一、AI模型的生态与分类
1. 基础介绍
现在的模型平台虽然不多,但模型也如雨后春笋,日益爆发的增长,面对众多的模型选项,要做出正确的模型选择,首先需要全面理解这个生态系统的结构。现代AI模型可以按照功能特性、技术架构和应用场景三个维度进行分类,形成一个立体的技术选型空间。
从功能特性来看,AI模型主要分为三大类别:通用大语言模型、专业领域模型和基础能力模型。通用大语言模型如Qwen、ChatGLM、Baichuan等系列,具备强大的语言理解、生成和推理能力,适用于对话、创作、分析等通用场景。专业领域模型则针对特定任务深度优化,比如代码生成的CodeLLaMA、数学推理的Qwen-Math、多模态理解的Qwen-VL等。基础能力模型主要包括文本嵌入、重排序等,为更复杂的AI应用提供基础设施支持。
从技术架构角度,不同模型在参数量、层数、注意力机制等方面存在显著差异。参数量从几亿到上千亿不等,直接影响模型的能力边界和资源需求。层数决定了模型的深度和复杂度,序列长度限制了单次处理的文本范围,嵌入维度则影响语义表示的精细程度。这些技术指标共同构成了模型的技术特征图谱。
2. 模型分类
现代AI模型已经形成了完整的技术栈,理解这个体系是做出正确选择的基础。我们将AI模型分为三大类别:
2.1 通用大语言模型(LLM)
- **核心功能:**文本生成、对话交互、内容创作、逻辑推理
- 代表系列:
- Qwen系列(通义千问)
- ChatGLM系列(智谱AI)
- Baichuan系列(百川智能)
- InternLM系列(书生模型)
- GPT系列(OpenAI)
- LLaMA系列(Meta)
2.2 文本嵌入模型(Embedding Models)
- **核心功能:**语义理解、向量表示、相似度计算
- **技术特点:**将文本转换为高维向量,用于检索、聚类、分类
2.3 专业领域模型
- 代码生成模型(CodeLLaMA、Qwen-Coder)
- 数学推理模型(Qwen-Math)
- 多模态模型(Qwen-VL、VisualGLM)
- 语音模型(Whisper、Qwen-Audio)
3. ModelScope平台概述
ModelScope作为国内领先的模型开源社区,提供了完整的模型生命周期管理:
ModelScope平台的完整服务闭环:

- 发现阶段:帮助用户找到合适的模型资源
- 部署阶段:提供灵活多样的部署方案
- 评估阶段:确保模型选择的科学性和经济性
- 协作阶段:建立持续优化的社区生态
4. 单一模型的理解
通常我们在选定模型前,会先按我们的任务需求去找到对应模型列表,面对琳琅满目的模型列表,我们首先是进入到模型详细信息页面,了解模型相关的说明和一些常规指标,常用的指标包含了直观提示的模型说明
通过Qwen3 Embedding 系列模型列表提供的指标信息,我们初步了解每个指标的含义;
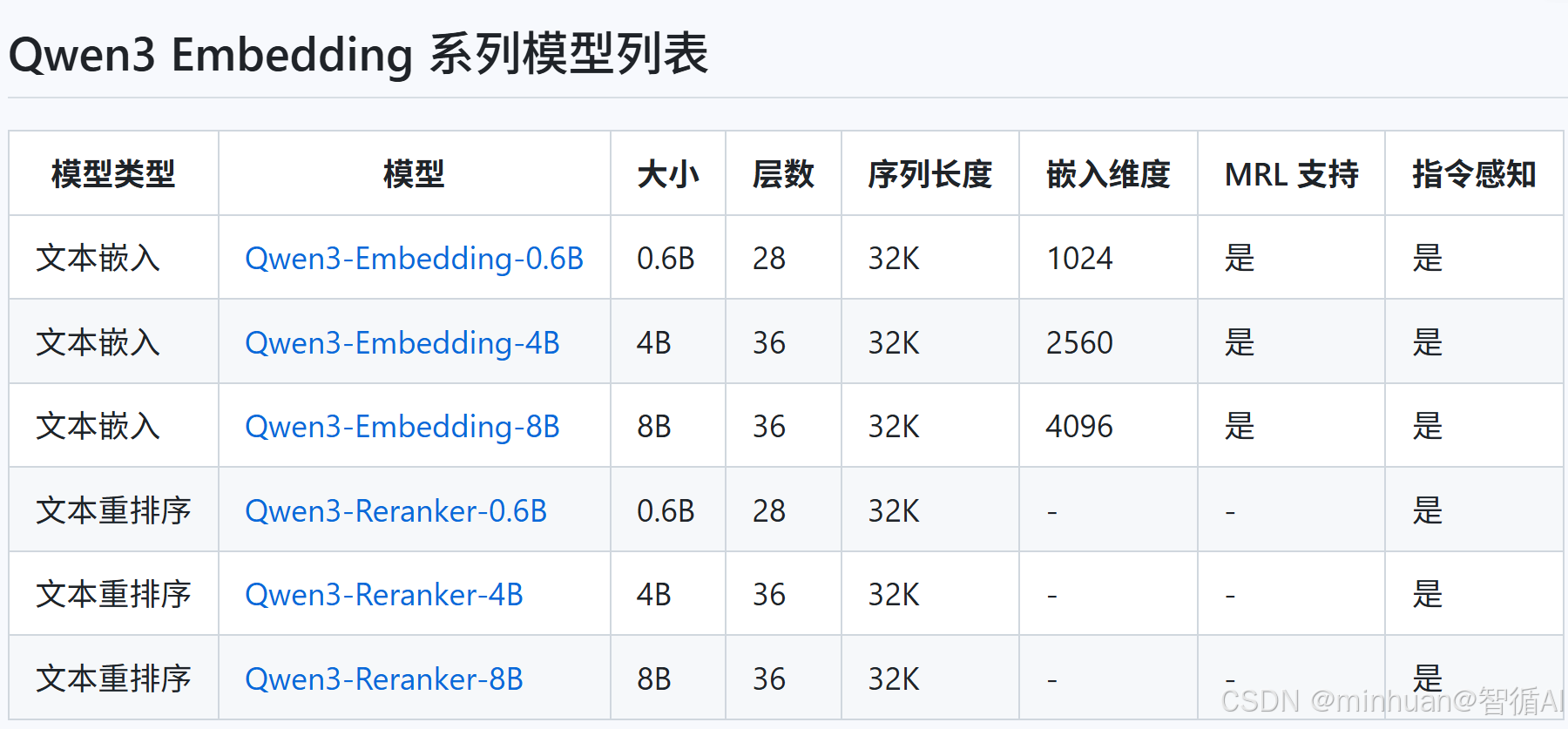
表格中有三种模型类型:文本嵌入(Text Embedding)和文本重排序(Text Reranker),我们详细解释每个指标,然后分别介绍这些模型的区别。
4.1 指标解释
- 模型类型
- **文本嵌入 (Text Embedding):**这类模型将文本转换为固定维度的向量表示。这些向量可以用于语义搜索、聚类、相似度计算等任务。
- **文本重排序 (Text Reranker):**这类模型用于对检索到的文档进行重新排序,以提高检索结果的相关性。它通常接收一个查询和多个文档,然后输出每个文档与查询的相关性分数。
- **模型 (Model):**模型的具体名称。
- **大小 (Size):**模型的参数量,以B(Billion)为单位。例如,0.6B表示6亿参数。
- **层数:**Transformer模型中的层数。层数越多,模型通常越复杂,表示能力越强。
- **序列长度:**模型一次性能处理的最大令牌数。序列长度越长,模型能处理的文本越长。
- **嵌入维度:**仅适用于文本嵌入模型,表示输出向量的维度。维度越高,能表示的信息越丰富,但计算和存储成本也越高。
- **MRL支持:**表示嵌入模型是否支持自定义最终嵌入的维度。
- **指令感知:**模型是否能够理解并遵循指令。对于嵌入模型,指令感知意味着模型可以根据不同的指令(例如,用于聚类、用于检索等)生成不同的向量表示。
4.2 模型区别
4.2.1 文本嵌入模型
文本嵌入模型用于将文本转换为向量,这些向量可以用于计算文本之间的相似度。表格中提供了三种规模的模型:0.6B、4B和8B。
- Qwen3-Embedding-0.6B:参数量0.6B,28层,序列长度32K,嵌入维度1024,支持MRL和指令感知。
- Qwen3-Embedding-4B:参数量4B,36层,序列长度32K,嵌入维度2560,支持MRL和指令感知。
- Qwen3-Embedding-8B:参数量8B,36层,序列长度32K,嵌入维度4096,支持MRL和指令感知。
如何选择:
- 如果计算资源有限,且对精度要求不高,可以选择0.6B模型。
- 如果需要更高的精度且资源充足,可以选择4B或8B模型。8B模型具有更高的嵌入维度,可能表示能力更强。
4.2.2 文本重排序模型
文本重排序模型用于对检索到的文档进行重新排序,以提高检索质量。它们不生成嵌入向量,而是直接对查询-文档对进行评分。
- Qwen3-Reranker-0.6B:参数量0.6B,28层,序列长度32K,支持指令感知(注意:重排序模型通常不需要嵌入维度,因为它们是直接输出分数的,所以表格中嵌入维度为"-")。
- Qwen3-Reranker-4B:参数量4B,36层,序列长度32K,支持指令感知。
- Qwen3-Reranker-8B:参数量8B,36层,序列长度32K,支持指令感知。
如何选择:
- 同样,根据计算资源和精度要求选择。较大的模型可能具有更好的性能,但需要更多的计算资源。
4.2.3 通用语言模型
通用语言模型主要用于理解和生成自然语言。它们可以用于对话、问答、文本生成等任务。其中:
- Base模型(如Qwen1.5-0.5B):经过预训练,包含丰富的语言知识,但未经过指令微调,适合作为基础模型进行微调或用于文本补全等任务。
- Chat模型(如Qwen1.5-0.5B-Chat):在Base模型的基础上经过指令微调,优化了对话交互,更适合直接与用户进行对话。
如何选择:
- 如果你需要构建一个对话系统,选择通用语言模型Chat版本。
4.3 使用场景
- 文本嵌入模型:适用于语义搜索、文档去重、聚类、推荐系统等。例如,将文档转换为向量后,可以通过向量相似度快速找到相关文档。
- 文本重排序模型:通常在检索系统(如使用BM25或嵌入模型进行初步检索)之后使用,对初步检索的结果进行重新排序,以提升Top结果的准确性。
二、业务场景需求分析
1. 业务目标与功能需求
选择AI模型的第一步是深入分析业务需求,将模糊的业务目标转化为具体的技术要求。这个过程需要系统性地考虑多个维度:
1.1 核心功能需求分析
需要明确回答:系统主要解决什么问题?是对话交互、内容创作、信息检索还是决策支持?例如,客服系统需要强大的多轮对话能力,知识管理系统则需要精准的检索和摘要功能。不同的功能需求对应着不同的模型能力要求。
1.2 性能指标量化
量化也是一个关键环节。需要明确界定响应时间、吞吐量、准确率等关键指标的具体要求。实时对话系统通常要求响应时间在2秒以内,而批量处理任务可能更关注吞吐量。这些量化指标直接影响后续的模型选择和部署方案。
1.3 用户体验考量
由于行业的差异性,很多行业特别是传统行业往往会不特别在意用户体验,容易被技术选型忽视,但实际上至关重要。包括交互的自然度、回答的准确度、错误处理的友好度等。例如,面向普通用户的系统需要模型具备更好的对话流畅性和解释能力,而面向专业人士的系统可能更注重回答的准确性和深度。
2. 约束条件评估
在明确需求后,需要系统评估各种约束条件:
2.1 技术约束
包括硬件资源、网络环境、部署条件等。GPU内存大小直接限制了可运行的模型规模,网络带宽影响云端服务的可行性,部署环境决定了对模型格式和推理引擎的要求,AI大模型比较不同的是对不同的型号的体量对硬件的要求也是相差甚远,所以准确的模型选择不仅是技术深度的考量,同时也是资金投入的权衡。
2.2 业务约束
涵盖响应时间、并发用户数、成本预算等运营指标。高并发场景需要选择推理效率更高的模型,严格的成本控制可能倾向选择较小规模的模型或特定的部署方案。
2.3 合规约束
在当下越来越重要,包括数据安全、隐私保护、行业规范等。金融、医疗等行业有严格的数据处理要求,需要选择支持本地部署的模型方案。
三、模型选型决策过程
1. 核心性能指标
模型的技术指标是选择决策的重要依据,但需要正确理解每个指标的实际意义:
1.1 参数量
- 参数量不仅影响模型能力,还直接关系到计算资源和推理速度。一般来说,参数量越大,模型的理解和生成能力越强,但同时也需要更多的计算资源和更长的推理时间。在实际选择时,需要在能力需求和资源约束之间找到平衡点。
1.2 序列长度
- 序列长度决定了模型单次处理的文本范围。长序列支持处理文档级别的输入,但会显著增加内存消耗和计算复杂度。选择时需要根据实际业务中典型输入的长度来确定合适的序列长度。
1.3 推理效率
- 推理效率包括延迟、吞吐量、并发能力等多个维度。这些指标不仅与模型本身相关,还与推理引擎、硬件配置等密切相关。在实际部署前,需要通过基准测试来验证实际性能表现。
2. 模型决策流程
开始选择
↓
主要任务类型?
├── 对话交互、内容创作、问答系统 → 选择通用语言模型
├── 语义搜索、文档检索、相似度计算 → 选择文本嵌入模型
└── 搜索结果优化、相关性排序 → 选择文本重排序模型
↓
通用语言模型细分:
├── 需要友好对话、用户体验重要 → Qwen1.5-0.5B-Chat
└── 技术任务、代码生成、需要原始输出 → Qwen1.5-0.5B
↓
文本嵌入模型细分:
├── 学习实验、资源有限 → Qwen3-Embedding-0.6B
├── 生产环境、平衡需求 → Qwen3-Embedding-4B
└── 高精度要求、专业应用 → Qwen3-Embedding-8B
↓
完成选择
3. 模型的决策策略
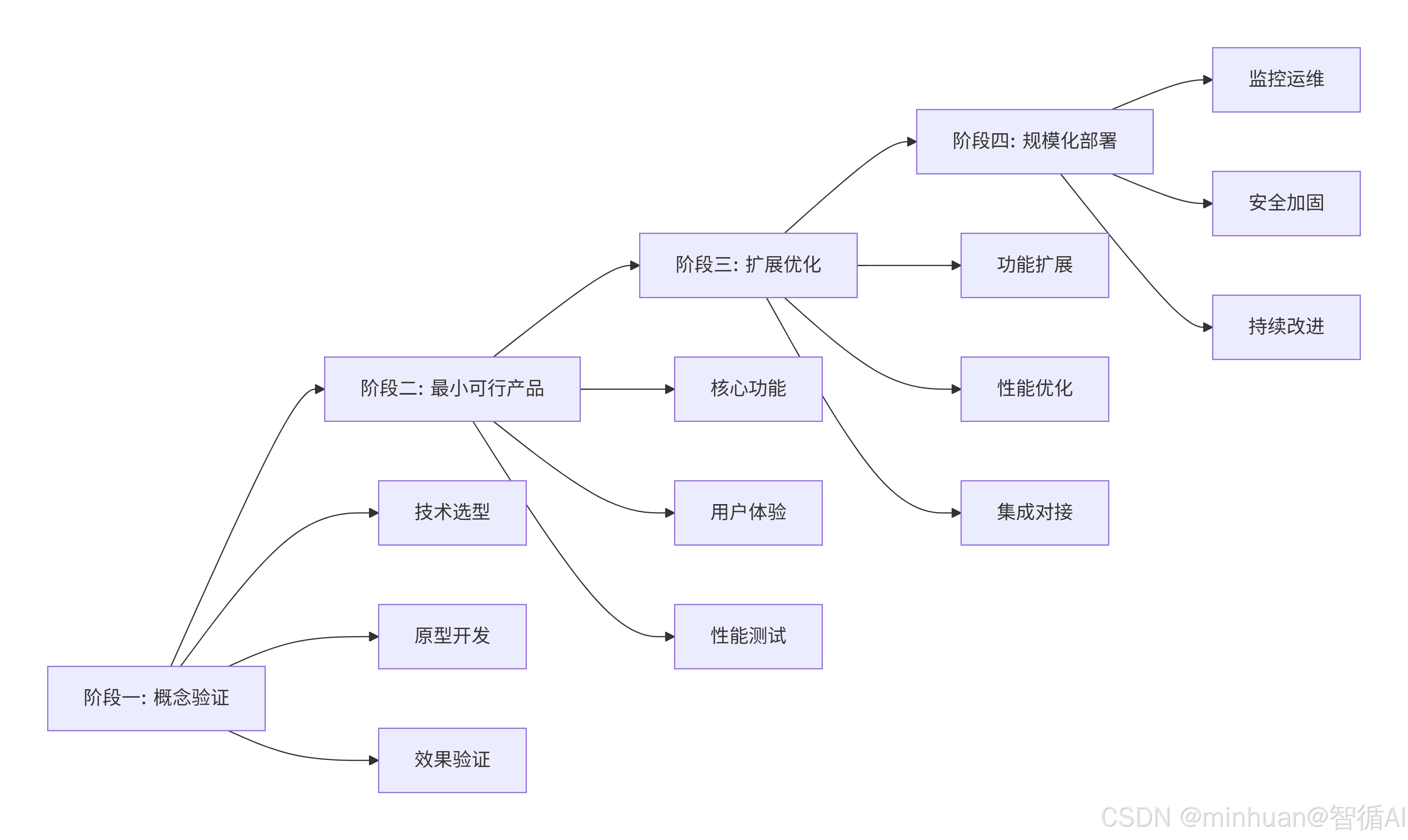
阶段详解:
阶段一:概念验证
- 核心目标:验证技术可行性,降低项目风险
- 关键活动:
- 技术选型:基于业务需求选择合适的AI模型和技术栈
- 原型开发:快速构建可演示的原型,验证核心想法
- 效果验证:通过小规模测试确认技术方案的有效性
- 产出成果:技术可行性报告、演示原型、初步效果数据
阶段二:最小可行产品
- 核心目标:构建具备核心功能的产品版本,获取用户反馈
- 关键活动:
- 核心功能:聚焦最关键的功能,避免过度开发
- 用户体验:确保产品易用性,收集用户使用反馈
- 性能测试:验证系统在真实环境下的表现
- 产出成果:可用的产品版本、用户反馈数据、性能基准报告
阶段三:扩展优化
- 核心目标:基于反馈完善产品,提升系统能力
- 关键活动:
- 功能扩展:根据用户需求增加新功能
- 性能优化:提升系统响应速度和稳定性
- 集成对接:与现有系统进行整合
- 产出成果:功能完善的产品、性能优化报告、系统集成方案
阶段四:规模化部署
- 核心目标:实现大规模稳定运行,建立持续改进机制
- 关键活动:
- 监控运维:建立完善的监控和运维体系
- 安全加固:增强系统安全性和可靠性
- 持续改进:基于数据驱动进行产品迭代
- 产出成果:生产环境系统、运维监控体系、持续改进流程
这个四阶段模型的主要优势:
- 风险控制:通过渐进式推进,避免一次性投入过大风险
- 快速验证:每个阶段都有明确的验证目标,及时调整方向
- 资源优化:根据阶段成果决定后续投入,提高资源利用效率
- 持续改进:建立从概念到产品的完整闭环,支持持续优化
四、典型场景的模型选择
1. 智能客服场景
在智能客服场景中,核心需求是准确理解用户问题并提供有用的回答。推荐选择中等规模的对话优化模型,如Qwen1.5-7B-Chat或ChatGLM3-6B。这些模型在保证响应速度的同时,提供了足够的知识和推理能力。
实际部署时,建议采用检索增强生成架构。使用嵌入模型构建知识库,通过检索相关文档来增强模型的回答准确性。这种架构既利用了模型的生成能力,又确保了信息的准确性。
2. 内容创作场景
内容创作场景对模型的创造性和语言质量要求较高。推荐选择较大规模的模型,如Qwen1.5-72B-Chat或Baichuan2-13B-Chat。这些模型在创意写作、文案生成等任务上表现更好。
针对不同类型的创作任务,需要调整生成参数。创意写作可以使用较高的温度参数增加多样性,技术文档写作则需要较低的温度参数确保准确性。
3. 知识管理场景
知识管理场景需要强大的检索和理解能力。推荐使用专门的嵌入模型,如Qwen3-Embedding系列,配合重排序模型提升检索质量。语言模型主要用于答案的生成和总结。
在架构设计上,建议采用分层检索策略。先使用嵌入模型进行粗筛,再用重排序模型进行精排,最后用语言模型生成答案。这种架构在保证质量的同时优化了系统性能。
五、总结
AI模型选择是一个涉及业务、技术、资源等多方面因素的复杂决策过程。通过系统化的分析框架和科学的选择流程,可以显著提高决策的质量和效率。
关键是要记住,没有最好的模型,只有最适合的模型。最佳选择来自于对业务需求的深刻理解、对技术能力的客观评估,以及对约束条件的现实考量。随着技术的快速发展和业务的不断变化,模型选择也应该是一个持续优化和迭代的过程。
附录:模型选择示例
1. 使用通用语言模型(Qwen1.5-0.5B-Chat)进行对话
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "Qwen/Qwen1.5-0.5B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
def chat_with_model(prompt):
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
print(chat_with_model("你好,请介绍一下你自己。"))2. 使用文本嵌入模型(以Qwen3-Embedding-0.6B为例)计算相似度
python
from transformers import AutoModel, AutoTokenizer
import torch
from sklearn.metrics.pairwise import cosine_similarity
model_name = "Qwen/Qwen3-Embedding-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
def get_embedding(text):
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model(**inputs)
return outputs.last_hidden_state[:, 0].cpu().numpy()
text1 = "今天天气真好"
text2 = "今天阳光明媚"
text3 = "编程很难"
emb1 = get_embedding(text1)
emb2 = get_embedding(text2)
emb3 = get_embedding(text3)
print("文本1和文本2的相似度:", cosine_similarity(emb1, emb2)[0][0])
print("文本1和文本3的相似度:", cosine_similarity(emb1, emb3)[0][0])3. 使用文本重排序模型(以Qwen3-Reranker-0.6B为例)对检索结果重排序
python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
model_name = "Qwen/Qwen3-Reranker-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
def rerank(query, documents):
scores = []
for doc in documents:
inputs = tokenizer(query, doc, return_tensors="pt", truncation=True, max_length=512).to(model.device)
with torch.no_grad():
outputs = model(**inputs)
score = torch.softmax(outputs.logits, dim=1)[0][1].item()
scores.append(score)
return scores
query = "什么是人工智能?"
documents = [
"人工智能是计算机科学的一个分支,旨在创造能够执行通常需要人类智能的任务的机器。",
"今天天气很好,适合出去散步。",
"人工智能包括机器学习、深度学习等技术。"
]
scores = rerank(query, documents)
for doc, score in zip(documents, scores):
print(f"文档: {doc} -> 相关性分数: {score}")