为什么要有文件系统?
文件系统负责对硬盘上的数据(文件)进行组织管理。
在Linux中,一切皆文件。不仅普通的文件,目录/块设备/管道/socket等也都当作是一个文件,统一交给文件系统来管理。
你现在有一块硬盘,并且里面已经保存了很多文件,但是这些文件在硬盘中只是一堆二进制数据,如下图所示。
怎么样才能让硬盘或者操作系统知道哪些数据属于哪一个文件呢?就好像我们人一样一眼看过去就知道哪些数据属于哪些文件(相同颜色为一个文件)。

一、文件系统中的逻辑块
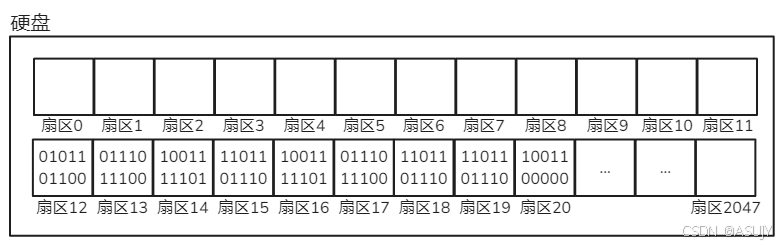
首先你要知道,硬盘读写的最小单位是扇区,每个扇区的大小为512B。如果每次对硬盘进行读写操作都是以一个扇区为单位进行读写,那么读写的效率就会非常低。
所以文件系统会把多个连续的扇区组成一个逻辑块,每次读写的最小单位就是 逻辑块 。常见的 逻辑块 大小有1024字节(1KB)、2048字节(2KB)或4096字节(4KB)等。本篇文章就以 1KB 大小的逻辑块为例,即一次性读写2个扇区,这比一次读写一个扇区的效率要高!
当然了,逻辑块的大小其实是操作系统规定好的!因为其实是操作系统在操作硬盘!即硬盘读写的最小单位是扇区这个规定是不会变的,只不过操作系统可以一次性读取两个扇区,即一次性读取一个逻辑块!
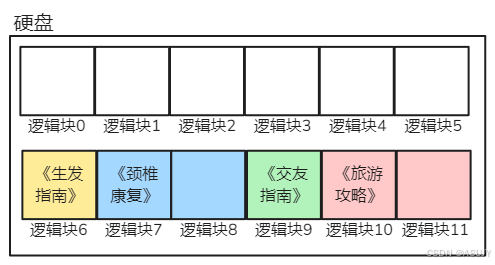
所以在文件系统的眼里,硬盘就变成了以下样子:
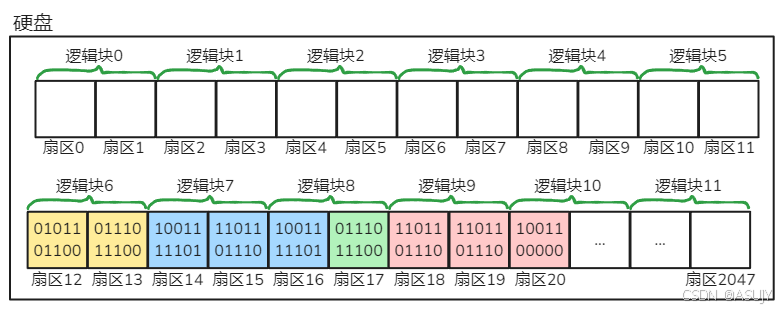
理论上,逻辑块中的内容都是属于同一个文件的,而不会出现上面绿色方框这种,两个文件的数据在同一个逻辑块中的情况。所以,硬盘中的数据就会变成以下样子:
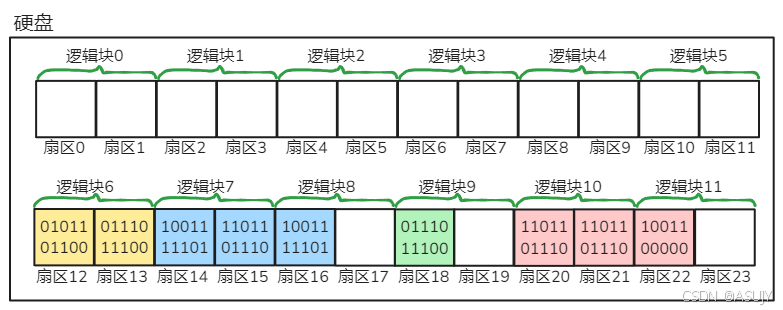
简化一下就变成如下所示:
二、文件系统原理
在没有文件系统之前,我们怎么查找文件,或者我们根据什么信息去硬盘中获取文件?是直接跟硬盘说,请给我6号逻辑块的文件,还有10号逻辑块的文件吗?虽然这样也可以,但是这样太不方便了,一方面我要记住文件存放在哪个逻辑块,另一方面,还得记住这个文件中保存的信息。
如果能够根据文件名去硬盘中获取对应的文件,那该多好啊!这样即不用记住文件存放在哪个逻辑块中,又能够根据文件名快速知道这个文件中保存的内容。
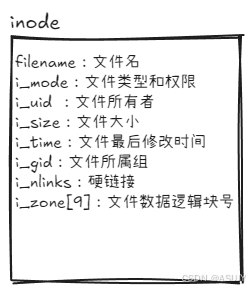
于是就需要有一个地方,记录文件名与逻辑块的对应关系 。这时候就需要在硬盘中找一个逻辑块来存放这些关系。此时inode结构体应运而生,inode结构体就是用来存放这些关系的。inode结构如下所示:

《生发指南》这个文件用这个inode结构的确不错,但是当我们的文件很大,像《颈椎康复》这种文件需要两个逻辑块怎么办?因为《颈椎康复》是连续存储的,所以很容易想到的是,使用 i_zone 记录文件的第一个块,再使用一个变量来记录文件占用多少块即可。
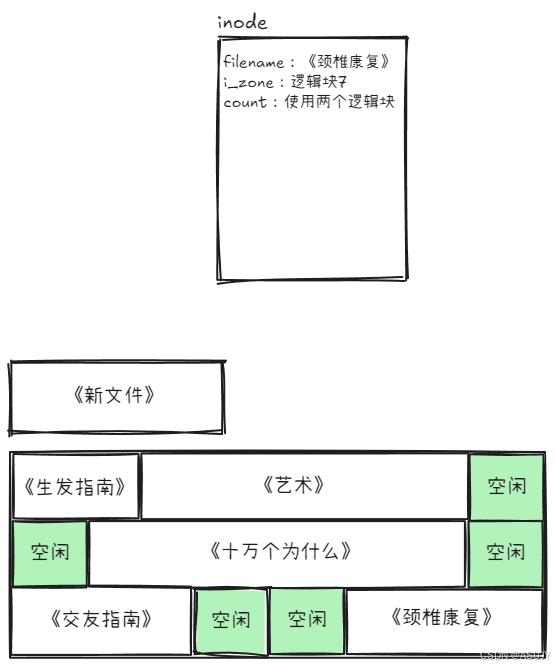
但是这样就带来了一个新的问题,经过多次的文件创建和删除操作,就会留下很多小的碎块,这样就会导致明明硬盘有足够的空间来存储《新文件》,但是因为这些空间不是连续的,所以最终硬盘存储不了《新文件》,导致了空间的浪费,如上图所示。
要解决这个问题也很简单,之前在 inode 中用 i_zone 记录了文件所在的块号,现在只需要扩展一下 i_zone 这个变量,多记录几块就可以了。扩展之后,硬盘就能够存储《新文件》了!如下图所示:
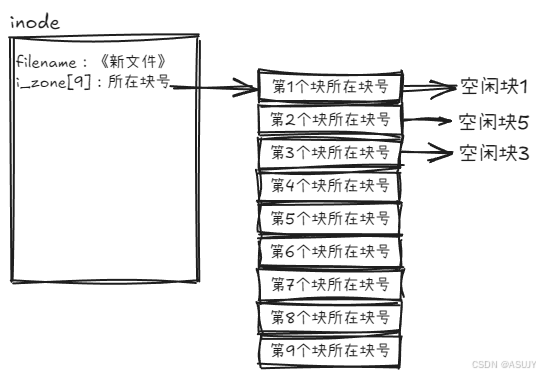
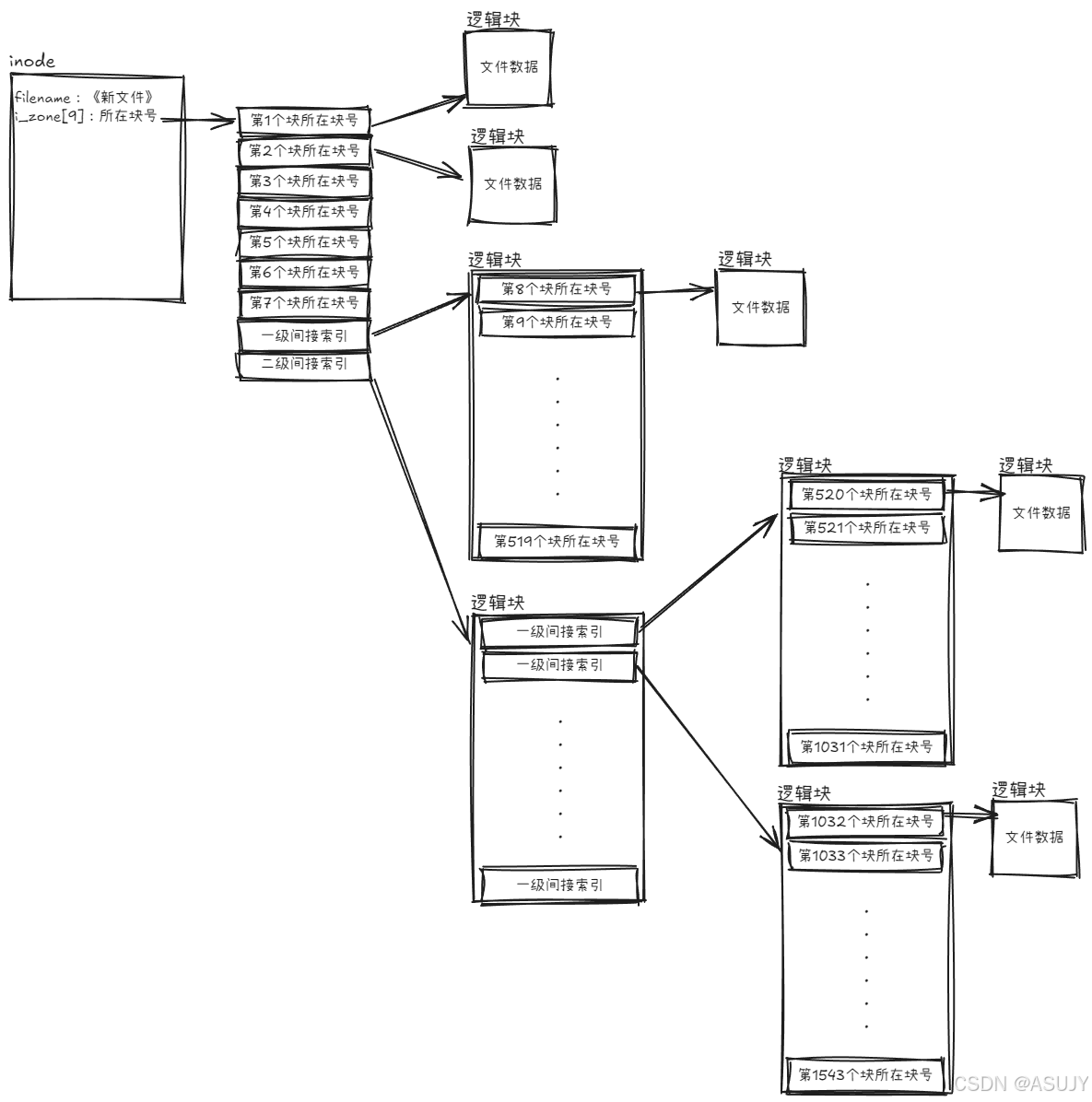
i_zone 扩展之后,现在能记录的最大文件是 9KB(一个逻辑块是 1KB), 如果文件大于9K的话怎么办?那就需要继续扩展 i_zone,如果只是单纯的增加 i_zone 数组的大小,也能够解决问题,但是这样不够灵活。因为如果要存放一个512KB大小的文件,就需要 i_zone 有512个元素,那么 i_zone 就会占用一个块,而且每个inode都有 i_zone[512],相当于一个inode至少占用一个逻辑块,这样是很浪费空间的。因为不是每个文件大小都有512KB。同时不利于文件的扩充,因为i_zone数组大小是固定的,只能存放最大512KB的文件,再大就不行了,除非修改 i_zone 数组大小。
比较好的方法是让 i_zone[] 中指向的其中一个块作为间接索引,如下图所示。
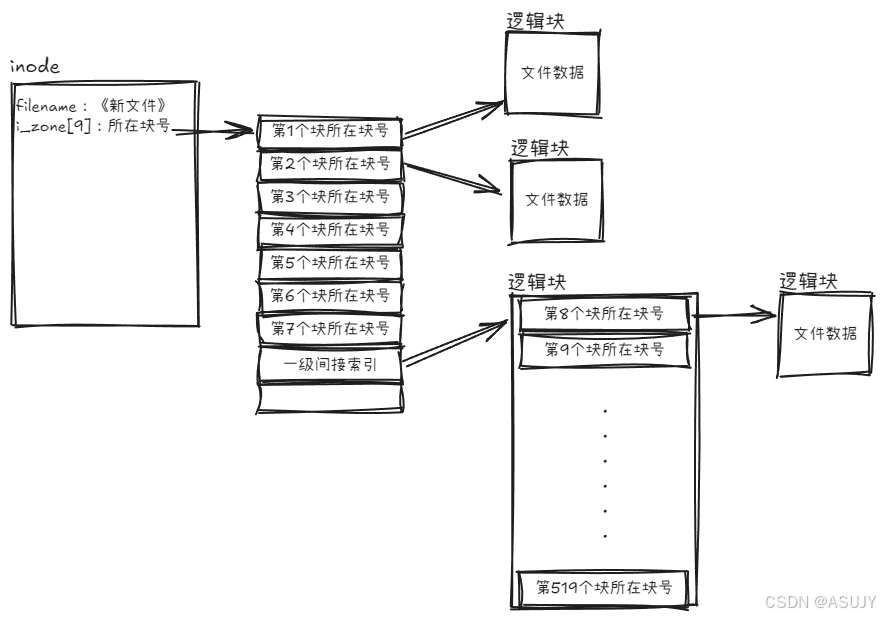
这样就可以存放519KB大小的文件了,这种索引叫 一级间接索引 。
如果要存放的文件大于519KB,那么可以再让 i_zone[] 中指向的其中一个块作为一级间接索引。或者让 i_zone[] 中指向的其中一个块作为 二级间接索引 ,这样就可以存放 7KB+512KB+512*512KB=262663KB≈256MB 大小的文件了!如果还觉得不够,可以继续做三级、四级间接索引,原理是一样的。
既然inode是用来存放文件相关的信息的,那么可以把文件名,文件大小,文件创建时间等信息都存放在inode中,假设inode的大小为32字节。也就是说一个文件除了要占用硬盘中的逻辑块来存放文件数据,还要占用一个32字节的inode来存放文件的这些元信息。
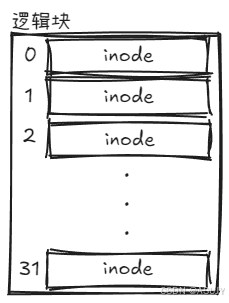
这就需要在硬盘中找一个逻辑块专门来存放inode,一个逻辑块可以存放 1024B÷32B=32 个inode,也就是可以存放32个文件的元信息。将这些inode编号,这样就构成了一个inode表。
新的问题来了,inode表中有那么多个inode,我们怎么知道哪个inode已经使用了,哪些还未使用?所以我们需要找一个逻辑块来记录inode的使用情况。那么就使用2号逻辑块来记录吧(你想使用哪个逻辑块都可以)!因为只需要记录inode已使用和未使用两种状态,所以只需要一个比特位就可以了,0表示未使用,1表示已使用。2号逻辑块中的每一个比特位都对应着一个inode,所以2号逻辑块也被称为 inode位图 ,一个逻辑块可以记录 1024B*8bit=8192个inode。如下所示,在inode位图中,分别指示了0、1、32、33号位图已使用。
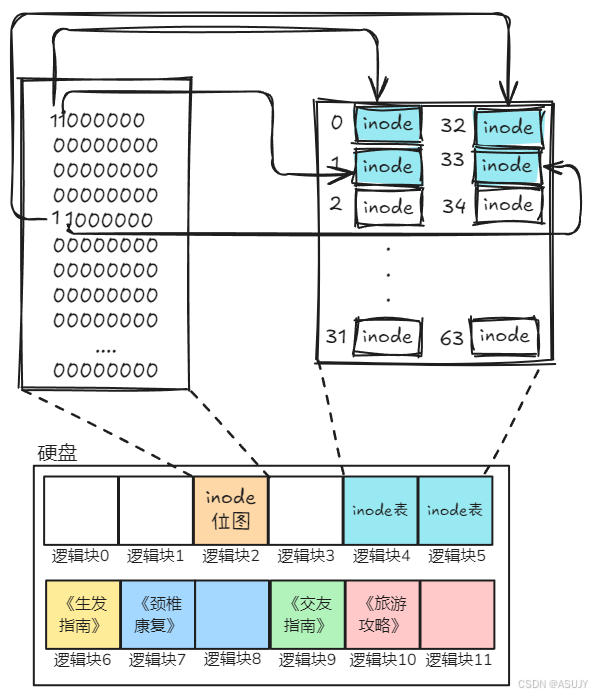
在寻找逻辑块存放inode位图的时候有一个问题,那就是如果inode位图存放到了 4号逻辑块 或者 6号逻辑块,那不就把inode表或者《生发指南》给覆盖掉了?
这肯定是不行的,所以需要找一个地方来记录逻辑块的使用情况。类似inode位图,因为只需要记录逻辑块已使用和未使用两种状态,所以只需要一个比特位就可以了。这里选取3号逻辑块来记录逻辑块的使用情况。如下图所示,在逻辑块位图中,分别指示了2~11号逻辑块已使用。一个逻辑块位图可以管理8192个逻辑块,即可以管理8MB的大小。
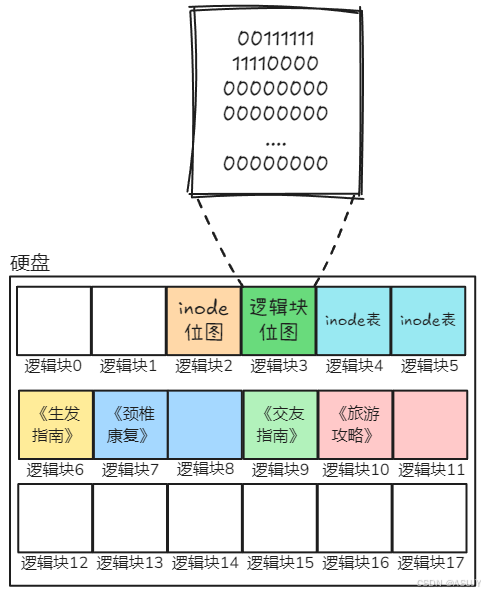
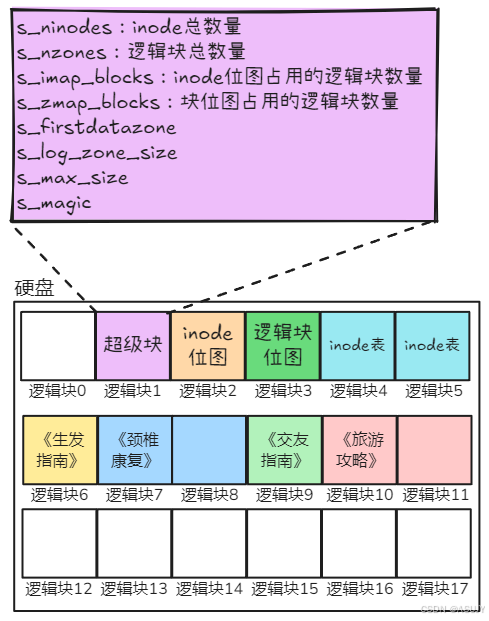
现在又有一个新的问题,那就是我们怎么知道硬盘一共被分成了多少个逻辑块?一共有多个逻辑块位图?一个有多少个inode位图?难道每次都遍历整个硬盘来获取这些信息吗?这显然是不好的。最直接获取这些信息的办法应该是找一个逻辑块来保存这些信息,每次获取这些信息就只需要到这个逻辑块中读取就可以了。我们就用1号逻辑块来存放这些信息吧,并且把1号逻辑块叫做 超级块 。超级块 中主要存放了有关整个文件系统(硬盘中的文件系统)的信息。一个设备一个超级块,超级块用于存放硬盘设备上文件系统结构的信息,并说明各部分的大小。
现在的文件系统已经可以使用了,但是有一个缺点,这个文件系统没有层级关系!如下图所示:

要想做到以下这种效果应该怎么办呢?

首先《生发指南》这种称为普通文件 ,"健康" 这种称为目录文件 , 如果要访问《生发指南》,那全文件名要写成"健康/《生发指南》"。
如果是普通文件 ,则这个 inode 所指向的数据块仍然和之前一样,就是文件本身原封不动的内容。
但如果是目录文件 ,则这个 inode 所指向的数据块,就需要重新规划了。
这个目录文件的inode所指向的数据块里应该是什么样子呢?可以是一个一个指向不同 inode 的紧挨着的结构体,比如这样。
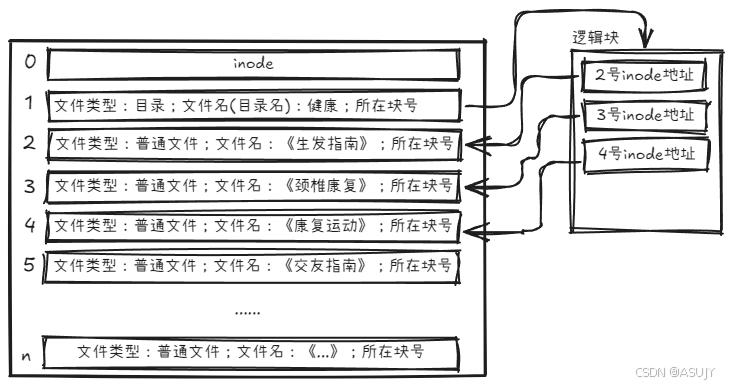
这样先通过 "健康" 这个目录文件,找到所在的逻辑块。再根据这个逻辑块里的一个个inode 地址,找到这个目录下的所有文件。
如果想要查看一下 "健康"这个目录下的所有文件(比如 ls 命令),将文件名都展示出来,怎么办呢?最容易想到的就是先获取目录指向的逻辑块,再根据这个逻辑块中的inode地址去inode表中找到对应的inode项,然后再从inode项中获取文件名。不过这样是很浪费时间的。
而让用户看到一个目录下的所有文件,又是一个极其常见的操作。所以,不如把文件名这种常见的信息,直接放在目录的逻辑块中比较好。同时,inode表 中 inode结构体 中的文件名就没什么用了,直接删除。
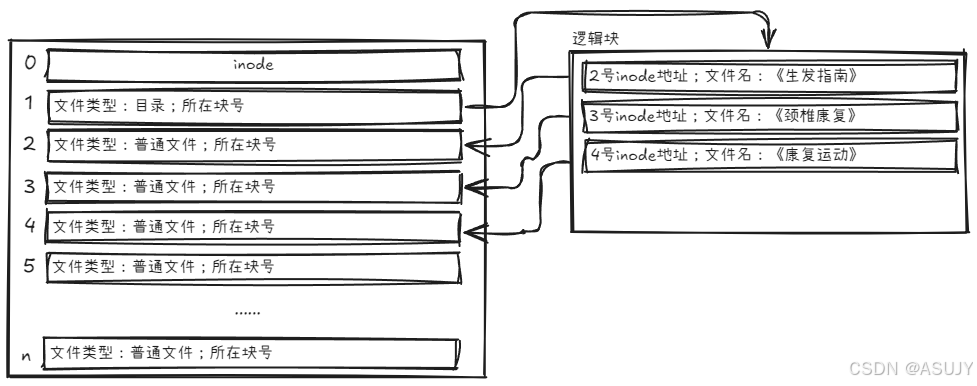
普通文件的逻辑块里面保存的是文件数据,目录文件的逻辑块里面保存的是目录里面一项一项的文件信息。
在目录文件的块中,最简单的保存格式就是列表,就是一项一项地将目录下的文件信息(如文件名、文件inode、文件类型等)列在表里。
列表中每一项就代表该目录下的文件的文件名和对应的inode,通过这个inode,就可以找到真正的文件。
通常,第一项是".",表示当前目录,第二项是"...",表示上一级目录,接下来就是一项一项的文件名和inode地址。
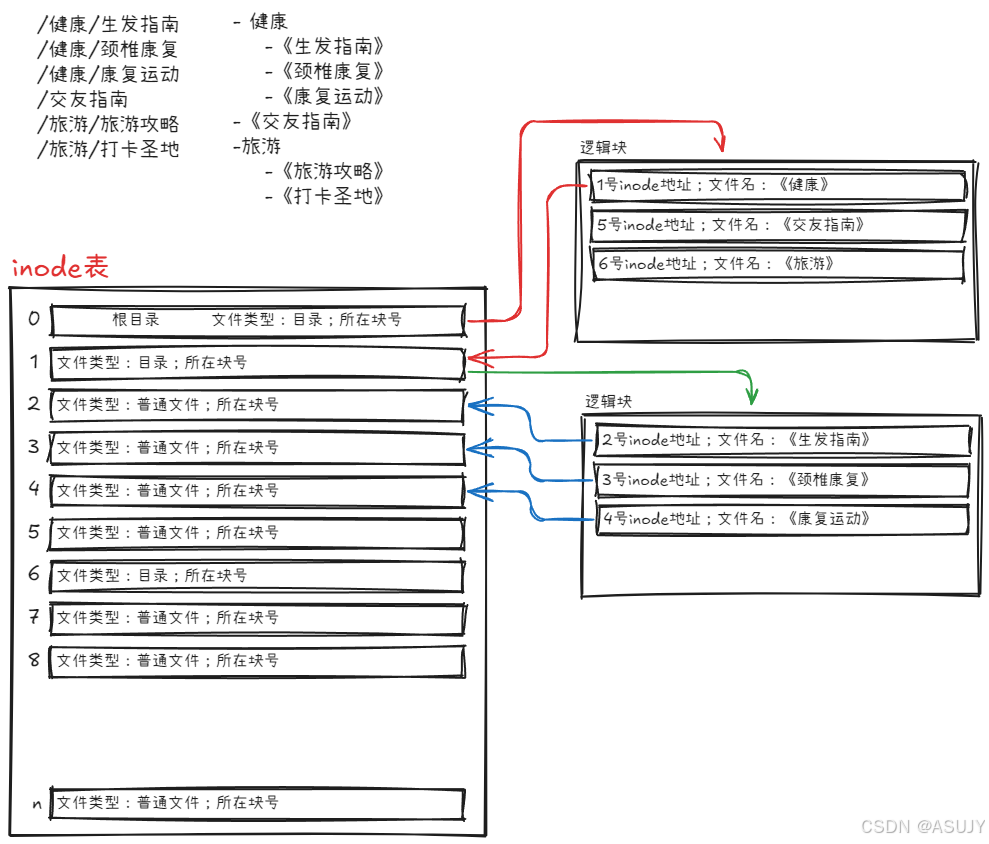
新问题又来了,因为现在inode中不存放文件名,那我们要怎么找到"健康"这个目录呢?答案就是规定inode表中的0号inode为根目录,一切的访问都从这个根目录开始,也就是0号inode中的逻辑块中存放着指向 "健康" 这个目录的地址。
如下图所示,先在inode表中找到根目录的inode,然后根据根目录inode的地址找到根目录对应的逻辑块,在逻辑块中找到 "健康" 这个目录的inode地址,然后在inode表中找出 "健康" 目录的inode,根据 "健康" 目录的inode中逻辑块的地址,找到对应的逻辑块。
三、根文件系统的加载过程:
加载根文件系统,其实就是把硬盘中已经存在的文件系统结构加载到内存中,即把硬盘中的某些数据加载到内存中。这样操作系统就可以通过内存中的数据,以文件系统的方式访问硬盘中的文件了。
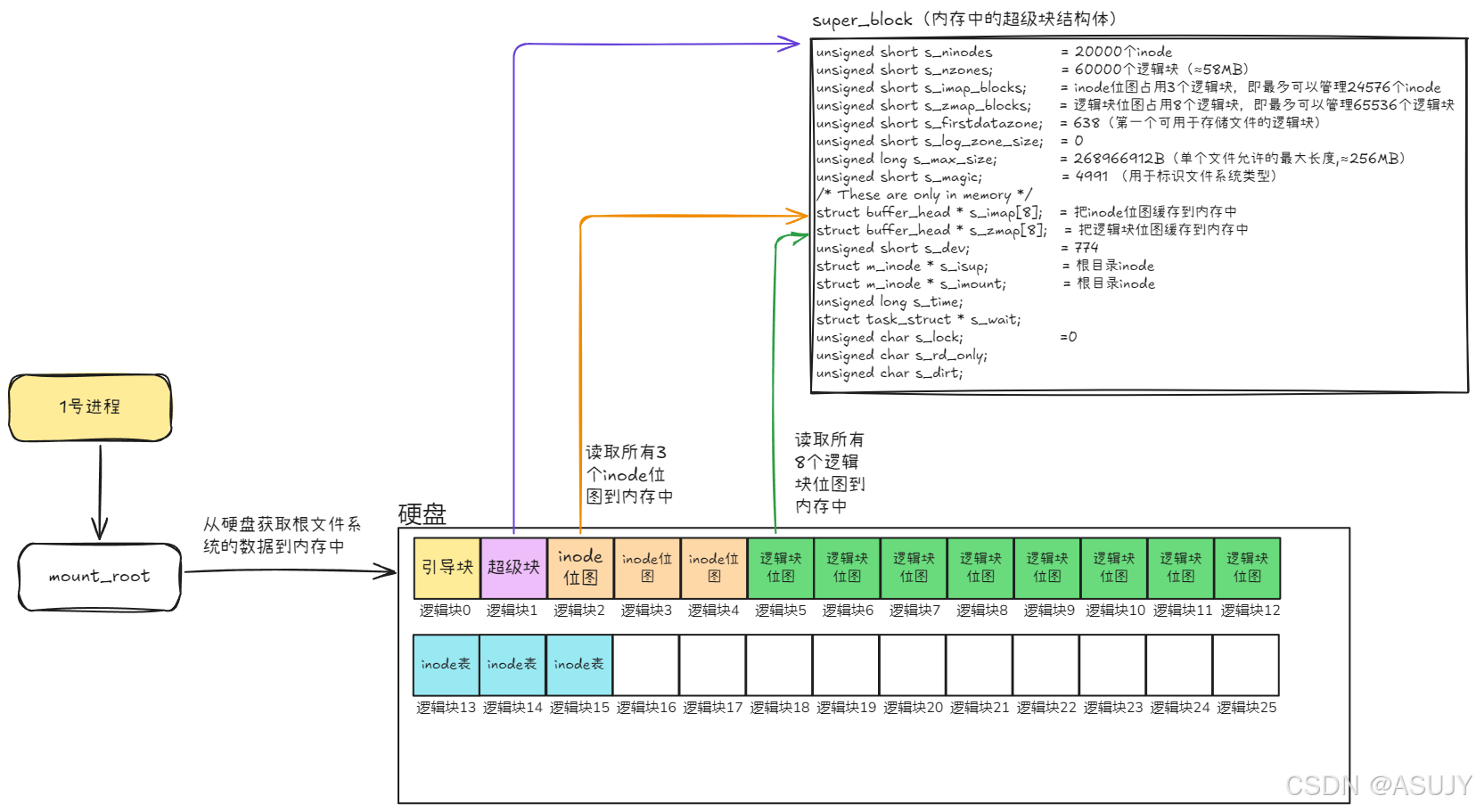
第一步,读取硬盘中的超级块信息到内存中,即把1号逻辑块中的内容加载到内存中,并且操作系统会用特定的数据结构来解释这些数据的含义。同时把inode位图和逻辑块位图也都加载到内存中,这样能够加快操作系统管理文件的速度(不用每次都从硬盘读取inode位图和逻辑块位图来查找哪些inode和逻辑块是空闲的)。
第二步,读取硬盘中根目录inode到内存中。然后设置当前进程(1号进程)的工作目录和根目录都指向根inode。
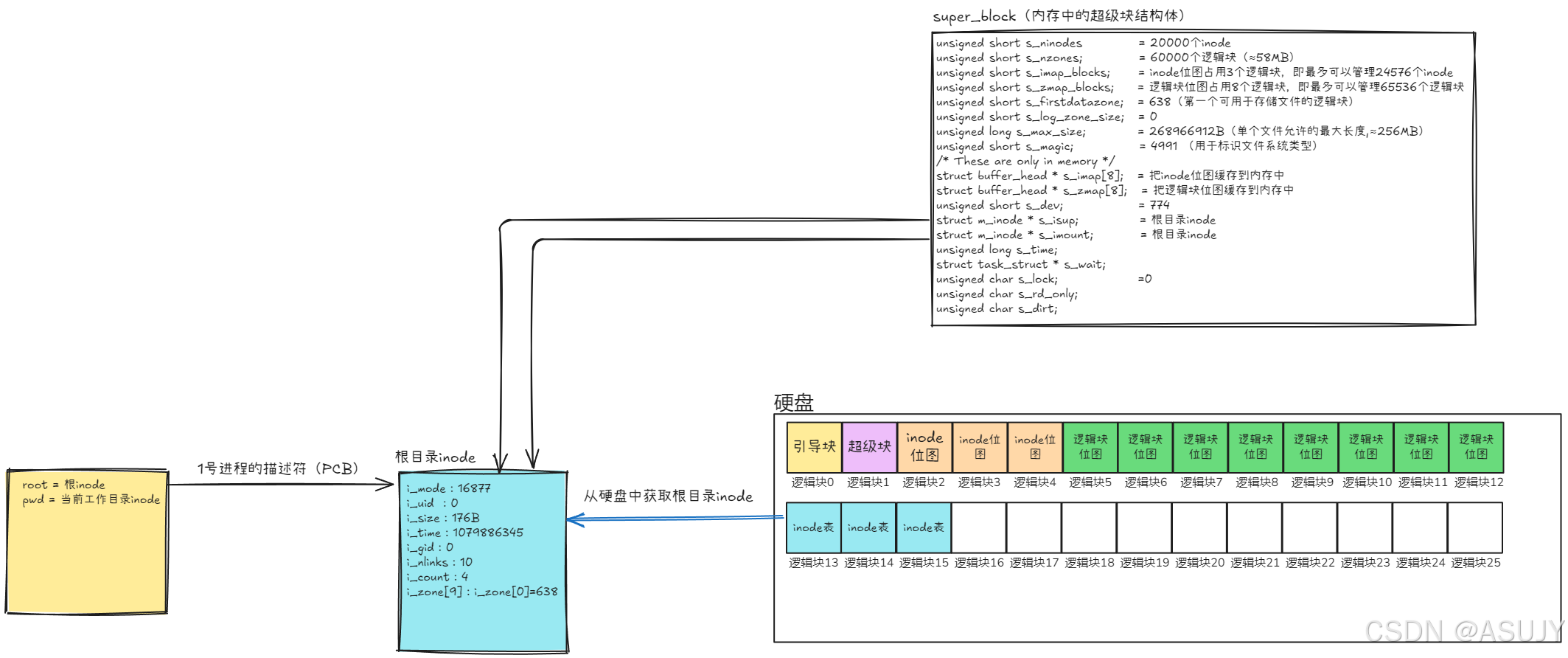
操作系统不会把所有的inode全部加载到内存中(虽然这样能够加快文件处理速度),因为内存有限。只有当需要使用到对应的inode的时候,才会把这个inode加载到内存中。现在因为需要根目录inode,所以才把根目录inode加载进来。
超级块加载到内存中的时间:当文件系统挂载时,加载到内存中。
inode加载到内存中的时间:当文件被访问时,加载到内存中。
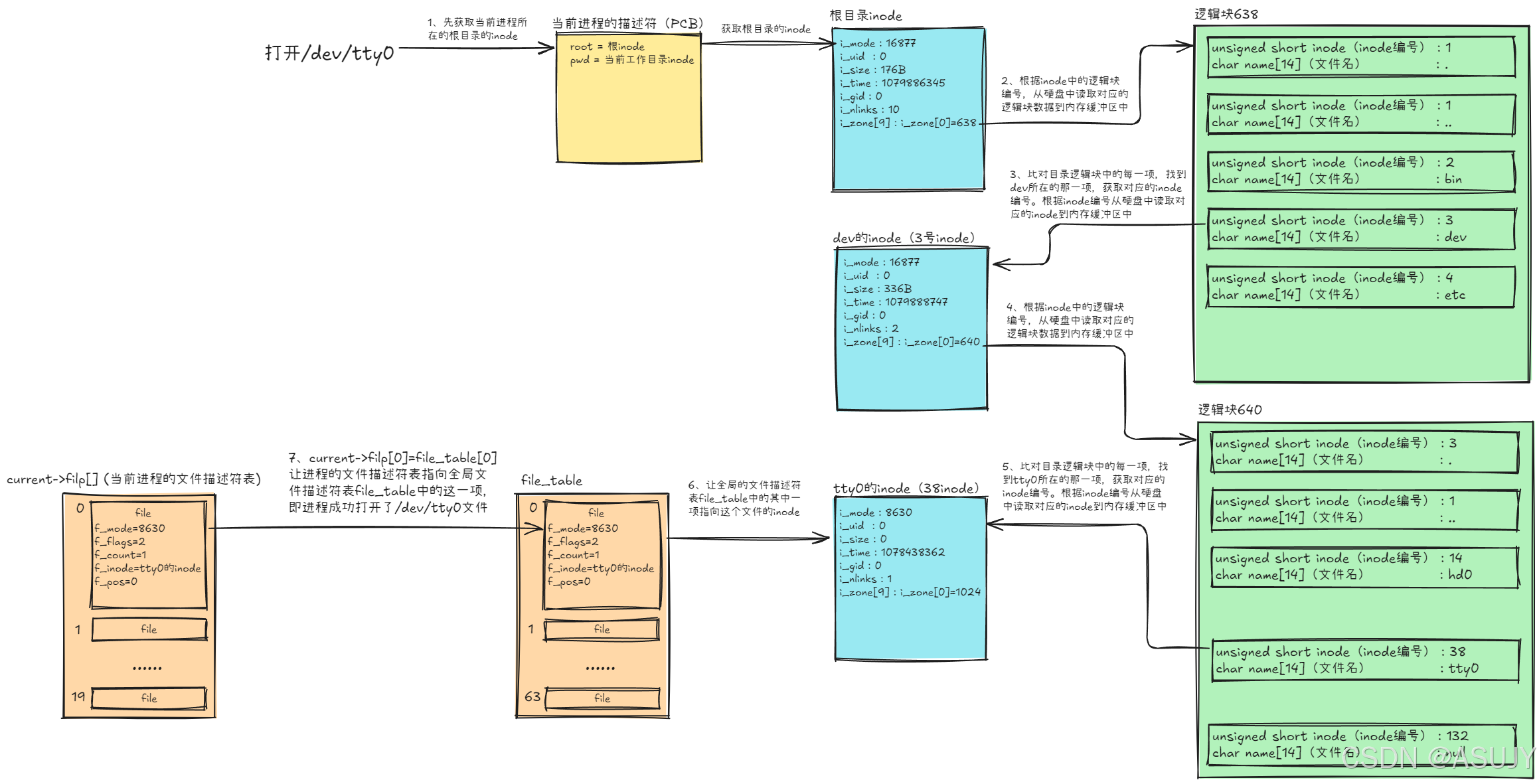
四、打开一个文件的流程(以Linux0.11中的minix文件系统为例,其它文件系统也类似)
在minix1.0的文件系统中,打开/dev/tty0的全过程如下所示(即让当前进程的文件描述符表中关联/dev/tty0这个文件的inode):