MAGREF:用于任意参考视频生成的掩码引导与主体解耦
paper是字节发布在Arxiv 2025的工作
paper title:MAGREF: Masked Guidance for Any-Reference VideoGeneration with Subject Disentanglement
Code:链接
Abstract
我们研究任意参考视频生成任务(any-reference video generation),其目标是在任意类型及任意组合的参考主体与文本提示条件下合成视频。该任务长期面临诸多挑战,包括主体身份不一致、多参考主体之间的纠缠,以及拷贝-粘贴式伪影等问题。为了解决这些问题,我们提出了 MAGREF------一个面向任意参考视频生成的统一且高效的框架。我们的方法引入了掩码引导(masked guidance)和主体解耦机制(subject disentanglement),从而实现了在多样参考图像与文本提示条件下的灵活生成。具体而言,掩码引导采用区域感知的掩码机制,并结合逐像素的通道级拼接操作,使多个主体的外观特征在通道维度上得以保留。这样的设计在无需对预训练骨干网络进行任何结构修改的前提下,既保证了身份一致性,又保留了骨干模型原有的能力。为缓解主体混淆,我们引入主体解耦机制,将由文本条件提取的每个主体的语义信息注入到其对应的视觉区域中。此外,我们构建了一个四阶段数据管线来构造多样化的训练样本对,从而有效减轻拷贝-粘贴伪影问题。在综合基准上的大量实验表明,MAGREF 在各项指标上持续优于现有最新方法,为可扩展、可控且高保真的任意参考视频生成铺平了道路。
1 Introduction
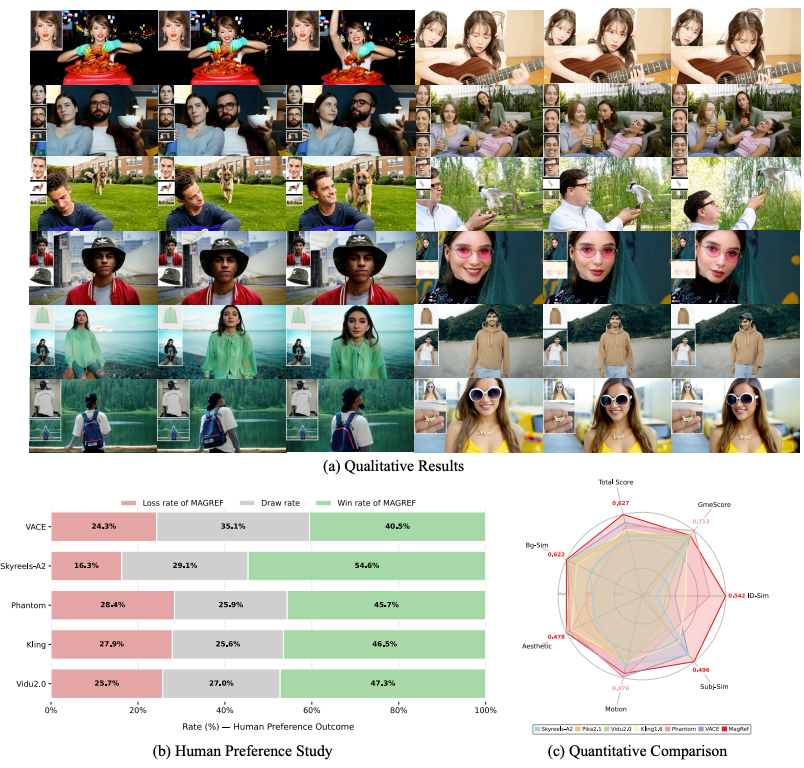
图 1 我们提出了 MAGREF,一个灵活的视频生成框架,能够在一次生成过程中支持包括人类、动物、服饰、配饰和环境在内的任意主体组合,同时保持视觉一致性并忠实遵循文本指令。(a) 在多样主体与场景上的定性结果,左上角给出了参考图像。更多定性案例见图 9--13。(b) 将 MAGREF 与现有模型进行比较的用户研究结果。© 在多主体评估集上的定量对比结果。
扩散模型的最新进展 17, 32, 41 已在很大程度上提升了在文本提示或单张参考图像条件下生成真实且时间连贯视频的能力。这些突破吸引了学术界和工业界 2, 31, 33, 40 越来越多的关注,推动了对可控视频合成的兴趣激增。超越仅由文本或图像驱动的生成,人们对利用多参考主体来实现对外观和身份的细粒度控制的需求正在不断增长。这一范式转变引发了对"任意参考视频生成"(any-reference video generation)的广泛探索,其目标是将多样的视觉线索整合为连贯、个性化且高保真的视频序列。
然而,在视频生成中同时以文本描述和多张参考图像作为条件极大地扩展了条件空间,导致在任意主体组合(如人类、动物、服饰、物体和环境)之间出现复杂的交互。这种复杂性使得很难在跨帧的过程中可靠地保持主体身份、在不产生混淆的情况下解耦多个主体,并在整合多样视觉线索时避免拷贝-粘贴式伪影。具体而言,这些复杂性可以归纳为以下主要挑战:(1)身份不一致:如面部结构或配饰等外观细节无法保持连贯;(2)多参考主体之间的纠缠:来自不同参考图像的身份被错误地混合或混淆;(3)拷贝-粘贴伪影:破坏了视觉真实感和场景完整性。近期工作 49, 59, 64 在保持单一身份方面取得了一定进展,但它们往往依赖外部身份模块和单图像参考,因而在真实应用中可扩展性有限。其他方法 21, 29, 65 则通过在 token 维度上拼接视觉 token 来简化条件建模,但这类文生视频框架需要大规模数据集,并且在身份保持与泛化能力方面表现不佳。12 探索了另一种图生视频设计,即在通道维度上配合时间掩码拼接参考图像,但在统一且有效地解决上述挑战方面仍显不足。
为克服这些限制,我们提出 MAGREF(Masked Guidance for Any-Reference Video Generation with Subject Disentanglement),从三个方面应对上述问题。(1)用于一致多主体身份保持的掩码引导。我们通过逐像素的通道级拼接在像素层面上以参考图像为条件,从而保留细粒度的外观细节;同时引入区域感知的掩码机制构建具有每个主体空间支持的参考画布,使模型能够在统一架构内(无需结构改动)对任意类别主体(人类、动物、服饰、物体、环境)进行精确条件控制。(2)用于缓解跨主体混淆的主体解耦。我们提出主体解耦机制,将由文本条件得到的主体 token 语义值显式注入到其对应的视觉区域中,从而强化身份分离,减少任意参考视频生成中的跨参考混淆。(3)系统化的四阶段数据管线以减轻拷贝-粘贴伪影。我们设计了一条高效的数据处理管线,将通用过滤与描述生成、目标处理、人脸处理以及跨样本对构建整合到一个统一系统中,在抑制拷贝-粘贴伪影的同时生成多样化的训练样本对。上述组件共同促进了可扩展、可控且高保真的任意参考视频合成,使得高度逼真的视频生成成为可能。
总体而言,MAGREF 的关键贡献如下:
- 我们提出了一种统一的掩码引导设计,将区域感知的掩码机制与逐像素通道拼接结合,用于在通道层面注入参考信息。该设计在进行最小化架构修改的前提下,保留细粒度外观线索,并支持跨任意类别的精确主体条件控制。
- 我们构建了一个主体解耦机制,将来自文本条件的语义值注入到其对应的视觉区域,从而在无需额外身份提取模块的情况下,实现身份的清晰分离并缓解跨参考混淆。
- 我们建立了一条系统化的四阶段数据管线,用于构造多样且跨配对的训练样本,有效抑制拷贝-粘贴伪影并提升鲁棒性。大量实证评估表明,MAGREF 在多主体一致性视频合成方面生成了高质量结果,超越所有现有方法,并在多个基准上取得了最新的性能。
2 Related Work
视频生成模型 近期的视频生成进展通常依赖变分自编码器(VAE)22, 26, 43 将原始视频数据压缩到低维潜空间。在这一压缩的潜空间中,使用基于扩散的方法 16, 42 或自回归方法 6, 37, 57 进行大规模生成式预训练。借助 Transformer 模型 32, 44 的可扩展性,这些方法在性能上持续取得提升 3, 4, 54。这一进步显著拓展了内容生成的可能性,并激发了后续关于文生视频 14, 24, 38, 46, 54, 56, 58 和图生视频 3, 5, 8, 13, 53, 55, 61, 62 生成模型的研究。
主体驱动视觉生成 从参考输入生成身份一致的图像和视频,需要准确捕捉主体特定特征。现有方法大致可分为基于微调和免训练(training-free)两大类。基于微调的方法 7, 50, 52, 66 通常依赖高效微调策略(如 LoRA 18 或 DreamBooth 39)将身份信息嵌入到预训练模型中,但需要对每个新身份进行重新微调,从而限制了可扩展性。相比之下,免训练方法在推理阶段采用前向传播、且不对每个身份单独微调,通常通过增强交叉注意力或自注意力来更好地保持身份一致性。代表性工作包括 StoryDiffusion 67,其采用一致性自注意力和语义运动预测;MS-Diffusion 48 则利用基于约束的重采样以及多主体交叉注意力来捕捉主体的细粒度细节。
近期工作探索了多种主体驱动视频生成策略。一部分方法专注于身份保持,例如 ConsisID 59 通过频域分解来维持人脸一致性。其他方法,如 ConceptMaster 20 和 VideoAlchemy 7,结合 CLIP 35 编码器与 QFormer 25 融合视觉-文本嵌入,以实现多概念定制。另一类工作 11, 19 引入多模态大语言模型(MLLM),如 Qwen2-VL 47 和 LLaVA 28,以增强提示与参考之间的交互。在 Wan2.1 46 的基础上,ConcatID 65、VACE 21、Phantom 29 和 SkyReels-A2 12 等方法进一步探索参考条件建模,要么通过将图像潜变量与噪声潜变量拼接,要么将参考特征作为条件输入注入,以引导扩散过程。
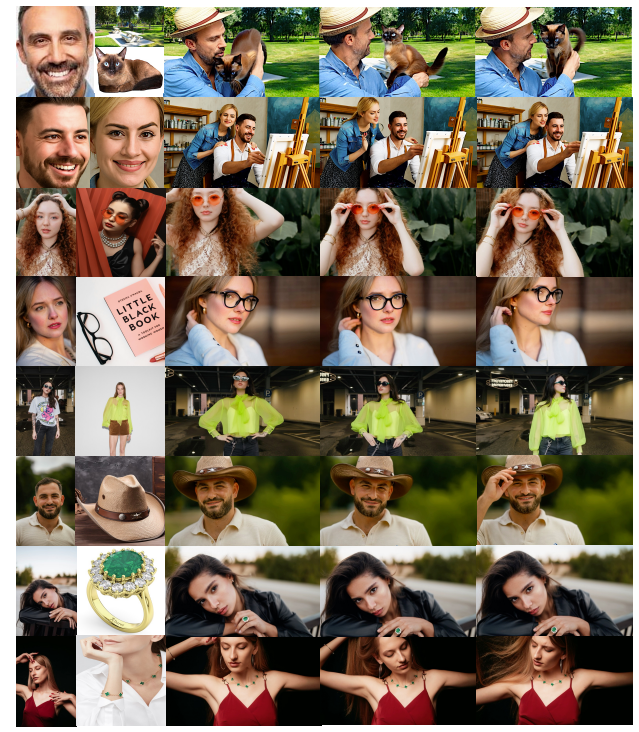
图 2 定性结果展示了多样的主体与场景,前两列给出了参考图像。MAGREF 支持广泛的组合形式,包括人物与配饰、时尚单品等。即使在复杂或杂乱的参考图像中,它也能可靠地识别目标物体,并忠实地遵循文本提示。
3 Method
给定一组参考图像及其对应的文本提示,我们的目标是生成在指定主体外观上保持一致的视频。关于视频扩散模型的基础背景介绍见附录 A。接下来,我们将介绍所提出的掩码引导与主体解耦机制,并详细说明四阶段的数据整理流程,该流程对视频--文本数据进行分解,并构造多样化的参考配对样本。
3.1 Video Generation via Masked Guidance
我们提出了 MAGREF,这是一种用于从多样参考图像进行连贯任意参考视频生成的新框架(见图 3)。不同于单主体场景,任意参考设定要求模型在主体数量和分布未知的情况下自动识别并对齐各个主体。为应对这一挑战,掩码引导机制引入了区域感知的掩码机制,并结合逐像素的通道级拼接,将多张参考图像中的信息注入到生成过程中。这样的设计使模型能够更好地利用预训练视频骨干网络的身份保持能力,并将其有效扩展到任意参考设置中。
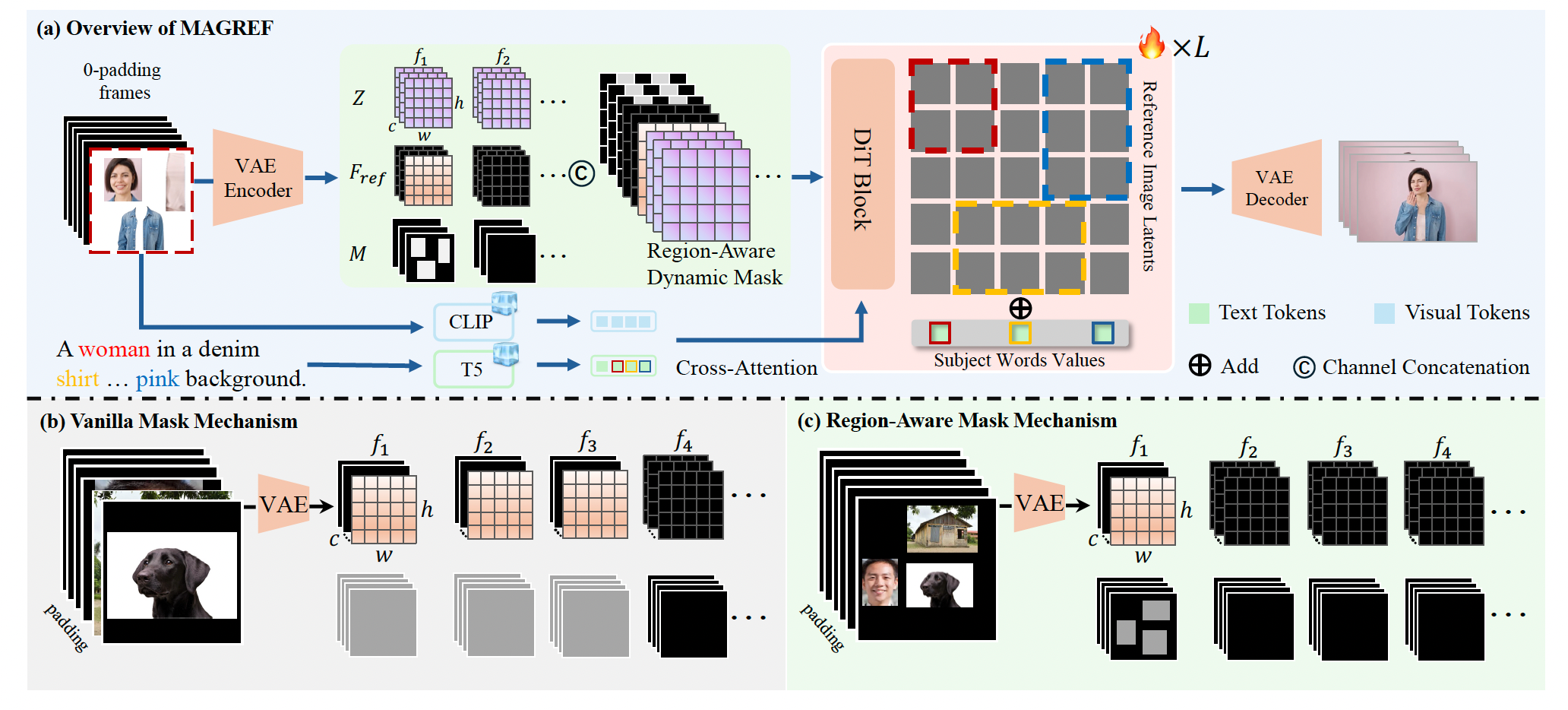
图 3 (a) MAGREF 概览。我们引入了一种区域感知的掩码机制来编码多个参考图像,并将其与噪声潜变量进行拼接;同时通过主体解耦,将每个参考主体与其对应的文本标签建立关联,以避免跨主体纠缠。与 (b) 朴素掩码机制(将参考图像在帧维度上拼接)相比,我们的 © 区域感知掩码机制将多个参考合成为一张复合图像,经由 VAE 编码后,再应用下采样的二值掩码以标注主体区域,从而在图生视频(I2V)模型中更好地保持首帧一致性。
区域感知掩码机制 为在保持与 I2V 建模范式一致的同时准确融合多主体信息,我们引入了一种区域感知掩码机制,该机制将参考图像进行拼接并同时生成对应的区域掩码。具体而言,给定一组 N N N 个参考图像 { I k } k = 1 N \{I_k\}{k=1}^N {Ik}k=1N,我们首先将所有图像放置在空白画布上的不同空间位置 { p k = ( x k , y k ) } k = 1 N \{p_k = (x_k, y_k)\}{k=1}^N {pk=(xk,yk)}k=1N。这样形成一张复合图像 I comp I_{\text{comp}} Icomp,其中每个像素的值由其位置对应的源图像决定。该过程表示为:
I comp ( i , j ) = ∑ k = 1 N I k ( i − y k , j − x k ) ⋅ 1 ( i , j ) ∈ R k , (1) I_{\text{comp}}(i, j) = \sum_{k=1}^N I_k(i - y_k, j - x_k) \cdot \mathbf{1}_{(i, j) \in R_k}, \tag{1} Icomp(i,j)=k=1∑NIk(i−yk,j−xk)⋅1(i,j)∈Rk,(1)
其中 R k R_k Rk 是参考图像 I k I_k Ik 在画布上的矩形区域, 1 ( ⋅ ) \mathbf{1}{(\cdot)} 1(⋅) 是指示函数。复合图像 I comp I{\text{comp}} Icomp 被视为单个参考帧,使模型能够继承图生视频生成能力。
与此同时,我们构造二值掩码来显式指示每个主体对应的空间区域:
M ( i , j ) = 1 ( i , j ) ∈ ⋃ k = 1 K R k . (2) M(i, j) = \mathbf{1}{(i, j) \in \bigcup{k=1}^K R_k}. \tag{2} M(i,j)=1(i,j)∈⋃k=1KRk.(2)
该掩码提供了参考帧中每个主体的精确空间先验,引导模型在主体层面保持一致性。为进一步增强鲁棒性,我们在训练过程中随机打乱主体位置,以减轻潜在的空间偏差。
逐像素通道级拼接 要实现连贯且身份一致的任意参考视频生成,需要对每个主体提供精确的身份相关线索。以往方法要么在时间维度上注入 VAE 表示 21,要么在 token 维度拼接视觉 token 65。然而,这些方法要求模型从零开始学习身份一致性,特别是在参考数量变化较大时,需要大量跨领域数据,导致泛化性能不足。
在 MAGREF 中,我们不沿 token 维度拼接参考,也不完全依赖自注意力,而是提出一种基于区域感知掩码的逐像素通道拼接机制,以保留主体特定外观特征,并确保身份一致性。
具体来说, I comp ∈ R 1 × C in × H × W I_{\text{comp}} \in \mathbb{R}^{1 \times C_{\text{in}} \times H \times W} Icomp∈R1×Cin×H×W 首先在时间维度上用零填充以匹配视频帧的维度,从而得到 I ~ comp ∈ R T × C in × H × W \tilde{I}{\text{comp}} \in \mathbb{R}^{T \times C{\text{in}} \times H \times W} I~comp∈RT×Cin×H×W。然后通过 VAE 编码器 E ( ⋅ ) E(\cdot) E(⋅) 获得潜特征图:
F comp = E ( I ~ comp ) ∈ R T × C × H × W , (3) F_{\text{comp}} = E(\tilde{I}_{\text{comp}}) \in \mathbb{R}^{T \times C \times H \times W}, \tag{3} Fcomp=E(I~comp)∈RT×C×H×W,(3)
其中 T , C , H , W T, C, H, W T,C,H,W 分别表示帧数、通道数、高度和宽度。同时,二值掩码 M M M 被下采样至与 F comp F_{\text{comp}} Fcomp 的空间分辨率一致,并沿通道维度复制,得到 M region ∈ R T × C m × H × W M_{\text{region}} \in \mathbb{R}^{T \times C_m \times H \times W} Mregion∈RT×Cm×H×W。这确保参考图像表示在时间上与视频帧对齐,便于在整个视频序列中无缝融合参考特征。
原始视频帧随后通过相同的 VAE 编码器 E ( ⋅ ) E(\cdot) E(⋅) 处理并加入高斯噪声,得到潜变量 Z ∈ R T × C × H × W Z \in \mathbb{R}^{T \times C \times H \times W} Z∈RT×C×H×W。
我们将带噪声的视频潜变量 Z Z Z、参考图像表示 F comp F_{\text{comp}} Fcomp 和特征掩码 M region M_{\text{region}} Mregion 沿通道维度拼接,构建最终输入 F input F_{\text{input}} Finput:
F input = Concat ( Z , F comp , M region ) ∈ R T × ( 2 C + C m ) × H × W , (4) F_{\text{input}} = \text{Concat}(Z, F_{\text{comp}}, M_{\text{region}}) \in \mathbb{R}^{T \times (2C + C_m) \times H \times W}, \tag{4} Finput=Concat(Z,Fcomp,Mregion)∈RT×(2C+Cm)×H×W,(4)
其中 Concat 表示通道级拼接。最终得到的复合输入 F input F_{\text{input}} Finput 会被送入后续模块,使模型能够实现连贯且身份一致的任意参考视频生成。
3.2 Subject Disentanglement
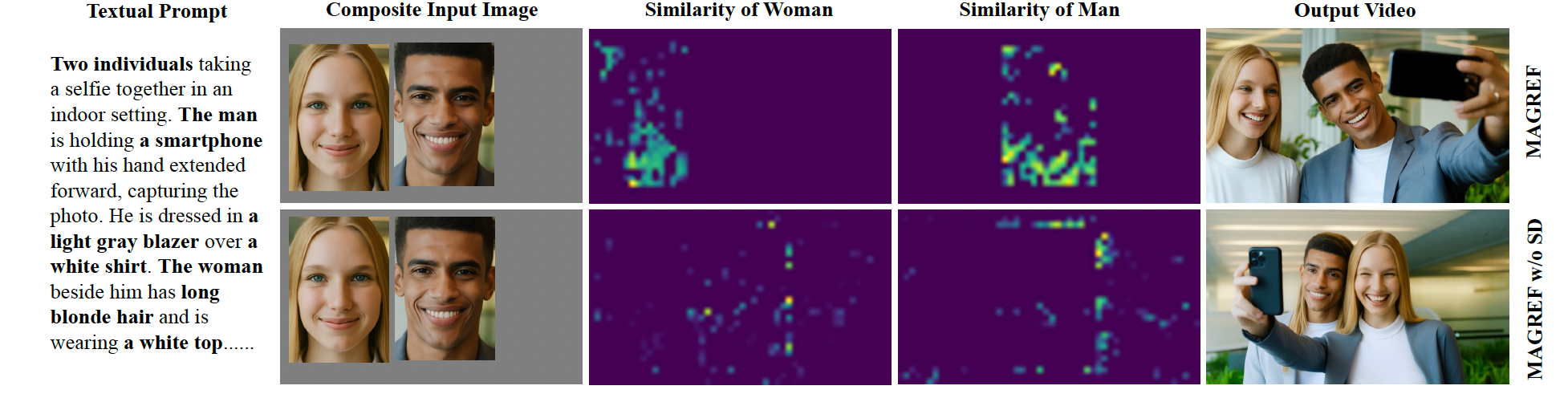
图 4:复合参考输入图像与文本标签之间的余弦相似度可视化。MAGREF 在多主体复合图像中能够更准确地将"男人(Man)"和"女人(Woman)"与对应的文本提示对齐。相比之下,移除主体解耦(SD)后,会导致主体之间的关联变得纠缠且模糊不清。
尽管掩码引导为每个主体提供了显式的特征区域,并使视觉分离更加清晰,但要使多个主体与其对应的文本描述准确对齐仍然具有高度挑战性。与单主体身份保持不同,多主体生成需要参考图像与文本条件之间更强的耦合;否则容易在主体间产生干扰与纠缠。为解决这一问题,我们扩展了区域感知掩码机制,通过将每个参考主体显式地与其对应的文本信息关联起来。
具体来说,主体解耦(Subject Disentanglement)首先解析文本条件,提取与参考主体对应的一组词标签,记为 { w i } i = 1 K \{w_i\}{i=1}^K {wi}i=1K。对于每个词语,我们从交叉注意力层提取对应的数值嵌入 V = { v i } i = 1 K V=\{v_i\}{i=1}^K V={vi}i=1K,其中 v i ∈ R D v_i \in \mathbb{R}^D vi∈RD。为在视觉域中空间地锚定这些语义概念,我们为每个主体构建掩码 M sub = { M sub k } k = 1 K M_{\text{sub}}=\{M^k_{\text{sub}}\}{k=1}^K Msub={Msubk}k=1K,以引导将参考图像的语义嵌入注入到其指定区域中。主体掩码 M sub k M^k{\text{sub}} Msubk 定义为:
M sub k ( i , j ) = 1 ( i , j ) ∈ R k , k = 1 , ... , K . (5) M^k_{\text{sub}}(i,j)=\mathbf{1}_{(i,j)\in R_k},\quad k=1,\ldots,K. \tag{5} Msubk(i,j)=1(i,j)∈Rk,k=1,...,K.(5)
然后,主体特定信息被直接注入到首帧的潜变量表示 z 0 ∈ R 1 × C × H × W z_0 \in \mathbb{R}^{1\times C\times H\times W} z0∈R1×C×H×W 的每一层中,并按如下方式更新:
z 0 ′ = z 0 + α ∑ i = 1 K ( M sub k ⊙ v i ) , (6) z'0 = z_0 + \alpha \sum{i=1}^{K} \left( M^k_{\text{sub}} \odot v_i \right), \tag{6} z0′=z0+αi=1∑K(Msubk⊙vi),(6)
其中 ⊙ \odot ⊙ 表示逐元素 Hadamard 积,并通过广播机制对齐张量形状。该定向注入操作在扩散过程的一开始就建立了指定图像区域与对应文本 token 之间的紧密对齐。因此,它有效缓解了属性泄露问题,并防止在视频生成过程中不同主体之间产生干扰(见图 4)。
3.3 Four-Stage Data Curation
我们设计了一条系统化的数据整理管线,用于处理训练视频、生成文本标签,并提取人脸、物体与背景等参考实体,以适配任意参考视频生成任务。如图 5 所示,该管线由四个阶段组成,这些阶段逐步对数据进行过滤、标注与参考构建,以用于后续的模型训练。
在阶段 1 中,使用场景切换检测对原始视频进行分段,质量较低或运动幅度极小的片段将被丢弃。剩余片段使用 Qwen2.5-VL 1 进行字幕生成,重点关注运动相关内容。
在阶段 2 中,从字幕中识别物体,并使用 GroundingDINO 30 进行定位,再利用 SAM2 36 将其分割成干净的参考图像。
阶段 3 通过 InsightFace 进行人脸检测,对检测到的人脸进行身份分配、基于姿态过滤,并按质量排序。从中挑选固定数量的高质量人脸以构成参考集合。
阶段 4 利用最先进的图像生成模型生成人脸与物体参考的增强版本,引入在姿态、外观和上下文方面的变化。背景图像也会进行增强,以丰富参考集合。
经过全部四个阶段后,最终训练样本形式化定义为:
R i = { V i , C i , ( I i Face , I i Face ′ ) , ( I i , 1 Obj , I i , 1 Obj ′ ) , ... , ( I i , k Obj , I i , k Obj ′ ) , I i Bg } , (7) \mathcal{R}i = \{V_i,\; C_i,\; (I_i^{\text{Face}}, I_i^{\text{Face}'}),\; (I{i,1}^{\text{Obj}}, I_{i,1}^{\text{Obj}'}),\; \ldots,\; (I_{i,k}^{\text{Obj}}, I_{i,k}^{\text{Obj}'}),\; I_i^{\text{Bg}}\}, \tag{7} Ri={Vi,Ci,(IiFace,IiFace′),(Ii,1Obj,Ii,1Obj′),...,(Ii,kObj,Ii,kObj′),IiBg},(7)
其中, V i V_i Vi 表示视频片段, C i C_i Ci 是文本描述, ( I i Face , I i Face ′ ) (I_i^{\text{Face}}, I_i^{\text{Face}'}) (IiFace,IiFace′) 分别为原始与变换后的人脸参考对, ( I i , j Obj , I i , j Obj ′ ) (I_{i,j}^{\text{Obj}}, I_{i,j}^{\text{Obj}'}) (Ii,jObj,Ii,jObj′) 表示物体的变体参考对, I i Bg I_i^{\text{Bg}} IiBg 表示背景参考。关于该管线的更多细节见附录 B。
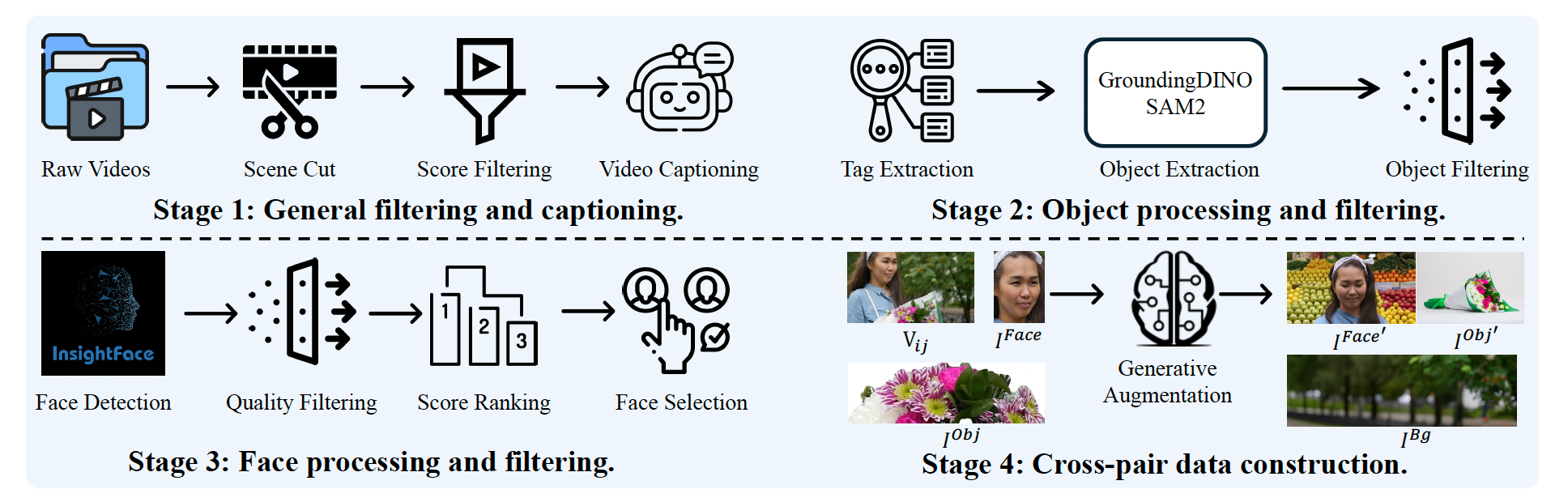
图 5:用于收集高质量训练样本的系统化四阶段数据管线。