ThreadLocal
ThreadLoacl在Java中的核心作用是提供线程内的局部变量。它能让每个线程拥有该变量的一个独立副本,从而避免了多线程之间的竞争和干扰。
底层原理
核心结构:数据存在哪里?
ThreadLocal 本身并不存储数据 ,它只是一个访问入口,真正存储数据的是 Thread 线程对象本身
-
每个
Thread对象内部都有一个名为threadLocals的成员变量。 -
这个变量的类型是
ThreadLocalMap(它是ThreadLocal的静态内部类)。 -
当我们调用
set()时,其实是把数据存到了当前线程 的threadLocals那个 Map 里
映射关系与冲突解决
在 ThreadLocalMap 中:
-
Key :是当前的
ThreadLocal对象实例。 -
Value :是我们想要保存的业务数据。
值得注意的是,
ThreadLocalMap和我们常用的HashMap不同。它在解决 Hash 冲突时,没有使用链表法,而是采用了线性探测法 。也就是说,如果计算出的槽位被占了,它会顺着数组往后找,直到找到一个空位为止。这也意味着ThreadLocalMap不适合存储大量数据。
弱引用与内存泄漏
ThreadLocalMap 的 Entry 对 Key(ThreadLocal 对象)使用的是弱引用 ,但对 Value 使用的是强引用。
-
设计初衷 :如果外部对
ThreadLocal对象的引用没了,GC 发生时,作为 Key 的ThreadLocal会被自动回收,变成null,这样尽量避免 Key 的内存泄漏。 -
潜在风险 :虽然 Key 回收了,但只要线程还在运行(比如在线程池中),Value 依然有一条强引用链:
Thread -> ThreadLocalMap -> Entry -> Value。 -
后果 :这会导致
Entry中出现Key为null,但Value还在的情况。这个 Value 既无法被访问(因为 Key 没了),也无法被 GC 回收,从而造成内存泄漏。
所以,我们在使用 ThreadLocal 时,标准范式是在 try-finally 代码块的 finally 中,显式调用 remove() 方法。这不仅是为了清理数据,更是为了切断 Value 的引用链,防止内存泄漏和线程复用导致的数据脏读。
应用场景
保存线程上下文信息(代替参数传递)
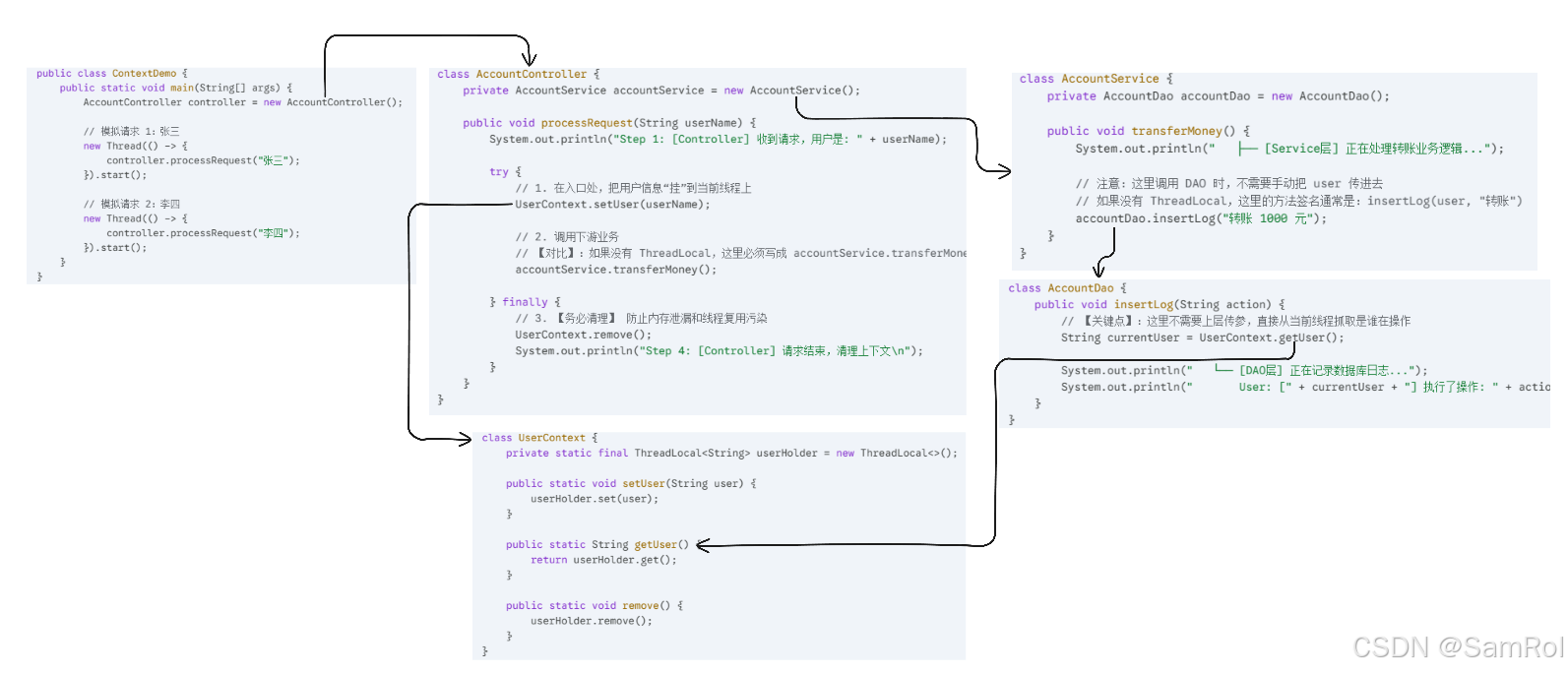
✨下面的代码模拟了一个 Controller -> Service -> DAO 的三层架构调用。请注意观察中间的 Service 层 ,它的方法参数里完全没有 用户信息,实现了参数解耦。
代码结构
-
UserContext:基于 ThreadLocal 的上下文容器。 -
AccountDao(底层):真正需要使用用户信息的地方。 -
AccountService(中间层) :业务逻辑层,它不需要感知用户信息的传递。 -
AccountController(顶层):模拟接收请求,设置上下文。
java
// ==========================================
// 1. 上下文容器 (工具类)
// ==========================================
class UserContext {
private static final ThreadLocal<String> userHolder = new ThreadLocal<>();
public static void setUser(String user) {
userHolder.set(user);
}
public static String getUser() {
return userHolder.get();
}
public static void remove() {
userHolder.remove();
}
}
// ==========================================
// 2. DAO 层 (最底层,需要用到用户信息)
// ==========================================
class AccountDao {
public void insertLog(String action) {
// 【关键点】:这里不需要上层传参,直接从当前线程抓取是谁在操作
String currentUser = UserContext.getUser();
System.out.println(" └── [DAO层] 正在记录数据库日志...");
System.out.println(" User: [" + currentUser + "] 执行了操作: " + action);
}
}
// ==========================================
// 3. Service 层 (中间层,无需透传参数)
// ==========================================
class AccountService {
private AccountDao accountDao = new AccountDao();
public void transferMoney() {
System.out.println(" ├── [Service层] 正在处理转账业务逻辑...");
// 注意:这里调用 DAO 时,不需要手动把 user 传进去
// 如果没有 ThreadLocal,这里的方法签名通常是:insertLog(user, "转账")
accountDao.insertLog("转账 1000 元");
}
}
// ==========================================
// 4. Controller 层 (入口,负责设置和清理)
// ==========================================
class AccountController {
private AccountService accountService = new AccountService();
public void processRequest(String userName) {
System.out.println("Step 1: [Controller] 收到请求,用户是: " + userName);
try {
// 1. 在入口处,把用户信息"挂"到当前线程上
UserContext.setUser(userName);
// 2. 调用下游业务
// 【对比】:如果没有 ThreadLocal,这里必须写成 accountService.transferMoney(userName)
accountService.transferMoney();
} finally {
// 3. 【务必清理】 防止内存泄漏和线程复用污染
UserContext.remove();
System.out.println("Step 4: [Controller] 请求结束,清理上下文\n");
}
}
}
// ==========================================
// 5. 测试主程序
// ==========================================
public class ContextDemo {
public static void main(String[] args) {
AccountController controller = new AccountController();
// 模拟请求 1:张三
new Thread(() -> {
controller.processRequest("张三");
}).start();
// 模拟请求 2:李四
new Thread(() -> {
controller.processRequest("李四");
}).start();
}
}通过 ThreadLocal,将用户信息存储在线程中,实现了层与层之间的零侵入 数据共享。
保证对象/资源的线程安全(资源隔离)
场景:数据库连接 (Connection)
问题背景: 假设你在一个 Service 方法里调用了 3 个 DAO 方法(插入A,更新B,删除C)。 为了让这 3 个操作在同一个事务 里(要么全成功,要么全回滚),它们必须使用同一个数据库连接 (Connection) 。
ThreadLocal 如何解决:
- 开启事务时 :Spring 获取一个数据库连接
conn1,然后调用ThreadLocal.set(conn1),把它绑在当前线程上。 - 执行 DAO A :DAO 问
ThreadLocal要连接,拿到了conn1。 - 执行 DAO B :DAO 问
ThreadLocal要连接,还是拿到了conn1。 - 执行 DAO C :DAO 问
ThreadLocal要连接,还是拿到了conn1。 - 提交事务时 :Spring 从
ThreadLocal取出conn1,执行conn1.commit()。 - 结束 :
ThreadLocal.remove()。
如果不用 ThreadLocal ,你就得把 Connection 对象作为参数,在 Service 和 DAO 的所有方法之间传来传去,代码会极其难看。
Sychronized
synchronized 是 Java 中最基础的并发控制关键字 。
它是一把"锁",用来控制多个线程对共享资源的访问,保证同一时刻只能有一个线程来执行特定的代码段。
使用方法
1.修饰实例方法(锁的是当前对象 this)
java
public synchronized void add() {
// 只有一个线程能进入这个方法
count++;
}含义 :想进这个屋,必须拿到这个对象实例的钥匙。
2.修饰静态方法(锁的是类对象 Class)
java
public static synchronized void add() {
count++;
}含义 :想进这个屋,必须拿到这个类的钥匙。因为类只有一个,所以这是全局锁,控制所有对象。
3.修饰代码块(锁的是指定对象)
java
public void add() {
// 只有这一小段代码需要排队,其他代码可以并发执行
synchronized(this) {
count++;
}
}这是最灵活的方式,也是推荐的方式(锁的范围越小性能越好)。
底层原理
synchronized 主要是通过**对象头(Object Header)**中的标记来实现的。
-
对象头:Java 中的每个对象在内存中都戴着一顶"帽子"(对象头)。这顶帽子里记录了这个对象**"属于谁"**(锁状态)。
-
Monitor(监视器锁):
- 当线程执行到
synchronized时,会尝试去获取该对象的 Monitor。 - 如果获取成功,对象头的标记就会变成"锁定",并记录当前线程 ID。
- 其他线程再来,发现对象头显示"已锁定",就会进入**等待队列(Entry Set)**睡觉,直到持有锁的线程出来。
- 当线程执行到
Synchronized的锁升级过程是怎么样的
为了提升性能,在Java6中JVM 引入了**"偏向锁 -> 轻量级锁 -> 重量级锁"**的升级过程。
形象比喻:占座
想象有一个会议室(对象),大家都要进去开会(获取锁)。
-
偏向锁 :只有张三一个人经常来,他在门口贴了个名字贴纸(记录线程ID),下次直接进,不用办手续。
-
轻量级锁 :李四也来了,发现贴着张三的名字。李四不甘心,就在门口转圈圈(自旋),等着张三出来抢贴纸。
-
重量级锁 :王五、赵六全来了,门口挤满了人。大家决定别转圈了,找个管理员(操作系统)装一把大铁锁,没钥匙的人全部去睡觉(阻塞),等叫号。
详细升级过程
第一阶段:偏向锁 (Biased Lock)
-
场景 :只有一个线程反复进入临界区,没有任何竞争。
-
动作:
-
当线程 A 第一次访问同步块时,JVM 只是把 线程 A 的 ID 通过 CAS 操作记录在对象的 Mark Word 中。
-
以后线程 A 再来,只要检查一下 Mark Word 里的 ID 是不是自己。如果是,完全不需要加锁解锁,直接进。
-
-
目的:消除在无竞争情况下的同步原语,提高单线程运行效率。
-
注:如果 JDK 启动参数关闭了偏向锁(JDK 15 以后默认废弃了偏向锁),则直接进入轻量级锁。
第二阶段:轻量级锁 (Lightweight Lock)
-
场景 :出现了轻微竞争。线程 A 还没执行完,线程 B 来了。
-
触发:线程 B 发现对象头里是线程 A 的 ID(偏向锁),于是尝试撤销偏向锁,升级为轻量级锁。
-
动作:
-
线程 A 和 线程 B 会在自己的栈帧中创建一块空间叫 Lock Record(锁记录)。
-
大家尝试用 CAS (Compare And Swap) 将对象头的 Mark Word 替换为指向自己 Lock Record 的指针。
-
抢到的:持有锁,执行代码。
-
没抢到的:不会立即睡觉(阻塞),而是进入**"自旋"**状态(Spinning)。也就是说,它会在 CPU 上空跑几个循环,看看持有锁的人会不会很快出来。
-
-
目的:避免线程挂起和恢复带来的上下文切换开销(这很慢)。
第三阶段:重量级锁 (Heavyweight Lock)
-
场景 :竞争变得剧烈。
-
情况 1:线程 B 自旋了很多次(默认 10 次)还没等到锁。
-
情况 2:线程 B 还在自旋,又来了个线程 C 也要抢。
-
-
触发:轻量级锁撑不住了,膨胀为重量级锁。
-
动作:
-
JVM 会向操作系统申请真正的互斥锁(Mutex Lock)。
-
锁标志位变为重量级锁状态。
-
此时,没抢到锁的线程不再自旋 (不耗 CPU 了),而是直接被操作系统挂起(Blocked),进入等待队列。
-
-
代价:线程的挂起和唤醒需要从"用户态"切换到"内核态",性能开销很大。
关键点
-
不可逆性 : 锁通常只能升级,不能降级。一旦升级为重量级锁,就不会再回到轻量级锁或偏向锁。(注:在 GC 期间只有极少数情况会降级,但面试通常忽略)。
-
为什么要有轻量级锁? 因为在实际开发中,很多锁的代码执行时间很短。如果直接挂起线程再唤醒,花费的时间可能比执行代码的时间还长。自旋(轻量级锁)就是用 CPU 时间换取响应速度。
-
为什么要有重量级锁? 如果持有锁的线程执行很慢,或者竞争非常激烈,一直自旋会白白消耗 CPU 资源。这时候必须让等待线程"睡觉",把 CPU 让给更有用的任务。
ReentrantLock
ReentrantLock (可重入锁)是 一种显式锁 。
如果把 synchronized 比作**"自动挡汽车"(简单、省心、由 JVM 自动控制),那么 ReentrantLock 就是"手动挡汽车"**(功能强大、灵活、需要手动挂挡/摘挡)。
核心特点:手动控制
与 synchronized 不同,ReentrantLock 需要你手动调用方法来加锁和释放锁。
java
// 1. 创建锁对象
Lock lock = new ReentrantLock();
// 2. 加锁
lock.lock();
try {
// === 业务逻辑 ===
System.out.println("我拿到锁了!");
} finally {
// 3. 【必须】在 finally 中解锁
// 如果不在 finally 解锁,一旦业务代码抛异常,锁永远不会释放,导致死锁
lock.unlock();
}ReentrantLock 比 synchronized 的核心区别
① 等待可中断 (lockInterruptibly)
-
synchronized:一旦去抢锁,要么抢到,要么一直等。如果别人一直不释放,你只能一直等,连线程中断(interrupt)都打断不掉你。 -
ReentrantLock:可以使用lock.lockInterruptibly()。如果你等得不耐烦了,别人可以调用thread.interrupt()打断你的等待,让你抛出异常去干别的事。
② 可实现"公平锁" (Fair Sync)
-
synchronized:默认是非公平的。锁释放了,大家一拥而上抢,谁运气好谁拿到(插队现象严重)。 -
ReentrantLock:默认也是非公平的(性能好),但你可以强制开启公平模式。
java
// true 表示开启公平锁:严格按照"先来后到"排队,绝对不允许插队
Lock lock = new ReentrantLock(true);③ 尝试非阻塞获取锁 (tryLock)
这是最骚的操作。
-
synchronized:不管有没有锁,头铁往里冲,没锁就阻塞。 -
ReentrantLock:可以使用tryLock()。-
"有人占着坑吗?有的话我就走了,不排队了。"
-
或者:"我等你 2 秒,2 秒不开门我就走了。"
-
java
if (lock.tryLock(2, TimeUnit.SECONDS)) {
try {
// 拿到锁了,干活
} finally {
lock.unlock();
}
} else {
// 没拿到锁,做降级处理(比如记录日志、以后再试)
System.out.println("太忙了,我溜了");
}底层原理:AQS + CAS
ReentrantLock 的底层完全是基于 AQS (AbstractQueuedSynchronizer) 框架实现的。
-
State 变量 :AQS 内部有一个
volatile int state。-
state = 0:表示锁是自由的。 -
state > 0:表示锁被占用了(数值表示重入次数)。
-
-
加锁过程:
-
线程尝试用 CAS 把
state从 0 改成 1。 -
如果成功:记录当前线程是锁的持有者(ExclusiveOwnerThread)。
-
如果失败:说明锁被占了。放入 AQS 的等待队列中(park 挂起),等待被唤醒。
-
synchronized和ReentrantLock的区别
| 特性 | synchronized | ReentrantLock |
|---|---|---|
| 用法 | 关键字,JVM 自动管理加锁解锁 | 类,必须手动 lock/unlock |
| 灵活性 | 低,死等 | 高,可中断、可超时、可尝试 |
| 公平性 | 只能非公平 | 可选 公平/非公平 |
| 实现机制 | Mark Word (对象头) + Monitor | AQS + CAS |
| 条件队列 | 只有一个 (wait/notify) | 可以有多个 (Condition) |
最佳实践建议:
-
首选
synchronized:在 JDK 1.6 之后,它的性能已经非常好了,而且代码简洁,不用担心忘记释放锁导致死锁。 -
只有当你需要以下功能时,才用
ReentrantLock:-
需要超时等待(等不到就不等了)。
-
需要公平锁(先来后到)。
-
需要复杂的线程协作(多个 Condition 条件)。
-