一、LVS
四层负载均衡
LVS有四种工作模式,十三种调度算法
NAT 地址转换模式(多目的ip的DNAT)
DR直连路由模式(修改请求报文的MAC地址)
TUN IP隧道模式
FULL-NAT 全NAT模式(在Linux的kernel中暂不支持)ipvsadm管理工具,管理lvs集群
ip_vs是内核的一个模块,通过netfiler的网络子系统来修改数据包,达到数据转发的目的。
yum install ipvsadm -y #安装lvs1、NAT工作模式
①客户端CIP向业务VIP发起请求,此时源地址是CIP,目的地址为VIP
②请求到达LVS后,ip_vs模块根据调度算法选择RIP作为后端服务器
③修改数据包,源地址保持不变,将目的地址修改为调度后的RIP地址
④(后端服务器的网关,需要指向LVS的DIP)RIP响应请求后,将数据包通过网关发送出去,此时的DIP相当于RIP的网关地址,将请求响应到CIP
特点:
①集群和LVS的节点要在同一个网络(集群内部互通)之中,并且LVS的DIP要充当RS的网关地址(集群内部的出口地址)。
②LVS要在客户端和真实服务器端进行数据转发,也就是负载均衡服务器内核要支持数据包转发
数据包转发------>开启ip_forward允许ip转发
③RS服务器可以是任何操作系统,不用做任何集群相关配置
④LVS支持做端口映射给后端服务器
配置LVS
ipvsadm
-A 添加一个集群
-a 添加后端真实服务器
-r 添加真实服务器时指定地址(如果不指定端口,默认跟VIP暴露的端口一致)
-t 集群使用TCP协议
-u 集群使用UDP协议
-D 删除规则
-s 指定调度算法(不指定默认是加权轮询)
-w 指定后端服务器权重
-m 指定lvs工作模式为NAT
-i 指定lvs工作模式为TUN
-g 指定lvs工作模式为DR
-l 查看集群条目
-n 以数字方式查看集群条目
-c 查看集群客户端连接情况
ipvsadm -A -t VIP地址:端口 #添加集群
ipvsadm -a -t VIP地址:端口 -r 真实服务器地址 -m -w 1 #添加真实服务器
ipvsadm -a -t VIP地址:端口1 -r 真实服务器地址:端口2 -m -w 1 #添加真实服务器,并将VIP的端口1接收到的流量转发给真实服务器的端口2
ipvsadm -ln 查看lvs规则
ipvsadm -C 清空规则
ipvsadm -lnc 查看当前连接状态
服务器端添加网关地址:
ip route add default via 网关地址 dev 网卡名(指定从哪个网口把流量转发出去)2、DR工作模式
实现方式:
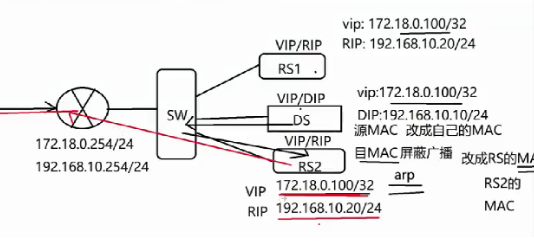
每台RS上都有VIP,LVS上有DIP和VIP
DS(负载均衡服务器)提前通过arp获取到集群内所有节点的RIP以及MAC地址。
当用户向VIP发起请求,此时通过屏蔽RS节点对arp的响应从而实现让LVS的VIP响应请求,LVS将源MAC改为自己的MAC,目的MAC改为调度到的RS的MAC,RS回包时,源MAC为RS的MAC,源地址为VIP,目的地址为CIP,目的MAC为LVS的网关MAC 。
特点:
1、DIP与RIP必须在同一个局域网中,每台RS节点都必须要自己真实的网关,且网关不能指向DIP。
2、RIP可以不是私网地址,可以真正访问网络
3、DR模式下不能实现端口映射
4、RS支持的操作系统必须支持屏蔽ARP(通常是Linux系统,通过内核参数来屏蔽arp)
5、负载能力更强,DR模式下LVS只有下行流量,上行流量由真实服务器直接回应客户端,因此业务的承载量通常是nat的数十倍。
路由器(可由一个服务器代替)的配置:
1、给路由器增加两张网卡
2、在路由器上开启ip_forward转发内核参数
3、在路由器防火墙上开启地址伪装
LVS的配置:
1、将VIP地址配置在dummy2类型的环回口上
2、开启ip转发
配置集群:
ipvsadm -A -t VIP地址:端口 -s rr #添加集群
ipvsadm -a -t VIP地址:端口 -r 真实服务器地址 -g #添加真实服务器
ipvsadm -ln 查看lvs规则
ipvsadm -C 清空规则
ipvsadm -lnc 查看当前连接状态RS的配置
1、将VIP地址配置在dummy2类型的环回口上
2、配置RS禁止响应ARP
net.ipv4.conf.default.arp_ignore=1
默认为0 任意接口收到arp就会响应
1 仅目标ip在本机上才响应arp
net.ipv4.conf.dummy2.arp_ignore=1
该接口不回应arp(当数据包进来,只让LVS响应)
配置RS ARP的通告级别
net.ipv4.conf.all.arp_announce=2
默认值0 表示向每个接口通告ARP
2表示避免向非本网络通告(避免RS都向交换机通告自己的VIP地址)3、TUN隧道模式
NAT和DR模式,都只能和LVS在同一局域网内
TUN再封装一层ip报文
实现方式:
在DR模式的基础上,封装一层IP报文,该报文源IP是LVS的DIP,目的IP是LVS根据负载均衡调度算法选择出来的RIP,当请求到达RIP以后,此时RS根据IP隧道解封装 ,由RS直接处理客户端的响应(RS上要有VIP)
特点:
1、DIP和RIP不再需要在同一个局域网内,但是DIP、RIP和VIP都要是公网地址
2、RS的真实服务器必须要支持IP隧道协议(ipip隧道、gue隧道、gre隧道),默认使用的是ipip隧道协议
3、IP隧道模式也不支持端口映射
4、支持RS的数量非常多,但需要更多的公网IP地址
4、FULL-NAT模式(商业模式)
在nat模式的基础上,可以同时修改请求的源IP和目的IP,在多个vlan之间进行源地址和目标地址的转发
特点:
1、VIP必须是公网地址,RIP和DIP只能是私网地址,并且RIP和DIP通常不在同一个局域网,且有多个vlan环境,所有RIP的网关也不会指向DIP。
2、RS收到请求的源地址是来自于DIP的,因此RIP虽然不指向DIP,但是必须将数据发送给DIP,也就是要响应DIP,最终的所有流量都要通过LVS发送给客户端。(在层层局域网中不断修改源目的IP,最终转发给DIP)
ipvsadm配置开机自启的方式:
ipvsadm --save > /etc/sysconfig/ipvsadm
systemctl start ipvsadm
5、调度算法的分类
静态算法:根据算法本身规则进行调度
动态算法:根据业务的承载进行调度
13种:
静态算法:
rr轮询
wrr加权轮询
SH源地址哈希
DH目的地址哈希
动态算法:
lc最小连接数(活动连接数*256-非活动连接数)
wlc 加权最小连接数(活动连接数*256-非活动连接数/权重值)
二、Nginx和Harpoxy
1、Nginx
nginx可以进行四层和七层负载均衡
location 和 proxy是否以斜杠结尾,表示了完全不同的访问路径(location和haproxy_pass都加/)
location /test/{proxy_pass http://192.168.1.123/;},最终转发路径为:http://192.168.1.123/index.html (将location代理到后端服务器)
location /test/{proxy_pass http://192.168.1.123;},最终转发路径为:http://192.168.1.123/test/index.html
location /test{proxy_pass http://192.168.1.123/;},最终转发路径为:http://192.168.1.123//index.html
location /test{proxy_pass http://192.168.1.123;},最终转发路径为:http://192.168.1.123/test/index.html反向代理和负载均衡结合都要定义到http的段落中,都要location
2、haproxy
特点
1、四层(实现TCP的转发)和七层(支持HTTP的调度)负载均衡、端口映射
2、可以根据ACL的访问控制将前端的请求调度到后端服务器(可实现动静分离)
3、和nginx一样,所有的流量都需要经过haproxy,并且它本身是单进程模型,通过异步IO(事件方式)来处理连接
4、支持图形化资源控制,并且支持通用的负载均衡算法,比如轮询、加权轮询算法的特征:
1、部分算法支持动态调整权重(rr、leastconna、hash),不需要重启haproxy
2、支持慢启动
3、hash的方式多样,几乎可以涵盖HTTP的头部信息,也就是可以对url、客户端来源、头部文件信息、用户agent等进行hash计算
4、强一致性haproxy的日志配置
vim /etc/haproxy/haproxy.cfg
log 127.0.0.1 local2 info #指定rsyslog中日志的级别 info级别表示info以上的级别,也就是包含错误、警告、严重错误日志。
重启haproxy
vim /etc/rsyslog/rsyslog.conf #编写local2.info日志存放文件
$ModLoad imudp #加载udp模块
$UDPServerRun 514 #开启监听端口
local2.* /var/log/haproxy.log #指定日志类型和级别存放文件 *表示任意级别,也可以是local2.info
重启rsyslog服务
systemctl restart rsyslog.servicedefaults的优先级高于global
配置文件
option forwardfor except 127.0.0.1/8 #将客户端IP透传给后端服务器,因为负载均衡器要check后端服务的状态,所以把负载均衡本地的探测IP排除,避免出现在后端服务器的日志中
frontend main #main是前端名
bind *:监听端口
default_backend http_back #将监听到的请求转发到后端的http_back服务器组
backend http_back
balance roundrobin #设置调度算法为轮询
server 服务器名 IP:端口 check(检测该服务器的存活状态)
server 服务器名 IP:端口 check(检测该服务器的存活状态)
server 服务器名 IP:端口 check(检测该服务器的存活状态)
server 服务器名 IP:端口 check(检测该服务器的存活状态)
......基于acl的配置

Haproxy的acl语法规则:
acl的格式:
acl acl的名称 acl的匹配条件(理解为类别) 字符操作符 具体操作符 操作对象匹配条件:来源地址、请求方法、目标地址、url等
acl的调度规则:
请求来源控制访问:
acl acl_name src 192.168.1.0/24
请求方法控制:
acl allow_get method GET
acl allow_get method POST
域名访问控制:
acl allow_domain hdr(host) -i example.com #匹配请求头中的User-Agent,-i不区分大小写
URL请求来源进行访问控制:
acl php url_reg(表示将使用正则表达式去匹配url) -i \.php$ #使用正则表达式去匹配url
acl php url_end(表示匹配url中,以什么结尾的内容) -i .php #直接指定url中以.php 结尾的文件
acl dir path /api/v1 #匹配指定的路径为ACL指定后端服务器:
use_backend 直接指定后端
use_backend backend_name {if |unless } acl_name
请求条件跳转:
redirect location http://www.baidu.com/ if acl_name
default_backend 前端默认使用的后端,不满足acl时使用的后端
http的拒绝和允许:
defaults
mode http
acl acl_name src 192.168.1.0/24
http-request allow if acl_name
http-request deny if acl_name
TCP的允许和拒绝:
客户端与服务器建立连接时进行判断:
tcp-request connection {accept |reject} [{if unless} acl_name
服务端发送响应后进行判断:
tcp-response connection {accept reject | close} [{if unless} acl_ name
例如:
defaults
mode tcp
frontend main #main是前端名
bind *:监听端口
acl acl_name src 192.168.1.0/24
tcp-request connection reject if acl_name
default_backend http_back
backend http_back
balance roundrobin #设置调度算法为轮询
server aaa 172.18.0.20:81 check例如:
frontend main #main是前端名
bind *:监听端口
acl source_ip src 172.18.0.1
use_backend test_back if source_ip
default_backend http_back #将监听到的请求转发到后端的http_back服务器组
backend http_back
balance roundrobin #设置调度算法为轮询
server aaa 172.18.0.20:81 check
server bbb 172.18.0.20:82 check
backend test_back
server ccc 172.18.0.20:83 checkACL 具备逻辑关系:
逻辑与: 默认所有的acl 之间都是逻辑与的关系,因此逻辑与没有任何方式进行表示,两个条件需要同时满足
逻辑或:使用or来进行表示,只要满足两个条件中的任意一个即可
逻辑非:使用!表示拒绝
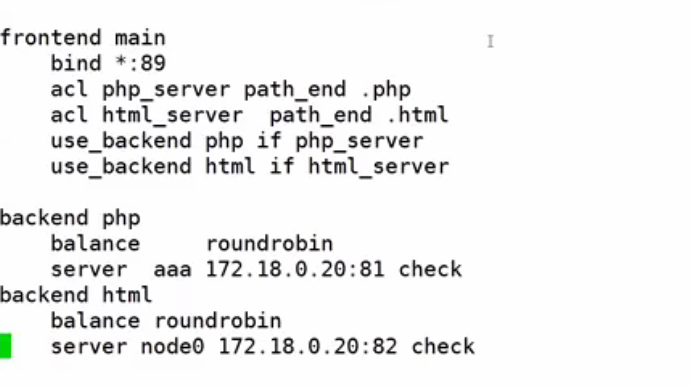
通过Haproxy实现动静分离
Haproxy的节点 172.18.0.10
PHP 的节点 172.18.0.2:81 #专门处理PHP的文件
html的节点 172.18.0.2:82 #专门处理php网页静态文件
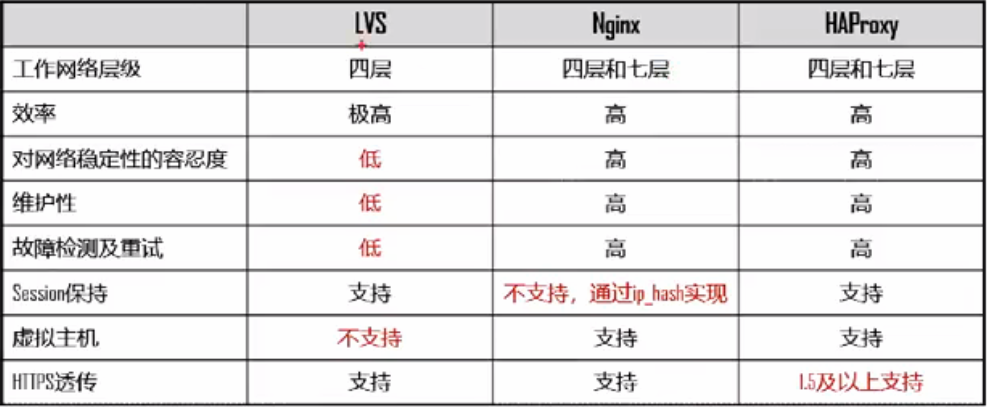
LVS、nginx、Haproxy负载均衡对比:
三、keepalived
nginx和Haproxy都可以通过自己的配置实现对后端服务器的健康检查"
nginx------>配置health_check
Haproxy------>为每个节点配置check
功能
1、对LVS进行健康检查
2、通过VRRP将浮动IP迁移到合适的节点上

keepalived支持的健康检查类型
tcp_check 第四层
http_get第五层 url
ssl_get
misc_check 自定义脚本检测keepalived通过VRRP虚拟路由冗余协议来实现高可用,也就是通过心跳转移故障节点。

initialize不可用状态(初始状态或节点故障)
master 在该状态下,keepalived正常工作并承载集群的流量访问出入口,也就是该状态下所在的节点是浮动IP所在节点,并且向网络中正常发送VRRP的报文
backup备用状态,keepalived处于备用模式,不会承载集群的流量,仅接受和处理VRRP心跳报文,并监听master状态,一旦master节点发生故障,则抢占浮动IP,将业务流量切换到该节点,且自身变成master节点
VRRP选取机制
1.通过各个节点的优先级来进行比较,优先级大的成为master
2.通过比较接口的主IP地址,比较值大为 master 节点
master down后,backup通过心跳检测到,然后多个backup之间通过VRRP的选举规则,选举出新的masterKeepalive 的三种防止脑裂的方式
1.通过第三方仲裁(第三方同时监控master和backup的状态,并同步给他俩)
2.通过加强心跳网络(master和backup之间,搞两个心跳)
3.通过自定义检测脚本(脚本检测master和backup的状态,若状态不正常,直接down掉)
keepalived的部署(主备都配置)
keepalived默认只能检测到节点的keepalived存活状态
yum install keepalived -y
vim /etc/keepalived/keepalived.conf
#自定义检测脚本
vrrp_script nginx_check{
script /etc/keepalived/nginx_check.sh
interval 1 #每隔一秒执行一次
weight -5
fail 3
#定义VIP节点
vrrp_instance VI 1{
state MASTER
interface ens33
virtual router id 51 #主备都一致
priority 255
advert int 1
authentication{
auth type PAss
auth pass 1111
virtual ipaddress #VIP
{172.18.0.90/24
}
track_script{ #引用健康检查配置
nginx_check
}
}vim /etc/keepalived/nginx_check.sh
结束keepalived服务或者是返回值exit为非0,VIP漂移
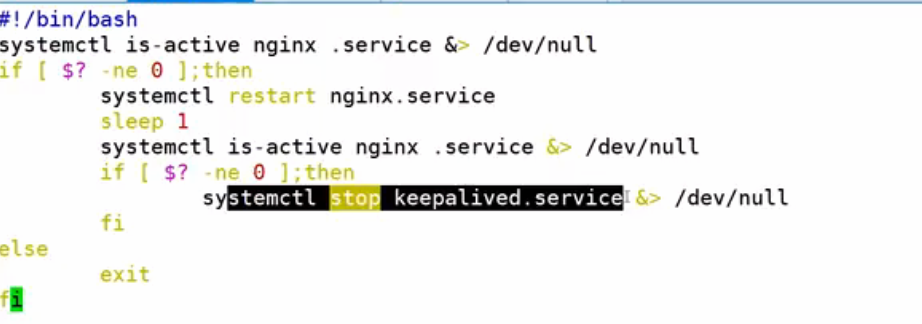
LVS+keepalived,keepalived中可以配置LVS的VIP和后端服务器信息,以及健康检查