上一回咱们聊完了服务的注册发现,接下来就得直面一个微服务世界里谁都逃不掉的问题------全链路日志。为了让大家能轻松跟上节奏,老规矩,还是先从一个真实场景说起。
1 业务场景:这个请求到底经历了什么
接着上回,业务线刚"搬家"到 Spring Cloud,但为了省事,注册中心沿用了原来的 ZooKeeper,只引入了 Feign 做服务调用。这架构一定,立马就暴露了一个头疼问题:日志散得到处都是,根本串不起来。
以前单体应用时,日志往本地文件一丢,再用 ELK 收集一下,看似也够用。可一旦拆成微服务,这种"各扫门前雪"的日志方式,在排查问题时简直是一场噩梦。
举个真实的"车祸现场":
有一次,某用户总是登录失败,调用链路是:UserAPI → AuthService → UserService。
在 UserAPI 的日志里,我们还能靠用户名和时间戳,勉强跟到一个线程 ID 的所有记录。但请求一到 AuthService 就抓瞎了------同一时刻,多个服务节点、成百上千个线程都在跑,你根本分不清哪条日志才是刚才那个请求的"亲兄弟"。
最后怎么办?等半夜没流量了,运维同学手动重试了好几次,才像大海捞针一样,在某个节点的日志文件里挖到了线索。结果发现,问题竟是因为一个参数里的特殊字符,被 Tomcat 默默丢弃了。
经此一役,项目组痛定思痛,决定把日志规范提上日程。我们梳理出三条核心的日志记录需求:
- 中间件操作:调用缓存、MQ、ES 等,要记清在哪个类、哪个方法、耗时多久。
- 数据库访问:执行了什么 SQL,耗时多久。
- 服务间调用:调了哪个服务、什么方法、耗时多久。
但这还不够。一个请求往往会穿过多个服务,因此又补充了两条全局性需求:
- 全链路串联:能把同一个请求在所有服务中的上述日志,串成一棵完整的"调用树"。
- 统计与查询:能基于这些结构化日志,做查询和基础的数据统计。
这样一来,理想状态就清晰了:一个页面,就能看清一个请求的完整生命周期树。日后线上再出问题,调查效率将大幅提升。
需求明确了,下一步就是技术选型------该用哪种开源方案来实现这套全链路日志追踪?咱们下一章接着聊。
2 技术选型
面对市面上众多的全链路日志中间件(如原文表所示),项目组没有盲目,而是制定了一套清晰的选型原则
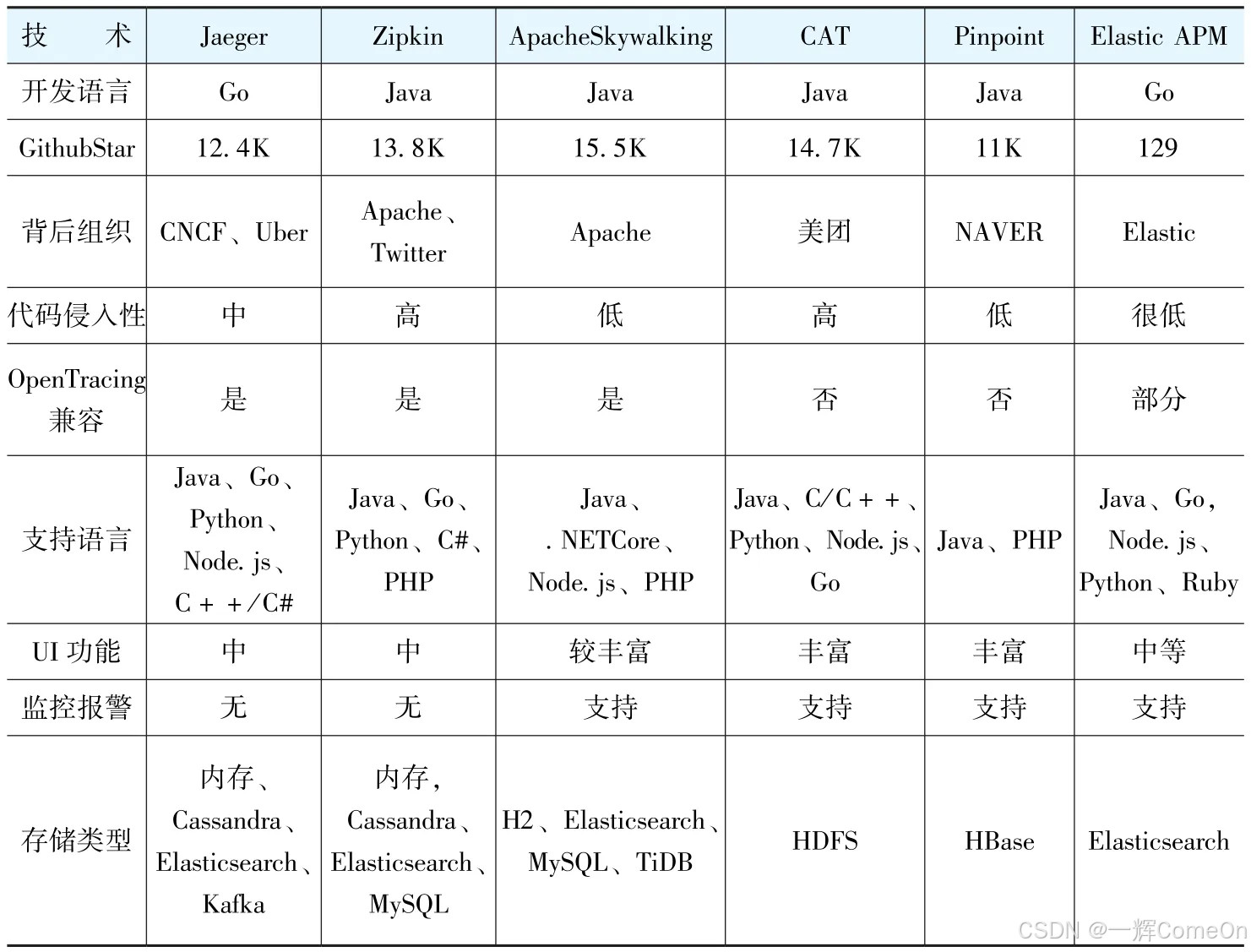
2.1 日志数据结构支持OpenTracing
过去日志一行行孤立无援,只能靠线程ID强行"拉郎配"。我们需要一个更强大的数据结构,能把一个请求在所有服务中的碎片日志串联成完整故事。OpenTracing 就是这个故事的"通用语法"。它由云原生计算基金会(CNCF)维护,提供了一套与具体实现无关的API。选择它,相当于给系统上了"保险"------即便当前选用的实现不理想,未来也能轻松更换,避免被单一技术锁死。
接下来解释一下OpenTracing标准,它主要包含两个概念:一个是Trace,一个是Span。先来看看下面的例子,如图所示。
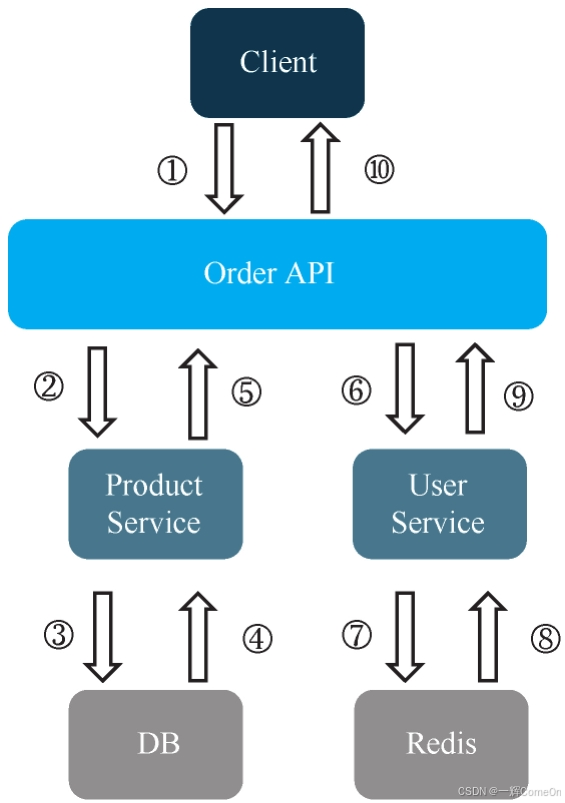
我们来具体拆解一下OpenTracing的核心概念,它其实就像给一次完整的线上请求拍一部"微电影"。
- Trace(追踪) :就是整部"电影"。它完整记录了一个外部请求(比如用户下单)从发起到结束的全部旅程。客户端调用Order API的完整流程①~⑩,就是一个Trace。
- Span(跨度) :是电影中的一个个"关键场景"。它代表了一个具有名称、可计时的连续操作单元。例如,图中Order API调用Product Service的整个过程②~⑤,就是一个独立的Span。
- 父子关系与Reference(引用) :精彩之处在于,场景里还能嵌套子场景。比如在Product Service处理(Span)中,访问数据库的操作③④本身又是一个更细粒度的Span。因此,Span之间可以形成父子嵌套关系,这种关系就称为Reference。这让我们能清晰地看到调用链的层次结构。
为什么我们坚决拥抱OpenTracing标准?这背后有一个血泪教训:过去我们曾深度绑定某个特定框架,结果它停止维护后,我们立刻陷入两难------全盘迁移代价高昂;不迁移则意味着抱着过时的技术负重前行,维护成本陡增。正因为掉过这个坑,项目组在这次选型上达成高度共识:必须保证系统的可替代性,绝不能把自己"焊死"在某一项具体实现上。 而采用OpenTracing这套厂商中立的开放标准,正是为此上的关键保险。未来即便需要更换底层追踪系统,业务代码也无需伤筋动骨。
2.2 支持Elasticsearch作为存储系统
海量日志的存储与高效查询是硬性要求。考虑到公司运维团队对Elasticsearch(ES)的技术栈非常熟悉,将其作为日志存储后端顺理成章。ES强大的全文检索与聚合分析能力,正好能满足我们后续的查询统计需求。
2.3 保证日志的收集对性能无影响
日志收集绝不能拖慢业务!我们曾调研过Pinpoint,发现在一定并发下,其吞吐量会导致服务性能腰斩,这直接越过了我们的底线。理想的方案必须在高负载下,对服务性能的影响微乎其微(通常要求吞吐量下降不超过10%)。
2.4 查询统计功能的丰富程度
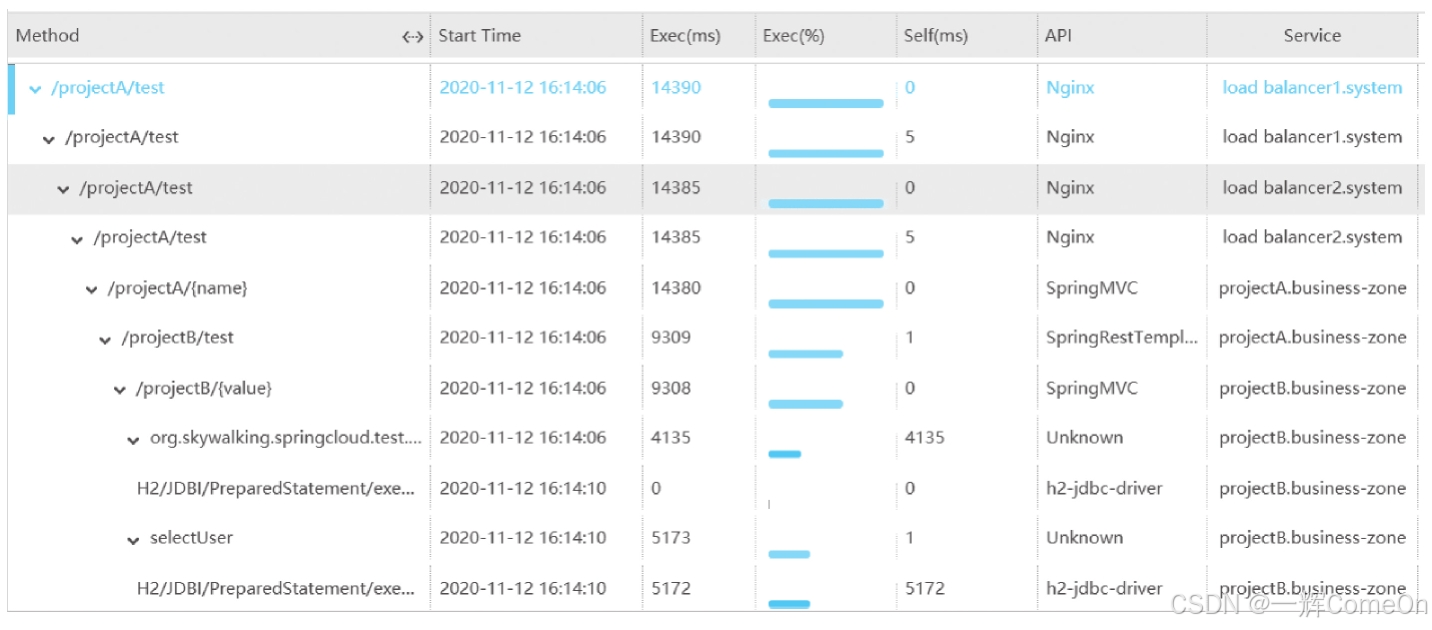
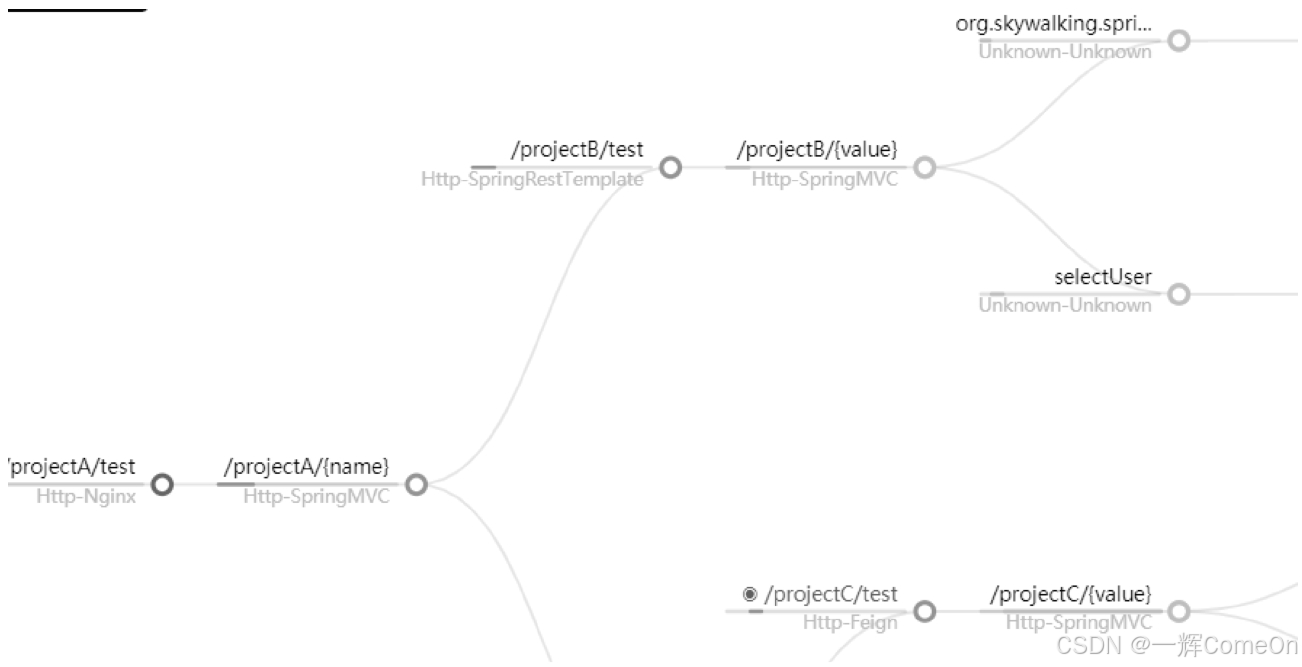
基础中的基础是:必须能清晰展示每个请求的树状全链路调用图,如下图所示)。在此之上,如果自带丰富的监控报警、性能指标统计等功能,就能大大减少我们的二次开发成本。SkyWalking的UI功能在这方面就非常突出。

如何以最小的业务代码侵入性引入这些功能?
项目组希望日志数据的收集过程对写业务代码的人保持透明,因此,一种比较理想的解决方案是使用Java的探针,通过字节码加强的方式进行埋点。不过,这种方式对系统性能也会产生一定影响。
而且在实际业务中,公司都会把访问数据库、Redis、MQ的代码进行封装,无法通过字节码加强的方式实现埋点,就只能尝试在封装的代码中实现,这样对开发业务代码的人来说同样透明。
2.5 使用案例
一个被众多大型复杂业务场景验证过的技术,其稳定性和坑点解决方案都更有保障。社区的活跃度和"前辈们"的实战经验,是重要的信心来源。
2.6 最终选择
综合以上原则,并经过严格的性能压测(结果与官方报告一致:在500并发以下,对服务吞吐量影响通常<10%),SkyWalking脱颖而出,成为我们的最终选择。
除了它完美契合上述技术要求外,还有两个不可忽视的因素:
主观倾向: 技术选型也需考虑团队的技术偏好与熟悉度。
国产开源力量的崛起: 正如Vue、Dubbo等优秀国产框架一样,SkyWalking作为Apache顶级项目,由国人主导,更贴近国内开发者的实际需求和运维习惯,社区响应迅速,文档友好。
至此,技术方案尘埃落定。接下来,就是如何将它落地到我们的Spring Cloud架构中了。
3 注意事项
确定了SkyWalking作为技术方案,但在正式引入前,我们必须搞清楚它的运行机制和容错能力,避免给线上系统埋下隐患。
3.1 SkyWalking的数据收集机制
试想一下,如果每次记录日志都需要实时、同步地等待远端服务响应,会是什么场景?那意味着业务线程必须"原地挂起",直到日志成功发送出去后才能继续工作。这无疑会直接拉长每个请求的响应时间,让性能变得无法接受。
更关键的是,这种设计会导致系统架构的致命耦合:高可用的核心业务系统,竟然依赖于一个可用性要求相对较低的辅助系统(日志系统)。这违反了架构设计的基本原则------绝不能"让一个将军(业务系统)去等一个信使(日志系统)的汇报"。
因此,日志收集必须是异步的,且与核心业务流程完全解耦。
SkyWalking正是这么做的。它在每个服务实例中设计了一个本地内存缓冲区(Buffer)。所有埋点产生的追踪数据(Trace)会先被快速写入这个缓冲区,就像把快递先放入家门口的快递柜。随后,一个独立的后台线程会异步、批量的将缓冲区中的数据"打包"发送给SkyWalking的服务端。
这样一来,业务代码在执行埋点时,完全无需等待网络I/O,写缓冲区内存的操作是微秒级的,从而实现了近乎零性能损耗的数据采集。
3.2 如果SkyWalking服务端宕机了,会出现什么情况
一个很自然的问题是:如果服务端宕机,客户端缓冲区里的数据发不出去,岂不是会越积越多,最终导致内存溢出(OOM),拖垮业务服务?
这一点SkyWalking早有防备。其客户端缓冲区的容量是有上限的,并配置了相应的内存保护策略。当服务端不可用或网络异常时,如果缓冲区被填满,新的Trace数据将被果断丢弃,而不是无限堆积。
这体现了一种 "断臂求生"的工程智慧:在极端情况下,优先保障业务主流程的稳定运行是第一位。丢失部分可追溯的日志虽然可惜,但远比因日志收集导致整个服务崩溃要好。毕竟,日志系统的核心价值是在绝大多数时候帮助我们排查问题,它自身不能成为新的故障源。
3.3 流量较大时,如何控制日志的数据量
面对突发高并发流量,收集每一个请求的日志是不现实的,那会产生海量数据,对存储和传输都是巨大负担。因此,采样(Sampling) 是必选项。
SkyWalking允许你在每个服务上配置采样率。例如,将 sampleRate 设置为 100,意味着只收集大约1%的请求数据。你可以根据流量规模灵活调整:流量越大,采样率通常设得越低,代码如下所示。
nginx
agent-analyzer:
default:
forceSampleErrorSegment: true # 强烈建议设置为 true
sampleRate: ${SW_AGENT_ANALYZER_SAMPLE_RATE:10000} # 默认10000=100%采样
...但这里有两个至关重要的细节:
错误全记录:一旦启用 forceSampleErrorSegment: true (强烈建议),那么所有出错的请求追踪都会被完整收集,不受采样率限制。这确保了问题排查时,我们总能拿到"案发现场"的完整证据。
采样率一致:在整个调用链中,所有服务的采样率必须保持一致。如果服务A以1%的采样率调用服务B,而B是10%的采样率,那么绝大多数情况下,一个Trace在B服务端就"断掉"了,无法串成完整链路。
3.4 日志的保存时间
全链路日志不需要永久保存,通常保留近期(如1-3个月)的数据即可,具体时长请根据公司合规与运维需求设定。SkyWalking支持对ES中的索引(Index)进行生存时间(TTL)配置,实现数据的自动过期清理,无需再额外开发维护脚本。SkyWalking进行配置代码如下所示。
nginx
storage:
selector: ${SW_STORAGE:elasticsearch} # 假设使用ES存储
elasticsearch:
# 记录数据(如追踪的span详情)保留75天
recordDataTTL: ${SW_STORAGE_ES_RECORD_DATA_TTL:75}
# 指标数据(如服务响应时间指标)保留365天
metricsDataTTL: ${SW_STORAGE_ES_METRICS_DATA_TTL:365}
# ... 其他ES配置3.5 集群配置:如何确保高可用
先来看看SkyWalking官方文档给出的SkyWalking架构,如图所示。
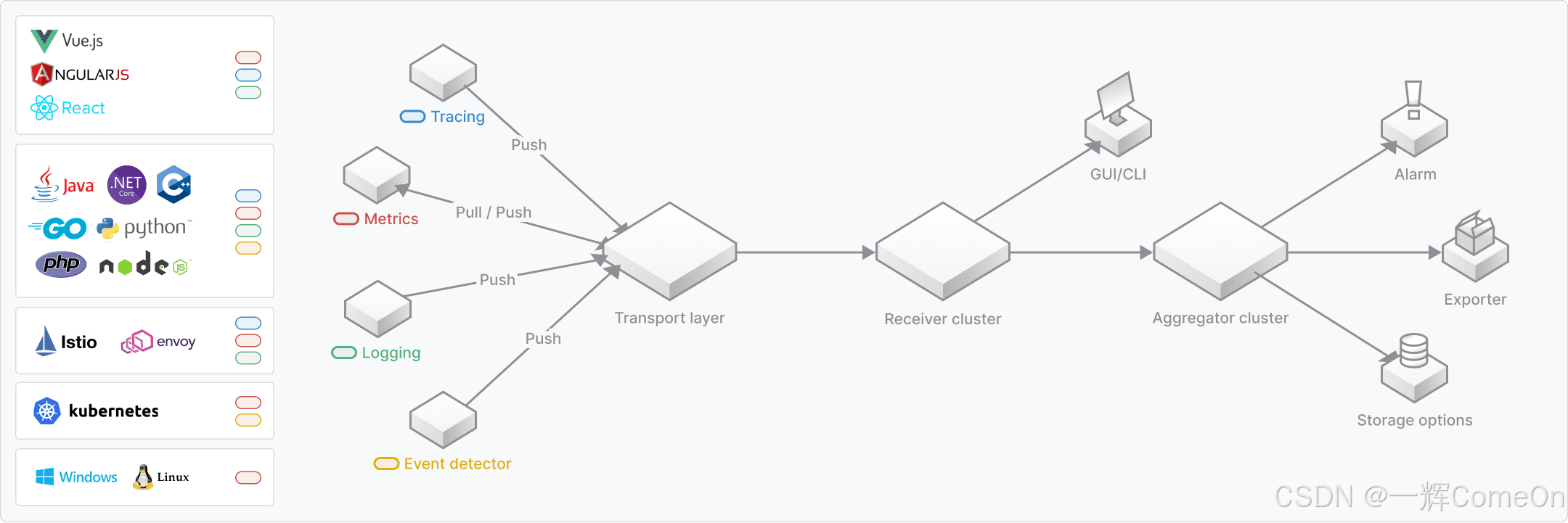
对于生产环境,SkyWalking服务端(包括Receiver和Aggregator组件)必须支持集群部署,以避免单点故障。其集群协调依赖于外部的协调服务,官方支持Kubernetes、ZooKeeper、Consul、Nacos等主流方案。鉴于我们项目中已长期使用并熟悉ZooKeeper,它自然成为集群协调组件的最终选择。
4 小结
引入SkyWalking后,问题排查效率获得了质的提升。再次面对"用户登录失败"这类问题时,我们只需根据一个TraceID,就能在界面中一键拉出贯穿所有服务的、树状结构的完整调用日志,每个环节的耗时与状态一目了然。
不仅如此,该系统还成为了性能优化的利器。所有慢请求的瓶颈点被清晰暴露,团队据此完成了多项有效的性能调优,产出了不少可汇报的技术成果。
当然,SkyWalking早期版本曾存在一些兼容性问题,但如今其成熟度已显著提高。选用其最新稳定版本,基本可以规避大部分已知陷阱。
本次架构实践的重点并非复杂的设计,而在于贴合需求的技术选型和对关键细节的把握。希望通过以上剖析,能帮助你高效理解全链路日志的核心,并在自己的技术选型中做出明智的决策。