此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本周为第四课的第三周内容,这一课所有内容的中心只有一个:计算机视觉 。应用在深度学习里,就是专门用来进行图学习的模型和技术,是在之前全连接基础上的"特化",也是相关专业里的一个重要研究大类。
这一整节课都存在大量需要反复理解的内容和机器学习、数学基础。 因此我会尽可能的补足基础,用比喻和实例来演示每个部分,从而帮助理解。
第三周的内容将从图像分类 进一步拓展到目标检测(Object Detection) 这一更具挑战性的计算机视觉任务。
与分类任务只需回答"图中有什么"不同,目标检测需要同时解决" 有什么 "以及"在什么位置 "两个问题,因此在模型结构设计、训练方式和评价标准上都更为复杂。
本篇的内容关于目标检测算法。
1. 检测算法1.0:对窗口分类
我们知道,想要实现目标检测,首先就要完成目标识别 。
只有当模型能够回答"要找什么 "后,我们才有可能进一步让它回答"它在哪里"。
在早期,人们并没有一套专门为"检测"设计的网络结构,于是有人提出了这样一种想法:既然分类网络已经很成熟,那能不能把"找位置"这个问题,转化成一堆"分类问题"?
而实现这种逻辑的具体做法就是滑动窗口(Sliding Window) 。
在这种方法中,我们用一个固定大小的窗口 在整张图像上从左到右、从上到下不断滑动 ,把图像裁剪成一块一块的小区域。
然后,将每一个窗口都单独送入一个已经训练好的图像分类网络 中,判断这个窗口里"有没有目标"。
如果某个窗口被分类器判断为"汽车""行人"等目标类别,那么我们就认为:目标就出现在这个窗口所对应的位置上。
就像这样:
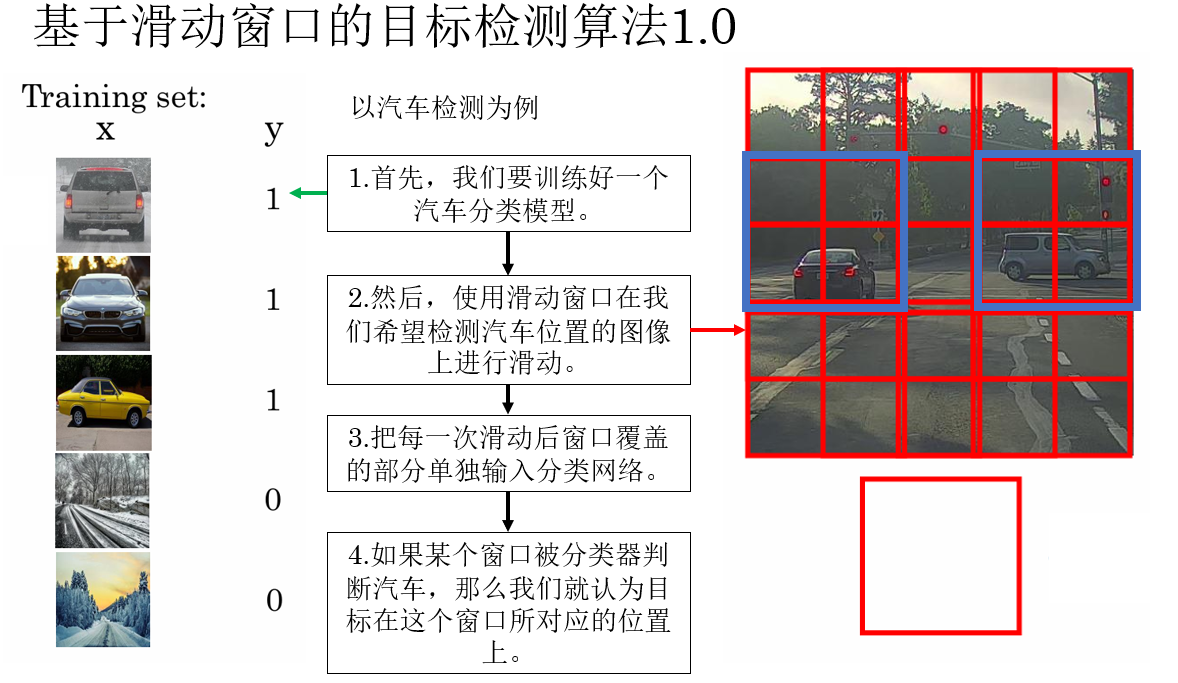
从整体上看,这种检测流程可以被理解为:
- 用滑动窗口 枚举可能的位置
- 用分类网络 判断每个位置是什么
- 将被判定为目标的窗口位置,作为最终的检测结果
但显然,即使假设分类器完全准确,这种算法仍有它的不足之处。
对于滑动窗口,我们可以设置它的尺寸和步长 来调整它在图像中的运动轨迹,这种固定的设置都十分死板,且同时很难兼顾不同大小目标的完整覆盖 。
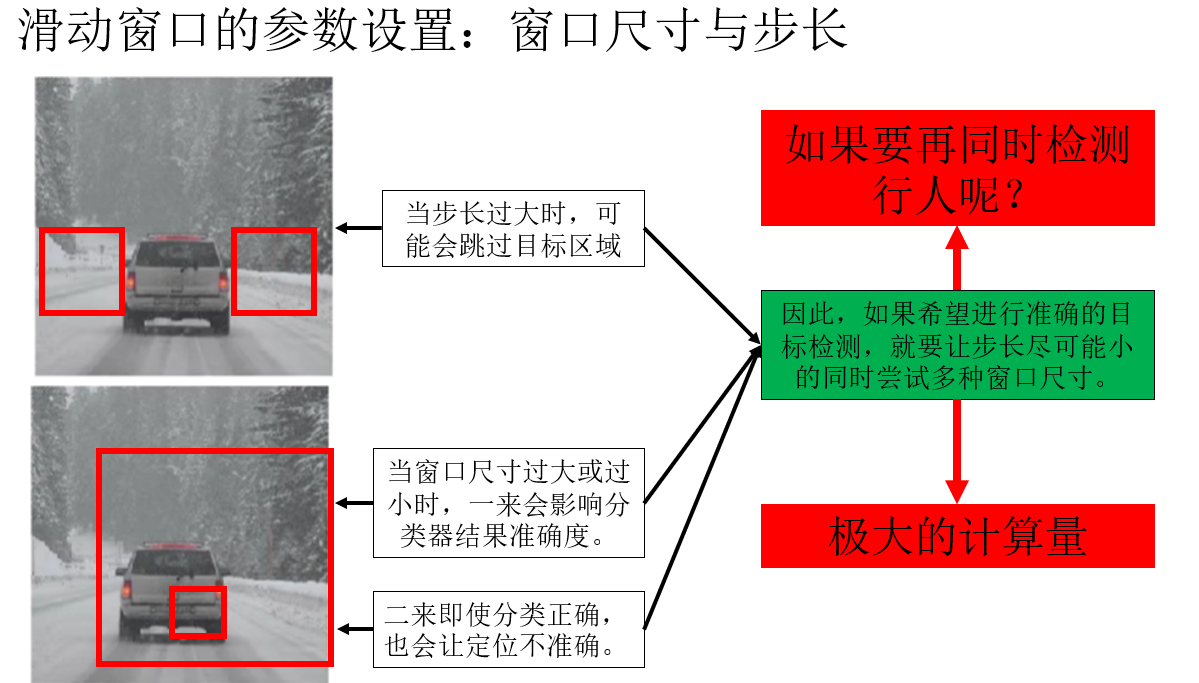
因此,你会发现这种检测方法其实是一种"取巧",它本质上并没有"直接学位置",而是通过大量的局部分类结果 ,间接拼凑出目标的位置,在依赖单独训练的分类器准确率的前提下还需要极大的计算量。
于是下一步改进出现了。
2. 检测算法2.0:对整幅图像应用卷积
为了更好地进行目标检测,面对 1.0 中出现的极大计算量问题,人们运用数学逻辑,发现了这样一种情况:当为了更精准的检测而应用更小步长的窗口时,相邻的窗口存在公共区域,让部分计算重复进行。
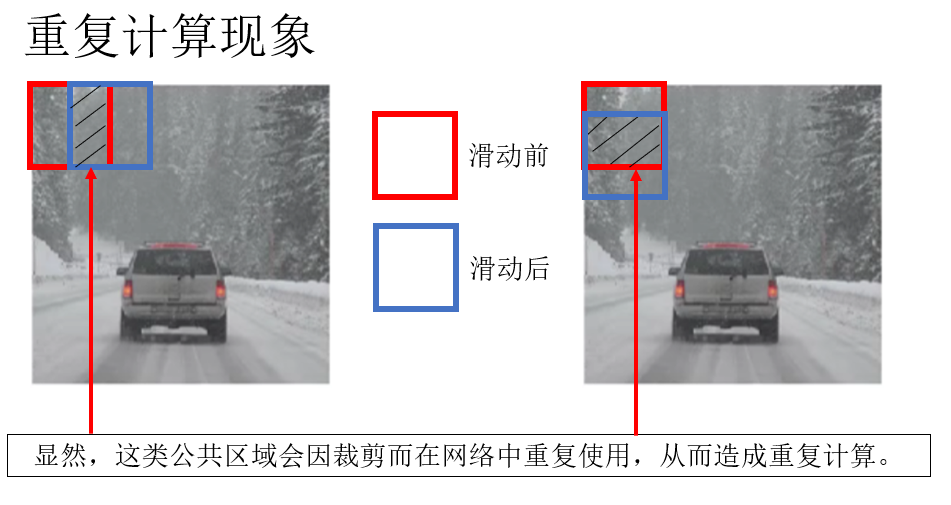
而如果不希望出现公共区域,那就又要增大步长至和尺寸同大小,就又回到了漏检小目标、定位不精确的问题。
有没有一种办法,既能享有小步长带来的精确度,又能让重复计算的结果复用从而及减小计算量呢?
有的兄弟,有的。
在 2014 年,一篇名为 OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 的论文发表,提出了一个利用卷积神经网络同时实现分类、定位和检测 的统一框架。
而相比 1.0 算法,2.0 最大的改变就是不再把每个窗口裁出来送进网络,而是直接把整张图像送进网络,让卷积层自动完成"滑动 + 特征提取"的过程,直接输出图像各部分的分类结果。
我们来详细展开这一部分:
2.1 修改网络结构适应输出要求
明确了目标之后,你会发现,不同于原本使用全连接层输出一维分类结果,现在我们希望让输出为一个二维特征图,图中每一个元素就代表一个窗口的分类结果 。
就像这样:
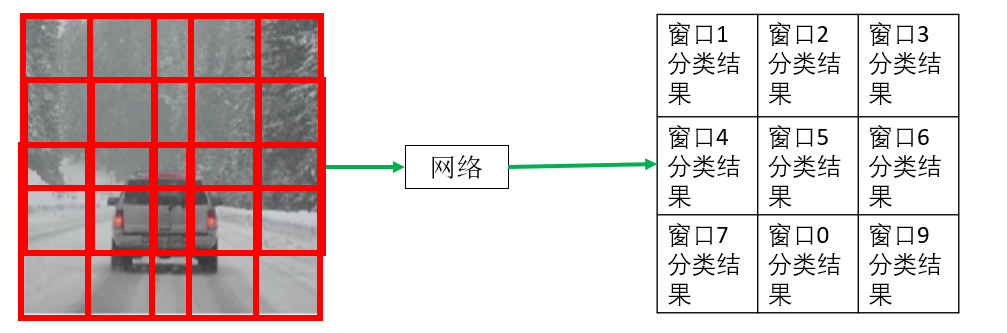
因此,现在我们需要修改网络结构,使用卷积层取代原本的全连接层,保证输出同样为特征图 。
而要合理地实现这一部分,首先,就要了解如何用卷积层等效代替全连接层。
先说结论:使用和输入特征图尺寸等大小的卷积核 。
就像这样:
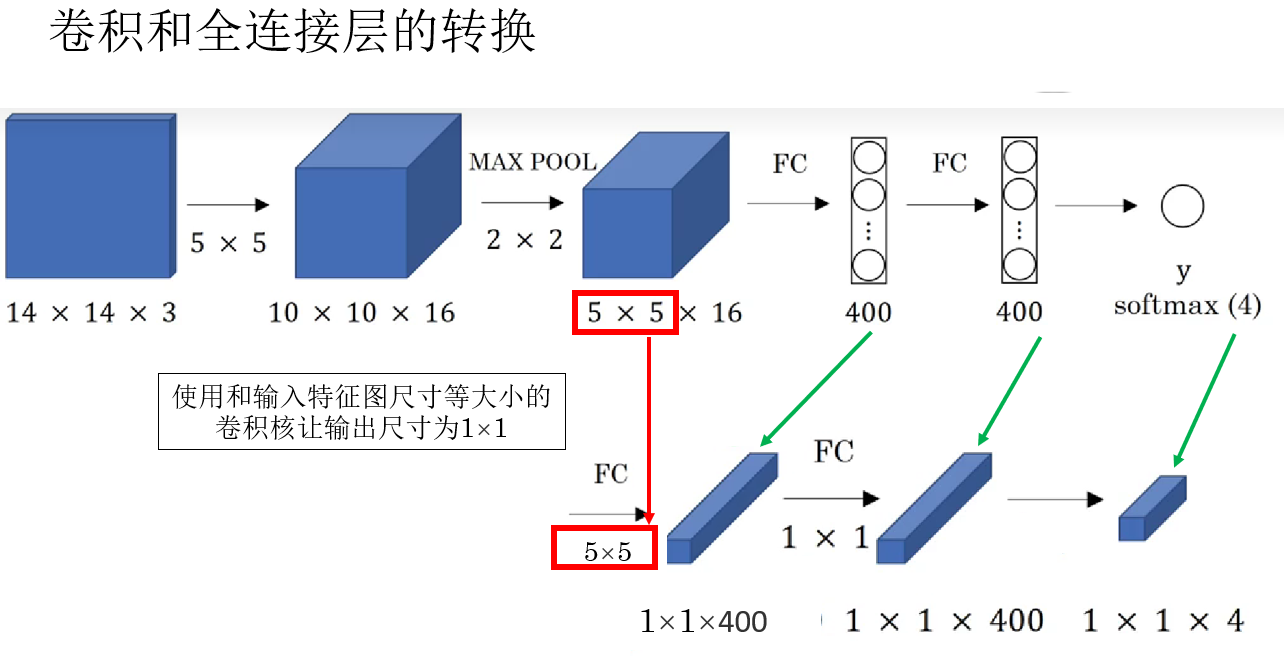
再展开说说原理:
在分类网络中,当特征提取部分结束后,输入全连接层的,通常是一个形状为 \(H \times W \times C\) 的特征图。
全连接层做的事情,本质上是: 把这整个特征图"摊平",然后与一组权重做一次线性组合,输出一个结果。
如果用公式表示,就是:
\y = \\sum_{i,j,k} w_{i,j,k} \\cdot x_{i,j,k} + b \\
换一个角度看,这个过程其实非常像什么? ------用一个和输入特征图尺寸完全一致的卷积核,在特征图上做一次卷积。
因此,当卷积核的尺寸等于输入特征图的空间尺寸时:
- 卷积核只会在输入上"滑动"一次。
- 卷积输出自然就是一个 \(1 \times 1\) 的结果。
- 这个结果与全连接层的输出在数学形式上是完全等价的。
因此可以得到一个直观的结论:全连接层可以被看作一种特殊形式的卷积层。
现在,我们就了解了如何修改我们原本一直使用的全连接层作为输出层的网络结构,从而适应输出为带有空间结构的特征图的要求。
现在,就来看看,输入整幅图像进入完善后的网络得到分类输出的具体过程。
2.2 窗口在网络中的传播
我们就用课程里的例子来演示一下网络如何一次输出整幅图像各个窗口的分类结果:
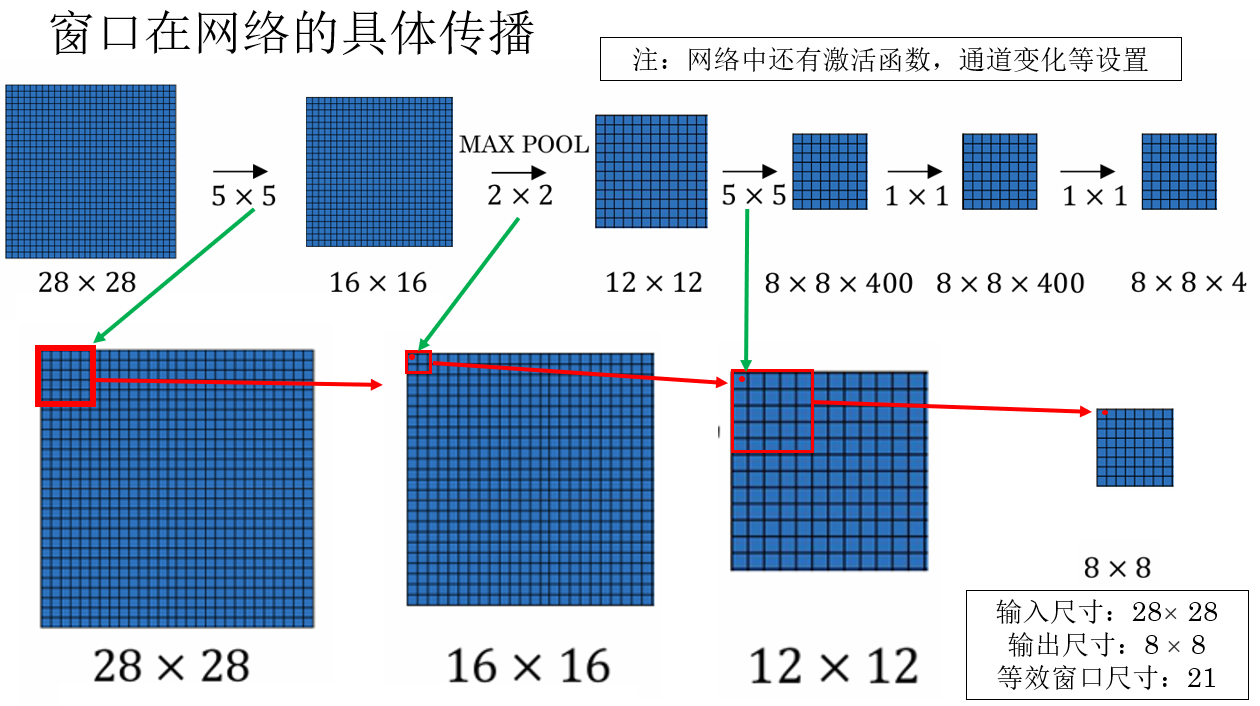
你会发现,得益于卷积操作的特性,输入图像的局部特征本身就在传播中被一步步集中,第一层特征图中的每一个像素,本身就对应着输入图像中的一个小窗口 。
而随着网络不断加深,卷积层不断堆叠,每一个特征点所对应的输入区域不断变大。
最终,在靠近输出层的位置,特征图中的一个位置 实际上已经"覆盖"了输入图像中的一个较大窗口区域 。
只不过现在窗口不再由我们手动裁剪,而是由网络结构决定。
2.3 拓展:特征图输出的标签问题
到这里,我想你可能会有这样一个问题:我们虽然改变了网络结构,但是我们这时使用的还是原本分类器的数据,即对一幅图像的标签只有一个0或1来表示图像里是否存在目标。现在我们修改了输出格式,是否需要也修改标签,改为给每个窗口打标签?
答案是不用。
为什么?
虽然在训练阶段,网络接收到的仍然只是图像级别的分类标签 ,但由于输出已经被展开为一个带空间结构的特征图,这个标签会被隐式地约束到整张特征图上:只要某一个位置对应的窗口能够正确响应目标类别,这一次预测就被认为是"成功的"。
换句话说,卷积化之后的分类网络,并不是在学习"这整张图像是不是目标",而是在学习:"在这张图像的哪些位置,存在一个可以被识别为目标的窗口"。
有些抽象,我们可以来看一个具体的例子:
假设训练集中有一张图片,内容是一辆汽车,整张图像的唯一标签 就是「car」。
当这张图像被送入卷积化后的网络时,输出的不再是一个标量,而是一个 \(H' \times W'\) 的分类特征图,其中每一个位置 都对应输入图像中的一个窗口。
在初始训练阶段,这张特征图上的绝大多数位置,输出的分类结果其实都是错误的:
- 有的位置覆盖的是背景
- 有的位置只覆盖了汽车的一部分
- 还有的位置甚至只包含天空或道路
但这并不会破坏训练过程。
因为此时网络的目标并不是要求每一个位置都预测为 car,而是至少存在某一个位置,其对应的窗口能够对 car 类别产生足够强的响应。
更准确地说,在训练阶段,并不是直接将整个 \(H' \times W'\) 的输出特征图与图像级标签逐位置对齐计算损失。
网络通常会先在空间维度上进行一次聚合操作(最常见的是取最大响应),将整张特征图压缩为一个标量预测,再与图像级标签计算分类损失。
这种训练方式可以被理解为一种弱监督学习 :
只要输出特征图中存在某一个空间位置,对目标类别产生了足够强的响应,这张图像就被认为预测正确。
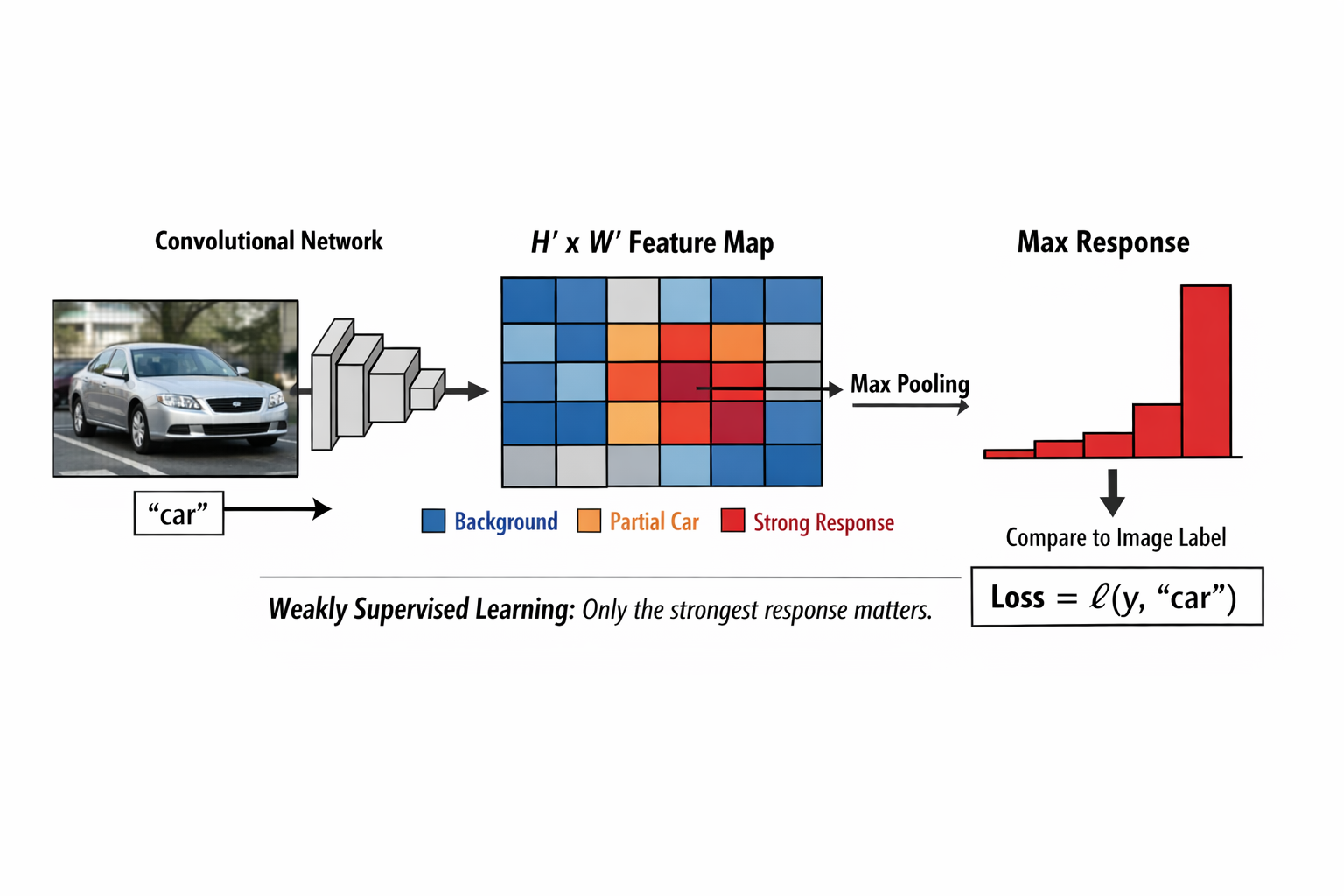
在反向传播过程中,梯度主要会通过这些高响应位置回传,从而推动网络逐渐强化那些确实覆盖了完整目标或关键判别区域的空间位置,而对背景区域的响应自然被压低。
最终,在输出特征图上,你会看到:只有少数几个位置对 car 类别产生明显高响应,而这些位置恰好落在汽车所在的区域附近。
此时,虽然训练标签始终只是一个"图像级标签",但网络已经自动学会了在空间维度上区分"哪里值得响应"。
于是我们就解决了 1.0 算法导致的极大计算量问题,但是还有一个问题仍然存在,就是固定尺寸的窗口仍无法实现对目标的较精准定位。
怎么解决?来看看 3.0 算法。
3. 检测算法3.0:YOLO 算法
YOLO 算法是目前真正主流的算法之一,你可以在目前几乎目标检测的所有领域看到它的身影,时至今日,它仍在不断地更新。
虽然在 2.0 中,窗口已经不再由人手工滑动,而是由网络结构隐式决定,但本质并没有变:
网络输出的是: "这个窗口里有没有目标" ,而不是:"目标在哪里、是什么、边界在哪。"
也就是说,2.0 的网络会告诉你: "这里大概有个 car",但不会直接告诉你:"car 的中心在这,宽高是多少。"
它的定位准确度问题仍然存在且不可忽视。
于是,在 2015 年,一篇名为You Only Look Once的论文被发表,它的核心观点就是:能不能让网络别再纠结"窗口",而是直接预测目标本身?
论文本身较为复杂,我们来看看 YOLO 相对 1.0、2.0 最关键的改变:规范目标检测任务的标签。
YOLO 算法本身为目标检测任务提出了专用的标签,正是我们在上一篇中介绍的"位置信息 "。
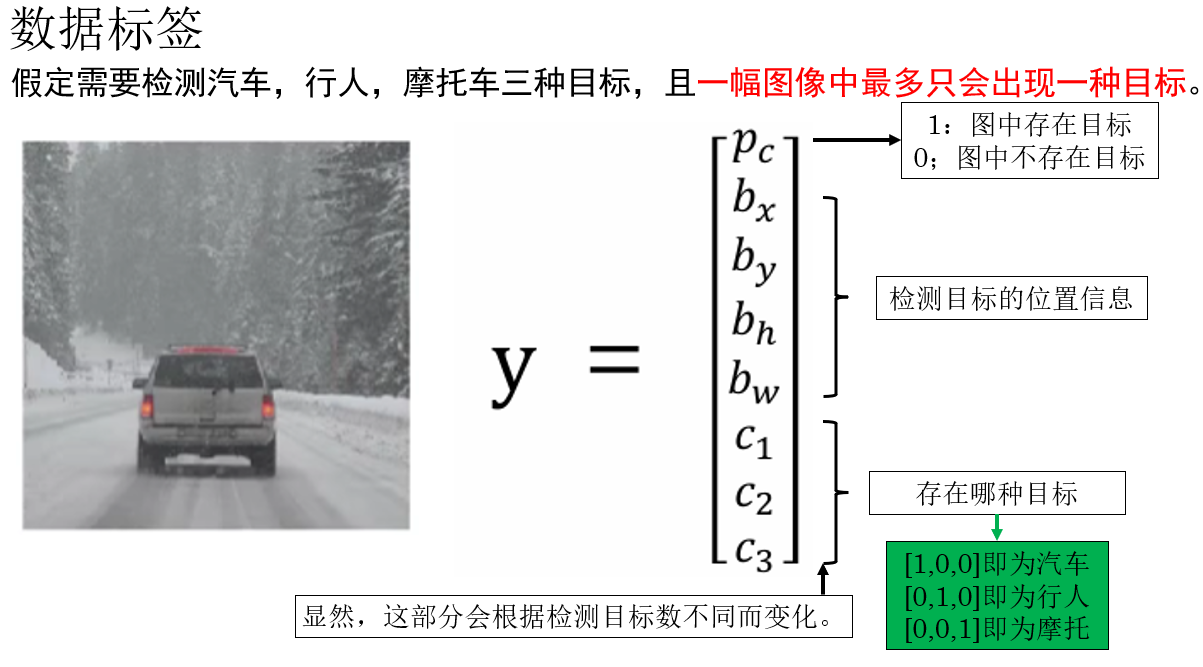
- \(p_c\):表示当前图像中是否存在需要检测的目标 ,这是一个二值变量,通常取值为 \(0\) 或 \(1\)。
当 \(p_c = 1\) 时,表示图像中确实存在目标,此时后续的位置信息和类别信息才是"有效"的;
当 \(p_c = 0\) 时,表示图像中不存在目标,其余参数通常被忽略或置为 0。 - \(b_x,b_y,b_h,b_w\) :表示检测目标的位置信息。
- \(c_n\):表示目标所属的类别信息 。
在二分类问题中,它可以是一个标量;
在多分类问题中,通常采用 独热编码 的形式,用一个向量来表示目标属于哪一类。
规范好标签本身后,我们来看看算法如何使用标签:
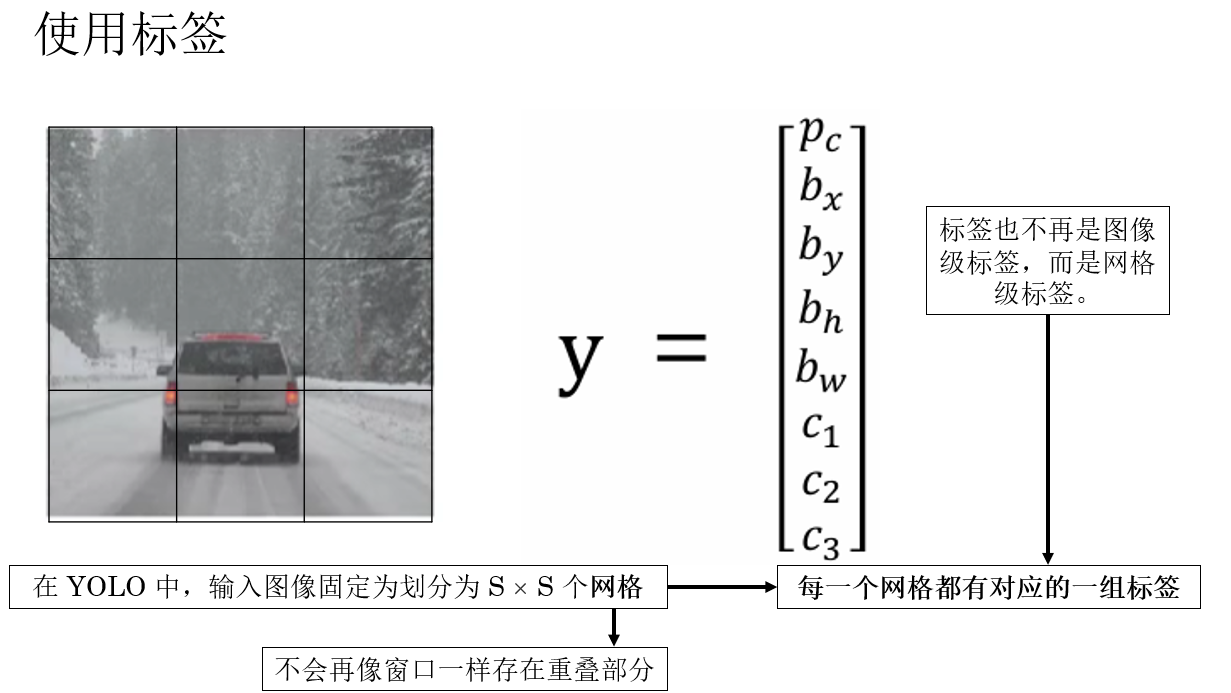
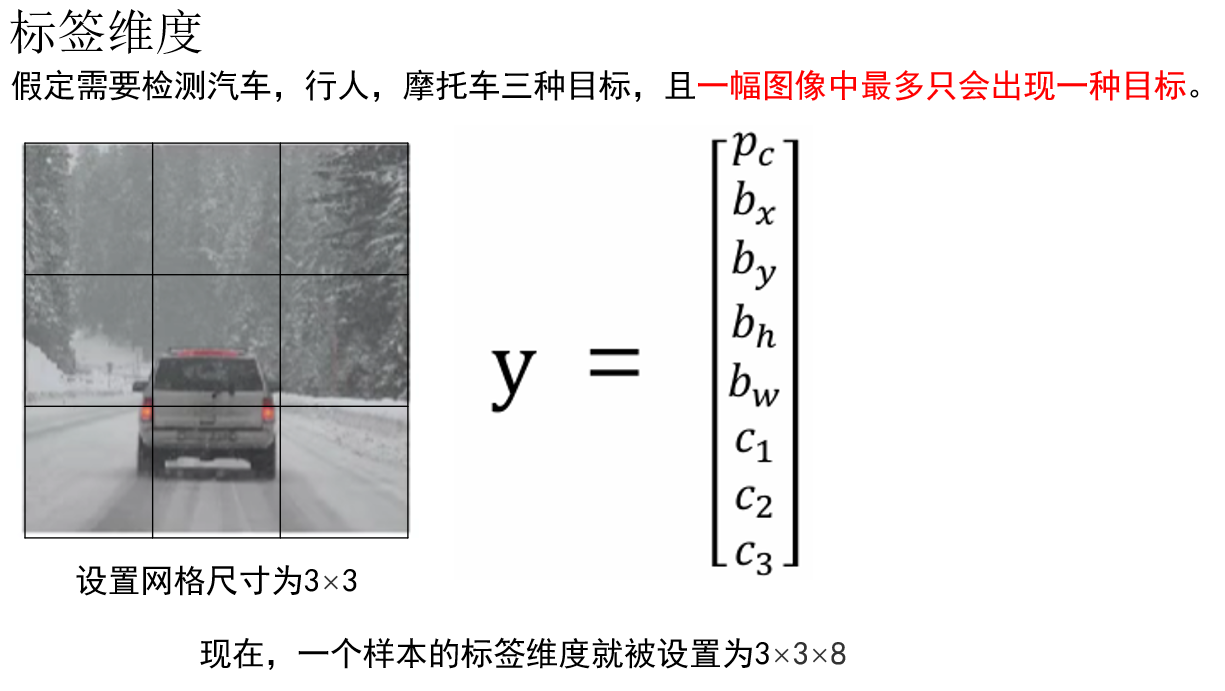
因此,一个样本在 \(S \times S\) 网格划分下,其标签张量维度为:
\S \\times S \\times (5 + c_n) \\
看到这里,你可能会疑惑,划分网格的作用是什么?我们最开始说 YOLO 避开了窗口又是指什么?
别急,关键点就在于我们刚刚规范的新标签:\(b_x,b_y,b_h,b_w\) 。
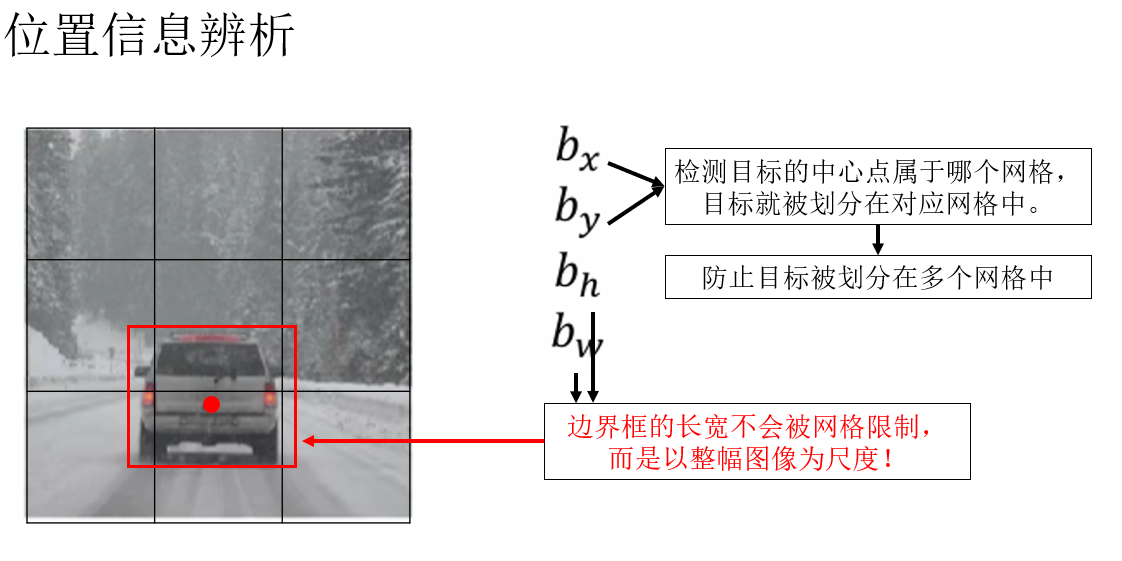
你会发现,通过几个位置信息参数,我们虽然划分了网格,但是网格却不会像窗口的步长一样限制目标的边界框,每个网格单元相当于一个预测单元来预测中心点在本单元格里的目标的类别和边界框。
现在,我们就可以继续应用 2.0 中的网络,调整输出特征图为新的标签维度,即可以此计算损失并反向传播了。
你会发现,YOLO 的核心优势是:
- 不再枚举窗口,不再重复计算。
- 每个网格单元独立负责预测目标,同时输出边界框和类别。
- 训练时即可端到端优化,预测阶段一次前向传播完成整图检测。
可以说,YOLO 的提出让"检测"真正从"分类的延伸"脱离出来,成为计算机视觉领域的核心任务之一,它的内容还有很多,我们遇到再慢慢展开。
4.总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 1.0 滑动窗口检测 | 使用固定大小窗口在图像上滑动,将每个窗口送入分类网络判断是否包含目标;通过局部分类结果间接拼凑目标位置 | 就像用放大镜逐块检查整张图,找到目标再标记位置 |
| 问题 | 计算量巨大,每个窗口都要单独处理;定位精度依赖分类结果拼凑 | 翻阅整本书寻找关键词,每页都要仔细看一遍 |
| 2.0 卷积化检测 | 将整幅图像送入卷积网络,卷积层自动完成滑动和特征提取,输出二维特征图表示各位置分类结果;全连接层可被等效卷积替代 | 不用逐页检查,而是扫描整本书,自动标记出现关键词的区域 |
| 窗口在特征图中传播 | 随着卷积层堆叠,每个特征图位置对应输入图像的一个大窗口区域;训练阶段采用弱监督,只需部分高响应位置预测正确即可 | 小窗口信息逐渐汇聚,像放大镜自动跟踪关键区域 |
| 标签设计 | 输出特征图使用图像级标签,卷积网络自动学会空间位置响应,无需对每个窗口手工标注 | 给整本书一个主题标签,网络自动找到相关章节 |
| 3.0 YOLO | 网络直接预测每个网格单元内目标的类别和边界框;端到端训练,不再依赖滑动窗口或重复计算 | 每个网格像一个小探员,直接告诉你目标在这里,并画出轮廓 |
| YOLO 标签规范 | 每个网格包含 \(p_c\)(是否有目标)、\(b_x,b_y,b_h,b_w\)(边界框位置)、\(c_n\)(类别);输出维度 \(S \times S \times (5 + c_n)\) | 每个小探员携带完整信息卡片,报告目标位置和类型 |