扫描网站结构的SEO元数据抓取方案

🌈你好呀!我是 是Yu欸 🚀 感谢你的陪伴与支持~ 欢迎添加文末好友 🌌 在所有感兴趣的领域扩展知识,不定期掉落福利资讯(*^▽^*)
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
扫描网站结构的SEO元数据抓取方案
#爬虫API #数据采集 #亮数据 #BrightData #效率工具 #科研 #大数据 #人工智能 #WebScraping #开发者 #数据分析
Bright Data 官方注册活动链接:注册点我,额外赠送30刀试用金
- 亮数据账户注册,代理创建
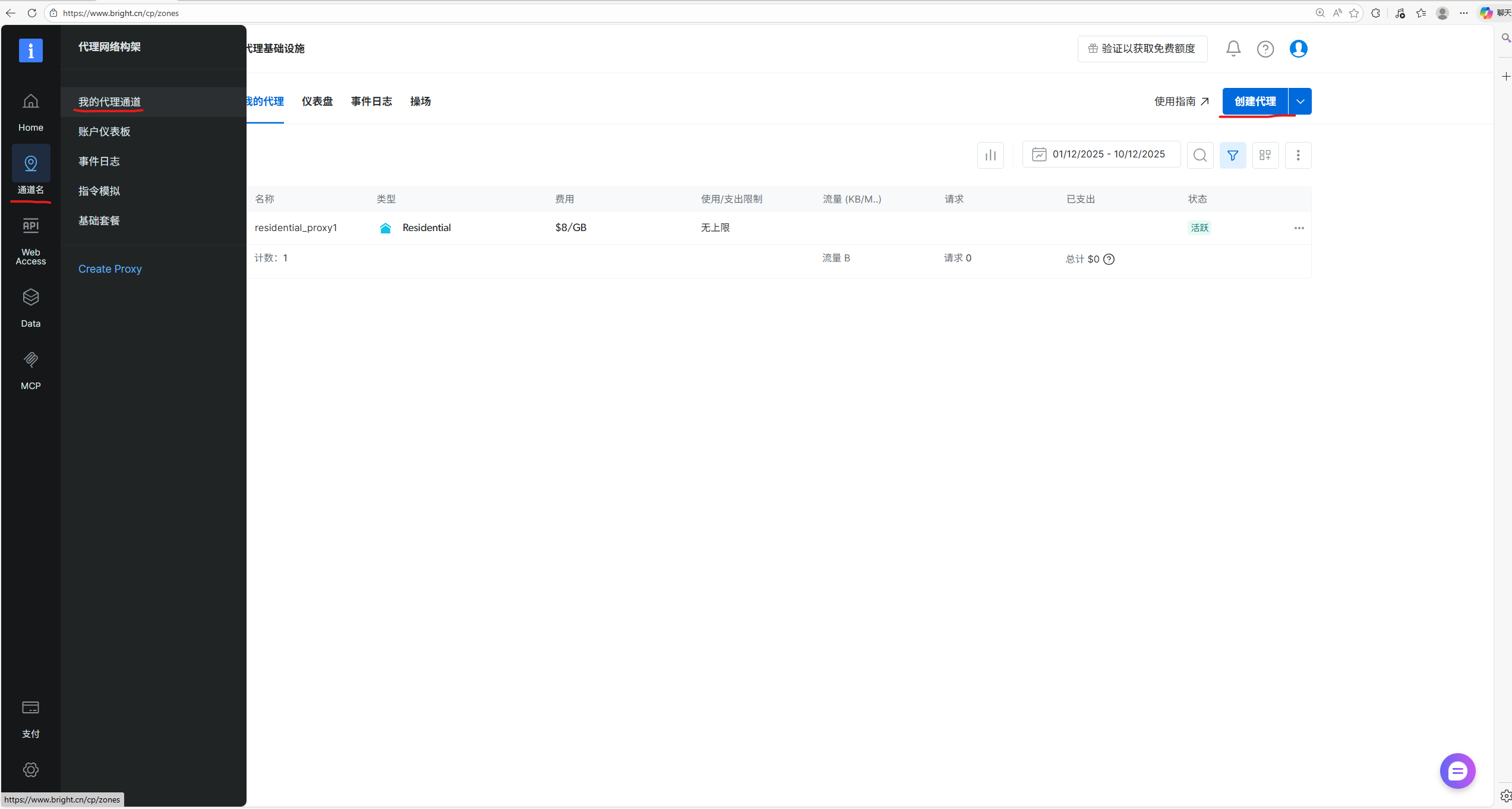
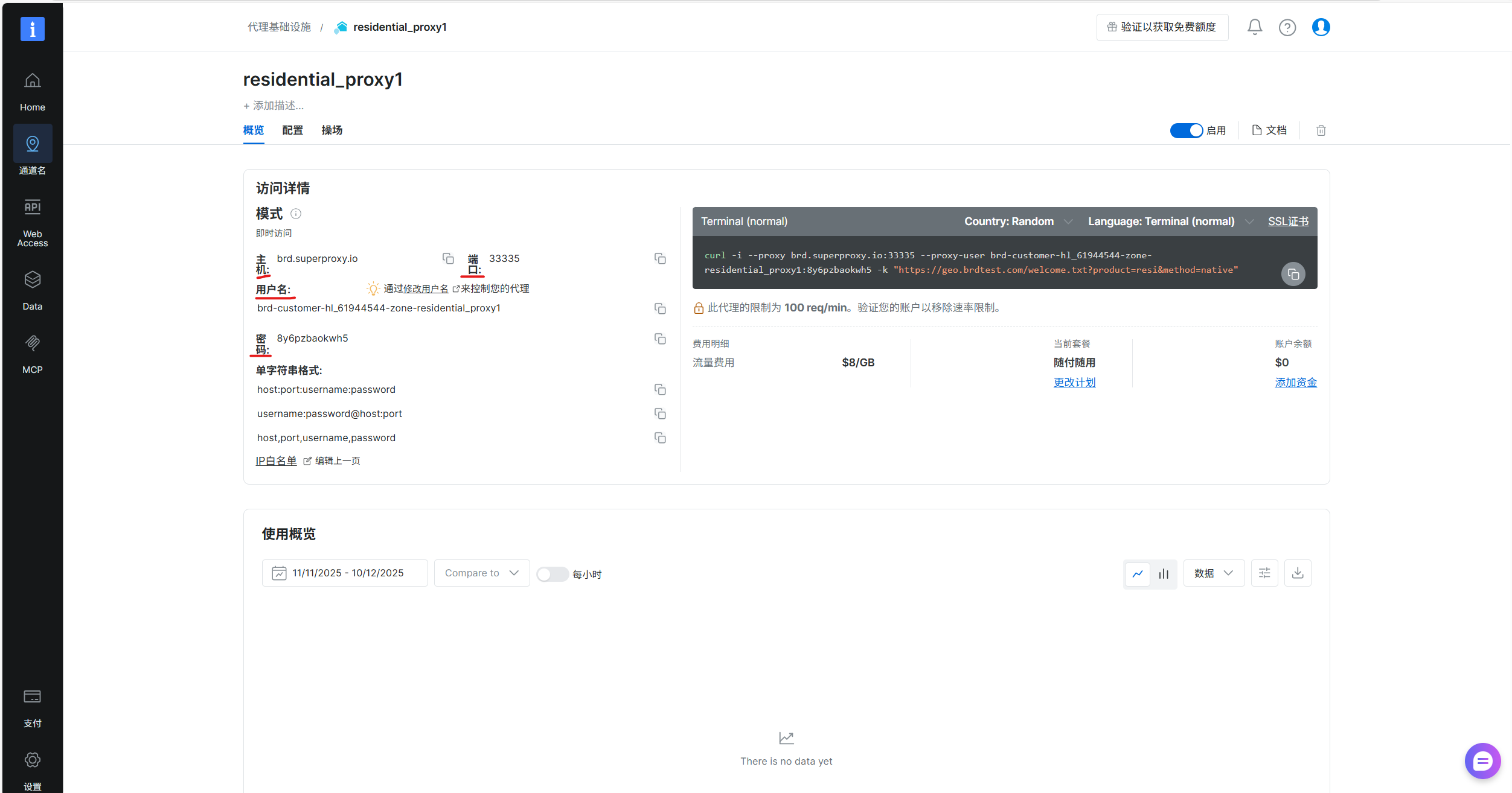
下图中的4个字段是后续尖叫蛙配置代理需要的
- 下载尖叫蛙:Screaming Frog SEO Spider Website Crawler
- 参考该链接 Screaming Frog代理集成 - 所有代理类型免费试用,将Screaming Frog与Bright Data代理集成。
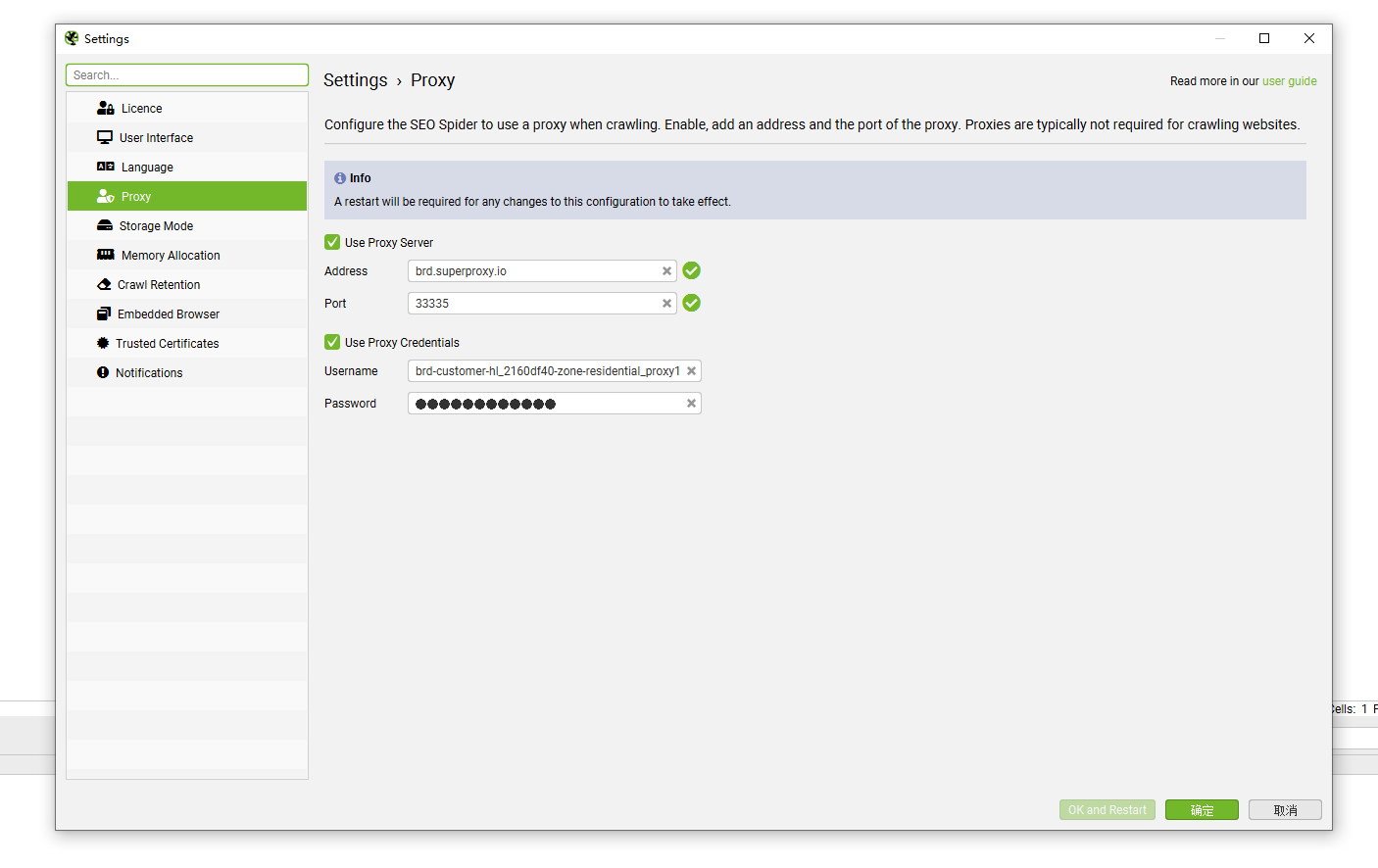
将在亮数据中创建的代理对应的字段填入,每次修改配置都需要重新启动
- 测试。输入URL,点击开始就可以抓取内容,这里是做简单测试,并没有获取具体的内容。
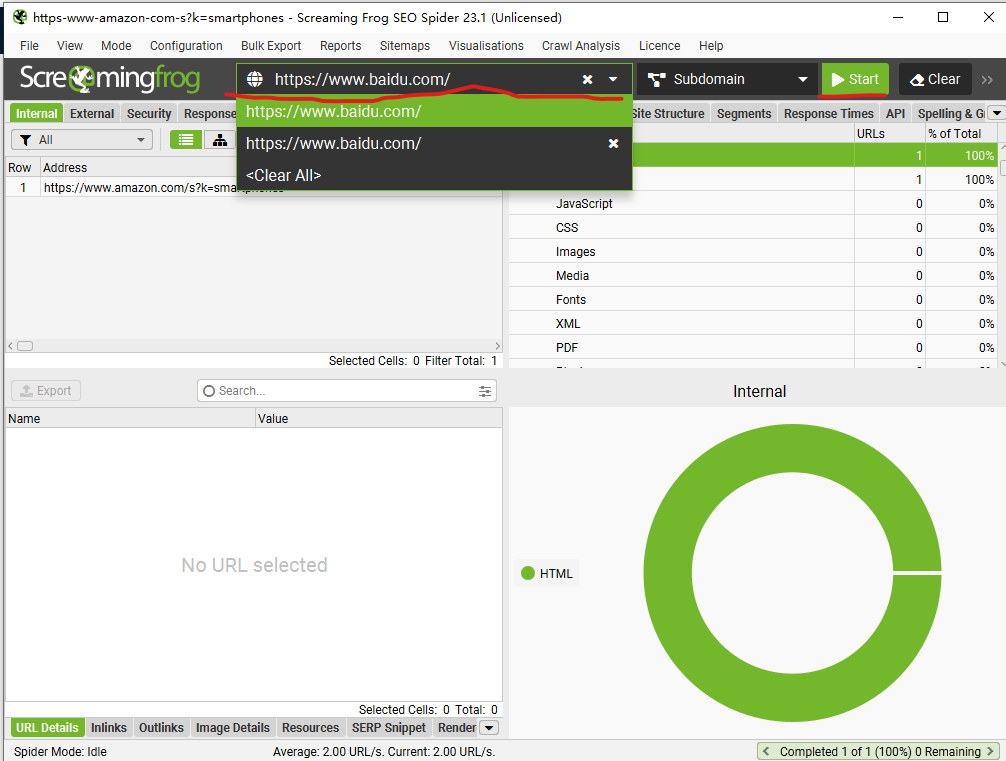
①https://www.baidu.com/。是否设置代理都可以抓取数据。
②https://www.amazon.com/s?k=smartphones。不设置代理无法抓取数据。
这两个测试案例可以展示亮数据的优势:

hello,我是 是Yu欸。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。