Redis 持久化的核心目的是 将内存中的数据落地到磁盘 ,避免 Redis 重启(如服务器宕机、进程退出)后数据丢失。Redis 提供两种核心持久化机制:RDB(快照) 和 AOF(Append Only File) ,4.0 版本后支持 混合持久化(结合两者优势),下面逐一详解:
一、持久化概述
Redis 是内存数据库,默认不开启持久化时,数据仅存于内存,进程终止后数据全部丢失。持久化通过 "磁盘备份"+"重启恢复" 实现数据可靠性,两种机制各有侧重,可单独使用或组合配置。
二、RDB(Redis Database):全量快照
1. 定义
RDB 是 Redis 的默认持久化方式,在指定时间点拍摄内存数据的全量快照 ,并保存为二进制文件(默认 dump.rdb)。重启时,Redis 直接加载该文件到内存,恢复速度极快。
2. 核心原理
RDB 通过 写时复制(Copy-On-Write, COW) 机制实现无阻塞快照:
- 触发 RDB 时,Redis 会
fork()一个子进程(父子进程共享内存); - 子进程负责将内存数据写入 RDB 文件,父进程继续处理客户端请求;
- 若父进程修改数据,会先复制该数据的副本,再修改副本(不影响子进程的快照写入)。
3. 触发方式
(1)手动触发(生产常用)
save:同步触发,会阻塞父进程(期间无法处理请求),不建议生产环境使用(数据量大时阻塞时间长);bgsave:异步触发,fork()子进程执行快照,父进程无阻塞,生产环境首选。
(2)自动触发(配置文件控制)
在 redis.conf 中配置 "触发条件",满足任一条件时自动执行 bgsave:
ini
# 格式:save <秒数> <修改次数>
save 900 1 # 900秒内有1次修改
save 300 10 # 300秒内有10次修改
save 60 10000 # 60秒内有10000次修改(高并发场景)其他自动触发场景:
- 执行
shutdown命令(无 AOF 时); - 主从复制时,从节点同步数据前,主节点会自动执行
bgsave生成 RDB 发送给从节点。
4. 优缺点
优点:
- 恢复速度快:二进制文件加载效率高,适合大规模数据恢复;
- 文件体积小:全量快照压缩后占用磁盘空间少,便于备份 / 迁移(如跨机房同步);
- 性能开销低 :仅
fork()子进程时短暂阻塞,快照写入不影响主进程。
缺点:
- 数据丢失风险 :仅保存 "触发时间点" 的数据,两次快照间的修改会丢失(如配置
save 60 10000,若 59 秒时宕机,近 59 秒数据丢失); - fork 开销大 :数据量越大,
fork()子进程占用的内存和时间越多(极端情况可能阻塞主进程秒级); - 不适合实时持久化:无法做到 "秒级数据安全"。
5. 关键配置
ini
dbfilename dump.rdb # RDB文件名
dir ./ # RDB文件存储路径(默认当前目录)
stop-writes-on-bgsave-error yes # bgsave失败时,是否停止接收写请求(避免数据不一致)
rdbcompression yes # 是否压缩RDB文件(默认开启,节省空间,轻微CPU开销)
rdbchecksum yes # 加载RDB时校验文件完整性(默认开启,轻微性能开销)三、AOF(Append Only File):增量日志
1. 定义
AOF 是 "增量日志" 机制,记录所有写操作命令(如 SET、HSET) ,以文本格式追加到文件(默认 appendonly.aof)。重启时,Redis 重新执行 AOF 文件中的所有命令,还原数据。
2. 核心原理
AOF 分为三步流程("命令追加 - 文件写入 - 文件同步"):
- 命令追加 :客户端执行写命令后,Redis 先将命令追加到内存中的
aof_buf缓冲区; - 文件写入 :操作系统将
aof_buf中的数据写入磁盘文件(但此时数据可能仍在系统缓存,未真正落盘); - 文件同步(fsync):强制操作系统将缓存中的数据刷到磁盘,确保数据持久化。
3. 触发方式
需在 redis.conf 中手动开启 AOF:
ini
appendonly yes # 开启AOF(默认no)
appendfilename "appendonly.aof" # AOF文件名(1)同步策略(关键配置,平衡性能与安全性)
Redis 提供三种 AOF 同步策略(通过 appendfsync 配置):
| 策略 | 配置值 | 说明 | 数据安全性 | 性能开销 |
|---|---|---|---|---|
| 总是同步 | always | 每次写命令都触发 fsync(数据实时落盘) | 最高(无丢失) | 最大(IO 密集) |
| 每秒同步 | everysec | 每秒触发一次 fsync(默认配置) | 较高(最多丢 1 秒数据) | 适中(推荐生产) |
| 操作系统控制 | no | 由操作系统决定何时 fsync(通常 30 秒左右) | 最低(可能丢大量数据) | 最低(性能最优) |
4. AOF 重写(解决文件膨胀问题)
(1)问题背景
AOF 记录所有写命令,若频繁执行 SET key value、INCR counter 等命令,AOF 文件会越来越大(如 10 万次 INCR 会记录 10 万条命令),导致:
- 磁盘占用过高;
- 重启恢复时间过长。
(2)重写原理
AOF 重写是 "合并命令、压缩体积" 的过程:Redis 扫描内存中的数据,用一条命令替代多条冗余命令(如 10 万次 INCR counter 合并为 SET counter 100000),生成新的 AOF 文件替换旧文件。
(3)触发方式
-
手动触发:执行
bgrewriteaof(异步重写,不阻塞主进程); -
自动触发:通过配置文件设置重写阈值: ini
auto-aof-rewrite-percentage 100 # AOF文件体积比上次重写后增长100%(即翻倍) auto-aof-rewrite-min-size 64mb # AOF文件最小体积(小于64mb不重写)
5. 优缺点
优点:
- 数据安全性高 :支持秒级持久化(
everysec策略),最多丢失 1 秒数据; - 日志可读性强:文本格式命令,可手动编辑(如误删数据后,可修改 AOF 文件恢复);
- 无数据丢失风险 :
always策略可实现实时持久化(适合金融等核心场景)。
缺点:
- 文件体积大:相同数据量下,AOF 文件比 RDB 大得多;
- 恢复速度慢:重启时需重新执行所有命令,数据量大时恢复时间长;
- 写性能开销 :相比 RDB,AOF 每秒 fsync 会带来额外 IO 开销(但
everysec策略影响较小)。
6. AOF 文件修复
若 AOF 文件因宕机等原因损坏,Redis 启动时会拒绝加载。可通过 Redis 自带工具修复:
bash
运行
redis-check-aof --fix appendonly.aof四、混合持久化(Redis 4.0+)
1. 定义
混合持久化是 RDB + AOF 的结合体 :开启后,AOF 重写时会将当前内存数据以 RDB 格式写入 AOF 文件开头,后续增量写命令仍以 AOF 格式追加。最终 AOF 文件结构为:[RDB 二进制数据] + [AOF 文本命令]。
2. 核心原理
- 重启恢复时:先加载 RDB 部分(快速恢复全量数据),再执行 AOF 部分(恢复增量数据);
- 兼顾 RDB 的 "快速恢复" 和 AOF 的 "数据安全",解决了纯 RDB 数据丢失多、纯 AOF 恢复慢的问题。
3. 配置开启
ini
aof-use-rdb-preamble yes # 开启混合持久化(Redis 5.0+默认开启,4.0需手动开启)五、数据恢复流程
Redis 启动时,按以下优先级恢复数据:
- 若同时开启 AOF 和 RDB:优先加载 AOF 文件(数据更全);
- 若仅开启 RDB:加载
dump.rdb文件; - 若均未开启:数据仅存于内存(重启丢失)。
恢复验证:启动 Redis 后,执行 info persistence 查看持久化状态,或直接通过 GET key 验证数据是否存在。
六、生产环境最佳实践
1. 持久化方案选择
- 核心场景(数据不能丢) :开启混合持久化(
aof-use-rdb-preamble yes),AOF 同步策略设为everysec; - 非核心场景(允许少量丢失) :仅开启 RDB(定期
bgsave备份),减少 IO 开销; - 极端性能场景(不在乎数据丢失):关闭持久化(如缓存临时数据)。
2. 关键配置优化
ini
# RDB 配置
save "" # 关闭自动 RDB 触发(避免频繁 fork 子进程),仅手动执行 bgsave 备份
rdbcompression yes # 开启 RDB 压缩
rdbchecksum yes # 开启 RDB 校验
# AOF 配置
appendonly yes
appendfsync everysec
auto-aof-rewrite-percentage 100 # AOF 翻倍时重写
auto-aof-rewrite-min-size 64mb # 最小重写体积
aof-use-rdb-preamble yes # 混合持久化3. 备份与监控
- 定期备份:每天执行
bgsave生成 RDB 文件,复制到异地存储(如 S3、备份服务器); - 监控文件:通过 Prometheus + Grafana 监控 RDB/AOF 文件大小、重写频率、fsync 耗时;
- 测试恢复:定期模拟宕机,验证 RDB/AOF 文件能否正常恢复(避免文件损坏未发现)。
4. 避坑要点
- 禁止用
save命令:同步阻塞主进程,导致服务不可用; - 控制
fork频率:数据量过大时(如 10GB 内存),fork可能阻塞秒级,需避开高峰期执行bgsave/bgrewriteaof; - 避免磁盘 IO 瓶颈:将 RDB/AOF 文件存储在独立磁盘(如 SSD),减少 IO 竞争。
七、总结
| 特性 | RDB | AOF | 混合持久化 |
|---|---|---|---|
| 数据完整性 | 较低(丢失两次快照间数据) | 较高(最多丢 1 秒) | 高(结合两者) |
| 恢复速度 | 快(二进制加载) | 慢(执行命令) | 快(RDB + 增量 AOF) |
| 文件体积 | 小(压缩) | 大(文本命令) | 中等(RDB + 压缩 AOF) |
| 写性能开销 | 低(仅 fork 时阻塞) | 中(每秒 fsync) | 中(同 AOF) |
| 适用场景 | 备份、迁移、非核心数据 | 核心数据、实时持久化 | 生产环境首选 |
Redis 持久化的核心是 "平衡数据安全性与性能",生产环境建议优先选择 混合持久化,搭配定期 RDB 备份,既保证数据可靠性,又兼顾恢复速度和写性能。
Redis 主从复制(Master-Slave Replication)
Redis 主从复制是 Redis 高可用架构的基础,核心作用是 实现数据冗余备份、读写分离、负载均衡 ,同时为后续哨兵(Sentinel)或集群(Cluster)的故障转移提供支撑。简单来说:主节点(Master)负责写操作和数据同步,从节点(Slave/Replica)负责读操作和数据备份,从节点的数据完全由主节点同步而来。
一、核心概念与目标
1. 核心角色
- 主节点(Master) :
- 唯一可写入节点(默认配置下,从节点只读);
- 接收所有写命令(SET、HSET、DEL 等),并将命令同步给所有从节点;
- 可拥有多个从节点(无上限,建议不超过 3-5 个,避免主节点同步压力过大)。
- 从节点(Slave/Replica) :
- 只读节点(默认
replica-read-only yes),无法执行写命令(除INFO、SLAVEOF等少数命令); - 从主节点同步数据,保持与主节点数据一致;
- 可作为 "从节点的主节点"(级联主从),分担主节点的同步压力。
- 只读节点(默认
2. 核心目标
- 数据冗余:从节点备份主节点数据,避免单点故障导致数据丢失(配合持久化效果更佳);
- 读写分离:主节点负责写,从节点负责读(如查询、统计类操作),分摊主节点压力,提升并发能力;
- 负载均衡:多个从节点可分散读请求,支持更高的读并发(Redis 读多写少场景的核心优化手段);
- 故障转移基础:主节点故障时,可手动或通过哨兵将从节点晋升为主节点,实现服务高可用。
二、主从复制核心原理
Redis 主从复制分为 三个阶段:「建立连接 → 数据同步 → 命令传播」,整个过程异步非阻塞(主节点同步时不影响处理写请求)。
1. 阶段 1:建立连接(从节点主动发起)
从节点通过配置或命令指定主节点地址后,会主动与主节点建立连接,流程如下:
- 从节点执行
SLAVEOF master_ip master_port(或配置文件指定),发起同步请求; - 主节点接受连接后,创建「复制客户端」(专门用于与该从节点通信);
- 从节点向主节点发送
PSYNC命令,请求同步数据(携带自身的「复制偏移量」和「主节点运行 ID」,用于判断是否支持增量同步)。
2. 阶段 2:数据同步(全量 / 增量同步)
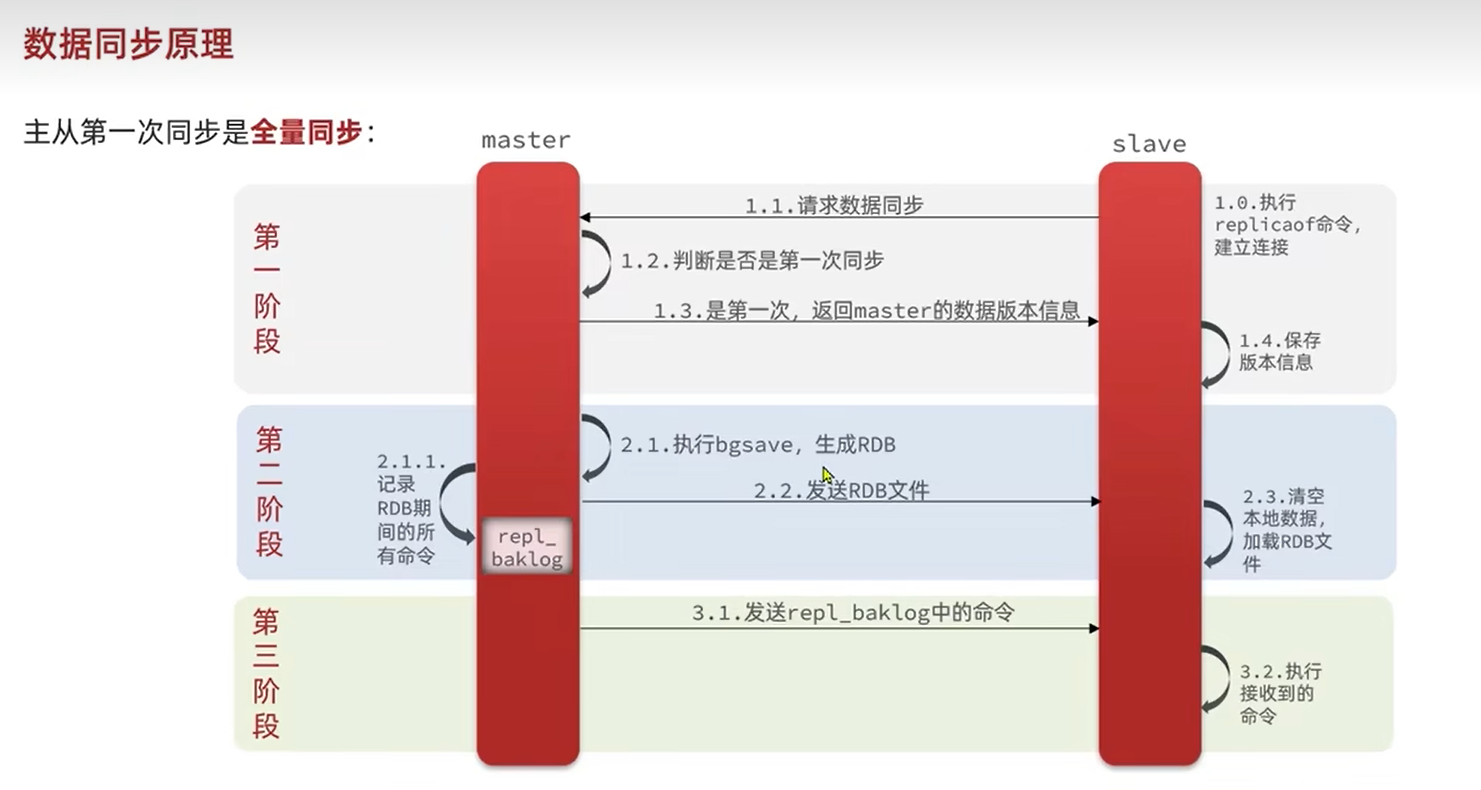
数据同步是主从复制的核心,分为「全量同步」和「增量同步」两种场景:
(1)全量同步(首次同步 / 断点无法续传时)
适用于:从节点首次连接主节点、从节点与主节点断开连接后偏移量差距过大(超过主节点的复制积压缓冲区)。流程:
- 主节点收到
PSYNC后,判断需要全量同步,回复FULLRESYNC(携带主节点运行 ID 和当前复制偏移量); - 主节点执行
BGSAVE生成 RDB 快照文件(期间主节点继续处理写请求,所有写命令会存入「复制积压缓冲区」); - 主节点将 RDB 文件发送给从节点;
- 从节点接收 RDB 文件后,清空自身旧数据,加载 RDB 到内存(期间从节点暂时无法处理读请求);
- 主节点将「复制积压缓冲区」中存储的、RDB 生成后的写命令,全部发送给从节点;
- 从节点执行这些增量命令,最终与主节点数据一致。
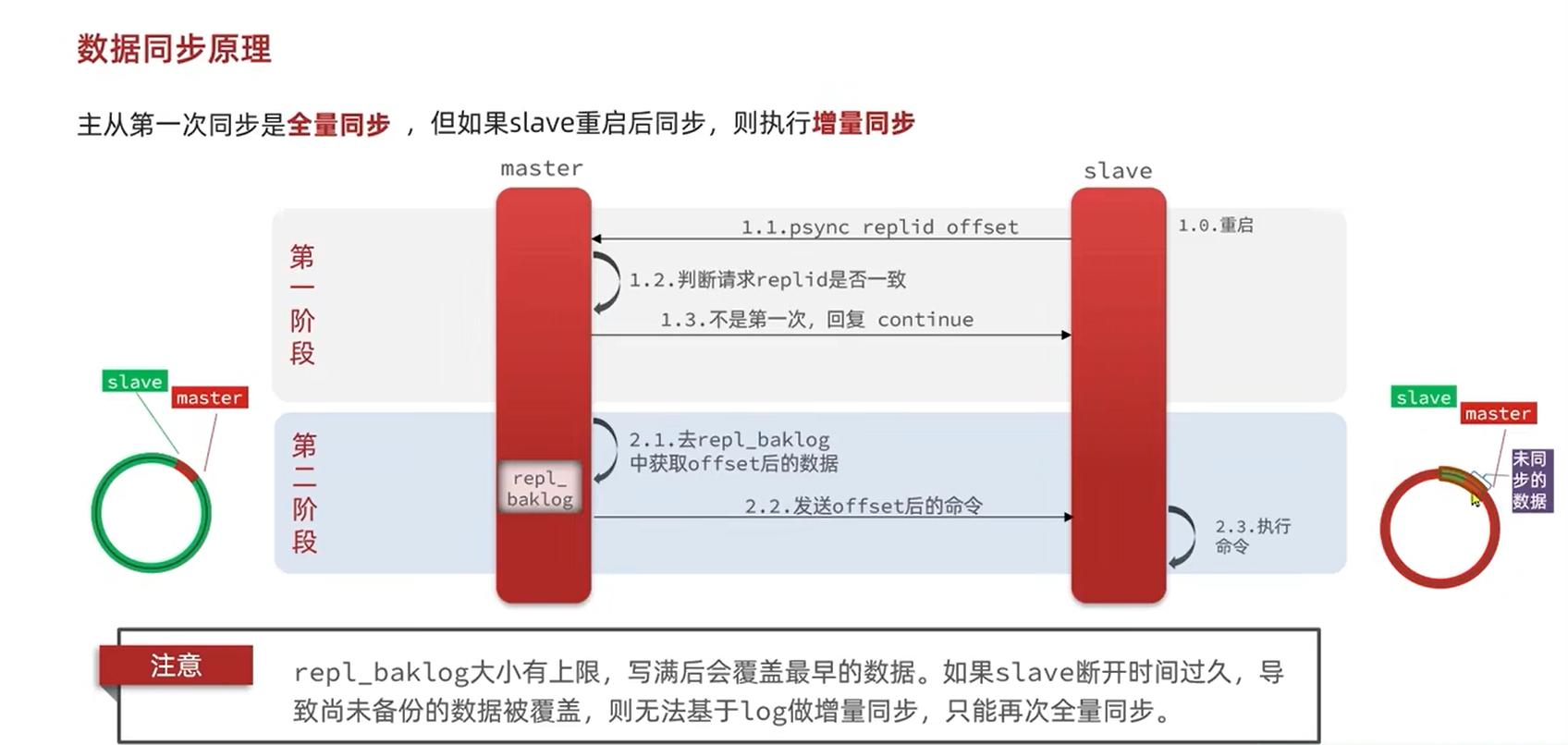
(2)增量同步(从节点重连后偏移量有效时)
适用于:从节点短暂断开连接后重新连接,且断开期间主节点的写命令未超出「复制积压缓冲区」(默认 1MB,可配置)。流程:
- 从节点重连后,发送
PSYNC命令,携带上次同步的「复制偏移量」和「主节点运行 ID」; - 主节点验证运行 ID 一致,且偏移量在复制积压缓冲区范围内,回复
CONTINUE; - 主节点将从节点偏移量之后的所有写命令,从复制积压缓冲区中取出并发送给从节点;
- 从节点执行命令,快速同步至主节点当前状态(无需全量加载 RDB,效率极高)。
3. 阶段 3:命令传播(实时同步)
数据同步完成后,主节点进入「命令传播」阶段:
- 主节点每执行一次写命令,都会将命令同步给所有从节点;
- 从节点接收命令后立即执行,确保与主节点数据实时一致;
- 同步方式:主节点通过「复制客户端」向从节点发送命令,从节点被动接收并执行(异步传播,存在微小延迟,通常毫秒级)。
三、主从复制配置(实操步骤)
Redis 主从配置支持「命令行临时配置」(重启失效)和「配置文件永久配置」(生产推荐),以下以 Redis 6.x 为例(5.0 后将 slaveof 改为 replicaof,功能完全一致)。
前提条件
- 主从节点网络互通(关闭防火墙或开放 Redis 端口,默认 6379);
- 主节点无需特殊配置(默认支持作为主节点);
- 从节点需配置主节点地址,且确保主节点密码(若有)正确。
1. 命令行临时配置(测试场景)
从节点执行以下命令,立即成为指定主节点的从节点(重启后失效):
bash
运行
# 连接从节点 Redis 客户端
redis-cli -h 从节点IP -p 从节点端口
# 配置主节点(Redis 5.0+ 用 replicaof,5.0- 用 slaveof)
127.0.0.1:6379> replicaof 主节点IP 主节点端口
# 若主节点设置了密码(requirepass),需配置认证(从节点向主节点同步时用)
127.0.0.1:6379> config set masterauth 主节点密码
# 验证配置(查看复制状态)
127.0.0.1:6379> info replication2. 配置文件永久配置(生产场景)
修改从节点的 redis.conf 文件,重启后永久生效:
ini
# 1. 配置主节点地址(核心配置)
replicaof 主节点IP 主节点端口 # Redis 5.0+;5.0- 用 slaveof
# 2. 主节点密码(若主节点开启 requirepass,必须配置)
masterauth 主节点密码
# 3. 从节点只读(默认 yes,生产强制开启,避免误写)
replica-read-only yes
# 4. 其他优化配置(可选)
repl-diskless-sync yes # 开启无盘同步(默认 no,减少从节点磁盘 IO,适合 SSD)
repl-diskless-sync-delay 5 # 无盘同步延迟(等待 5 秒,收集更多从节点一起同步)
repl-backlog-size 1mb # 复制积压缓冲区大小(增大可减少全量同步概率,如 8mb)
repl-timeout 60 # 复制超时时间(默认 60 秒,网络差可适当增大)
repl-ping-replica-period 10 # 从节点向主节点发送 PING 的频率(默认 10 秒)3. 配置验证
主从节点均执行 info replication 命令,查看关键字段:
- 主节点:
role:master,connected_slaves:1(从节点数量),slave0:ip=从节点IP,port=从节点端口,...; - 从节点:
role:slave,master_host:主节点IP,master_port:主节点端口,master_link_status:up(同步正常)。
示例(从节点 info replication 输出):
plaintext
# Replication
role:slave
master_host:192.168.1.100
master_port:6379
master_link_status:up # 同步正常(down 表示连接失败)
master_last_io_seconds_ago:3
master_sync_in_progress:0 # 无同步任务
slave_repl_offset:12345 # 复制偏移量(与主节点一致则同步完成)四、主从复制核心特性
1. 读写分离
- 主节点:处理所有写请求(SET、HSET、DEL 等),同时同步命令给从节点;
- 从节点:处理所有读请求(GET、HGET、KEYS 等),默认只读(
replica-read-only yes); - 价值:分摊主节点读压力(Redis 场景多为 "读多写少",如电商商品查询、缓存查询),提升系统并发能力。
2. 数据冗余与高可用基础
- 从节点是主节点的完整数据备份,主节点宕机后,可手动将从节点晋升为主节点(执行
replicaof no one),快速恢复服务; - 配合持久化(如混合持久化):主从保证 "内存级冗余",持久化保证 "磁盘级落地",双重保障数据不丢失。
3. 从节点只读限制
- 从节点默认禁止写操作,若执行写命令(如 SET key value),会返回错误:
(error) READONLY You can't write against a read only replica; - 若需临时允许从节点写(测试场景),可执行
config set replica-read-only no(生产不建议开启)。
4. 主从链(级联复制)
- 支持 "主 → 从 → 从" 的级联结构(如主节点 M → 从节点 S1 → 从节点 S2);
- 价值:减轻主节点同步压力(主节点仅需同步给 S1,S1 再同步给 S2),适合从节点数量较多的场景;
- 注意:级联深度不宜过深(建议 ≤2 级),否则会导致末端从节点复制延迟过大。
五、常见问题与优化方案
1. 复制延迟(主从数据不同步)
原因:
- 网络带宽不足(主节点同步 RDB / 命令给从节点时网络拥堵);
- 从节点磁盘 IO 慢(加载 RDB 文件耗时久);
- 主节点写压力过大(大量写命令导致同步队列堆积);
- 级联复制过深(末端从节点延迟叠加)。
优化:
- 网络优化:主从节点部署在同一机房,使用高速网络(如万兆网卡),避免跨地域同步;
- 存储优化:从节点使用 SSD 磁盘(提升 RDB 加载和命令写入速度);
- 配置优化:开启无盘同步(
repl-diskless-sync yes),减少从节点磁盘 IO;增大复制积压缓冲区(repl-backlog-size 8mb),减少全量同步; - 架构优化:减少从节点数量(≤3 个),避免级联复制,采用 "一主多从" 直连架构;
- 压力分流:通过读写分离,将读请求分散到从节点,减少主节点压力。
2. 主从数据不一致
原因:
- 网络抖动:主节点命令传播中断,从节点未接收完整命令;
- 脑裂(主从分区):主节点网络断开但未宕机,从节点被晋升为主节点,之后原主节点恢复,出现两个 "主节点";
- 从节点写操作:误开启从节点可写,导致从节点数据与主节点不一致。
解决:
- 网络层面:使用稳定网络,配置合理的超时时间(
repl-timeout 60); - 脑裂防护:开启主节点「min-replicas-to-write」配置(如
min-replicas-to-write 1),要求主节点至少有 1 个健康从节点才允许写操作,避免脑裂后原主节点单独写入; - 禁止从节点写:生产强制开启
replica-read-only yes; - 数据校验:定期通过
redis-cli --scan遍历主从节点数据,对比一致性(如校验 key 数量、数据摘要)。
3. 全量同步开销过大
原因:
- 从节点频繁重连(导致每次重连都触发全量同步);
- 复制积压缓冲区过小(
repl-backlog-size不足,断开后偏移量超出缓冲区); - 主节点
BGSAVE耗时久(数据量大时生成 RDB 文件慢,阻塞主节点)。
优化:
- 增大复制积压缓冲区(如
repl-backlog-size 16mb),延长偏移量有效期; - 避免从节点频繁重启(稳定运行);
- 主节点优化:关闭自动 RDB 触发(
save ""),仅通过主从同步触发BGSAVE;开启 RDB 压缩(rdbcompression yes),减少 RDB 文件体积,加快同步速度; - 从节点优化:提前加载 RDB 备份文件,减少首次同步时的 RDB 传输时间。
4. 主节点宕机后如何恢复?
手动故障转移步骤:
- 确认主节点宕机(通过监控或
redis-cli ping验证); - 选择一个数据最新的从节点(查看
slave_repl_offset,与主节点差距最小); - 登录该从节点,执行
replicaof no one,将其晋升为主节点; - 其他从节点执行
replicaof 新主节点IP 新主节点端口,重新同步新主节点; - 修复原主节点,将其配置为新主节点的从节点(避免再次启动后成为独立主节点)。
自动故障转移:
- 手动故障转移效率低,生产建议使用「Redis 哨兵(Sentinel)」,自动监控主从节点状态,主节点宕机后自动将从节点晋升为主节点,无需人工干预。
六、生产环境最佳实践
1. 架构选择
- 推荐「一主多从」直连架构(主节点 1 个 + 从节点 2-3 个),避免级联复制;
- 若读并发极高,可搭配「哨兵」实现自动故障转移,或直接使用 Redis Cluster(支持多主多从,更高可用性)。
2. 核心配置优化(从节点 redis.conf)
ini
# 基础配置
replicaof 192.168.1.100 6379 # 主节点地址
masterauth redis@123456 # 主节点密码(若有)
replica-read-only yes # 强制只读
# 同步优化
repl-diskless-sync yes # 无盘同步(减少磁盘 IO)
repl-backlog-size 8mb # 复制积压缓冲区(增大至 8-16mb)
repl-timeout 60 # 同步超时时间
repl-ping-replica-period 10 # 从节点 PING 频率
# 持久化配合(从节点开启混合持久化,主节点按需开启)
appendonly yes
aof-use-rdb-preamble yes
appendfsync everysec3. 监控要点
- 复制状态:通过
info replication监控master_link_status(是否 up)、slave_repl_offset(主从偏移差); - 复制延迟:监控
master_last_io_seconds_ago(从节点上次与主节点通信时间,建议 ≤10 秒); - 主节点压力:监控主节点的
used_cpu_sys、used_cpu_user(CPU 使用率)、instantaneous_ops_per_sec(每秒操作数); - 磁盘 / 网络:监控从节点 RDB 加载耗时、网络带宽占用(避免同步导致 IO / 网络瓶颈)。
4. 备份策略
- 从节点备份:在从节点执行
bgsave生成 RDB 文件(避免主节点备份占用资源),定期将 RDB 复制到异地存储; - 避免主节点备份:主节点仅负责写操作,备份任务交给从节点,减少主节点压力。
七、主从与持久化的配合
主从复制和持久化是 Redis 数据可靠性的两大核心,需搭配使用:
- 主节点:可开启混合持久化(或仅 AOF),确保写命令落地磁盘;
- 从节点:必须开启持久化(混合持久化最佳),避免从节点晋升为主节点后,重启数据丢失;
- 核心逻辑:主从保证 "内存级冗余",持久化保证 "磁盘级落地",即使所有节点宕机,也可通过 RDB/AOF 文件恢复数据。
八、总结
Redis 主从复制的核心价值是 读写分离 + 数据冗余,是 Redis 高可用架构的基础。生产环境中,建议:
- 采用「一主 2-3 从」直连架构,搭配混合持久化;
- 开启读写分离,分散主节点压力;
- 配置哨兵实现自动故障转移(替代手动切换);
- 重点监控复制延迟、数据一致性、主从连接状态,避免同步异常。
若需更高可用性(如多主多从、跨地域部署),可在此基础上升级为 Redis Cluster(集群),但主从复制的核心原理和配置逻辑仍适用。
Redis 哨兵(Sentinel):主从架构的高可用 "守护者"
Redis 哨兵是主从复制架构的高可用组件 ,核心作用是自动监控主从节点状态、主节点宕机后自动故障转移,替代手动切换从节点为主节点的操作,保证服务不中断。
一、哨兵的核心功能
简单说,哨兵是主从架构的 "管家",负责 4 件事:
- 监控(Monitoring):持续检查主节点、从节点是否正常运行;
- 自动故障转移(Automatic Failover):主节点宕机时,自动将一个从节点晋升为新主节点;
- 通知(Notification):主从状态变化时,通过 API / 消息通知客户端;
- 配置更新(Configuration Provider):故障转移后,自动更新所有节点的主从配置(如其他从节点同步新主节点)。
二、哨兵的工作原理(简单版)
哨兵通常以集群形式部署(至少 3 个节点)(避免 "脑裂"),核心流程分 3 步:
1. 状态检测:主观下线 + 客观下线
- 主观下线(SDOWN):单个哨兵连续多次(默认 30 秒)Ping 不通主节点,认为主节点 "疑似宕机";
- 客观下线(ODOWN) :超过
quorum(配置的 "投票数")个哨兵都认为主节点主观下线,才判定主节点 "真正宕机"(避免单哨兵误判)。
2. 选新主节点:按规则挑最优从节点
主节点宕机后,哨兵集群会从所有从节点中选一个 "最优者" 升为主节点,规则优先级:
- 从节点优先级(replica-priority):数值越小优先级越高(默认 100,0 表示不能升主);
- 复制偏移量:与原主节点数据同步最完整的(偏移量最大);
- 运行 ID:ID 最小的(兜底规则)。
3. 故障转移:自动完成 "升主 + 同步"
- 哨兵向选中的从节点发送
replicaof no one,将其晋升为新主节点; - 哨兵向其他从节点发送
replicaof 新主节点IP 新主节点端口,让它们同步新主节点; - 原主节点恢复后,哨兵会将其配置为新主节点的从节点。
三、Windows 下哨兵配置(基于你的主从环境)
假设你已在 Windows 上部署了主节点(6379)+ 从节点(6380),现在配置哨兵:
1. 准备哨兵配置文件
在C:\Redis下新建sentinel目录,创建sentinal.conf(注意:Redis 对文件名不敏感,sentinel.conf或sentinal.conf都可),写入以下配置:
ini
# 1. 哨兵端口(默认26379,多哨兵需改端口,如26380、26381)
port 26379
# 2. 监控主节点:格式 sentinel monitor <主节点名> <主节点IP> <主节点端口> <quorum投票数>
# 解释:监控名为mymaster的主节点(127.0.0.1:6379),至少2个哨兵认为其下线才触发故障转移
sentinel monitor mymaster 127.0.0.1 6379 2
# 3. 主节点密码(若主节点设了requirepass,必须配置)
# sentinel auth-pass mymaster 你的主节点密码
# 4. 主节点主观下线超时(默认30000毫秒=30秒)
sentinel down-after-milliseconds mymaster 30000
# 5. 故障转移超时(默认180000毫秒=3分钟)
sentinel failover-timeout mymaster 1800002. 开放哨兵端口的防火墙(Windows 关键步骤)
哨兵默认端口是 26379,需开放防火墙(同主从端口的开放方式):
bash
运行
# 管理员命令行执行,开放哨兵端口
netsh advfirewall firewall add rule name="Redis Sentinel Port 26379" dir=in action=allow protocol=TCP localport=263793. 启动哨兵
在sentinel目录下执行(注意加--sentinel参数):
bash
运行
cd C:\Redis\sentinel
redis-server.exe sentinel.conf --sentinel4. 验证哨兵是否正常
连接哨兵客户端,查看监控状态:
bash
运行
# 连接哨兵(默认端口26379)
redis-cli -p 26379
# 查看哨兵状态(会显示监控的主节点、从节点信息)
127.0.0.1:26379> info sentinel成功标志:sentinel_masters:1,且mymaster对应的status:ok。
四、测试故障转移(验证哨兵效果)
- 停掉主节点(6379):直接关闭主节点的 Redis 窗口;
- 等待 30 秒左右,查看哨兵日志:会出现 "failover" 相关日志,显示从节点(6380)被晋升为新主节点;
- 验证新主节点:连接 6380 端口,执行
info replication,会显示role:master; - 恢复原主节点(6379):重启 6379,执行
info replication,会显示role:slave(自动同步新主节点 6380)。
五、生产环境注意事项
- 哨兵集群至少 3 个节点:部署在不同机器,避免单机器故障导致哨兵失效;
- 哨兵端口不重复 :多哨兵需改
port(如 26379、26380、26381); - 主从 + 哨兵 + 持久化配合:持久化保证数据不丢,哨兵保证服务不中断;
- Windows 不建议生产用:Redis 官方对 Windows 支持有限,生产建议用 Linux。
Redis 分片集群(Redis Cluster):解决 "单节点内存 / 性能瓶颈" 的横向扩展方案
Redis 分片集群(官方叫 Redis Cluster)是Redis 官方的分布式架构 ,核心作用是将数据分散到多个主节点(分片),同时通过 "主从备份" 保证每个分片的高可用 ------ 既解决了单节点内存不足的问题,又能提升并发读写性能。
一、分片集群的核心:哈希槽(Hash Slot)
Redis Cluster 把数据划分为 16384 个哈希槽(Hash Slot),这是分片的核心逻辑:
- 每个主节点会负责一部分槽(比如 3 个主节点的话,可能各分 5461/5461/5462 个槽);
- 存储数据时,Redis 会通过
CRC16(key) mod 16384计算 key 对应的槽,再把 key 存到负责该槽的主节点上; - 读取数据时,客户端会直接连接负责对应槽的节点(智能客户端会缓存槽的分布,无需转发)。
二、分片集群的架构:多主多从(高可用 + 分片)
生产环境的分片集群通常是 "N 主 + 每个主配 1 个从" 的结构(比如 3 主 3 从):
- 主节点:负责哈希槽和写操作,数据分散在不同主节点(实现分片);
- 从节点:每个主节点对应 1 个(或多个)从节点,同步主节点的数据(实现该分片的高可用);
- 示例:主节点 A(槽 0-5460)→ 从节点 A1;主节点 B(槽 5461-10922)→ 从节点 B1;主节点 C(槽 10923-16383)→ 从节点 C1。
三、分片集群的核心能力(对比主从 / 哨兵)
| 架构类型 | 核心能力 | 数据存储上限 | 并发能力 | 高可用方式 |
|---|---|---|---|---|
| 单节点 | 基础读写 | 单节点内存 | 单节点性能 | 无 |
| 主从(哨兵) | 读写分离 + 故障转移 | 单主内存 | 读并发提升 | 哨兵 / 集群自带 |
| 分片集群 | 分片存储 + 多主并发 + 高可用 | 所有主节点内存总和 | 多主并行读写 | 从节点自动晋升主节点 |
四、关键注意:Windows 不支持官方分片集群
Redis 官方的Cluster 功能仅支持 Linux 系统 (依赖 fork、集群网络等 Linux 特性),Windows 版本(微软维护的旧版)不支持分片集群 ------ 若你在 Windows 上测试,只能用第三方工具(如 Redis Cluster Proxy),但生产环境必须用 Linux 部署分片集群。
五、Linux 下分片集群的最简配置步骤(3 主 3 从示例)
以 3 主 3 从(端口 7001-7006)为例:
-
创建 6 个节点的配置文件(每个节点一个目录):
ini
# 每个节点的配置(以7001为例) port 7001 cluster-enabled yes # 开启集群模式 cluster-config-file nodes-7001.conf # 集群配置文件(自动生成) cluster-node-timeout 15000 # 节点超时时间 appendonly yes # 开启AOF daemonize yes # 后台启动 -
启动 6 个节点:
bash
运行
redis-server /etc/redis/7001/redis.conf redis-server /etc/redis/7002/redis.conf # ... 直到7006 -
创建集群(指定主从关系):
bash
运行
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1(
--cluster-replicas 1表示每个主节点配 1 个从节点)
六、分片集群的核心特性
- 自动分片:数据自动分散到不同主节点,无需手动分库分表;
- 自动故障转移:主节点宕机后,其从节点会自动晋升为主节点(替代哨兵的功能);
- 客户端路由:智能客户端(如 JedisCluster)会缓存槽的分布,直接连接目标节点,性能无损耗;
- 扩缩容支持 :可通过
redis-cli --cluster add-node/del-node动态添加 / 删除节点,同时迁移哈希槽。