文章导读
本文是对go语言的gmp模型的一个技术分享。
本文一共分成四个部分对gmp进行学习:
- 前置知识:操作系统的一些概念,协程、线程等知识。
- golang的gmp模型:这是go语言的核心拼图,理解这块底层知识,后面的学习才会得心应手,这部分是偏原理性的介绍。
- 核心数据结构:这部分,基于源码,对go语言的标准库runtime这个包中gmp涉及到的核心的数据结构的一些定义进行认识。
- 动态的调度流程:对整个gmp的调度的链路,源码进行走读。
一. 前置知识
1.1 线程
首先是线程,总所周知,线程是操作系统的最小调度单元。
通义中的线程,指的是内核线程,其核心特点如下:
- 操作系统本身有用户态和内核态的区分,线程作为最小的调度单元,是在内核态的视角之下的;
- 创建、销毁、调度均由内核完成,cpu需要完成用户态和内核态之间的切换;
- 可充分利用多核实现并行;
1.2 协程
前文已经强调,线程是内核态视角下的昂贵资源,那么协程和线程就相对,是用户态视角下的一个产物。
这两者并非平级,协程比线程低一级,是线程的子集,是在先有线程的基础之上,在用户态的视角之下,进行二次加工,二次开发的衍生产物,更像是一个逻辑上的概念,最终底层物理意义上,本质还是一个线程,还是一个最小的调度单元。
协程有以下核心特点:
- 与线程存在映射关系,为M:1,可以理解为依附与某一个线程而生的,可以理解为用户态基于某些操作,依附与某一个始终存活可运行的线程之上的一个子单元;
- 创建、销毁、调度都是在用户态完成,更像一种逻辑处理,所以更轻;
- 从属于某一个内核级线程,无法并行,也就是说,当一个协程阻塞,从属于同一个线程的所有协程将无法运行;
也就是说,从属于同一个线程 的协程组,在用户态视角下,实际上是只能做到并发。(缺陷)
1.3 goroutine
前文提到的协程主流叫法叫:Coroutine
而goroutine其实是经过go语言优化后的特殊"Coroutine",是特指go世界中,优化改良后的一种协程。
将goroutine和线程之间的强依附性,强关联性解绑了。
加了一个go调度器,在中间动态的维护goroutine和线程之间的关系。
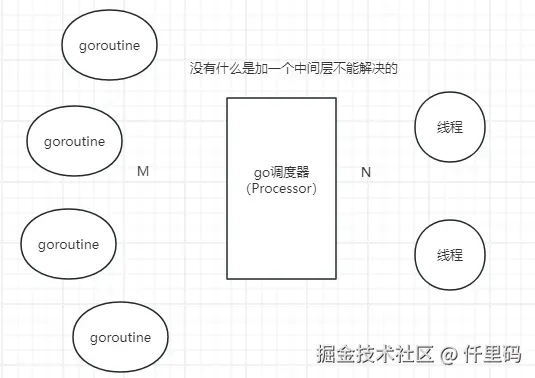
核心特点:
- 将映射关系变成M:N,可利用多个线程;
- 创建、销毁、调度也是在用户态完成,极轻,初始化才2kb,无需内核态的介入;
- 能够真正的做到并行;
- 通过go调度器的斡旋,实现和线程之间的动态绑定,从而更加灵活的调度;
- goroutine栈空间大小可以动态扩展,因地制宜(区别于线程栈);
综上,可以看出,go语言在调度协程上做了优化,实现了"灵活调度",但是,这其中,针对"如何减少加锁的行为","如何避免资源分配不均"等问题到底是怎么解决的呢?
二. golang的gmp模型
gmp=goroutine+machine+processor
下面单独说一下各个组件
2.1 g
g即是goroutine,在go语言中,是对协程的一种抽象。
每一个g都有自己的栈、状态和执行的函数(通过go func指定,在堆上创建)
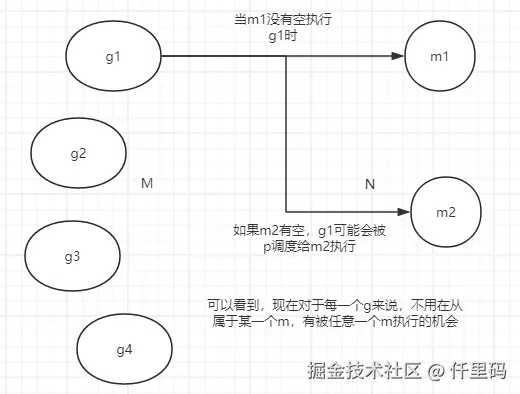
由操作系统线程(M)执行,通过(P)获取运行资源。g只知道自己在哪个M上运行,不知道也不关心是哪个P在提供资源。
2.2 m
m就是machine,是go语言对线程一个抽象
M直接执行并记录当前G的信息,P为M提供运行资源。G在生命周期内可以被不同M执行,但同一时刻只能在一个M上运行。
2.3 p
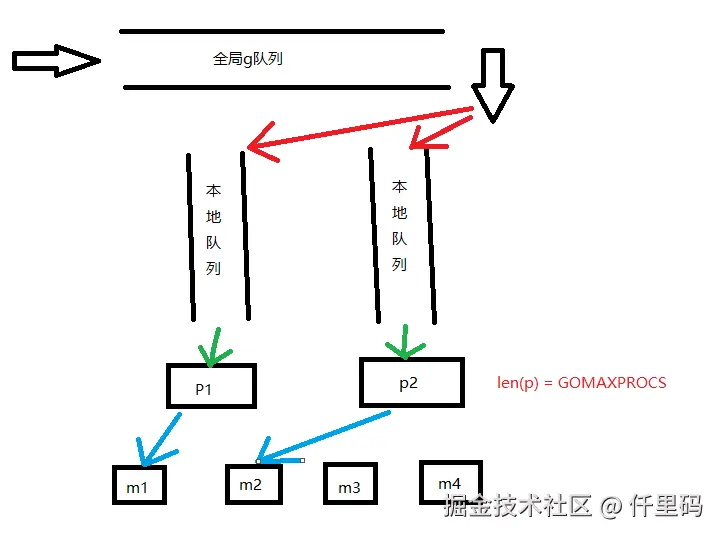
p即是processor,是go语言中,抽象为对协程的一个调度器,g只有进入p队列,才能得以执行
P为M提供G队列和运行资源。P的数量限制同时执行的G数量
三. 核心数据结构
3.1 g
源码位置:$(go env GOROOT)/src/runtime/runtime2.go
3.1.1 g的结构定义
go
type g struct {
m *m // 当前交与的m的指针(操作系统线程),可变,也可空
sched gobuf // 专门用于切换 Goroutine 时保存和恢复执行上下文
atomicstatus atomic.Uint32 // G status 存储生命状态
...
}
// Goroutine Buffer(Go运行时上下文缓冲区)
type gobuf struct {
sp uintptr // 保存cpu的rsp寄存器的值,指向函数调用栈的栈顶
pc uintptr // 保存cpu的rip寄存器的值,指向程序下一条执行指令的地址
g guintptr // 当前 Goroutine 的指针(指向自己)
ret uintptr // 保存系统调用的返回值
bp uintptr // 保存cpu的rbp寄存器的值,存储函数栈帧的起始位置
...
}这里的m应该怎么来理解?
这里的m不是具体绑定到某一个m,而是一个指针,是动态可变的,是调度器分配的
很明显,g.sched是专供调度器使用的,调度器需要这个字段来执行 g 的切换
因为Goroutine需要被暂停和恢复 (比如等待I/O时让出CPU)。调度器暂停一个g时,就把CPU的sp、pc等寄存器值保存到g.sched里,恢复时再从g.sched读出来放回CPU寄存器,g就能接着执行了
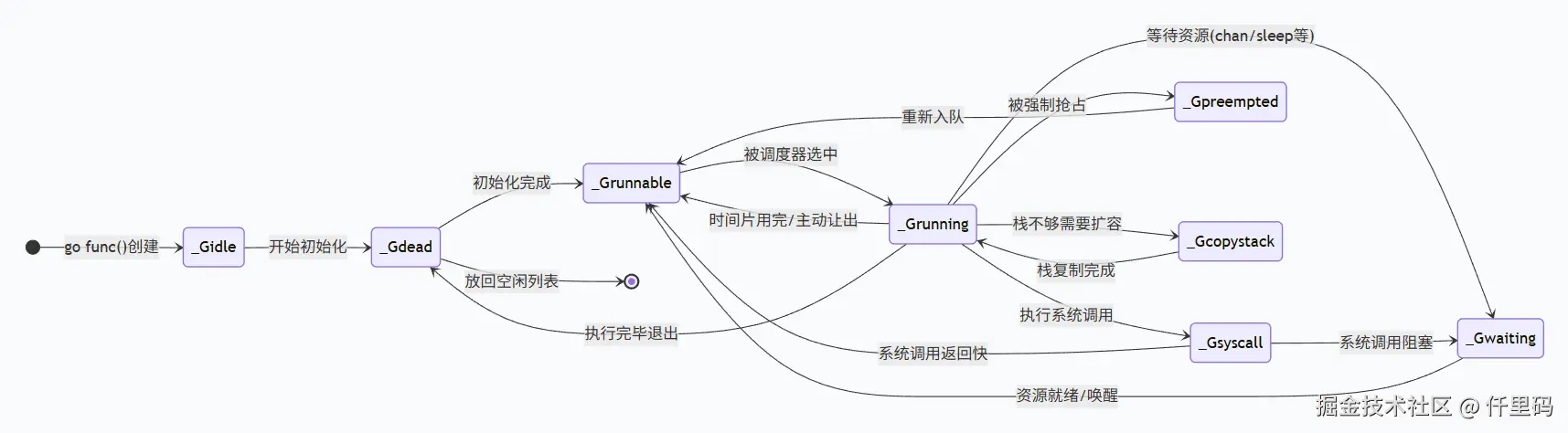
3.1.2 g的生命周期状态
go
// g status
const (
_Gidle = iota // 0 // 刚创建,还没初始化
_Grunnable // 1 // 就绪态,随时可以被调度
_Grunning // 2 // 运行态,正在 CPU 上执行
_Gsyscall // 3 // 系统调用态,正在执行系统调用
_Gwaiting // 4 // 等待态,被阻塞
_Gdead // 6 // 死亡态,已退出,还没被清理
_Gcopystack // 8 // 栈复制态,正在扩容/收缩栈
_Gpreempted // 9 // 被抢占态,被强制让出m
...
// 这里有个有意思的点:为什么变量的命名要使用下划线和大写字母
// 明明如果不想被外部包访问,直接写成gidle = iota不就可以了吗?
// 主要是因为:
// 可读性: _开头=运行时私有,大写=关联G结构体,包外不可访问
// 历史习惯:早期C/Unix风格,系统级代码用 `_` 前缀表示内部/系统
// 分组归类:运行时有很多私有常量,需要分类,例如,_Gidle表示G状态,_Pidle就可以表示P状态了,很清晰
)g.atomicstatus用 atomic.Uint32 就是为了保证:原子性、可见性和不用锁。
例如:g 正从 _Grunning 切换到 _Gwaiting,同时垃圾回收器在检查所有 G 的状态,用原子操作能确保不会看到中间的不一致状态
3.2 m
3.2.1 m的结构定义
go
type m struct {
g0 *g // goroutine with scheduling stack
curg *g // current running goroutine
tls [tlsSlots]uintptr // thread-local storage
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr
...
}这里的g0要怎么理解,怎么看起来还是m直接管理g?
g0其实是一类特殊的协程,称为始祖协程,是调度器的工作协程 ,用操作系统线程的原生栈,专门处理协程切换,与m的关系是1:1,这里的g0虽然也是一个指针,但是却是绑定的关系
- p:该m为了执行go代码所依附的p,没有执行时,就为nil
- nextp:临时存放的P(准备绑定),也就是下一个可以依附的p
- oldp:g退出_Grunning前保存的P,也就是p和解绑时保存,直到恢复时,p = oldp(恢复绑定,如果该p没有新的m的话)
| 特点 | g | g0 |
|---|---|---|
| 谁创建 | go func() 创建 |
运行时创建(线程启动时) |
| 用途 | 执行用户代码 | 执行调度、垃圾回收等系统任务 |
| 数量 | 成千上万 | 1:1 对应每个m |
| 栈在哪 | 堆上分配的普通栈 | 操作系统线程栈 |
| 能否被抢占 | 能 | 不能(必须一次性执行完) |
| 特权 | 用户态 | 和普通g一样在用户态运行 |
3.3 p
3.3.1 p的结构定义
go
type p struct {
runqhead uint32 // 队列头地址
runqtail uint32 // 队列尾地址
runq [256]guintptr // 本地goroutine队列,固定最大长度256
runnext guintptr // 下一个可执行的goroutine地址
status uint32 // p的生命状态
m muintptr // 该p获取到的m
...
}p.runq就是p本身私有的一个g队列,但是这个队列是有一个最大的容量的
go
type schedt struct {
lock mutex
// Global runnable queue.
runq gQueue
runqsize int32
...
}schedt是对全局goroutine队列的封装
lock是一把操作全局队列时使用的锁,runq、runqsize即为队列和队列的容量
go
const (
_Pidle = iota // 空闲,等待M绑定
_Prunning // 已被M绑定,正在运行
_Psyscall // 绑定M在系统调用,可被其他M偷
_Pgcstop // 暂停(GC时)
_Pdead // 销毁
)P 的状态决定谁可以绑定
3.4 三者的关系
从以上的结构定义可以看到:
- m中似乎有最全的信息,两种g(g0和curg),有p,nextp,oldp的地址;
- p中有g的队列,也有*m;
- 而g中只有*m,和自己的相关信息(sched、status)之外,没有p;
这种设计,既体现了g和m之间,协程和线程之间本质的关系(协程依托于线程才能执行),又证明p是go语言中的一个优化存在,P事实上是一个抽象理解的 "资源管理者",是g的"管理者",也作为m获取g的"工作台"
css
启动顺序:
1. 进程启动 → 创建 M0(静态分配,后续动态创建)
2. runtime初始化 → 创建 P(GOMAXPROCS个)
3. 创建主goroutine(main方法)
4. M0的g0开始调度,P绑定到M
时间线:
M0存在 → P创建 → M0绑定P → 开始调度从g的结构体定义可以看到,g中没有p啊,那g被创建出来后,此时没有*m,第一次是怎么入队列的,入的什么队列?
新创建的g既没有m也没有p,它被放入创建它的g的p的本地队列的队尾
那main这个主goroutine是谁创建的,是不是g0?因为g0是使用的线程栈,那么是创建在堆上,还是在线程栈上?
是 runtime 自己创建的,不是 g0 直接创建的
调用链:runtime.main → newproc() → 创建主goroutine → 放入队列,堆上!所有用户goroutine的栈都在堆上分配,包括main的主goroutine
直到main方法结束,exit(0) 是粗暴的进程终止,操作系统回收所有资源。
3.5 sysmon
sysmon 不是 m 结构体的字段,而是一个运行在专用M上的goroutine函数。这个M不绑定P,专门执行系统监控任务。运行时不需要在 m 中标记 sysmon,因为它是通过启动专用m来运行的独立监控实体。专用m,也不参与p的绑定
- 不参与普通调度
- 可以看见所有P的状态
- 不会被系统调用阻塞影响
四. 动态的调度流程
核心的部分,追溯gmp模型的调用链路
4.1 两种g的转换
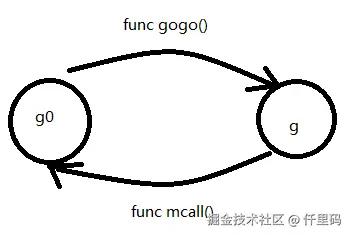
前面3.2中,对m的结构定义学习时,m中不止有g0的指针,也有curg的指针,很明显curg指向的就是当前正在被m处理的g
一个完整的goroutine的调用链路,其实就是会有一个从g0到g,g再回归g0的这样的一个闭环,而在这个过程中会有一组对偶的函数,分别是func gogo()和func mcall()
接口被定义在runtime包的stubs.go中
4.2 几种调度类型
源码在proc.go文件中,以下方法也都是用户g来调用
4.2.1 主动调度
这里的主动,是指用户的主动,也就是用户在代码中使用runtime包对外暴露的Gosched方法,使当前的g出让执行权,主动进入全局队列 等待下次被调度,调用它的 g 变为 _Grunnable 状态
go
// Gosched yields the processor, allowing other goroutines to run. It does not
// suspend the current goroutine, so execution resumes automatically.
//
//go:nosplit
func Gosched() {
checkTimeouts() // 检查是否有超时的timer
mcall(gosched_m)
}意思就是,Gosched会让出处理器,允许其他协程运行。它不会挂起当前的协程,因此执行会自动恢复。
值得注意的是这里的checkTimeouts(),这是go14引入的安全机制,因为 mcall 切换到 g 后,g 执行调度逻辑也需要时间!如果一直 mcall,g0 会一直占用CPU,没机会调度timer goroutine。
4.2.2 被动调度
这个就不是用户主动的让g出让执行权了,而是 g 本身遇到了没有必要继续占用 m 的情况
1) _Gsyscall
entersyscall(),这个方法会让当前运行的g进入_Gsyscall:
- m会保存g当前的信息(g.sched)
- m会带着g进入内核态去执行
- 并记录此时的p到m.oldp
- 此时p就会和m解绑,去寻找其他的m(如果有的话)
- g就会留在_Gsyscall,直到内核态结束,调用exitsyscall()
exitsyscall(), 这个方法,如果原来的 P 还空闲(没有绑定新的m),就可以直接恢复运行态,否则就是进入就绪态等待新的调度
2) _Gwaiting
gopark(),这个方法在g遇到阻塞时就会调用,目的是为了让g进入_Gwaiting,例如channer、select和同步锁等情况,和前者不同的是,m立即执行其他g ,与P保持绑定,此时的g进入的是一个等待队列,直到有"唤醒者"执行goready(*g),被唤醒的g会优先放入唤醒者的p的本地队列,这样才可能更快被m执行
这是为了利用CPU缓存局部性,当前CPU核心的缓存很可能已经有这个P的数据,如果放到其他P的队列,需要同步缓存,开销大,减少调度延迟,提高性能。
如果正好遇到唤醒者本地队列满的情况,则会调用runqputslow():
- 移动128个G到全局队列
- 把新G(被唤醒者)放入本地队列空位
- 本地队列现在有 256-128+1 = 129个G
这是为了避免频繁操作全局队列,如果每次满都只放一个G到全局,频繁加锁 → 性能差
总之被唤醒的g只能是回到_Grunable。
而值得注意得是,执行goready的g自己并不会进入_Gwaiting,因为这样设计可以避免死锁。举个例子:
go
ch := make(chan int) // 无缓冲
// G1: 接收者(先启动)
go func() {
val := <-ch // 阻塞!gopark()到_Gwaiting,并将G1自己的信息带给ch.recvq,因为期待ch接收数据时唤醒自己
fmt.Println("收到:", val)
}()
// G2: 唤醒者(后启动)
go func() {
time.Sleep(time.Second)
ch <- 42 // 1. 发现ch.recvq有等待的G1
// 2. 调用 goready(G1) 唤醒G1
// 3. 唤醒者继续执行下一行代码!
fmt.Println("发送完成") // ← 立即执行,不会阻塞!
}()如果 goready(G1) 会阻塞,那么 fmt.Println("发送完成") 就永远不会执行,形成死锁!
3) 抢占调度
抢占调度 = 强制打断正在运行的Goroutine,不让它霸占CPU太久。
Go 1.14+:基于异步信号的抢占,任何地方都可能被中断!才是真正的抢占
抢占如何工作?
- 标记阶段(sysmon负责)
go
func retake(now int64) {
for 每个P {
if pp.status == _Prunning {
// G运行超过10ms?
if now-pp.schedtick > 10*1000*1000 {
preemptone(pp) // 标记这个P上的G应该被抢占
}
}
}
}
func preemptone(pp *p) bool {
gp := pp.curg
if gp == nil || gp == pp.g0 {
return false
}
gp.preempt = true // ← 设置抢占标志
// 告诉G:"你该让出了!"
gp.stackguard0 = stackPreempt
return true
}- 执行阶段(G自己检查或信号中断)
异步信号(Go 1.14+)
scss
// 操作系统信号(如SIGURG)中断G
// 在信号处理程序中切换到调度器
func sighandler(sig int32) {
if sig == sigPreempt {
// 被抢占!
doasyncPreempt() // 切换到调度去找下一个g
}
}抢占完整链路
makefile
时间线(详细版):
t0: G1在CPU上执行
↓
t1: sysmon调用 signalM(M1, SIGURG)
↓
t2: 内核向CPU发送中断信号
↓
t3: CPU中断当前指令,保存寄存器
↓
t4: 跳转到内核信号处理代码(C)
↓
t5: 内核调用Go注册的sigtramp(汇编)
↓
t6: sigtramp保存完整上下文,调用sighandler(Go)
↓
t7: sighandler识别是抢占信号,调用doasyncPreempt
↓
t8: doasyncPreempt调用mcall()切换到g0
↓
t9: g0执行调度,选G2抢占的局限:即使有抢占,Go仍不是完全实时的
arduino
// 这些情况可能延迟抢占:
1. G在执行不可抢占的系统调用
2. G在修改运行时关键数据结构(持锁)
3. 信号被阻塞或延迟传递
// 所以Go文档说:
// "Goroutines没有超时概念"
// 不能依赖抢占做超时控制正确的超时控制方式:
错误控制
scss
go func() {
doWork() // 可能运行很久
// 期望1秒超时?不保证!
}()正确控制
go
// 方法1:context.WithTimeout
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
go func() {
select { // goroutine启动,监听两个channel
case <-ctx.Done(): // 1秒后ctx.Done()可读
return
case result := <-doWorkAsync(): // 如果doWorkAsync()先返回结果
// 正常完成
}
}()
// 方法2:带超时的channel操作
select {
case result := <-ch:
// 正常
case <-time.After(1 * time.Second):
// 超时
}
// 方法3:定期检查退出标志
stop := make(chan bool)
go func() {
for {
select {
case <-stop:
return
default:
doChunkOfWork() // doChunkOfWork() 执行后立即再次检查stop
}
}
}()
time.Sleep(1 * time.Second)
close(stop) // 请求停止
// 关闭channel的效果:
// 1. 所有从这个channel接收的操作立即返回零值
// 2. 不再阻塞
// 3. 可以通知多个接收者五. work-stealing
Work-Stealing是Go调度器的负载均衡算法:空闲的P从忙碌的P的本地队列偷一半Goroutine过来执行,实现自动负载均衡,减少空闲,提高CPU利用率。
5.1 工作原理:
1) 什么时候发生?
go
func findRunnable() {
// 当P自己的队列为空时...
if 自己队列空 && 全局队列空 {
// 尝试从其他P偷工作
gp := runqsteal(pp)
if gp != nil {
return gp // 偷到工作了!
}
}
}2) 怎么偷?
go
func runqsteal(pp *p) *g {
// 1. 随机选一个其他P
victim := 随机选择一个P
// 2. 偷它本地队列**一半**的G
// 比如:victim有10个G,偷5个过来
half := victim队列长度 / 2
// 3. 把偷来的G放到自己队列
for i := 0; i < half; i++ {
g := victim.pop() // 从victim队列取
pp.push(g) // 放到自己队列
}
}5.2 为什么需要Work-Stealing?
makefile
// P3、P4从P1、P2偷工作
P1: 10 → 5个G (被偷走5个)
P2: 10 → 5个G (被偷走5个)
P3: 0 → 5个G (偷了P1的5个)
P4: 0 → 5个G (偷了P2的5个)
// 现在4个P都有5个G,负载均衡!5.3 Work-Stealing的优势:
1) 减少锁竞争
arduino
// 每个P操作自己的队列(无锁)
// 只有偷窃时才需要锁其他P的队列
// 大部分时间无竞争2) 利用局部性
arduino
// G通常在自己的P上执行
// 只有P空闲时才去偷
// 保持CPU缓存热度3) 自适应的负载均衡
less
/ 忙的P不会被过度干扰
// 闲的P自动找活干
// 无需中央调度器六. p到底干了什么?
P其实不调用任何方法,它只是个被操作的"资源包"。P什么也不干,只是被g/g0读写的数据结构。
P就像"工作台":工作台不会自己干活,工人(g)用工具(m)在工作台上干活
虽然P不调用方法,但它是关键的资源管理者 :P提供本地队列、缓存等资源,但所有操作都是G/g0在对P进行读写。这是Go调度器"G中心"设计哲学的体现。
既然,p这个结构体,只是一个被g和g0操作的数据结构,那为啥,都说processor是gmp中核心的调度器,明明它啥也没干?
6.1 说P是"核心调度器"是从架构和性能角度说的
- 并行度控制中心
go
// 系统能同时运行多少个G?由P的数量决定!
GOMAXPROCS = 4 // ← 创建4个P
// 最多4个G真正并行执行
// P是并行度的"闸门"- 本地化调度中心
go
// 没有P:所有m竞争一个全局队列 → 锁竞争严重
// 有P:每个P有本地队列 → 减少90%锁竞争
// 调度性能提升10倍+的关键!- CPU亲和性锚点
go
M是流动的(线程可能被OS调度到不同CPU核心)
P是固定的(每个P尽量绑定到固定CPU核心)
G → 绑定到 → P → 亲和到 → CPU核心
(调度关系) (缓存优化)- 工作窃取(Work Stealing)的枢纽
css
// 当P1空闲时,它偷谁的工作?
// 偷其他P的队列!P是窃取的单位
func stealWork(pp *p) {
// 遍历其他P,偷它们的G
for 每个其他P {
从其他P.runq偷一半G
}
}6.2 P的"被动核心"设计哲学
Go调度器的创新:
传统线程池: Worker(主动) + Queue(被动)
Go的GMP: G(主动) + P(被动+智能) + M(执行)
P的"智能被动":
- 本地队列(256) ← 智能缓冲:减少竞争
- runnext槽位 ← 智能缓存:下一个立即执行
- 各种内存池 ← 智能复用:减少分配
- 状态机管理 ← P.status: _Pidle, _Prunning, _Psyscall, _Pdead,通过状态知道P在干嘛
没有P(Go 1.0之前) :Benchmark调度-4核: 100万次切换/秒
有P(Go 1.1引入P后):Benchmark调度-4核: 5000万次切换/秒 提升50倍!
6.3 调度器真正的工作流
vbnet
真正的"调度大脑"是:g0 + P的数据
g0(决策) + P(数据) = 完整调度器
↓ ↓
"做什么" "用什么做"
比如:
g0: "该执行下一个G了"
↓
g0: 查看当前P.runq(数据在P中)
↓
g0: 取出G(操作P的字段)
↓
g0: 执行GP提供了调度需要的所有数据,g0提供决策逻辑
6.4 所以,不应该说"P是核心调度器"
更准确的说法:
- g0 :调度器的逻辑核心(做决策)
- P :调度器的数据核心(提供资源)
- M :调度器的执行核心(跑代码)
- G :调度器的任务核心(要执行的工作)
6.5 源码中的体现
在runtime包的proc.go文件中:
go
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
mp := getg().m
if mp.locks != 0 {
throw("schedule: holding locks")
}
if mp.lockedg != 0 {
stoplockedm()
execute(mp.lockedg.ptr(), false) // Never returns.
}
if mp.incgo {
throw("schedule: in cgo")
}
top:
pp := mp.p.ptr()
pp.preempt = false
if mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
throw("schedule: spinning with local work")
}
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
if debug.dontfreezetheworld > 0 && freezing.Load() {
lock(&deadlock)
lock(&deadlock)
}
if mp.spinning {
resetspinning()
}
if sched.disable.user && !schedEnabled(gp) {
lock(&sched.lock)
if schedEnabled(gp) {
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
if tryWakeP {
wakep()
}
if gp.lockedm != 0 {
startlockedm(gp)
goto top
}
execute(gp, inheritTime)
}整个调度循环都围绕着"当前P"的数据操作!
这个方法是g0调用,在go run之后,就开始循环,其中的getg()就是取得g0本身
具体到代码中的循环路径:
- 普通调度循环
scss
func schedule() {
gp := findRunnable() // 1. 找个可运行的G
execute(gp, inheritTime) // 2. 执行它(永不返回!)
}
func execute(gp *g, inheritTime bool) {
// M设置当前G
_g_.m.curg = gp // M ← G
gp.m = _g_.m // G ← M g.m和m.gcurg的赋值是在execute中完成的
// M开始执行G的代码
gogo(&gp.sched) // 3. 切换到用户G(不返回!)事实上gogo只负责数据恢复
}
// 用户G执行...
// 用户G调用 runtime.Gosched() 或阻塞时:
func gosched_m(gp *g) {
// 4. 用户G通过mcall()切换到g0执行这个函数
schedule() // 5. 重新调度!回到步骤1
}这里execute() 调用 gogo() 后不返回 !所以 schedule() 也不返回!
findRunnable() 是调度器的"找活干"函数,它按优先级从多个地方寻找可运行的G:
markdown
findRunnable() 的查找顺序:
1. 当前P的runnext(最高优先级)
2. 当前P的本地队列
3. 全局队列
4. 网络轮询器(netpoll)
5. 从其他P偷工作(work stealing)
6. 如果还找不到 → 休眠等待- 两种 goto top 的情况
情况1:G被锁定到特定的M(gp.lockedm != 0)
scss
if gp.lockedm != 0 {
// 这个G必须运行在特定的M上
// 比如:cgo回调、某些系统调用
startlockedm(gp) // 把P交给那个M,自己阻塞
goto top // 重新找其他G执行
}情况2:用户调度被禁用(sched.disable.user)
scss
if sched.disable.user && !schedEnabled(gp) {
// 用户G调度被临时禁用(比如在STW垃圾回收)
// 但GC worker等系统G可以运行
sched.disable.runnable.pushBack(gp) // 放回特殊队列
goto top // 跳过这个用户G,重新找
}