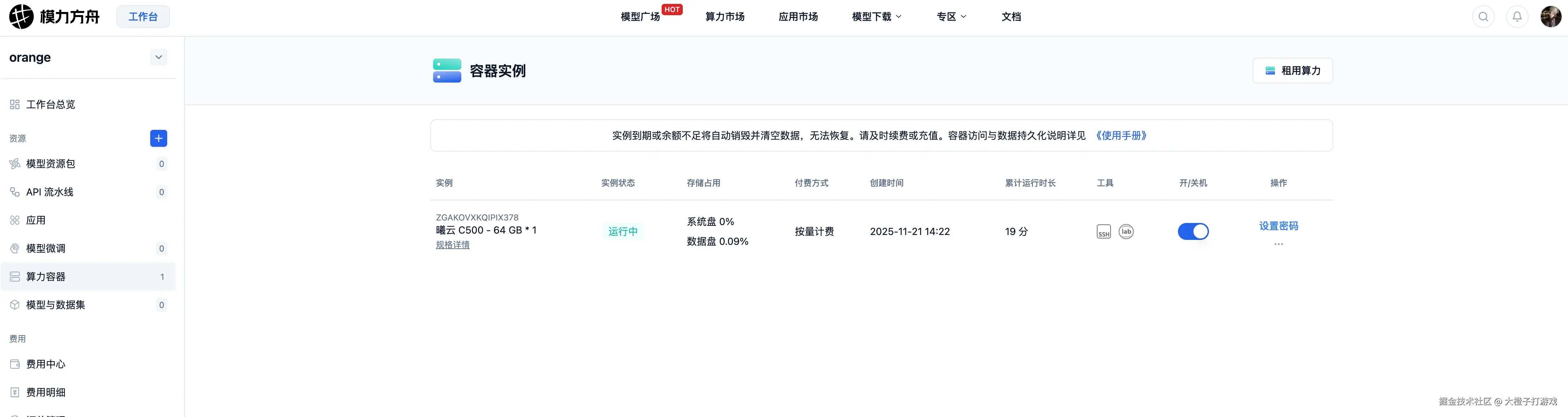
开机
以沐曦 曦云C500型号 为例,租用一张64GB,镜像选择 PyTorch / 2.6.0 / Python 3.10 / maca 3.2.1.3
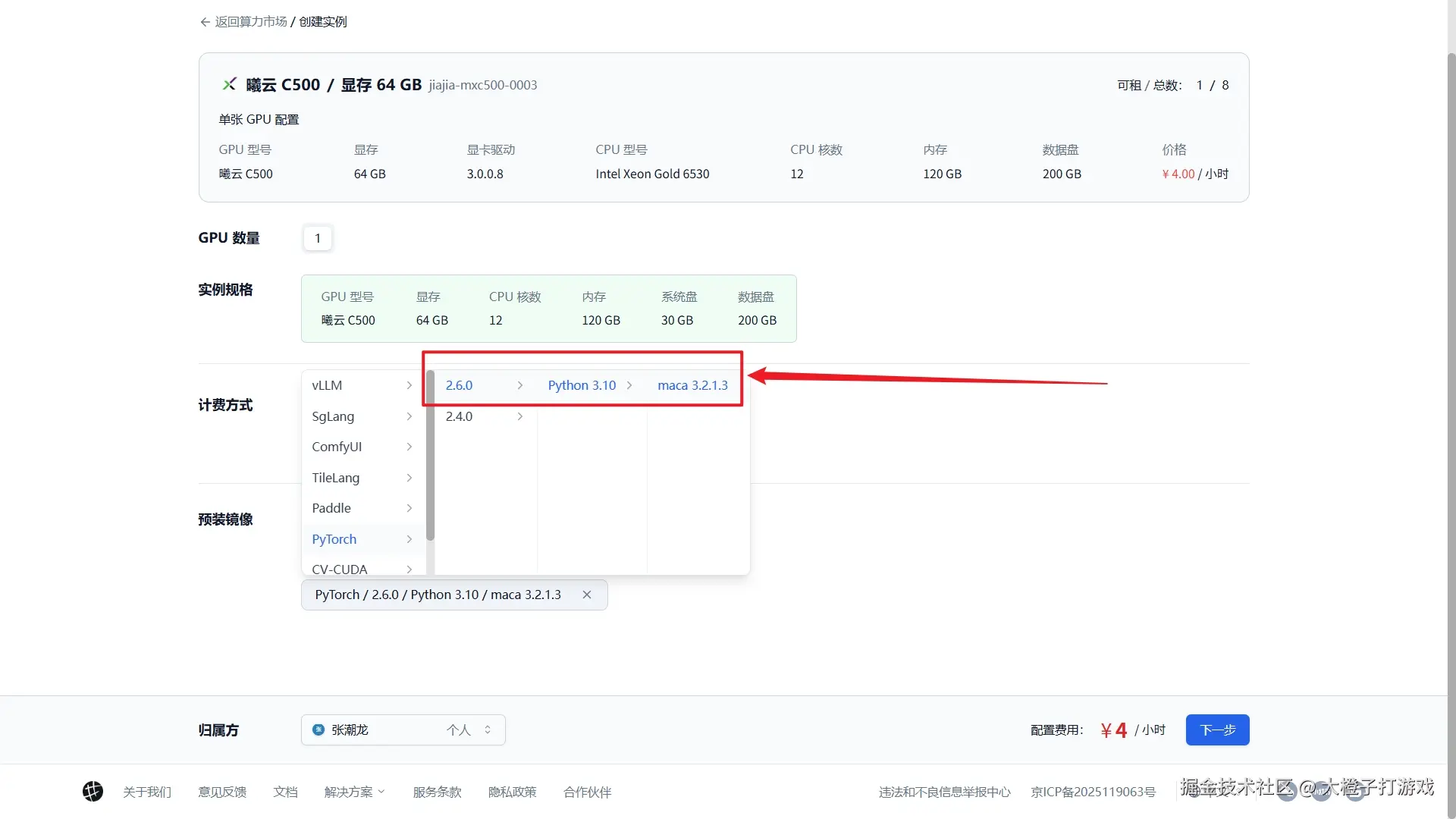
编写代码
点击选择Jupyterlab进入到容器当中并新建一个.ipynb文件
需要先行安装一下diffusers库
python
!pip install diffusers之后运行下列代码,自行修改生图提示词
python
from diffusers import DiffusionPipeline
import torch
#如果是沐曦的曦云C500,可使用内置的模型路径 /mnt/moark-models/Qwen-Image
model_name = "/mnt/moark-models/Qwen-Image"
# Load the pipeline
if torch.cuda.is_available():
torch_dtype = torch.bfloat16
device = "cuda"
else:
torch_dtype = torch.float32
device = "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
# Generate image
prompt = '''生图提示词在这里写'''
negative_prompt = " "
aspect_ratios = {
"1:1": (1328, 1328),
"16:9": (1664, 928),
"9:16": (928, 1664),
"4:3": (1472, 1140),
"3:4": (1140, 1472),
"3:2": (1584, 1056),
"2:3": (1056, 1584),
}
width, height = aspect_ratios["9:16"]
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=width,
height=height,
num_inference_steps=50,
true_cfg_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42)
).images[0]查看结果
之后将得到
内置模型
这个容器当中已经内置了很多模型,目录在/mnt/moark-models/Qwen-Image

命令行工具
在运行的过程中,可以使用mx-smi命令查看显存的占用情况
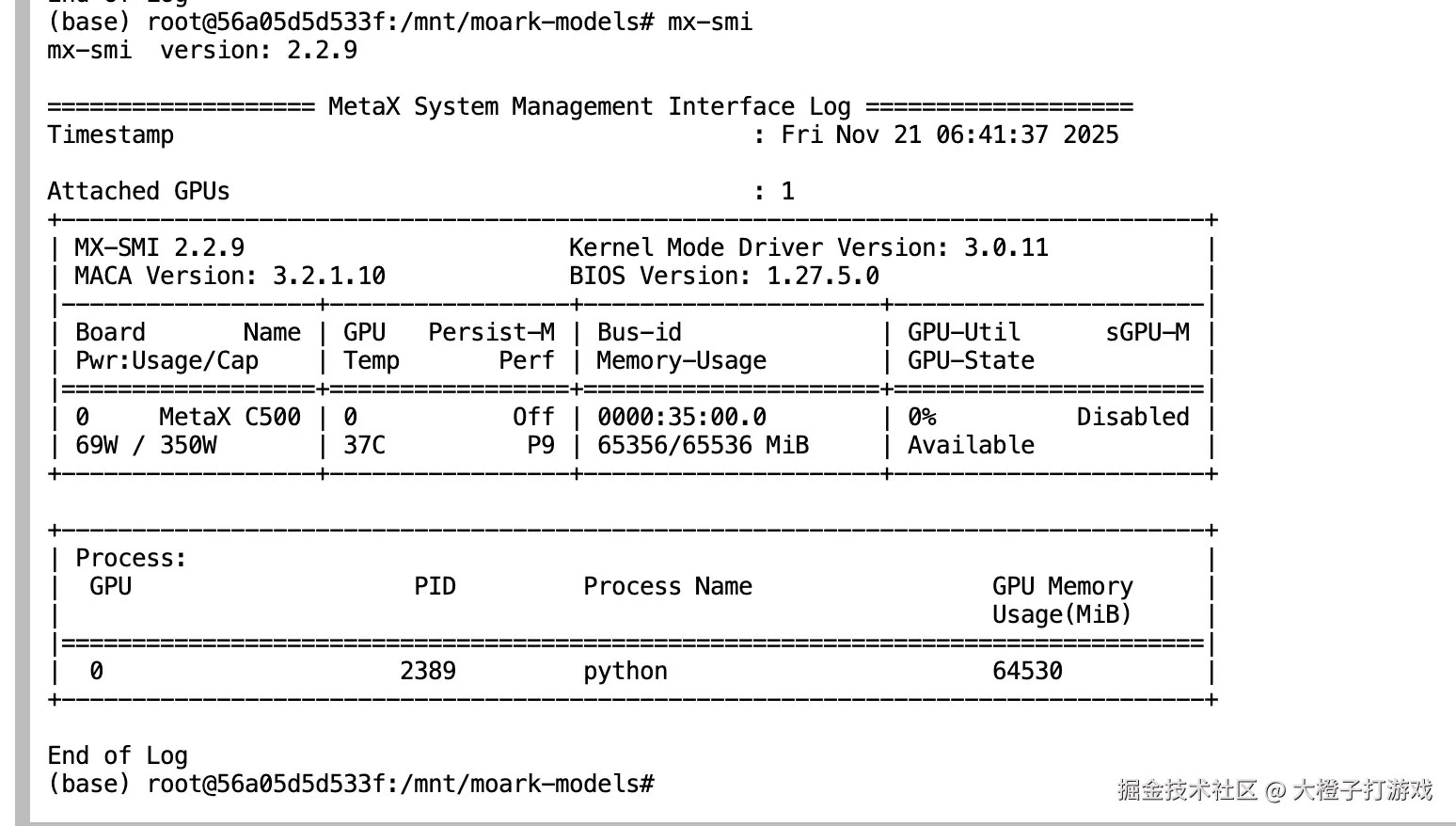
从开机到得到第一张图,大概就是一分钟左右两分钟的样子,真的很快,在科研、原型验证阶段,是非常好的帮手!