产品概述
IPIDEA是业界领先的企业级代理网络服务平台,专注为全球开发者和企业用户提供高质量、高稳定性的代理IP解决方案。作为新一代智能代理服务提供商,IPIDEA凭借其遍布全球的优质IP资源池、先进的负载均衡技术和完善的API生态系统,已成为数据采集、网络爬虫、隐私保护、业务拓展等领域的首选技术伙伴。 核心功能: 企业级代理网络服务、智能抓取解决方案、专业数据集服务、全方位开发者支持
多语言生态支持
IPIDEA构建了完整的多语言开发生态,为不同技术栈的开发者提供原生级别的接入体验:
主流编程语言支持,如果你偏向做传统的企业级应用或者大数据处理这一类,Java 还是很合适的选择。像 Spring Boot 这种框架已经非常成熟,不管是用 Maven 还是 Gradle 来管理依赖,都有一整套完善的生态支撑。在高并发场景下,只要设计得当,Java 的稳定性和可靠性是比较有保障的。
做前后端一体化或者各种实时应用,比如实时推送、聊天系统、在线协作之类的,很多团队会选 Node.js。它本身是异步非阻塞 I/O,加上 npm 生态非常丰富,要接各种第三方库都很方便。在需要扛大量并发连接、又希望内存占用控制得比较好的场景里,Node.js 也挺常见。
如果重点是微服务、云原生,或者对性能、资源利用比较敏感,Go 是一个很有竞争力的方案。它用协程来做并发,写法相对简单,又是编译型语言,性能不错,部署也不复杂------通常就是一个二进制文件丢到服务器上就能跑。 Web 开发这块,尤其是内容管理、企业官网、后台系统这一类,PHP 依然有很大的应用面。像 Laravel、Symfony 这种框架成熟好用,文档也多,上手快、开发效率高,而且部署方式也比较简单,很多现成的环境都支持。
如果是系统级开发或者需要极致性能的计算型应用,比如自己写网络服务、底层组件、引擎类东西,C/C++ 还是绕不开。可以直接使用底层网络库,控制内存和资源使用的细节,在性能和资源占用上都能压得比较低。
而在企业应用和桌面软件领域,C#/.NET 也是一个很稳的选择。现在有 .NET Core 之后,跨平台能力也比以前强了不少。C# 本身是强类型语言,配合 Visual Studio 这一类开发工具,调试、重构、代码分析都比较顺手,适合长期维护的大型项目。
灵活接入模式
如果你有那种需要经常更替IP、并发量又很高的场景,可以用 API 动态模式。通过 RESTful API 去实时获取代理 IP,每次要发请求前拉一个新 IP,特别适合频繁切 IP 的任务。
在大规模数据采集这种场景下,一般都是成千上万的请求一起跑,如果一直用同一个 IP,很容易被目标网站防护上,所以就需要不停地轮转IP,把被停用风险压到最低。
如果是高频抓取要抓很多页面、很多站点,而且请求间隔又短,那几乎离不开频繁更替IP,不然很快就会被识别出来。
做不同地区的业务测试时,也会用到这种代理方案,比如要模拟"我在上海""我在美国""我在欧洲"分别访问同一个服务,看响应有没有差异。
还有一种,就是那种高并发的接口调用场景,一下子要打出去大量请求,这时候通常会接一个代理池,一边分摊压力,一边用不同 IP 去访问,整体就会更稳、更不容易触发限制。
使用案例
前面介绍这么多,为了让大家直观的看出产品的便捷性,下面通过模拟电商客户为了抓取亚马逊电子产品的数据作为案例看下如何使用IPIDEA通过代理IP抓取网页数据。
API模式示例
步骤一:注册和获取代理IP
在 IPIDEA 官网完成账号与套餐配置,再将接口接入到 Python 以获取全球代理 IP。建议流程如下:
1、注册与认证 点击访问 IPIDEA 官网,点击注册并填写信息完成账号创建。首次登录并完成实名认证后,官方会赠送 2G 测试流量;官网也提供免费试用,想先体验的同学可先试用后再购买(具体以官网最新政策为准)。 2、选择套餐 根据业务规模选择合适的代理服务套餐,可按代理 IP 数量、并发与使用时长等维度进行配置。 3、生成提取链接/API 在控制台创建/生成提取链接或获取 API Key/Token,并按需设置地区、协议、会话保持等参数。 4、接入Python 将提取链接或 API 接入到 Python 脚本中,按需拉取全球各地区的代理 IP,用于后续的数据采集任务。 5、参考示例截图
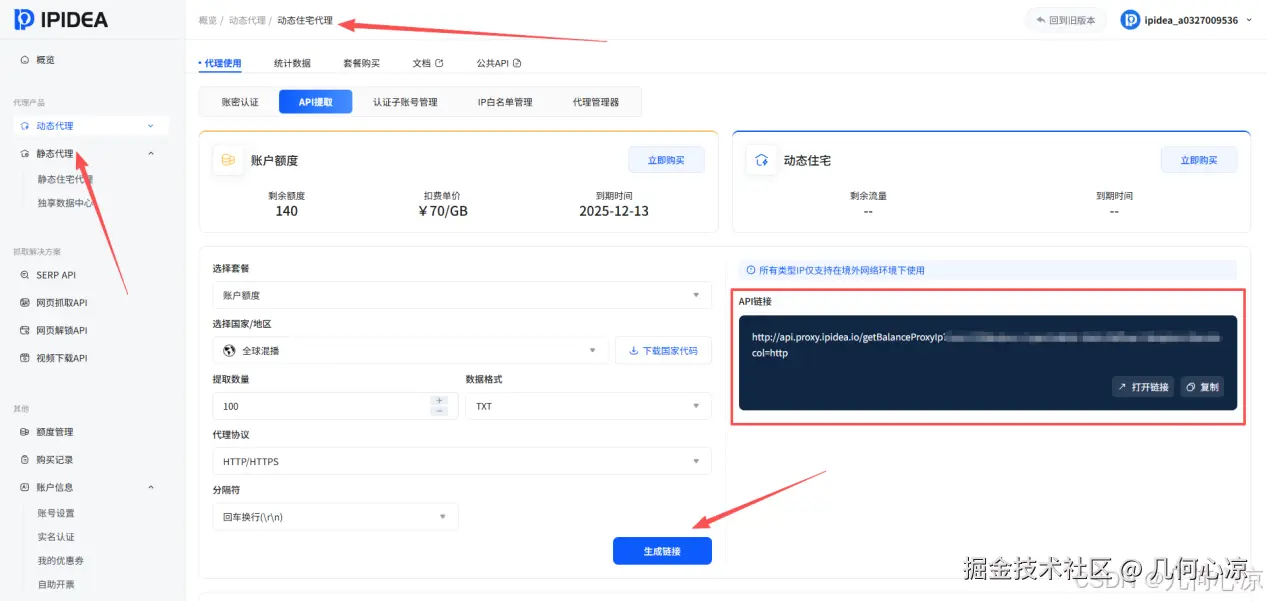
步骤二:查看官方的操作文档
官方的文档中有动态IP代理和静态IP代理的操作手册和步骤,我们可以根据官网的操作手册来完成我们接下来结合python的使用动态代理IP来采集电商行业的数据。

步骤三:编写数据采集python脚本代码
从事电商的开发者每次提起同行的数据第一个想到的就是境外电商巨头亚马逊,我们本次的目标也不例外,主要是来爬虫亚马逊的电子商品一类的数据,同时将爬取的数据吸入到表格中用于日后的数据清洗和数据分析。
python
import requests
from bs4 import BeautifulSoup
import csv
import time
from random import randint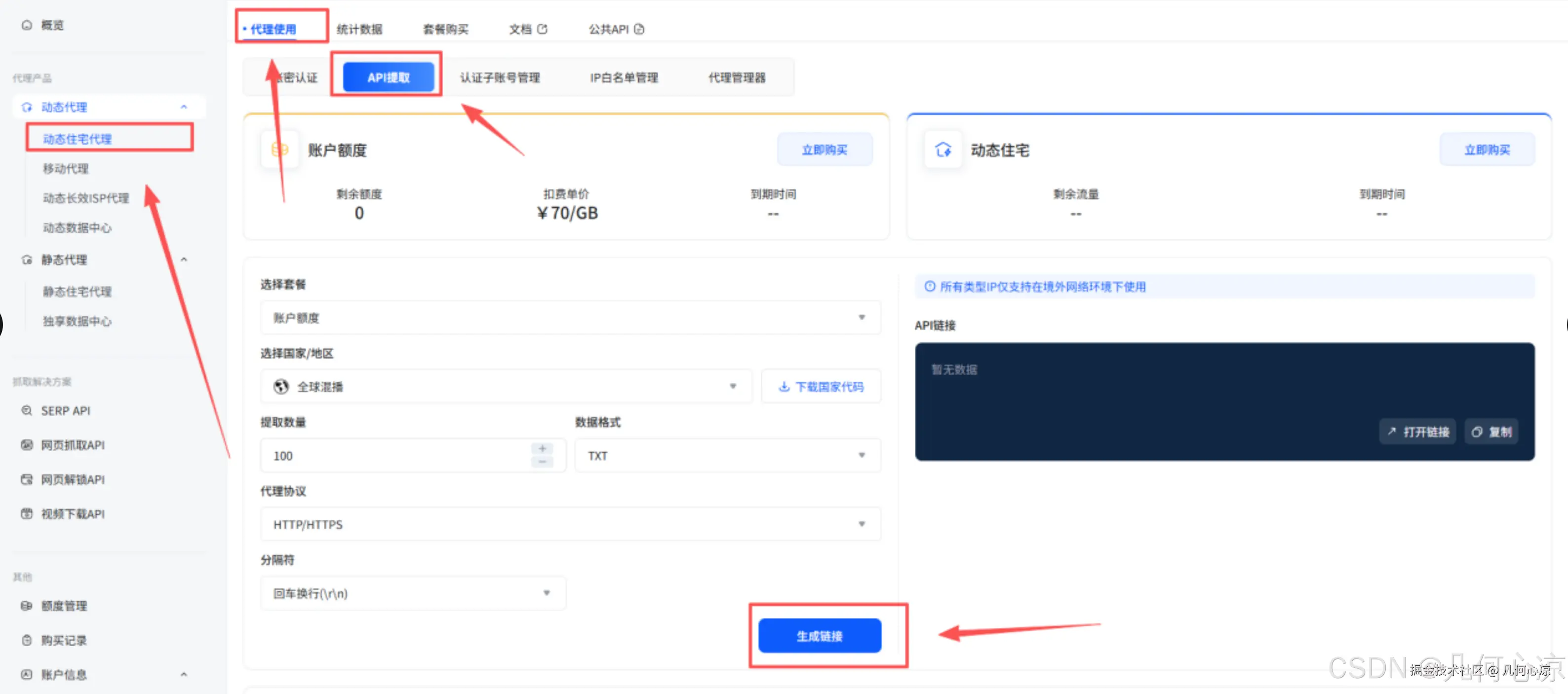
我们在IPIDEA的官网中找到我们需要的API链接,并且生成之后我们需要将这些链接用到我们的代码中。
python
# 获取代理IP列表
def get_proxies():
proxies = []
for _ in range(5): # 获取5个代理IP
response = requests.get('http://api.proxy.ipidea.io/getBalanceProxyIp?num=1&return_type=txt&lb=1&sb=0&flow=1®ions=&protocol=http')
proxies.append(response.text.strip())
return proxies
# 轮换代理IP
def rotate_proxy(proxies):
return {'http': proxies[randint(0, len(proxies)-1)]}
我们找到亚马逊的官网,并且开始使用代理IP来爬取我们想要的商品数据。
python
# 数据采集函数
def fetch_data(url, proxies):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'DNT': '1'
}
for attempt in range(5): # 重试5次
proxy = rotate_proxy(proxies)
try:
response = requests.get(url, headers=headers, proxies=proxy, timeout=10)
response.raise_for_status() # 检查请求是否成功
return response.text
except requests.exceptions.RequestException as e:
print(f'请求失败(第{attempt+1}次尝试),错误: {e}')
time.sleep(randint(5, 10)) # 随机等待5到10秒后重试
# 设置代理IP
print("正在获取代理IP...")
proxies = get_proxies()
print(f"获取到 {len(proxies)} 个代理IP")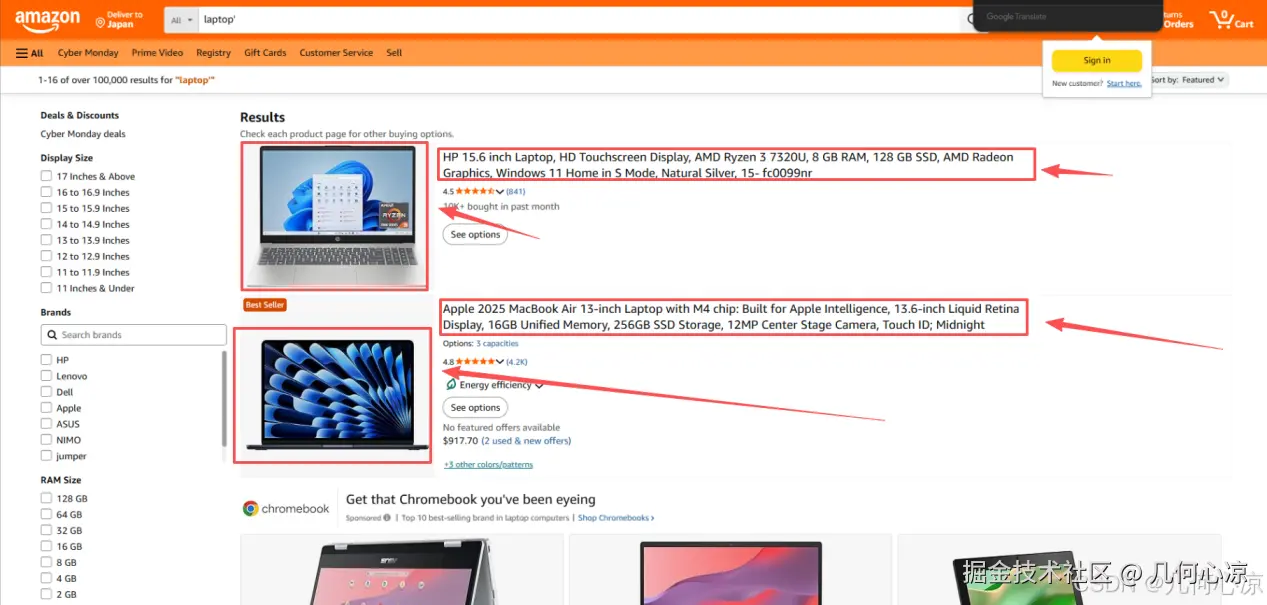
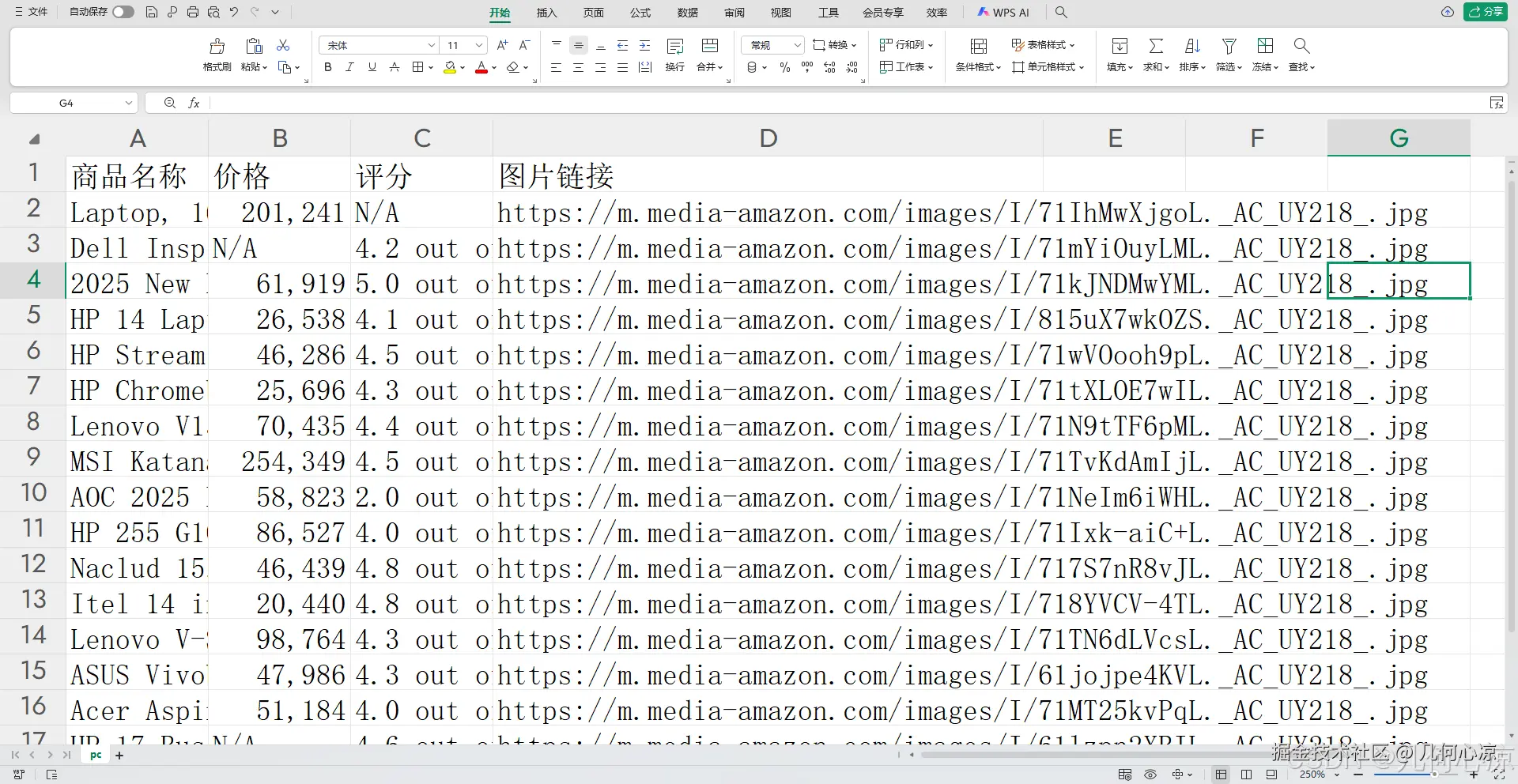
这是我们需要爬取的目标网站,亚马逊有反反爬虫机制,所以我们需要使用IP代理的轮换的方式来爬取目标页面的内容数据。
python
# 目标URL
url = 'https://www.amazon.com/s?k=laptop'
print(f"开始访问URL: {url}")
response_text = fetch_data(url, proxies)
python
if response_text:
print("成功获取页面内容")
soup = BeautifulSoup(response_text, 'html.parser')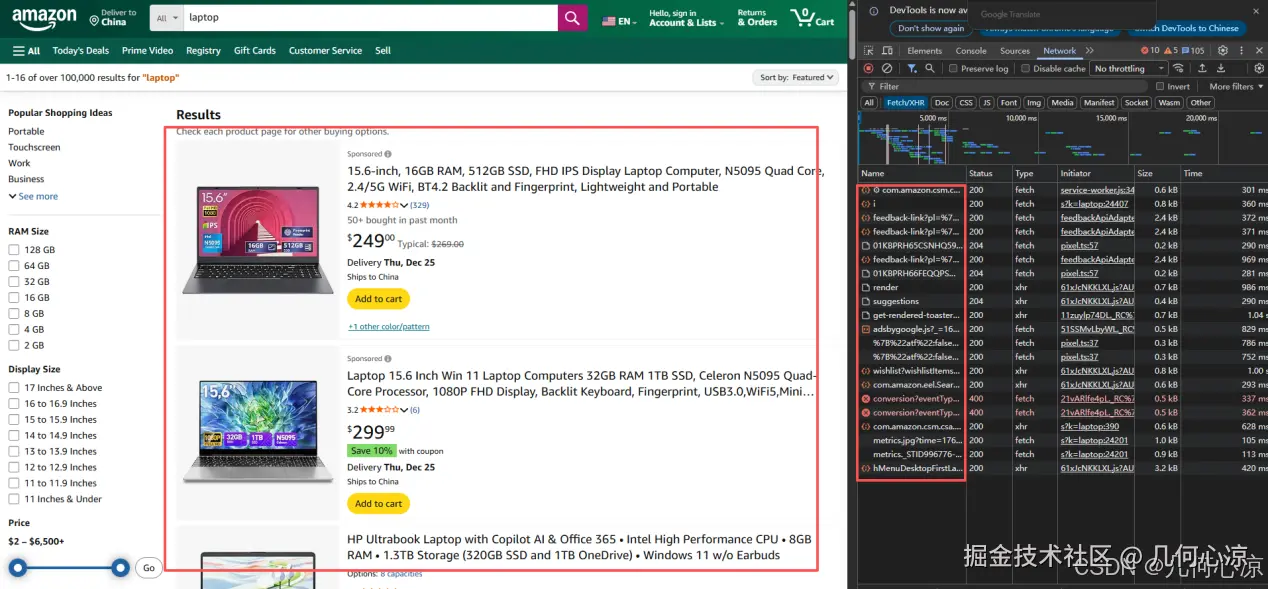
python
# 提取商品信息
products = soup.find_all('div', {'data-component-type': 's-search-result'})
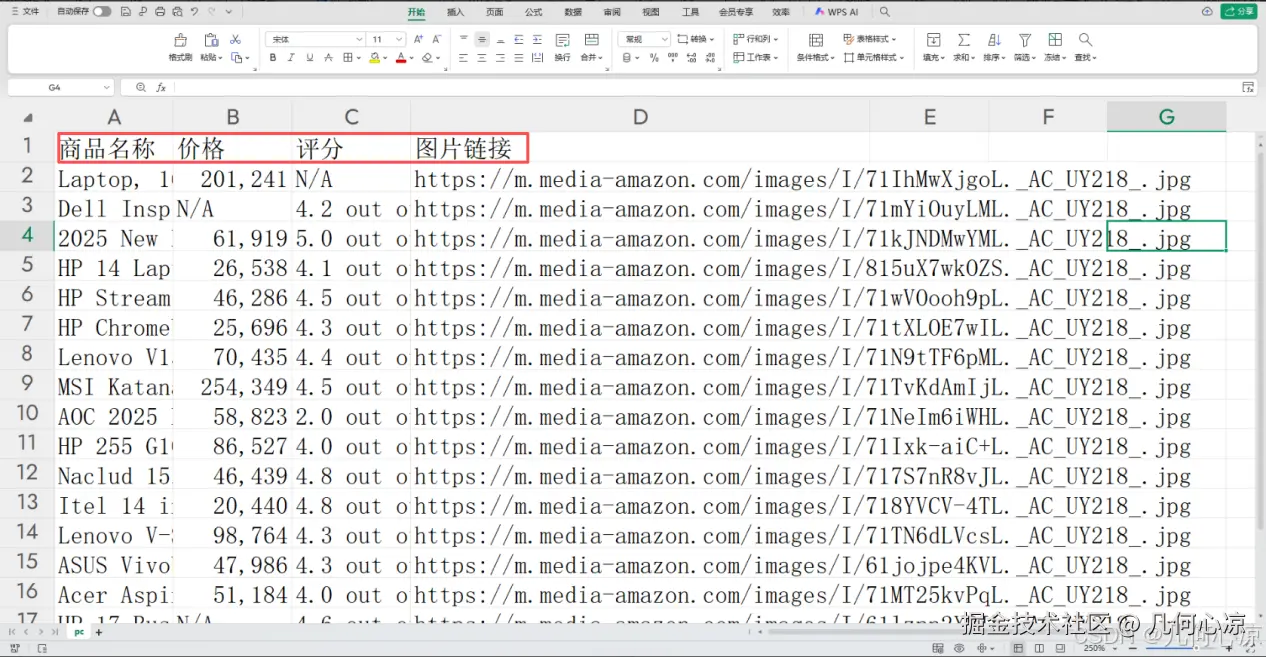
print(f"找到 {len(products)} 个商品")数据表格部分,我们需要将数据表格的代码撷取整个程序中,我们使用代码爬取数据成功之后,需要将数据存入到表格中进行显示存储。
python
# 打开 CSV 文件进行写入
with open('pc.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['商品名称', '价格', '评分', '配送信息', '商品链接', '图片链接', '是否Prime'])
data_count = 0
for i, product in enumerate(products):
# 尝试多种商品名称选择器
name = (product.find('span', class_='a-size-medium a-color-base a-text-normal') or
product.find('span', class_='a-size-base-plus a-color-base a-text-normal') or
product.find('h2', class_='a-size-mini') or
product.find('h2').find('span') if product.find('h2') else None)
# 尝试多种价格选择器
price = (product.find('span', class_='a-price-whole') or
product.find('span', class_='a-price-range'))
# 尝试多种评分选择器
rating = (product.find('span', class_='a-icon-alt') or
product.find('span', {'aria-label': True}))
# 获取图片链接
img_element = product.find('img', class_='s-image')
img_link = img_element['src'] if img_element and img_element.get('src') else "N/A"
print(f"商品 {i+1}: 名称={'找到' if name else '未找到'}, 价格={'找到' if price else '未找到'}, 评分={'找到' if rating else '未找到'}")
# 只要有名称就写入,其他字段可以为空
if name:
name_text = name.text.strip() if name else "N/A"
price_text = price.text.strip() if price else "N/A"
rating_text = rating.text.strip() if rating else "N/A"
delivery_text = delivery.text.strip() if delivery else "N/A"
writer.writerow([name_text, price_text, rating_text, delivery_text, product_link, img_link, is_prime])
data_count += 1
print(f"成功写入 {data_count} 条商品数据")
else:
print('数据采集失败')动态境外IP代理脚本代码爬取成功
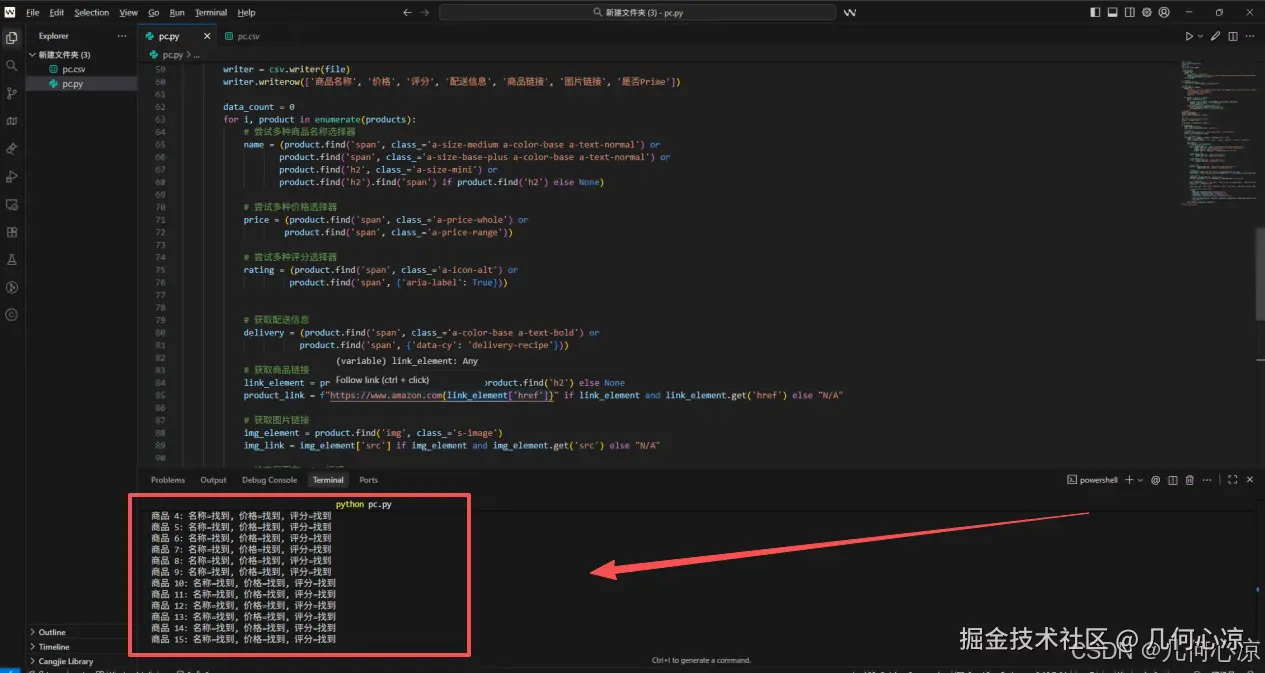
数据存储表格部分
python
if name:
name_text = name.text.strip() if name else "N/A"
price_text = price.text.strip() if price else "N/A"
rating_text = rating.text.strip() if rating else "N/A"
delivery_text = delivery.text.strip() if delivery else "N/A"
writer.writerow([name_text, price_text, rating_text, delivery_text, product_link, img_link, is_prime])
data_count += 1请求头以及报错打印
python
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'DNT': '1'
}
for attempt in range(5): # 重试5次
proxy = rotate_proxy(proxies)
try:
response = requests.get(url, headers=headers, proxies=proxy, timeout=10)
response.raise_for_status() # 检查请求是否成功
return response.text
except requests.exceptions.RequestException as e:
print(f'请求失败(第{attempt+1}次尝试),错误: {e}')
time.sleep(randint(5, 10)) # 随机等待5到10秒后重试爬取数据以及数据处理
python
for i, product in enumerate(products):
# 尝试多种商品名称选择器
name = (product.find('span', class_='a-size-medium a-color-base a-text-normal') or
product.find('span', class_='a-size-base-plus a-color-base a-text-normal') or
product.find('h2', class_='a-size-mini') or
product.find('h2').find('span') if product.find('h2') else None) 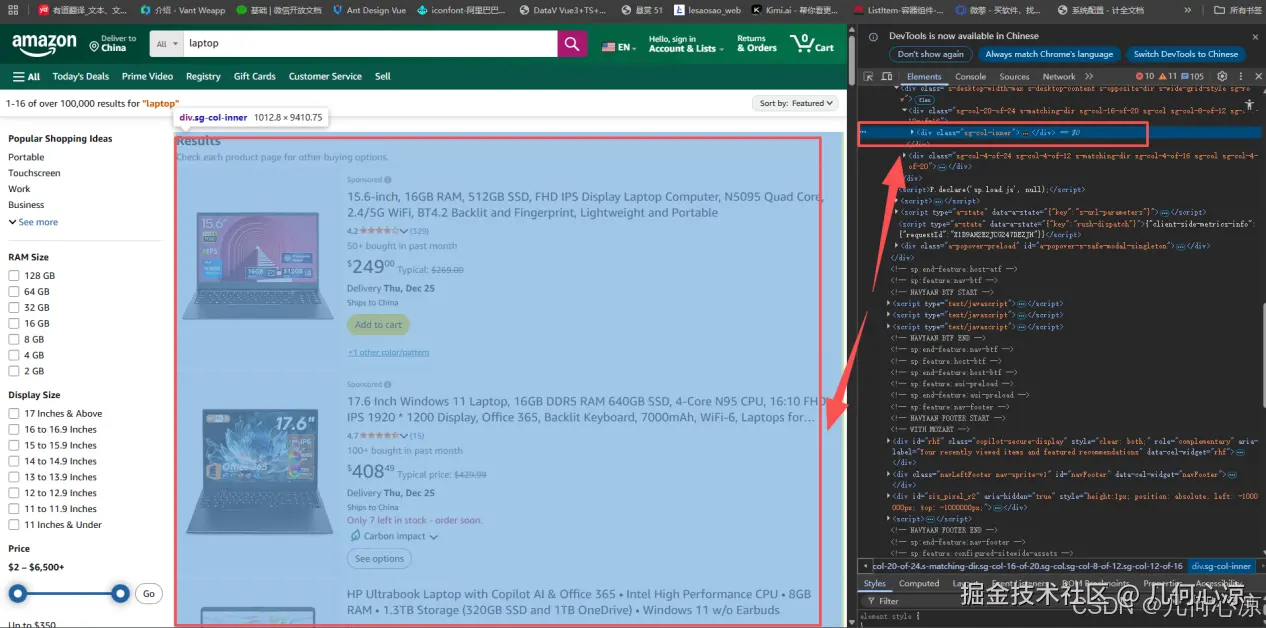
python
# 获取商品链接
link_element = product.find('h2').find('a') if product.find('h2') else None
product_link = f"https://www.amazon.com{link_element['href']}" if link_element and link_element.get('href') else "N/A"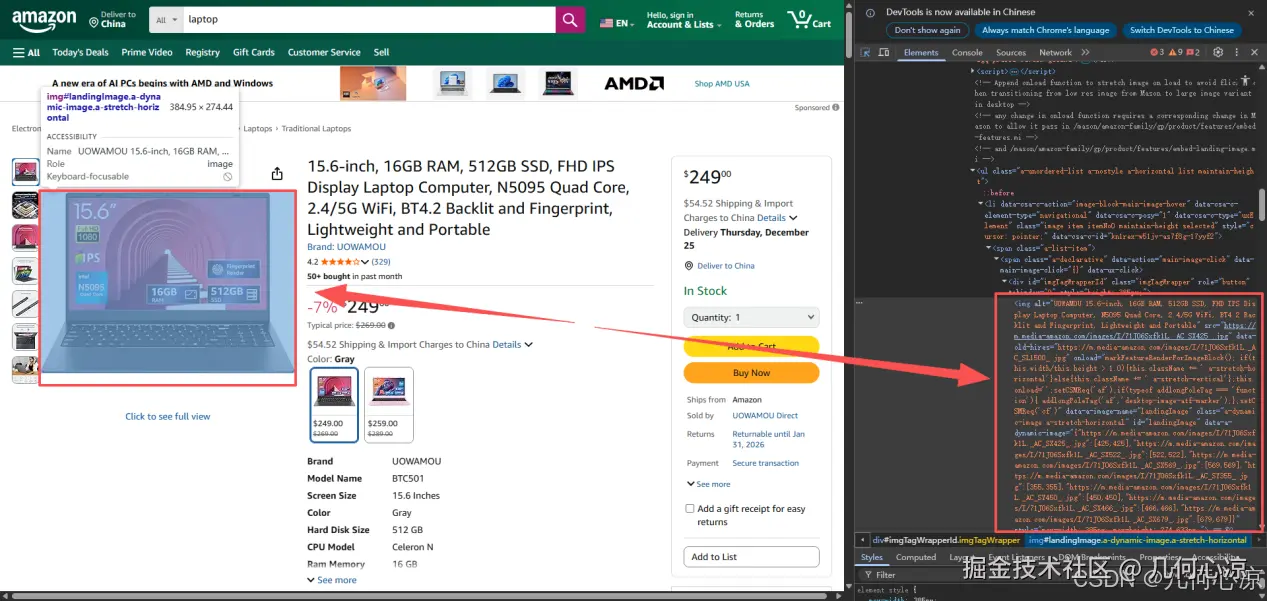
python
# 获取图片链接
img_element = product.find('img', class_='s-image')
img_link = img_element['src'] if img_element and img_element.get('src') else "N/A"
print(f"商品 {i+1}: 名称={'找到' if name else '未找到'}, 价格={'找到' if price else '未找到'}, 评分={'找到' if rating else '未找到'}")以上就是利用 IPIDEA 进行数据采集的一个完整示例。通过这种方式,我们可以轻松地从任意平台获取数据,特别适用于跨境电商相关的应用。无论是用于市场分析还是优化产品策略,都能大大提高工作效率。
当然我们也可以用官网提供的案例来熟悉具体的操作步骤,包含了常用的 C/C++语言、GO语言、Node.js语言、Php语言、JAVA语言、Python 语言以及 python-selenium 语言。
核心应用场景
IPIDEA代理服务广泛应用于各行各业,为不同领域的数字化需求提供强有力的技术支撑:
智能网络抓取
智能网络抓取在电商场景里挺常见的。比如说,你想批量把商品的信息都抓下来,不只是标题和价格,还包括库存、评价这些细节,它都可以自动帮你跑一遍。 如果你需要盯着竞品,看竞争对手最近上了什么新产品、价格怎么调的,也可以用抓取做成一个持续监控的系统,随时掌握他们的动向。
价格监控与商业智能
在电商这块,如果你想做动态定价,其实离不开对市场数据的持续监控。比如各种促销活动、满减、秒杀、优惠券之类的信息,系统可以自动帮你识别和跟踪,不用你天天盯着页面看。把这些历史价格和活动数据积累起来之后,就可以大致看出价格的变化规律,帮你判断什么时候进货更划算,什么时候不适合抄底。
写在最后
技术规格与性能指标
核心能力主要集中在几个组件上:调度这块有一个智能调度引擎,会用机器学习相关的算法来决定怎么分配 IP,尽量保证质量和成功率;监控这块是一个实时监控系统,可以做到毫秒级去检测 IP 质量,一旦发现某个节点或者某段 IP 状态不好,就能自动做故障切换;前端的流量入口由负载均衡器来承担,支持多种策略,比如按权重、按连接数、按响应时间等自动把流量分发到不同节点;数据访问这块有一套 Redis 集群,用来做缓存,加速各种配置、令牌、状态类的数据访问,基本是毫秒级响应;日志方面则是用类似 ELK 这类技术栈来做日志采集、检索和分析,可以根据日志做实时告警和问题定位。
总结
在技术这块,我们比较核心的优势是调度做得比较"聪明"。IP 分配不是简单轮询或者随机,而是用了一套基于机器学习的算法来决定什么时候用哪一段 IP,尽量在稳定性、成功率和成本之间找到一个比较好的平衡。监控和故障切换也是重点,下游一旦有异常,系统可以在毫秒级做检测和切换,整体恢复速度会比行业里常见的方案更快一些。
IPIDEA致力于成为您数字化转型路上最可靠的技术伙伴。无论您的需求规模大小,我们都有合适的解决方案等待您的发现。有需要的伙伴可以来体验:点击直达官网