最近想给我的博客的网页换个字体,在修复了历史遗留的一些bug之后,去google fonts上找了自己喜欢的字体,本地测试和自己的设备发现没问题后,便以为OK了。
但是当我接朋友的设备打开时,发现网页依然是默认字体。这时候我才发现,我的设备能够翻墙,所以能够使用Google CDN服务,但是对于我的其他读者们,在大陆内是访问不了Google的,便也无法渲染字体了。
于是为了解决这个问题,我尝试了各种办法比如格式压缩,子集化(Subset),分包等等,最后考虑到本站的实际情况选用了一种比较邪门 的方法,让字体压缩率达到了惊人的98.5%!于是,这篇文章就是对这个过程的总结。也希望这篇文章能够帮助到你。😊
想要自定义网站的字体,最重要的其实就是字体包的获取。大体上可以分为两种办法:在线获取 和网站本地部署。
在线获取──利用 CDN 加速服务
CDN(Content Delivery Network) 意为内容配送网络。你可以简单理解为是一种"就近给你东西"的互联网加速服务。
传统不使用 CDN 服务的是这样的: User ←→ Server,如果相聚遥远,效果显然很差。
使用了 CDN 服务是这样的: User ←→ CDN Nodes ←→ Server,CDN 会提前把你的网站静态资源缓存到各个节点,但你需要时可以直接从最近的节点获取。
全球有多家CDN服务提供商,Google Fonts使用的CDN服务速度很快。所以如果在网络畅通的情况下,使用Google Fonts API是最简单省事的!
你可以直接在文件中导入Google fonts API:
css
@import url('https://fonts.googleapis.com/css2?family=Inter:ital,opsz,wght@0,14..32,100..900;1,14..32,100..900&family=Merriweather:ital,opsz,wght@0,18..144,733;1,18..144,733&family=Noto+Serif+SC:wght@500&display=swap');这样网站它便会自动向最近的Google CDN节点请求资源。
当然,这些都是建立在网络状态畅通无阻的情况下。大陆用户一般使用不了Google服务,但并不意味着无法使用CDN服务。国内的腾讯云,阿里云同样提供高效的服务,但具体的规则我并不了解,请自行阅读研究。
本地部署
既然用不了在线的,那就只能将字体包文件一并上传到服务器上了。
这种做法不需要依赖外部服务,但缺点是字体包的文件往往很大,从进入网站到彻底加载完成的时间会及其漫长!而且这种问题尤其在中日韩(CJK)字体上体现的十分明显。
以本站为例,我主要采用了三种字体:Merriweather, Inter, Noto Serif SC. 其中每种字体都包含了Bold和Regular两种格式。前面两种都属于西文字体,每种格式原始文件大小都在200kb-300kb,但是到了思源宋体这里,仅仅一种格式的字体包大小就达到了足足14M多 。如果全部加载完,恐怕从进入网站到完全渲染成功,需要耽误个2分钟。所以将原始字体包文件上传是极不可取的做法!
为了解决这个问题,我在网上查阅资料,找到了三种做法。
字体格式转换(WOFF2)
WOFF2 (Web Open Font Format 2.0) 是一种专为 Web 设计的字体文件格式,旨在提供更高的压缩率和更快的加载速度,也是是目前在 Web 上部署自定义字体的推荐标准。它本质上是一种将 TTF 或 OTF 字体数据进行高度压缩后的格式,目前已经获得了所有主流浏览器的广泛支持。
我们可以找一个在线的字体格式转化网站来实现格式的转化。本文我们以NotoSerifSC-Bold.ttf为例,转换后的NotoSerifSC-Bold.woff2文件只有5.8M左右,压缩率达到了60%!
但是,这仍旧是不够的,仅两个中文字体包加起来也已经快12M,还没有算上其他字体。这对于一个网页来说依然是灾难性的。我们必须寻找另一种方法。
子集化处理(Subset)
中国人都知道,虽然中文的字符加起来有2万多个,但是我们平常交流基本只会用到3000多个,范围再大一点,6000多个字符已经可以覆盖99%的使用场景。这意味着:
我们根本不需要保留所有字符,而只需要保留常用的几千个汉字即可。
于是这就给了我们解决问题的思路了。
首先我们可以去寻找中文常用汉字字符表,这里我获取的资源是 All-Chinese-Character-Set。我们将文件下载解压后,可以在里面找到各种各样按照字频统计的官方文件。这里我们就以《通用规范汉字表》(2013年)一级字和二级字为例。我们创建一个文档char_set.txt并将一级字和二级字的内容全部复制进去。这份文档就是我们子集化的对照表。
接着我们需要下载一个字体子集化工具,这里使用的是Python中的fonttools库,它提供了许多工具(比如我们需要的pyftsubset)可以在命令行中执行子集化、字体转化字体操作。
我们安装一下这个库和对应的依赖(在这之前确保你的电脑上安装了Python和pip,后者一般官方安装会自带)
bash
pip install fonttools brotli zopfli然后找到我们字体包对应的文件夹,将原来的char_set.txt复制到该文件夹内,在该文件下打开终端,然后以NotoSerifSC-Bold.ttf为例,输入以下命令:
bash
pyftsubset NotoSerifSC-Bold.ttf --output-file=NotoSerifSC-Bold.subset.woff2 --flavor=woff2 --text-file=char_set.txt --no-hinting --with-zopfli过一会就能看到会输出一个NotoSerifSC-Bold.subset.woff2的文件。
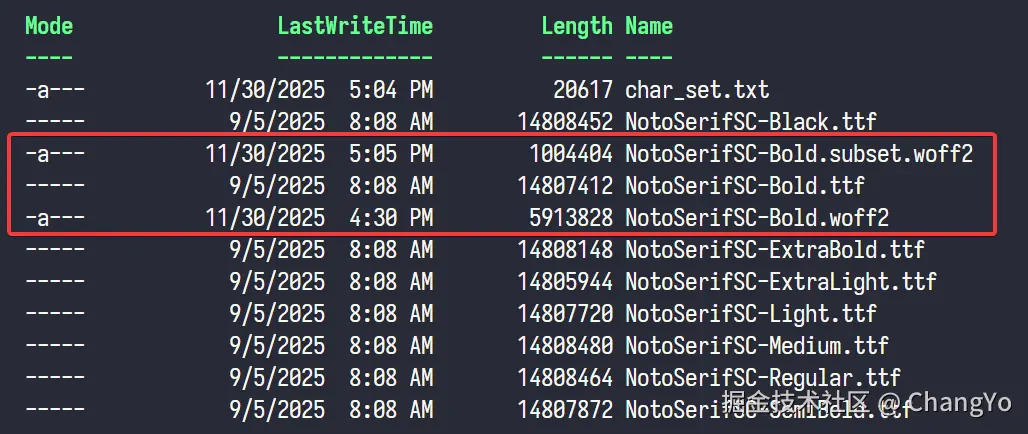 我们欣喜的发现这个文件的大小竟然只有980KB 。至此,我们已经已经将压缩率达到了93%!到这一步,其实直接部署也并没有十分大问题,不过从加载进去到完全渲染,可能依然需要近十秒左右,我们依然还有优化空间。
我们欣喜的发现这个文件的大小竟然只有980KB 。至此,我们已经已经将压缩率达到了93%!到这一步,其实直接部署也并没有十分大问题,不过从加载进去到完全渲染,可能依然需要近十秒左右,我们依然还有优化空间。
分包处理实现动态加载
这个方法是我阅读这篇文章了解到的,但是遗憾的是我并没有在自己的网站上实现,不过失败的尝试也让我去寻找其它的方法,最终找到适用本站的一种极限字体渲染的方法,比这三种的效果还要好。下面我依然简单介绍一下这个方法的原理,想更了解可以通过看到最后通过参考资料去进一步了解。
在2017年,Google Fonts团队提出切片字体,因为他们发现:绝大部分网站只需要加载CJK字体包的小部分内容即可覆盖大部分场景。基于适用频率统计,他们将字符分成多个切片,再按 Unicode 编码对剩余字符进行分类。
怎么理解呢?他其实就是把所有的字符分成许多个小集合,每个集合里面都包含一定数量的字符,在靠前的一些集合中,都是我们常用的汉字,越到后,字形越复杂,使用频率也越低。当网页需要加载字体文件时,它是以切片为单位加载的。这意味,只有当你需要用到某个片区的字符时,这个片区才会被加载。
这种方式的好处时,能够大大加快网站加载速率。我们不用每次都一次性把全部字符加载,而是按需加载。这项技术如今已经被Noto Sans字体全面采用。
但是我们需要本地部署的话,需要多费一点功夫。这里我们利用中文网字计划的在线分包网站来实现。
我们将需要的字体上传进行分包,可以观察到输出结果是一系列以哈希值命名的woff2文件。分包其实就是做切分,把每个切分后的区域都转化为一份体积极小的woff2文件。
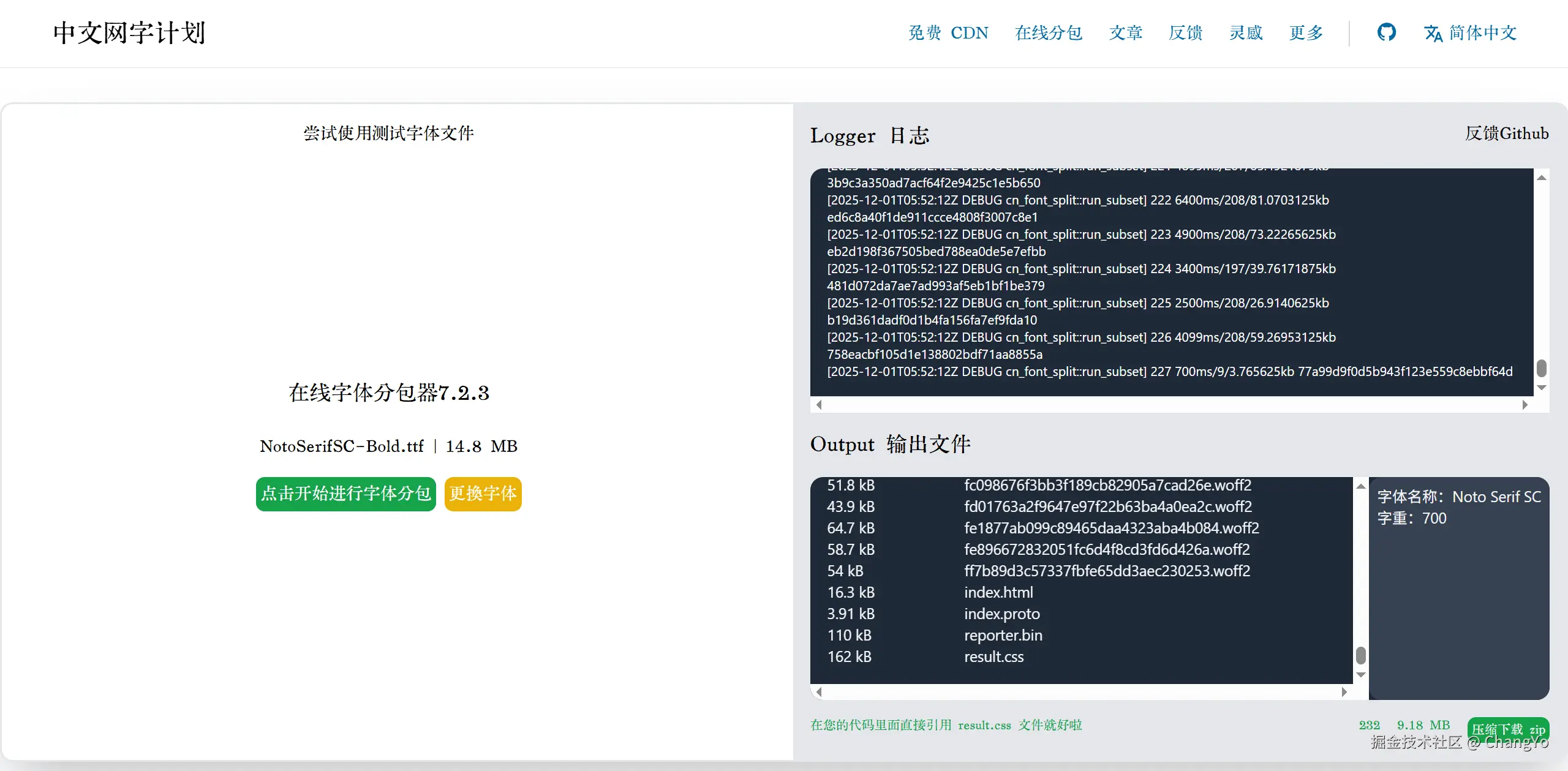 下载压缩包,然后可以将里面的文件夹导入你的项目,并引用文件夹下的
下载压缩包,然后可以将里面的文件夹导入你的项目,并引用文件夹下的result.css即可。理论上,当网站需要加载渲染某个字体时,它会根据css里面的规则去寻找到对应的分包再下载。每个包的体积极小,网站加载的速度应该提升的很明显。
我的实践──将字符压缩到极限
我的方法可以理解为子集化的一种,只不过我的做法更加的极端一些──只保留文章出现的字符!
根据统计结果,截止到这篇post发布,我的文章总共出现的所有字符数不到1200个(数据来源见下文),所以我们可以做的更激进一些,只需将文章出现的中文字符全部记录下来,制成一张专属于自己网站的字符表,然后在每次发布文章时动态更新,这样我们能够保证字体完整渲染,并且处于边界极限状态!
实现这个个性化字符表char_set.txt的核心是一个提取文章中文字符的算法。这部分我是通过Gemini生成了一个update_lists.cpp文件,他能够识别_posts/下面所有文章,并输出到根目录的char_set.txt中,你可以根据代码内容进行自定义的修改:
cpp
/**
* @file update_lists.cpp
* @brief Scans Markdown files in /_posts/ and updates char_set.txt in root.
* @author Gemini
* @date 2025-11-28
*/
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <unordered_set>
#include <filesystem>
namespace fs = std::filesystem;
namespace char_collector {
const std::string kRegistryFilename = "char_set.txt";
const std::string kMarkdownExt = ".md";
const uint32_t kCJKStart = 0x4E00;
const uint32_t kCJKEnd = 0x9FFF;
bool NextUtf8Char(std::string::const_iterator& it,
const std::string::const_iterator& end,
uint32_t& out_codepoint,
std::string& out_bytes) {
if (it == end) return false;
unsigned char c1 = static_cast<unsigned char>(*it);
out_bytes.clear();
out_bytes += c1;
if (c1 < 0x80) { out_codepoint = c1; it++; return true; }
if ((c1 & 0xE0) == 0xC0) {
if (std::distance(it, end) < 2) return false;
unsigned char c2 = static_cast<unsigned char>(*(it + 1));
out_codepoint = ((c1 & 0x1F) << 6) | (c2 & 0x3F);
out_bytes += *(it + 1); it += 2; return true;
}
if ((c1 & 0xF0) == 0xE0) {
if (std::distance(it, end) < 3) return false;
unsigned char c2 = static_cast<unsigned char>(*(it + 1));
unsigned char c3 = static_cast<unsigned char>(*(it + 2));
out_codepoint = ((c1 & 0x0F) << 12) | ((c2 & 0x3F) << 6) | (c3 & 0x3F);
out_bytes += *(it + 1); out_bytes += *(it + 2); it += 3; return true;
}
if ((c1 & 0xF8) == 0xF0) {
if (std::distance(it, end) < 4) return false;
unsigned char c2 = static_cast<unsigned char>(*(it + 1));
unsigned char c3 = static_cast<unsigned char>(*(it + 2));
unsigned char c4 = static_cast<unsigned char>(*(it + 3));
out_codepoint = ((c1 & 0x07) << 18) | ((c2 & 0x3F) << 12) |
((c3 & 0x3F) << 6) | (c4 & 0x3F);
out_bytes += *(it + 1); out_bytes += *(it + 2); out_bytes += *(it + 3); it += 4; return true;
}
it++; return false;
}
bool IsChineseChar(uint32_t codepoint) {
return (codepoint >= kCJKStart && codepoint <= kCJKEnd);
}
class CharManager {
public:
CharManager() = default;
void LoadExistingChars(const std::string& filepath) {
std::ifstream infile(filepath);
if (!infile.is_open()) {
std::cout << "Info: " << filepath << " not found or empty. Starting fresh." << std::endl;
return;
}
std::string line;
while (std::getline(infile, line)) {
ProcessString(line, false);
}
std::cout << "Loaded " << existing_chars_.size()
<< " unique characters from " << filepath << "." << std::endl;
}
void ScanDirectory(const std::string& directory_path) {
if (!fs::exists(directory_path)) {
std::cerr << "Error: Directory '" << directory_path << "' does not exist." << std::endl;
return;
}
for (const auto& entry : fs::directory_iterator(directory_path)) {
if (entry.is_regular_file() &&
entry.path().extension() == kMarkdownExt) {
ProcessFile(entry.path().string());
}
}
}
void SaveNewChars(const std::string& filepath) {
if (new_chars_list_.empty()) {
std::cout << "No new Chinese characters found." << std::endl;
return;
}
std::ofstream outfile(filepath, std::ios::app);
if (!outfile.is_open()) {
std::cerr << "Error: Could not open " << filepath << " for writing." << std::endl;
return;
}
for (const auto& ch : new_chars_list_) {
outfile << ch;
}
std::cout << "Successfully added " << new_chars_list_.size()
<< " new characters to " << filepath << std::endl;
}
private:
std::unordered_set<std::string> existing_chars_;
std::vector<std::string> new_chars_list_;
void ProcessFile(const std::string& filepath) {
std::ifstream file(filepath);
if (!file.is_open()) return;
std::cout << "Scanning: " << fs::path(filepath).filename().string() << std::endl;
std::string content((std::istreambuf_iterator<char>(file)),
std::istreambuf_iterator<char>());
ProcessString(content, true);
}
void ProcessString(const std::string& content, bool track_new) {
auto it = content.begin();
auto end = content.end();
uint32_t codepoint;
std::string bytes;
while (NextUtf8Char(it, end, codepoint, bytes)) {
if (IsChineseChar(codepoint)) {
if (existing_chars_.find(bytes) == existing_chars_.end()) {
existing_chars_.insert(bytes);
if (track_new) {
new_chars_list_.push_back(bytes);
}
}
}
}
}
};
}
int main() {
char_collector::CharManager manager;
manager.LoadExistingChars(char_collector::kRegistryFilename);
manager.ScanDirectory("_posts");
manager.SaveNewChars(char_collector::kRegistryFilename);
return 0;
}然后我们在终端编译一下再运行即可:
bash
clang++ update_lists.cpp -o update_lists && ./update_lists然后我们就会发现这张独属于本站的字符表生成了!🥳 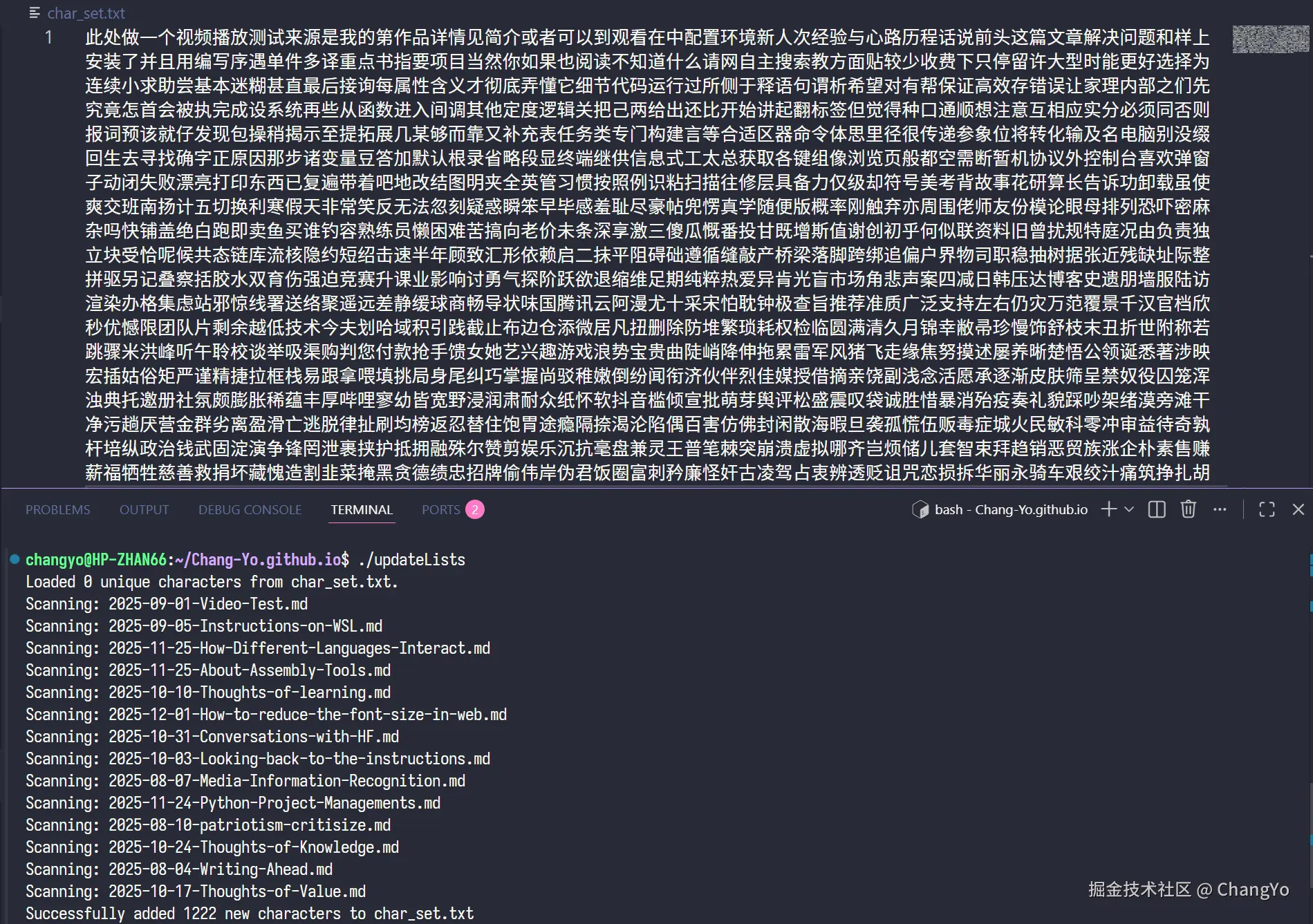 为了方便操作,我们把原始的ttf文件放入仓库的
为了方便操作,我们把原始的ttf文件放入仓库的/FontRepo/下(最后记得在.gitignore添加这个文件夹!),然后稍微修改一下之前子集化的命令就可以了:
bash
pyftsubset /FontRepo/NotoSerifSC-Bold.ttf --output-file=/assets/fonts/noto-serif-sc/NotoSerifSC-Bold.subset.woff2 --flavor=woff2 --text-file=char_set.txt --no-hinting --with-zopfli可以看到,最终输出的文件只有200K!压缩率达到了98.5%!
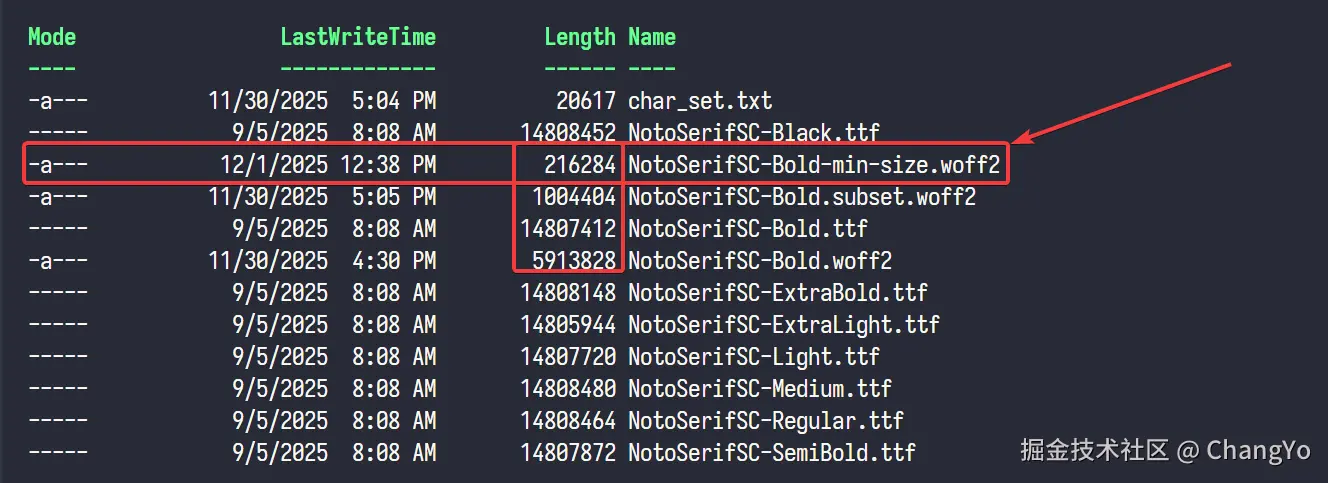 但是这个方法就像前面说的,处于字体渲染的边界。但凡多出一个字符表中的符号,那么这个字符就无法渲染,会回退到系统字体,看起来格外别扭。所以,在每次更新文章前,我们都需要运行一下
但是这个方法就像前面说的,处于字体渲染的边界。但凡多出一个字符表中的符号,那么这个字符就无法渲染,会回退到系统字体,看起来格外别扭。所以,在每次更新文章前,我们都需要运行一下./update_lists。此外,还存在一个问题,每次更新产生新的子集化文件时,都需要把旧的子集化文件删除,防止旧文件堆积。
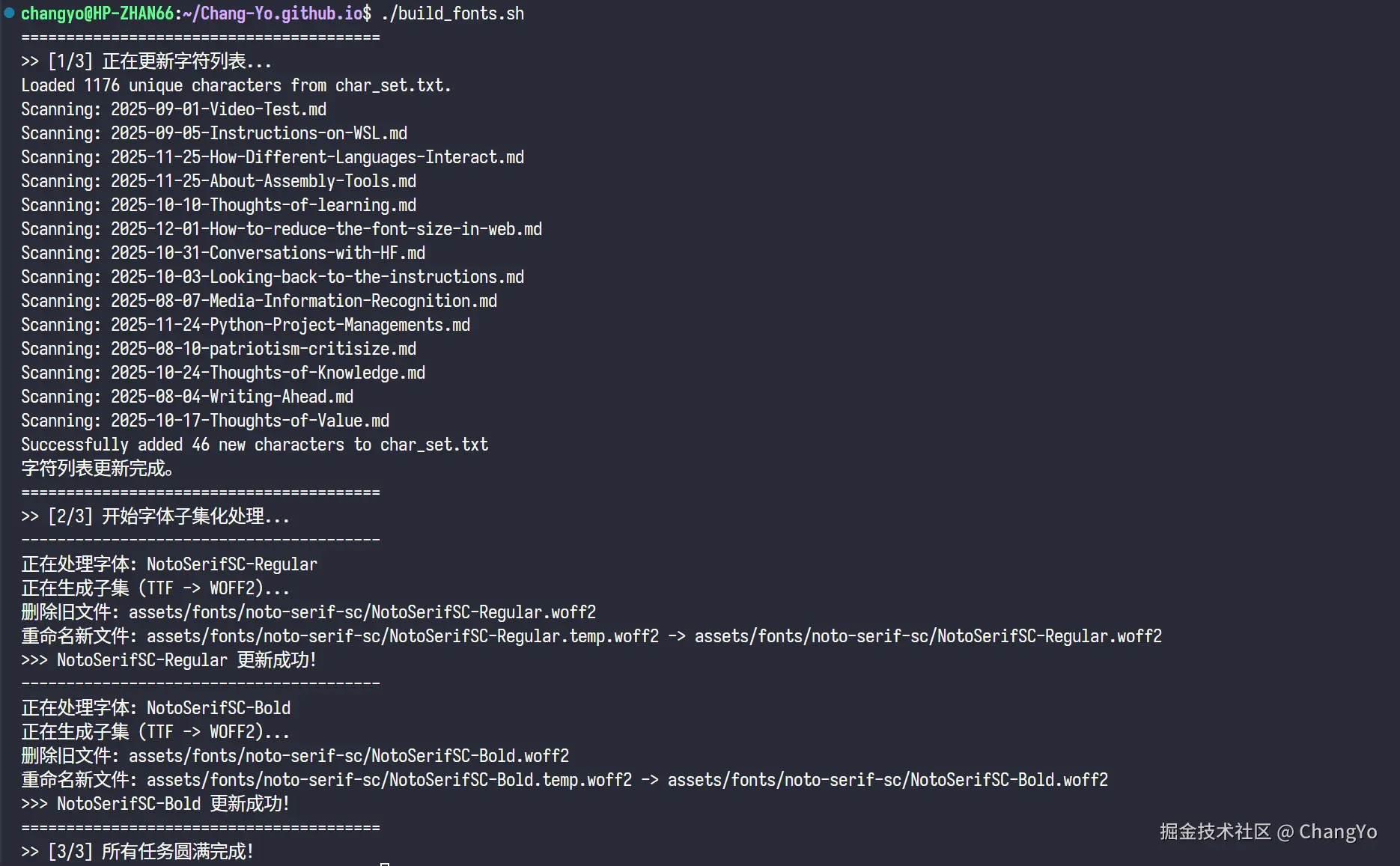
这些过程十分繁琐而且耗费时间,所以我们可以写一个bash脚本来实现这个过程的自动化。我这里同样是求助了Gemini,写了一个build_fonts.sh:
bash
#!/bin/bash
set -e # 遇到错误立即停止执行
# ================= 配置区域 =================
# 字体源文件目录
SRC_DIR="FontRepo"
# 字体输出目录
OUT_DIR="assets/fonts/noto-serif-sc"
# 字符列表文件
CHAR_LIST="char_set.txt"
# C++ 更新工具
UPDATE_TOOL="./updateLists"
# 确保输出目录存在
if [ ! -d "$OUT_DIR" ]; then
echo "创建输出目录: $OUT_DIR"
mkdir -p "$OUT_DIR"
fi
# ================= 第一步:更新字符表 =================
echo "========================================"
echo ">> [1/3] 正在更新字符列表..."
if [ -x "$UPDATE_TOOL" ]; then
$UPDATE_TOOL
else
echo "错误: 找不到可执行文件 $UPDATE_TOOL 或者没有执行权限。"
echo "请尝试运行: chmod +x updateLists"
exit 1
fi
# 检查 char_set.txt 是否成功生成
if [ ! -f "$CHAR_LIST" ]; then
echo "错误: $CHAR_LIST 未找到,字符表更新可能失败。"
exit 1
fi
echo "字符列表更新完成。"
# ================= 定义子集化处理函数 =================
process_font() {
local font_name="$1" # 例如: NotoSerifSC-Regular
local input_ttf="$SRC_DIR/${font_name}.ttf"
local final_woff2="$OUT_DIR/${font_name}.woff2"
local temp_woff2="$OUT_DIR/${font_name}.temp.woff2"
echo "----------------------------------------"
echo "正在处理字体: $font_name"
# 检查源文件是否存在
if [ ! -f "$input_ttf" ]; then
echo "错误: 源文件 $input_ttf 不存在!"
exit 1
fi
# 2. 调用 fonttools (pyftsubset) 生成临时子集文件
# 使用 --obfuscate-names 可以进一步减小体积,但这里只用基础参数以保证稳定性
echo "正在生成子集 (TTF -> WOFF2)..."
pyftsubset "$input_ttf" \
--flavor=woff2 \
--text-file="$CHAR_LIST" \
--output-file="$temp_woff2"
# 3. & 4. 删除旧文件并重命名 (更新逻辑)
if [ -f "$temp_woff2" ]; then
if [ -f "$final_woff2" ]; then
echo "删除旧文件: $final_woff2"
rm "$final_woff2"
fi
echo "重命名新文件: $temp_woff2 -> $final_woff2"
mv "$temp_woff2" "$final_woff2"
echo ">>> $font_name 更新成功!"
else
echo "错误: 子集化失败,未生成目标文件。"
exit 1
fi
}
# ================= 第二步 & 第三步:执行转换 =================
echo "========================================"
echo ">> [2/3] 开始字体子集化处理..."
# 处理 Regular 字体
process_font "NotoSerifSC-Regular"
# 处理 Bold 字体
process_font "NotoSerifSC-Bold"
echo "========================================"
echo ">> [3/3] 所有任务圆满完成!"如此一来,以后每次更新完文章,都只需要在终端输入./build_fonts.sh就可以完成字符提取、字体包子集化、清除旧字体包文件的过程了。
一点感想
在这之前另外讲个小故事,我尝试更换字体之前发现自定义的字体样式根本没有用,后来检查了很久,发现竟然是2个月前AI在我代码里加的一句font-family:'Noto Serif SC',而刚好他修改的又是优先级最高的文件,所以后面怎么修改字体都没有用。所以有时候让AI写代码前最好先搞清除代码的地位i,并且做好为AI代码后果负全责的准备。
更改网站字体其实很多时候属于锦上添花的事情,因为很多读者其实并不会太在意网站的字体。但不幸的是我对细节比较在意,或者说有种敝帚自珍的感觉吧,想慢慢地把网站装饰得舒适一些,所以才总是花力气在一些细枝末节的事情上。更何况,我是懂一点点设计的,有时候看见一些非常丑的Interface心里是很难受的。尽管就像绝大部分人理解不了设计师在细节上的别有用心一样,绝大部分人也不会在意一个网站的字体如何,但是我自己的家,我想装饰地好看些,对我来说就满足了。
更不要说,如果不去折腾这些东西,怎么可能会有这篇文章呢?如果能够帮助到一些人,也算是在世界留下一点价值了。
参考资料及附录
-
参考资料
a. 网页中文字体加载速度优化
b. 缩减网页字体大小
-
让Gemini生成代码时的Prompt:
plaintext
---Prompt 1---
# 任务名称:创建脚本实现对字符的收集
请利用C++来完成一下任务要求:
1. 该脚本能够读取项目目录下的markdown文件,并且能够识别当中所有的中文字符,将该中文字符与`/char_test/GeneralUsedChars.txt`的字符表进行查重比较:
若该字在表中存在,则跳过,处理下一个字;
若不存在,则将该字添加到表中,然后继续处理下一个字符
2. 请设计一个高效的算法,尤其是在字符查重的过程中,你需要设计一个高效且准确率高的算法
3. 请注意脚本的通用性,你需要考虑到这个项目以后可能会继续增加更多的markdown文件,所以你不应该仅仅只是处理现有的markdown文件,还需要考虑到以后的拓展性
4. 如果可以的话,尽可能使用C++来实现,因为效率更高
---Prompt 2---
可以了,现在我要求你编写一个脚本以实现自动化,要求如下:
1. 脚本运行时,首先会调用项目根目录下的updateLists可执行文件,更新char_set.txt
2. 接着,脚本会调用fonttools工具,对路径在`/FontRepo/`下的两个文件进行ttf到woff2的子集化转化,其中这两个字体文件的名字分别为`NotoSerifSC-Regular.ttf`和`NotoSerifSC-Bold.ttf`。
3. 转化好的子集文件应该输出到 `/assets/fonts/noto-serif-sc/`文件夹下。
4. 将`/assets/fonts/noto-serif-sc/`文件夹下原本已经存在的两个字体文件`NotoSerifSC-Bold.woff2`和`NotoSerifSC-Regular.woff2`删除,然后将新得到子集化文件重新命名为这两个删除了的文件的名字。这一步相当于完成了字体文件的更新
请注意文件的命名,尤其是不要搞错字号,新子集文件和旧子集文件。
请注意在子集化步骤的bash命令,环境已经安装好fonttools及其对应依赖,你可以参考下面这个命令来使用,或者使用更好更稳定的用法:
pyftsubset <path/to/ttf/file> --flavor=woff2 --text-file=<path/to/char_set.txt> --output-file=<the/subset/name>
(再次注意输出路径)-
最终实践效果(以
NotoSerifSC-Bold为例)处理方式 字体包体积 压缩率 无处理 14.462M 0% 格式转化 5.776M 60.06% 子集化处理 981K 93.21% 分包处理 依据动态加载量而定 无 我的实践 216K 98.5%