概述
在前端安全扫描中,获取完整的 JavaScript 代码是分析的基础。本文档介绍 Web 应用、H5 应用和快应用三种场景下的 JS 代码获取方法,以及如何使用 Cursor 进行代码分析。
一、Web 应用代码获取(HAR 方式)
1.1 下载网站的完整 HAR 文件
HAR(HTTP Archive)文件是浏览器将整个网页加载过程的所有网络请求完整记录下来的"抓包日志文件"。它记录了浏览器访问网页时触发的所有 HTTP 请求及详细信息,包括静态资源(JS/CSS/图片)的下载情况。我们下载 HAR 文件后,可以提取网页中的所有资源,其中 JS 是我们最主要的分析对象。
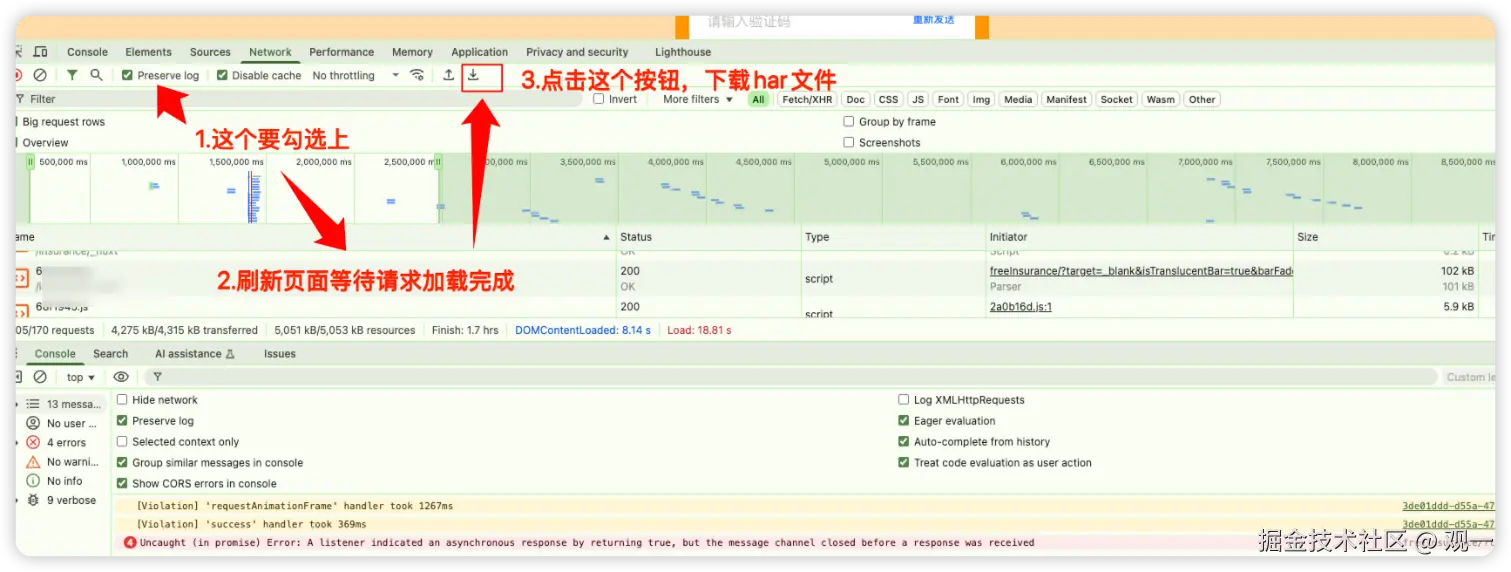
操作步骤:
-
访问目标网站,打开浏览器开发者工具(F12)
-
选择 Network 面板 ,勾选 Preserve log 选项
- 勾选后,页面跳转或刷新时,Network 面板中的请求记录不会被清空,会保留下来
- 勾选后,页面跳转或刷新时,Network 面板中的请求记录不会被清空,会保留下来
-
刷新页面,让 JS 等资源加载完成
-
点击下载按钮,导出 HAR 文件
-
下载完成后 ,会得到一个
domain.har的文件
1.2 还原 HAR 文件中的内容
使用以下 Python 脚本将 HAR 文件中的所有响应内容还原并保存为文件,保持原始目录结构。
运行命令:
bash
python extract_all_from_har.py site.har output_dirPython 脚本代码:
python
# 该文件是把web端加载的har中还原成内容
import json
import os
import sys
from urllib.parse import urlparse
import base64
if len(sys.argv) < 3:
print("Usage: python extract_all_from_har.py site.har output_dir")
sys.exit(1)
har_file = sys.argv[1]
out_root = sys.argv[2]
os.makedirs(out_root, exist_ok=True)
def guess_ext(url_path: str, mime: str) -> str:
# 如果 URL 自带扩展名,优先用它
name = os.path.basename(url_path)
if "." in name and not name.endswith("."):
return ""
# 否则根据 mimeType 猜一个
if not mime:
return ".txt"
mime = mime.lower()
if "javascript" in mime:
return ".js"
if "json" in mime:
return ".json"
if "html" in mime:
return ".html"
if "css" in mime:
return ".css"
if "xml" in mime:
return ".xml"
if "svg" in mime:
return ".svg"
if "plain" in mime:
return ".txt"
return ".txt"
with open(har_file, "r", encoding="utf-8") as f:
har = json.load(f)
count = 0
for entry in har["log"]["entries"]:
req = entry.get("request", {})
res = entry.get("response", {})
content = res.get("content", {})
text = content.get("text")
# 没有内容就跳过(很多大文件/二进制在 HAR 里不会带完整内容)
if not text:
continue
url = req.get("url", "")
if not url:
continue
parsed = urlparse(url)
host = parsed.netloc or "unknown_host"
path = parsed.path or "/"
mime = content.get("mimeType", "")
# 生成本地文件路径:root/host/path
# 例如:https://a.com/path/to/file.js -> out_root/a.com/path/to/file.js
# 如果 path 以 / 结尾,补一个 index
if path.endswith("/"):
path = path + "index"
# 目录 + 文件名拆分
dir_path, filename = os.path.split(path)
if not filename:
filename = "index"
# 根据 mime 猜扩展名(如果 URL 里没有)
ext = ""
if "." not in filename:
ext = guess_ext(path, mime)
filename_full = filename + ext
out_dir = os.path.join(out_root, host, dir_path.lstrip("/"))
os.makedirs(out_dir, exist_ok=True)
# 防止重名覆盖:同路径多次响应时加计数后缀
out_path = os.path.join(out_dir, filename_full)
if os.path.exists(out_path):
base, ext2 = os.path.splitext(filename_full)
out_path = os.path.join(out_dir, f"{base}_{count}{ext2}")
# 处理可能的 base64 编码
if content.get("encoding") == "base64":
try:
data = base64.b64decode(text)
# 尝试按 utf-8 解码成文本,失败就直接写二进制
try:
text_decoded = data.decode("utf-8")
with open(out_path, "w", encoding="utf-8", errors="ignore") as out:
out.write(text_decoded)
except UnicodeDecodeError:
with open(out_path, "wb") as out:
out.write(data)
except Exception as e:
print(f"[WARN] failed to decode base64 for {url}: {e}")
continue
else:
# 直接写文本
with open(out_path, "w", encoding="utf-8", errors="ignore") as out:
out.write(text)
count += 1
print(f"Saved {count} responses to {out_root}")执行结果:
执行完成后,可以看到网站中的 JS 文件已经被全部下载下来了。 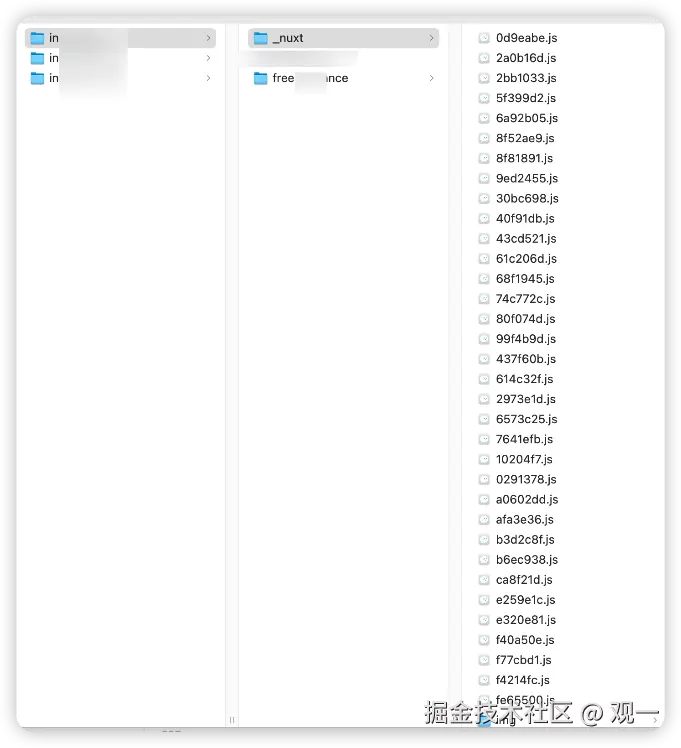
二、H5 应用代码获取
H5 和快应用类型的业务也是通过 JS 实现的,因此也可以通过 Cursor 来分析,只是获取 JS 代码的方式略有不同。
方式一:直接访问网站(推荐)
H5 的 JS 代码可以直接访问网站地址,通过和 Web 应用一样的方式获得:
- 使用浏览器直接访问 H5 页面 URL
- 按照 "一、Web 应用代码获取" 的方法,下载 HAR 文件并还原
方式二:Attach 到 WebView 实例(Hybrid 场景)
当 H5 页面嵌入在 App 的 WebView 中时,可以通过以下方式获取:
-
开启 WebView 调试
- 在 App 中启用 WebView 调试功能(通常需要在代码中设置
setWebContentsDebuggingEnabled(true))
- 在 App 中启用 WebView 调试功能(通常需要在代码中设置
-
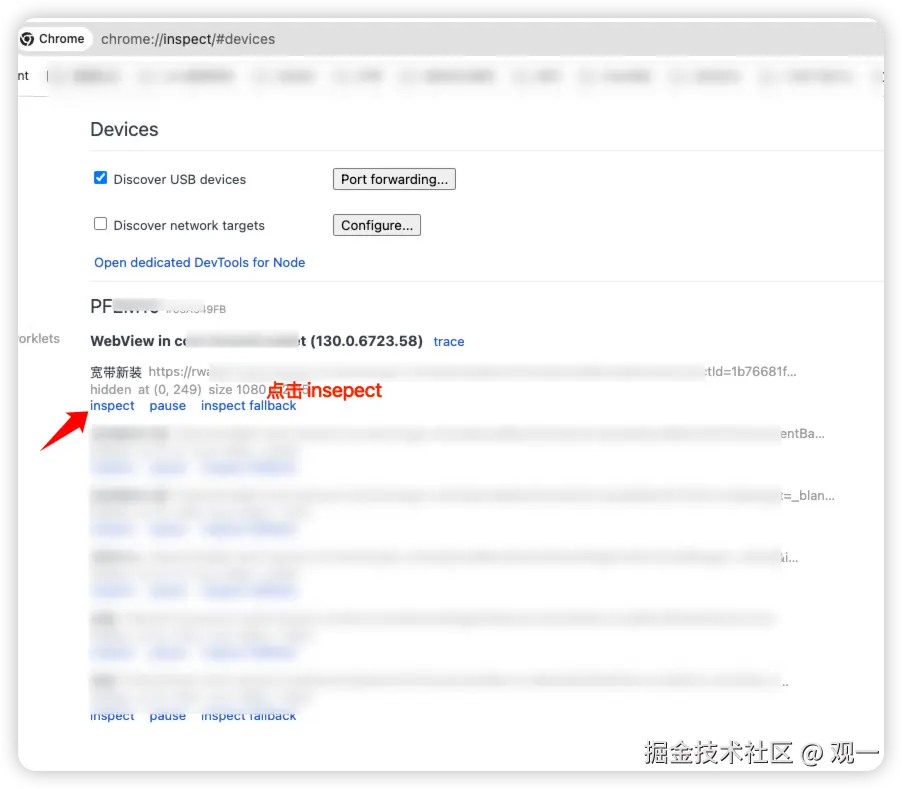
连接 WebView
- 在 Chrome 浏览器中打开
chrome://inspect/#devices - 找到目标 WebView 实例,点击 "inspect" 按钮
- 在 Chrome 浏览器中打开
-
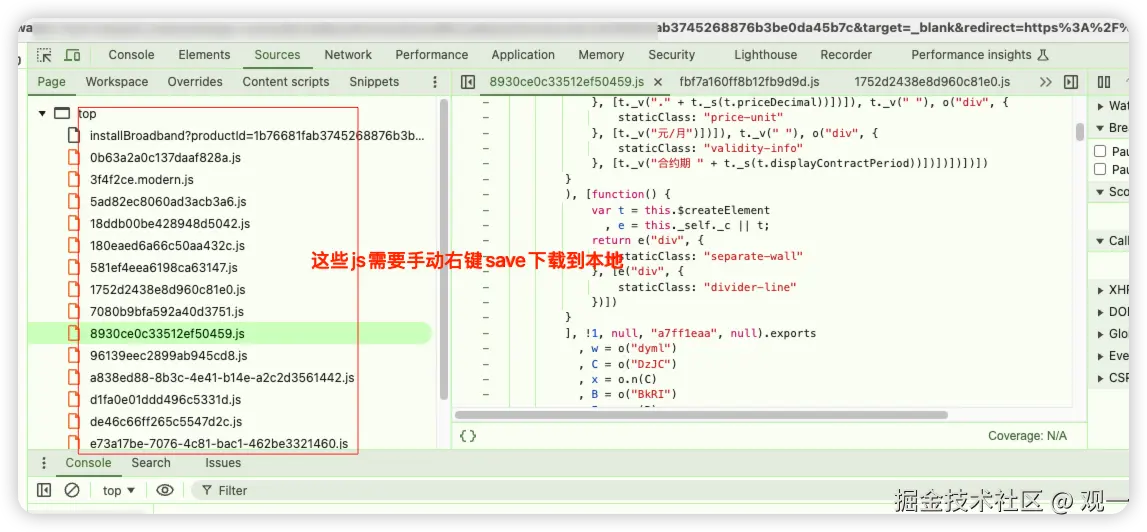
手动下载 JS 文件
- 在打开的 DevTools 中,切换到 Sources 面板
- 找到需要分析的 JS 文件,右键选择 "Save as..." 保存到本地
为什么不能自动下载 HAR?
在 Attach 到 WebView 时,Network 面板的事件来自 CDP(Chrome DevTools Protocol)网络域,是映射/转换后的视图,不一定包含完整的响应体。而 Sources 面板通过调试接口(Debugger.getScriptSource)直接从运行时获取脚本源码,因此可以下载。所以需要手动下载 JS,而不是依赖 HAR 导出。
三、快应用代码获取
方式一:有 RPK 包的情况
直接将快应用的 RPK 包进行解压即可获得完整的代码:
bash
# RPK 文件本质上是一个 ZIP 压缩包
unzip target_app.rpk -d output_dir方式二:无 RPK 包的情况
-
在快应用 App 中加载目标快应用
- 快应用引擎会把快应用的代码下载到本地
-
定位快应用包体目录
- 快应用的私有目录通常在:
/data/data/com.quick.instant/com.target.demo - 具体路径可能因快应用引擎而异
- 快应用的私有目录通常在:
-
使用 adb 命令导出
bash
# 连接设备后,使用 adb pull 导出
adb pull /data/data/com.quick.instant/com.target.demo ./output_dir四、使用 Cursor 进行代码分析
4.1 导入项目目录
将获得的目录(无论是 HAR 还原的、WebView 下载的,还是快应用解压的)导入到 Cursor 中。
4.2 开始安全分析
Cursor 可以对整个项目目录进行整体性分析,我们可以充分利用这个能力来识别 JS 中是否存在风险。
典型分析场景:
-
接口加密和签名算法分析
- 识别 API 请求的加密方式
- 分析签名算法实现
-
硬编码敏感信息检测
- 查找硬编码的 Token、API Key、密码等
- 识别敏感配置信息
-
安全漏洞扫描
- XSS 漏洞分析
- 开放重定向检测
- JSBridge 安全分析(针对 H5)
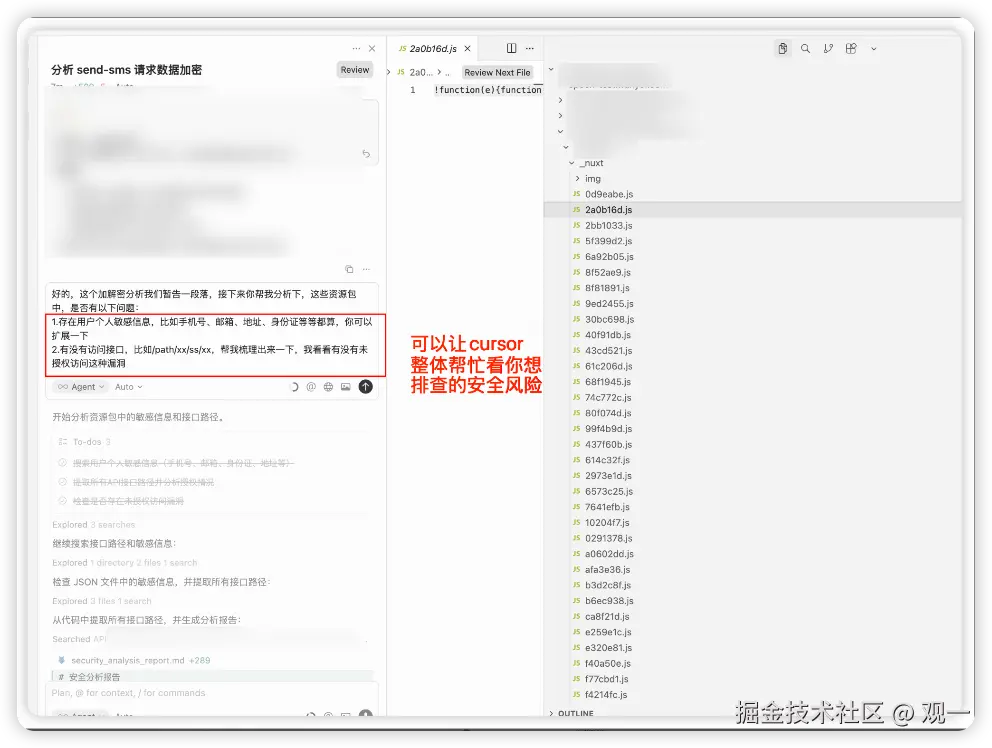
实战研究发现:
Cursor 的分析能力非常强大,基本上可以完成绝大部分的分析工作,极大提升研究效率。
总结
| 应用类型 | 代码获取方式 | 注意事项 |
|---|---|---|
| Web 应用 | 下载 HAR → Python 脚本还原 | 确保勾选 Preserve log,完整加载页面 |
| H5 应用 | 方式一:直接访问下载 HAR 方式二:Attach WebView → Sources 手动下载 | WebView 方式需手动下载,无法使用 HAR |
| 快应用 | 方式一:解压 RPK 包 方式二:adb pull 导出 | 需要 root 权限或使用 adb |
无论使用哪种方式获取代码,最终都可以导入 Cursor 进行统一的安全分析,提高效率。