注:本文为 "MMU 与 Unix/Linux 内核的协同管理" 相关合辑。
英文引文,机翻未校。
如有内容异常,请看原文。
Memory Management Unit (MMU)
内存管理单元(MMU)
It would be a good strategy to be familiar at the simplified principles of memory mapping and memory protection before getting too deeply into this article, as the MMU is where they meet.
在深入阅读本文之前,熟悉 内存映射 和 内存保护 的简化原理会是一个不错的策略,因为 MMU 是这两者的交汇点。
Caveat: different MMUs will be implemented in ways which differ in detail. This page is intended to illustrate the general principles in a particular way.
注意:不同的 MMU 在实现细节上会有所不同。本页面旨在以一种特定的方式阐释通用原理。
MMU Definition
MMU 定义
A Memory Management Unit (MMU) is the hardware system which performs both virtual memory mapping and checks the current privilege to keep user processes separated from the operating system --- and each other. In addition it helps to prevent caching of 'volatile' memory regions (such as areas containing I/O peripherals).
内存管理单元(MMU)是一种硬件系统,它既执行虚拟内存映射,又检查当前的 特权级别,以将用户进程与操作系统以及进程之间相互隔离。此外,它还有助于防止对"易失性"内存区域(例如包含 I/O 外设 的区域)进行 缓存。
MMU inputs
MMU 输入
-
a virtual memory address
一个 虚拟 内存地址
-
an operation: read/write, maybe a transfer size
一种操作:读/写,可能包含传输大小
-
the processor's privilege information
处理器的特权级别信息
MMU outputs
MMU 输出
-
a physical memory address
一个 物理 内存地址
-
cachability (etc.) information
可缓存性(等)信息
or
或
-
a rejection (memory fault) indicating:
拒绝(内存故障),表示:
-
no physical memory (currently) mapped to the requested page
(当前)没有物理内存映射到请求的页面
-
illegal operation (e.g. writing to a 'read only' area)
非法操作(例如,向"只读"区域写入数据)
-
privilege violation (e.g. user tries to get at O.S. space)
特权级别违规(例如,用户试图访问操作系统空间)
-
Example
示例
A typical MMU in a virtual memory system will use a paging system. The page tables specify the translation from the virtual to the physical page addresses; only one set of page tables will be present at any time (green, in the figure below) although other pages may still be present until the physical memory is 'overflowing', after which they may need to be "paged out".
虚拟内存 系统中的典型 MMU 会使用 分页系统。页表 规定了从虚拟页地址到物理页地址的转换;任何时刻只会存在一组页表(下图中绿色部分),尽管其他页面可能仍会存在,直到物理内存"溢出",之后这些页面可能需要被"换出"。
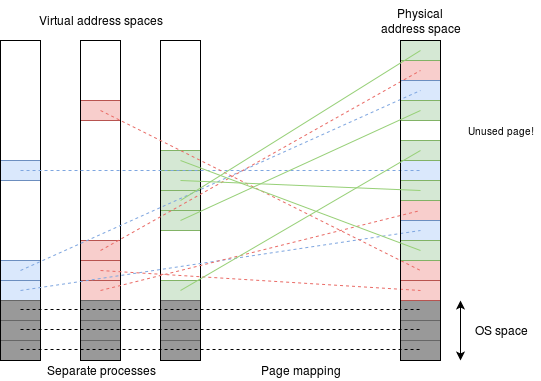
页面映射
All the current process' pages must be in the page tables but they need not all be physically present: they may have been 'backed off' onto disk. In this case the MMU notes the fact and the O.S. will have to fetch them on demand .
当前进程的所有页面都必须存在于页表中,但并非所有页面都需要物理上存在:它们可能已被"备份"到磁盘上。在这种情况下,MMU 会记录该情况,操作系统必须根据需求加载这些页面。
As was observed in the memory mapping article, the page table entries have some 'spare' space. Part of this indicates things like "this page is writeable" and the MMU checks each access request against this. Only if there is a valid mapping and the operation is legitimate will the MMU let the processor continue, otherwise it will indicate a memory fault.
如 内存映射 一文中所述,页表项包含一些"空闲"空间。其中部分空间用于标识诸如"此页面可写"等信息,MMU 会根据这些信息检查每个访问请求。只有当存在有效映射且操作合法时,MMU 才会允许处理器继续执行,否则会触发 内存故障。
Architecture
架构
The figure below shows a typical MMU 'in situ' This translates virtual to physical addresses, usually fairly quickly using a look-up (TLB). This also returns some extra information -- copied from the page tables -- such as access permissions. If the virtual address is found in the (virtually addressed) level 1 cache then the address translation is discarded as it is not needed; the permission check is still performed though because (for example) the particular access could be a user application hitting some cached operating system (privileged) data.
下图展示了一个典型的"在位"MMU。它通过查找(TLB)将虚拟地址转换为物理地址,该过程通常相当迅速。同时,它还会返回一些从页表复制的额外信息,例如 访问权限。如果虚拟地址在(虚拟寻址的)一级缓存中找到,则地址转换结果会被丢弃,因为此时已无需该转换;但权限检查仍会执行,例如,某个访问可能是用户应用程序试图访问缓存中的操作系统(特权)数据。
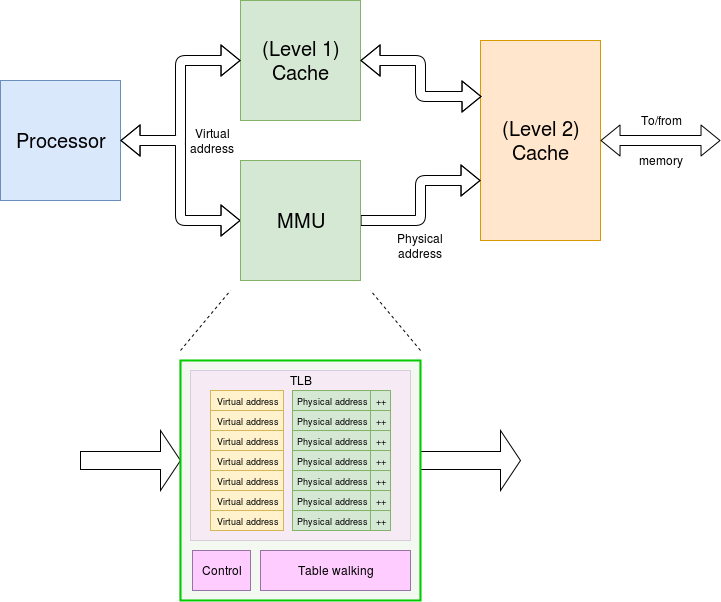
The look-up takes some time, so it is usually done in parallel ("lookaside") with the first level cache, which is why the level 1 cache is keyed with virtual addresses -- something which is of importance during context switching.
查找过程需要一定时间,因此通常会与一级缓存并行执行("旁路查找"),这也是一级缓存以虚拟地址为索引的原因------这一点在 上下文切换 过程中尤为重要。
Example page table structure
示例页表结构
The figure below shows a simple page table for a 32 32 32-bit machine using 4 4 4 KiB pages ( 2 12 2^{12} 212 bytes), leaving 20 20 20 bits to select the page ( 2 20 = 1048576 2^{20} = 1048576 220=1048576 pages).
下图展示了一个适用于 32 32 32 位机器的简单页表,该机器使用 4 4 4 KiB 页面( 2 12 2^{12} 212 字节),剩余 20 20 20 位用于选择页面( 2 20 = 1048576 2^{20} = 1048576 220=1048576 个页面)。
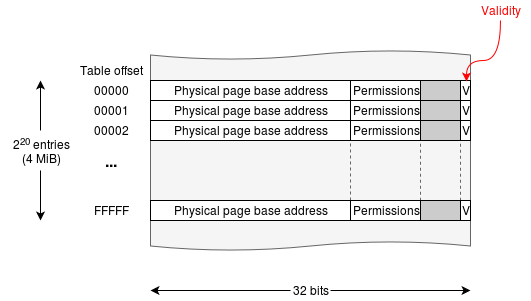
示例页表结构
Implementation
实现
Because page tables are quite large -- and there must be a set for each process -- they, themselves need to be stored in memory. This means that they are accessible for the O.S. software to maintain them -- they must be in O.S. space for security, of course -- but makes the memory access process very slow (and energy inefficient, too) because (in principle) there is one (or more) O.S. look-ups before every user data transfer takes place. If this really had to happen the computer would be horrendously inefficient!
由于页表规模较大,且每个进程都必须有一组页表,因此页表本身需要存储在内存中。这意味着操作系统软件可以访问并维护它们------当然,为了安全性,页表必须位于操作系统空间------但这会导致内存访问过程非常缓慢(且能量效率低下),因为(原则上)每次用户数据传输之前都需要进行一次(或多次)操作系统查找。如果确实必须如此,计算机的效率将会极低!
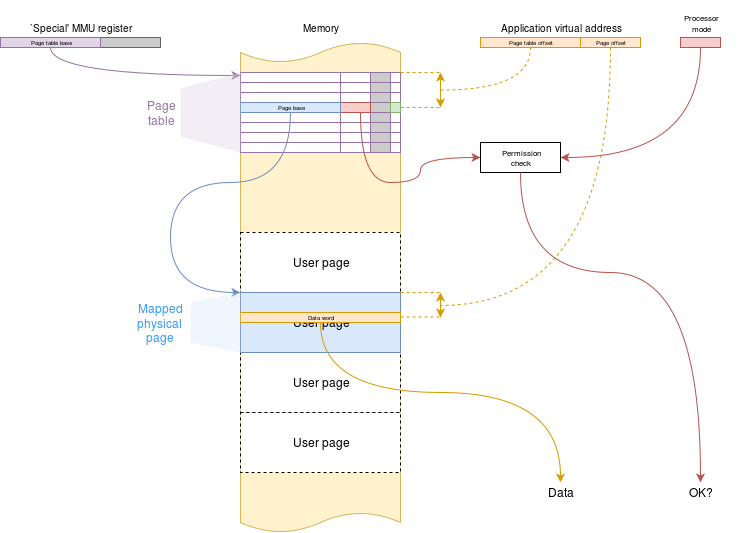
页表操作
In the 'definition', above, the MMU function was defined as a 'black box'; a common set of page translations can be cached locally to avoid the extra accesses, most of the time. This is the function of the TLB.
在上述"定义"中,MMU 的功能被定义为一个"黑盒";大多数情况下,一组常用的页表转换结果可以在本地进行 缓存,以避免额外的访问。这就是 转换检测缓冲区(TLB) 的功能。
In practice the TLB will satisfy most memory requests without needing to check the 'official' page tables. Occasionally, the TLB misses: this then causes the MMU to stall the processor whilst it looks up the reference and (usually) updates the TLB contents. This process is known as "table walking"; it is usually a hardware job so you don't have to worry about the details in this course unit.
实际上,TLB 可以满足大多数内存请求,而无需检查"正式"页表。偶尔会发生 TLB 未命中:此时 MMU 会暂停处理器,同时查找该引用并(通常)更新 TLB 内容。这个过程被称为"页表遍历";它通常是硬件层面的工作,因此在本课程单元中无需关注其细节。
How Does the Memory Management Unit (MMU) Work with the Unix/Linux Kernel?
内存管理单元(MMU)如何与 Unix/Linux 内核协同工作?
Understanding how your CPU's MMU collaborates with the Linux kernel to create process isolation, memory protection, and the illusion of infinite RAM.
了解 CPU 的 MMU 如何与 Linux 内核协同工作,以实现进程隔离、内存保护和无限内存的假象。
Mohit
Jun 15, 2025
When you write a program that allocates memory with malloc() or maps a file with mmap(), a fascinating dance occurs between hardware and software that most programmers never see. At the heart of this interaction lies the Memory Management Unit (MMU), a piece of hardware that works closely with the Unix/Linux kernel to create the illusion that each process has its own private memory space.
当你编写一个使用 malloc() 分配内存或使用 mmap() 映射文件的程序时,硬件和软件之间会发生一场大多数程序员从未见过的奇妙协作。这种交互的核心是内存管理单元(MMU),这是一种与 Unix/Linux 内核紧密协作的硬件,它能营造出每个进程都拥有自己私有内存空间的假象。
Many developers harbor misconceptions about the MMU's role. Some believe it's part of the kernel itself, while others think the kernel performs all address translations in software. The reality is more nuanced: the MMU is a hardware component, typically integrated into the CPU, that performs the actual address translation, while the kernel acts as its configurator and manager.
许多开发人员对 MMU 的作用存在误解。有些人认为它是内核本身的一部分,而另一些人则认为内核通过软件执行所有地址转换。实际情况更为复杂:MMU 是一种硬件组件,通常集成在 CPU 中,负责执行实际的地址转换,而内核则充当其配置器和管理器。
Understanding this relationship is crucial for system programmers, kernel developers, and anyone debugging memory-related issues. The MMU and kernel work together to provide virtual memory, process isolation, and efficient memory management, features that form the foundation of modern Unix-like operating systems.
理解这种关系对于系统程序员、内核开发人员以及任何调试内存相关问题的人来说都至关重要。MMU 和内核协同工作,提供虚拟内存、进程隔离和高效的内存管理,这些特性构成了现代类 Unix 操作系统的基础。
Overview of the MMU and Memory Management
MMU 与内存管理概述
The Memory Management Unit serves as a hardware translator between the virtual addresses your programs use and the physical addresses where data actually resides in RAM. Think of it as an extremely fast address book that converts every memory reference your program makes.
内存管理单元(MMU)是程序使用的虚拟地址与数据在 RAM 中实际存储的物理地址之间的硬件转换器。可以将其视为一本极快的地址簿,负责转换程序发出的每一个内存引用。
Virtual memory provides several critical benefits. First, it gives each process the illusion of having access to a large, contiguous address space, even when physical memory is fragmented or limited. Second, it enables process isolation, basically one process cannot accidentally (or maliciously) access another process's memory. Third, it allows the system to use secondary storage as an extension of physical memory through swapping.
虚拟内存提供了多项关键优势。首先,它让每个进程都感觉自己可以访问一个庞大、连续的地址空间,即使物理内存是碎片化的或有限的。其次,它实现了进程隔离,即一个进程无法意外(或恶意)访问另一个进程的内存。第三,它允许系统通过交换将辅助存储作为物理内存的扩展。
The MMU is a hardware component, not software. On most modern architectures, it's integrated directly into the CPU alongside the cache controllers and execution units. This hardware implementation is essential for performance, translating virtual addresses to physical addresses happens on every memory access, potentially billions of times per second.
MMU 是硬件组件,而非软件。在大多数现代架构中,它与缓存控制器和执行单元一起直接集成在 CPU 中。这种硬件实现对于性能至关重要,因为每次内存访问都需要将虚拟地址转换为物理地址,这个过程每秒可能发生数十亿次。
When your program accesses memory at address 0x400000, the MMU immediately translates this virtual address to whatever physical address actually contains your data. This translation happens transparently and at hardware speed, making virtual memory practical for real-world use.
当你的程序访问地址 0x400000 处的内存时,MMU 会立即将这个虚拟地址转换为实际存储数据的物理地址。这种转换是透明的,且以硬件速度执行,使得虚拟内存在实际应用中具有可行性。
MMU and the Unix/Linux Kernel
MMU 与 Unix/Linux 内核
The relationship between the MMU and kernel often confuses developers. The MMU is hardware, while the kernel is software that configures and manages that hardware. The kernel doesn't perform address translation, the MMU does that autonomously for every memory access.
MMU 与内核之间的关系常常让开发人员感到困惑。MMU 是硬件,而内核是配置和管理该硬件的软件。内核不执行地址转换,MMU 会为每次内存访问自主完成这项工作。
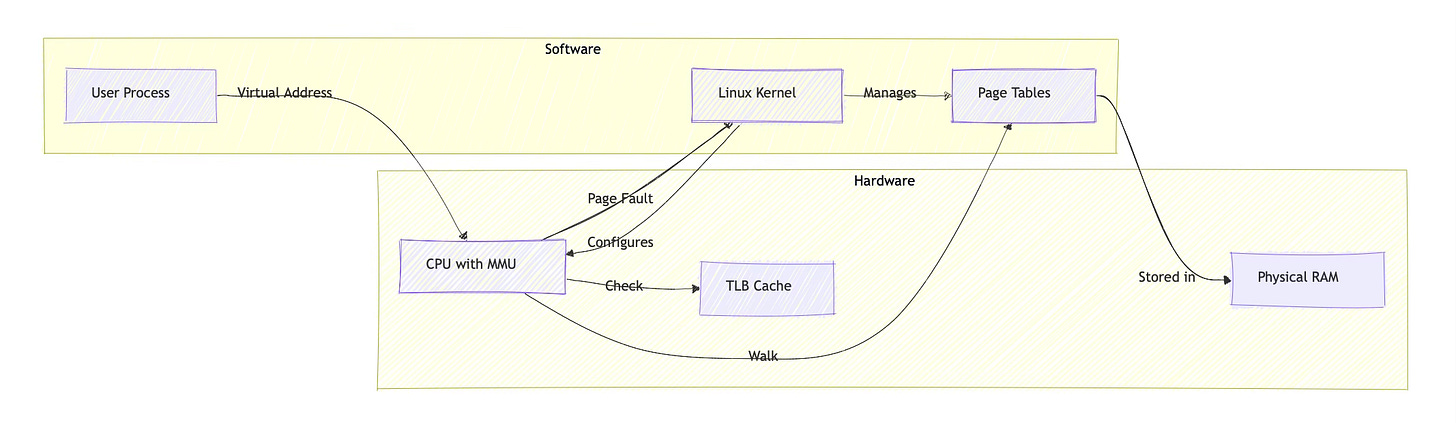
The kernel's role is to set up the data structures that the MMU uses for translation. These data structures, called page tables, live in main memory and contain the mapping information the MMU needs. When a process starts, the kernel allocates and initializes page tables for that process, then tells the MMU where to find them.
内核的作用是建立 MMU 用于转换的数据源结构。这些被称为页表的数据源结构存储在主内存中,包含 MMU 所需的映射信息。当一个进程启动时,内核会为该进程分配并初始化页表,然后告知 MMU 这些页表的位置。
Consider what happens when you call fork(). The kernel creates new page tables for the child process, often using copy-on-write semantics to share physical pages initially. The kernel configures these page tables, but the MMU performs all subsequent address translations using the information the kernel provided.
思考调用 fork() 时会发生什么。内核会为子进程创建新的页表,通常使用写时复制语义,初始时共享物理页面。内核配置这些页表,但 MMU 会使用内核提供的信息执行所有后续的地址转换。
The distinction is important: kernel data structures like vm_area_struct in Linux track memory regions at a high level, while page tables contain the detailed mappings the MMU actually uses. The kernel manages both, but the MMU only directly interacts with page tables.
这种区别很重要:Linux 中的 vm_area_struct 等内核数据源结构在高层级跟踪内存区域,而页表包含 MMU 实际使用的详细映射。内核管理这两者,但 MMU 只与页表直接交互。
Address Translation Mechanics
地址转换机制
Address translation happens through a multi-level page table walk. Modern systems typically use hierarchical page tables with multiple levels, like x86-64 systems commonly use four levels, creating a tree-like structure that the MMU traverses to find the final physical address.
地址转换通过多级页表遍历实现。现代系统通常使用具有多个级别的分层页表,例如 x86-64 系统通常使用四级页表,形成一个树状结构,MMU 会遍历该结构以找到最终的物理地址。
Each virtual address is divided into several fields. The most significant bits select entries at each level of the page table hierarchy, while the least significant bits provide an offset within the final page. For example, on x86-64, a 48 48 48-bit virtual address might be split into four 9 9 9-bit page table indices and a 12 12 12-bit page offset.
每个虚拟地址被划分为多个字段。最高有效位用于选择页表层级中每个级别的条目,而最低有效位则提供最终页面内的偏移量。例如,在 x86-64 架构上,一个 48 48 48 位的虚拟地址可能被拆分为四个 9 9 9 位的页表索引和一个 12 12 12 位的页面偏移量。
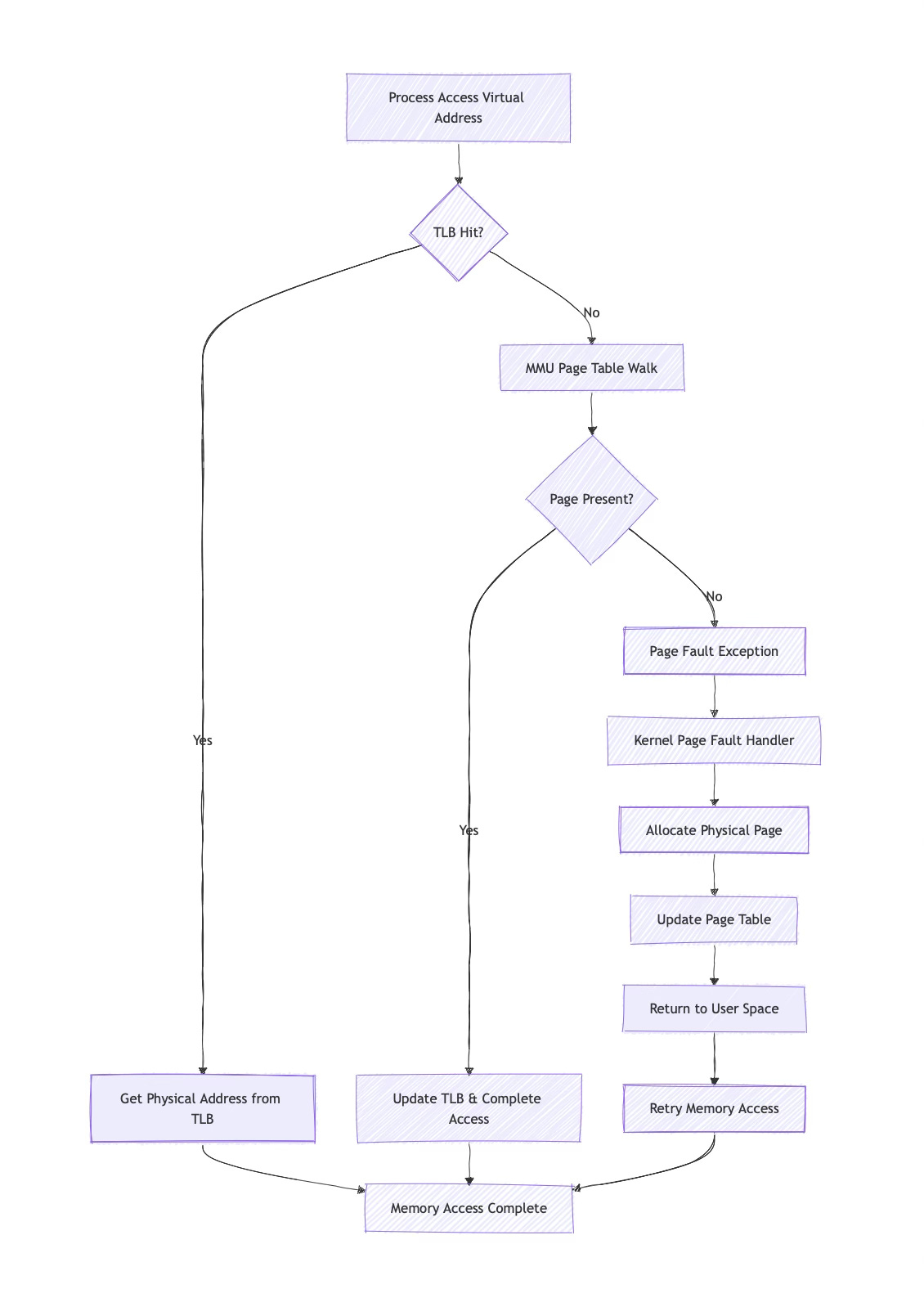
MMU Address Translation Flow
MMU 地址转换流程
The Translation Lookaside Buffer (TLB) acts as a cache for recently used translations. Since page table walks require multiple memory accesses, the TLB dramatically improves performance by caching translation results. A typical TLB might cache several hundred translations, with separate TLBs for instructions and data.
转换检测缓冲区(TLB)充当最近使用的转换结果的缓存。由于页表遍历需要多次内存访问,TLB 通过缓存转换结果显著提高了性能。一个典型的 TLB 可能缓存数百个转换结果,并且指令和数据通常有各自独立的 TLB。
When the MMU encounters a virtual address not in the TLB, it performs a page table walk. Starting with the page table base address (stored in a special CPU register), it uses each level of the virtual address to index into successive page table levels until it reaches the final page table entry containing the physical address.
当 MMU 遇到不在 TLB 中的虚拟地址时,它会执行页表遍历。从页表基地址(存储在一个特殊的 CPU 寄存器中)开始,它使用虚拟地址的每个级别来索引后续的页表级别,直到找到包含物理地址的最终页表条目。
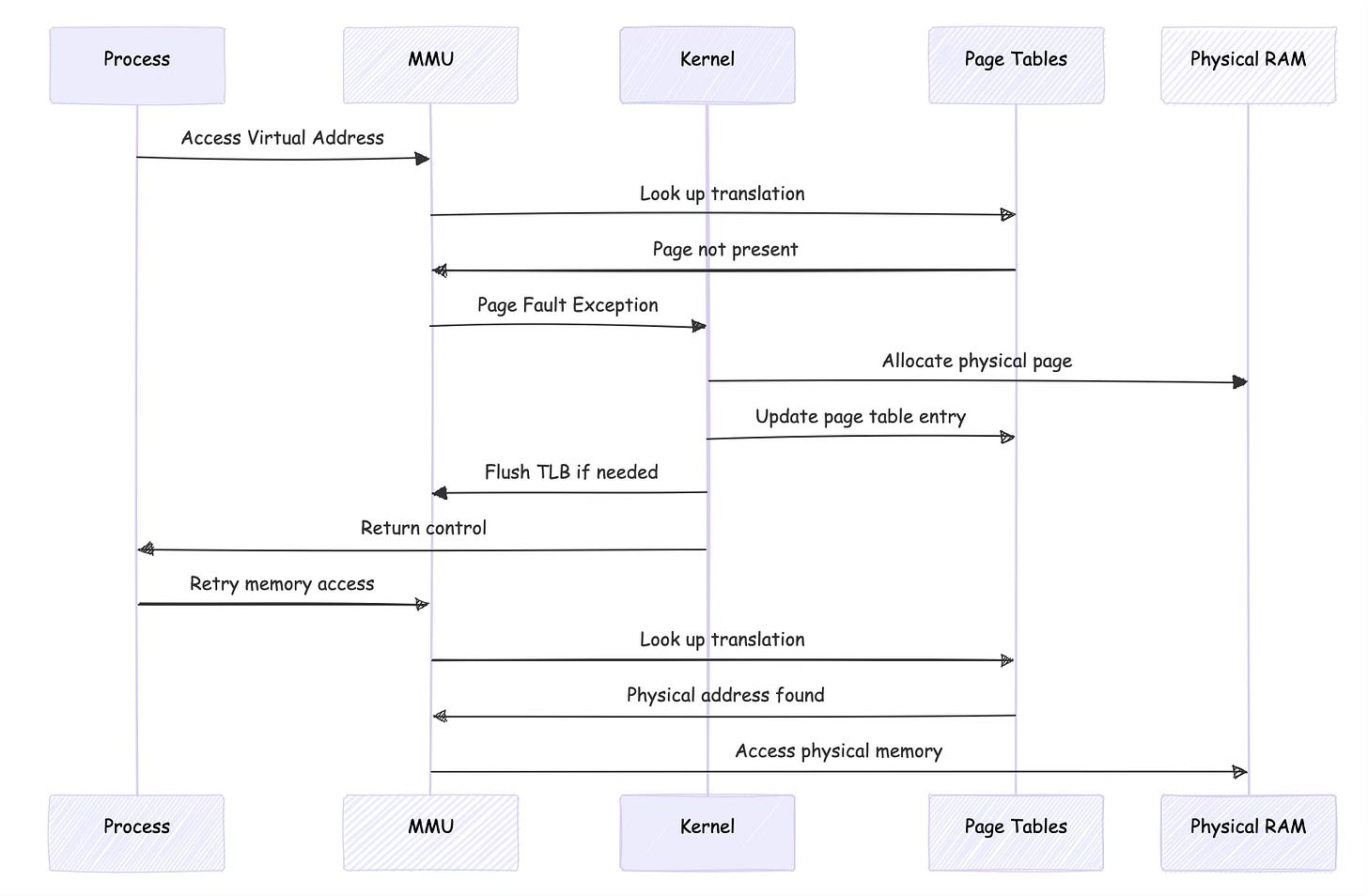
Page faults occur when the MMU cannot complete a translation. This might happen because a page isn't present in memory, the access violates permissions, or the page table entry is invalid. The MMU generates an exception that transfers control to the kernel's page fault handler.
当 MMU 无法完成转换时,会发生页面故障。这可能是因为页面不在内存中、访问违反了权限,或者页表条目无效。MMU 会生成一个异常,将控制权转移到内核的页面故障处理程序。
Page Tables and Kernel Management
页表与内核管理
Page tables are hierarchical data structures stored in main memory that map virtual pages to physical pages. Each entry in a page table contains not just address translation information, but also permission bits (read, write, execute), presence flags, and architecture-specific metadata.
页表是存储在主内存中的分层数据源结构,用于将虚拟页面映射到物理页面。页表中的每个条目不仅包含地址转换信息,还包含权限位(读、写、执行)、存在标志位和架构特定的元数据。
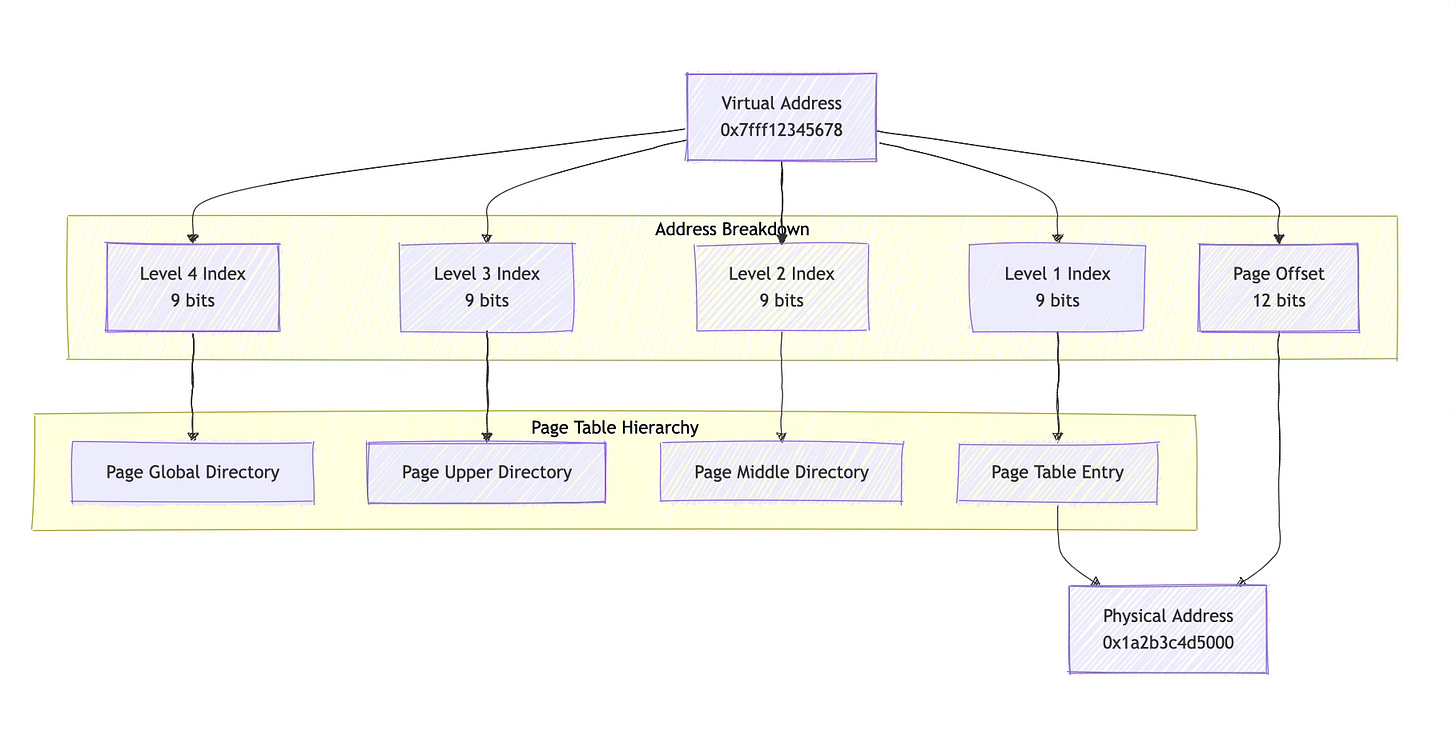
The kernel maintains these page tables through a sophisticated memory management subsystem. In Linux, the core data structures include the memory descriptor (mm_struct), virtual memory areas (vm_area_struct), and the actual page tables themselves. The kernel provides architecture-independent interfaces that hide the differences between various MMU designs.
内核通过复杂的内存管理子系统维护这些页表。在 Linux 中,核心数据源结构包括内存描述符(mm_struct)、虚拟内存区域(vm_area_struct)以及实际的页表本身。内核提供了与架构无关的接口,隐藏了不同 MMU 设计之间的差异。
When a process requests memory through mmap() or brk(), the kernel typically doesn't immediately populate page tables. Instead, it creates a VMA (Virtual Memory Area) describing the mapping and defers actual page table creation until the process accesses the memory. This lazy allocation approach saves memory and improves performance.
当进程通过 mmap() 或 brk() 请求内存时,内核通常不会立即填充页表。相反,它会创建一个描述该映射的 VMA(虚拟内存区域),并将实际的页表创建推迟到进程访问该内存时。这种延迟分配方法节省了内存并提高了性能。
Here's a simplified example of what happens during memory allocation:
以下是内存分配过程的简化示例:
// Process calls mmap()
void *ptr = mmap(NULL, 4096, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// Kernel creates VMA but doesn't populate page tables yet
// First access to *ptr triggers page fault
*((int*)ptr) = 42; // Page fault occurs here
// Kernel page fault handler:
// 1. Finds the VMA covering the faulting address
// 2. Allocates a physical page
// 3. Updates page tables to map virtual to physical address
// 4. Returns to user space, where access succeeds
// 进程调用 mmap()
void *ptr = mmap(NULL, 4096, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// 内核创建 VMA,但尚未填充页表
// 首次访问 *ptr 触发页面故障
*((int*)ptr) = 42; // 此处发生页面故障
// 内核页面故障处理程序:
// 1. 找到覆盖故障地址的 VMA
// 2. 分配一个物理页面
// 3. 更新页表,将虚拟地址映射到物理地址
// 4. 返回用户空间,此时访问成功The kernel must synchronize page table updates with the MMU's TLB. When changing page table entries, the kernel often needs to flush TLB entries to ensure the MMU sees the updated mappings. This synchronization is critical for correctness but can impact performance.
内核必须将页表更新与 MMU 的 TLB 同步。修改页表条目时,内核通常需要刷新 TLB 条目,以确保 MMU 能看到更新后的映射。这种同步对于正确性至关重要,但可能会影响性能。
Process Isolation and Physical Address Awareness
进程隔离与物理地址感知
The MMU provides strong process isolation by ensuring each process has its own virtual address space. Process A's virtual address 0x400000 maps to completely different physical memory than Process B's virtual address 0x400000. User-space processes have no direct access to physical addresses, they only see virtual addresses.
MMU 通过确保每个进程都有自己的虚拟地址空间来提供强大的进程隔离。进程 A 的虚拟地址 0x400000 与进程 B 的虚拟地址 0x400000 映射到完全不同的物理内存。用户空间进程无法直接访问物理地址,它们只能看到虚拟地址。
However, the kernel maintains awareness of physical addresses for several reasons. Device drivers need to know physical addresses to program DMA controllers. The kernel's memory allocator works with physical pages. Kernel debuggers and profiling tools sometimes need to correlate virtual and physical addresses.
然而,内核出于多种原因需要感知物理地址。设备驱动程序需要知道物理地址来配置 DMA 控制器。内核的内存分配器操作物理页面。内核调试器和性能分析工具有时需要关联虚拟地址和物理地址。
Linux provides several mechanisms for examining address translations. The /proc/<pid>/pagemap interface allows privileged processes to read page table information, including physical addresses corresponding to virtual addresses. This interface has security implications and is typically restricted to root.
Linux 提供了多种检查地址转换的机制。/proc/<pid>/pagemap 接口允许特权进程读取页表信息,包括与虚拟地址对应的物理地址。该接口涉及安全问题,通常仅对 root 用户开放。
The kernel uses functions like virt_to_phys() and phys_to_virt() to convert between virtual and physical addresses within kernel space. These functions work because the kernel maintains a direct mapping of physical memory in its virtual address space.
内核使用 virt_to_phys() 和 phys_to_virt() 等函数在内核空间中进行虚拟地址和物理地址之间的转换。这些函数之所以有效,是因为内核在其虚拟地址空间中维护了物理内存的直接映射。
User processes remain unaware of physical addresses by design. This abstraction enables the kernel to move pages in physical memory (during compaction), swap pages to storage, and implement copy-on-write semantics transparently.
设计上,用户进程无法感知物理地址。这种抽象使内核能够在物理内存中移动页面(压缩过程中)、将页面交换到存储设备,以及透明地实现写时复制语义。
Low-Level Mechanics
底层机制
System calls that manipulate memory mappings interact with both kernel memory management and the MMU. Consider mprotect(), which changes page permissions:
操作内存映射的系统调用会同时与内核内存管理和 MMU 交互。以更改页面权限的 mprotect() 为例:
// Make a page read-only
int result = mprotect(ptr, 4096, PROT_READ);
// Kernel implementation:
// 1. Find VMA covering the address range
// 2. Update VMA permissions
// 3. Update page table entries to reflect new permissions
// 4. Flush TLB entries for affected pages
// 5. Return to user space
// 将页面设为只读
int result = mprotect(ptr, 4096, PROT_READ);
// 内核实现:
// 1. 找到覆盖该地址范围的 VMA
// 2. 更新 VMA 权限
// 3. 更新页表条目以反映新权限
// 4. 刷新受影响页面的 TLB 条目
// 5. 返回用户空间The mmap() system call demonstrates the kernel's role in configuring MMU behavior. When you map a file, the kernel creates VMAs and may populate some page table entries immediately. For anonymous mappings, the kernel typically uses demand paging, creating page table entries only when pages are first accessed.
mmap() 系统调用展示了内核在配置 MMU 行为中的作用。映射文件时,内核会创建 VMA,并可能立即填充一些页表条目。对于匿名映射,内核通常使用请求分页,仅在页面首次被访问时才创建页表条目。
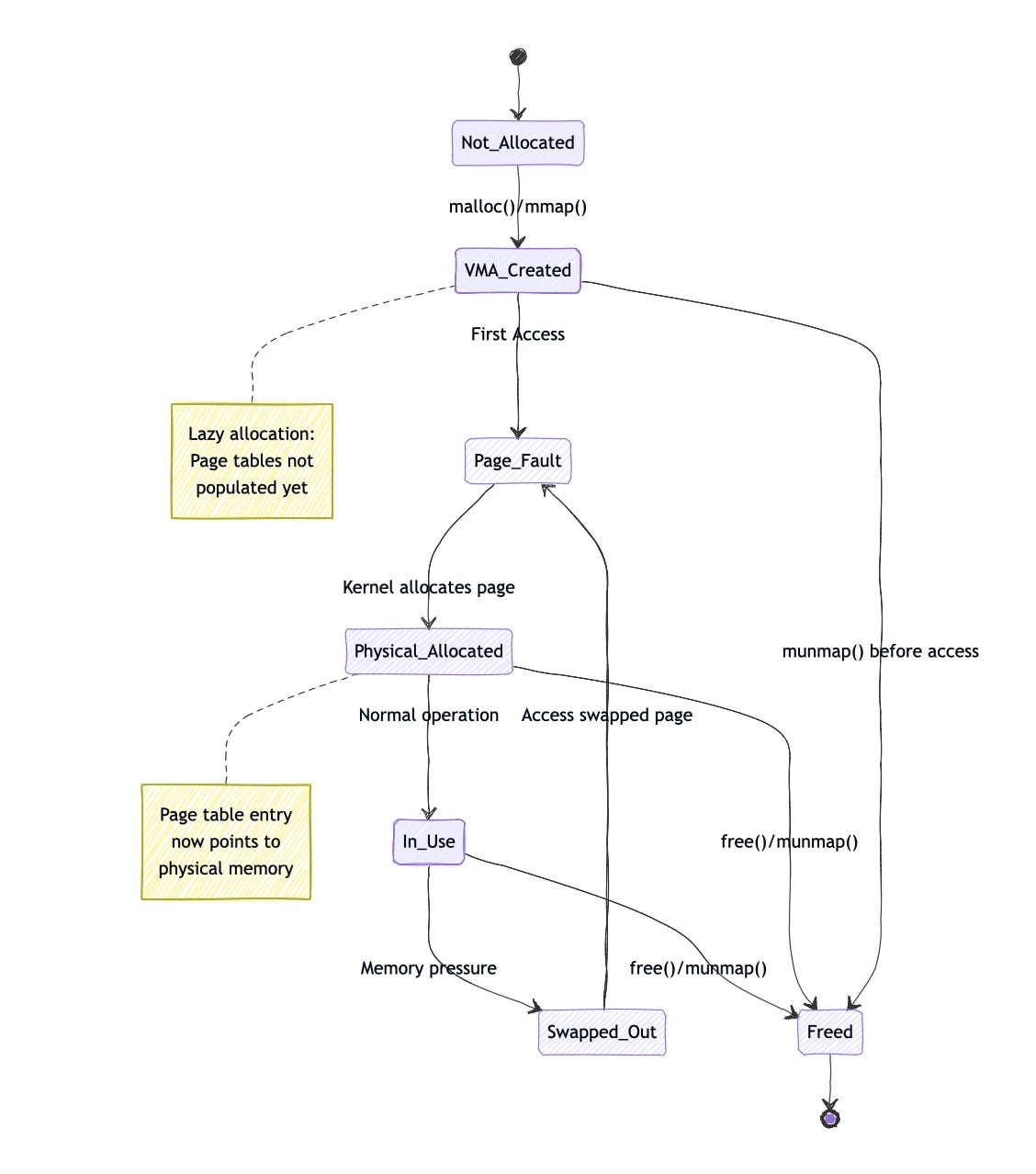
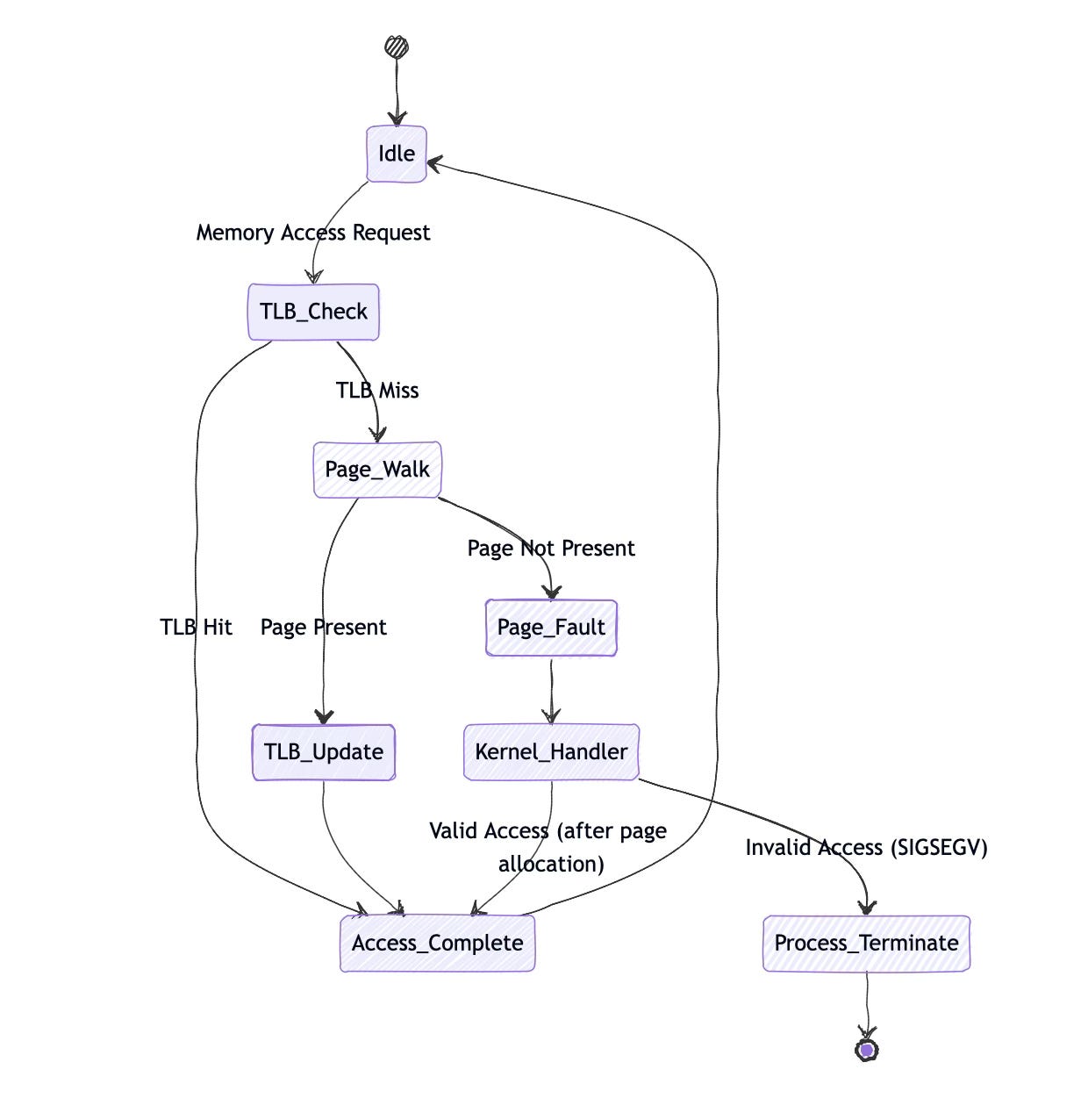
Page fault handling reveals the intricate cooperation between MMU and kernel. When the MMU cannot translate an address, it generates a page fault exception. The kernel's page fault handler determines whether the fault is valid (accessing a mapped but not-present page) or invalid (accessing unmapped memory), then takes appropriate action.
页面故障处理揭示了 MMU 与内核之间复杂的协作。当 MMU 无法转换某个地址时,会生成一个页面故障异常。内核的页面故障处理程序会判断该故障是有效的(访问已映射但未在内存中的页面)还是无效的(访问未映射的内存),然后采取相应的行动。
Here's what happens during a typical page fault:
以下是典型页面故障的处理过程:
// User code accesses previously unused memory
char *buffer = malloc(1024 * 1024); // 1MB allocation
buffer[500000] = 'A'; // Page fault occurs here
// MMU generates page fault exception
// Kernel page fault handler:
// 1. Saves processor state
// 2. Determines faulting virtual address
// 3. Finds VMA covering the address
// 4. Allocates physical page
// 5. Updates page table entry
// 6. Flushes TLB if necessary
// 7. Restores processor state and returns
// 用户代码访问之前未使用的内存
char *buffer = malloc(1024 * 1024); // 分配 1MB 内存
buffer[500000] = 'A'; // 此处发生页面故障
// MMU 生成页面故障异常
// 内核页面故障处理程序:
// 1. 保存处理器状态
// 2. 确定故障虚拟地址
// 3. 找到覆盖该地址的 VMA
// 4. 分配物理页面
// 5. 更新页表条目
// 6. 必要时刷新 TLB
// 7. 恢复处理器状态并返回Practical Examples
实际示例
Debugging memory-related issues often requires understanding MMU and kernel interactions. The strace tool can reveal system calls that affect memory mappings:
调试内存相关问题通常需要理解 MMU 与内核的交互。strace 工具可以显示影响内存映射的系统调用:
$ strace -e mmap,mprotect,brk ./my_program
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f8a1c000000
brk(NULL) = 0x55a1b8000000
brk(0x55a1b8021000) = 0x55a1b8021000
mprotect(0x7f8a1c000000, 4096, PROT_READ) = 0The /proc/<pid>/maps file shows a process's virtual memory layout:
/proc/<pid>/maps 文件展示了进程的虚拟内存布局:
$ cat /proc/1234/maps
55a1b7000000-55a1b7001000 r-xp 00000000 08:01 1234567 /usr/bin/my_program
55a1b7200000-55a1b7201000 r--p 00000000 08:01 1234567 /usr/bin/my_program
55a1b7201000-55a1b7202000 rw-p 00001000 08:01 1234567 /usr/bin/my_program
7f8a1c000000-7f8a1c021000 rw-p 00000000 00:00 0 [heap]For more detailed analysis, /proc/<pid>/pagemap provides physical address information (requires root access):
如需更详细的分析,/proc/<pid>/pagemap 提供物理地址信息(需要 root 权限):
c
#include <fcntl.h>
#include <unistd.h>
#include <stdint.h>
// Read physical address for virtual address 读取虚拟地址对应的物理地址
uint64_t virt_to_phys(void *virt_addr, pid_t pid) {
int fd;
char path[256];
uint64_t page_info;
off_t offset;
snprintf(path, sizeof(path), "/proc/%d/pagemap", pid);
fd = open(path, O_RDONLY);
if (fd < 0) return 0;
offset = ((uintptr_t)virt_addr / 4096) * sizeof(uint64_t);
lseek(fd, offset, SEEK_SET);
read(fd, &page_info, sizeof(page_info));
close(fd);
if (page_info & (1ULL << 63)) { // Page present 页面存在于内存中
return (page_info & ((1ULL << 54) - 1)) * 4096 +
((uintptr_t)virt_addr % 4096);
}
return 0; // Page not present 页面不存在于内存中
}Challenges
挑战
Several common misconceptions complicate understanding of MMU-kernel interactions. Developers sometimes assume the kernel performs address translation in software, not realizing that the MMU handles this autonomously. Others believe that page tables are part of the kernel's address space, when they're actually separate data structures in main memory.
一些常见的误解使 MMU 与内核交互的理解变得复杂。开发人员有时会认为内核通过软件执行地址转换,而没有意识到 MMU 会自主处理这项工作。另一些人则认为页表是内核地址空间的一部分,而实际上它们是主内存中独立的数据源结构。
Security issues can arise from improper handling of physical address information. Exposing physical addresses to user space can enable side-channel attacks or help bypass security mitigations like ASLR (Address Space Layout Randomization). Modern systems increasingly restrict access to physical address information.
物理地址信息的不当处理可能引发安全问题。向用户空间暴露物理地址可能会启用侧信道攻击,或帮助绕过地址空间布局随机化(ASLR)等安全防护措施。现代系统越来越严格地限制对物理地址信息的访问。
Performance problems often stem from excessive page faults or TLB misses. Applications that access memory in patterns that defeat the TLB cache may experience significant slowdowns. Understanding the relationship between virtual memory layout and hardware behavior becomes crucial for optimization.
性能问题通常源于过多的页面故障或 TLB 未命中。以破坏 TLB 缓存的模式访问内存的应用程序可能会出现显著的性能下降。理解虚拟内存布局与硬件行为之间的关系对于优化至关重要。
Memory fragmentation presents another challenge. While virtual memory provides each process with a contiguous address space, physical memory may become fragmented. The kernel must balance the need for large contiguous physical allocations (for DMA buffers, for example) with efficient memory utilization.
内存碎片化是另一个挑战。虽然虚拟内存为每个进程提供了连续的地址空间,但物理内存可能会变得碎片化。内核必须在对大型连续物理分配的需求(例如 DMA 缓冲区)与高效的内存利用率之间取得平衡。
Solutions
解决方案
Effective memory management requires understanding both kernel interfaces and MMU behavior. Use mmap() with appropriate flags to control caching and sharing behavior. The MAP_POPULATE flag can prefault pages to avoid later page fault overhead, while MAP_HUGETLB can reduce TLB pressure for large allocations.
有效的内存管理需要同时理解内核接口和 MMU 行为。使用带有适当标志的 mmap() 可以控制缓存和共享行为。MAP_POPULATE 标志可以预加载页面,以避免后续的页面故障开销,而 MAP_HUGETLB 可以减少大型分配的 TLB 压力。
Modern Linux systems provide several mechanisms for optimizing MMU usage. Transparent huge pages automatically promote small page allocations to larger pages when possible, reducing TLB misses. Applications can also explicitly request huge pages through the hugetlbfs filesystem or mmap() flags.
现代 Linux 系统提供了多种优化 MMU 使用的机制。透明大页面会在可能的情况下自动将小页面分配提升为大页面,减少 TLB 未命中。应用程序也可以通过 hugetlbfs 文件系统或 mmap() 标志显式请求大页面。
Memory locking with mlock() or mlockall() prevents pages from being swapped, ensuring predictable access times for real-time applications. However, locked memory consumes physical RAM and should be used judiciously.
使用 mlock() 或 mlockall() 进行内存锁定可以防止页面被交换出去,确保实时应用程序具有可预测的访问时间。然而,锁定的内存会占用物理 RAM,应谨慎使用。
NUMA (Non-Uniform Memory Access) systems require additional consideration. The kernel's NUMA policy affects which physical memory banks are used for allocations, impacting both performance and memory bandwidth utilization. Applications can influence NUMA placement through numactl or programmatic interfaces.
非均匀内存访问(NUMA)系统需要额外的考虑。内核的 NUMA 策略会影响分配使用的物理内存 bank,进而影响性能和内存带宽利用率。应用程序可以通过 numactl 或编程接口影响 NUMA 布局。

Performance Considerations
性能考量
Address translation overhead varies significantly based on TLB effectiveness. Applications with good spatial locality, accessing nearby memory addresses, experience fewer TLB misses and better performance. Conversely, applications that access memory randomly or with large strides may suffer from frequent TLB misses.
地址转换开销因 TLB 效率而异。具有良好空间局部性、访问邻近内存地址的应用程序会经历更少的 TLB 未命中,从而获得更好的性能。相反,随机访问内存或大步长访问内存的应用程序可能会频繁遭遇 TLB 未命中。
Page table walks consume memory bandwidth and cache capacity. Multi-level page tables require multiple memory accesses for each translation miss, creating bottlenecks on memory-intensive workloads. Some architectures provide hardware page table walkers that can perform multiple translations concurrently.
页表遍历会消耗内存带宽和缓存容量。多级页表在每次转换未命中时需要多次内存访问,在内存密集型工作负载中会造成瓶颈。一些架构提供了硬件页表遍历器,可以并发执行多个转换。
The kernel's page table management also affects performance. Copy-on-write semantics reduce memory usage but can cause unexpected page faults when pages are first written. Applications sensitive to latency may prefer to prefault pages or use different allocation strategies.
内核的页表管理也会影响性能。写时复制语义减少了内存使用,但在页面首次被写入时可能会导致意外的页面故障。对延迟敏感的应用程序可能更倾向于预加载页面或使用不同的分配策略。
Modern MMUs include various optimizations like page size extensions, tagged TLBs that don't require flushing on context switches, and hardware support for virtualization. Understanding these features helps in designing efficient systems software.
现代 MMU 包含多种优化,例如页面大小扩展、上下文切换时无需刷新的标记 TLB 以及虚拟化的硬件支持。了解这些特性有助于设计高效的系统软件。
Summary
总结
The Memory Management Unit and Unix/Linux kernel form a sophisticated partnership that enables modern memory management. The MMU, as a hardware component integrated into the CPU, performs rapid virtual-to-physical address translation using page tables configured by the kernel. This division of labor hardware for speed-critical translation, software for complex policy decisions provides both performance and flexibility.
内存管理单元(MMU)与 Unix/Linux 内核形成了复杂的协作关系,实现了现代内存管理。MMU 作为集成在 CPU 中的硬件组件,使用内核配置的页表执行快速的虚拟地址到物理地址的转换。这种分工------硬件负责速度关键的转换,软件负责复杂的策略决策------既保证了性能,又提供了灵活性。
Key takeaways include understanding that the MMU is hardware, not part of the kernel, though it relies on kernel-managed page tables stored in main memory. The kernel maintains awareness of physical addresses while keeping user processes isolated in virtual address spaces. Page faults represent the primary communication mechanism between MMU and kernel, allowing for sophisticated memory management techniques like demand paging and copy-on-write.
核心要点包括:MMU 是硬件,而非内核的一部分,尽管它依赖于存储在主内存中的内核管理页表。内核感知物理地址,同时将用户进程隔离在虚拟地址空间中。页面故障是 MMU 与内核之间的主要通信机制,支持请求分页和写时复制等复杂的内存管理技术。
For system programmers and administrators, this understanding enables better debugging of memory-related issues, more effective performance tuning, and informed decisions about memory allocation strategies. The MMU-kernel collaboration underlies features we take for granted: process isolation, virtual memory, and efficient memory utilization.
对于系统程序员和管理员来说,这种理解有助于更好地调试内存相关问题、更有效地进行性能调优,并在内存分配策略方面做出明智的决策。MMU 与内核的协作是我们习以为常的特性(进程隔离、虚拟内存和高效内存利用)的基础。
Modern systems continue to evolve this relationship, adding features like huge pages, NUMA awareness, and hardware virtualization support. However, the fundamental principles remain constant: hardware MMUs provide fast address translation while kernels manage the complex policies that govern memory allocation, protection, and sharing.
现代系统不断发展这种关系,增加了大页面、NUMA 感知和硬件虚拟化支持等特性。然而,基本原理保持不变:硬件 MMU 提供快速的地址转换,而内核管理着控制内存分配、保护和共享的复杂策略。
via:
- Memory Management Unit (MMU) - COMP15212 Wiki
https://wiki.cs.manchester.ac.uk/COMP15212/index.php/Memory_Management_Unit_(MMU) - How Does the Memory Management Unit (MMU) Work with the Unix/Linux Kernel?
https://chessman7.substack.com/p/how-does-the-memory-management-unit