背景:数据迁移的核心需求
在数据库运维中,跨环境数据迁移是高频场景:
- 开发环境→生产环境的数据同步
- 数据分析需导出结构化数据集
- 系统迁移或备份容灾场景
MongoDB 官方工具链中的 mongoexport/mongoimport 凭借轻量级、格式兼容性强(JSON/CSV)的特点,成为首选方案。本指南深度解析其高级应用
权限配置与基础操作
权限最小化原则
执行操作需严格权限控制(最小权限原则):
mongodb
// 创建专用只读用户(非root账户)
use admin
db.createUser({
user: "migrate_user",
pwd: "encryptedPass123!",
roles: [
{ role: "readWrite", db: "target_db" } // 精确到库级别
]
})关键点:
- 生产环境禁止使用
readAnyDatabase全局权限 - 认证库需显式声明:
--authenticationDatabase admin
mongoexport 数据导出
1 ) CSV格式导出(适合结构化数据分析)
bash
mongoexport \
--db sales \
--collection orders \
--type=csv \
--fields "order_id,customer.name,amount,timestamp" \ # 嵌套字段用点语法
--query '{ "timestamp": { "$gt": "2025-01-01" } }' \ # 条件筛选
--out /backup/2025_orders.csv \
--username migrate_user \
# --password secure_password \ # 这个可以不要,在后面输
--authenticationDatabase admin 关键参数解析:
--type=csv:指定导出格式为 CSV--fields:必须显式声明导出字段(逗号分隔)--out:定义输出文件路径(缺省时输出到 stdout)
特性与陷阱:
| 行为 | 说明 |
|---|---|
| 字段必显式声明 | 未指定--fields将报错 |
| 嵌套文档处理 | customer.name导出为扁平列(非JSON结构) |
| 逗号处理 | 字段值含逗号时自动包裹双引号(如"Smith, John") |
内嵌文档处理技巧:当导出内嵌文档字段时,使用点号语法:
bash
mongoexport \
--fields "name.first,name.last,balance" \
--type=csv \
--out accounts_nested.csv2 ) JSON格式导出(保留完整文档结构)
bash
mongoexport \
--type=json \ # 注意这里
--fields "order_id,customer,amount" \ # customer保持嵌套对象
--gzip \ # 大文件压缩
--out orders_2025.json
# --out orders_2025.json.gz优势:
_id字段始终自动包含(确保数据可追溯性)fields参数可选(缺省时导出完整文档结构)- 保留原始文档层级关系(内嵌文档结构不变)
- 保留BSON数据类型(如Date、ObjectId)
mongoimport 数据导入
1 ) CSV导入关键逻辑
bash
mongoimport \
--db production \
--collection orders \
--type=csv \
--headerline \ # 首行为字段名
--upsertFields "order_id" \ # 按order_id更新而非新增
--ignoreBlanks \ # 忽略空字段
--file /backup/2025_orders.csv或
bash
mongoimport \
--db test \
--collection import_accounts \
--type=csv \
--headerline \
--file accounts_nested.csv \
--username read_user \
--password secure_password \
--authenticationDatabase admin关键参数说明:
--headerline:将首行作为字段名声明--file:指定导入文件路径--drop:导入前清空集合(可选)
字段映射关系:
graph LR
CSV文件 -->|--headerline| 首行作为字段名
CSV文件 -->|--fields "a,b,c"| 自定义字段名
数据 --> 嵌套文档[点号字段自动转嵌套结构]
2 ) JSON导入与更新
bash
mongoimport \
--db test \
--collection import_accounts \
--type=json \
--file accounts_export.json \
--upsertFields "name.first,balance"或
bash
mongoimport \
--type=json \
--mode=upsert \ # 等效upsertFields "_id"
--file orders_2025.json 数据类型一致性:
- JSON 自动识别 BSON 类型(如
ISODate("2025-01-01T00:00:00Z")) - CSV需显式类型声明:
--columnsHaveTypes 'order_id.string(),amount.double()'
案例:高级场景实战
1 ) 案例1:增量数据同步
通过--query+--upsertFields实现增量同步:
bash
# 导出今日新增订单
mongoexport --query '{ "timestamp": { "$gte": ISODate("2025-05-10") } }'
# 导入时按order_id更新, 通过覆盖来去重
# 若集合中已存在相同 order_id 的文档,则用新数据覆盖旧文档(更新)
# 若不存在相同 order_id,则插入新文档
mongoimport --upsertFields "order_id" --stopOnError工作机制:
- 比较指定字段组合是否匹配
- 存在匹配文档 → 执行更新操作
- 无匹配文档 → 执行插入操作
- 忽略
_id字段(CSV 文件不含该字段)
工程化参数:
| 参数 | 功能描述 |
|---|---|
--stopOnError |
首次遇到错误立即终止导入(保障数据完整性) |
--maintainInsertionOrder |
严格保持文件中的文档顺序(时序敏感数据处理) |
--numInsertionWorkers |
多线程导入控制(默认 1 线程,可增加并发),如:--numInsertionWorkers 4 |
--bypassDocumentValidation |
跳过模式校验(限已知结构) |
--ignoreBlanks |
忽略CSV空字段(防null覆盖) |
2 ) 案例2:NestJS 服务集成
安全导出服务封装:
typescript
import { Injectable } from '@nestjs/common';
import { exec } from 'child_process';
@Injectable()
export class ExportService {
async exportCollectionToCSV(
db: string,
collection: string,
outputPath: string,
fields: string[]
): Promise<void> {
const fieldList = fields.join(',');
const cmd = `mongoexport \
--db ${db} \
--collection ${collection} \
--type=csv \
--fields "${fieldList}" \
--out ${outputPath}`;
return new Promise((resolve, reject) => {
exec(cmd, (error) => {
if (error) reject(`Export failed: ${error.message}`);
else resolve();
});
});
}
}批量导入容错机制:
typescript
async importWithRetry(filePath: string, retries = 3) {
let attempt = 0;
while (attempt < retries) {
try {
await this.runImport(`mongoimport --file ${filePath} --stopOnError`);
break;
} catch (e) {
attempt++;
logger.error(`Attempt ${attempt} failed: ${e}`);
}
}
}或
ts
import { Controller, Post, Body } from '@nestjs/common';
import { ImportService } from './import.service';
@Controller('data')
export class DataImportController {
constructor(private readonly importService: ImportService) {}
@Post('import')
async importData(@Body() importDto: {
filePath: string;
collection: string;
upsertFields?: string[];
}) {
return this.importService.importFromFile(
importDto.filePath,
importDto.collection,
importDto.upsertFields
);
}
}更多NestJS集成示例
1 )方案1
typescript
// 使用MongoDB原生驱动执行export
import { spawn } from 'child_process';
const runExport = () => {
const exportProcess = spawn('mongoexport', [
'--db=test',
'--collection=accounts',
'--type=json',
'--out=./export.json'
]);
exportProcess.stdout.on('data', (data) => {
console.log(`Export Output: ${data}`);
});
};
// 使用Mongoose模型导入数据
import { Injectable } from '@nestjs/common';
import { InjectModel } from '@nestjs/mongoose';
import { Model } from 'mongoose';
import * as fs from 'fs';
@Injectable()
export class ImportService {
constructor(
@InjectModel('Account') private accountModel: Model<AccountDocument>
) {}
async importFromJson(path: string) {
const data = JSON.parse(fs.readFileSync(path, 'utf-8'));
await this.accountModel.bulkWrite(
data.map((doc) => ({
updateOne: {
filter: { _id: doc._id },
update: { $set: doc },
upsert: true
}
}))
);
}
}2 ) 方案2:封装mongoexport服务
typescript
import { Injectable } from '@nestjs/common';
import { exec } from 'child_process';
@Injectable()
export class ExportService {
async exportCSV(): Promise<string> {
const command = `mongoexport --db test --collection accounts --type=csv --fields "name.first,name.last,balance"`;
return new Promise((resolve, reject) => {
exec(command, (err, stdout) => {
if (err) reject(`导出失败: ${err.message}`);
else resolve(stdout);
});
});
}
}3 ) 方案3: 流式导入优化方案
typescript
import { spawn } from 'child_process';
const importer = spawn('mongoimport', [
'--db=test',
'--collection=accounts',
'--type=json',
'--jsonArray'
]);
fs.createReadStream('data.json').pipe(importer.stdin);
importer.stdout.on('data', (data) => {
console.log(`进度: ${data}`);
});
importer.on('close', (code) => {
console.log(`导入完成,状态码: ${code}`);
});避坑指南:高频问题解决方案
| 问题类型 | 原因 | 解决方案 |
|---|---|---|
| CSV首行作为数据导入 | 未用--headerline或--fields |
检查文件首行格式,二选一参数强制声明字段映射关系 |
| 嵌套结构丢失 | CSV点号字段未自动转换 | 确保导入字段名含点号(如--fields "customer.name") |
| 重复数据累积 | CSV无_id且未用upsertFields |
联合业务字段作唯一键:--upsertFields "order_id,timestamp" |
| 数值类型错误 | CSV中数字被识别为字符串 | 添加类型声明:--columnsHaveTypes 'amount.double()' |
| 大文件内存溢出 | 未分片或压缩 | 分批次导出:--skip 10000 --limit 50000 + --gzip |
-
CSV 格式陷阱
- 字段含逗号时需用双引号包裹(
"Smith, John") - 日期类型建议先转换为 ISO 格式
- 字段含逗号时需用双引号包裹(
-
内嵌文档处理
json// 错误处理 { "name.first": "John", "name.last": "Doe" } // 正确结构 { "name": { "first": "John", "last": "Doe" } } -
数据类型一致性
- 导入前验证数值字段无字符串污染
- 使用
--columnsHaveTypes声明类型(CSV 导入)
-
大文件处理策略
- 分批次导出:
--skip和--limit参数 - 压缩传输:
--gzip压缩输出
bashmongoexport --gzip --out data.json.gz - 分批次导出:
-
权限最小化原则
mongodb// 更安全的权限配置 use test db.createUser({ user: "export_user", pwd: "export_pass", roles: [ { role: "read", db: "test" } ] }) -
权限控制
- 导出需
read权限,导入需write+convertToCapped权限 - 生产环境建议使用专用角色(非
readAnyDatabase)
- 导出需
-
CSV处理特殊性
- 必须显式声明字段(
--fields或--headerline) - 数值类型自动转换(字符串需加引号)
- 必须显式声明字段(
-
数据一致性保障
- 高频导入使用
--upsertFields避免重复数据 - 关键操作配合
--drop确保集合状态纯净
- 高频导入使用
-
嵌套结构差异
字段展开 保留层级 字段映射 CSV导出 扁平结构 JSON导出 嵌套文档 CSV导入 自定义结构
工具对比与最佳实践
工具链选型建议
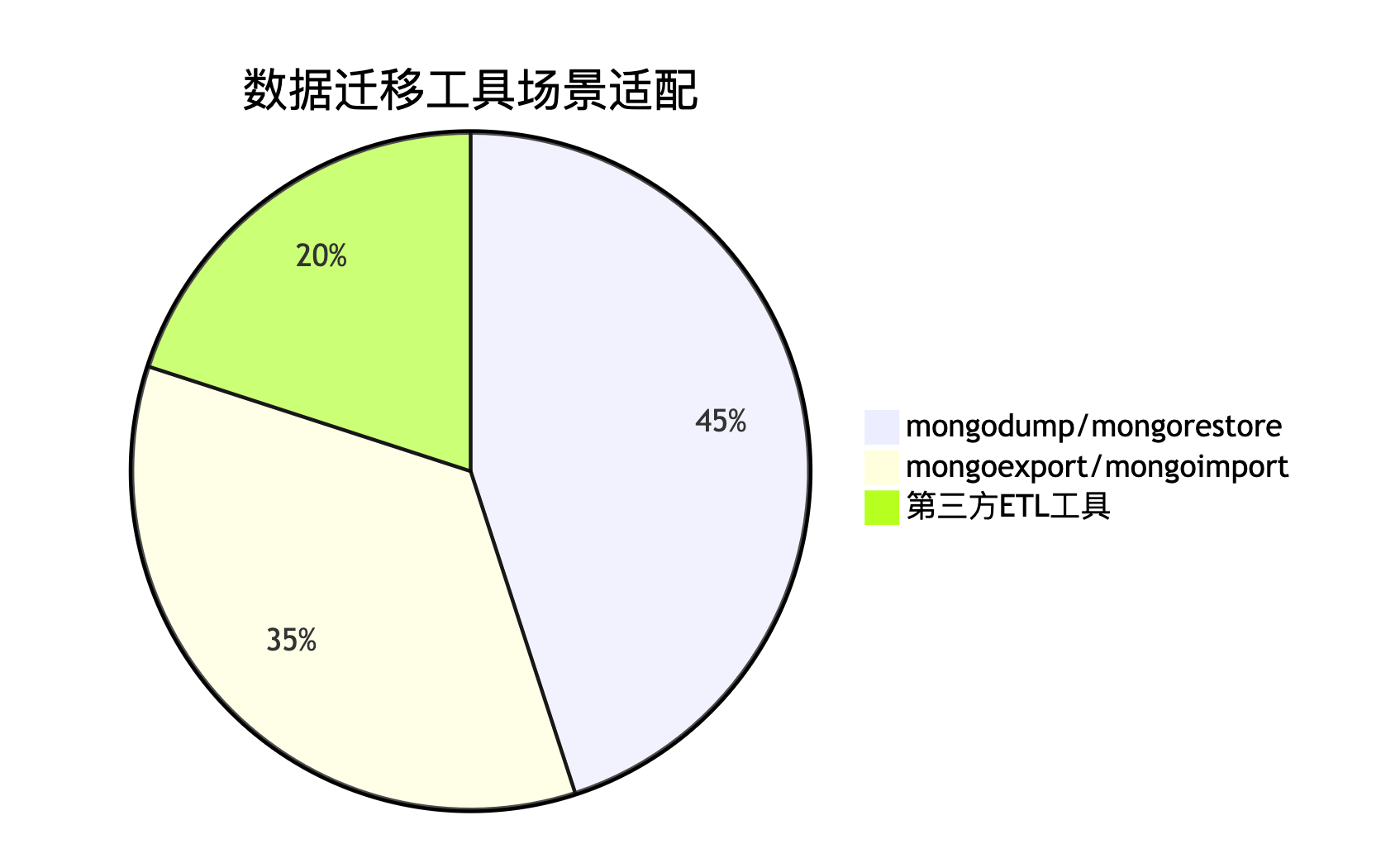
核心最佳实践
1 ) 权限管控
-
为迁移任务创建专属账号(非
readAnyDatabase) -
权限精确到库级别(
readWrite@specific_db) -
执行
mongoexport需对目标数据库具备读权限 -
创建专用只读用户:
mongodbuse admin db.createUser({ user: "readUser", pwd: "password", roles: ["readAnyDatabase"] }) -
关键点:
readAnyDatabase为MongoDB内置角色,仅在admin库生效
2 ) 数据一致性
- 导出前用
--query过滤无效数据 - 导入必用
--upsertFields或--drop避免冗余
3 ) 性能优化
bash
# 并行导出(v6.0+)
mongoexport --numParallelCollections 4
# 批处理导入
mongoimport --batchSize 1000 4 ) 版本兼容
| MongoDB版本 | 关键特性支持 |
|---|---|
| 4.2+ | --numInsertionWorkers 多线程 |
| 5.0+ | --bypassDocumentValidation |
终极建议:
- JSON用于文档结构敏感场景(如嵌套数组)
- CSV适用于扁平数据分析(需显式类型声明)
- 超10GB迁移改用
mongodump+mongorestore组合
5 )核心要点
| 工具 | 关键能力 | 生产建议 |
|---|---|---|
| mongoexport | 支持JSON/CSV格式;字段筛选;查询过滤 | 大数据量迁移时分批导出避免内存溢出 |
| mongoimport | 字段映射;重复数据更新(upsertFields) |
CSV导入必用--headerline或--fields |
| 权限控制 | 最小化权限原则(如只读用户) | 禁止使用root账户操作 |
6 )最佳实践:
- 数据一致性:导入导出使用相同字段命名规范(避免结构歧义)
- 性能优化:超大数据集启用
--numParallelCollections并行导出 - 安全加固:通过TLS加密连接传输敏感数据
- 大数据量迁移优先使用
mongodump/mongorestore,JSON格式作为次要选择,CSV格式仅适用于结构化数据分析场景
7 ) 要点总结
- 权限最小化是安全底线,避免使用全局角色
--upsertFields是避免CSV重复数据的核心机制- 嵌套字段用点语法导出,导入自动恢复结构
- 生产环境必用
--stopOnError+--maintainInsertionOrder保障一致性