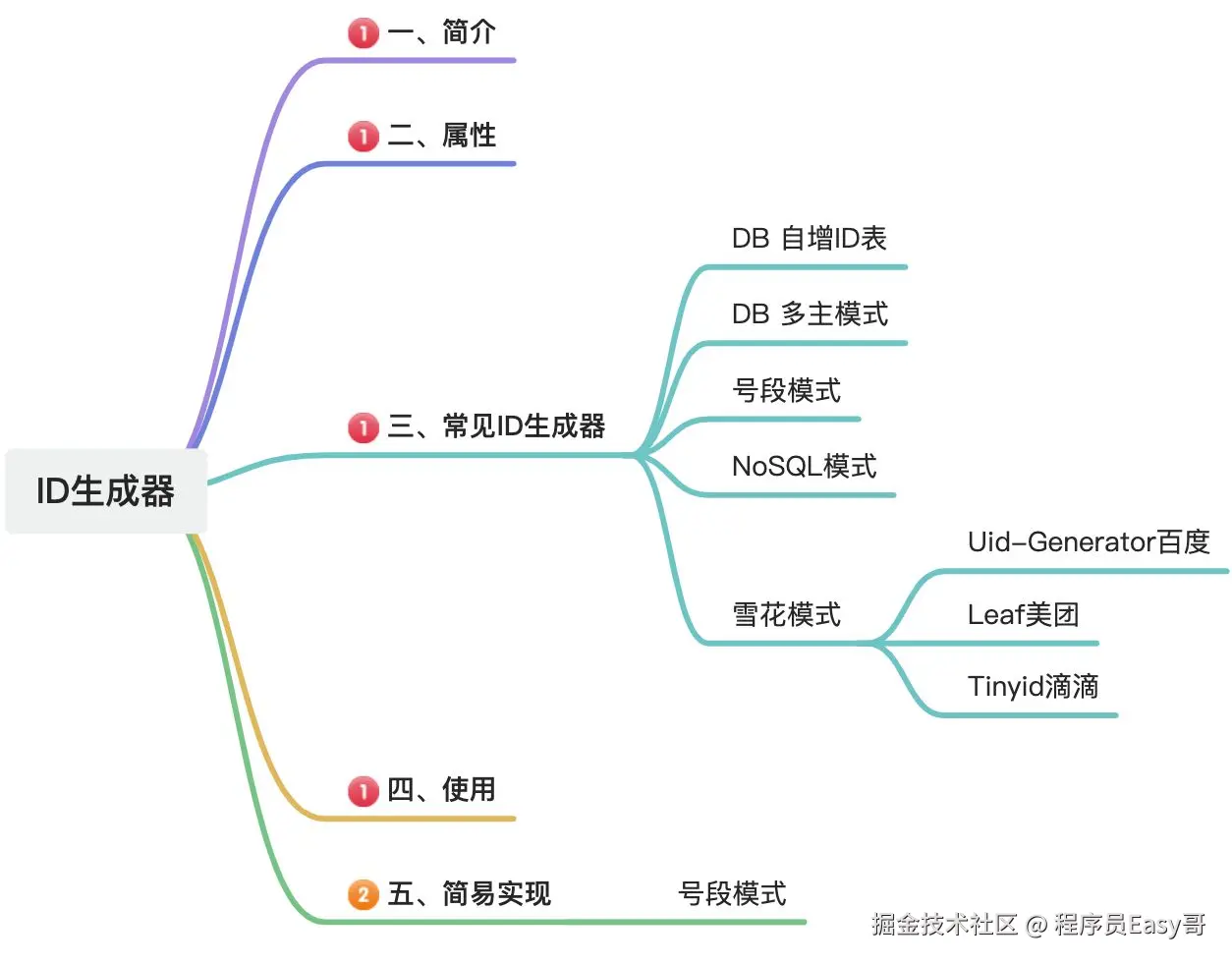
一、介绍
ID 是标识符(identifier)的前缀,它代表一个可以唯一识别一个对象或者物体的名称。在软件系统中,ID 用于对一组信息进行标识,它是信息系统里最底层、最基础的概念,从系统诞生到消亡,都与 ID 息息相关。
在分布式系统中,ID生成器是至关重要的,因为分布式系统中,一个数据表可能存储在多个物理机上,这样主键Id如何生成,怎么保证其有序性,生成可靠性,生成稳定性等都是一个问题。
作为一个Java后端架构师,我们需要知道 ID生成器的原理和常见的ID生成器都有哪些,以及如何自己实现一个简易的Id生成器,加深对分布式系统的理解。
二、属性
用5 个属性来分析
- 自身属性: 类型、长度
- 领域属性: 唯一性、稀疏度、递增性
三、各种Id生成
1、db自增ID表
介绍: 自增ID表其实就是给db中写一张id表,利用数据库主键id自增思想来生成id.
java
create table `id_gen`
(
`id` bigint(20) not null auto_increment,
primary key(`id`)
) engine=InnoDB DEFAULT CHATSET = utf8mb4;优点 : 实现简单,成本不高,自增连续性好,Id严格从1增长
缺点:
css
- 单表<font style="color:#DF2A3F;">过热</font>,<font style="color:#DF2A3F;">qps存在瓶颈</font>。
- <font style="color:#DF2A3F;">安全问题</font>(根据订单ID递增规则推送出每天的数据量等等)
- 每获取一次Id都需要访问一次数据库,单个db的<font style="color:#DF2A3F;">连接数</font>是瓶颈.2、db多主模式
介绍: 多个表同时提供ID服务,一个表从1开始步长为2,一个表从2开始步长2。
生产id: 1, 3, 5. 2, 4, 6.
如果需要新增一个db实例,就需要重新调整.
比较繁琐.
set @@auto_increment_offset = 2; --- 起始值
set @@auto_increment_increment= 2; --- 步长
优点 : 分散db压力
缺点: 扩展性和复杂度提高, 其实并没有实现分布式
3、号段模式
介绍:
数据库每次递增一条肯定是不行的,所以能否一次请求,生成一段Id, 放在内存中,下次直接访问内存即可, 这样减轻db请求次数. 这就是我们所说的基于数据库号段生成分布式Id。
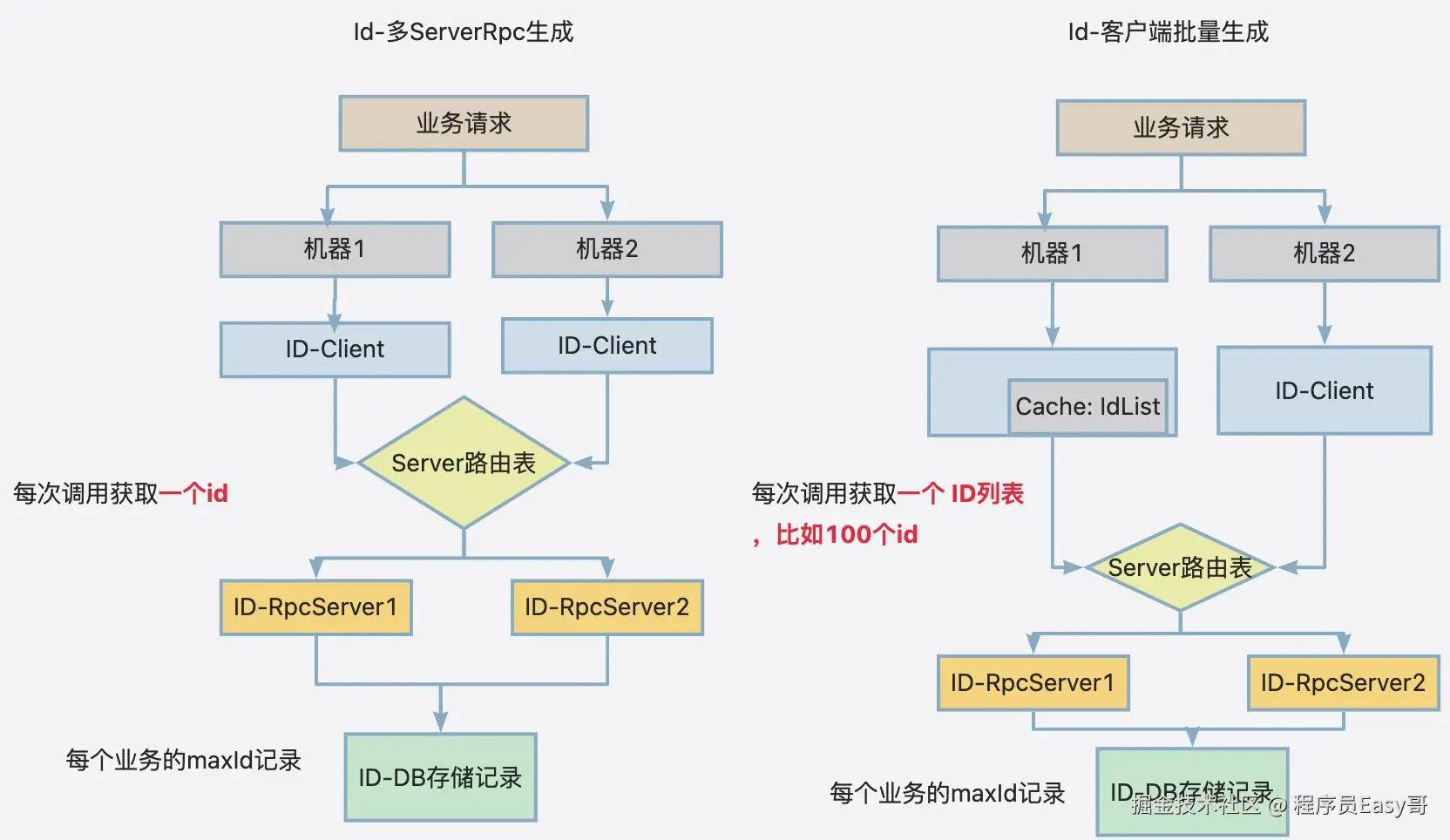
具体实现:
- Idserver 多个rpc生成: 瓶颈在于id server 数量
- 客户端批量生成: 瓶颈在于DB,多个实例同时请求同一个业务的更新权限时,其实就是会抢行锁.
- 如果是认为单表过热的话,也就是多个业务,其实可以横向扩充shard即可. biz_id % shard 去操作.
idserver我们就不用多说了,其实就是单个单个server组成集群,每个server提供id生成服务.
我们下面来看一下客户端批量生成单表.
java
create table `id_generator` (
`id` bigint(20) not null,
`max_id` bigint(20) not null comment '最大id',
`step` int(10) not null comment '号段长度',
`version` int(20) not null comment '版本',
`biz_type` int(20) not null comment '业务类型',
primary key(`id`)
) engine = InnoDB default charset=utf8mb4;select + update 重试
java
update ml_id_gen set version=version + 1, max_id =newMaxId where biz_id=:bizId and version = version
如果updateCount == 0, 重复select, update直到修改成功
注意: newMaxId = oldMaxId + step
// 那就得先获取版本, 再更新.
select version from ml_id_gen where biz_id = :bizId
在获取层client, 内部就可以封装一个loadingCache<bizId, Tuple<Long, Long>>
Tuple中是 curId, curRegionMaxId
case:
1. bizId 无, 去找db 生成
2. bizId 有
2.1 curId = curRegionMaxId
找server分配, 更新cache
重新拿到curId, curId++更新cache.
return 重新拿到curId;
2.2 curId < curRegionMaxId
long oldId = curId++;
更新cache(curId, curRegionMaxId)
return oldId;优点: ID 趋势增长、存储消耗空间少
缺点 : 单表存在热点问题,Id 没有意义,安全问题(步长很容易被猜出来)
4、NoSQL自增
介绍:
采用incr自增获取.
**优点: **性能非常好,并且Id有序增长。
缺点:
markdown
- **存在单点. 当然有集群.**
- **RDB**: 每隔一段时间快照,但是如果连续incr,redis挂了,会造成id重复.
- **AOF**: 不会重复,但是incr命令过多,导致重启恢复数据时间过长.5、雪花算法及其多个实现
**介绍: **
雪花算法: snowflow是twitter开源的分布式Id生成算法.
long 我们都知道8个字节==64bit.
diff
- 第一位标识: 0: 正数 1: 负数
- 41位: 时间戳部分ms, 一般是当前时间 - 固定的开始时间,这样产生的ID可以从更小值开始. 而且41位可以用 (1L << 41 / (1000 * 3600 * 24 * 365)) = 69年.
- 10位: 工作机器id,5位为机房信息,5位为机房中的机器号 workerId, 这样可以部署1024个节点.
- 12位: 序列号部分, 支持统一ms内同一个节点可以生成4096个ID.优点: 生成速度快、生成的ID有序递增、比较灵活(可以改造)
缺点: 需要解决重复ID问题 (比较依赖服务器时间,在机器时间不对的情况下, 可能会造成重复ID)
后面百度uid-generator, 美团leaf,滴滴Tinyid等都是修改 这个几个的位数和 具体workerId怎样生成的。
Uid-Generator(百度):
uid-generator 基于Java、snawflake实现的唯一Id生成器。
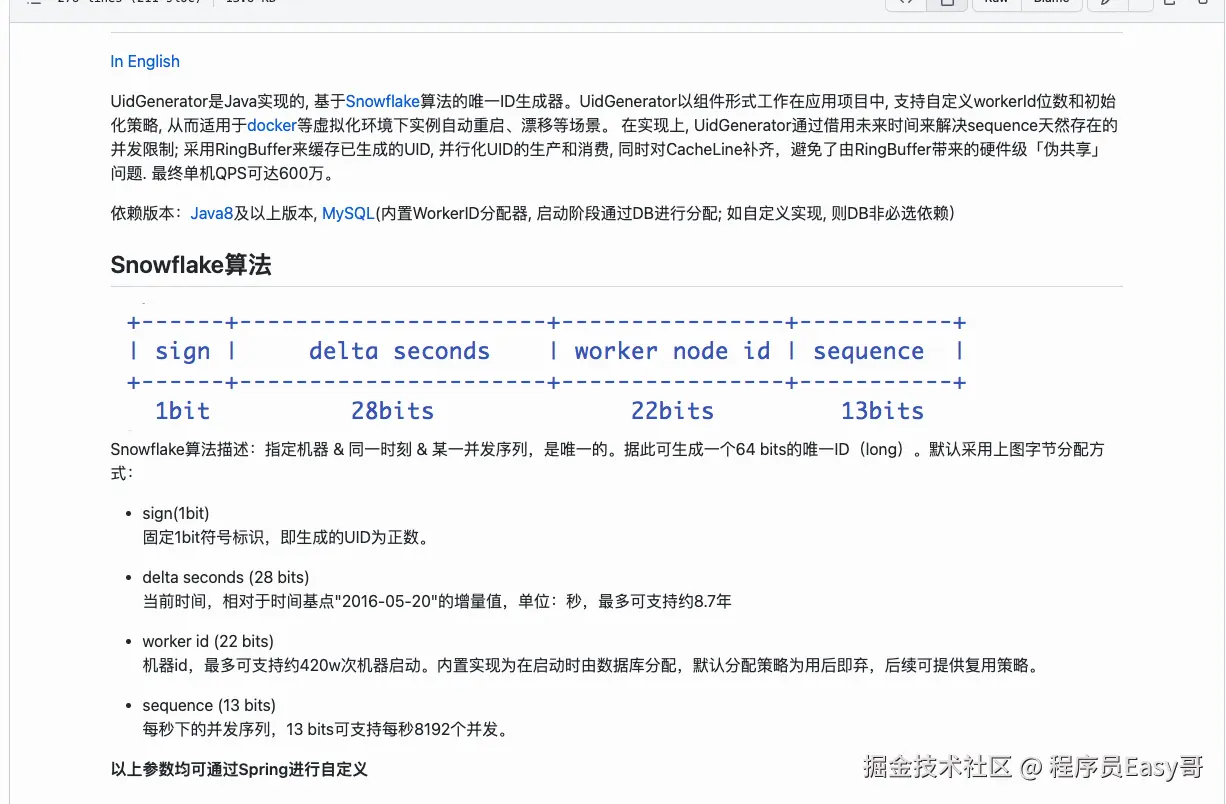
看起来已经不在维护了.
Leaf(美团):
Leaf 最早期需求是各个业务线的订单ID生成需求。\ 看起来以前他们是db自增,redis自增来生成ID,后面他们统一了。\ 这其实得深入了解美团的技术组成,如果内部有两个相同的业务,就会整合成一个,这一点非常好.
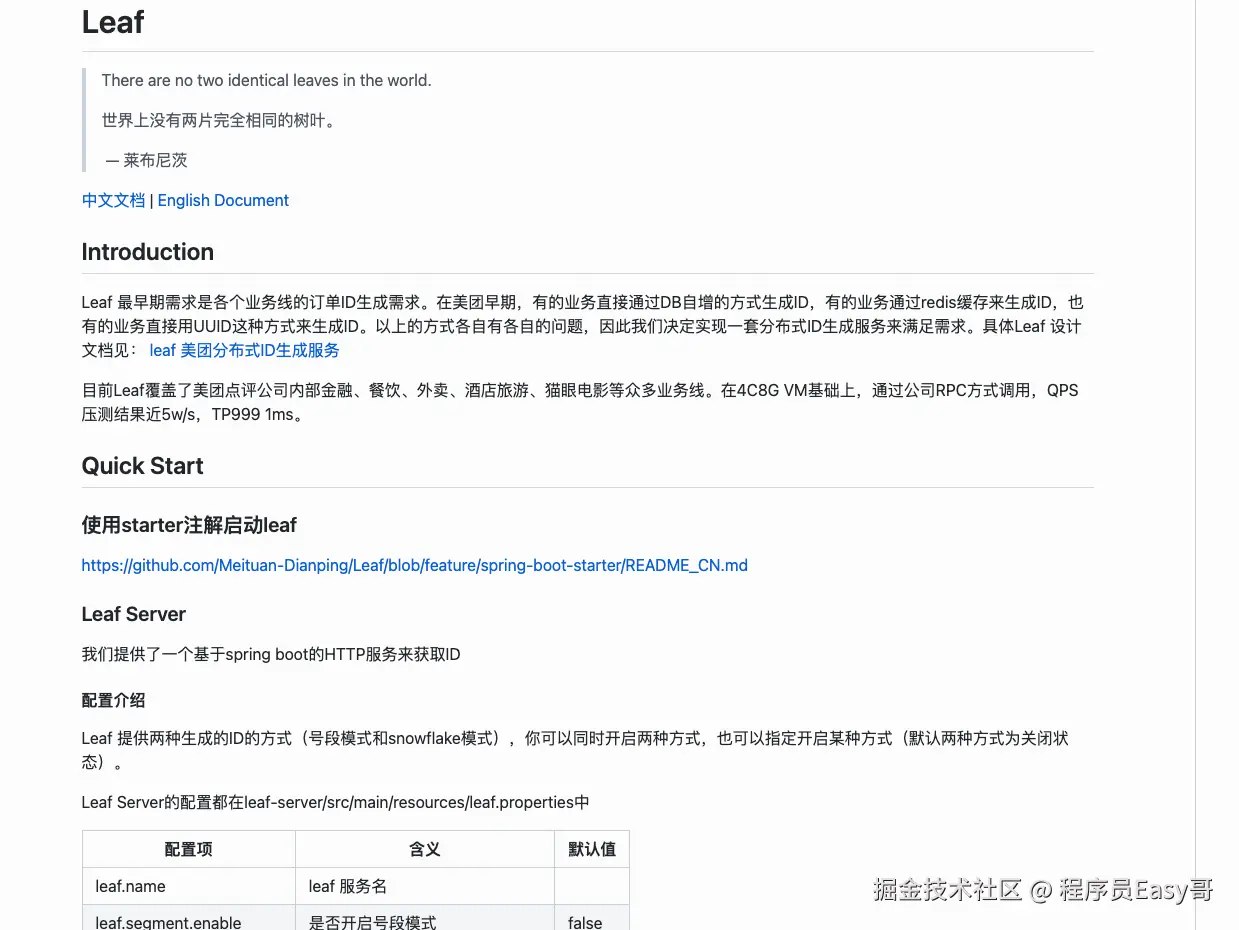
世界上没有两片完全相同的树叶,人也是一样.
Leaf 提供了 号段模式 和 snowflow(雪花算法) 这两种模式来生成分布式ID。
支持双号段,解决了雪花ID 系统时钟回拨问题。但是时钟问题的解决依赖于Zk。
雪花的号段位分布. Leaf------美团点评分布式ID生成系统
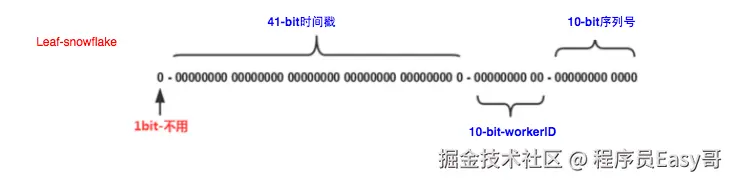
主要是workerId生成不同,leaf中workId 是基于zk的顺序id来生成的,每个应用在使用Leaf-snowFlake时,在启动时都会在zk中生成一个顺序id,相当于一个机器对应一个顺序节点,也就是一个workId。
Tinyid(滴滴):
Tinyid(opens new window)是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
相关文档: Tinyid原理介绍

到此一个简单的id生成系统就完成了,那么是否还存在问题呢?回想一下我们最开始的id生成系统要求,高性能、高可用、简单易用,在上面这套架构里,至少还存在以下问题:
- 当id用完时需要访问db加载新的号段,db更新也可能存在version冲突,此时id生成耗时明显增加
- db是一个单点,虽然db可以建设主从等高可用架构,但始终是一个单点
- 使用http方式获取一个id,存在网络开销,性能和可用性都不太好
所以后面加了下面这几个来优化.
- 双号段缓存:
- 为了避免在获取新号段的情况下,获取唯一ID的速度比较慢。Tinyid中的号段在加载到一定的程度(比如一半),就去异步加载下一个号段,保证内存中永远始终有可用的号段。
- 增加多db支持 其实就是生成奇数,偶数这种.
- 支持多个DB,并且,每个DB都能生成唯一ID,提高可用性。
- 增加tinyid-client。
- 纯纯本地操作,无http请求损耗。
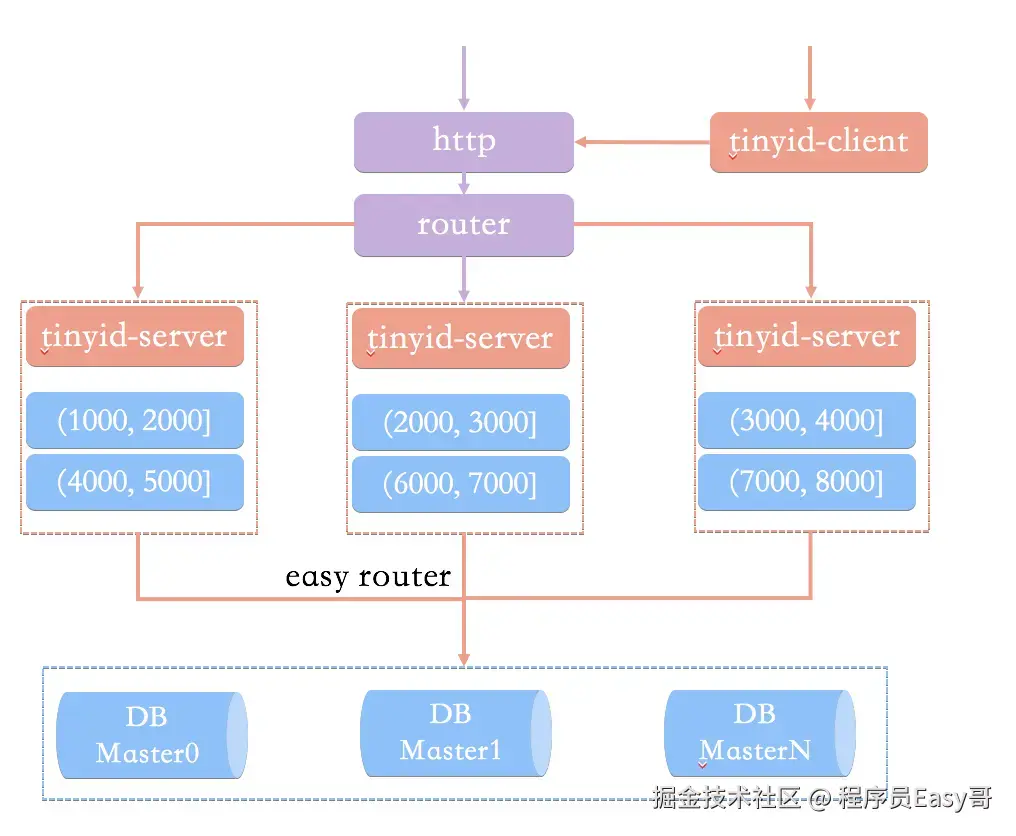
优缺点: 上面也说了很多,但是要注意数据库号段的缺点。
6、UUID
介绍:
UUID 是 Universally unique identifier (通用唯一标识符) 的 缩写。UUID 包含32个16进入数字 (8-4-4-4-12) 。
JDK 中就用现成的。
java
final UUID uuid = UUID.randomUUID();
System.out.println(uuid);
System.out.println(uuid.version());
4c994944-82e1-4be4-a543-ab182d87b11d
4RFC 4122(opens new window)中关于 UUID 的示例是这样的:

其实需要关注版本即可,不同的版本对应的UUID 的生成规则是不同的。
5 种不同的 Version(版本)值分别对应的含义(参考维基百科对于 UUID 的介绍(opens new window)):
- 版本 1 : UUID 是根据时间和节点 ID(通常是 MAC 地址)生成;
- 版本 2 : UUID 是根据标识符(通常是组或用户 ID)、时间和节点 ID 生成;
- 版本 3、版本 5 : 版本 5 - 确定性 UUID 通过散列(hashing)名字空间(namespace)标识符和名称生成;
- 版本 4 : UUID 使用随机性(opens new window)或伪随机性(opens new window)生成。
下面是 Version 1 版本下生成的 UUID 的示例:

JDK 中通过 UUID 的 randomUUID() 方法生成的 UUID 的版本默认为 4。
我们看UUID的生成包含: MAC地址、时间戳、命名空间、随机或伪随机数、时序等元素,当然极少概率会出现重复.
优点: 生成速度比较快、简单
缺点: 存储消耗空间大(36字符,128位)、 不安全(基于MAC地址生成会造成MAC地址泄漏)、无序、没有具体的业务含义、需要解决重复ID问题 (当机器时间不对的时候, linux 的ntp时间会有问题, 可能会导致重复Id)
说明:
- 其中1.2.3.4 数据自增思想.
- 5属于snowFlake思想,各个bit位数不一样,workerId生成不一样.
四、使用
其实在大厂里都有自己的id生成器,一般都是雪花算法的变种,当然也提供类似号段模式,id-server严格递增等等。
还是需要根据业务诉求、背景去找到符合自己背景的id生成器