以下的习题解答均来自于图1,这里仅仅是为了加强对相关内容的理解,没有其它目的。

图1.
1-01 计算机网络可以向用户提供哪些服务?
这道题没有现成的标准答案,因为可以从不同的角度来看"服务"
首先要明确的是,计算机网络可以向用户提供的最重要的功能有两个:连通性和共享。所谓连通性,就是计算机网络使上网用户之间都可以交换信息,好像这些用户的计算机都可以彼此直接联通一样。用户之间的距离也似乎因此而变得更近了。所谓共享就是指资源共享。资源共享的含义是多方面的,可以是信息共享,软件共享,也可以是硬件共享。例如,计算机网络上有许多主机存储了大量有价值的电子文档,可供上网的用户自由读取或下载(无偿或有偿)。由于网络的存在,这些资源好像在用户身边一样。
我们知道,互联网允许分布式的应用程序运行在连接到网络上的端系统上。正是因为计算机网络有了上述的两项功能,这些应用程序才能够互相交换数据,因而能够向用户提供各种不同的服务。因此,计算机网络能够向用户提供各种不同的服务,其实也就是这些应用程序能够向用户提供各种不同的服务。
但是应当记住的是,计算机网络是一种基础设施,各种应用程序是在计算机网络之上运行的。由于新的应用程序不断出现,因此计算机网络能够向用户提供的服务也就不是固定不变的,而是不断地有新的服务出现。
目前,用户使用最多的网络服务有:电子邮件(传送信息、文件、图片、视频节目等),网上聊天,网上游戏,网上购物,网上转账,网上检索,远程教育,网上电视节目的播放,等等。
1-02 试简述分组交换的要点。
分组交换最主要的特点就是采用存储转发技术。
我们把要发送的整块数据称为一个报文。在发送报文之前,先把较长的报文划分成一个个更小的等长数据段,例如,每个数据段位1024bitbitbit。在每一个数据段前面,加上一些必要的控制信息组成的首部后,就构成了一个分组。分组又称为"包",而分组的首部也可以称为"包头"。分组是在互联网中传送的数据单元。分组中的"首部"是非常重要的,正是由于分组的首部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立地选择传输路径。
互联网的核心部分是由许多网络和把它们互联起来的路由器组成的,而主机处在互联网的边缘部分。主机是为用户进行信息处理的,并且可以和其他主机通过网络交换信息。路由器则是用来转发分组的(即进行分组交换)的。路由器每收到一个分组,先临时存储下来(这个存储的时间非常短暂),再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去,把这个分组转交给下一个路由器。这样一步一步地经过若干个或几十个不同的路由器,以存储转发的方式把分组交付最终的目的主机。各路由器之间必须经常交换彼此掌握的路由信息,以便创建和维护在路由器中的转发表,使得转发表能够在整个网络拓扑发生变化时及时更新。
1-03 试从多个方面比较电路交换、报文交换和分组交换的主要优缺点
电路交换的主要特点:
- 通信之前先要建立连接,通信完毕之后要释放连接。也就是说,通信一定要有三个阶段:建立连接、通信、释放连接。
- 在整个通信过程中,通信的双方自始至终占用着所使用的物理通道。
因此,对于计算机通信,由于计算机数据是突发性的,因此,从通信线路的利用率来考虑,电路交换的效率就比较低。此外,当通信双方占用的通信线路由很多段链路(通过若干个交换机把这些链路连通)组成时,只有在每一段链路都能接通(每一段链路都有空闲的信道资源还没有被其他用户占用,即有可用资源)时,整个的连接建立才能完成(哪怕只有一段链路没有空闲的信道可供使用,连接建立也无法完成)。当通信网的业务量很繁忙时,电路交换无法保证用户的每一个呼叫都能接通。如果第一阶段的连接建立不能完成,那么后续阶段的通信过程当然也就无法进行。
在电路交换的通信过程中,只要在整个连接中有一个环节(如某段链路或某个交换机)出了故障,那么整个连接就不复存在,接着就是通信的中断。若要重新进行通信,必须重新建立连接。如果能够绕过刚才的故障链路或故障交换机而建立新的连接,那么就可以开始新的通信。这就是说,电路交换系统不能自动从故障中进行恢复。
但电路交换有一个最主要的优点,就是只要连接能够建立,那么双方通信所需的传输带宽就已经分配好而不会再改变。这叫做静态分配传输带宽。通信双方愿意占用通信资源多久,就占用多久(对于公用网,只要按规定付费即可),而不受网络中的其他用户的影响。当网络发生拥塞时,网络中的其它用户很可能反复呼叫都无法建立连接,但这些动作都不会影响已经占用了通信资源的用户的通信质量(除非发生了通信网络中的故障,影响到正在进行通信的连接)。
目前最常用的分组交换使用无连接的IPIPIP协议。这种分组交换以分组作为传输的单位,采用存储转发技术,并且没有连接建立和连接释放这两个阶段,因此传送数据比较迅速。在传输数据的过程中,动态分配传输带宽,对通信链路是逐段占用的。这就是说,若某段链路的带宽较高,分组的传输速率就较快;若另一段链路的带宽较低,传输速率就较慢。不像电路交换那样,从源点到终点都是同样的传输速率。可见,分组交换能够比较合理而有效地利用各链路的传输带宽。
分组交换采用分布式的路由选择协议。当网络中的某个节点或链路出现故障时,分组传送的路由可以自适应地动态改变,使数据的传送能够继续下去。传送数据的源点和接收数据的终点甚至不会感觉到网络中所发生的故障。因此分组交换网络有很好的生存性。
分组交换也有一些缺点。例如,分组在各路由器存储转发时需要排队,这就会造成一定的时延。此外,由于分组交换无法确保通信时端到端所需的带宽,因此当分组交换网的通信量突然增大时,可能会在网络中的某处产生拥塞,从而延长数据的传送时间。当网络拥塞非常严重时,整个网络也可能会瘫痪。分组交换的另一个问题是各分组必须携带控制信息,这也就造成了一定的开销。整个分组交换网还需要专门的管理和控制机制。当然,电路交换网也需要网络管理,但电路交换网的交换机都具有很强的网络管理功能,能够对网络进行很有效地管理。分组交换网中的路由器比较简单,无法对整个网络进行管理。必须在网络中由专门的主机来运行专门的网络管理润软件,对整个网络进行管理。
报文交换也采用存储转发技术,不同的是,报文交换不再把报文划分为更小的分组,而是把整个报文在网络的节点中存储下来,然后再转发出去。这样做,省去了划分小的分组的步骤,也省去了在终点把分组重装成报文的过程。但报文交换在灵活性上不如分组交换,传送数据的时延较大。本来报文交换是用来传送电报的。现在已经很少有人打电报了,因此报文交换已经很少使用了。
1-04 为什么说互联网是自印刷术发明以来人类在存储和交换信息领域的重大变革?
自印刷术发明以来,使用书刊和报纸来传播信息,是人类通信的一个很大变革。
在印刷术出现之后,对人类通信起过重要作用的技术有很多,如电报、电话、传真、无线电通信、广播、电视、数字通信、卫星电话、蜂窝无线电通信等等。这些技术所起的作用,这里就不一一论述了。
但互联网出现后,互联网上的应用的确层出不穷,因而也就出现了许多重大的变革。下面可以通过一些例子来说明这个问题。
最早出现的电子邮件使人们可以非常方便而快捷地进行通信。电子邮件的大量使用,使得传统的电报业务(更贵、更慢,而且更不方便)基本上已无人使用。使用电子邮件,发件人可以非常方便地把同一邮件非常快捷地传递给很多远隔千里的友人。人们在互联网上发布自己创作的文章和视频,可以让成千上万的网民(这里有很多网民是我们并不认识的)在网上看到,而且基本上感觉不到有什么时间上的延迟。网上的IPIPIP电话既便宜通话质量又好,使得网民们能够随时和异地的友人在网上聊天,还可以进行网上地可视通信。如果愿意支付少量的费用(例如每分钟两美分),这种IPIPIP电话还能够直接拨打远隔重洋的固定电话。万维网的出现,大大地方便了广大网民上网。例如,当我们发现某个网站有很多有用的信息时,我们不必把这些信息一一传送给远地的友人,而是可以仅仅把该网址传送给这些友人,让他们自己上网查询和下载。这就比传统的通信方式效率高出很多。我们从网上还可以免费下载很多的电子图书和文章,大大加快了信息的广泛传播。这相当于一下子就免费得到了很多想看的书籍和文章。
以前当我们遇到一些问题(如见到一个不懂的新名词),我么可以打电话或写信向远地的老师或有人请教。而现在我们利用互联网的搜索引擎上网查询一下,就可以非常快地获得满意的答案。这显然比传统的通信方式进步了很多。
又如,以前大家都有排长队购买火车票的经历。但现在可以上网购买火车飘了,免除了亲自去火车票出售点排队的麻烦。由于采用了实名制购票,因此游客进站和出站都不需要出示火车票,而只需在所购买车次的检票口刷一下本人的有效身份证,即可完成相当于传统的检票过程。列车员查票时,旅客也只需出示有效身份证就行。这样就使得我们的出行更加方便。
互联网在金融、证券、网购、物流、管理等各行各业、各个领域中的应用,更是不胜枚举。
因此,仅仅从以上列举的一些方面就可看出,说互联网是自印刷术发明以来人类通信方面最大的变革,一点也不夸张。
1-05 互联网基础结构的发展大致分为哪几个阶段?请指出这几个阶段最主要的特点。
互联网的基础结构大体上经历了三个阶段的演进。但这三个阶段在时间划分上并非截然分开而是有部分重叠的,这是因为网络的演进是逐渐的而不是在某个日期突然发生的。
第一阶段是从单个网络ARPANETARPANETARPANET向互联网发展的过程。1969年美国国防部创建的第一个分组交换网ARPANETARPANETARPANET最初只是一个单个的分组交换网(并不是一个互联的网络)。所有要连接在ARPANETARPANETARPANET上的主机都直接与就近的节点交换机相连。但到了20世纪70年代中期,人们已认识到不可能仅使用一个单独的网络来解决所有的通信问题。于是ARPAARPAARPA开始研究多种网络(如分组无线电网络)互联的技术,这就导致了后来互联网的出现。这样的互联网就成为现在互联网(InternetInternetInternet)的雏形。1983年TCP/IPTCP/IPTCP/IP协议成为ARPANETARPANETARPANET上的标准协议,使得所有使用TCP/IPTCP/IPTCP/IP协议的计算机都能利用互联网相互通信,因而人们就把1983年作为互联网的诞生时间。1990年ARPANETARPANETARPANET正式宣布关闭,因为它的实验任务已经完成。
第二阶段的特点是建成了三级结构的互联网。从1985年起,美国国家科学基金会NSF(NationalScienceFoundation)NSF(National\quad Science\quad Foundation)NSF(NationalScienceFoundation)就围绕6个大型计算机中心建设计算机网络,即国家科学基金网(NSFNETNSFNETNSFNET)。它是一个三级计算机网络,分为主干网、地区网和校园网(或企业网)。这种三级计算机网络覆盖了全美国主要的大学和研究所,并且成为互联网中的主要组成部分。1991年,NSFNSFNSF和美国的其它政府机构开始认识到,互联网必将扩大其使用范围,不应仅限于大学和研究机构。世界上的许多公司纷纷接入到互联网,使网络上的通信量急剧增大,互联网的容量已满足不了需要。于是美国政府决定将互联网的主干网转交给私人公司来经营,并开始对接入到互联网的单位收费。1992年互联网上的主机超过100万台。1993年互联网主干网的速率提高到45Mbit/s45Mbit/s45Mbit/s(T3T3T3速率)。
第三阶段的特点是逐渐形成了多层次ISPISPISP结构的互联网。从1993年开始,由美国政府资助的NSFNETNSFNETNSFNET逐渐被若干个商用的互联网主干网替代,而政府机构不再负责互联网的运营。这样就出现了一个新的名词:互联网服务提供者ISP(InternetServiceProvider)ISP(Internet\quad Service\quad Provider)ISP(InternetServiceProvider)。在许多情况下,ISPISPISP就是一个从事商业活动的公司,因此ISPISPISP又常译为互联网服务提供商。ISPISPISP拥有从互联网管理机构申请到的多个IPIPIP地址,同时拥有通信线路(大的ISPISPISP自己建造通信线路,小的ISPISPISP则向电信公司租用通信线路)以及路由器等连网设备,因此任何机构和个人只要向ISPISPISP缴纳规定的费用,就可以从ISPISPISP得到所需的IPIPIP地址,并通过该ISPISPISP接入到互联网。我们通常所说的"上网"就是指"(通过某个ISPISPISP)接入到互联网",因为ISPISPISP向连接到互联网的用户提供了IPIPIP地址。IPIPIP地址的管理机构不会把一个单个的IPIPIP地址分配给单个用户(不"零售"IPIPIP地址),而是把一批IPIPIP地址有偿分配给经审查合格的ISPISPISP地址分配给单个用户(只"批发"IPIPIP地址)。从以上所讲的可以看出,现在的互联网已不是某个单个组织所拥有而是全世界无数大大小小的ISPISPISP所共同拥有的。
1-06 简述互联网标准制定的几个阶段。
制定互联网的正式标准要经过以下三个阶段:
- 互联网草案(InternetDraftInternet\quad DraftInternetDraft):互联网草案的有效期只有六个月。在这个阶段还不能算是RFCRFCRFC文档。
- 建议标准(ProposedStandardProposed\quad StandardProposedStandard):从这个阶段就开始成为RFCRFCRFC文档。
- 互联网标准(InternetStandardInternet\quad StandardInternetStandard):如果经过长期的检验,证明某个建议标准可以变成互联网标准时,就给它分配一个编号,记为STDxxSTDxxSTDxx,这里STDSTDSTD是"Standard"的英文缩写,而"xx"是标准的编号(有时也写成4位数编号,如STD0005STD0005STD0005)。一个互联网标准可以和多个RFCRFCRFC文档关联。
原先制定互联网标准的过程是:"建议标准"−>->−>"草案标准"−>->−>"互联网标准"。由于"草案标准"容易和成为RFCRFCRFC文档之前的"互联网草案"混淆,从2011年10月起取消了"草案标准"这个阶段RFC6410RFC\\quad 6410RFC6410。这样,现在制定互联网标准的过程简化为:"建议标准"−>->−>"互联网标准"。在新的规定以前就已发布的草案标准,将按照以下原则进行处理:若已达到互联网标准,就升级为互联网标准。对目前尚不够互联网标准条件的,则仍称为发布时的旧名称"草案标准"。
1-07 小写和大写开头的英文名字internetinternetinternet和InternetInternetInternet在意思上有何重要区别?
以小写字母iii开始的internetinternetinternet(互连网)是一个通用名词,它泛指由多个计算机网络互联而成的网络。这些网络之间的通信协议(即通信规则)可以是任意的。
以大写字母III开始的InternetInternetInternet(互联网或因特网)是一个专用名词,它指当前全球最大的、开放的、由众多网络相互连接而成的特定计算机网络,它采用TCP/IPTCP/IPTCP/IP协议族作为通信的规则,且其前身是美国的ARPANETARPANETARPANET。
1-08 计算机网络都有哪些类别?各种类别的网络都有哪些特点?
可以从不同的角度回答这个问题。
从网络的作用范围来划分,有:
- 广域网WANWANWAN,作用范围通常为几十到几千公里,有时也称为远程网。
- 城域网MANMANMAN,作用范围一般是一个城市,可跨越几个街区甚至整个城市,其作用距离约为5−>50KM5->50KM5−>50KM。
- 局域网LANLANLAN,作用范围局限在较小的范围(如1KM1KM1KM左右)。
- 个人区域网PANPANPAN,也常称为无线个人区域网WPANWPANWPAN,其作用范围大约在10米左右。
按照使用者来划分,有:
- 公用网,这是指电信公司(国有或私有)出资建造的大型网络。"公用"的意思就是所有愿意按电信公司的规定交纳费用的人都可以使用这种网络。因此公用网也可称为公众网。
- 专用网,这是某个部门为满足本部门的特殊业务工作的需要而建造的网络。这种网络不向本部门以外的人提供服务。例如,军队、铁路、电力、银行等系统均有本系统的专用网。
按照采用的交换技术来分,有:
- 电路交换网。
- 分组交换网。
- 混合交换网。
还有一种网络叫做接入网(ANANAN),用来把用户接入到互联网。接入网也叫做本地接入网。
1-09 计算机网络中的主干网和本地接入网的主要区别是什么?
计算机网络中的主干网是计算机网络核心部分的重要组成部分。主干网是由许多高速通信链路组成的,因而能够迅速地传送数据。主干网中还有许多路由器,能够把分组一步一步地转发到正确的目的地。本地接入网的作用仅仅是把用户接入到互联网。当然,接入网应当使用户可以更快地通过计算机网络可靠地下载文件和上传数据。
1-10 试在下列条件下比较电路交换和分组交换。要传送的报文总共xbitx\quad bitxbit。从源点到终点共经过kkk段链路,每段链路的传播时延为dsd\quad sds,数据率为 bbit/sb\quad bit/sbbit/s。在电路交换时电路的建立时间为sss\quad sss。在分组交换时,分组长度为pbitp\quad bitpbit,每个分组所必须添加的首部都很短,对分组的发送时延的影响在题中可以不考虑。此外,各节点的排队等待时间也可忽略不计。问在怎样的条件下,分组交换的时延比电路交换的要小?(提示:画一下草图观察kkk段链路共有几个节点。)
电路交换必须先建立连接,需要的时间是sss\quad sss。发送xbitx\quad bitxbit的报文所需的时间是报文长度除以数据率bbit/sb\quad bit/sbbit/s。因此发送时延是xb\frac{x}{b}bx。总的传播时延是链路数乘以每段链路的传播时延,即kdkdkd。因此,电路交换的时延由以上三项组成,即:s+xb+kds+\frac{x}{b}+kds+bx+kd。
分组交换时延的计算要稍微麻烦一点。请注意,分组经过kkk段链路,中间要经过k−1k-1k−1个节点的转发。这里可以简单的理解为最后一个分组的最后一个比特位到达最后一个节点所花的时间。从第一个分组的第一个比特位开始发送到最后一个分组的最后一个比特位开始发送所需的时间为⌈xp⌉×pb\lceil \frac{x}{p} \rceil \times\frac{p}{b}⌈px⌉×bp,这里⌈x⌉\lceil x \rceil⌈x⌉表示大于等于xxx的最小整数,当要传送的报文的总的比特数不是每个分组的比特数的整数倍时,最后一个分组里面的比特数就没有pbitp\quad bitpbit,这里为了简便,假设要传送的报文的总的比特数是每个分组的比特数的整数倍,因此这里采用了⌈x⌉\lceil x \rceil⌈x⌉运算操作。从最后一个分组的最后一个比特位在第一个节点发送出去之后到最后一个分组的最后一个比特位达到第二个节点需要的时间为dsd\quad sds。这里需要注意的是只有一个分组的所有比特位到达特定的节点之后才会开启针对其它节点的转发。
当最后一个分组的所有比特位到达第二个节点之后,它的所有比特位传输到第三个节点所需花的时间为pb+d\frac{p}{b} + dbp+d,因为一共需要经过kkk段链路,中间要经过k−1k-1k−1个节点的转发。因此以上过程重复k−1k-1k−1次之后最后一个分组的最后一个比特位可以到达最后一个节点。传输完成。因此这里分组交换总的时延为⌈xp⌉×pb+d+(k−1)×(pb+d)=kd+⌈xp⌉×pb+(k−1)×pb\lceil \frac{x}{p} \rceil \times\frac{p}{b}+d+(k-1)\times( \frac{p}{b} + d)=kd+\lceil \frac{x}{p} \rceil \times\frac{p}{b}+(k-1)\times \frac{p}{b}⌈px⌉×bp+d+(k−1)×(bp+d)=kd+⌈px⌉×bp+(k−1)×bp。
因此分组交换时延较电路交换时延小的条件为:
- kd+⌈xp⌉×pb+(k−1)×pb<s+xb+kdkd+\lceil \frac{x}{p} \rceil \times\frac{p}{b}+(k-1)\times \frac{p}{b}<s+\frac{x}{b}+kdkd+⌈px⌉×bp+(k−1)×bp<s+bx+kd,即⌈xp⌉×pb+(k−1)×pb<s+xb\lceil \frac{x}{p} \rceil \times\frac{p}{b}+(k-1)\times \frac{p}{b}<s+\frac{x}{b}⌈px⌉×bp+(k−1)×bp<s+bx。
当x≥px\geq px≥p时:
- ⌈xp⌉≈xp\lceil \frac{x}{p} \rceil \approx \frac{x}{p}⌈px⌉≈px
因此分组交换时延小于电路交换时延的条件是:(k−1)×pb<s(k-1)\times \frac{p}{b}<s(k−1)×bp<s。
1-11 在上题的分组交换网中,设报文长度和分组长度分别为 xxx和(p+h)bit(p+h) bit(p+h)bit,其中ppp为分组的数据部分的长度,hhh为每个分组所添加的首部长度,与ppp的大小无关。通信的两端共经过kkk段链路。链路的数据率为 bbit/sb\quad bit/sbbit/s,但传播时延和节点的排队时间均可忽略不计。若打算使总的时延为最小,问分组的数据部分长度ppp应取为多大?
本题实际上是假定了整个报文恰好可以划分为xp\frac{x}{p}px个分组。
现在每一个分组的发送时延是p+hb\frac{p+h}{b}bp+h,还有这里忽略了传播时延。因此这里总的时延为:
- D=xp×p+hb+(k−1)p+hb=xb+hxbp+(k−1)pb+(k−1)hbD=\frac{x}{p}\times \frac{p+h}{b}+(k-1)\frac{p+h}{b}=\frac{x}{b}+\frac{hx}{bp}+(k-1)\frac{p}{b}+(k-1)\frac{h}{b}D=px×bp+h+(k−1)bp+h=bx+bphx+(k−1)bp+(k−1)bh,求导可得:
- D′(p)=k−1b−xhb1p2D^{'}(p)= \frac{k-1}{b}-\frac{xh}{b}\frac{1}{p^2}D′(p)=bk−1−bxhp21
- D′′(p)=2xhb1p3D^{''}(p)= \frac{2xh}{b}\frac{1}{p^3}D′′(p)=b2xhp31
令D′(p)=k−1b−xhb1p2=0D^{'}(p)= \frac{k-1}{b}-\frac{xh}{b}\frac{1}{p^2}=0D′(p)=bk−1−bxhp21=0可得p=(hxk−1)p=\sqrt(\frac{hx}{k-1})p=( k−1hx),且可以看出D′′(p)D^{''}(p)D′′(p)在p=(hxk−1)p=\sqrt(\frac{hx}{k-1})p=( k−1hx)的取值时为正数。因此当p=(hxk−1)p=\sqrt(\frac{hx}{k-1})p=( k−1hx)时,DDD取极小值。

图.
分组长度有一个最佳值的物理意义是这样的:从下面的表达式可以看出,若分组很短,则下面的表达式的右端的第一项将增大。这表示分组数组很大会导致每个分组的控制信息所引起的延时增大。但若分组很长,则该表达式右端第二项将增大。因此,分组的长度不宜太短或太长。
- D=xp×p+hb+(k−1)p+hb=(xb+hxbp)+(k−1)p+hbD=\frac{x}{p}\times \frac{p+h}{b}+(k-1)\frac{p+h}{b}=(\frac{x}{b}+\frac{hx}{bp})+(k-1)\frac{p+h}{b}D=px×bp+h+(k−1)bp+h=(bx+bphx)+(k−1)bp+h
1-12 互联网的两大组成部分(边缘部分与核心部分)的特点是什么?它们的工作方式各有什么特点?
互联网的拓扑结构非常复杂,并且在地理上覆盖了全球,但从其工作方式上看,可以划分为以下两大块:
- 边缘部分:由所有连接在互联网上的主机组成。这部分是用户直接使用的,用来进行通信(传送数据、音频或视频)和资源共享。
- 核心部分:由大量网络和连接在这些网络的路由器组成。这部分是为边缘部分提供服务的(提供连通性和交换)。
在网络边缘的端系统之间的通信方式通常可划分为两类:客户-服务器方式(C/SC/SC/S方式)和对等方式(P2PP2PP2P方式)。这两种通信方式的区别见习题1−131-131−13。
在网络核心部分起作用的是路由器。路由器是实现分组交换的关键构件,如果没有路由器,再多的网络也无法构建成互联网。由此可以看出,互联网的核心部分的工作方式其实也就是路由器的工作方式。
路由器的任务是转发收到的分组。当路由器转发分组时,必须查找路由表。因此,互联网中的各路由器必须根据路由选择协议的规定相互交换路由信息,以便使路由表能够及时反映出网络拓扑的变化。
由此可见,互联网的核心部分的工作方式有两种:一种是路由器转发分组(这是直接为主机之间的通信服务的),另一种是路由器之间不断地交换路由信息(这是为了保证路由表的路由信息与网络的实际拓扑一致)。
1-13 客户-服务器方式与P2PP2PP2P对等通信方式的主要区别是什么?有没有相同的地方?
客户-服务器方式所描述的是进程之间服务和被服务的关系。客户是服务请求方,服务器是服务提供方。服务请求方和服务提供方都要使用网络核心部分所提供的服务。
客户程序被用户调用后运行,在通信时主动向远程服务器发起通信(请求服务)。因此客户程序必须知道服务器程序的地址。客户程序不需要特殊的硬件和很复杂的操作系统。服务器程序是一种专门用来提供某种服务的程序,可同时处理多个远地或本地的用户请求。服务器程序在系统启动后即自动调用并一直不断地运行着,被动地等待并接收来自各地的客户的通信请求。因此,服务器程序不需要知道客户程序的地址,并且一般需要有强大的硬件和高级的操作系统支持。
客户与服务器的的通信关系建立后,通信可以是双向的,客户和服务器都可发送和接收数据。
对等连接(或P2PP2PP2P方式)是指两个主机在通信时并不区分哪一个是服务请求方哪一个是服务提供方。只要两个主机都运行了对等连接软件(P2PP2PP2P软件),它们就可以进行平等的对等连接通信。
实际上,对等连接方式从本质上看依然使用客户-服务器方式,只是对等连接中的每一个主机既是客户又是服务器。
1-14 计算机网络有哪些常用的性能指标?
计算机网络常用的性能指标如下:
- 速率:指的是连接在计算机网络上的主机在数字信道上传送数据的速率,也称为数据率或比特率。
- 带宽:用来表示网络的通信线路传送数据的能力,网络带宽表示在单位时间内(一般是每秒钟)从网络的某一点到另一点所能通过的"最高数据率"。
- 吞吐量:表示在单位时间内(一般是每秒钟)通过某个网络(或信道、接口)的数据量。
- 时延:指数据(一个报文或分组、甚至比特)从网络(或链路)的一端传送到另一端所需的时间。时延包括发送时延、传播时延、处理时延和排队时延等。
- 时延带宽积:是传播时延sss和带宽bit/sbit/sbit/s的乘积。链路的时延带宽积又称为以比特为单位的链路长度。
- 往返时间:表示从发送方发送数据开始,到发送方收到来之接收方的确认(接收方收到数据之后便立即发送确认),总共经历的时间。有时,往返时间还包括网络各中间节点的处理时延、排队时延以及转发数据时的发送时延。
- 利用率:分信道利用率和网络利用率两种。信道利用率指出某信道有百分之几的时间是被利用的(由数据通过)。完全空闲的信道的利用率为0。网络利用率则是全网络的信道利用率的加权平均值。
1-15 假定网络的利用率达到了90%90\%90%,试估算一下现在的网络时延是它的最小值的多少倍?
根据教材中的公式(1−5)(1-5)(1−5),DD0=11−U\frac{D}{D_0}=\frac{1}{1-U}D0D=1−U1,这里DDD表示网络当前的时延,D0D_0D0表示网络空闲时的时延,UUU表示网络当前的利用率,此时U90%U90\%U90%。因此此时DD0=11−0.9=10.1=10\frac{D}{D_0}=\frac{1}{1-0.9}=\frac{1}{0.1}=10D0D=1−0.91=0.11=10,也就是现在的网络时延是最小值的10倍。
1-16 计算机通信网有哪些非性能特征?非性能特征与性能指标有什么区别?
计算机通信网的非性能特征友以下一些:
- 费用
- 质量
- 标准化
- 可靠性
- 可扩展性和可升级性
- 易于管理和维护
非性能特征与性能指标的主要区别就是:性能指标是直接反应网络性能的,而非性能指标则不是网络所特有的指标。例如,非性能指标中的费用,在所有的工程项目中都存在费用的问题。所以费用不能说是网络的性能指标。然而一般说来,网络的速率越高,其价格也越高。当我们要求网络的速率非常高时,其费用就可能达到我们不能承受的数值,而且使我们无法实现这样的性能。也就是说,有时网络的非性能特征能够制约网络性能指标的实现。再例如,某个网络的性能指标都很不错,但很不便于管理和维护,那么这种网络可能就不宜选用。
1-17 收发两端之间的传输距离为1000kmkmkm,信号在媒体上的传播速率为2×108m/s2\times 10^{8}m/s2×108m/s。试计算以下两种情况的发送时延和传播时延:
- 数据长度为107bit10^7bit107bit,数据发送速率为100kbit/s100kbit/s100kbit/s
- 数据长度为103bit10^3bit103bit,数据发送速率为1Gbit/s1Gbit/s1Gbit/s
两种情况分别计算如下:
- 发送时延为107bit/(100kbit/s)=100s10^7bit/(100kbit/s)=100s107bit/(100kbit/s)=100s,传播时延为106m/(2×108m/s)=5ms10^6m/(2\times 10^{8}m/s)=5ms106m/(2×108m/s)=5ms,发送时延大于传播时延。
- 发送时延为103bit/(1Gbit/s)=1us10^3bit/(1Gbit/s)=1us103bit/(1Gbit/s)=1us,传播时延为106m/(2×108m/s)=5ms10^6m/(2\times 10^{8}m/s)=5ms106m/(2×108m/s)=5ms,传播时延大于发送时延。
因此,若数据长度大而发送速率低,则在总的时延中,发送时延往往大于传播时延。但若数据长度短而发送速率高,则传播时延又可能是总时延中的主要成分。
1-18 假设信号在媒体上的传播速率为2.3×108m/s2.3\times 10^{8}m/s2.3×108m/s。媒体长度lll分别为:
- 10cm10cm10cm(网络接口卡)
- 100m100m100m(局域网)
- 100km100km100km(城域网)
- 5000km5000km5000km(广域网)
现在连续传送数据,数据率分别为1Mbit/s1Mbit/s1Mbit/s和10Gbit/s10Gbit/s10Gbit/s.试计算每一种情况下在媒体中的比特数。(提示:媒体中的比特数实际上无法使用仪表测量。本题是假想我们能够看见媒体中正在传播的比特,能够给媒体中的比特拍个快照。媒体中的比特数取决于媒体的长度和数据率。)
计算步骤如下:
- 先计算10cmcmcm(即0.1mmm)的媒体上信号的传播时延:0.1m/(2.3×108m/s)=4.3478×10−10s≈4.35×10−10s0.1m/(2.3\times 10^{8}m/s)=4.3478\times 10^{-10}s\approx4.35\times 10^{-10}s0.1m/(2.3×108m/s)=4.3478×10−10s≈4.35×10−10s,再计算10cmcmcm线路上正在传播的比特数:
- 1Mbit/s1Mbit/s1Mbit/s速率时为:1Mbit/s×4.35×10−10s=4.35×10−4bit1Mbit/s\times 4.35\times 10^{-10}s=4.35\times 10^{-4}bit1Mbit/s×4.35×10−10s=4.35×10−4bit,读者应该正确理解在线路上只有0.0004350.0004350.000435个比特到底是什么意思?
- 1Gbit/s1Gbit/s1Gbit/s速率时为:1Gbit/s×4.35×10−10s=4.35bit1Gbit/s\times 4.35\times 10^{-10}s=4.35\quad bit1Gbit/s×4.35×10−10s=4.35bit,对于后面的几种情况,计算方法都是一样的。计算结果如下表所示:
| 媒体长度l | 传播时延 | 媒体中的比特数(1Mbit/s1Mbit/s1Mbit/s) | 媒体中的比特数(1Gbit/s1Gbit/s1Gbit/s) | |
|---|---|---|---|---|
| 1 | 0.1mmm | 4.35×10−10s4.35\times 10^{-10}s4.35×10−10s | 4.35×10−44.35\times 10^{-4}4.35×10−4 | 4.354.354.35 |
| 2 | 100mmm | 4.35×10−7s4.35\times 10^{-7}s4.35×10−7s | 0.4350.4350.435 | 4.35×1034.35\times 10^{3}4.35×103 |
| 3 | 100km | 4.35×10−4s4.35\times 10^{-4}s4.35×10−4s | 4.35×1024.35\times 10^{2}4.35×102 | 4.35×1064.35\times 10^{6}4.35×106 |
| 4 | 5000km | 0.0217s0.0217s0.0217s | 2.17×1042.17\times 10^{4}2.17×104 | 2.17×1082.17\times 10^{8}2.17×108 |
1-19 长度为100字节的应用层数据交给运输层传送,需加上20字节的TCPTCPTCP首部。再交给网络层传送,需加上20字节的IPIPIP首部。最后交给数据链路层的以太网传送,加上首部和尾部共18字节。试求数据的传输效率。数据的传输效率是指发送的应用层数据除以所发送的总数据(即应用数据加上各种首部和尾部的额外开销)。若应用层数据长度为1000字节,数据的传输效率是多少?
数据长度为100字节时,以太网的帧长为100+20+20+18=158100+20+20+18=158100+20+20+18=158字节,因此数据传输效率为100158=63.29%\frac{100}{158}=63.29\%158100=63.29%。数据长度为1000字节时,以太网的帧长为1000+20+20+18=10581000+20+20+18=10581000+20+20+18=1058字节,因此数据传输效率为10001058=94.25%\frac{1000}{1058}=94.25\%10581000=94.25%。传输效率明显提高了。
1-20 网络体系结构为什么要采用分层次的结构?试举出一些与分层体系结构的思想相似的日常生活的例子。
网络体系结构采用分层次的结构,是因为"分层"可以把庞大而复杂的问题转化为若干较小的局部问题,而这些较小的局部问题比较容易研究和处理。
在日常生活中,经常会遇到与分层体系结构的思想相似的情况。例如,AAA有一个急件要尽快地交付到远地(例如,在美国)的友人BBB。如果AAA自己买机票亲自去送,那么这就是一个不分层的交付。
但是我们可以请快递公司帮我们做这件事。这样就有了两个层次,如图2所示

图2.两个层次的快件传送
像这样的层次划分方法并不是唯一的。我们还可以把快递公司这一层再划分的细一些。例如,快递公司可以雇用业务员到发件人AAA的家中收取快件,然后汇总起来交给运输部门。运输部门把快件运送到终点。快递公司同样雇用业务员 把快递送到收件人BBB的家中。这种层次的划分对顾客来说完全是透明的。发件人AAA把快件交给快递公司的业务员以后,就不用管快递公司内部的事了。AAA就是把业务员看成是快递公司。图3表示了这种情况。

图3.三个层次的快件传送
实际上快递公司还可以继续划分自己公司的层次。更重要的是,快递公司可以使用非本公司的运输工具。也就是说,把快件的运输交给其它公司来承担。而这一点对用户AAA和BBB来说,都是透明的。用户AAA和BBB并不知道快件是由那个运输部门传送的(也不必要知道)。这就是分层带来的好处。
总之,划分层次可以把复杂的问题划分成多个比较简单的较小的问题。这样做实现起来比较方便,也比较容易分工协作。
1-21 协议与服务有何区别?有何联系?
为进行网络中的数据交换而建立的规则、标准或约定称为网络协议,简称为协议。网络协议是计算机网络不可缺少的组成部分。
协议是控制两个对等实体(或多个实体)进行通信的规则的集合。协议的语法方面的规则定义了所交换的信息的格式,而协议的语义方面的规则定义了发送者或接收者所要完成的操作。
在协议的控制下,两个对等实体间的通信使得本层能够向上一层提供服务。要实现本层协议,还需要使用下面一层所提供的服务。
协议和服务在概念上是很不一样的:
- 首先,协议的实现保证了能够向上一层提供服务。使用本层服务的实体只能看见服务而无法看见下面的协议。下面的协议对上面的实体是透明的。
- 其次,协议是"水平的",即协议是控制对等实体之间通信的规则。但服务是"垂直的",即服务是由下层向上层通过层间接口提供的。另外,并非在一个层内完成的全部功能都称为服务,只有哪些能够被高一层实体"看得见"的功能才能称为"服务"。
1-22 网络协议的三个要素是什么?各有什么含义?
网络协议主要由以下三个要素组成:
- 语法,即数据与控制信息的结构或格式
- 语义,即需要发出何种控制信息,完成何种动作以及做出何种相应。
- 同步,即事件实现顺序的详细说明。
1-23 为什么一个网络协议必须把各种不利的情况都考虑到?
如果一个网络协议只考虑了一些正常的、有利的情况,那么当各种情况都很正常时,这种协议当然能够正常的工作。但是情况不可能永远都是正常的,总有一些时候会出现异常情况。我们知道,出现异常情况的概率一般是不大的,但这并非绝对不可能出现。因此,如果网络协议没有考虑到一些不利情况(这些当然都是小概率事件),那么一旦这些不利情况出现,协议就会失败。
1-24 试述具有五层协议的网络体系结构的要点,包括各层的主要功能。
我们知道,OSIOSIOSI的体系结构是七层协议。TCP/IPTCP/IPTCP/IP的体系结构是四层协议,而真正有具体内容的只是上面三层。在学习计算机网络的原理时往往采取折中的办法,即综合OSIOSIOSI和TCP/IPTCP/IPTCP/IP的优点,采用一种有五层协议的体系结构。如图4所示
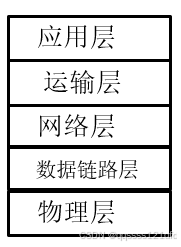
图4.
这五层协议的主要功能如下:
- 物理层:在物理层上所传数据的单位是比特。物理层的任务就是透明地传送比特流。物理层还要确定连接电缆的插头应当有多少根引脚以及各条引脚应如何连接。当然,那几个比特代表什么意思,则不是物理层所要管的。请注意,传递信息所利用的一些物理媒体,如双绞线、同轴电缆、光缆、无线信道等,并不在物理层协议之内而是在物理层协议的下面。因此也有人把物理媒体当做第0层。
- 数据链路层:常简称为链路层。在两个相邻节点之间(主机和路由器之间或路由器和路由器之间)传送数据是直接发送的(即不需要经过转发的点对点通信)。这时就需要使用专门的链路层协议。数据链路层将网络层交下来的IPIPIP数据报装成帧,在两个相邻节点之间的链路上"透明"地传送帧中的数据。每一帧包括数据和必要的控制信息(如同步信息、地址信息、差错控制等)。在接收数据时,控制信息使接收端能够知道一个帧从那个比特开始到那个比特结束。这样,数据链路层在收到一个帧后,就可从中提取出数据部分,上交给网络层。控制信息还使接收端能够检测到所收到的帧中有无差错。如发现有差错,数据链路层就简单地丢弃这个出了差错的帧,以免继续传送下去白白浪费网络资源。如果需要改正错误,就由运输层的TCPTCPTCP协议来完成。
- 网络层:网络层负责为分组交换网上的不同主机提供通信服务。在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组或包进行发送。在TCP/IPTCP/IPTCP/IP体系中,由于网络层使用IPIPIP协议,因此分组也叫做IPIPIP数据报,简称为数据报。网络层的另一个任务就是选择合适的路由,使源主机运输层所传下来的分组能够通过网络中的路由器找到目的主机。对于由广播信道构成的分组交换网,路由选择的问题很简单,因此这种网络的网络层非常简单,甚至可以没有。
- 运输层:运输层的任务就是向两个主机中进程之间的通信提供服务。由于一个主机可同时运行多个进程,因此运输层有复用和分用的功能。复用就是多个应用层进程同时使用下面运输层的服务,分用则是运输层把收到的信息分别交付上面应用层中相应的进程。运输层主要使用以下两种协议:一个是传输控制协议TCPTCPTCP,是面向连接的,数据传输的单位是报文段,能够提供可靠的交付。另一个是用户数据报协议UDPUDPUDP,是无连接的,数据传输的单位是数据报,不保证提供可靠的交付,只能提供"尽最大努力交付"。
- 应用层:应用层是体系结构中的最高层。应用层直接为用户的应用进程提供服务。这里的进程就是指正在运行的程序。互联网中的应用层协议很多,如支持万维网应用的HTTPHTTPHTTP协议、支持电子邮件的SMTPSMTPSMTP协议、支持文件传送的FTPFTPFTP协议,等等。
1-25 试举出日常生活中有关"透明"这一名词的例子。
"透明"表示:某一个实际存在的事物看起来却好像不存在一样(例如,你看不见在你前面100%100\%100%透明的玻璃的存在)。"在数据链路层透明的传送数据"表示无论什么样的比特组合的数据都能够通过这个数据链路层。因此,对所传送的数据来说,这些数据就"看不见"数据链路层。或者说,数据链路层对这些数据来说是透明的。
在日常生活中,打电话就是一种透明传输。假定AAA和BBB通电话。AAA说,BBB听。AAA所发送的所有话音信号,都能通过电话传输系统传送到BBB。只要是符合电话传输标准的电话系统,BBB都能听清楚AAA所说的话。
又如,银行给储户的利息是非常透明的。这就是说,根据银行的公告,储户就能够很准确地知道自己将能够获得多少利息(取决于储户存款的种类和期限)。但银行如何处理储户的存款(贷款给什么人?投资到什么地方去?),则是对储户不透明的,即储户看不见这些信息,好像被什么东西挡住了。
1-26 试解释以下名词:协议栈、实体、对等层、协议数据单元、服务访问点、客户、服务器、客户-服务器方式。
名词解释含义如下:
- 协议栈:由于计算机网络的体系结构采用了分层结构,因此不论是在主机中还是在路由器中协议都有好几层。这一层一层的协议画起来很像堆栈的结构,因此就把这些协议层称为协议栈。
- 实体:表示任何可发送或接收信息的硬件或软件进程。在许多情况下,实体就是一个特定的软件模块。
- 对等层:在网络体系结构中,通信双方实现同样功能的层。例如,AAA向BBB发送数据,那么AAA的第nnn层和BBB的第nnn层就构成了对等层。
- 协议数据单元:通常记为PDUPDUPDU,它是对等实体之间进行信息交换的数据单元。
- 服务访问点:通常记为SAPSAPSAP,在同一系统中相邻两层的实体进行交互(即交换信息)的地方,通常称为服务访问点。
- 客户:在计算机网络中进行通信的应用进程中的服务请求方。
- 服务器:在计算机网络中进行通信的应用进程中的服务提供方。但在很多情况下,服务器也常指运行服务器程序的机器。
- 客户-服务器方式:这种方式所描述的是进程之间服务的请求方和服务的提供方的关系。服务的请求方是主动进行通信的一方,而服务器是被动接收通信的一方。系统启动后即自动调用服务器程序。并一直不断地运行着,被动地等待并接收来自各地的客户的通信请求。客户与服务器的通信关系建立后,通信可以是双向的,客户和服务器都可发送和接收数据。
1-27 试解释everythingoverIPeverything\quad over\quad IPeverythingoverIP和IPovereverythingIP\quad over\quad everythingIPovereverything的含义。
TCP/IPTCP/IPTCP/IP协议可以为各式各样的应用提供服务。从协议栈来看,在IPIPIP层上面可以有很多应用程序。这既是everythingoverIPeverything\quad over\quad IPeverythingoverIP
另一方面,TCP/IPTCP/IPTCP/IP协议也允许IPIPIP协议在各式各样的网络构成的互联网上运行。在IPIPIP层以上看不见下层究竟是什么样的物理网络。这就是IPovereverythingIP\quad over\quad everythingIPovereverything。
1-28 假定要在网络上传送1.5MB1.5MB1.5MB的文件。设分组长度为1KB1KB1KB,往返时间RTT=80msRTT=80msRTT=80ms。传送数据之前还需要有建立TCPTCPTCP连接的时间,这时间是2×RTT=160ms2\times RTT=160ms2×RTT=160ms。试计算在以下几种情况下接收方收完该文件的最后一个比特所需的时间。
- 数据发送率为10Mbit/s10Mbit/s10Mbit/s,数据分组可以连续发送。
- 数据发送率为10Mbit/s10Mbit/s10Mbit/s,但每发送完一个分组后要等待一个RTTRTTRTT时间才能再发送下一个分组。
- 数据发送率极快,可以不考虑数据发送所需的时间。但规定在每一个RTTRTTRTT往返时间内只能发送20个分组。
- 数据发送率极快,可以不考虑数据发送所需的时间。但在第一个RTTRTTRTT往返时间内只能发送1个分组,在第2个RTTRTTRTT内可发送2个分组,在第3个RTTRTTRTT内可发送4个分组(即23−1=22=42^{3-1}=2^2=423−1=22=4个分组)(这种发送方式见教材第五章"TCP的拥塞控制"部分)。
题目的已知条件中的M=220=1048576,K=210=1024M=2^{20}=1048576,K=2^{10}=1024M=220=1048576,K=210=1024。
- 1.5MB=1.5×1048576BYTE=1.5×1048576×8bit=12582912bit1.5MB=1.5\times 1048576\quad BYTE=1.5\times 1048576\times 8\quad bit=12582912\quad bit1.5MB=1.5×1048576BYTE=1.5×1048576×8bit=12582912bit,发送这些比特所需时间=12582912107=1.258s=\frac{12582912}{10^7}=1.258s=10712582912=1.258s,最后一个分组的传播时间还需要0.5×RTT=40ms0.5\times RTT=40ms0.5×RTT=40ms。总共需要的时间为2×RTT+1.258+0.5×RTT=1.458s2\times RTT+1.258+0.5\times RTT=1.458s2×RTT+1.258+0.5×RTT=1.458s
- 需要划分的分组数=1.5M/1KB=1.5×1024=1536=1.5M/1KB=1.5\times1024=1536=1.5M/1KB=1.5×1024=1536,第一个分组以后的1535个分组需要等待的时间是1535×RTT=122.8s1535\times RTT=122.8s1535×RTT=122.8s,因此本题总共需要的时间为1.458+122.8=124.258s1.458+122.8=124.258s1.458+122.8=124.258s
- 在每一个RTTRTTRTT往返时间内只能发送20个分组。1536个分组,需要76个RTTRTTRTT(76个RTTRTTRTT可以发送76×20=152076\times 20=152076×20=1520个分组),最后剩下16个分组,一次发送完。但最后一次发送的分组到达接收方也需要0.5×RTT0.5\times RTT0.5×RTT,因此总共需要的时间=76.5×RTT+2×RTT=6.28s=76.5\times RTT+2\times RTT=6.28s=76.5×RTT+2×RTT=6.28s
- 在两个RTTRTTRTT后就开始传输数据。1.5M1.5M1.5M需要1536个分组来传送。经过n个RTT,发送了1+2+4+8+...+2n−1=2n−11+2+4+8+...+2^{n-1}=2^n-11+2+4+8+...+2n−1=2n−1个分组。若n=10n=10n=10,那么可发送1023个分组,可见10个RTT不够,若n=11n=11n=11,那么可发送2047个分组,可见剩下的513个分组都可以在0.5×RTT0.5\times RTT0.5×RTT的时间内到达接收方,因此接收方收到该文件最后一个比特位所需的时间是(2+10+0.5)RTT=1s(2+10+0.5)RTT=1s(2+10+0.5)RTT=1s。
1-29 有一个点对点链路,长度为50KMKMKM,若数据在此链路上的传播速率为2×108m/s2\times 10^8m/s2×108m/s,试问链路的带宽应该为多少才能使传播时延和发送100字节的分组的发送时延一样大?如果发送的是512字节长的分组,结果又应该如何?
整条链路的传播时延是50KM/(2×108m/s)=250us50KM/(2\times 10^8m/s)=250us50KM/(2×108m/s)=250us。如果在250us250us250us把100字节发送完,则发送速率应该为800bit/250us=3.2Mbit/s800bit/250us=3.2M bit/s800bit/250us=3.2Mbit/s,这也是链路带宽应有的数值。
如果改为发送512字节的分组,则发送速率应该为512×8bit/250us=16.38Mbit/s512\times 8bit/250us=16.38M bit/s512×8bit/250us=16.38Mbit/s,这也是链路带宽应有的数值。
1-30 有一个点对点链路,长度为20000KMKMKM,数据的发送速率为1kbit/s1kbit/s1kbit/s,要发送的数据有100bit100bit100bit。数据在此链路上的传播速率为2×108m/s2\times 10^8m/s2×108m/s,假定我们可以看见在线路上传输的比特,试画出我们看到的线路上的比特(画两张图,一张是在100bit100bit100bit刚刚发送完时,另一张是再经过0.05s0.05s0.05s后)。
100bitbitbit的发送时间=100bit/1kbit/s=0.1s=100bit/1kbit/s=0.1s=100bit/1kbit/s=0.1s ,如图5所示0.1s0.1s0.1s的时间可以传播20000km20000km20000km,正好是线路的长度。因此当发送的第一个比特到达终点时,发送方也正好把100比特的数据发送完毕,整个线路上都充满了所传输的100比特。再经过0.05s0.05s0.05s后,所有的比特都向前走了10000km10000km10000km,这就是说,发送的前50比特已经到达终点了,剩下的50比特还在线路上传播,最后一个比特正好走了一半(10000km10000km10000km),在线路的正中间。
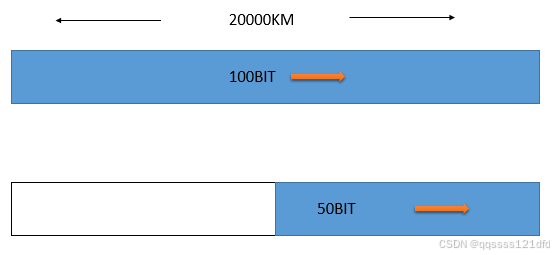
图5.
1-31 条件同上题,但数据的发送速率为1Mbit/s1Mbit/s1Mbit/s,和上题的结果相比较,你可以得出什么结论?
100bitbitbit的发送时间=100bit/1Mbit/s=0.0001s=100bit/1Mbit/s=0.0001s=100bit/1Mbit/s=0.0001s ,只有上一题的千分之1。如图6所示0.0001s0.0001s0.0001s的时间可以传播20km20km20km,只有线路的长度的千分之1。因此现在整个100比特都在线路靠发送端的位置。再经过0.05s0.05s0.05s后,所有的比特都向前走了10000km10000km10000km,这时整个100比特都在线路上传播,最后一个比特正好走了一半(10000km10000km10000km),在线路的正中间。和上题相比较,我们可以看出,同样是在一条线路上传送100bitbitbit的数据,在较低速的线路上(例如,1kbit/s的发送速率),100bitbitbit的数据看起来像是数据流,而在在较高速的线路上(例如,1Mbit/s的发送速率),100bitbitbit的数据看起来像是"小分组"。
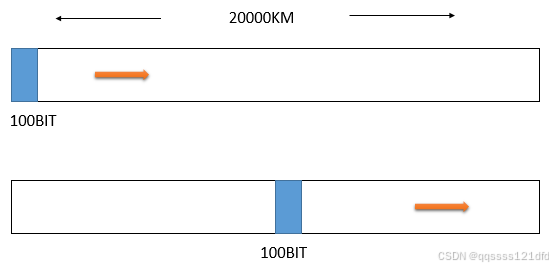
图6.
1-32 以1Gbit/s1Gbit/s1Gbit/s的速率发送数据。试问在以距离或时间为横坐标时,一个比特的宽度分别是多少?
当我们在某一个位置上观察信号随时间的变化规律时,我们往往需要以时间为横坐标来看信号的变化。当以1Gbit/s1Gbit/s1Gbit/s的速率发送数据时,每一个比特的持续时间是10−9s10^{-9}s10−9s,也就是0.001us=1ns0.001us=1ns0.001us=1ns。因此在以时间为横坐标时,一个比特的宽度是0.001us=1ns0.001us=1ns0.001us=1ns
现在看以距离为横坐标的情况。假定信号在线路上的传播速度为2×108m/s2\times 10^8m/s2×108m/s,那么在一个比特时间内信号可以前进20cmcmcm。请注意,这两种表示信号的方法都很有用,但这两个横坐标的量纲不同,我们不能说哪一个信号更宽一些或更窄一些,这样比较是没有意义的。
1-33 我们在互联网上传送数据经常是从某个源点传送到某个终点,而并非传送过去又再传送回来。那么为什么往返时间RTT是个很重要的性能指标呢?
我们在传送数据时经常要使用TCP协议。TCP连接的建立需要消耗时间,这与RTT有密切关系,在传输数据时也常常需要对方的确认,在发送数据后要经过多少时间才能收到对方的确认,这也取决于往返时间RTT的大小。
另外,在计算吞吐率时,有时也要考虑到返时间RTT。例如,一个10610^6106字节的文件在1Gbit/s1Gbit/s1Gbit/s的发送速率下,发送只需要8ms,但如果我们通过网络向远方某个主机请求把这样大的文件发送过来,RTT=100msRTT=100msRTT=100ms,那么总共需要的时间至少为100+8=108ms100+8=108ms100+8=108ms,是原来发送时间的十几倍。
1-34 主机A向主机B发送一个长度位10710^7107比特的报文,中间要经过两个节点交换机,即一共经过三段链路。设每段链路的传输速率为2Mbit/s2Mbit/s2Mbit/s。忽略所有的传播、处理和排队时延。
- 如果采用报文交换,即整个报文不分段,每台节点交换机收到整个的报文后再转发。问从主机A把报文传送到第一个节点交换机需要多少时间?从主机A把报文传送到主机B需要多少时间?
- 如果采用分组交换,报文被划分为1000个等长的分组(这里忽略分组首部对本题计算的影响),并连续发送。节点交换机能够边接收边发送。问从主机A把第一个分组传送到第一个节点交换机需要多少时间?从主机A把第一个分组传送到主机B需要多少时间?从主机A把1000个分组传送到主机B需要多少时间?
- 就一般情况而言,比较用整个报文来传送和划分多个分组来传送的优缺点。
A把报文传送到第一个节点交换机需要时间=107/(2×106)=5s=10^7/(2\times 10^6)=5s=107/(2×106)=5s,从主机A把报文传送到主机B要经过3段链路,因此需要3×5=15s3\times 5=15s3×5=15s
报文被划分为1000个等长的分组,每个分组的长度为10000bit10000bit10000bit,A发送一个分组需要时间=104/(2×106)=0.005s=10^4/(2\times 10^6)=0.005s=104/(2×106)=0.005s,这也是A把第一个分组传送到第一个交换机节点需要的时间。A把第一个分组传送到B需要时间=3×0.005s=0.015s=3\times 0.005s=0.015s=3×0.005s=0.015s。A把1000个分组传送到主机B需要时间=0.015+999×0.005s=5.01s=0.015+999\times0.005s=5.01s=0.015+999×0.005s=5.01s。
一般来讲,使用分组传送会更快些。如果整个报文存储转发,只要其中有一个比特出错,整个报文就必须重传,这很浪费网络资源。使用分组交换,只需要重传出错的那个分组即可。在复杂的网络中,使用分组交换还可以使有些分组通过不太拥塞的路径传播,这就加快了数据的传输。但在使用分组交换时,在目的主机收到的分组中,只要缺少了一个,就无法重装成原来的报文,这就使所收到的分组都没有用处。此外,分组首部造成的开销有时并不能忽略不计。
1-35 主机A向B连续传送一个长度为600000600000600000比特的文件,A和B之间有一条带宽为1Mbit/s1Mbit/s1Mbit/s的链路相连,距离为5000KM5000KM5000KM,在此链路上的传播速率为2.5×108m/s2.5\times 10^8m/s2.5×108m/s。
- 链路上的比特数目的最大值是多少?
- 链路上每比特的宽度(以米来计算)是多少?
- 若想把链路上每比特的宽度变为5000km5000km5000km(即整条链路的长度),这时应把发送速率调整到什么数值?
传播时延=链路长度/传播速率=5×106m/2.5×108m/s=0.02s5\times 10^6m/2.5\times 10^8m/s=0.02s5×106m/2.5×108m/s=0.02s。时延带宽积=0.02s×106bit/s=2×104bit0.02s\times 10^6bit/s=2\times 10^4bit0.02s×106bit/s=2×104bit,由于文件长度大于这个时延带宽积,因此链路上的比特数目的最大值是2×104bit2\times 10^4bit2×104bit。如果文件长度只有2000比特,那么链路上的比特数目的最大值就是2000比特。
链路上每比特的宽度=传播速率/发送速率=传播速率/链路带宽=2.5×108m/s/106bit/s=250m/bit2.5\times 10^8m/s/10^6bit/s=250m/bit2.5×108m/s/106bit/s=250m/bit,即每比特的宽度为250M。
发送速率=传播速率/链路上每比特的宽度=2.5×108m/s/5×106m/bit=50bit/s2.5\times 10^8m/s/5\times10^6m/bit=50bit/s2.5×108m/s/5×106m/bit=50bit/s,当发送速率调整为50bit/s50bit/s50bit/s的时候,链路上每比特的宽度=5000KM。
1-36 主机A到主机B的路径上有三段链路,其速率分别为2Mbit/s2Mbit/s2Mbit/s,1Mbit/s1Mbit/s1Mbit/s,500Kbit/s500Kbit/s500Kbit/s。现在A向B发送一个大文件。试计算该文件传送的吞吐量。设文件长度为10MB,而网络上没有其它的流量。试问该文件从A传送到B大约需要多少时间?为什么这里只是计算大约的时间?
文件传送的吞吐量由瓶颈链路决定,因此吞吐量是500Kbit/s500Kbit/s500Kbit/s。文件长度为10MB=10×220×8bit=10\times 2^{20}\times 8 bit=10×220×8bit。文件传送时间=文件长度/吞吐量=10×220×8bit/500Kbit/s≈167.77s=10\times 2^{20}\times 8 bit/500Kbit/s\approx 167.77s=10×220×8bit/500Kbit/s≈167.77s,即约为168秒。这就是大约的传送时间,因为有很多细节都没有考虑,如划分为多大的分组、每个分组首部的开销,在链路上的传播时延,在每个节点的处理时延和排队时延等等。
/********************************************************************************************/
下面接下来是习题解答里面额外的习题。
1-1 怎样理解"网络的网络"?
大家知道网络有三个要素,即计算机、节点(如计算机、集线器、交换机或路由器等)和链路。可以用以下方式来表述:网络=计算机,节点,链路{计算机,节点,链路}计算机,节点,链路,这里的"节点"起把各计算机黏合起来的作用。
网络的网络是把许多网络连接起来,因此,网络的网络也有三个要素,即网络、节点(这里的节点就是路由器)和链路。因此网络的网络可用以下方式来表述:网络的网络=互联网={网络,路由器,链路},如图7所示。
因此我们必须建立这样的概念:网络把许多计算机连接在一起,而互联网则把许多网络连接在一起。
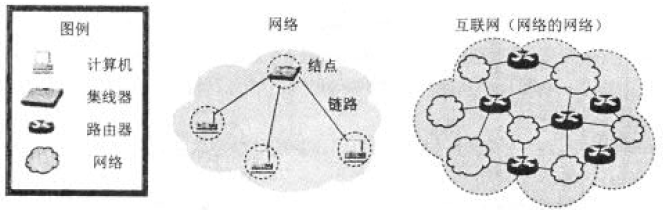
图7.
1-2 为什么我们要区分小写iii的internetinternetinternet和大写III的InternetInternetInternet?
中文没有什么大写和小写的问题,是创建互联网的美国人强调了这种区分。他们在RFC1208RFC\quad 1208RFC1208中强调了这两个名词的意思是很不一样的。即:
以小写字母iii开始的internetinternetinternet(互连网)是一个通用名词,它泛指由多个计算机网络互连而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。
以大写字母III开始的InternetInternetInternet(互联网)则是一个专用名词,它指当前全球最大的,开放的、由众多网络互联而成的特定计算机网络,它采用TCP/IPTCP/IPTCP/IP协议族作为通信的规则,且其前身是美国的ARPANETARPANETARPANET。顺便指出,现在世界上一百多个国家都把自己建造的网络连接到互联网上,因此现在说"互联网是美国的"则是错误的。凡连接到互联网的国家,都能够享受互联网所提供的各种服务。从享受服务的意义上讲,互联网可以说是属于全世界的。当然,每一个国家所建造的网络的主权,还是属于各自国家的。
虽然"因特网"曾被推荐为InternetInternetInternet的译名,但因多种原因未能被各界采用。因此本教材也不再采用"因特网"这一译名。
上面是将这两种网络(internetinternetinternet和InternetInternetInternet)的区别,但这两种网络却有一个共同点,它们都是"网络的网络"
1-3 有人把InternetInternetInternet译为"国际互联网",这样的译名是否准确?
不太准确!这是因为互联网本来就是国际性的,没有必要再加上"国际"这样的定语。没有"本国的"互联网。
1-4 为什么internetinternetinternet有两种不同的译名----"互联网"和"互连网"?
作者认为,这里的原因是我们的译名标准化的工作滞后,结果各种不同的译名都出现了。
在《现代汉语辞典》修订本(中国社会科学院语言研究所辞典编辑室编,商务印书馆1996年出版)第782页上有:"连接也作联接"。在《现代汉语辞典》第785页上有:"联接同连接"。因此"联接"和"连接"基本上是一样的意思。
在全国自然科学名词审定委员会公布的《计算机科学技术名词》(科学出版社1994年12月出版)一书中,英文名词ConnectionConnectionConnection确定译为"连接","Interconnection"确定译为"互连","Internetworking"确定译为"网际互连",这样的译名是很准确的。
1997年7月18日,"全国科学技术名词审定委员会推荐名(一)"公布了。其中的第一个名词就是"互联网",它对应的英文名称为:"Internet","Internetwork""Interconnection network"。在现有名一栏中有"互联网","互连网"",网际网"和"网间网",在注释栏中有这样几个字:又称互连网。
但是使用"互连网"的好处是可以和《计算机科学技术名词》早已定制过的一些名词衔接的更好些。不过请注意,把所有的"互连"统统改成"互联"则是不恰当的。
总之,现在普遍的用法是这样的:"互连网"表示通用名词internetinternetinternet,而"互联网"表示专用名词InternetInternetInternet。
我们在学习计算机网络时,应当清楚地了解这一现实。
1-5 名词node应当译为"节点"还是"结点"?
名词node的标准译名有两个。在科学出版社1994年出版的《计算机科学技术名词》的第112页是这样写的:
- node 节点 08.078,节点 12.023
上面的08.078代表的意思是:08----指的是《计算机科学技术名词》一书中的第八分支学科,即"语言与翻译"学科,而078表示本学科中的第78个名词。再看看这个名词前面的两个名词(语义树、伪语义树),我们就更加清楚地看到,在涉及"树"的时候,node应该译为节点。其实,在通信学科,在天线领域,当node用来指天线上驻波电场强度等于0的地方时,就应当用节点(很像竹竿上的一个个节点)。
上面的12.023代表的意思是:12----指的是《计算机科学技术名词》一书中的第12分支学科,即"计算机网络"学科,而023表示本学科中的第23个名词。
可见网络上的node应该译为"结点"(很像打鱼的网上面的结点)
但不知道是什么原因,一开始就有很多人把网络上的node译为节点,也许是因为在《计算机科学技术名词》一书中节点写在前面,而结点写在后面,因而误认为应当优先使用写在前面的译名。结果习惯成自然。尽管有很多专家提出,对于网络,应当使用准确的译名结点,但据估计,目前国内的教科书和文献中,绝大多数人仍然习惯于使用不大准确的译名节点。为此,本书也按照国内大多数人的用法,现在采用节点,不再使用结点。
1-6 "主机"和"计算机"一样不一样?
"主机"(host)就是"计算机"(computer),因此"主机"和"计算机"应当是一样的意思。不过在互联网中,"主机"是指任何连接在互联网上的(也就是连接在互联网中某一个物理网络上的)、可以运行应用程序的计算机系统。主机可以小到PC,也可以大到巨型机。主机的CPU可以很慢也可以很快,其存储器可以很小也可以很大。但TCP/IP协议族可以使互联网上的任何一对主机都能进行通信,而不管他们的硬件有多大区别。
1-7 名词ISP(InternetServiceProvider)ISP(Internet\quad Service\quad Provider)ISP(InternetServiceProvider)应当译为"互联网服务提供商"还是"互联网服务提供者"?
有人把ISPISPISP译为"互联网服务提供商",理由是因为很多ISPISPISP都是要收费的,是运营商。但作者认为ISPISPISP并不都是运营商。有的ISPISPISP是学校(如有的比较大的大学就是一个ISPISPISP,它负责分配本大学内部的IPIPIP地址),但是这个ISPISPISP并不是以盈利为目的。因此,ISPISPISP中的ProviderProviderProvider还是译为"提供者"比较准确。
1-8 在C/SC/SC/S方式中,为什么CCC(即client)有时译为客户而有时却译为客户机?
我们不把clientclientclient译为客户机而是译为客户,是为了强调这是个软件,不是机器。同样地,服务器("Server")也是软件,不是机器。然而有时我们也需要谈到运行这些软件的机器。客户端的机器(clientmachineclient\quad machineclientmachine),则译为客户端或客户机。服务器端的机器,英文仍然是ServerServerServer,因此中文就仍然叫做"服务器"。因此服务器有时指软件,有时指硬件。
这里最重要的概念就是:客户(ClientClientClient)和服务器(ServerServerServer)都是指通信中所涉及的应用进程。客户-服务器方式所描述的是进程之间服务和被服务的关系。客户是服务请求方,服务器是服务提供方。当然,"器"也不一定是硬件。例如,软件中的编译程序也叫编译器。所以关键是要弄清楚是硬件还是软件。
1-9 能否说:"电路交换就是面向连接的,而分组交换就是无连接的"?
不行。这在概念上是很不一样的。现举例说明如下。
电路交换就是在A和B要通信之前,必须先建立一条从A到B的连接(中间可能经过很多的交换节点)。当A到B的连接建立之后,通信就沿着这条路径进行。A和B在通信期间始终占用这条通道(全程占用),即使在通信的信号暂时不在通信路径上流动时(例如打电话时双方暂时停止说话),也同样占用信道。通信完毕时就释放所占用的信道,即断开连接,将通信资源还给网络,以便让其他用户可以使用。因此电路交换使用面向连接的服务。
分组交换也可以使用面向连接服务。例如X.25X.25X.25网络、桢中继网络或ATM网络都属于分组交换网。然而这种面向连接的分组交换网在传送用户数据之前必须先建立连接。数据传送完毕之后还必须释放连接。因此使用面向连接服务的可以是电路交换,也可以是分组交换。换言之,电路交换肯定是面向连接的,但面向连接的也可以是分组交换。传统的电路交换时面向连接的,而IP这种分组交换是无连接的。
使用分组交换时,分组在那条链路上传送就占用了那条链路的信道资源,但分组尚未到达的链路则暂时还不占用这部分网络资源(这时,这些资源可以让其他用户使用)。因此分组交换不是全程占用资源而是在一段时间占用一段资源,可见,分组交换方式是很灵活的。
现在的互联网所使用的分组交换采用IP协议,IP协议使用无连接的IP数据报来传送数据,即不需要先建立连接就可以立即发送数据。当数据发送完毕后也不存在释放连接的问题。因此,使用无连接的数据报进行通信既简单又灵活。
面向连接和无连接强调的是通信必须经过什么样的阶段。面向连接必须经过三个阶段:"建立连接->传送数据->释放连接",而无连接则只有一个阶段:"传送数据"。
电路交换和分组交换强调的则是在通信时用户对网络资源的占用方式。电路交换在连接建立后到连接释放前全程占用信道资源,而分组交换则强调在数据传送时断续占用信道资源(分组在那一条链路上传送就占用那一条链路的信道资源)。
面向连接和无连接往往可以在不同的层次上来讨论。例如,在数据链路层,HDLCHDLCHDLC和PPPPPPPPP协议是面向连接的,而以太网使用的CSMA/CDCSMA/CDCSMA/CD是无连接的。在网络层,X.25X.25X.25协议是面向连接的,IPIPIP协议是面向无连接的。在运输层,TCPTCPTCP协议是面向连接的,UDPUDPUDP协议是面向无连接的。但是我们却不能说:"TCP"是电路交换,而应当说:"TCP"可以向应用层提供面向连接的服务。需要注意的是,在运输层的面向连接中的"连接",并非是"物理上的连接"。
1-10 我们能否在同一时间,在不同的层次上使用不同的连接方式(面向连接和无连接方式)?
当然可以。例如当我们发送电子邮件时,电子邮件协议需要使用面向连接的TCPTCPTCP协议,但TCPTCPTCP协议需要使用下面的无连接的IPIPIP协议。IPIPIP协议又使用数据链路层的PPPPPPPPP协议,而PPPPPPPPP协议是面向连接的。
1-11 一个主机能否同时连接到两种不同的网络上,其中的一个网络采用面向连接的方式通信,而另一个网络采用无连接方式?
可以。一个主机可以使用两个不同的接口。一个接口连接到面向连接的分组交换网(例如X.25X.25X.25网),而另一个接口连接到无连接的分组交换网(如使用IPIPIP协议的互联网)。具有多个网络接口的主机叫做"多归属主机"(multi−homedhostmulti-homed\quad hostmulti−homedhost)。
1-12 在计算机网络中,经常遇到"面向连接"这样的名词。应当怎样理解"面向"所代表的意思?
"面向连接"这是英文术语connectionorientedconnection\quad orientedconnectionoriented的标准译名。"面向连接"的意思实际上就是"基于连接"。
1-13 在物理层的"连接"是否就是"使用导线的连接"?
在早期的电话通信中,从主叫用户到被叫用户的确存在一条真真的物理连接,即用导线的连接。
但采用了分时复用后(TDMTDMTDM),在交换机中实现的时隙交换和以前的物理上的连接并不一样。比特从交换机的入口写入到某个时隙。然后隔了非常短的时间之后(电话用户根本不会感觉到这种时间滞后),又在另一个时隙读出,从交换机的出口发送到下一个交换机。这样,从主叫用户到被叫用户的连接,已经不再是真真的使用导线的物理连接了。像这样的通信任然属于电路交换。在这种情况下,我们仍然说,在主叫和被叫的通话期间,它们一直占用着这条连接的整个通信资源(其他用户不能共享这条连接的通信资源)。
当移动通信出现后,从主叫用户手机到基站,以及从另一个基站到被叫用户,都占用了相应的无线链路的连接。因此,从主叫用户到被叫用户的连接,即包含了无线连接,也包含了有线连接(铜线或光纤)。显然,无线连接就不是使用导线的连接。因此,在物理层的连接不一定是使用导线的连接。
1-14 互联网使用的IPIPIP协议是无连接的,因此其传输是不可靠的。这样容易使人们
感到互联网很不可靠。那么为什么当初不把互联网的传输设计为可靠的?
这个问题很重要,需要多一些篇幅来讨论。
先打一个比方。邮局寄送的平信很像无连接的IPIPIP数据报。每封平信可能走不同的传送路径,同时邮局对平信也不保证不丢失。当收信人没有收到寄出的平信时,去找邮局索赔是没有用的。邮局会说:"平信不保证不丢失。怕丢失就请你寄挂号信。"但是大家并不会将所有的信件都用挂号方式邮寄,这是因为邮局并不会随意地将平信丢弃,而平信丢失的概率也不大,况且寄挂号信要多花些钱,还要去邮局排队,太麻烦。总之,尽管寄平信有可能会丢失,但绝大多数的信件还是平信,因为寄平信方便、便宜。
我们知道,传统电信网的最主要用途是进行电话通信。普通的电话机很简单,没有什么智能。因此电信公司就不得不把电信网设计得非常好,这种电信网可以保证用户通话时的通信质量。这点对使用非常简单的电话机的用户则是非常方便的。但电信公司为了建设能够确保传输质量的电信网则付出了巨大的代价(使用昂贵的程控交换机和网管系统)。
数据的传送显然必须是非常可靠的。当初美国国防部在设计 ARPANETARPANETARPANET时有一个很重要的讨论内容就是:"谁应当负责数据传输的可靠性?"这时出现了两种对立的意见。一种意见主张应当像电信网那样,由通信网络负责数据传输的可靠性(因为电信网的发展历史及其技术水平已经证明了人们可以把网络设计得相当可靠)。但另一种意见则坚决主张由用户的主机负责数据传输的可靠性。这里最重要的理由是:这样可以使计算机网络便宜、灵活,同时还可以满足军事上的各种特殊的需求。下面用一个简单例子来说明这一问题。
设主机 A 通过互联网向主机B 传送文件(如图8所示)。怎样才能实现文件数据的可靠传输呢?
如按照电信网的思路,就应当设法把不可靠的互联网做成可靠的互联网(这需要花费相当多的钱)。
但设计计算机网络的人采用另外一种思路,即设法实现端到端的可靠传输。
提出这种思路的人认为,计算机网络和电信网的一个重大区别就是终端设备的性能差别很大。电信网的终端是非常简单的、没有什么智能的电话机。因此电信网的不可靠必然会严重此地影响人们利用电话的通信。但计算机网络的终端是有很多智能的主机,这样就使得计算机网和和电信网有两个重要区别。第一,即使传送数据的互联网有一些缺陷(如造成比特差错或分组丢失),但具有很多智能的终端主机仍然有办法实现可靠的数据传输(例如,能够及时发现差错并通知发送方重传刚才出错的数据)。第二,即使网络可以实现 100%的无差错传输,端到端的数据传输仍然有可能出现差错。我们可以用一个简单的例子来说明这个问题。这就是主A 向主机B传送一个文件的情况。
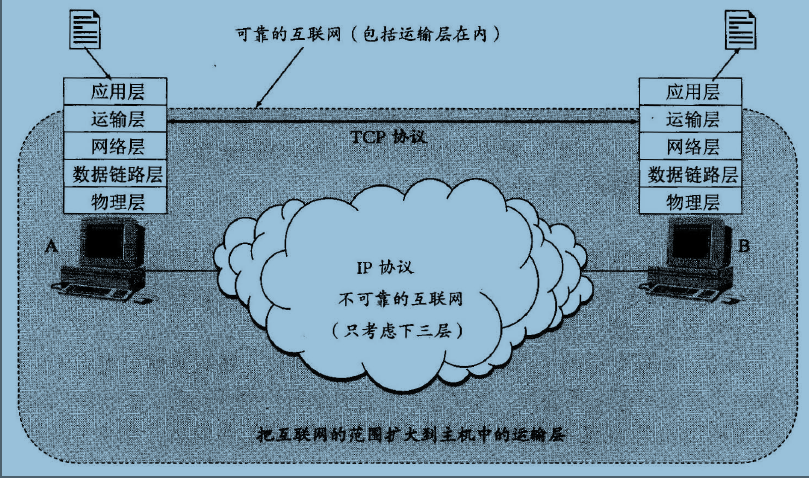
图8.
文件通过一个文件系统存储在主机A 的硬盘中。主机B 也有一个文件系统,用来接收和存储从A 发送过来的文件。应用层使用的应用程序现在就是文件传送程序,这个程序的一部分在主机A 运行,另一部分在主机B 运行。现在讨论文件传送的大致步骤。
- 主机A 的文件传送程序调用文件系统把文件从硬盘中读出,然后文件系统把文件传递
给文件传送程序。 - 主机A 请求数据通信系统把文件传送到主机B 。这里包括使用一些通信协议和把数据
文件划分为适当大小的分组。 - 通信网络把这些数据分组逐个传送给主机B 。
- 在主机B ,数据通信协议把收到的数据传递给文件传送程序在主机B 运行的那一部分。
- 在主机B, 文件传送程序请求主机B 的文件系统把收到的数据写到主机B 的硬盘中。
在以上的几个步骤中,都存在使数据受到损伤的一些因素。例如:
- 虽然文件原来是正确地写在主机A 的硬盘上的,但在读出后可能出现差错(如在磁盘
存储系统中的硬件出现了故障)。 - 文件系统、文件传送程序或数据通信系统的软件在对文件中的数据进行缓存或复制的
过程中都有可能出现故障。 - 主机A 或B 的硬件处理机或存储器在主机A 或B 进行数据缓存或复制的过程中也有
可能出现故障。 - 通信系统在传输数据分组时有可能产生检测不出来的比特差错,甚至丢失某些分组。
- 主机A 或B 都有可能在进行数据处理的过程中突然崩溃。
由此可看出,即使对于这样一个简单的文件传送任务,仅仅使通信网络非常可靠并不能保证文件从主机A 硬盘到主机B 硬盘的传送是可靠的。也就是说,花费很多的钱把数据传输网络做成非常可靠的,对传送计算机数据来说是得不偿失的。既然现在的终端设备有智能,就应当把数据传输网络设计得简单些,而让具有智能的终端来完成"使传输变得可靠"的任务。
于是,计算机网络的设计者采用了一种策略,这就是"端到端的可靠传输"。更具体些说,就是在运输层使用面向连接的 TCP 协议,它可保证端到端的可靠传输。只要主机B的TCP发现数据的传输有差错,就告诉主机 A 把出现差错的那部分数据重传,直到这部分数据正确传送到主机 B 为止。而TCP 发现不了数据有差错的概率是很小的。采用这样的建网策略,既可以使网络部分价格便宜和灵活可靠,又能够保证端到端的可靠传输.
这样,我们可以想象,把互联网的范围稍微扩大一些,即不仅包括网络层,而且扩大到主机中的运输层(见图8)。由于运输层使用了 TCP 协议,使得端到端的数据传输成为可靠的,这样扩大了范围的互联网就成为可靠的网络。
因此,"互联网提供的数据传输是不可靠的"或"互联网提供的数据传输是可靠的"这两种说法都可以在文献中找到,问题是怎样界定互联网的范围。如果说互联网提供的数据传输是不可靠的,那么这里的互联网指的是不包括主机在内的网络(仅有下三层)。说互联网提供的数据传输是可靠的,就表明互联网的范围已经扩大到主机的运输层。
再回到通过邮局寄平信的例子。当我们寄出一封平信后,可以等待收信人的确认(通过他的回信)。如果隔了一些日子还没有收到回信,我们可以将该信件再寄一次。这就是将"端到端的可靠传输"的原理用于寄信的例子。
1-15 在具有五层协议的体系结构中,如果下面的一层使用面向连接服务或无连接
服务,那么上面的一层是否也必须使用同样性质的服务呢?或者说,我们是否可以在各层任意使用面向连接服务或无连接服务呢?
实际上,在五层协议栈中,并非在所有的层次上都存在这两种服务方式的选择问题。
网络层现在都使用IP 协议,它只提供一种服务,即无连接服务。在使用IP 协议的网络层的下面和上面,都可以使用面向连接服务或无连接服务。
已经过时的OSI 体系结构在网络层使用面向连接的X.25 协议。但在互联网成为主流计算
机网络后,即使还有很少量的X.25 网在使用,那也往往是在X.25 协议上面运行IP 协议,即IP 网络把X.25 网当作一种面向连接的链路使用。
在网络层下面的数据链路层可以使用面向连接服务(如使用拨号上网的PPP 协议),即IP可运行在面向连接的网络之上。但网络层下面也可以使用无连接服务(如以太网),即IP 可运行在无连接网络之上。
网络层的上面是运输层。运输层可以使用面向连接的TCP, 也可以使用无连接的UDP 。
1-16 在运输层应根据什么原则来确定使用面向连接服务还是无连接服务?
根据上层应用程序的性质来确定使用哪种连接服务。
例如,在传送文件时要使用文件传送协议FTP, 而文件的传送必须是可靠的,因此在运输层就必须使用面向连接的TCP 协议。但是若应用程序要传送分组话音或视频点播信息,那么为了保证信息传输的实时性,在运输层就必须使用无连接的UDP 协议。
另外,选择TCP 或UDP 时还需考虑对连接资源的控制。若应用程序不希望在服务器端同时建立太多的TCP 连接,可考虑采用UDP 。
1-17 在数据链路层应根据什么原则来确定使用面向连接服务还是无连接服务?
在设计硬件时就能够确定。例如,若采用拨号电路,则数据链路层将使用面向连接服务。但若使用以太网,则数据链路层使用的是无连接服务。
1-18 TCP/IP 的体系结构到底是四层还是五层?
在一些书籍和文献中的确有这两种不同的说法。作者认为,四层或五层都关系不大。因为TCP/IP 体系结构中最核心的部分就是靠上面的三层:应用层、运输层和网络层。至于最下面的是一层一网络接口层,还是两层一网络接口层和物理层,这都不太重要,因为TCP/IPTCP/IPTCP/IP本来没有为网络层以下的层次制定什么标准。TCP/IP 的思路是:形成IPIPIP 数据报后,只要交给下面的网络去发送就行了,不必再考虑得太多。用OSI 的概念,将下面的两层称为数据链路层和物理层是比较清楚的。
1-19 我们常说"分组交换",但又常说"路由器转发IP 数据报"或"路由器转发帧",
"分组"一词究竟应当用在什么场合?
"分组"(packet)也就是"包",它是一个不太严格的名词,意思是将若干个比特加上首部的控制信息封装在一起,组成一个在网络上传输的数据单元。在数据链路层这样的数据单元叫作"帧"。而在IP 层(即网络层)这样的数据单元叫作"IP 数据报"。在运输层这样的数据单元叫作"TCP 报文段"或"UDP 用户数据报"。但在不需要十分严格和不致弄混的情况下,有时也都可笼统地采用"分组"这一名词。这点请读者注意。
OSI 为了使数据单元的名词准确,就创造了"协议数据单元"PDU 这一名词。在数据链路层的PDU 叫作DLPDU, 即"数据链路协议数据单元"。在网络层的PDU 叫作"网络协议数据单元"NPDU。在运输层的PDU 叫作"运输协议数据单元"TPDU 。虽然这样做十分严谨,但过于烦琐,现在已没有什么人愿意使用这样的名词了。
1-20 到商店购买一个希捷公司生产的4TB 的硬盘。当安装到电脑上以后,我们使
用Windows 资源管理器在该磁盘的"属性"中发现只有3.63 TB 。是什么地方出了
差错吗?
不是。这个因为希捷公司的硬盘标记中的T 表示101210^{12}1012, 而微软公司Windows 软件中的T 表示2402^{40}240 。3.63×240≈4×10123.63 \times 2^{40}\approx 4\times10^{12}3.63×240≈4×1012 , 即希捷公司的4TB 和微软公司的3.63 TB 相等。
1-21 字节(byte)和八位位组(octet)有没有区别?
严格说来,这两个名词是有区别的。"字节"与具体的计算机有关。有的计算机( 如以前的CDC 大型机)定义一个字节等千6 bit, 但也有的计算机(如BBN 的C 型计算机)则定义一个字节等于10 bit 。但一个八位位组严格地等千8 bit。可见,当计算机使用的字节定义为8 bit 时,"字节"和"八位位组"是一样的。但是现在绝大多数的计算机工作者都已经把"字节"和"八位位组"当作同义词了。总之,当需要使用各种不同的计算机时,区分"字节"和"八位位组"是必要的。我们的教材主要讲授基本原理,因此可以认为"字节"和"八位位组"都表示8 bit 。
1-22 英文名词bit 应当译为"比特"还是"位"?
在《计算机科学技术名词》的第90 页上面给出了bit 的标准译名:
- bit [二进制]位01.128, 比特12.070
可见bit 有两个标准译名"位"和"比特"。
这里要注意的是,本来bit 就是从"binary digit" 衍生出来的名词。在英语世界的国家中,不论是计算机学科,还是通信学科,都使用bit 这个名词,从来没有产生过什么不明确的地方。但在翻译成中文时出现了不同的译名。计算机界愿意用"位",而通信界则愿意用"比特"。这样就产生了两个不同的译名。
我们还应当注意的是,严格来讲,"位"其实应当是指二进制的位。我们有时可能还会用到八进制或十六进制的"位",那么这时的"位"就不应当是bit 了。还要指出的是,在《计算机科学技术名词》中的"位"后面的01.128 代表的意思是:
- 01----指《计算机科学技术名词》一书中的第1 分支学科,即"总论"学科,而128 表
示本学科中的第128 个名词。
在《计算机科学技术名词》中的"比特"后面的12.070 代表的意思是:
- 12 ------指《计算机科学技术名词》一书中的第12 分支学科,即"计算机网络"学科,
而070 表示本学科中的第70 个名词。
这样看来,在计算机网络中,把bit 译为"比特"应当是没有问题的。但计算机网络是通信与计算机相结合的学科。因此,在涉及计算机较多的地方,很多人又喜欢使用"位"这个名词,如"32 bit 的IP 地址"译为"32 位的IP 地址"。当然,用"32 比特的IP 地址"也是可以的。又如, "10 Mbit/s 的速率"则应当译为"每秒10 兆比特的速率",而不应当译为"每秒10兆位的速率"。
1-23 有这样的说法:习惯上,人们都将网络的"带宽"作为网络所能传送的"最高数据率"的同义语。这样的说法有何根据?
还没有找到这种说法出自哪一个国际标准或重要的RFC 文件(欢迎读者告诉作者)。但是在一些著名国外教材中可以找到类似的说法。例如,在教材附录C 的PETEll 一书的第45 页上写着:
If you see the word "bandwidth" used in a situation in which it is being measured in hertz, then it probably refers to the range of signals that can be accommodated.
(如果你见到"带宽"使用在用赫兹度量的情况下,那么它很可能就是指可提供的信号的
范围。)
When we talk about the bandwidth of a communication link, we normally refer to the numberof bits per second that can be transmitted on the link.
(当我们谈到一条通信链路的带宽时,我们通常是指在这条链路上每秒所能传送的比特
数。)
1-24 有时可听到人们将"带宽为10 Mbit/s 的以太网"说成是"速率( 或速度)为10 Mbit/s 的以太网"或"10 兆速率(或速度) 的以太网" 。试问这样的说法正确否?
这种说法在网络界的确很常见。
例如, 当10 Mbit/s 以太网升级到100 Mbit/s 时,这种100 Mbit/s 的以太网就称为快速以太网,表明速率提高了。当调制解调器每秒能够传送更多的比特时就称为高速调制解调器。当网络中的链路带宽增加时,也常说成是链路的速率提高了。因此在计算机网络领域,"速率"和" 带宽"有时代表同样的意思。
但我们必须对网络的"速度"有正确的理解。
我们早已在物理课程中学过,速率(或速度)的单位是"米/秒"。我们谈到"高速火车"是指这种火车在单位时间内行驶的距离增大了。但"网络提速"井不是指信号在网络上传播得更快了(更多的"米/秒"),而是说网络的传输速率(更多的"比特/秒")提高了。
这里特别要注意,"传播" (propagation 或propagate)和"传输"(transmission 或transmit)这两个中文名词仅一字之差,但意思却差别很大。
传播速率:信号比特在传输媒体上的传播速率就是电磁波在单位时间内能够在传输媒体上走的距离。这个速率大约只有电磁波在真空中的传播速率的2/3 左右。或者说,信号比特在传输媒体上1 微秒可传播200 米左右的距离。
传输速率:计算机每秒可以向所连接的媒体或网络注入(也就是发送)多少个比特则是传输速率。若计算机在单位时间内能够发送更多的比特也就是"发送速率提高了",但一定要弄清,这里的"速率"指的是"比特/秒"而不是指"米/秒( 传播速率)"。
由此可见,当我们使用"速率"表示"比特/秒"时,就应当将其理解为主机向链路( 或网络)发送比特的速率。这也就是比特进入链路(或网络)的速率,而不是比特在链路上(或在网络上)传播的速率。同理,传播时延和传输时延的意思也是完全不同的。由千传输时延很容易和传播时延弄混,因此最好使用发送时延来代替传输时延这个名词。请记住:
发送时延=传输时延≠\neq=传播时延
1-25 有人说,宽带信道相当于高速公路车道数目增多了,可以同时并行地跑更多数量的汽车,虽然汽车的时速并没有提高( 这相当千比特在信道上的传播速率没有提高),但整个高速公路的运输能力却提高了,相当千能够传送更多数量的比特。这种比喻合适否?
这样比喻是很不恰当的,很容易产生误解。请注意:汽车可以提高在高速公路上的行驶速度,但我们却无法提高比特在网络上的传播速率。如果一定要用汽车在高速公路上跑和比特在通信线路上的传输相比较,那么可以这样来想象:低速信道对应的数据发送速率较低,相当于汽车进入高速公路的时间间隔较长。例如,每隔1 分钟有一辆汽车进入高速公路。"高速率信道" 对应的数据发送速率较高,相当于进入高
速公路的汽车的时间间隔缩短了,例如,现在每隔6 秒就有一辆汽车进入高速公路。虽然汽车在高速公路上行驶的速度没有变化,但在同样时间内,进入高速公路的汽车总数却增多了(每隔1 分钟进入高速公路的汽车现在增加到10 辆),因而吞吐量也就增大了。图9可帮助理解这一概念。
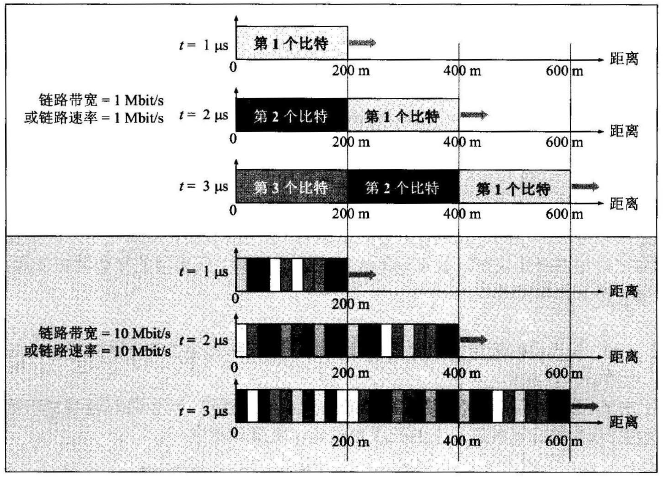
图9 链路带宽对信号传输速率的影响.
假定一条链路的传播速率为2×108m/s2 \times 10^8 m/s2×108m/s 。这相当于电磁波在该媒体上1 μs 可向前传播200m 。若链路带宽为1 Mbit/s, 则主机在1 μs 内可向链路发送1 bit 数据。图中用横坐标表示距离(请注意,横坐标不是时间) 。当t= 0 时开始向链路发送数据。这样,我们有:
- 当t = 1μs 时,信号传播到200m 处。注入到链路上1 个比特。
- 当t= 2 μs 时,信号传播到400m 处。注入到链路上共2个比特。
- 当t= 3 μs 时,信号传播到600m 处。注入到链路上共3 个比特。
现在将链路带宽提高到10 倍,即达到10 Mbit/s 。这相当千1 μs 内可向链路发送10 bit 数据。显然,发送速率提高了。然而这些数据比特在链路上的传播速率(m/sm/sm/s)并没有任何变化,即传播速率仍然是200 m/μs 。这点从图的上下两部分对比即可看出:
- 当t = 1 μs 时,信号仍然是传播到200m 处。但注入到链路上已有10 个比特。
- 当t=2 μs 时,信号仍然是传播到400m处。但注入到链路上已有20 个比特。
- 当t= 3 μs 时,信号仍然是传播到600m 处。但注入到链路上已有30 个比特。
也就是说,当带宽或发送速率提高后,比特在链路上向前传播的速率并没有提高,只是每秒钟注入到链路的比特数增加了。"速率提高"就体现在单位时间内发送到链路上的比特数增多了,而井不是比特在链路上跑得更快。
但是我们不能认为,在通信线路上的所有传输都只是串行传输,而没有并行传输。例如,在一条光缆中可以放入多条光纤并行传输。这样就可使整条光缆的数据传输速率比每一条光纤的数据传输速率提高好几倍。这就是并行传输的一个例子。这相当千多个车道的公路。又如,采用先进的调制方法,可以在一条通信线路上划分出很多条子信道并行地传输数据。这样就使通信线路的数据率提高很多。
目前在无线局域网中广泛使用的正交频分复用技术OFDM, 也是使用多个子信道并行地传输数据的,因而使数据的传输速率大大提高。但这种复杂的调制技术,无法使用高速公路来进行简单的对比。
如果我们的主机连接到一条100 Mbit/s 的宽带线路上,那么主机就能以100 Mbit/s 的速率向宽带线路发送数据。这些数据肯定是以串行传输的方式进入宽带线路的。在这种情况下,我们往往可以简单地把这种通信线路看成是一条串行传输的线路,虽然实际上数据进入通信线路后有可能是用划分子信道的方式进行并行传输的,但这些细节在许多情况下可能是我们并不关心的(例如在讨论网络协议时,就可以不去深究通信线路中所采用的复杂调制技术)。因此,不宜用高速公路来比喻宽带线路。
1-26 如果将时延带宽积管道比作传输链路,那么是否宽带链路对应的时延带宽积
管道就比较宽呢?
对的。我们可以用时延带宽积管道来表示传输链路。可以将时延带宽积管道画成如图10所示的长方形管道,它的长度是时延,宽度是带宽。

图10 时延带宽积管道.
对千图9的例子,时延以微秒(μs)作为单位,因此600m 长度的链路相当于时延3 μs长的管道。管道的宽度是带宽,现在以Mbitls 作为单位。图11显示的是在不同时间、链路带宽为不同数值时,时延带宽积管道中的比特填充情况。
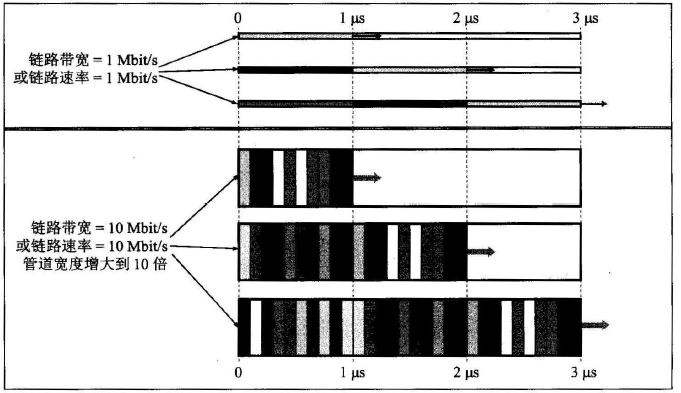
图11 时延带宽积管道中的比特填充情况.
图11 中上面的部分是链路带宽为1 Mbit/s 的情况,下面的部分是链路带宽为10Mbit/s 的情况。对比这两部分就可看出,当链路速率提高到10 倍时,时延带宽积管道的宽度
也相应地增大到10 倍。对比图中的上、下两部分,我们可以看出:
- 当t = 1 μs 时,管道中的比特数(即注入到链路上的比特数)分别为1 bit 和10 bit 。
- 当t= 2 μs时,管道中的比特数(即注入到链路上的比特数)分别为2 bit 和20 bit 。
- 当t=3 μs时,管道中的比特数(即注入到链路上的比特数)分别为3 bit 和30 bit 。
对于图9的例子, 600 m 长度的链路相当于时延3 μs, 在图11上、下两部分的时延带宽积分别为3 bit 和30 bit 。
1-27 网络的吞吐量与网络的时延有何关系?
本来吞吐量和时延是两个完全不同的概念,它们似乎应当是彼此无关的。然而,吞吐量和时延却是密切相关的。当网络的吞吐量增大时,分组在路由器中等待转换时就会经常处在更长的队列中,因而增加了排队的时间。这样,时延就会增大。当吞吐量进一步增加时,还可能产生网络的拥塞。这时整个网络的时延将大大增加。可见吞吐量与时延的关系是非常密切的。
1-28 什么是"无缝的""透明的"和"虚拟的" ?
"无缝的"(seamless)用于网络领域时,表示几个网络的互连对用户来说就好像一个网络。这是因为互连的各网络都使用统一的网际协议IP, 都具有统一的IP 地址,就好像所有网络上的主机和路由器都连接在一个大的互连网上。用户看不见各个不同的网络相连接的"缝",因此称这种连接为"无缝的"。在这个意义上讲,"无缝的"和"透明的"意思很相近。
当"无缝的"用于计算机程序时,表示有几个程序联合起来完成一项任务,但对用户来说只有一个接口,这样的接口叫作"无缝的用户接口",表示程序之间的其他一些接口对用户是不可见的。"透明的"(transparent)表示实际上存在的东西对我们却好像看不见一样。例如,网络的各层协议都是相当复杂的。当我们在电脑上编辑好一封邮件后,只要用鼠标点击一下"发送"按钮,这封邮件就发送出去了。实际上,我们的电脑要使用好几个网络协议。可是这些复杂的过程我们都看不见。因此,这些复杂的网络协议对网络用户来说都是"透明的"。意思是:这些复杂的网络协议虽然都存在千电脑中,但用户却看不见(如果要看,就要使用专门的网络软件)。
我们在使用调制解调器上网时使用PPP 协议。不管我们发送什么样的字符, PPP 协议都可以进行传输。这种传输方式叫作"透明传输"。有时我们也说网络是透明的。这表示对应用程序来说,只要将要做的事情交给应用层下面的应用编程接口API ,后面的事情就不必管了。网络程序会将应用程序传送到远地的目的进程。
因此这个网络的复杂机制对端用户来说也是看不见的,因而是透明的。
"虚拟的"(virtual)表示看起来好像存在但实际上并不存在。"虚拟的"有时可简称为"虚"。如"虚电路"就表示看起来好像有这样一条电路,但在现实世界并没有这样的一条电路存在。"虚拟局域网"VLAN 表示看起来这几个工作站组成了一个局域网,但实际上并没有这样的一个局域网存在。读者应当注意,从字典上看,英文单词virtual 还有"实际上的""实质上的""现实的"等意思,这正好和"虚拟的"相差很大。
1-29 我们知道,协议有三个要素,即语法、语义和同步。语义是否已经包括了同
步的意思?
"语义"并不包括"同步" 。"语义"指出需要发出何种控制信息、完成何种动作以及做出何种响应。但"语义" 并没有说明应当在什么时候做这些动作。而"同步"则详细说明这些事件实现的顺序(例如,若出现某个事件, 则接着做某个动作) 。
1-30 为什么协议不能设计成100%可靠的?
设想某一个要求达到100%可靠的协议需要A 和B 双方交换信息共N 次,而这N次交换信息都是必不可少的。也就是说,在所交换的N 次信息中是没有冗余的。
nbsp; 假定第N 次交换的信息是从B 发送给A 的。B 发送给A 的这个信息显然是需要A 加以确认的。这是因为:若不需要A 的确认,则表示B 发送这个信息丢失了或出现差错都不要紧。这就是说, B 发送的这个信息是可有可无的。
nbsp; 如果B 发送的这个信息是可有可无的,那么最后这次的信息交换就可以取消,因而这个协议就只需要A 和B 交换信息N-1 次而不是N 次。这就和原有的假定不符。
nbsp; 如果B 发送的这个最后的信息是需要A 加以确认的,那么这个协议需要A 和B 交换信息的次数就不是N 次,而是还要增加一次确认(A 向B 发送的确认),即总共需要交换信息N+ 1 次。但这就和原来假定的"双方交换信息共N 次"相矛盾。
nbsp; 显然,这个矛盾无法解决。这样就证明了协议不能设计成100%可靠的。然而在非常重要的任务中,协议可以设计成非常接近千100%可靠的。
1-31 什么是互联网的摩尔定律?
互联网的三十年发展历史的统计资料表明,互联网上的通信量大约每年要翻一番("大约"是指每年大约增长75 %至150% ),见图12, 这被称为互联网的摩尔定律(Moore's Law) 。图12中的TB 是TeraByte 的缩写,即2402^{40}240 字节。
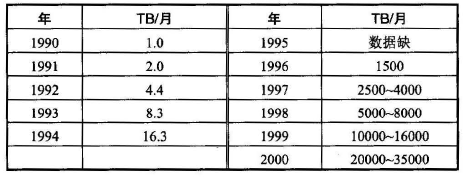
图12 互联网上的通信量的增长数据.
摩尔定律本来是说明集成电路芯片上的元器件密度平均每隔18 个月翻一番。摩尔定律不是自然定律,而是来自技术、社会学和经济学等许多复杂因素的相互作用。顺便要指出,英文名字Moore 在常用的英汉词典上给出的中文译名有两个,即"穆尔"和"摩尔"。前者在发音方面比较准确,也是词典上首先推荐的。但考虑到目前流行更广的是后者, 因此我们现在就采用"摩尔"这个译名。
1-32 假定从节点A 发送一个很短的分组到节点B, B 收到后立即发送很短的应答分组给A (这就表示双方的发送时延均可忽略不计)。A 测量出往返时间RTT 。试问这个RTT 值是否就是A 和B 之间的传输媒体的往返传播时延?
如果A 和B 是直接连接的,那么这个RTT 值就是A 和B 之间的传输媒体的往返传播时延。但如果A 和B 之间还有一个或多个路由器,那么这个RTT 值还应包括分组经过的所有路由器的排队时间和处理时间。如果遇到网络拥塞,位于途中的某个路由器甚至会丢弃这个分组。在这种情况下,测量出的RTT 值就是无穷大值(即测不出RTT 的数值),表明B 永远收不到应答分组。这时,可能是A 发送的分组在途中被丢弃,没有到达B ;也可能是B 发送的应答分组在途中被丢弃,没有到达A 。