OpenCL 是一个由 Khronos Group(一个行业协会,也负责 OpenGL 和 Vulkan 等标准)维护的开放、免授权费的标准。它定义了一个用于编写并行程序的框架,这些程序可以在 CPU、GPU、FPGA(现场可编程门阵列)和其他类型的异构处理器上高效执行。
OpenCL 的核心价值在于其跨平台性 和异构性,它旨在为并行计算提供一个统一的编程模型,避免厂商锁定。
1. OpenCL 编程模型的核心概念
OpenCL 编程模型分为两个主要部分:主机端(Host)和设备端(Device)。
1.1 主机端(Host):管理与控制
主机端程序(通常在 CPU 上运行)使用 C/C++ 编写,通过 OpenCL API 来管理计算资源和控制并行执行流程。
-
平台(Platform): 指硬件厂商提供的 OpenCL 实现(如 NVIDIA、AMD、Intel)。
-
设备(Device): 计算设备,可以是 CPU、GPU、FPGA 或其他加速器。
-
上下文(Context): 协调主机和设备之间操作的环境,管理设备集合、内核、内存对象和命令队列。
-
命令队列(Command Queue): 主机用于向设备发送指令(如内存传输和内核执行)的通道。命令队列中的操作可以是同步 或异步的。
1.2 设备端(Device):并行计算
设备端代码(Kernel)使用 OpenCL C 语言编写,这是一种基于 C99 标准的扩展语言,用于在设备上执行并行计算。
-
内核(Kernel): 实际在设备上执行的并行函数。
-
执行模型: OpenCL 定义了与 CUDA 相似的线程执行模型。
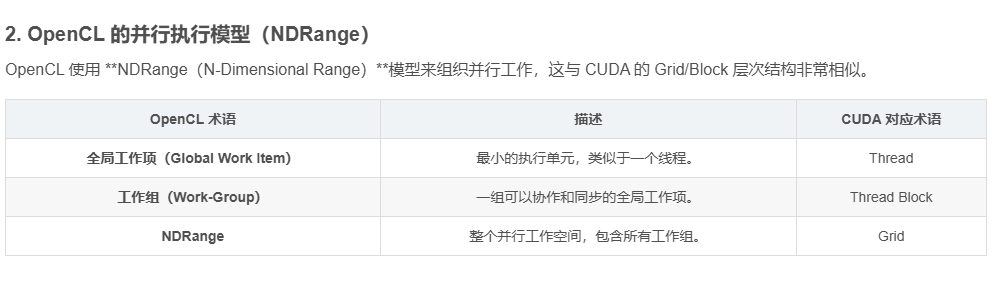
2. OpenCL 的并行执行模型(NDRange)
OpenCL 使用 **NDRange(N-Dimensional Range)**模型来组织并行工作,这与 CUDA 的 Grid/Block 层次结构非常相似。
| OpenCL 术语 | 描述 | CUDA 对应术语 |
|---|---|---|
| 全局工作项(Global Work Item) | 最小的执行单元,类似于一个线程。 | Thread |
| 工作组(Work-Group) | 一组可以协作和同步的全局工作项。 | Thread Block |
| NDRange | 整个并行工作空间,包含所有工作组。 | Grid |
3. 内存模型:跨越主机与设备
OpenCL 内存模型定义了不同级别的存储器,以便在主机和设备之间以及设备内部进行数据交互。
| 内存类型 | 描述 | 访问范围 | CUDA 对应内存 |
|---|---|---|---|
| 主机内存 | CPU 上的系统内存。 | Host | Host Memory |
| 全局内存(Global Memory) | 设备上的主存储器(如显存),主机和所有内核可见。 | Global | Global Memory |
| 局部内存(Local Memory) | 设备上快速的片上存储器,供同一工作组内的所有工作项共享。 | Work-Group | Shared Memory |
| 私有内存(Private Memory) | 仅供单个工作项使用的寄存器或缓存。 | Work Item | Registers |
4. OpenCL 的优势与挑战
4.1 优势:跨平台与开放性
-
真正的跨平台性: 能够真正在 Intel CPU、Intel iGPU、AMD GPU、NVIDIA GPU、以及 Altera/Xilinx 的 FPGA 上运行相同的 OpenCL 代码。
-
开放标准: 作为开放标准,它避免了开发者被锁定在任何单一的硬件供应商生态系统中。
4.2 挑战:竞争与性能
-
与 CUDA 的竞争: 在 GPU 计算领域,NVIDIA 的 CUDA 具有成熟的生态系统、更丰富的工具链和更强大的库(cuDNN, cuBLAS)。在深度学习等领域,CUDA 仍占据主导地位。
-
性能考量: 由于 OpenCL 必须支持各种异构硬件,其抽象层有时可能不如针对特定硬件优化的原生 API(如 CUDA)高效。开发者需要投入更多精力来优化内存访问和线程配置。
-
易用性: OpenCL 的 API 相对底层和冗长,需要开发者手动管理设备、上下文、命令队列和内存对象,学习曲线较陡峭。
5. 总结
OpenCL 是一个强大的异构计算标准,它提供了在多种处理器上编写并行程序的能力。
-
定位: 适用于科学计算、信号处理、密码学等需要硬件多样性和跨平台兼容性的领域。
-
发展: 尽管在深度学习领域,它受到了 cuDNN/CUDA 的强力挑战,但 OpenCL 仍然是许多厂商(尤其是非 NVIDIA 硬件)和 HPC 社区用于实现底层异构加速的首选开放标准。