目录
- [一. 🦁 写在前面](#一. 🦁 写在前面)
- [二. 🦁 搭建流程](#二. 🦁 搭建流程)
-
- [2.1 总体工作流展示](#2.1 总体工作流展示)
- [2.2 外部工作流搭建流程](#2.2 外部工作流搭建流程)
-
- [2.2.1 方案一---pandas + 规则解析 + 字段RAG 混合问数](#2.2.1 方案一—pandas + 规则解析 + 字段RAG 混合问数)
- [2.2.2 方案二---Text2SQL方案](#2.2.2 方案二—Text2SQL方案)
- [2.3 表格展示构建实现](#2.3 表格展示构建实现)
- [2.4 图表展示构建实现](#2.4 图表展示构建实现)
- [2.5 其它环节](#2.5 其它环节)
- [三. 🦁 写在最后](#三. 🦁 写在最后)

一. 🦁 写在前面
今天,狮子使用中国电信的智能体平台------星辰智能体平台,搭建一个基于Excel表格问数的工作流,给了两张表(一张用户个人画像表(大概120多个字段),一张订单表(大概四个个字段)),一共两万条数据,现在要做根据自然语言问数,需要返回的数据形式有多种:分别是表格、柱状图、饼图、折线图这几种。
看了一下这个平台,因为神态酷似dify,但是确实插件比较少,给的数据源数据量较大,所以决定采用外部实现一个智能体用于处理数据和提供接口,在平台http接口的形式调用,在平台内实现图表和表格生成(尽力了,真不知道在平台怎么处理这个数据源)。
现在狮子来回忆一波捏这个工作流的步骤,并且分享一下在平台上实现图表的教程!!!
二. 🦁 搭建流程
2.1 总体工作流展示
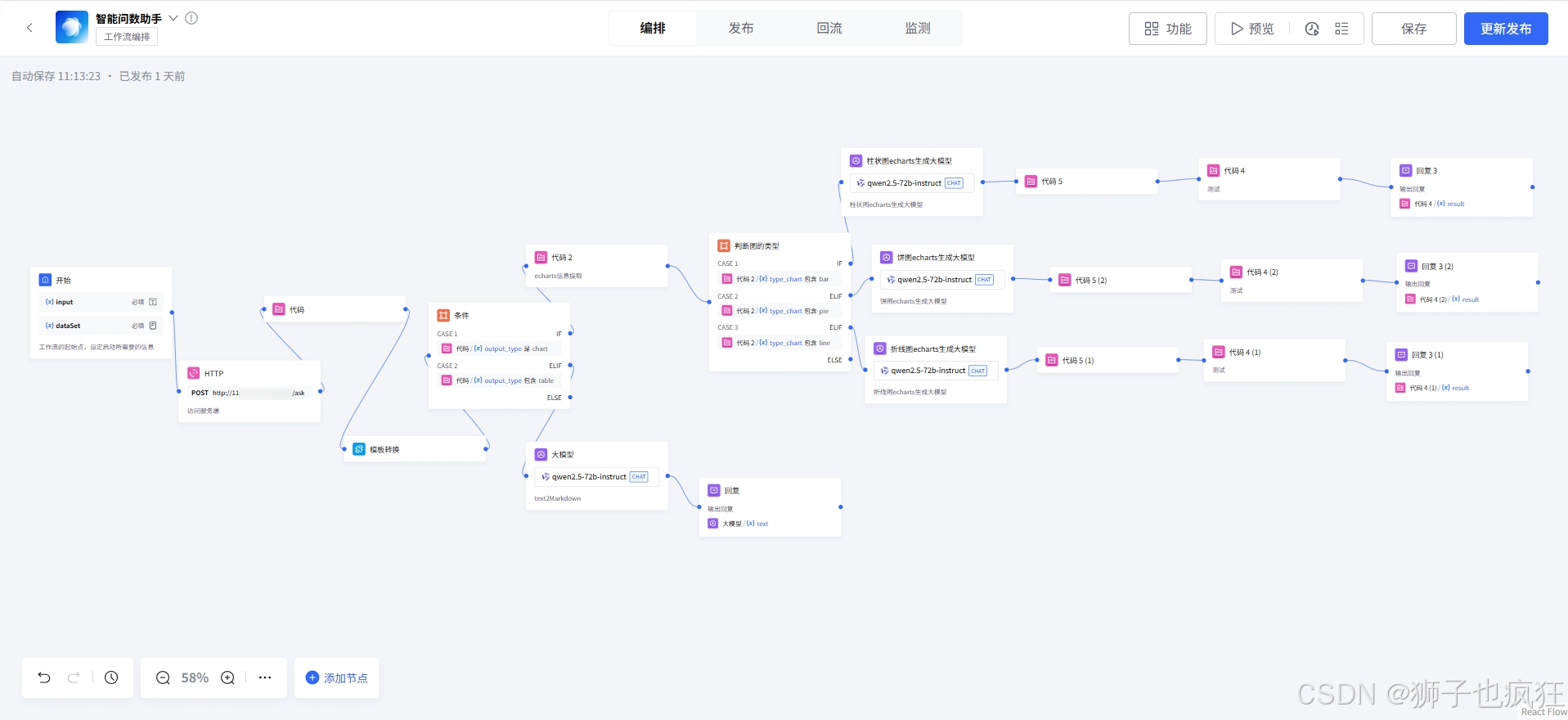
2.2 外部工作流搭建流程
这个外部工作流的作用是查询数据源,并且返回用户需要的数据!数据源格式如下:
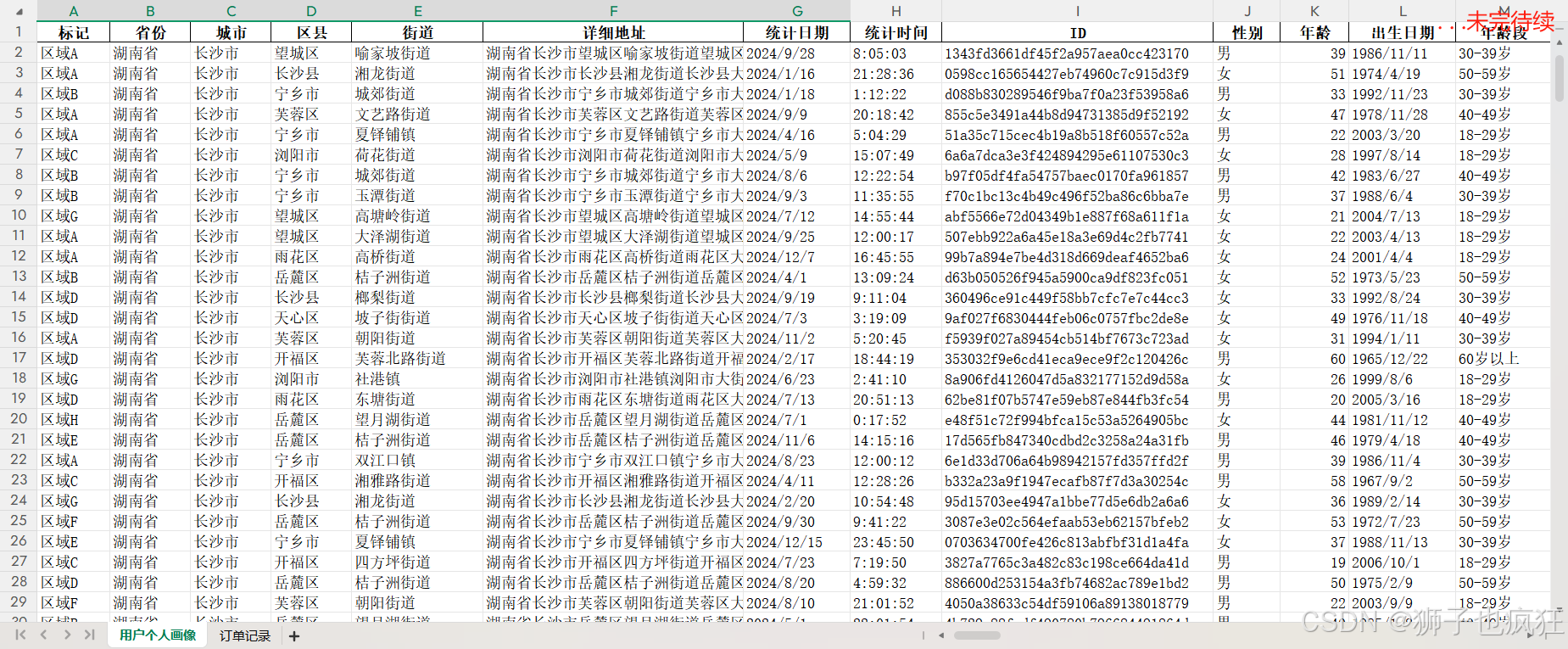
实现该流程的方案有两种。
2.2.1 方案一---pandas + 规则解析 + 字段RAG 混合问数
第一种方案就是利用pandas解析Excel表格的便捷性,将问题中的筛选条件提取出来标准化,再去Rag数据库那里检索最相关的字段说明,将检索结果与统计摘要拼成prompt交给大模型生成简短关联分析,同时通过pandas根据字段筛选出相应的数据,通过接口返回。具体流程如下:
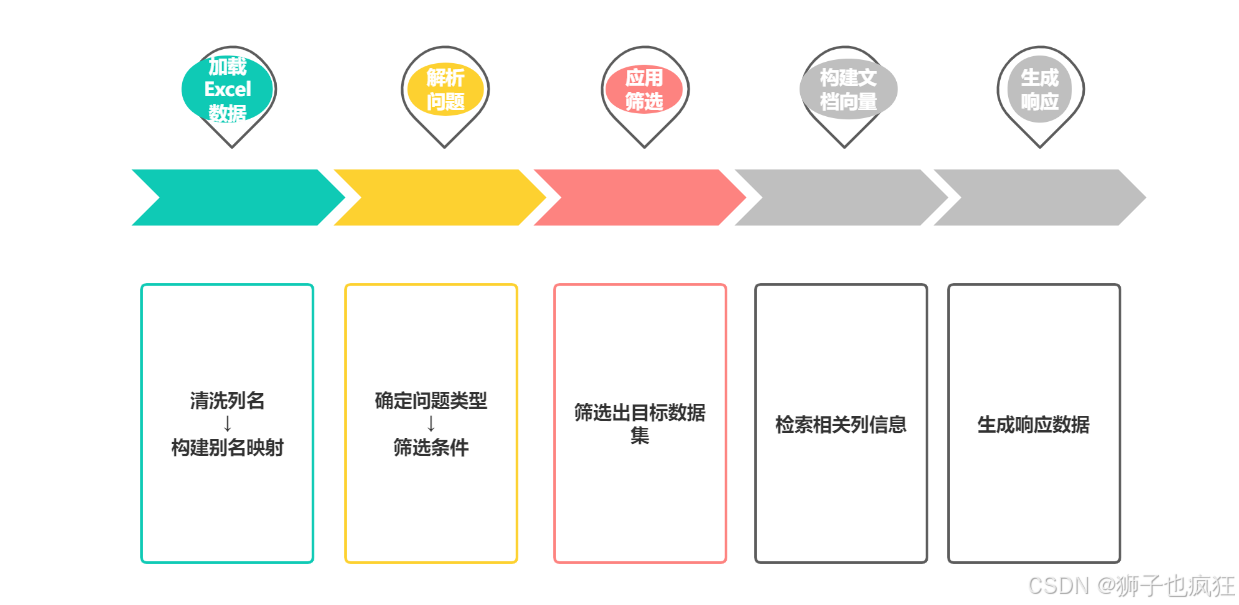
ps:
狮子选择该种方法实现问数,因为时间有点急,数据库处理很麻烦。
2.2.2 方案二---Text2SQL方案
方案二则是将Excel的数据导入到数据库(可以选择SQLite)中,然后构建Rag向量库。用户输入问题后,先去知识库筛选对应的表信息,再封装成Prompt提交给大模型,让大模型帮忙生成对应的SQL,具体实现可以参考以下流程图:
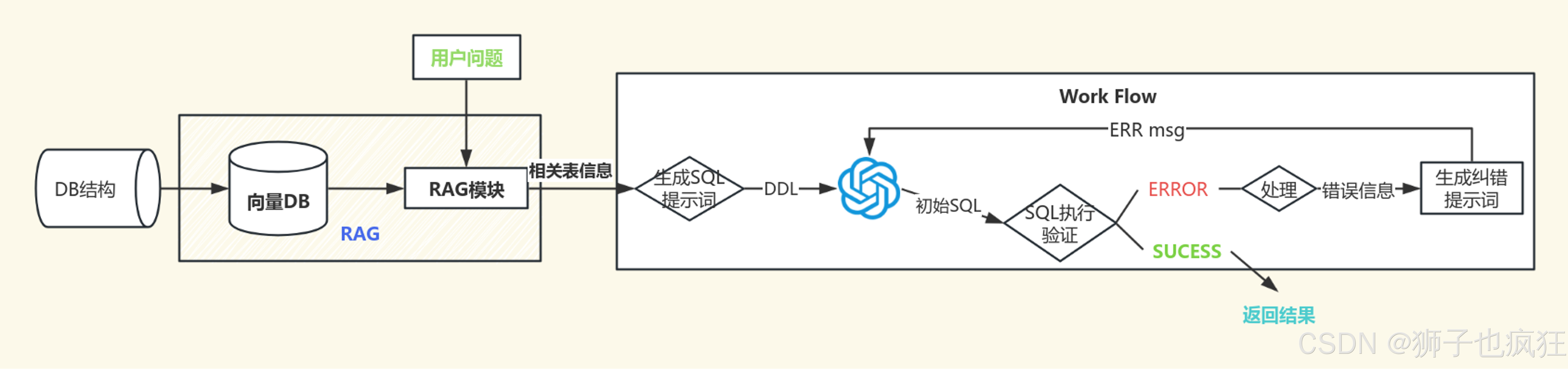
ps:
这里后续还会有具体的文章来说明!
2.3 表格展示构建实现
如果用户的问题是返回对应的列表时,则需要展示时使用表格的方式呈现,这个其实很好实现,因为智能体平台一般都支持Markdow语法的数据展示,所以直接将得到的数据通过大模型转化为表格的语法,输出则是表格的形式。这个我们通过规定的提示词给大模型则可以实现,提示词如下:
bash
1. 接收{{output#}}内容并检查其是否为空。
2. 如果输入内容为空,输出"未查询到结果请调整查询话术"。
3. 如果输入内容不为空,将提取的{{output#}}整理成表格,同时汇总数量。简洁输出
2.4 图表展示构建实现
ps:
这一步之所以能实现,完全是因为平台支持Echarts的md格式,当平台的前端界面识别到这个由三个反引号包裹、并标记为
echarts的代码块时,便会自动将其渲染为交互式图表
图表展示这块,我们肯定使用熟悉的Echarts组件库,官网地址如下:https://echarts.apache.org/examples/zh/index.html,在官网我们可以看到其实每种图都有一个代码模板的,比如折线图:
javascript
{
"title": {
"text": "{{ CHART_TITLE | default('Chart') }}",
"left": "center"
},
"tooltip": {
"trigger": "axis",
"axisPointer": {
"type": "cross"
},
"formatter": "{b} : {c}"
},
"xAxis": {
"type": "category",
"data": {{ data.labels | tojson }},
"boundaryGap": false
},
"yAxis": {
"type": "value",
"name": "{{ Y_AXIS_NAME | default('Y') }}"
},
"series": [{
"name": "{{ SERIES_NAME | default('Series') }}",
"type": "line",
"data": {{ data.values | tojson }},
"smooth": true,
"lineStyle": {
"color": "rgba(54, 162, 235, 1)",
"width": 2
},
"itemStyle": {
"color": "rgba(54, 162, 235, 0.8)"
},
"areaStyle": {
"color": "rgba(54, 162, 235, 0.1)"
}
}]
}我们每次只要将不同的数据填充进来,就能都得到不同数据的折线图,但是我们通过接口传过来的数据是json字符串,那应该如何将这个数据填充进Echarts模板呢?
这时候可以使用到大模型来帮我们完成,需要编写一段提示词,将json的数据对象提取出来交给大模型,大模型就会根据提示词将数据给我们格式化为Echarts代码。提示词如下:
powershell
你是一个专业的ECharts数据可视化专家。根据用户提供的数据,使用提供给您的模板,生成标准的折线图ECharts配置。
用户数据:{{#1765639035525.chart_data#}}
提供给您的模板:
"
# 折线图模板
适用场景:展示数据随时间的变化趋势
模板代码:
```json
{
"title": {
"text": "{{ CHART_TITLE | default('Chart') }}",
"left": "center"
},
"tooltip": {
"trigger": "axis",
"axisPointer": {
"type": "cross"
},
"formatter": "{b} : {c}"
},
"xAxis": {
"type": "category",
"data": {{ data.labels | tojson }},
"boundaryGap": false
},
"yAxis": {
"type": "value",
"name": "{{ Y_AXIS_NAME | default('Y') }}"
},
"series": [{
"name": "{{ SERIES_NAME | default('Series') }}",
"type": "line",
"data": {{ data.values | tojson }},
"smooth": true,
"lineStyle": {
"color": "rgba(54, 162, 235, 1)",
"width": 2
},
"itemStyle": {
"color": "rgba(54, 162, 235, 0.8)"
},
"areaStyle": {
"color": "rgba(54, 162, 235, 0.1)"
}
}]
}
## 关键点说明:
- 数据输入结构
- 使用 data.labels 和 data.values 两组数据来驱动 X 轴时间数据和折线的数值。
- data.labels 与 data.values 的长度应一致,确保一一对应。
- 默认值与容错
- CHART_TITLE 使用 default('Chart'),如果未提供就显示"Chart"。
- Y_AXIS_NAME 使用 default('Y'),SERIES_NAME 使用 default('Series')。
- 数据通过 tojson 安全渲染,避免 JSON 转义问题。
- 单/多线扩展
- 该模板当前设计为单系列折线图;若未来需要多系列,可以在 series 中添加更多对象,并把数据结构调整为多组 data.values(或提供一个 series_list)。
- 显示与样式
- smooth 设置为 true,呈现平滑曲线。
- areaStyle 提供区域填充,颜色为浅蓝色调,便于对比趋势。
- xAxis 的 boundaryGap 设置为 false,便于时间序列数据紧贴边界显示。
- 语言一致性
- 演示中的占位符名为英文,默认文本也尽量使用英文;实际显示文本可按需要由数据源提供英文或翻译后文本。
"
请严格按以下步骤操作:
1. 从检索结果中选择最匹配的图表模板
2. 将用户数据按ECharts标准格式填入占位符
3. 输出完整且可直接使用的ECharts option配置
输出要求:
- 必须输出标准的ECharts option JSON格式
- 所有占位符{{}}必须被实际数据替换
- 确保JSON语法完全正确,可直接用于echarts.setOption()
- 数据格式严格遵循ECharts规范:
* 字符串用双引号包围
* 数组格式正确:["item1", "item2"]
* 数值不加引号:[100, 200, 300]
- 图表标题简洁明了,符合数据内容
输出格式示例:
echarts
{
"title": {
"text": "Monthly Sales Data",
"left": "center"
},
"tooltip": {
"trigger": "axis",
"axisPointer": {
"type": "cross"
},
"formatter": "{b} : {c}"
},
"xAxis": {
"type": "category",
"data": ["January", "February", "March", "April", "May", "June"],
"boundaryGap": false
},
"yAxis": {
"type": "value",
"name": "Sales Amount"
},
"series": [{
"name": "Sales",
"type": "line",
"data": [120, 200, 150, 300, 250, 400],
"smooth": true,
"lineStyle": {
"color": "rgba(54, 162, 235, 1)",
"width": 2
},
"itemStyle": {
"color": "rgba(54, 162, 235, 0.8)"
},
"areaStyle": {
"color": "rgba(54, 162, 235, 0.1)"
}
}]
}
注意:输出的JSON必须能够直接复制粘贴到ECharts中使用,不允许有任何语法错误。这样就可以将我们的数据转换成Echarts的格式了,但是到这里还不行,我们还需要将大模型生成的代码整理成md格式的代码,这里就直接使用代码来处理了,具体代码示例如下:
python
import json
def main(option=None):
# 如果没有传入 option,给一个默认版本(中文文本示例)
if option is None:
option = {
"title": {
"text": "BMI Distribution",
"left": "center"
},
"grid": {
"left": "8%",
"right": "4%",
"bottom": "6%",
"containLabel": True
},
"tooltip": {
"trigger": "axis",
"axisPointer": {
"type": "line"
},
"formatter": "{b} : {c}"
},
"xAxis": {
"type": "category",
"data": ["BMI>=24", "BMI<=20"]
},
"yAxis": {
"type": "value",
"name": "Count"
},
"series": [{
"name": "Population",
"type": "bar",
"data": [3294, 1985],
"barWidth": "20%",
"barMaxWidth": 40,
"itemStyle": {
"color": "rgba(255, 99, 132, 0.8)"
}
}]
}
# 如果 option 是字符串,尝试解析为字典
if isinstance(option, str):
try:
option = json.loads(option)
except Exception as e:
return {"error": f"Invalid JSON string: {e}"}
# 现在 option 应该是一个字典
try:
option_json = json.dumps(option, indent=2, ensure_ascii=False)
output = "```echarts\n" + option_json + "\n```"
return {"result": output}
except Exception as e:
return {"error": str(e)}效果展示:
ps:
有人会问,为什么不用大模型直接生成md格式的Echarts代码?
这里也是可以这么做的,但是我觉得让大模型专心处理一件事情就好了,怕出错!
另外,其它类型的表也是按上面一样的方法,只是把折线图的模板换成其它类型,这一步可以通过AI完成。
2.5 其它环节
主要环节搭建已经完成,其它环节就是对数据的一些处理,无非就是新增一些节点来处理数据,我这里搭建的很匆忙,有很多节点处理得不好,其实有很多步都是可以优化的,总体还是显得有些冗余。
三. 🦁 写在最后
从Excel数据到最终的交互图表,这个项目完整地实践了如何将一个复杂的业务需求,拆解、封装成一个个可控的技术模块,并通过智能体平台进行高效组装。
🦁 其它优质专栏推荐 🦁
🌟《Java核心系列(修炼内功,无上心法)》: 主要是JDK源码的核心讲解,几乎每篇文章都过万字,让你详细掌握每一个知识点!
🌟 《springBoot 源码剥析核心系列》:一些场景的Springboot源码剥析以及常用Springboot相关知识点解读
欢迎加入狮子的社区 :『Lion-编程进阶之路』,日常收录优质好文
更多文章可持续关注上方🦁的博客,2025咱们顶峰相见!